自由学习记录(139)
hardware pipeline 的大阶段顺序不是 PSO 决定的,而是由 GPU graphics pipeline 类型本身决定的;PSO 决定的是这次 draw 在这条既定阶段链上,各阶段用什么程序、什么状态、哪些阶段启用。
也就是说,像:
IA -> VS -> HS/DS -> GS -> Raster -> PS -> OM
这条“骨架顺序”本身不是 PSO 发明出来的。
它是 graphics pipeline 的结构。
PSO 做的是给这条结构填具体配置。
例如:
-
VS 用哪个 shader bytecode
-
有没有 HS/DS
-
有没有 GS
-
Rasterizer state 是什么
-
DepthStencil state 是什么
-
Blend state 是什么
-
Primitive topology 类型是什么
-
Render target format / depth format 是什么
所以 PSO 更像:
对一次图元批处理的完整图形执行契约
更准确应该说:
PSO 包含 shader 编译产物,但 PSO 本身不是 HLSL 直接编译结果。
因为 HLSL 编译出来的首先是 shader bytecode / DXIL 之类的阶段程序。
而 PSO 是在 API 层把这些 shader bytecode 和固定功能状态一起封装成的对象。
拿 DX12 的语义说更清楚:
HLSL 编译产物通常是:
-
VS bytecode
-
PS bytecode
-
可能还有 HS/DS/GS/CS/MS/AS bytecode
然后创建 PSO 时,再把这些东西连同:
-
BlendState
-
RasterizerState
-
DepthStencilState
-
SampleMask
-
RTV/DSV formats
-
Primitive topology type
-
Root Signature
一起提交给驱动,形成ID3D12PipelineState。
所以关系更像是:
HLSL -> shader bytecode
然后shader bytecode + fixed-function states + layout contract -> PSO
不是:
HLSL -> PSO
这点很重要,因为它解释了为什么同一份 shader bytecode 可能对应多个 PSO。
例如同一个 VS/PS,如果你改:
-
blend state
-
depth state
-
render target format
-
rasterizer state
那通常就是不同 PSO 了,即使 shader 代码根本没变。
Epic 在把材质系统从“少数几个固定模式的经验型开关”,重构成“更接近真实光学行为、也更利于渲染路径优化的声明式系统”。UE 5.7 里,Substrate 已经是 production-ready,并且默认启用;官方明确把它描述为用更模块化、物理基础更强的框架,去替代过去那套固定 shading model / blend mode 组合。名字变长、变细,正说明设计目标已经从“给美术一个大概能用的几档选项”,转成“明确告诉渲染器:这个材质到底是在做覆盖、遮罩、加法、预乘合成,还是在做灰度透射、彩色透射”。UE 5.7 官方文档对 Blend Mode 的定义仍然是“当前材质如何和背景像素混合”,但 Substrate 文档同时强调它要表达更真实的 BSDF / 层叠 / 透射行为,而不是只靠过去那种粗粒度枚举。
底层架构的根本性变革
- 核心变化:对 GBuffer (几何缓冲区) 的完全重新配置。
- 传统延迟渲染:使用固定的 GBuffer 布局,每个通道(RT)存储特定的信息(如 BaseColor、Normal、Roughness 等)。
- Substrate 的方法:抛弃了固定布局,转而将材质属性打包存储在紧凑的 GPU 缓冲区 (Packed GPU Buffers) 中。这是一种更灵活、更具扩展性的数据结构,为复杂的材质分层提供了基础。
自适应 GBuffer (Adaptive GBuffer)
- 目标平台: 设计为 Shader Model 6 (SM6) 平台(如 PC SM6、PS5、Xbox Series)的新默认模式。
- 实现方式: 使用一组 位打包的 UAV (Bitpacked Unordered Access Views) 来逐像素编码 Substrate 数据。
- 功能:
- 解锁 Substrate 的所有高级功能,包括闭包混合 (closure blending) 和逐像素材质拓扑 (per-pixel material topology)。
- 提供了系统的全部灵活性和表现力。
- 注意事项:
- 由于数据是打包存储的,不支持硬件混合。
- 这一限制导致 DBuffer Decals 成为使用自适应 GBuffer 时唯一可用的贴花方法。
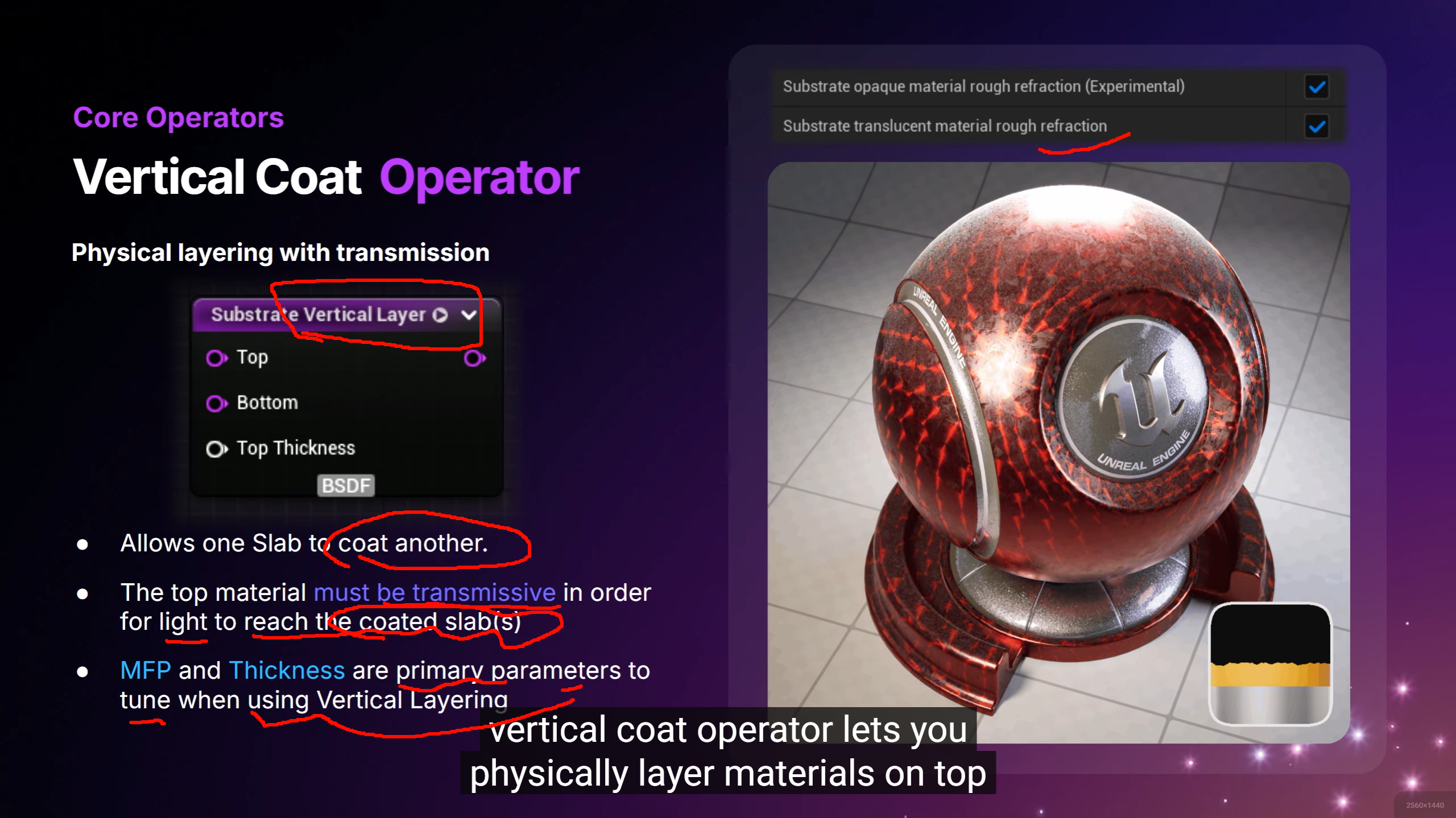
打破传统固定着色模型(Shading Models)的限制,实现更真实、更灵活、可分层的材质渲染 。模块化的方式组合不同的材质层(Slabs),不再局限于原有的“漫反射+高光+粗糙度”单层模式。
改变了材质的描述方式 ,从“硬编码的着色模型”转变为“基于Slab(薄片)的参数化堆叠系统” 。传统材质(Default Lit)是一个预定义的、单一的BRDF(双向反射分布函数)。而 Substrate 引入了 Slab(薄片) 的概念,材质不再是一个扁平的结构,而是像堆汉堡一样,允许将多个 Slab 节点组合、层叠(Layer)或混合(Mix)在一起。完美处理多层材质之间光的透射、吸收和散射。通过使用垂直堆叠(Vertical Layering),系统会自动计算第一层表面对第二层表面的遮挡和混合。这意味着可以轻松制作出珍珠、泡沫、清漆木材等具有复杂光线流转的材质。采用了“基于物理的组件化(Modular)策略” 。这让艺术家可以用更简单、更符合物理直觉的层级节点来描述极其复杂的真实材质,而不再被传统引擎的单个高光+漫反射模型所束缚 。传统材质系统区分不透明材质和透明材质(Translucent)。Substrate 将不透明和透明材质统一在同一个结构中,使得制作如“次表面散射的清漆金属”等跨模式材质成为可能。Substrate 允许用户通过节点图(Material Graph)将多个不同的材质描述按层堆叠。这与传统材质最大的不同在于,复杂材质不再是一个固定的着色模型 ,而是由多个基础层混合而成的复杂结构。节点式混合: 用户可以利用 Substrate Slab 节点和运算符节点(如 VerticalLayer 、HorizontalBlend )层层混合。例如,一个汽车漆材质可以是:一层透明清漆(Clear Coat) + 一层金属基底(Metal Base) + 一层汽车漆底色(Car Paint Base)。
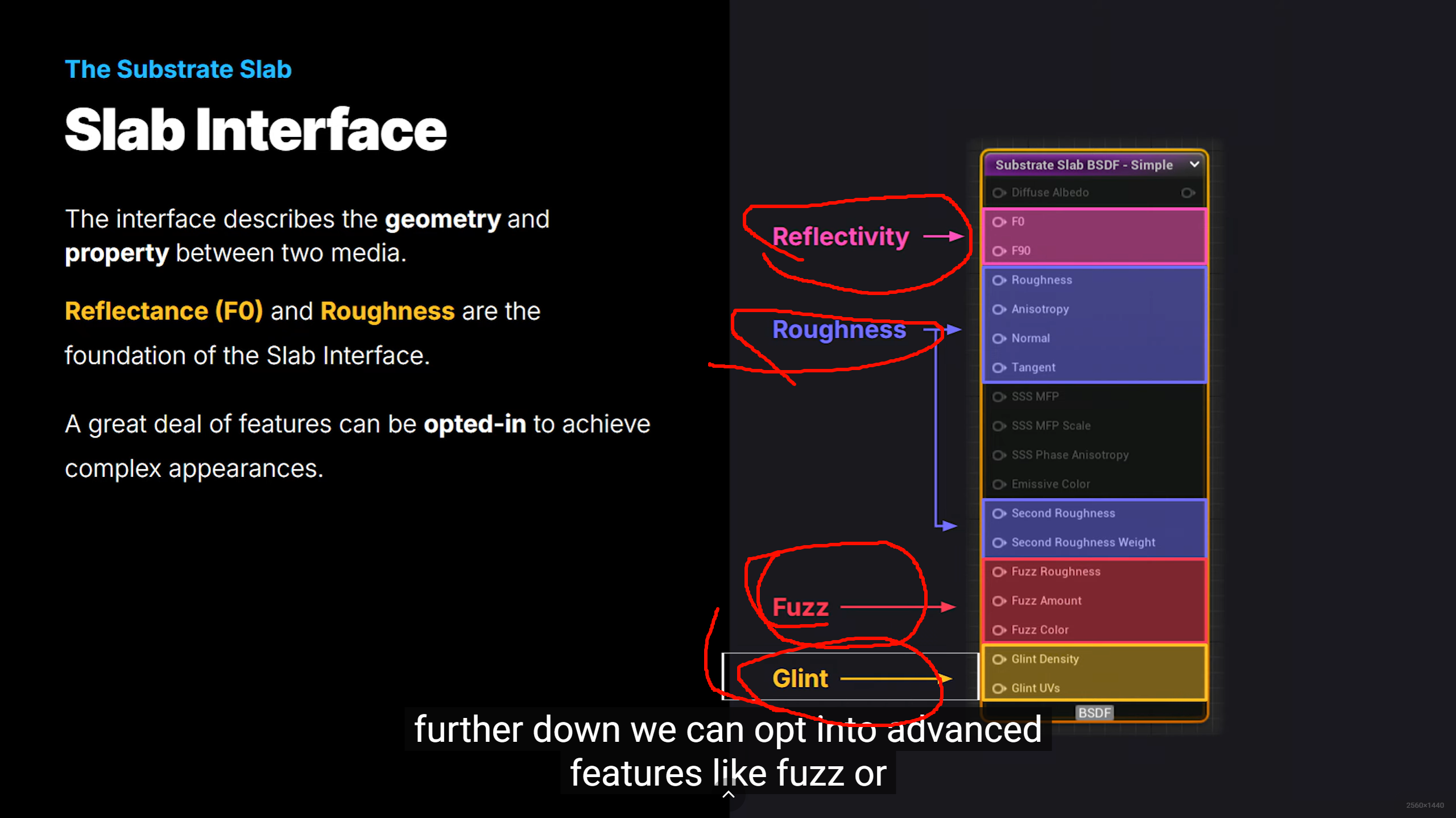
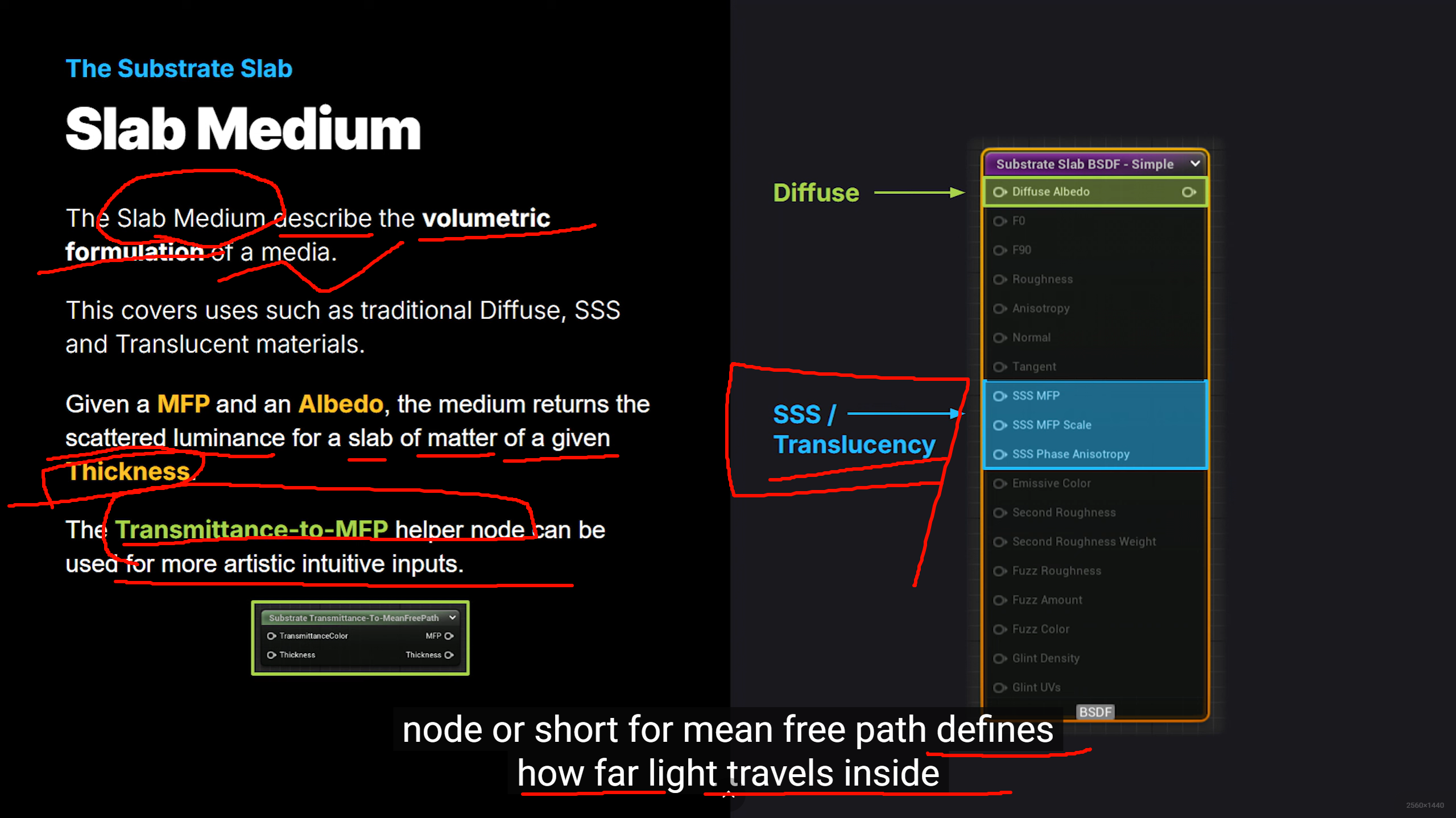

stained glass 需要的是“彩色透射”,不是简单 alpha 混合;而普通半透明 UI 更接近 compositing 语义。Colored Translucent Shadows / transmittance 相关文档,说明他们是在把“透过去的光是什么颜色、如何投影”单独建模。材质语义更稳定地映射到底层渲染路径。Blend mode 不是纯 UI 选项,它直接决定哪些 material input 生效、走哪些 pass、能否参与某些光照/阴影路径。AlphaComposite、AlphaHoldout、不同 transmittance 形式拆开,本质是在减少歧义,让引擎知道你究竟要哪种数学混合和哪种光学行为。兼容历史,同时逐步迁移。你搜到的 API 页面里其实还能看到一些隐藏别名,例如 BLEND_TranslucentGreyTransmittance = BLEND_Translucent、BLEND_ColoredTransmittanceOnly = BLEND_Modulate 这样的映射痕迹。这说明 Epic 没有完全推翻旧 enum,而是在保留底层兼容的同时,把编辑器和 Substrate 语义往新模型上迁移。所以你会感觉“菜单长得不一样、术语也更学术”,但底层有一部分仍是对旧模式的语义重包装。
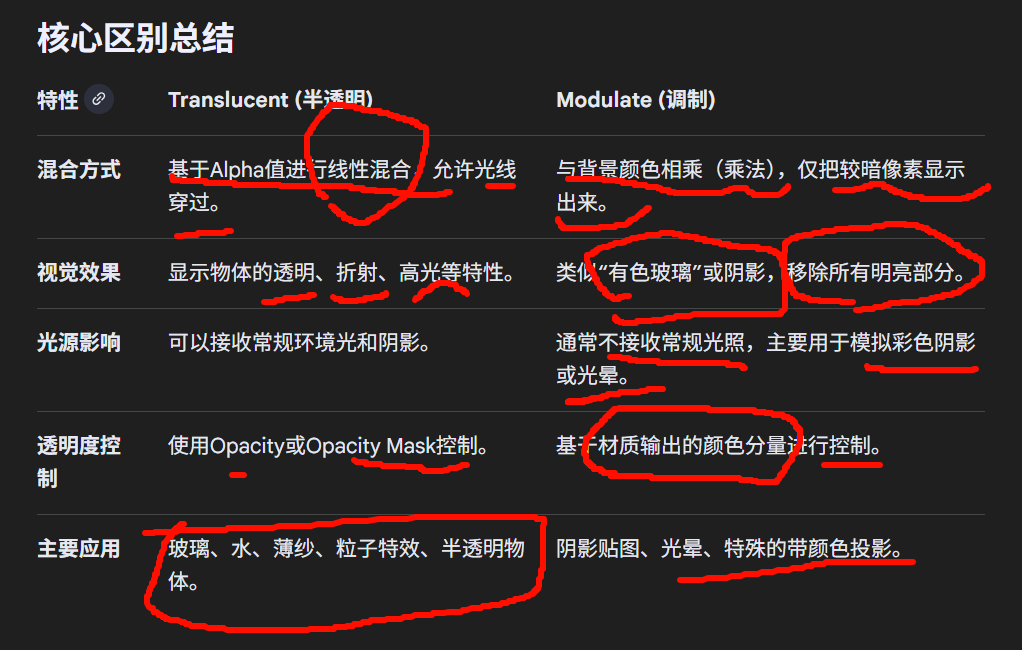
旧方案的问题是:
一个选项名字短,但语义过载;
美术靠经验试错,不知道自己选的是“混合方式”还是“透光模型”;
渲染后端很难根据一个含糊的 Translucent 推断最优路径。新方案的问题则相反:学习成本更高,但语义清楚,长期更适合 Substrate 这种 BSDF/层系统。UE 不再把材质面板当“效果快捷菜单”,而是当“渲染意图声明接口”。这很像从老式 fixed-function 风格 UI,转向更接近 render graph / explicit pipeline state 的思想。
Blend Mode 不只是“怎么混颜色”,而是一个高层语义标签,同时在声明三件事:
-
像素级混合算子(compositing operator)
-
光是否穿透(transmittance vs coverage)
-
是否参与光照/阴影/能量守恒路径
也就是说,它已经从“屏幕空间混合公式选择器”,变成“光学+管线行为的联合描述”。
-
Coverage(覆盖)
→ 物体要么挡住光,要么不挡(binary or masked)
→ 典型:Opaque / Masked
→ 对应 几何可见性(visibility)问题 -
Transmittance(透射)
→ 光穿过物体,被吸收/染色
→ 典型:TranslucentGrey / ColoredTransmittance
→ 对应 参与介质(participating media)问题
混合公式背后的物理含义:
-
Additive
→ 能量只增加(emissive-like)
→ 不守恒(典型 VFX) -
AlphaComposite(Premultiplied)
→ 标准 Porter-Duff compositing
→ 假设 alpha = coverage -
Transmittance
→ Beer–Lambert 类模型(近似)
→ alpha ≈ 吸收系数
这一步的本质是:
从“图像合成公式” → “光能如何流动”
不同模式会决定:
-
是否写 GBuffer
-
是否参与 deferred lighting
-
是否有 shadow / GI / reflection
例如:
-
Opaque → 完整参与
-
Translucent → 单独 forward path / lighting approximation
-
Transmittance → 可能影响 shadow color(colored shadow)
Substrate 的目标是:
BSDF + layer + transmission 的组合系统
如果 blend mode 语义不清:
-
无法正确组合 BSDF
-
无法优化 shader permutation
-
无法做 render graph 级别裁剪
blend mode ue5.7这套分类其实对应三个经典理论来源:
1. 渲染方程拆解(Kajiya)
把表面行为拆成:
-
反射(BRDF)
-
透射(BTDF)
-
吸收(extinction)
现在 UE 的做法是:
Blend Mode 负责告诉你:有没有 BTDF / extinction
2. Beer–Lambert Law(透射)
Transmittance 类模式,本质在表达:
T=e−σdT = e^{-\sigma d}T=e−σd
UE 没完全物理,但语义已经对齐:
-
GreyTransmittance → scalar absorption
-
ColoredTransmittance → wavelength dependent
3. Porter–Duff Compositing
AlphaComposite / Holdout 属于:
-
图像合成规则(coverage domain)
-
与物理光传输无关
UE 现在是明确区分:
“这是 compositing 语义,不是光学语义”
现在的 Blend Mode 可以这样理解:
它定义的是:这个材质在 可见性(coverage) / 光传输(transmittance) / 合成规则(compositing) / 光照参与方式 四个维度上的组合状态。
UE 的视口默认渲染路径对材质做了多层光照/后处理叠加。你只贴了 BaseColor,但 viewport 里走的是完整 shading pipeline。
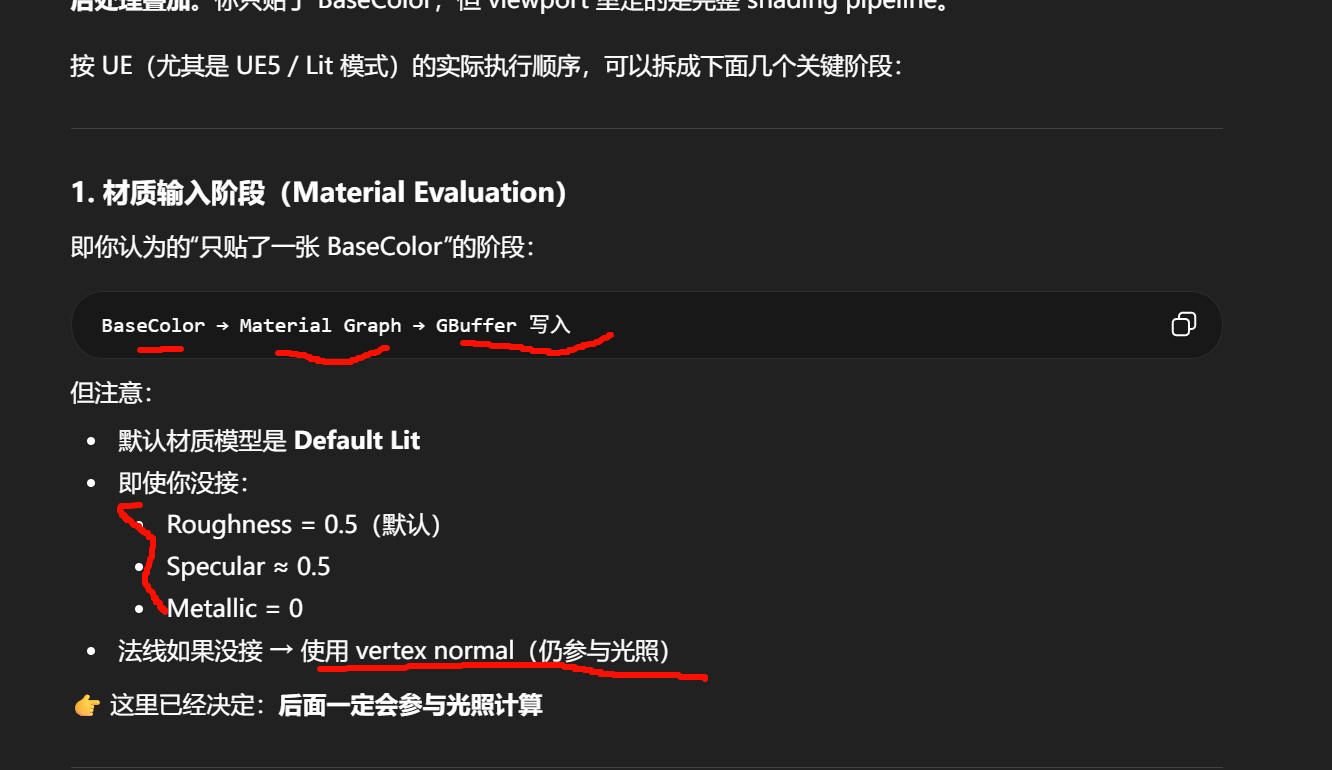
GBuffer(BaseColor, Normal, Roughness, etc.)
↓
Light Accumulation(方向光 / 环境光 / Skylight / IBL)
↓
Shading = Diffuse + Specular
即:
FinalColor ≠ BaseColor
FinalColor = BaseColor * Lighting + Specular + Indirect
你现在看到“灰掉”的原因主要是:
-
Skylight / HDRI 参与了 diffuse
-
默认 tone 偏低(ACES)
-
没有 unlit → 被物理光照压暗
不知道该效果属于哪个成本域。
你至少得知道它主要吃的是:
-
CPU 提交
-
GPU ALU
-
GPU 带宽
-
显存
-
overdraw
-
阴影缓存
-
屏幕分辨率
-
几何复杂度
-
动态物体数量
不知道它的放大因子。
也就是它随什么增长:
-
分辨率增长
-
灯数量增长
-
屏幕覆盖率增长
-
三角形/cluster 增长
-
透明层数增长
-
骨骼数量增长
-
视距增长
-
哪个阶段执行?
是 BasePass、ShadowPass、Lighting、PostProcess、Translucency,还是独立 compute? -
它主要吃什么?
ALU、纹理采样、带宽、RT 读写、深度复杂度、CPU draw/setup? -
随什么放大?
分辨率、灯数、屏幕覆盖、几何复杂度、材质指令数、骨骼数? -
不开它,有什么便宜替代?
烘焙、贴图假效果、局部体积、半分辨率、材质近似、风格化简化? - 个问题答不上来,就不该默认大范围上生产内容。
核心变化(本质)
从:
BaseColor → GBuffer → Lighting → Shadow → AO → ToneMapping → PostProcess变成:
Material(Emissive/BaseColor) → 直接输出 → ToneMapping → PostProcess关键点:
-
❌ 没有 GBuffer(不参与 deferred)
-
❌ 没有任何光照(无 direct / indirect)
-
❌ 没有 shadow / AO / SSR / Lumen
-
✅ 仍然是 HDR → LDR 的显示链
左边(黑背景角色)
-
主关卡 viewport
-
你关掉了部分 PostProcessing(比如 EyeAdaptation)
👉 所以画面是:
-
没曝光
-
没 bloom / DOF
-
更接近“裸输出”
默认状态:引擎内置后处理即使你不添加任何组件,UE 也会应用一套 默认的后处理设置 。这些设置定义在引擎的配置文件中,包括基本的曝光控制、色调映射(Tonemapper)和运动模糊等。- 局限性 :这些默认值无法在编辑器窗口中直接调整,且往往不符合特定项目的美术风格。
- 特征 :如果不加组件,你可能会发现画面有自动曝光(眼睛适应感)或特定的饱和度,这是因为内置的默认配置正在生效。
核心组件:Post Process Volume(后处理体积)想要手动控制和定制后处理效果,最标准的方法是添加 Post Process Volume 资产。- 局部覆盖 :默认情况下,该组件仅影响相机进入其立方体范围内时的画面。
- 全局覆盖 :在组件的“细节”面板中搜索并勾选 Infinite Extent (Unbound) ,它就会覆盖整个关卡,无论相机在何处。
- 优先级 :你可以添加多个体积,通过调整 Priority (优先级)属性来控制不同区域的效果切换。
自动曝光 (Auto Exposure / Eye Adaptation)这是最明显的默认效果。当你从暗处看向亮处,或者场景光照剧烈变化时,画面会像人眼或摄像机一样自动调整亮度。- 现象: 关卡里明明没放 Post Process Volume,但画面总是忽亮忽暗。
- 原因: UE 默认开启了基于直方图的自动曝光。
色调映射 (Tone Mapper)UE 使用电影级的 ACES 标准 色调映射。- 现象: 即使是简单的纯色材质,在光照下也会呈现出非常柔和、写实的色彩过渡,而不是生硬的色块。
- 作用: 确保高光部分(如太阳)不会直接变成一片纯白死区,而是有层次地向白色过渡。
颜色校正 (Color Correction)默认会有微弱的对比度和饱和度调整,以确保渲染出的线性空间颜色(Linear Color)在你的显示器上看起来是“正常”的。如何“关掉”或修改这些默认行为?如果你觉得这些默认效果干扰了你的设计(比如你想要一个纯二维的不带光影变化的画面),你需要:- 在场景中放入一个 Post Process Volume 。
- 勾选 Infinite Extent (Unbound) 使其全局生效。
- 覆盖默认值:
- 关掉自动曝光: 找到
Lens->Exposure->Metering Mode改为Manual(手动),或者将Min Brightness和Max Brightness设为相同的值(如 1.0)。 - 调整饱和度: 找到
Color Grading->Global->Saturation进行覆盖。
- 关掉自动曝光: 找到
简单来说: 引擎自带的默认值是为了保证“下限”,让你随手拉个模型进去看起来都不至于太糟糕;而添加 Post Process Volume 是为了提高“上限”,实现你真正想要的美术风格。 -
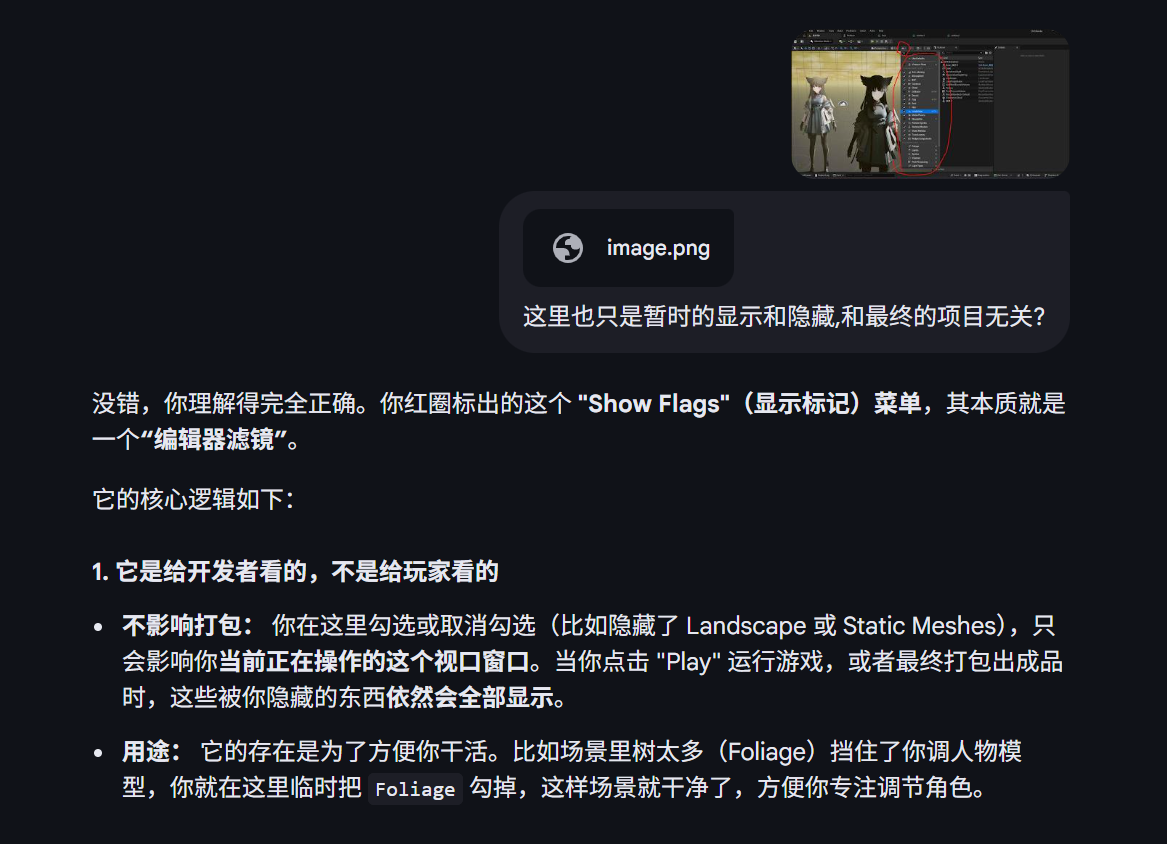
- Preview Material :只实时刷新最终的材质预览球。
- Realtime Nodes :实时刷新受时间影响的节点(如 Panner 这种会动的节点)。
- All Node Previews(最广) :只要你改动任何参数或连线,所有节点的预览小图都会立即重新计算并显示结果。
- 缺点 :如果材质极其复杂,开启这个会非常吃显卡性能,导致连线时卡顿。
如果你想改完立刻看到效果(不卡顿):
建议使用 Material Instance(材质实例) 。在实例里拖动数值或切换贴图,场景是完全实时 变化的,不需要点 Apply,也不需要等编译。
- 发现 Scatter(散射) 、Backlit(背光) 等特有插槽被激活(变亮)了。
- 置灰不可用 :如果你切换回默认的 Default Lit ,这些 Hair 特有的插槽就会变灰,无法连接。反之,Hair 模式下某些原本可用的插槽(如 Metallic)在某些特定模型下也会失效或改变含义。
- 特定属性出现 :例如,只有在 Shading Model 设置为 Thin Translucent 时,才会出现“Transmission”(透射)相关的设置。
- 底层算法切换 :不同的模型会开启或关闭底下的 Usage(用法) 勾选项。比如有些模型会自动勾选“Used with Hair Strands”。
Shading Model = Hair,它会强制切换到一套专用的光照路径(Hair BSDF),这条路径和常规的 Translucency(半透明)是互斥的。
本质原因(渲染管线层面)
Hair Shading Model 走的是:
-
专用的 Hair Lighting Model(Marschner / Dual Scattering 近似)
-
Forward-like lighting(即使在 Deferred Renderer 中)
-
使用:
-
Tangent(发丝方向)
-
Scatter(透射近似)
-
Backlit
-
Anisotropy
-
而 Translucency 走的是:
-
Separate Translucency Pass / After DOF Pass
-
非物理的透射(基于 opacity + lighting mode)
👉 这两套路径在 UE 里是完全不同的 shader permutation
所以引擎直接做了限制:
Hair → 禁用 Translucency 面板
Dither (抖动/交错)是一种材质技术和渲染技巧,用于通过交错分布的不透明像素来模拟半透明效果 。它通常与时间性抗锯齿(Temporal Anti-Aliasing, TAA 或 TSR)结合使用,通过这种方式,原本不透明的物体可以表现出类似透明的视觉效果,且性能消耗较低 。
- 模拟半透明 :传统的透明材质(Translucent)非常消耗性能,尤其是在叠加层次很多时。Dither技术通过在材质的Masked(掩码)模式下,使用“抖动”模式,让像素点随机或按规律地出现和消失。
- 利用TAA抗锯齿 :UE的TAA技术会比较前后两帧的像素。当Dither产生的像素每帧都在变化时,TAA会将这些点“混合”起来,使人眼看起来该物体就是半透明的。
- 材质节点 :在UE材质编辑器中,最常用的节点是 DitherTemporalAA 。
- DitherTemporalAA :最常用的节点,通常连接到“遮罩裁剪值(Opacity Mask)”,用于实现柔和的裁剪效果。
Blue Noise(蓝噪声) :UE5 中更推崇的一种噪声类型,因为它比传统的白噪声分布更均匀,视觉上的噪点感更低。
https://www.ntiaudio.cn/客户支持/拓展/五彩斑斓的噪声/
噪声在我们的生活中随处可“见”,从物理角度上看,噪声是那些频率、强弱无规律变化,或者说杂乱无章的声音。而从心理学 上说,任何让人感觉烦躁的声音都可以归类为噪声。噪声”是英文 noise 的标准翻译,“噪音”为不规范用法,因为“声”是物理学 术语,指能够引起听觉的机械波 ,而“音”是人文领域的用法,指有规律的乐音,故不能将两者混淆。

Hair 使用:
-
多 lobes specular(R / TT / TRT)
-
内部散射(沿发丝方向)
Translucency 使用:
-
Volumetric / Surface Lighting(简化)
👉 无法共存同一 BRDF
无法共存同一 BRDFDither Temporal AA:软边
Hair 会触发:
然后:
-
禁用 Translucency permutations
-
强制走 Hair lighting pipeline
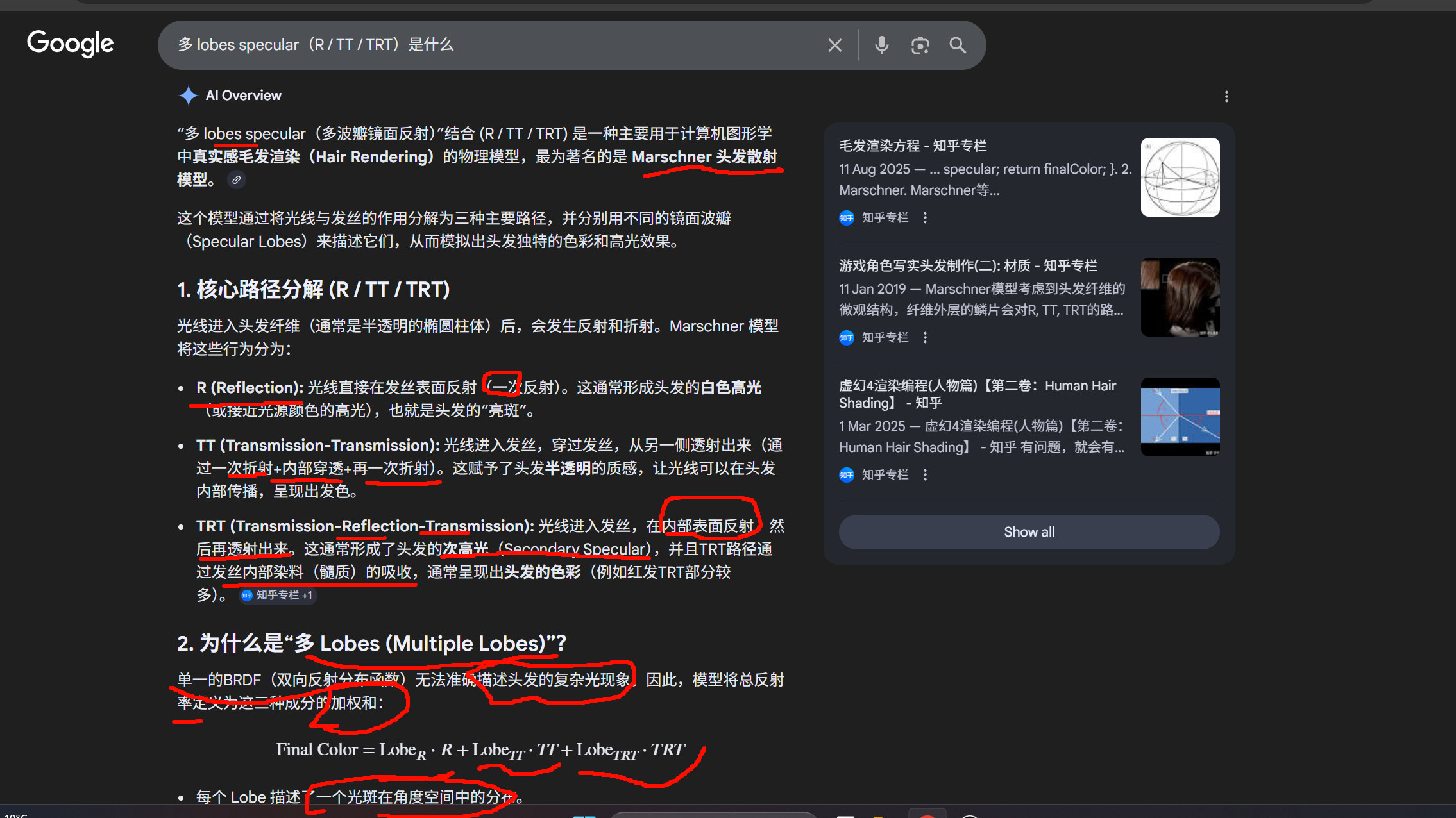
- 每个 Lobe 描述了一个光斑在角度空间中的分布。
- R 波瓣最尖锐(主高光)。
- TRT 波瓣较宽,通常在不同于主高光的方向。
- 这种“多波瓣”设计能够精准模拟真实世界中,一根发丝上呈现主次两个高光斑、且呈现透射光和染色光的效果。
- Marschner 模型: 由 Steve Marschner 等人提出,是现代毛发渲染的基石。
- 游戏渲染: 在《虚幻引擎》(Unreal Engine)中的 Human Hair Shading 模型中应用了类似的原理,通过多层Specular分量来描绘写实皮肤和头发。
- 真实感: 该模型考虑了鳞片引起的位移(R与TRT角分布的不同)和纤维内部的吸收,从而实现了高质量的写实角色制作。
- 实时渲染中的“每像素每帧采样数(spatial samples per frame)”,而不是最终收敛质量对应的总采样数。
单帧内的空间采样数(spatial samples)
比如:
-
TAA / Dither TAA / stochastic sampling
-
DOF / motion blur / shadow PCF / SSGI 等
这里的“8~15个采样”指的是:
一个像素在当前帧内做了多少次随机/抖动采样
而不是最终效果的“等效采样”。
实际依赖的是 时间累积(temporal accumulation)
TAA 类方法的本质是:
C f i n a l = ∑ t = 0 N w t ⋅ C t C_{final} = \sum_{t=0}^{N} w_t \cdot C_t Cfinal=t=0∑Nwt⋅Ct也就是说:
-
每帧只做很少的 sample(例如 1~8)
-
通过历史帧不断累积(几十甚至上百帧)
👉 等效结果:
-
单帧:8 samples
-
30帧累计:≈ 240 samples(但带有temporal correlation)
这就是为什么:
实时渲染里“单帧采样很少”,但最终看起来像高采样
为什么 PC 也只有 8~15?
这是纯粹的 带宽 + ALU + latency budget 限制
即便在高端 PC:
-
一个 full-screen pass:
-
4K 分辨率 ≈ 8.3M pixels
-
-
如果每像素 30 samples:
-
就是 2.5亿次采样(还不算 shading cost)
-
这会直接:
-
爆 L1/L2 cache
-
增加 texture fetch latency
-
拉高 register pressure(尤其在 wave64 / SIMT 下)
所以现实工程里:
-
SSR / SSGI:通常 1~8 samples
-
PCF shadow:4~16 taps(已经算重)
-
DOF stochastic:4~8
移动端为什么 <6
移动 GPU(tile-based + bandwidth constrained):
-
texture fetch 成本更高(尤其是 external memory)
-
ALU 也更紧(尤其是中低端 Mali / Adreno)
所以:
-
常见是 1~4 samples
-
甚至完全依赖 temporal + reprojection
-
-
Lumen GI:
-
单帧 trace 数非常少(甚至 1~2)
-
靠 temporal + screen space reuse
-
-
TSR / DLSS:
-
本质也是 temporal accumulation + reconstruction
-
“8~15采样”不是最终质量采样数,而是:
实时渲染中单帧可承受的空间采样预算,上限由带宽/延迟决定,最终质量依赖 temporal accumulation。
wave/warp 切换去隐藏部分 latency
每多一个 sample,就多一串读请求。GPU 虽然能靠 wave/warp 切换去隐藏部分 latency,但隐藏能力不是无限的。只要:
-
访存太散
-
cache hit 低
-
register pressure 高导致 occupancy 降低
那 latency 就开始暴露成真实耗时。
cache miss 带来的层级存储访问延迟。
采样不是只有“次数”问题,还有 空间局部性 问题。
比如径向模糊:
-
采样点沿半径发散
-
很容易跨 cache line
-
命中 L1/L2 的概率下降
于是会发生:
-
近邻 sample 还好
-
半径一大,很多 sample 直接掉到更低层 cache,甚至外存
这时单次 sample 成本就明显上升。
所以“30+ 采样才够好”在算法上可能成立,但在硬件上会被 cache behavior 打爆。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)