【实战】从0到1构建互联网消费金融智能风控系统:基于WOE-IV-LR的信用评分卡模型
导读:
随着互联网消费金融的快速发展,单日放贷笔数突破百万量级,传统依赖人工审核的模式已无法满足需求。信用评分卡(Credit Scorecard)凭借着其极强的可解释性和稳定性,成为了金融风控领域的工业级标准方案。
本文将复盘我近期独立完成的一个智能风控信用评估系统。文章将从业务背景、数据预处理、核心方法论(WOE-IV-LR)、评分转换公式到常见问题的Q&A进行全流程剖析,希望能为对金融数据分析、AI产品经理方向感兴趣的小伙伴提供一些鄙人的拙见。
一、项目概述与核心亮点
本项目是一套面向 消费金融场景的信用评分卡系统,实现了从数据清洗、特征筛选、模型训练到 Web 应用部署的全目标闭环。
- 业务目标:预测借款人违约概率,自动做出审批决策,并输出直观的信用评分(如:300-900分)及五级信用评级。
- 技术栈选型:Python (数据清洗/建模) + WOE-IV-LR模型 + Flask (RESTful API API部署) + HTML/JS (玻璃拟态前端交互)。
- 最大亮点(可解释AI落地):不仅给出“通过”或“拒绝”,系统还会基于特征对评分的负向贡献度,实时反推导致拒件的 Top-3 核心风险因素(如:负债收入比过高),满足金融监管“可解释、可审计”的要求。
二、业务背景:为什么是 WOE + 逻辑回归?
为什么放着精度极高的 XGBoost 或 LightGBM 不用,金融界偏偏钟爱看似老旧的逻辑回归(LR)?
这是一个典型的 业务与技术 问题:
- 监管合规与可解释性(核心因素):金融信贷严格受巴塞尔协议等监管,模型绝不能是“黑盒”。如果拒绝了用户的借款,必须能给出明确的理由。逻辑回归是极简的线性组合,特征权重一目了然;配合 WOE 分箱,实现了完美的白盒化。而集成树模型虽然精度高,但很难解释具体某个特征的单调影响。
- 天然单调性:我们在分箱时会刻意保证 WOE 值与违约率的单调关系。逻辑回归非常契合这种线性假设。
- 极佳的鲁棒性(稳定性):风控模型经常一跑就是大半年,LR 结合 WOE 分箱天然抗异常值(极端值会被压在同一个箱内),PSI(群体稳定性)表现远好于容易过拟合的树模型。
因此,选择 WOE + IV + (逻辑回归)Logistic Regression 的原因:它是业界公认的工业级标准风控模型。每一个特征对违约的具体贡献度是一目了然的线性相加关系(白盒),具有极高的可解释性和稳定性。
三、项目实战全流程拆解
1. 数据质量诊断与清洗
本项目使用了约 8万条模拟消费金融数据(包含 28 个变量)。且数据集经过脱敏处理,并在以下方面刻意保留了真实业务数据的典型质量问题:
|
数据质量问题类型 |
具体表现 |
数量规模 |
|
重复记录 |
完全重复的申请行 |
约500条 |
|
缺失值 |
月收入、工作年限等字段存在缺失 |
各1.5%-2% |
|
异常值 |
年龄出现负数/超大值;信用卡使用率超过1 |
各0.5%-1% |
|
拼写不一致 |
学历字段存在"大专""专科""大 专"等变体 |
15%的学历记录 |
|
单位错误 |
部分贷款金额以"万元"而非"元"录入 |
约2%的金额记录 |
|
类别同义词 |
申请渠道"APP""app""手机APP"混用 |
约10%的渠道记录 |
重要提示:在正式建模之前,上述所有数据质量问题必须被识别和处理,否则模型结果将严重失真。数据清洗质量直接影响后续评分卡的有效性。
数据质量诊断报告:
|
字段名 |
缺失值数量 |
缺失率 (%) |
唯一值数量 |
数据类型 |
处理方式 |
|
app_id |
0 |
0 |
80000 |
object |
唯一标识,无需处理 |
|
apply_date |
0 |
0 |
1460 |
object |
日期字段,无需处理 |
|
age |
0 |
0 |
51 |
float64 |
异常值替换为 NaN,按教育程度分组中位数填充 |
|
education |
0 |
0 |
15 |
object |
统一拼写,消除噪声变体 |
|
marital_status |
0 |
0 |
5 |
object |
类别变量,无需处理 |
|
province |
0 |
0 |
12 |
object |
类别变量,无需处理 |
|
is_urban |
0 |
0 |
2 |
int64 |
二分类变量,无需处理 |
|
monthly_income |
1607 |
2 |
19126 |
float64 |
连续型,中位数填充 |
|
debt_to_income_ratio |
0 |
0 |
6808 |
float64 |
连续型,无需处理 |
|
job_tenure_months |
1210 |
1.5 |
360 |
float64 |
连续型,中位数填充 |
|
employment_type |
0 |
0 |
6 |
object |
类别变量,无需处理 |
|
company_size |
0 |
0 |
5 |
object |
类别变量,无需处理 |
|
hist_overdue_30d_count |
0 |
0 |
10 |
int64 |
计数型,无需处理 |
|
hist_overdue_90d_count |
0 |
0 |
10 |
int64 |
计数型,无需处理 |
|
num_credit_accounts |
806 |
1 |
20 |
float64 |
计数型,0 填充 |
|
credit_utilization_rate |
0 |
0 |
9140 |
float64 |
连续型,截断至 [0,1] |
|
credit_inquiries_6m |
0 |
0 |
20 |
int64 |
计数型,无需处理 |
|
num_credit_cards |
0 |
0 |
15 |
int64 |
计数型,无需处理 |
|
oldest_account_months |
1608 |
2 |
240 |
float64 |
连续型,中位数填充 |
|
has_bad_record |
0 |
0 |
2 |
int64 |
二分类变量,无需处理 |
|
loan_purpose |
0 |
0 |
7 |
object |
类别变量,无需处理 |
|
loan_amount |
0 |
0 |
16 |
float64 |
连续型,修正单位错误 |
|
loan_term_months |
0 |
0 |
5 |
int64 |
计数型,无需处理 |
|
apply_channel |
0 |
0 |
12 |
object |
统一拼写,消除噪声变体 |
|
apply_hour |
0 |
0 |
24 |
int64 |
计数型,无需处理 |
|
apply_weekday |
0 |
0 |
7 |
int64 |
计数型,无需处理 |
|
device_risk_score |
0 |
0 |
707 |
float64 |
连续型,无需处理 |
|
is_default |
0 |
0 |
2 |
int64 |
目标变量,无需处理 |
|
education_cleaned |
0 |
0 |
14 |
object |
无需处理 |
根据诊断报告,我们可以进行一个各字段的处理方式选择并给出选择依据
|
字段名 |
处理方案 |
选择依据 |
|
app_id |
无需处理 |
仅用于数据溯源、去重,不参与建模,处理无意义,避免冗余操作 |
|
apply_date |
无需处理 |
原始日期无直接预测价值,需后续衍生特征(如月份、星期),暂不处理 |
|
age |
异常值替换为NaN,按教育程度分组中位数填充 |
年龄与教育程度相关性强,分组填充更贴合实际风险分布;中位数抗异常值,避免均值被极端值影响 |
|
education |
统一拼写,消除噪声变体 |
类别变量需保证同一类别表述一致,否则会被模型误判为不同类别,影响特征区分度 |
|
marital_status |
无需处理 |
类别划分清晰,无噪声、无歧义,可直接用于WOE编码及建模 |
|
province |
无需处理 |
地域类别划分明确,无噪声,可直接用于分析地域风险差异及WOE编码 |
|
is_urban |
无需处理 |
取值仅0/1,无歧义,可直接用于模型输入,反映城乡差异 |
|
monthly_income |
中位数填充 |
缺失率较低(<5%),中位数填充不影响整体分布;连续型收入变量,中位数抗极端值,贴合实际收入分布 |
|
debt_to_income_ratio |
无需处理 |
变量取值合理,无极端值、无噪声,直接反映还款能力,可直接用于建模 |
|
job_tenure_months |
中位数填充 |
缺失率低,中位数填充可保留变量分布特征;工作年限为连续型,中位数能避免极端值(如超长工作年限)的影响 |
|
employment_type |
无需处理 |
职业类型划分清晰,无噪声,可直接用于WOE编码,反映收入稳定性 |
|
company_size |
无需处理 |
企业规模划分明确,与收入稳定性、违约风险相关,可直接用于建模 |
|
hist_overdue_30d_count |
无需处理 |
逾期次数直接反映信用状况,取值合理,无噪声,可直接用于建模及分箱 |
|
hist_overdue_90d_count |
无需处理 |
严重逾期次数是核心风险指标,取值无歧义,可直接用于建模,区分度强 |
|
num_credit_accounts |
0填充 |
信用账户数量缺失,合理假设为“无信用账户”(取值0),符合业务逻辑;计数型变量0填充不影响分布,且贴合实际场景 |
|
credit_utilization_rate |
连续型,截断至[0,1] |
信用利用率的合理范围为0-1(0%-100%),超出范围为异常值;截断处理可保留有效信息,避免异常值影响模型 |
|
credit_inquiries_6m |
无需处理 |
6个月征信查询次数反映申请活跃度,取值合理,无噪声,可直接用于建模 |
|
num_credit_cards |
无需处理 |
信用卡数量反映信用状况,取值无歧义,可直接用于WOE编码及建模 |
|
oldest_account_months |
连续型,中位数填充 |
缺失率低,中位数填充可保留信用历史长度的分布特征;连续型变量用中位数抗极端值,贴合实际信用历史分布 |
|
has_bad_record |
无需处理 |
取值仅0/1(有无不良记录),直接反映核心信用风险,无歧义,可直接用于建模 |
|
loan_purpose |
无需处理 |
贷款用途划分清晰,与违约风险相关(如经营贷 vs 消费贷),可直接用于WOE编码 |
|
loan_amount |
连续型,修正单位错误 |
贷款金额为核心业务指标,单位错误会导致数值偏差,影响模型对还款能力的判断,需统一单位(如统一为“元”) |
|
loan_term_months |
无需处理 |
贷款期限取值合理,无噪声,直接反映还款压力,可直接用于建模 |
|
apply_channel |
统一拼写,消除噪声变体 |
申请渠道为类别变量,表述不一致会导致模型误判,统一拼写可保证类别完整性,便于后续分析渠道风险 |
|
apply_hour |
无需处理 |
申请小时取值为0-23,无歧义,可后续衍生特征(如工作时间/非工作时间),暂不处理 |
|
apply_weekday |
无需处理 |
申请星期取值为1-7,无歧义,可后续衍生特征(如工作日/节假日),暂不处理 |
|
device_risk_score |
无需处理 |
设备风险评分已为标准化指标,取值合理,直接反映设备安全风险,可直接用于建模 |
|
is_default |
无需处理 |
目标变量(是否违约),取值仅0/1,无歧义,是模型训练的核心标签,无需任何处理 |
|
education_cleaned |
无需处理 |
已完成拼写统一、噪声消除,类别规范,可直接用于WOE编码及建模,无需重复处理 |
进行基本的数据清洗操作:
- 重复行处理的陷阱:遇到重复行能直接删吗?
- 绝对不能!!! 必须先检查重复行的违约率分布。如果重复行的违约率远高于整体,这可能是真实业务特征(比如反复提交申请),一旦盲目删除会导致整体好坏样本比例失真,极大地扭曲后续的 WOE 和 IV 计算。
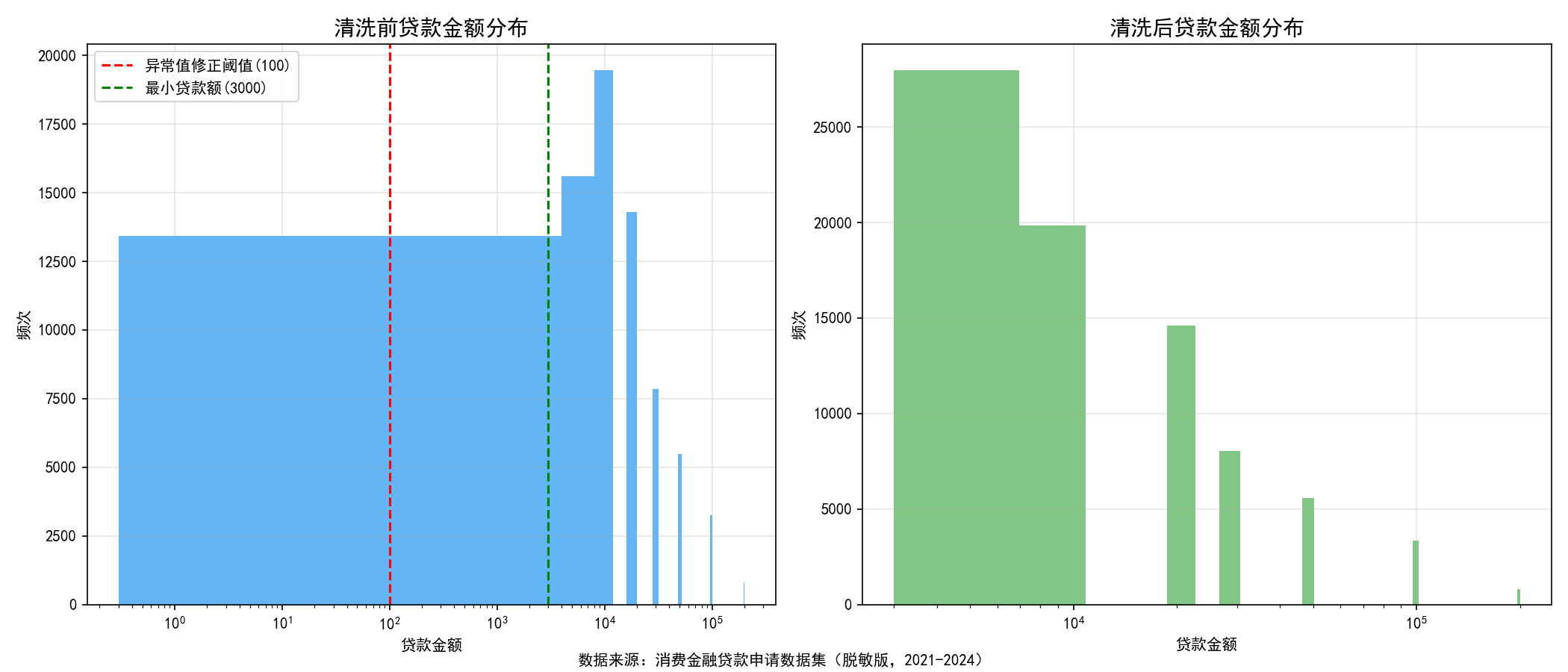
- 异常值清洗:比如数据探查发现 `贷款金额` 最小值为 0.3 元,这显然违反常理。经清洗修正后,将合理范围限定在 `[3000, 200000]`,修正了 1610 条异常业务数据。
- 标识类字段剔除:将 `app_id`(唯一标识,无预测价值)和直接的 `apply_date` 剔除或做衍生处理。
数据清洗前后样本变化量统计
|
阶段 |
样本量 |
变化量 |
变化率 |
|
原始数据 |
80500 |
- |
- |
|
删除重复行后 |
80162 |
-338 |
-0.42% |
|
最终清洗后 |
80162 |
-338 |
-0.42% |
清洗前存在缺失的数据与清洗后的对比
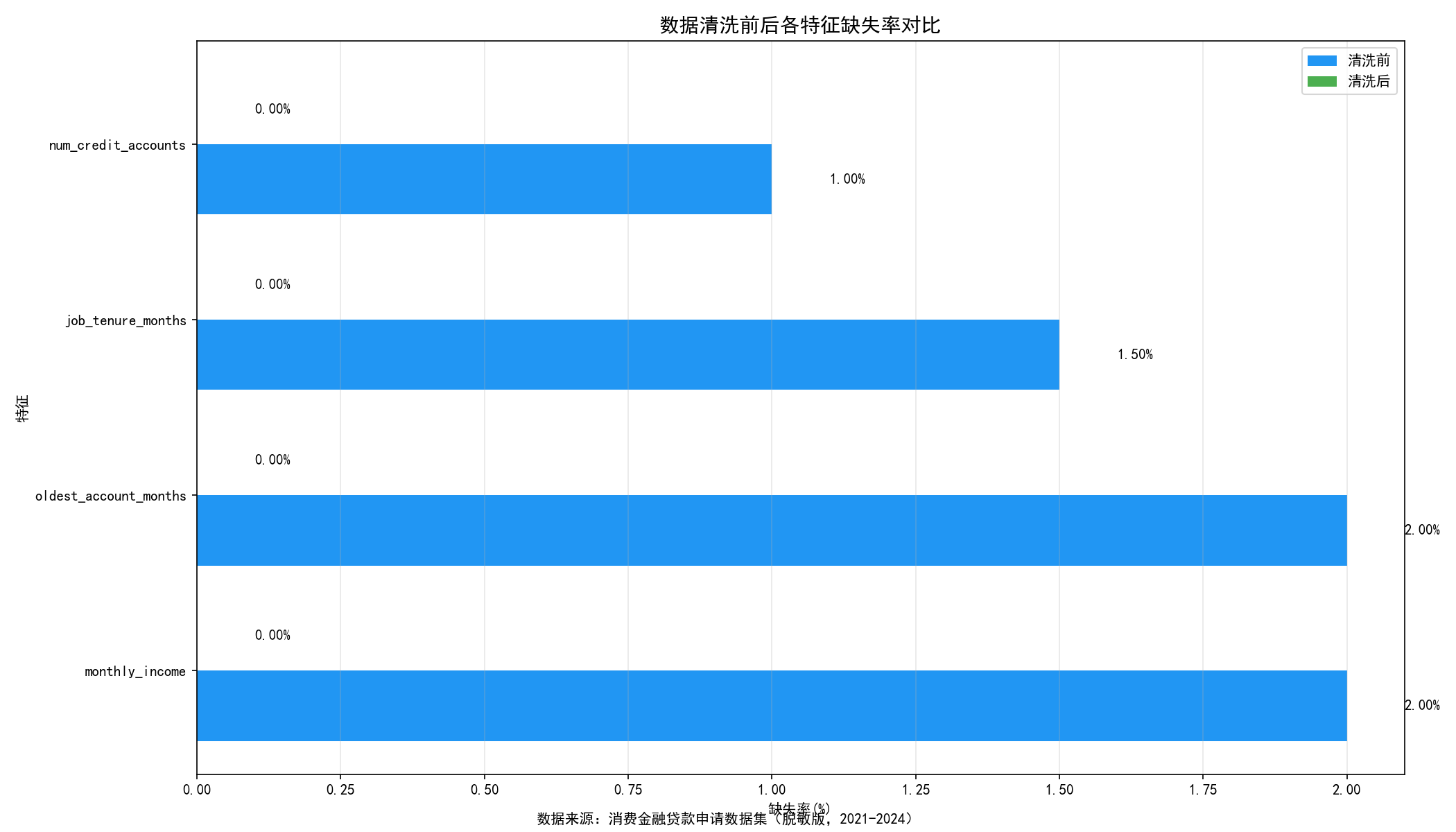
=== 贷款金额清洗前后对比 ===
清洗前贷款金额范围: [0.30, 200000.00]
清洗后贷款金额范围: [3000.00, 200000.00]
修正的异常值数量: 1610
2. 特征工程:WOE 分箱与 IV 筛选
WOE (Weight of Evidence,证据权重) 编码 [分箱]
将所有的连续变量离散化(分箱),并计算 WOE:
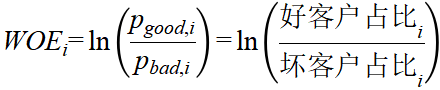
这是风控建模里最关键的一步。
例如:连续型变量(如“月收入”)不能直接扔进线性模型,必须进行离散化。
操作:把“月收入”分成几档(如:0-3000, 3000-8000, 8000+)。计算每个档次里坏人和好人的比例。
意义:将所有不同量纲、不同含义的特征(有的是钱,有的是次数,有的是率),通过公式统一映射为了 蕴含风险严重程度的值(WOE值)。如果WOE越大,说明该区间的违约概率越高。
IV (Information Value,信息值) 筛选
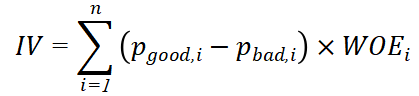
通过设定 `IV >= 0.02` 作为门槛,自动剔除对预测毫无区分度的噪音字段,本系统最终精准筛选出了 11 个核心变量(包括 `近6月查询次数`、`历史30天逾期次数`、`负债收入比` 等)。
计算了所有特征的WOE后,用IV公式计算该特征对Y标签的 整体预测区分能力。
经过 Ⅳ 值筛选操作后,得出 Ⅳ 值排序前15的特征如下:
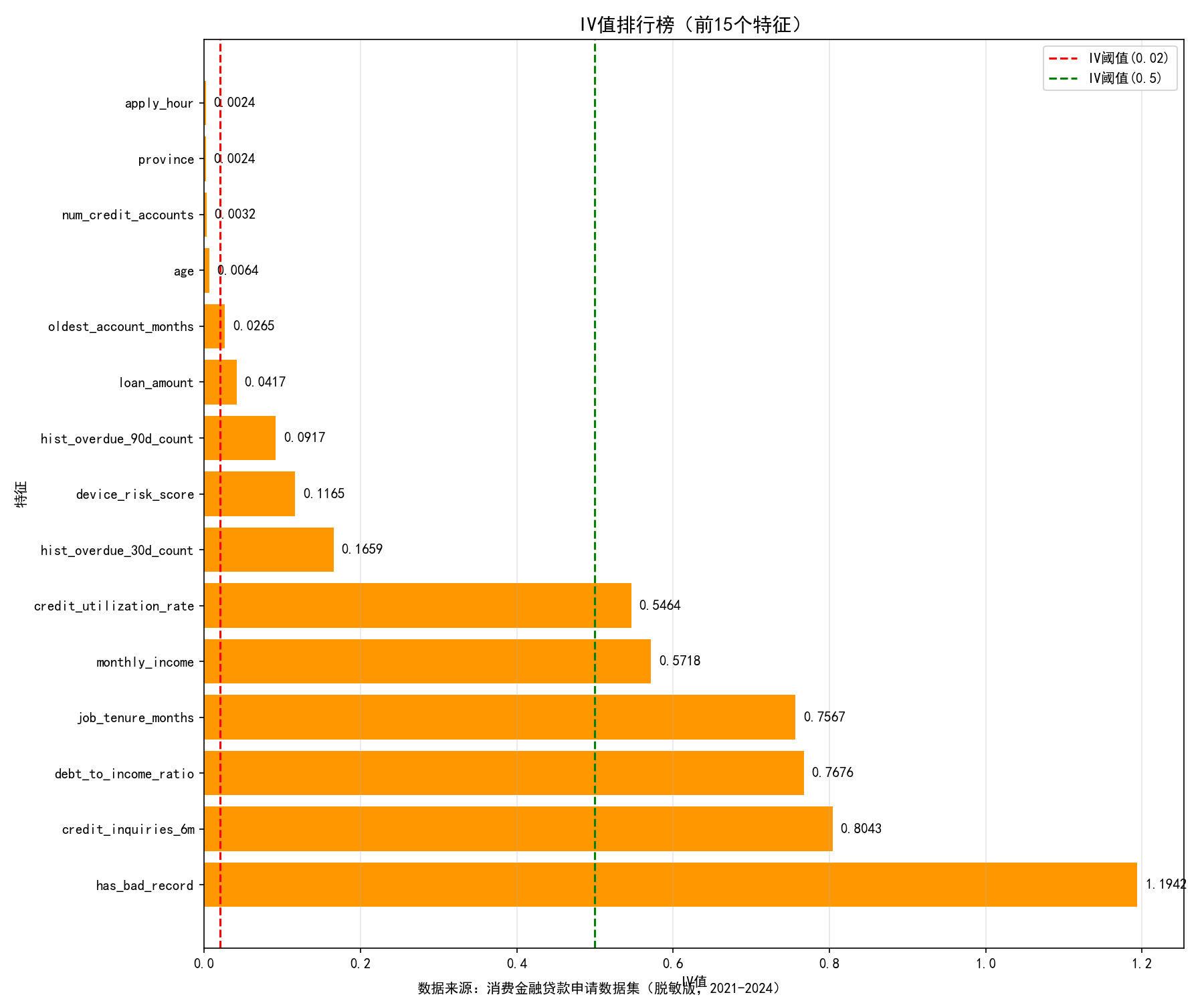
Ⅳ 值 越大,说明该特征对整体预测的能力越强。
3. 模型拟合与标准评分转换
将特征喂给逻辑回归模型后,系统吐出的是一个晦涩的违约概率 。我们要将其转化为业务通用的信用分数。
核心转换公式:
,即坏好比。
,这里的 PDO (Points to Double the Odds) 代表违约几率翻倍时,分数减少的值(本项目中设为 20 分)。
基于此,模型概率被成功映射为广为人知的 300 ~ 900 信用分区间。
4. 严格的模型评估指标
对于风控评分卡,以下三大评估指标是不可逾越的红线:
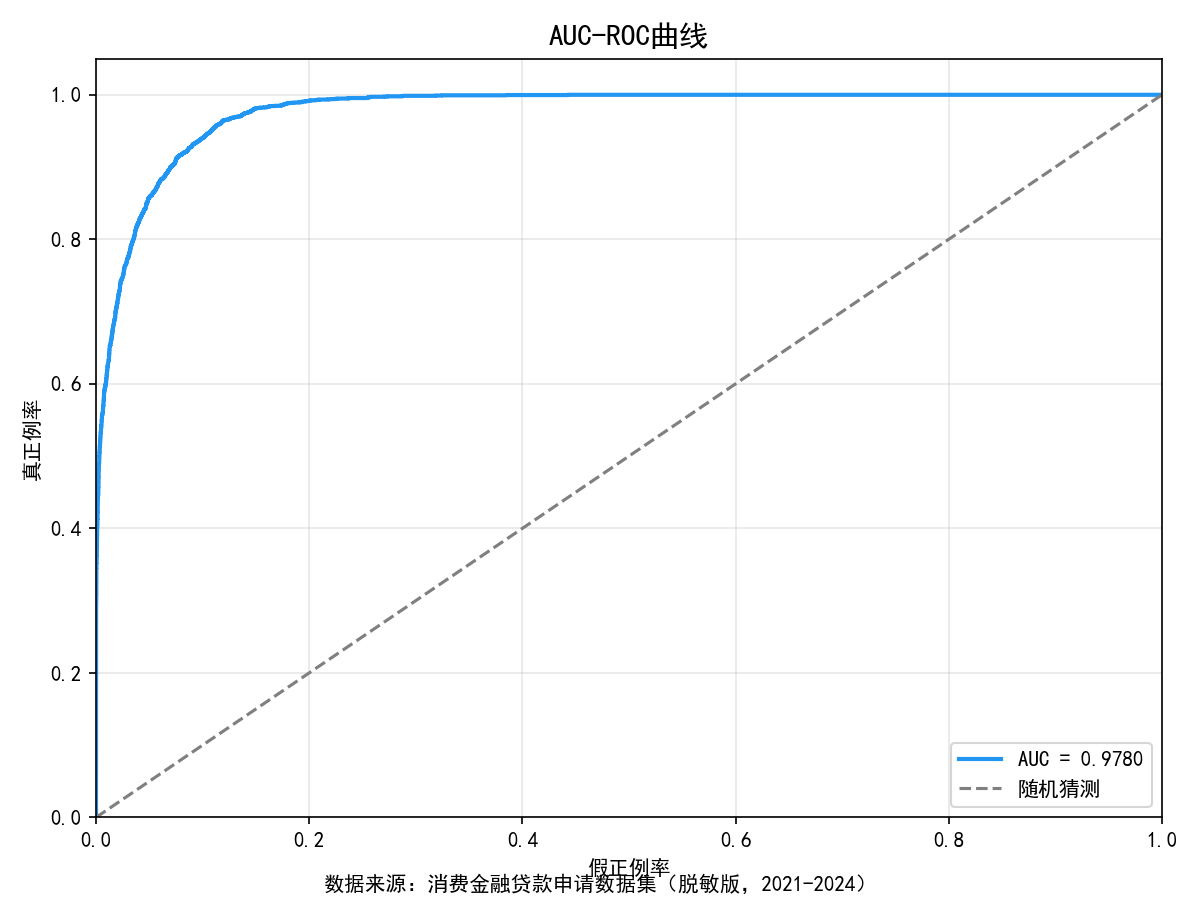
1. AUC (ROC曲线下面积):衡量整体排序准度。本项目高达 0.978,分类能力卓越。
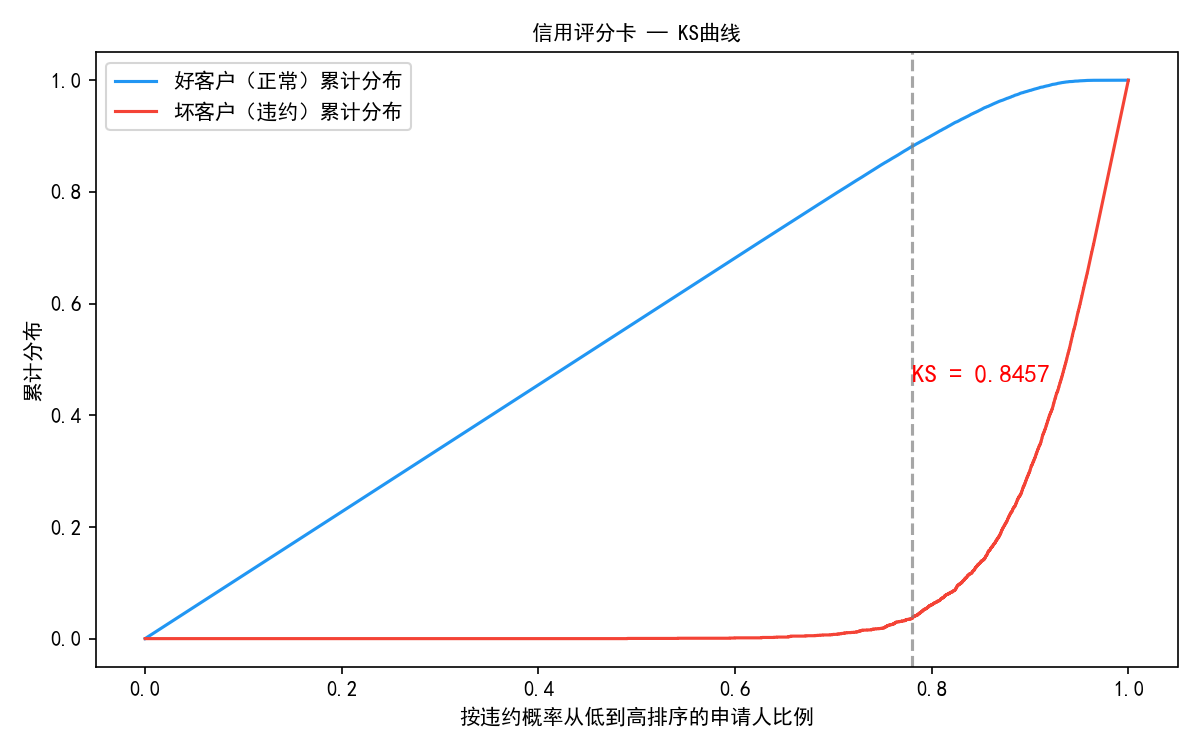
2.KS (Kolmogorov-Smirnov):衡量好坏客户累积分布的最大偏离距离。
行业标准:KS > 0.2 才认为模型有基本区分能力;0.3-0.5 为良好;> 0.5 为优秀。
本项目达到了优异的 0.8455。
公式:
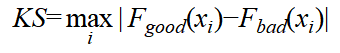
3. PSI (群体稳定性系数):衡量模型跨时间/数据集的稳定性。
行业标准:PSI < 0.1 稳定;0.1-0.25 需关注;> 0.25 模型需重新训练。
公式:
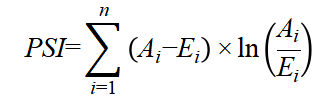
其中:
为实际分布,
为期望分布(训练集分布)
本项目测试集 PSI = 0.0006(远小于行业警戒线 0.1),说明哪怕宏观环境微变,模型依旧稳如老狗。
5.工程部署与落地呈现
1. 参数序列化 (`model_params.json`)
为了做到“零数据科学包依赖”(不需要安装臃肿的 pd/sklearn),我将刚才训练好的 LR 系数、每个特征分箱的 WOE 字典,全部抽取保存为一个轻量级的 JSON 文件。
2. 后端轻量级 Flask API (`app.py`)
Flask启动时加载 JSON。当前端用户填完表单发起 POST 请求时,Flask 进行实时查表(寻找输入值在哪个WOE箱),执行一次简单的线性加权乘法,算出信用分,并匹配出风险建议,以 JSON 格式返回给前端(全程不到10毫秒)。
3. 前端互动展现 (`index.html`)
原生HTML+JS,使用了SVG环形图动态画出分数圆环,结合玻璃拟态UI展示五级信用评级。让体验非常接近真实金融App中的查贷额度或芝麻分模块。
写在最后
由于本人只是一个 “金融 + 信管” 背景的普通双非本的学生,本文内容出自个人兴趣所作,融合了数据挖掘课程理论与实践项目。因此,难以避免在学术理论知识上存在瑕疵和技术可行性出现漏洞。若各位金融领域、技术领域的大牛们,或同为大学生的兄弟姐妹们在阅读本文的过程中,发现该文中出现的大大小小的问题,烦请各位为小弟指点迷津,提出理论修正建议和技术优化方法。
你们的宝贵意见是支撑我持续提升学术能力和强化技术能力的强心剂!
感谢你能读到这里!祝你生活愉快,学业/工作顺利!我们一起进步!
快速浏览本项目的链接:
https://Gleason007.pythonanywhere.com
鄙人的项目获取链接:
百度网盘:
链接: https://pan.baidu.com/s/1WhTWELdxL6oby_qsG0BfJA?pwd=ac22 提取码: ac22
夸克网盘:
链接:https://pan.quark.cn/s/a75ed4ad3bc7

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)