推荐系统学习笔记-02
原文链接:https://datawhalechina.github.io/fun-rec/chapter_5_gr_basic/2.gr_arch_base.html#id13
生成式推荐领域主要依赖两大类架构范式:Transformer和Diffusion模型 。在这部分介绍到两者的不同:
1) Transformer以自回归的方式逐token生成序列,这里更强调序列生成和前后依赖关系; 2) 而Diffusion模型的实现是以迭代去噪的方式从噪声中恢复数据。为了方便读者理解"迭代去噪"这一抽象概念,作者在后面举例,把现成的原石材料进行雕刻打磨,雕塑出一件艺术品,将这一过程称为反向去噪(Reverse Denosing Process)。评估这一过程是否成功的依据是与其逆向工程做对比,也就是前向扩散(Forward Diffusion Process),即,将成品逐渐侵蚀成一块模糊的石料。
另外,Transformer和Diffusion模型并不因为架构的不同而互相排斥,而是可以互相补充。
Transformer
Transformer在生成式推荐系统中的优势体现在3个方面:
1)Transformer中的自注意力机制天然的适合捕捉用户行为序列中的长的依赖关系。无论用户的历史交互有多长,模型都能够灵活地关注到任意时刻的行为信号;
2)另外,Transformer的并行化特性使其能够高效处理长序列。这对于需要建模用户完整行为历史的推荐场景至关重要;
3)最后,Transformer架构的统一性和可扩展性,使得我们可以通过简单地堆叠更多层、增加隐层维度来提升模型容量,这为推荐模型的规模化(Scaling)提供了坚实基础。
在这一篇文章中,着重介绍了Transformer架构的核心模块:(1)自注意力机制;(2)位置编码与序列建模;
自注意力机制
注意力机制的核心思想是:让模型自动地学习 “在预测下一个物品时,应该关注哪些历史行为”。不同于RNN那种固定的顺序处理方式,注意力机制允许模型动态地、选择性地聚焦于序列中的任意位置,根据当前的预测需求灵活分配注意力权重。
对自注意力机制公式的理解是:前面的softmax函数是一个求权重的过程,Q是查询,K是提供的信息、内容。是内积计算,计算“第i个Query与第j个Key的相似度”,值越大,相关性越大,越需要注意。
代表缩放因子,防止前面计算的内积值过大,使注意力分布更平滑。
softmax是归一化操作,将得到的相似度分数 转化为和为1的概率分布。
最后对Value进行加权求和。
一点理解
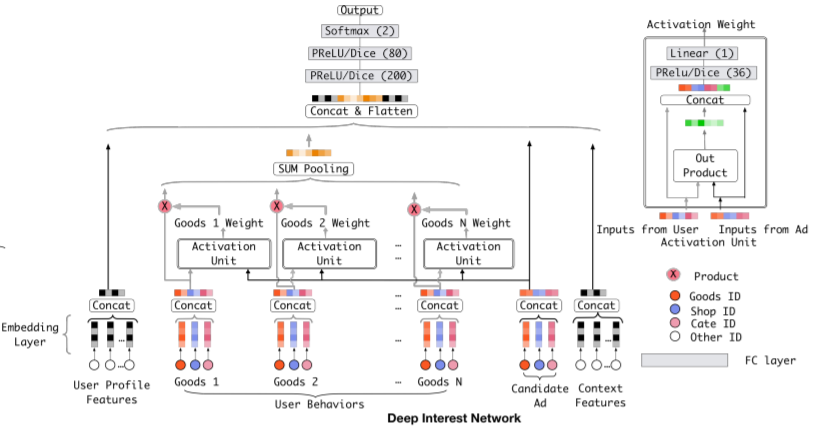
图1 DIN
结合DIN算法中对注意力机制的使用进行理解,Q是候选物品(Candidate Ad),先与用户历史行为序列(K)进行内积交互,从中寻找相关联的物品,越相关,值就越大,对应的权重也就越大。最后,用计算出的权重(Weight)从用户历史行为序列(V=K)中有侧重的挑选物品。
QKV的计算
通过三个不同的线性变换生成Query、Key、Value矩阵,这三个线性变换的作用是什么?
-
Query(Q):表示“当前位置想要查询什么信息”。在推荐场景中,它可以理解为“当前时刻的预测需求”。
-
Key(K):表示“序列中每个位置提供了什么信息”。它是用来与Query进行匹配的“索引”。
-
Value(V):表示“序列中每个位置实际包含的内容”。当确定了哪些位置重要之后,我们聚合的就是这些Value。
这是作者对Q、K、V的解释,这三句原话是理解注意力机制的精髓!
多头注意力的作用
对多头注意力(Multi-Head Attention)的理解可以是,多个关注不同方面的“专家”。在推荐系统中,用户的行为往往受到多种因素的影响——有时关注价格,有时关注品牌,有时关注功能。使用多个注意力头,就可以让模型能够同时学习多种不同的关注模式。
位置编码和序列建模
为了强调序列中的顺序要素的重要性,引入了位置编码(Positional Encoding)。为序列中的每个位置注入位置信息,使得模型能够感知元素的相对或绝对位置。
位置编码又考虑到时间信息。
两种结构范式
在此处,着重介绍了两种编码机制:Encoder-decoder (编码器-解码器)架构和 Decoder-Only(仅解码器)架构。
文中提到,在Encoder-Decode架构中Encoder部分使用到双向自注意力;Decoder部分使用到因果自注意力(Mask Self-Attention)和交叉注意力(Cross-Attention)。 Decoder-Only将输入和输出视为一个连续的序列,通过统一的因果自注意力机制进行处理。
(本人能力有限,此处内容请大家自行进行学习。)
Diffusion模型
此处作者提到 由于Transformer通过自回归的方式逐个生成token,局限性在于:生成速度受限于序列长度,难以并行化;对于某些任务,严格的顺序约束可能并非必需。所以引入了Diffusion模型。
Diffusion模型(扩散模型)提供了一种全新的生成范式。它不是通过逐步添加token来构建序列,而是从纯噪声开始,通过迭代去噪的过程逐步恢复出目标数据。
DIffusion模型的核心机制
Diffusion模型的核心思想可以概括为以下两个互逆的马尔可夫过程。
-
前向扩散过程:从真实数据出发,通过逐步添加高斯噪声,经过 步得到近似纯噪声的状态。
-
反向去噪过程:从随机噪声开始,通过学习到的去噪网络,逐步去除噪声,最终恢复出真实数据。
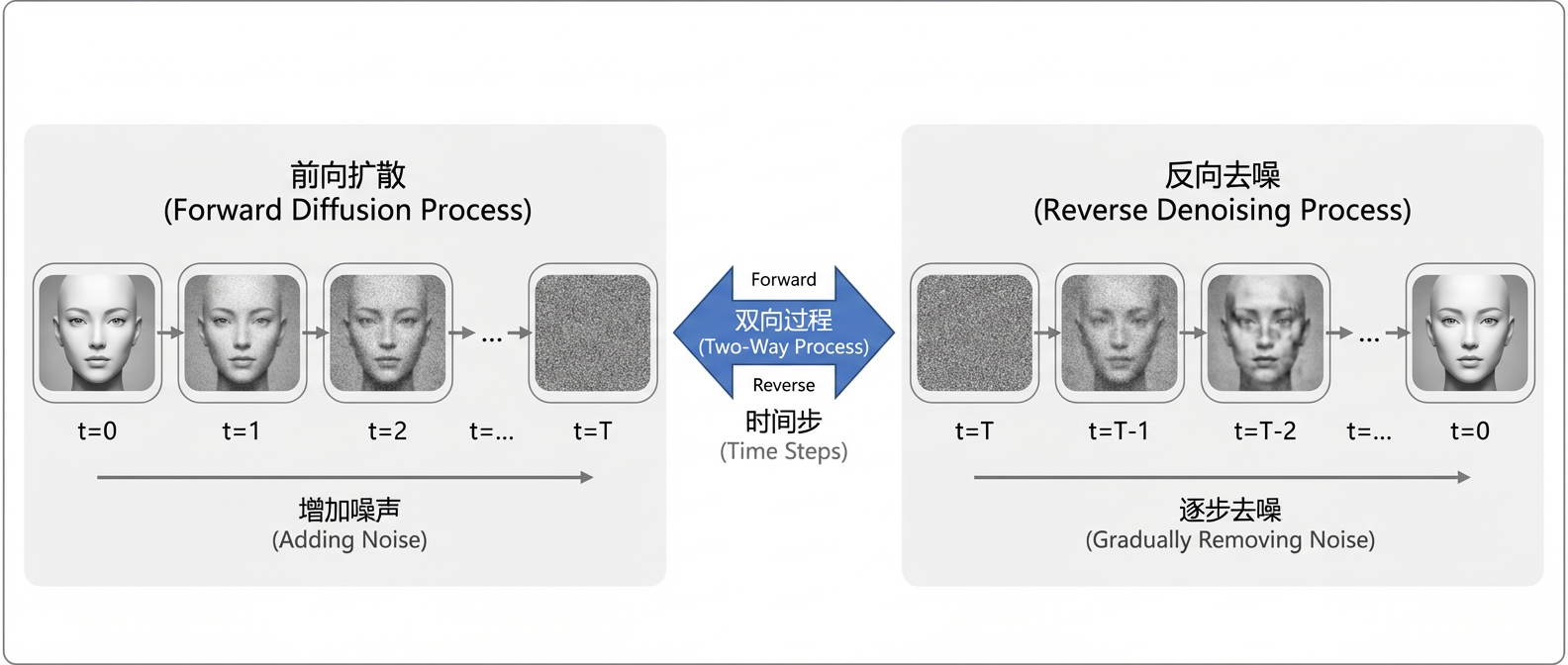
图2 前向扩散与反向去噪过程
写在最后
本篇文章有太多之前没有接触过的内容,对内容的掌握也不够透彻。有理解错误的地方希望大家批评与指正,希望感兴趣的伙伴自行查看原文进行学习。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)