使用Chinese-CLIP识别六,九宫格图片
参考链接:大炮打麻雀 — CLIP 图文多模态模型,人均通杀 AIGC 六、九宫格验证码
具体流程:先下载 Chinese-CLIP 到本地,序列化样本图片数据,修改执行训练脚本生成pt模型文件,将pt模型转换为onnx模型,最后部署到Django5.2上。
1.下载 Chinese-CLIP 准备python环境
本地环境: python3.12, torch==2.10.0,具体如下所示
annotated-doc==0.0.4
anyio==4.12.1
asgiref==3.11.1
certifi==2026.2.25
charset-normalizer==3.4.5
click==8.3.1
colorama==0.4.6
Django==5.2.12
filelock==3.25.0
flatbuffers==25.12.19
fsspec==2026.2.0
h11==0.16.0
hf-xet==1.3.2
httpcore==1.0.9
httpx==0.28.1
huggingface_hub==1.5.0
idna==3.11
Jinja2==3.1.6
joblib==1.5.3
lmdb==1.7.5
loguru==0.7.3
markdown-it-py==4.0.0
MarkupSafe==3.0.3
mdurl==0.1.2
modelscope==1.34.0
mpmath==1.3.0
networkx==3.6.1
numpy==2.4.2
onnxruntime==1.24.3
packaging==26.0
pillow==12.1.1
protobuf==7.34.0
Pygments==2.19.2
PyQt5==5.15.11
PyQt5-Qt5==5.15.2
PyQt5_sip==12.18.0
PyYAML==6.0.3
requests==2.32.5
rich==14.3.3
safetensors==0.7.0
scikit-learn==1.8.0
scipy==1.17.1
setuptools==82.0.1
shellingham==1.5.4
six==1.17.0
sqlparse==0.5.5
sympy==1.14.0
threadpoolctl==3.6.0
timm==1.0.25
torch==2.10.0
torchvision==0.25.0
tqdm==4.67.3
typer==0.24.1
typing_extensions==4.15.0
tzdata==2025.3
urllib3==2.6.3
win32_setctime==1.2.0
WSL2 环境:Ubuntu 24.04.4 LTS,用的也是上面的本地虚拟环境,因为我本地有张4090的显卡,所以没有按参考链接去租用服务器。
本地目录结构如下图所示,下载完Chinese-CLIP项目后,创建文件夹 KG_finetune 及其子目录,子目录为空,后续操作会生成对应的数据到目录中去。
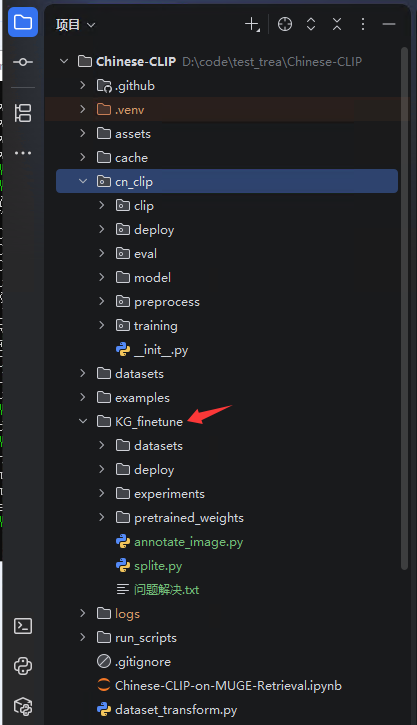
annotate_image.py 为标注程序,splite.py为数据处理程序,程序代码如下。splite.py程序我做了修改,因为参考链接中,只有通过annotate_image.py程序标注了的图片数据才能生成 .tsv 和 .jsonl 文件。但是我的图片数据已经标注好了,所以没有必要再去通过annotate_image.py标注生成这两个文件。
# annotate_image.py
import sys
import os
import json
import base64
from PyQt5 import QtWidgets, QtGui
from PyQt5.QtWidgets import QFileDialog, QVBoxLayout, QLabel, QLineEdit, QPushButton, QWidget, QListWidget
def load_progress(progress_file):
if os.path.exists(progress_file):
with open(progress_file, 'r') as f:
return json.load(f)
return {"current_idx": 0}
def save_progress(progress_file, progress_data):
with open(progress_file, 'w') as f:
json.dump(progress_data, f)
def load_annotated_texts(annotations_file):
if os.path.exists(annotations_file):
with open(annotations_file, 'r', encoding='utf-8') as f:
return json.load(f)
return {}
def save_annotated_texts(annotations_file, annotated_texts):
with open(annotations_file, 'w', encoding='utf-8') as f:
json.dump(annotated_texts, f, ensure_ascii=False)
def decode_base64_image(base64_str):
image_data = base64.b64decode(base64_str)
image = QtGui.QImage.fromData(image_data)
return image
class AnnotationTool(QWidget):
def __init__(self):
super().__init__()
self.initUI()
self.tsv_file = None
self.output_jsonl = None
self.progress_file = None
self.annotated_texts_file = None
self.lines = []
self.current_idx = 0
self.annotated_texts = {}
def initUI(self):
layout = QVBoxLayout()
# File selector button
self.file_btn = QPushButton('选择TSV文件', self)
self.file_btn.clicked.connect(self.open_tsv_file)
layout.addWidget(self.file_btn)
# Image display
self.image_label = QLabel(self)
self.image_label.setFixedSize(400, 400)
layout.addWidget(self.image_label)
# Text ID input
self.text_id_input = QLineEdit(self)
self.text_id_input.setPlaceholderText("输入文本ID")
layout.addWidget(self.text_id_input)
# Text input
self.text_input = QLineEdit(self)
self.text_input.setPlaceholderText("输入文本信息")
layout.addWidget(self.text_input)
# Save button
self.save_btn = QPushButton('保存标注', self)
self.save_btn.clicked.connect(self.save_annotation)
layout.addWidget(self.save_btn)
# List of previous annotations
self.annotation_list = QListWidget(self)
self.annotation_list.itemDoubleClicked.connect(self.fill_annotation)
layout.addWidget(self.annotation_list)
# Set layout
self.setLayout(layout)
self.setWindowTitle('图片标注工具')
def open_tsv_file(self):
options = QFileDialog.Options()
file_name, _ = QFileDialog.getOpenFileName(self, "选择TSV文件", "", "TSV Files (*.tsv);;All Files (*)",
options=options)
if file_name:
self.tsv_file = file_name
self.output_jsonl = self.tsv_file.replace('_imgs.tsv', '_texts.jsonl')
self.progress_file = self.tsv_file.replace('_imgs.tsv', '_progress.json')
self.annotated_texts_file = 'all_annotated_texts.json'
self.load_tsv()
def load_tsv(self):
with open(self.tsv_file, 'r') as f_in:
self.lines = f_in.readlines()
progress_data = load_progress(self.progress_file)
self.current_idx = progress_data["current_idx"]
# Load annotated texts from file
self.annotated_texts = load_annotated_texts(self.annotated_texts_file)
self.populate_annotation_list()
self.display_image()
def populate_annotation_list(self):
self.annotation_list.clear()
for text_id, text in self.annotated_texts.items():
self.annotation_list.addItem(f"{text_id}: {text}")
def display_image(self):
if self.current_idx < len(self.lines):
line = self.lines[self.current_idx]
image_id, image_base64 = line.strip().split('\t')
image = decode_base64_image(image_base64)
pixmap = QtGui.QPixmap.fromImage(image)
self.image_label.setPixmap(pixmap.scaled(self.image_label.size(), aspectRatioMode=1))
def save_annotation(self):
text_id = self.text_id_input.text()
text = self.text_input.text()
if text_id and text:
line = self.lines[self.current_idx]
image_id, _ = line.strip().split('\t')
image_id = int(image_id)
existing_annotations = {}
if os.path.exists(self.output_jsonl):
with open(self.output_jsonl, 'r', encoding='utf-8') as jsonl_file:
for line in jsonl_file:
entry = json.loads(line.strip())
existing_annotations[entry["text_id"]] = entry
if int(text_id) in existing_annotations:
existing_annotations[int(text_id)]["image_ids"].append(image_id)
else:
existing_annotations[int(text_id)] = {
"text_id": int(text_id),
"text": text,
"image_ids": [image_id]
}
with open(self.output_jsonl, 'w', encoding='utf-8') as jsonl_out:
for entry in existing_annotations.values():
jsonl_out.write(json.dumps(entry, ensure_ascii=False) + "\n")
# Add to the annotated texts and update the list
if text_id not in self.annotated_texts:
self.annotated_texts[text_id] = text
self.annotation_list.addItem(f"{text_id}: {text}")
# Save annotated texts to file
save_annotated_texts(self.annotated_texts_file, self.annotated_texts)
self.current_idx += 1
save_progress(self.progress_file, {"current_idx": self.current_idx})
# Clear inputs and load next image
self.text_id_input.clear()
self.text_input.clear()
self.display_image()
def fill_annotation(self, item):
# Fill the text ID and text when a list item is double-clicked
text = item.text()
text_id, annotation_text = text.split(": ", 1)
self.text_id_input.setText(text_id)
self.text_input.setText(annotation_text)
if __name__ == '__main__':
app = QtWidgets.QApplication(sys.argv)
tool = AnnotationTool()
tool.show()
sys.exit(app.exec_())
修改 split.py 文件遇到问题
在根据图片名进行分类生成jsonl字典时,创建了init_text_id_list字典列表,该列表传入到save_images_to_tsv()函数中时,未在该函数中创建临时列表进行深拷贝
导致valid_texts.jsonl和test_texts.jsonl的值是在train_texts.jsonl值的基础上不断增加的。
该问题导致最后训练结束对验证数据进行验证时出现:AttributeError: 'NoneType' object has no attribute 'tobytes'
这是因为程序在验证集(Valid)的 LMDB 数据库中找不到对应的图片 ID,导致返回了空值(None),
因为valid_texts.jsonl中有train_texts.jsonl的值,但是这些值在valid_imgs.tsv中找不到导致的
# splite.py
import os
import json
import random
import base64
from PIL import Image
from io import BytesIO
from sklearn.model_selection import train_test_split
def image_to_base64(file_path):
# Convert image to base64 string
with Image.open(file_path) as img:
img_buffer = BytesIO()
img.save(img_buffer, format=img.format)
byte_data = img_buffer.getvalue()
base64_str = base64.b64encode(byte_data).decode('utf-8')
return base64_str
def generate_random_id(length=10):
# Generate a random number with the specified number of digits
return ''.join([str(random.randint(1, 9)) for _ in range(length)])
def save_images_to_split_tsv(image_dir, output_dir, train_ratio=0.8, val_ratio=0.1, test_ratio=0.1, id_length=15):
# 获取所有图片文件
image_files = os.listdir(image_dir)
# 根据图片名进行分类生成jsonl字典,后续保存tsv文件的时候再将该数据一起保存
# {"text_id": 1, "text": "柠檬", "image_ids": []}
# 获取所有图片类别
text_id_set = set()
for name in image_files:
text = name.split('_')[0]
text_id_set.add(text)
# 初始类别字典列表
init_text_id_list = []
text_id = 1
for text in text_id_set:
init_text_id_list.append({"text_id": text_id, "text": text, "image_ids": []})
text_id += 1
# 创建临时列表,
# 随机分成训练集、验证集和测试集
train_files, test_files = train_test_split(image_files, test_size=test_ratio)
train_files, val_files = train_test_split(train_files, test_size=val_ratio / (train_ratio + val_ratio))
# 保存到不同的TSV文件中
save_images_to_tsv(train_files, os.path.join(output_dir, 'train_imgs.tsv'), image_dir, id_length, init_text_id_list)
save_images_to_tsv(val_files, os.path.join(output_dir, 'valid_imgs.tsv'), image_dir, id_length, init_text_id_list)
save_images_to_tsv(test_files, os.path.join(output_dir, 'test_imgs.tsv'), image_dir, id_length, init_text_id_list)
def save_images_to_tsv(image_files, output_file, image_dir, id_length, init_text_id_list):
# 图片列表,输出文件名,图片路径,id长度
jsonl_file = output_file.replace('_imgs.tsv', '_texts.jsonl')
with open(output_file, 'w') as f_out:
for file_name in image_files:
file_path = os.path.join(image_dir, file_name)
image_id = generate_random_id(id_length)
# 将图片id添加到初始类别列表中
for dic in init_text_id_list:
text = file_name.split('_')[0]
if text in dic['text']:
dic['image_ids'].append(image_id)
try:
base64_str = image_to_base64(file_path)
f_out.write(f"{image_id}\t{base64_str}\n")
except Exception as e:
print(f"Error processing {file_name}: {e}")
with open(jsonl_file, 'w', encoding='utf-8') as f_out:
for i in init_text_id_list:
f_out.write(f'{json.dumps(i, ensure_ascii=False)}\n')
if __name__ == '__main__':
# Example usage
image_directory = 'img'
output_directory = 'datasets'
save_images_to_split_tsv(image_directory, output_directory)
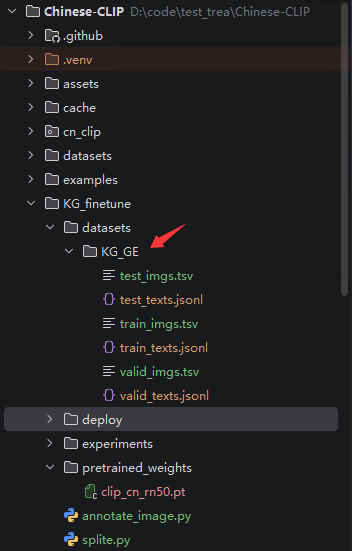
生成的jsonl文件和tsv文件如下图所示


jsonl文件和tsv文件放在 KG_finetune/datasets/KG_GE 目录下
2.序列化样本图片数据
在WSL中执行该命令
python cn_clip/preprocess/build_lmdb_dataset.py --data_dir KG_finetune/datasets/KG_GE --splits train,valid,test
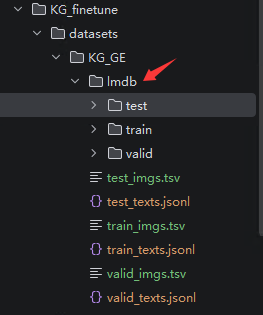
windows下执行可能出现的问题:lmdb.Error: .\KG_finetune\datasets\KG_GE\lmdb\train\imgs: ���̿ռ䲻�㡣 该问题为磁盘空间不足导致的,在Windows环境下执行序列化代码时出现,LMDB 是一种内存映射数据库,它在创建数据库文件时,并不会根据你实际塞进去的数据大小来一点点膨胀,而是会根据代码里的设置,一次性向操作系统申请并预先分配一块巨大的空间,所以会导致出现这个问题 解决方法为修改build_lmdb_dataset.py文件中的map_size参数,设置合适的大小,这里设置为20GB,map_size=1024**3*20 PS:实际在WSL2中执行该序列化程序时,并不会像Windows一样给每个数据集分配20GB LMDB数据,而是根据你的实际大小来生成对应大小的LMDB数据 序列化操作执行完成后,会生成如下图所示的 lmdb 文件夹
3.修改执行训练脚本生成pt模型文件
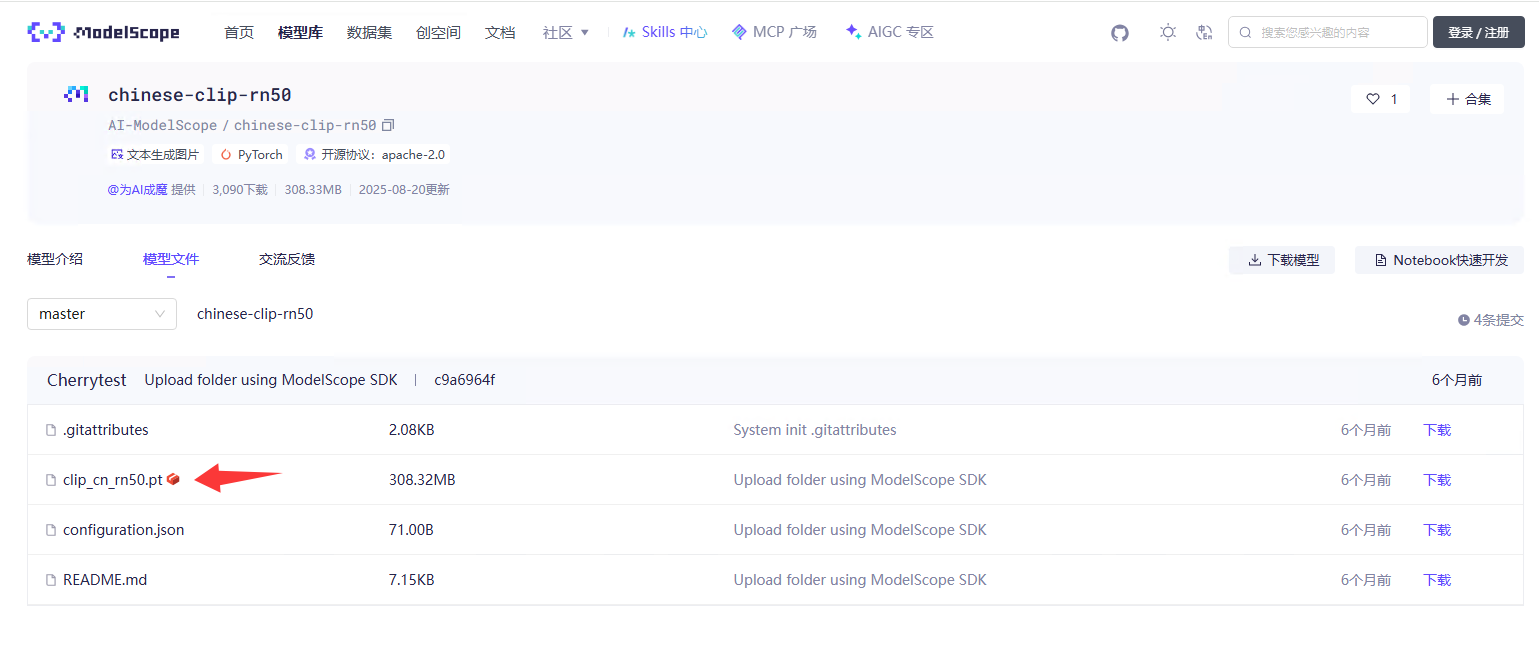
因为用的CN-CLIPRN50 骨架作为预训练模型,所以先下载该模型文件,然后移动到 KG_finetune/pretrained_weights 目录下。
下载链接:https://www.modelscope.cn/models/AI-ModelScope/chinese-clip-rn50/files
在 run_scripts 文件夹中 复制一个.sh脚本文件,重新命名为 tx_rs50_rbt-base.sh,内容如下
#!/usr/bin/env
# Guide:
# This script supports distributed training on multi-gpu workers (as well as single-worker training).
# Please set the options below according to the comments.
# For multi-gpu workers training, these options should be manually set for each worker.
# After setting the options, please run the script on each worker.
# Command: bash run_scripts/muge_finetune_vit-b-16_rbt-base.sh ${DATAPATH}
# Number of GPUs per GPU worker
GPUS_PER_NODE=1
# Number of GPU workers, for single-worker training, please set to 1
WORKER_CNT=1
# The ip address of the rank-0 worker, for single-worker training, please set to localhost
export MASTER_ADDR=localhost
# The port for communication
export MASTER_PORT=8514
# The rank of this worker, should be in {0, ..., WORKER_CNT-1}, for single-worker training, please set to 0
export RANK=0
export PYTHONPATH=${PYTHONPATH}:`pwd`/cn_clip/
# 在分布式环境下,这需要 WORLD_SIZE(总进程数)和 RANK(当前进程编号)等变量,单卡环境则设置固定即可
export LOCAL_RANK=0
export WORLD_SIZE=1
DATAPATH=${1}
# data options
train_data=${DATAPATH}/datasets/KG_GE/lmdb/train
val_data=${DATAPATH}/datasets/KG_GE/lmdb/valid # if val_data is not specified, the validation will be automatically disabled
# restore options
resume=${DATAPATH}/pretrained_weights/clip_cn_rn50.pt # or specify your customed ckpt path to resume
reset_data_offset="--reset-data-offset"
reset_optimizer="--reset-optimizer"
# reset_optimizer=""
# output options
output_base_dir=${DATAPATH}/experiments/
name=txmuge_rs50
save_step_frequency=999999 # disable it
save_epoch_frequency=20
log_interval=1
report_training_batch_acc="--report-training-batch-acc"
# report_training_batch_acc=""
# training hyper-params
context_length=52
warmup=100
batch_size=128
valid_batch_size=20
accum_freq=1
lr=5e-5
wd=0.001
max_epochs=150 # or you can alternatively specify --max-steps
valid_step_interval=20
valid_epoch_interval=1
vision_model=RN50
text_model=RBT3-chinese
use_augment="--use-augment"
# use_augment=""
#torchrun --nproc_per_node=${GPUS_PER_NODE} --nnodes=${WORKER_CNT} --node_rank=${RANK} \
# --master_addr=${MASTER_ADDR} --master_port=${MASTER_PORT} cn_clip/training/main.py \
# --train-data=${train_data} \
# --val-data=${val_data} \
# --resume=${resume} \
# ${reset_data_offset} \
# ${reset_optimizer} \
# --logs=${output_base_dir} \
# --name=${name} \
# --save-step-frequency=${save_step_frequency} \
# --save-epoch-frequency=${save_epoch_frequency} \
# --log-interval=${log_interval} \
# ${report_training_batch_acc} \
# --context-length=${context_length} \
# --warmup=${warmup} \
# --batch-size=${batch_size} \
# --valid-batch-size=${valid_batch_size} \
# --valid-step-interval=${valid_step_interval} \
# --valid-epoch-interval=${valid_epoch_interval} \
# --accum-freq=${accum_freq} \
# --lr=${lr} \
# --wd=${wd} \
# --max-epochs=${max_epochs} \
# --vision-model=${vision_model} \
# ${use_augment} \
# --text-model=${text_model}
python3 cn_clip/training/main.py \
--train-data=${train_data} \
--val-data=${val_data} \
--resume=${resume} \
${reset_data_offset} \
${reset_optimizer} \
--logs=${output_base_dir} \
--name=${name} \
--save-step-frequency=${save_step_frequency} \
--save-epoch-frequency=${save_epoch_frequency} \
--log-interval=${log_interval} \
${report_training_batch_acc} \
--context-length=${context_length} \
--warmup=${warmup} \
--batch-size=${batch_size} \
--valid-batch-size=${valid_batch_size} \
--valid-step-interval=${valid_step_interval} \
--valid-epoch-interval=${valid_epoch_interval} \
--accum-freq=${accum_freq} \
--lr=${lr} \
--wd=${wd} \
--max-epochs=${max_epochs} \
--vision-model=${vision_model} \
${use_augment} \
--text-model=${text_model} \
--num-workers=0 \
--valid-num-workers=0脚本执行命令如下
bash run_scripts/tx_rs50_rbt-base.sh KG_finetune
使用参考链接教程中的脚本遇到的问题:
问题1:首先对tx_rs50_rbt-base.sh脚本进行修改,最初执行使用 python3 -m torch.distributed.launch 但是我用的版本torch==2.10.0,所以执行代码修改为 torchrun 命令执行 但是使用 torchrun 命令执行脚本显示 error: ambiguous option: --logs=KG_finetune/experiments/ could match --logs-specs, --logs_specs 但是把--logs参数修改为--logs_specs参数之后,又出现 unrecognized arguments: --output-dir错误。。。 应该是Chinese-CLIP 的底层代码 cn_clip/training/main.py 在解析命令时,并没有定义 --output-dir 而是依然使用了 --logs, 这就形成了一个尴尬的局面:torchrun 觉得 --logs 不够明确(会警告甚至报错),而 main.py 又不认识 --output-dir。
问题1解决:依旧使用参数--logs,将python3 -m torch.distributed.launch 修改为 python3 cn_clip/training/main.py 即可正常运行
问题2: KeyError: 'LOCAL_RANK' 和 ValueError: environment variable WORLD_SIZE expected, but not set 错误 问题2解决: # 在分布式环境下,这需要 WORLD_SIZE(总进程数)和 RANK(当前进程编号)等变量,但是单卡环境则设置固定即可 export LOCAL_RANK=0 export WORLD_SIZE=1
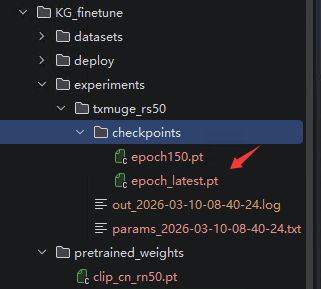
运行脚本开始训练模型完成之后出现的pt文件
4.将pt模型转换为onnx模型
在 run_scripts 目录下创建 conversion_onnx.sh 脚本,内容如下
#cd Chinese-CLIP/
export CUDA_VISIBLE_DEVICES=0
export PYTHONPATH=${PYTHONPATH}:`pwd`/cn_clip
# ${DATAPATH}的指定,请参考Readme"代码组织"部分创建好目录,尽量使用相对路径:https://github.com/OFA-Sys/Chinese-CLIP#代码组织
checkpoint_path=D:Chinese-CLIP/KG_finetune/experiments/txmuge_rs50/checkpoints/epoch_latest.pt # 指定要转换的ckpt完整路径
python cn_clip/deploy/pytorch_to_onnx.py \
--model-arch RN50 \
--pytorch-ckpt-path ${checkpoint_path} \
--save-onnx-path KG_finetune/deploy/ \
--download-root KG_finetune/pretrained_weights/ \
--convert-text \
--convert-vision运行命令: bash run_scripts/conversion_oonx.sh
转换onnx模型遇到的问题
问题1:cn_clip/clip/utils.py 代码55行中reponame, filename = _MODELS[modelname] 报错 KeyError: ('chinese-clip-rn50', 'clip_cn_rn50.pt')
解决办法:将cn_clip/clip/utils.py源码 reponame, filename = _MODELS[modelname] 修改为 reponame, filename = modelname
问题2:NotImplementedError: Please use from onnxconverter_common.float16 import convert_float_to_float16.
安装对应库 python3 -m pip install onnxconverter-common
修改pytorch_to_onnx.py文件中 12行导包代码
# from onnxmltools.utils import convert_float_to_float16 注释此导包,修改为下面导包
from onnxconverter_common.float16 import convert_float_to_float16
问题3: torch.onnx.errors.UnsupportedOperatorError: Exporting the operator 'aten::scaled_dot_product_attention' to ONNX opset version 13 is not supported. Support for this operator was added in version 14, try exporting with this version.
新版 PyTorch 底层为了极致加速,引入了一种叫 scaled_dot_product_attention 的高级算子,但是,Chinese-CLIP 官方的导出脚本里,默认使用的 ONNX "翻译字典" 版本太旧了(opset version 13 或者更低)
解决方法:修改pytorch_to_onnx.py文件中torch.onnx.export()函数中的参数 opset_version=14,如果没有这个参数就添加进去。
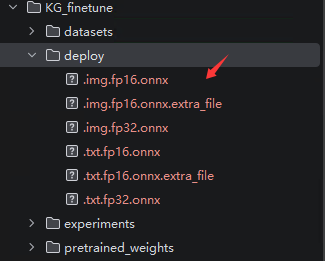
运行脚本后,生成的onnx模型在deploy文件夹中,如图所示,如果生产环境服务器只有 CPU 没有独立显卡,或者追求稳定性和兼容性,只用.img.fp32.onnx和.txt.fp32.onnx这两个文件就可以。
测试代码如下
import base64
import pathlib
import time
from io import BytesIO
from typing import List
import numpy as np
import onnxruntime
import requests
import torch
from PIL import Image, ImageDraw
from loguru import logger as log
import cn_clip.clip as clip
from cn_clip.clip.utils import _MODEL_INFO, image_transform
# ==========================================
# 1. 全局路径与环境配置
# ==========================================
# 获取当前脚本所在目录的绝对路径
DIR_PATH = pathlib.Path(__file__).parent.as_posix()
# ==========================================
# 2. 视觉模型 (Image Model) 初始化
# ==========================================
img_sess_options = onnxruntime.SessionOptions()
# 开启多线程优化,榨干 CPU 调度能力,保障数据喂给显卡的速度
img_sess_options.intra_op_num_threads = 8
img_sess_options.inter_op_num_threads = 4
# 加载处理图片的 FP32 格式 ONNX 骨干网络
img_onnx_model_path = f'{DIR_PATH}/cn_clip/model/tx666.img.fp32.onnx'
# 优先使用 CUDA (显卡) 进行加速,如果没有则自动退回 CPU
img_session = onnxruntime.InferenceSession(
img_onnx_model_path,
sess_options=img_sess_options,
providers=['CUDAExecutionProvider', 'CPUExecutionProvider']
)
# 加载官方的图片预处理函数(自动缩放、居中裁剪、标准化)
model_arch = "RN50"
preprocess = image_transform(_MODEL_INFO[model_arch]['input_resolution'])
# ==========================================
# 3. 文本模型 (Text Model) 初始化
# ==========================================
txt_sess_options = onnxruntime.SessionOptions()
txt_sess_options.intra_op_num_threads = 8
txt_sess_options.inter_op_num_threads = 4
# 加载处理文本的 FP32 格式 ONNX 骨干网络
txt_onnx_model_path = f'{DIR_PATH}/cn_clip/model/tx666.txt.fp32.onnx'
txt_session = onnxruntime.InferenceSession(
txt_onnx_model_path,
sess_options=txt_sess_options,
providers=['CUDAExecutionProvider', 'CPUExecutionProvider']
)
# ==========================================
# 4. 核心功能函数定义
# ==========================================
def convert_base64_to_image(base64_string: str) -> Image.Image:
"""将前端传来的 Base64 字符串解码并转换为 PIL 图像对象"""
decoded_data = base64.b64decode(base64_string)
return Image.open(BytesIO(decoded_data))
def crop_image_section(img: Image.Image, index: int) -> tuple:
"""
根据给定的索引 (0~5),从完整验证码图片中裁剪出对应的宫格小图。
返回:(裁剪后的 PIL 图像, 该图像在原图中的坐标框)
"""
# 预定义的六宫格坐标:(左, 上, 右, 下)
crop_positions = [
(0, 34, 220, 254), (226, 34, 446, 254), (452, 34, 672, 254),
(0, 260, 220, 480), (226, 260, 446, 480), (452, 260, 672, 480)
]
left, top, right, bottom = crop_positions[index]
return img.crop((left, top, right, bottom)), (left, top, right, bottom)
def draw_red_circle(image: Image.Image, box: tuple) -> None:
"""在指定的坐标框中心画一个红色的圆圈,用于可视化调试打点是否准确"""
draw = ImageDraw.Draw(image)
left, top, right, bottom = box
# 计算目标框的中心点坐标
center = (left + (right - left) // 2, top + (bottom - top) // 2)
radius = 60 # 圆圈的半径大小
# 画空心圆 (边界宽 4 像素)
draw.ellipse(
[center[0] - radius, center[1] - radius, center[0] + radius, center[1] + radius],
outline="red", width=4
)
def extract_text_features(text: str) -> np.ndarray:
"""
【性能优化核心 1】: 独立提取文本特征。
因为一次验证码请求中,目标文本(如"卡通的柠檬")是不变的。
我们将它单独提取,避免在 6 张小图的循环中重复计算,节省大量算力。
"""
# 使用“占位”词构成二分类对比,这是一种巧妙的 Zero-shot 技巧, 在这里相当于做判断题
text_tokens = clip.tokenize(["占位", text], context_length=52)
text_features = []
# 遍历这两个词,分别送入 ONNX 引擎提取特征
for one_text in text_tokens:
one_text = np.expand_dims(one_text, axis=0) # 增加 Batch 维度
text_feature = txt_session.run(["unnorm_text_features"], {"text": one_text})[0]
text_features.append(text_feature)
# 将两个特征垂直堆叠,形成形状为 (2, 1024) 的矩阵
text_features = np.vstack(text_features)
# 进行 L2 归一化,以便后续计算余弦相似度
text_features /= np.linalg.norm(text_features, axis=1, keepdims=True)
return text_features
def find_matching_indices(text: str, base64_string: str, img_show: bool = False) -> List[int]:
"""
主流程函数:接收目标文本和完整大图的 Base64,返回匹配成功的宫格序号列表。
【兼容修复版】:适配 ONNX 固定的 Batch Size = 1
"""
image = convert_base64_to_image(base64_string)
matching_indices = []
# 1. 提前算好文本特征 (全局仅算 1 次,极大地节约了算力!)
text_features = extract_text_features(text)
# 2. 循环处理 6 张小图 (每次 1 张送入 ONNX)
boxes = []
image_features_list = []
for index in range(6):
# 裁剪出小图和坐标
cropped_image, box = crop_image_section(image, index)
boxes.append(box)
# 预处理:返回 Tensor
img_tensor = preprocess(cropped_image)
# 增加 Batch 维度并转为 NumPy 数组,形状为 (1, 3, 224, 224) 满足 ONNX 的要求
img_array = img_tensor.float().unsqueeze(0).cpu().numpy()
# 单张图片送入推理,拿到形状为 (1, 1024) 的特征
single_img_feature = img_session.run(["unnorm_image_features"], {"image": img_array})[0]
image_features_list.append(single_img_feature)
# 将 6 次独立推理得到的特征垂直拼接成一个完整的矩阵,形状变为 (6, 1024)
image_features = np.vstack(image_features_list)
# 统一进行 L2 归一化
image_features /= np.linalg.norm(image_features, axis=-1, keepdims=True)
# 3. 矩阵点乘运算:一次性算出 6 张图对应 2 个文本的匹配得分
logits_per_image = 100 * np.dot(image_features, text_features.T)
# 4. 批量计算 Softmax 概率
exp_logits = np.exp(logits_per_image - np.max(logits_per_image, axis=-1, keepdims=True))
probabilities = exp_logits / np.sum(exp_logits, axis=-1, keepdims=True)
# 5. 解析结果并打点标记
for index in range(6):
# 提取当前图片对应目标文本的概率
prob = probabilities[index][1]
log.info(f"宫格序号: {index + 1}, 匹配概率: {prob:.4f}")
# 如果概率大于经验阈值 0.63,认为是正确目标
if prob >= 0.63:
matching_indices.append(index + 1)
# 画红圈
if img_show:
draw_red_circle(image, boxes[index])
# 展示画好圈的最终图片
if img_show:
image.show()
return matching_indices if matching_indices else [0]
if __name__ == "__main__":
# 模拟从本地读取一张测试图片
image_path = "卡通的柠檬-af42948325f94b3c98a6fd9609c0cded.png"
image = Image.open(image_path)
# 模拟前端传来的 Base64 编码过程
buffered = BytesIO()
image.save(buffered, format="PNG")
img_str = base64.b64encode(buffered.getvalue()).decode("utf-8")
# 记录起始时间,测试推理耗时
t1 = time.time()
# 执行核心识别流程
results = find_matching_indices('卡通的柠檬', img_str, img_show=False)
# 打印耗时和最终提取出的坐标序号
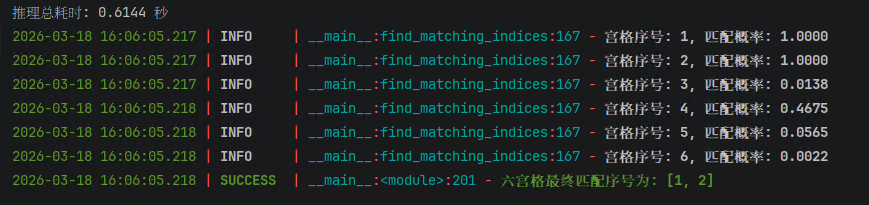
print(f"推理总耗时: {time.time() - t1:.4f} 秒")
log.success(f"六宫格最终匹配序号为: {results}")运行结果如图所示
5.Django5.2本地测试
安装环境
pip install onnxruntime pillow numpy
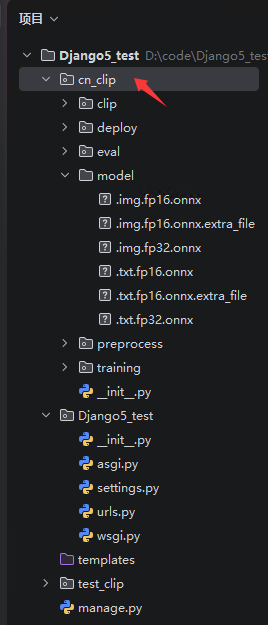
pip install torch结构目录如下图所示,将cn_clip文件夹复制到Django项目下。
view.py文件如下
import json
import base64
import numpy as np
import onnxruntime
import torch
from pathlib import Path
from PIL import Image
from io import BytesIO
from typing import Any
from django.http import JsonResponse
from django.views.decorators.csrf import csrf_exempt
# 引入 Django 异步转换神器,这是高并发的核心!
from asgiref.sync import sync_to_async
from loguru import logger as log
import cn_clip.clip as clip
from cn_clip.clip.utils import _MODEL_INFO, image_transform
# ==========================================
# 1. 全局模型加载 (只在 Django 启动时加载一次,常驻内存)
# ==========================================
BASE_DIR = Path(__file__).resolve().parent.parent
MODEL_DIR = BASE_DIR / 'cn_clip' / 'model'
img_sess_options = onnxruntime.SessionOptions()
img_sess_options.intra_op_num_threads = 8
img_sess_options.inter_op_num_threads = 4
img_session = onnxruntime.InferenceSession(
str(MODEL_DIR / '.img.fp32.onnx'),
sess_options=img_sess_options,
providers=['CUDAExecutionProvider', 'CPUExecutionProvider']
)
txt_sess_options = onnxruntime.SessionOptions()
txt_sess_options.intra_op_num_threads = 8
txt_sess_options.inter_op_num_threads = 4
txt_session = onnxruntime.InferenceSession(
str(MODEL_DIR / '.txt.fp32.onnx'),
sess_options=txt_sess_options,
providers=['CUDAExecutionProvider', 'CPUExecutionProvider']
)
preprocess = image_transform(_MODEL_INFO["RN50"]['input_resolution'])
# ==========================================
# 2. 核心运算函数 (同步 CPU/GPU 密集型任务)
# ==========================================
def extract_text_features(text: str) -> np.ndarray:
"""提取文本特征(使用更具排他性的负面词提升准确率)"""
text_tokens = clip.tokenize(["无关的背景图片", text], context_length=52)
text_features = []
for one_text in text_tokens:
one_text = np.expand_dims(one_text, axis=0)
text_feature = txt_session.run(["unnorm_text_features"], {"text": one_text})[0]
text_features.append(text_feature)
text_features = np.vstack(text_features)
text_features /= np.linalg.norm(text_features, axis=1, keepdims=True)
return text_features
def process_matching_logic(text: str, base64_string: str) -> list[int]:
"""具体的图像裁剪与矩阵点乘逻辑"""
decoded_data = base64.b64decode(base64_string)
image = Image.open(BytesIO(decoded_data))
matching_indices = []
text_features = extract_text_features(text)
crop_positions = [
(0, 34, 220, 254), (226, 34, 446, 254), (452, 34, 672, 254),
(0, 260, 220, 480), (226, 260, 446, 480), (452, 260, 672, 480)
]
image_features_list = []
for left, top, right, bottom in crop_positions:
cropped_image = image.crop((left, top, right, bottom))
img_tensor = preprocess(cropped_image)
img_array = img_tensor.float().unsqueeze(0).cpu().numpy()
single_img_feature = img_session.run(["unnorm_image_features"], {"image": img_array})[0]
image_features_list.append(single_img_feature)
image_features = np.vstack(image_features_list)
image_features /= np.linalg.norm(image_features, axis=-1, keepdims=True)
logits_per_image = 100 * np.dot(image_features, text_features.T)
exp_logits = np.exp(logits_per_image - np.max(logits_per_image, axis=-1, keepdims=True))
probabilities = exp_logits / np.sum(exp_logits, axis=-1, keepdims=True)
for index in range(6):
prob = probabilities[index][1]
if prob >= 0.63:
matching_indices.append(index + 1)
return matching_indices if matching_indices else [0]
# ==========================================
# 3. 暴露给网关的异步 API 接口 (Django 5.2 Async View)
# ==========================================
@csrf_exempt
async def match_captcha_api(request) -> JsonResponse:
"""
处理验证码识别的异步入口。
使用 async def 保证网络连接非阻塞,
使用 sync_to_async 将显卡运算卸载到后台线程池。
"""
if request.method != 'POST':
return JsonResponse({"code": 405, "msg": "Method Not Allowed", "data": []}, status=405)
try:
# Django 5.2 中可以使用原生 json 解析 body
body: dict[str, Any] = json.loads(request.body)
target_text: str = body.get('text', '')
img_base64: str = body.get('image_base64', '')
if not target_text or not img_base64:
return JsonResponse({"code": 400, "msg": "缺少关键参数 text 或 image_base64", "data": []}, status=400)
# 【性能核弹】:将耗时的推理任务扔进线程池,坚决不阻塞 ASGI 事件循环!
# thread_sensitive=False 允许利用多个后台线程并发处理多个识别请求
results = await sync_to_async(process_matching_logic, thread_sensitive=False)(target_text, img_base64)
return JsonResponse({
"code": 200,
"msg": "success",
"data": results
})
except Exception as e:
log.error(f"识别发生错误: {str(e)}")
return JsonResponse({"code": 500, "msg": f"Server Error: {str(e)}", "data": []}, status=500)
def index(request):
return JsonResponse({"code": 200, "msg": "success", "data": []}, status=200)urls.py文件
from django.urls import path
from .views import *
urlpatterns = [
path('', index, name="index"),
path('api/', match_captcha_api, name="api"),
]导包有 import cn_clip.clip as clip,只要把cn_clip这个文件夹复制过来就行,不需要去安装cn_clip。
如果要安装也可以,python3.12安装出现的问题如下
报错提醒:py-lmdb: Using bundled liblmdb with py-lmdb patches; override with LMDB_FORCE_SYSTEM=1 or LMDB_PURE=1. 解决方法: CMD设置 set LMDB_PURE=1 然后再执行 pip install cn_clip

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)