第一章 一生万物 — RADOS导论
文章目录
一、RADOS概述
1. Ceph简介
创始人:Sage Weil(美国人)
发表时间:2006 年
名字由来:Cephalopod 海洋软体类动物家族
吉祥物:Ceph以章鱼作为自己的吉祥物,表达了Ceph跟章鱼一样的并行行为
Ceph起源:由 Sage Weil 在加州大学圣克鲁兹分校(UCSC)攻读博士期间作为博士论文项目启动
Ceph是软件定义存储。可以运行在几乎所有主流的Linux发行版
Ceph是分布式存储。分布式基因使其可以轻易管理成百上千个节点,PB级及以上存储容量的大规模集群
Ceph是统一存储。Ceph即支持传统的块、文件存储协议,例如SAN和NAS,也支持新兴的对象存储协议,例如S3和Swift
Ceph在架构上采用存储应用与存储服务完全分离的模式(即Client/Server模式)。并基于RADOS(Reliable Autonomic Distributed Object)—— 一种可靠的、高度自治的分布式存储系统。


2. Ceph的三大核心应用
RADOS(Reliable Autonomic Distributed Object Store) 可靠的、自动化分布式存储系统
LIBRADOS(Library for RADOS)所有协议(RADOSGW、RBD、CEPHFS)的统一访问入口,高层协议依赖LIBRADOS,同时LIBRADOS提供一组API,允许应用程序直接访问Ceph的分布式存储集群(支持多种编程语言,如C、Java、Python等)可通过API接口直接调用LIBRADOS,但相对麻烦需要写代码,所以Ceph提供了三种原生存储接口,可直接调用:
RADOSGW(RADOS Gateway)它提供了一个与Amazon S3和OpenStack Swift兼容的RESTful网关,允许用户通过标准的HTTP协议访问 RADOS
RBD(RADOS Block Device)它提供了librbd接口,通过librbd调用LIBRADOS将数据写入RADOS集群,将RADOS中的对象抽象为可挂载的虚拟块设备
CEPHFS(Ceph File System)它提供了与POSIX兼容的分布式文件系统,允许用户以传统文件系统的方式(如目录、文件、权限)访问 Ceph 的分布式存储资源,CephFS 守护进程(mds daemon)内部静态链接了 librados,但实际也是需要通过 librados访问RADOS集群。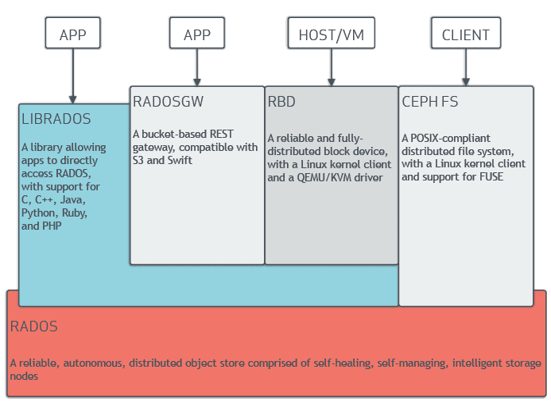
3. 块存储介绍
磁盘的最小读写单位为扇区,1个或多个连续的扇区组成一个block块,也称之为物理块,是操作系统的读写单位,块存储则是将存储集群中的空间划分为固定大小的块,以精简/厚置备的方式,为客户端提供块级的裸设备读写访问服务。
存储设备共享给客户端的是一块裸盘(不含文件系统),那么该存储设备提供的就是块存储,读写数据时直接读取数据块,IO路径短。通常一个块设备只给一个客户端使用,块存储不适用做数据共享,文件的检索过程是在本地完成的,标准协议有iSCSI、RBD等。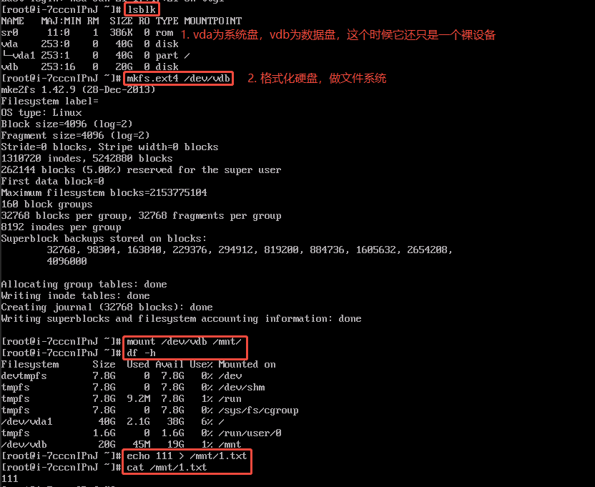
块存储协议原理(RBD)
在采用 iSCSI 协议提供块存储服务时,通常会在存储侧部署 3 至 5 台块存储网关,作为客户端的访问入口。这些网关节点之前可以由 Nginx 等负载均衡器统一分发客户端请求,以实现高可用和流量调度。由于块存储网关本身属于存储集群的一部分,因此其上必然部署了 Ceph 相关组件,并支持 RBD 协议——确切地说,是通过 librbd 库与 Ceph 交互。当 iSCSI 网关接收到来自客户端的 I/O 请求后,会调用 librbd 接口将数据切分成 RADOS 集群可识别的对象(默认对象大小为 4 MiB),随后借助 librados 库调用 CRUSH 算法,将这些对象最终分布写入到 RADOS 存储集群中。
iSCSI协议相关技术可以参考这篇博客 https://blog.csdn.net/lss0516/article/details/155066977?sharetype=blogdetail&sharerId=155066977&sharerefer=PC&sharesource=lss0516&spm=1011.2480.3001.8118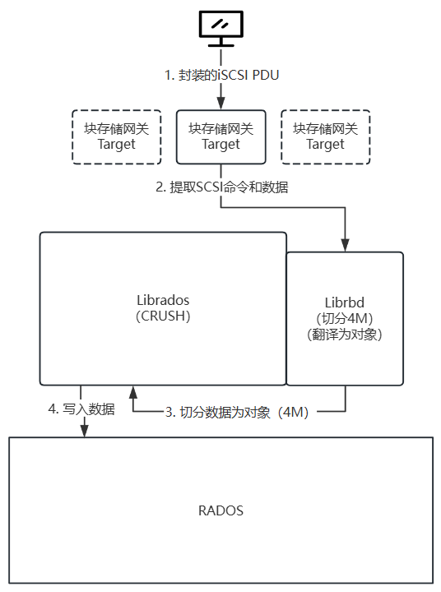
4. 文件存储介绍
一般存储设备共享给客户端的是文件夹,那么该存储设备提供的就是文件存储(可以理解成做了文件系统的块存储)。文件系统适用于数据共享,文件的检索过程是在存储设备里面完成的。文件存储是目录树结构,读写数据前需要先查一遍元数据,如果文件数量过多,元数据查询会成功瓶颈,标准协议有NFS、SMB/CIFS等。
1)客户端写数据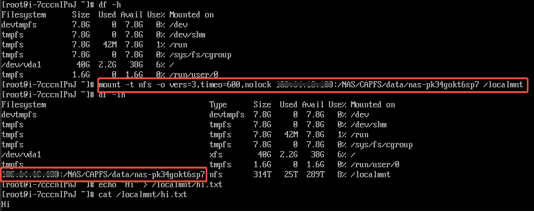
2)服务端能看到文件内容,说明文件存储的文件系统是在存储层做的,并不是在客户端的操作系统内做的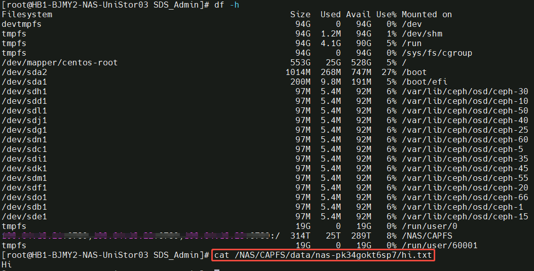
文件存储读文件遍历过程
cat /NAS/CAPFS/data/nas-kpozzjkknctc/your_data.file
- 解析路径,定位目标文件 your_data.file 所在的直接父目录 /NAS/CAPFS/data/nas-kpozzjkknctc
- 若MDS缓存未命中,从RADOS元数据池读取该目录的目录项对象,加载到MDS内存
- 在目录的有序目录项表中使用二分查找,通过文件名 your_data.file 定位对应inode号
- 根据文件inode号,加载该文件完整元数据(大小、数据布局、权限等)
- MDS将文件元数据与访问授权返回给ceph.ko(CephFS内核客户端)
- ceph.ko依据元数据计算数据对象OID,通过CRUSH算法定位对应OSD,调用内核版librados读取文件数据
文件存储协议原理(CephFS)
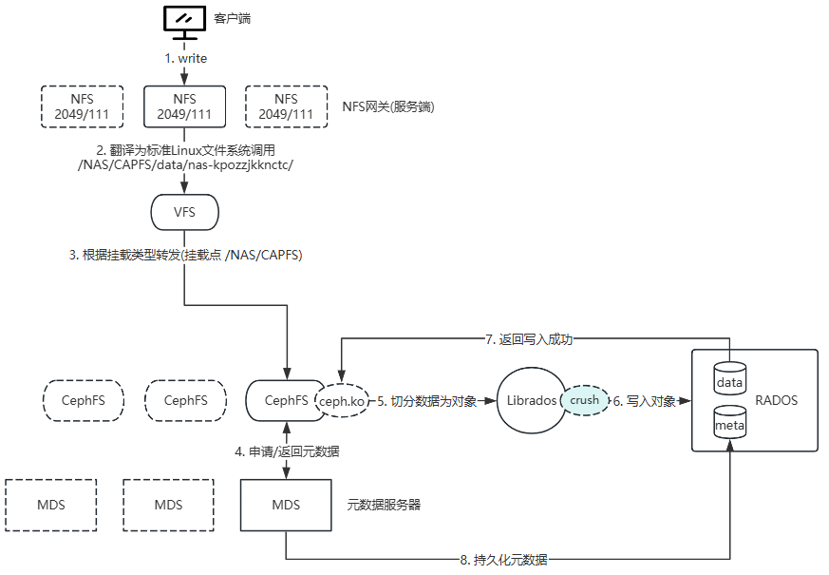
- 客户端通过 NFS 协议发起写入请求,服务端的 NFS 网关(如内核 NFS 服务)接收请求,将其转换为标准的 Linux 文件系统调用,并指向路径 /NAS/CAPFS/data/nas-kpozzjkknctc。
- VFS 根据挂载类型将调用转发至挂载点 /NAS/CAPFS,该挂载点的下层文件系统为 CephFS(通过内核模块 ceph.ko 挂载)。
- CephFS 客户端首先向 MDS 申请该文件的元数据(如 inode、布局信息),MDS 返回后,客户端获得文件的数据布局。
随后,ceph.ko 将待写入的数据按文件布局切分为多个对象(默认 4 MiB),并通过 librados CRUSH 映射,直接将对象写入数据池(data pool)中对应的 OSD。每个对象的写入遵循 Ceph 的副本或 EC 策略。 - 数据全部写入成功后,主 OSD 向 ceph.ko 返回写入成功确认。
- 接着,ceph.ko 通知 MDS 数据已写入完成,MDS 将更新后的元数据(如文件大小、时间戳)持久化到元数据池(meta pool)。
- 元数据写入成功后,MDS 向 ceph.ko 返回确认,ceph.ko 再通过 VFS 层层向上反馈,最终由 NFS 网关向客户端返回写入成功。
5. 对象存储介绍
对象存储是一种以「对象」为核心单位的海量非结构化数据存储架构,区别于块存储(按扇区 / 块读写)、文件存储(按目录 - 文件树读写),它将数据、元数据、唯一标识封装为独立「对象」,通过标准化的 RESTful API(如 S3/Swift)提供读写访问,专为PB/EB 级非结构化数据(图片、视频、日志、备份文件等)设计,全程基于 HTTP/HTTPS支持GET、POST、PUT、DELETE等,不支持在线修改文件内容。
举个例子
(1)数据:这里没有显示,但可以通过元数据定位到数据存储在了tiger池中
(2)元数据:从Key:test1116\storcli开始的所有内容都是元数据
(3)唯一标识:Key:test1116\storcli,通过唯一标识找到这个文件的元数据
(4)对象:图片上的所有内容都是对象
对象存储的 “文件夹” 只是UI 上的模拟,底层并没有真正的目录节点、没有 dentry、没有父 inode。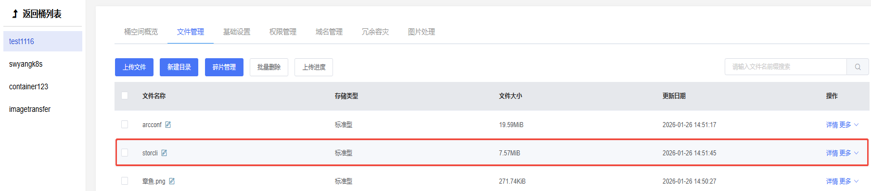
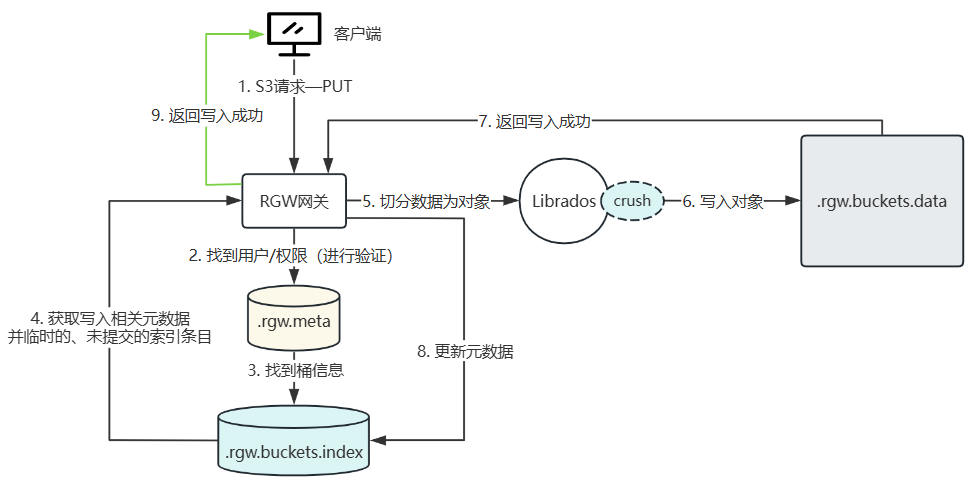
对象存储协议原理 (RGW)
客户端通过 HTTP/HTTPS 协议调用 S3 接口访问 RGW 网关,执行 PUT 写操作。请求头中携带访问密钥(AccessKey)、桶名、对象名等信息。RGW 网关的处理流程如下:
- 认证与鉴权:RGW 从请求中提取用户凭证,在 .rgw.meta 池中查找对应的用户信息,验证签名和权限。若验证失败,直接返回错误。
- 定位桶与获取配置:验证通过后,RGW 根据桶名在 .rgw.meta 池中读取桶的元数据(如桶的所有者、存储位置策略等),进而确定该桶使用的索引池(通常为 .rgw.buckets.index)和数据池(通常为 .rgw.buckets.data)。
- 数据切分与写入:RGW 将请求体中的数据按 RBD 对象大小(默认 4 MiB)切分为多个 RADOS 对象,通过 librados 库调用 CRUSH 算法,直接将对象写入数据池(.rgw.buckets.data)中对应的 OSD。每个对象的写入遵循 Ceph 的副本或 EC 策略。
- 更新桶索引(元数据持久化):数据全部写入成功后,RGW 在索引池(.rgw.buckets.index)中更新该对象的条目,记录对象名、大小、ETag、修改时间等元数据。此操作同样通过 librados 完成,确保索引与数据一致。
- 返回客户端成功:当索引更新确认后,RGW 网关向客户端返回 200 OK 响应,表示对象已成功存储。
6. 块/文件/对象存储区别和应用场景
块存储
特性:块级访问,I/O 路径最短,微秒级时延,高随机 IOPS
优点:性能极致,像跑车一样快,支撑数据库、虚拟机等核心业务,保障交易不卡顿、系统秒启动
缺点:原生不支持多端共享,需额外软件实现集群共享,扩展性有限,适合 “专属性能型” 场景,不适合 “通用共享型” 场景
应用场景:虚拟化、数据库、在线交易处理
生活中我们见到的:云硬盘、银行
文件存储
特性:文件 + 目录树管理,依赖 inode 元数据,支持多端共享。
优点:像货车按 “件” 配送,文件级管理直观易用,适合办公共享、开发测试环境,多端协作无冲突。
缺点:元数据查询增加时延,海量文件场景下性能易瓶颈,扩展性中等,不适合 PB 级非结构化数据存储。
应用场景:数据湖、AI大模型训练、邮件服务器
生活中我们见到的:OA系统、影视渲染、CAD
对象存储
特性:唯一 ID 标识,HTTP 协议访问,分布式架构,元数据与数据分离
优点:像货轮承载海量集装箱,无限横向扩容,成本低,适合图片、视频、日志等海量非结构化数据,跨网共享无障碍。
缺点:HTTP 协议封装增加时延,毫秒级响应,不适合低时延业务,且不支持文件级修改(只能重新上传,覆盖原文件内容才算修改),只适合 “一次写入、多次读取” 的场景。
应用场景:视频流媒体服务、备份系统、医疗应用系统
生活中我们见到的:百度网盘、iCloud、抖音/快手/红果/爱奇艺/优酷视频、医院拍片、停车场照片、监控视频
二.存储池介绍
1. 存储池介绍
为了实现存储资源按需配置,RADOS对集群中的OSD进行池化管理。实际上是一个虚拟概念,表示一组约束条件,例如可以针对存储池设计一组CRUSH规则,限制其只能使用某些规格相同的OSD,或者尽量将所有数据副本分布在物理隔离上的、不同故障域,也可以针对不同用途的存储池指定不同的副本策略,例如若存储池承载的存储应用对时延敏感,则采用多副本备份策略,反之,如果存储的是一些对时延不敏感的数据(例如备份数据)为提升空间利用率则采用纠删码备份策略。


2. 多副本池
在ceph上,存储池有两种类型;默认情况下,我们不指定什么类型的存储池就是副本池(Replicated Pool);所谓副本池就是存储在该存储之上的对象数据,都会由RADOS集群将每个对象数据在集群中存储为多个副本,其中存储于主OSD的为主副本,副本数量在创建存储池时 由管理员指定;默认情况下不指定副本数量,对应副本数量为3个,即1主2从;从上面的描述可以看到,当我们存储一份对象数据时,为了冗余备份,我们需要将数据存储3分,即有两份冗余;这也意味着,我们磁盘利用率也只有1/3。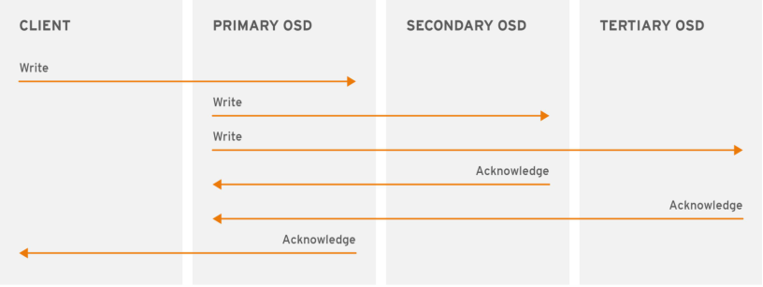
ceph osd crush rule ls //列出所有的crush规则
ceph osd pool get pool_name crush_rule //查看单个pool使用的crush规则,replicated_rule为三副本

3. 纠删码池
为了提高磁盘的利用率的同时,又能保证冗余,ceph还支持纠删码池(Erasure Code);纠删码池就是把对象存储为 N=K+M 个块,其中,K为数据块数量,M为编码块数量,因此存储池的尺寸为 K+M ;纠删码是一种前向纠错(FEC)代码通过将K块的数据转换为N块,假设N=K+M,则其中的M代表纠删码算法添加的额外或冗余的块数量以提供冗余机制(即编码块),而N则表示在纠删码编码之后要创建的块的总数,其可以故障的总块数为M(即N-K)个;类似RAID5;纠删码池减少了确保数据持久性所需的磁盘空间量,但计算量上却比副本存储池要更贵一些。
如上图所示客户端把包含数据“ABCDEFGHI”的对象NYAN保存到存储池中时,假设纠删码算法会将内容分割为三个数据块:第一个包含ABC,第二个为DEF,最后一个为GHI,并为这三个数据块额外创建两个编码块:第四个YXY和第五个QGC;在有着两个编码块配置的存储池中,它容许至多两个OSD不可用而不影响数据的可用性。假设,在某个时刻OSD1和OSD3因故无法正常响应客户端请求,这意味着客户端仅能读取到ABC、DEF和QGC,此时纠删编码算法会通过计算重算出GHI和YXY;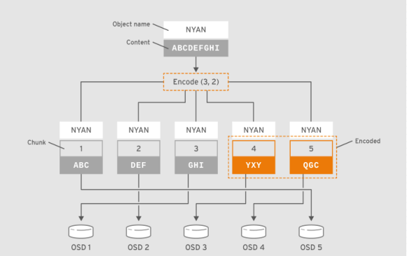
ceph osd crush rule ls //查看所有的crush规则
ceph osd pool get pool_name crush_rule //查看单个pool使用的crush规则,ecrule为纠删码

三、客户端寻址
第一步:file到object映射

目的1:将用户要操作的file,映射为RADOS能够处理的object
目的2:对file进行切分为多个大小一致的object(object_size默认是4M)
每一个切分后产生的object将获得唯一的oid,即object id
oid是由ino和ono两部分组成
ino是待操作file的元数据,可以简单理解为该file的唯一id
ono则是由该file切分产生的某个object的序号 [0.1.2.3….]
假如一个文件的ino为A,它被切成了两个对象,一个对象编号0,另一个编号1,那么这两个文件的oid则为A0与A1
十六进制:一般用数字0到9和字母A到F(或a~f)表示
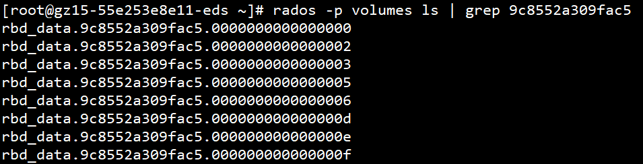
# rados -p pool_name ls | grep ino //查看xx pool下有哪些对象
第二步:object到PG映射
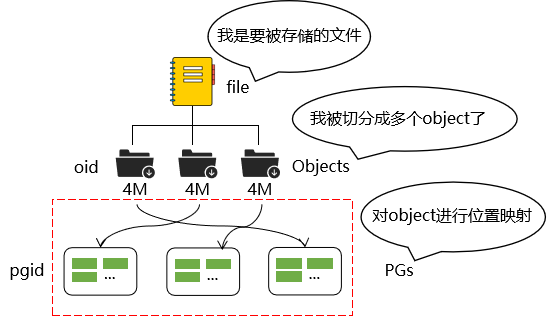
在file被映射为多个Object之后,就需要将每个Object独立地映射到一个PG中去
PG是逻辑性的概念,是存放object的一个载体
为什么要引用PG?
如果要追踪的目标是Object,追踪的数量太多了,将object装入PG中,以PG为存储单元,直接追踪PG的状态,一般PG的数量远远小于object的数量
pg_num:OSD数量*100pg单个数量/3副本=x,x再向上取2的次幂
算法:hash(oid)%pg_num
计算数据oid的Hash值并将结果和PG数目求模,以得到对应的PG编号
例子:pg_num为16,hash(oid)的结果等于30,30%16的取模结果=14,那个这个object就会存储到pg.14里面

第三步:PG到OSD映射
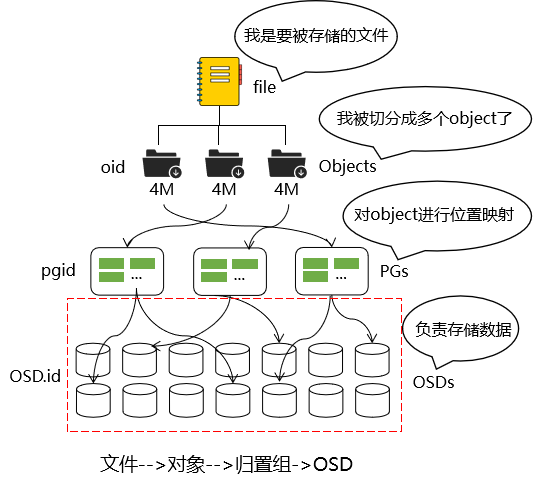
实际存储数据的进程,通常一个OSD daemon绑定一个物理磁盘,Client write/read 数据最终都会走到OSD去执行write/read操作
算法:crush(pgid)=【OSD.x,OSD.x,OSD.x】
PG通过CRUSH计算,映射到OSD中,如果是三副本的,则每个pg都会映射到三个OSD保证了数据的冗余
# ceph OSD map pool_name oid //查看object到osd的映射关系
查看rbd_data.9bf5658c4177e1.00000000000027ff对象的映射关系
object名称:rbd_data.9bf5658c4177e1.00000000000027ff
pg名称:1.1ff
OSD列表:[32,7,13]
Ceph会对每个pool再进行编号,一个PG的实际编号是由pool_id + . + pg_id组成。
四、三副本和纠删码实现原理
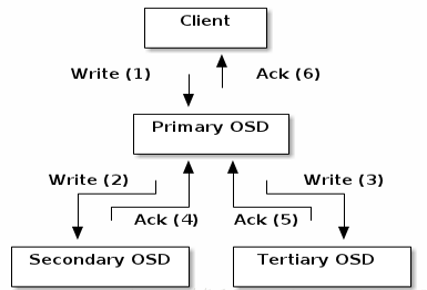
1. 三副本实现原理(读+写)
(1)假设文件映射到pg1.1ff中,pg1.1ff对应OSD.32,OSD.7,OSD.13
(2)其中OSD.32是主OSD数据节点,OSD.7,OSD.13是备OSD数据节点
(3)Client会先找到主OSD.32,写入数据
(4)主OSD.32同时会将数据同步写入到备OSD.7和OSD.13
(5)当备OSD7和OSD.13将数据落盘成功后,会将写入成功结果返回给主OSD.32
(6)主OSD.32收到它们的返回结果后也检查自己的数据是否落盘成功,如果也完成了再给Client回复写入成功
(7)读请求时也是由主OSD接受读请求,不会经过从OSD直接返回结果
2. 纠删码实现原理(写)
(1)原始Object name为NYAN,内容A B C D E F G H I (正好9B,不需要pad)
(2)根据纠删码策略在Primary OSD上进行分片,这里采用encode(3,2)意思是将数据分成3个数据块,并生成2个校验块
(3)由Primary OSD将这5块数据分发到不同故障域的Secondary OSD上
(4)每个Secondary OSD落盘成功后回ACK给Primary OSD,Primary OSD收到4个ACK 后(即 5 份全部写完)才向客户端返回写入成功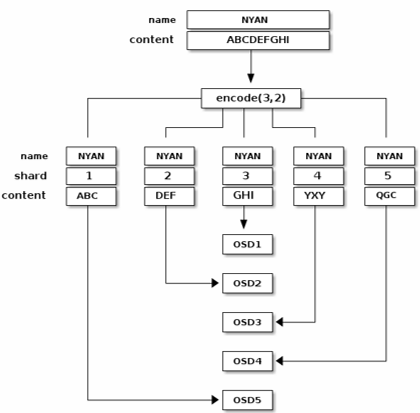
3. 纠删码实现原理(读)
(1)客户端把读请求发到Primary OSD
(2)Primary OSD 同时向所有幸存副本发出内部读请求,先凑够 k 份(图中 3 份)就立即返回客户端。通过这个图例我们可以看出无法读取区块5,因为OSD4已OUT,而OSD2是最慢的,它的块也没有被考虑在内。当从擦除编码池中读取对象NYAN时,解码函数读取三个区块:区块1包含、区块3包含和区块4包含。然后,它重建对象的原始内容。只要读取三个块,就可以调用解码函数。
(3)如果某个 OSD 故障,主 OSD 会自动换另一个拿数据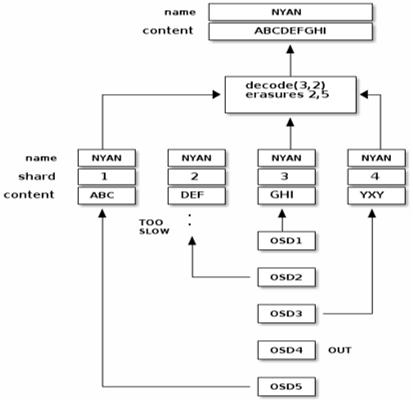
4. 纠删码k+m:1介绍
4+2要求最少6台节点,以节点为存储单元,将数据块和校验块分布到不同的节点上,可容忍坏2台节点,或任意两块硬盘故障,4+2:1要求最少3台节点,每个节点最多保存一个对象的2块数据(即每个节点选择2块硬盘来存放数据)以硬盘为存储单元,可容忍坏1台节点,或任意2块硬盘故障,空间利用率都是一样的k/(k+m)=66.67%,但通过减少节点数量降低了硬件成本。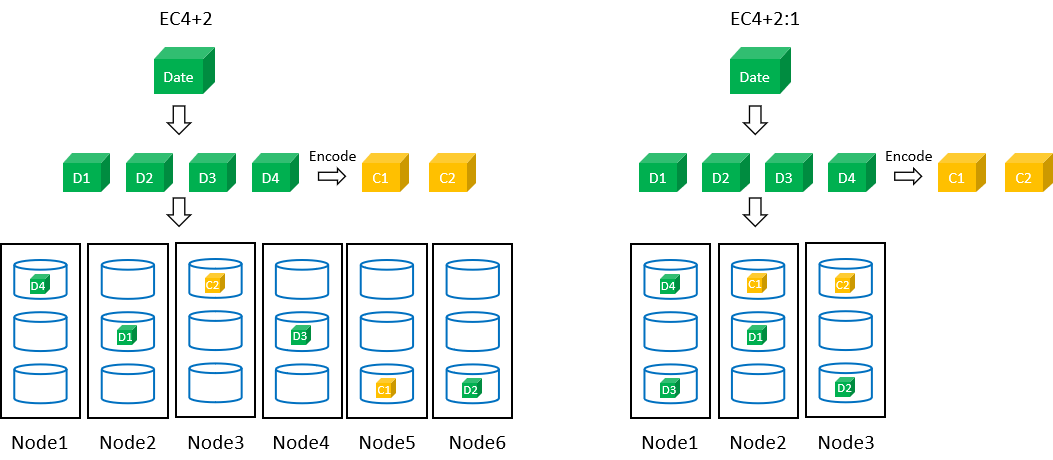
5. 纠删码k+m:1实现原理
嵌套选择
第一层选择(choose_indep)
从根节点58ce6a…-root下独立选择3个不同的host。
这保证了数据块分布在不同的物理主机上,即使一台主机故障,也不会丢失所有数据(满足纠删码的故障域要求)。
第二层选择(chooseleaf_indep):
针对上一步选出的每一个host,再从该主机内选择 2个不同的OSD。
最终每个主机提供2个OSD,总共3 × 2 = 6个OSD,恰好用于放置纠删码的多个数据块(例如 k+m 分片)。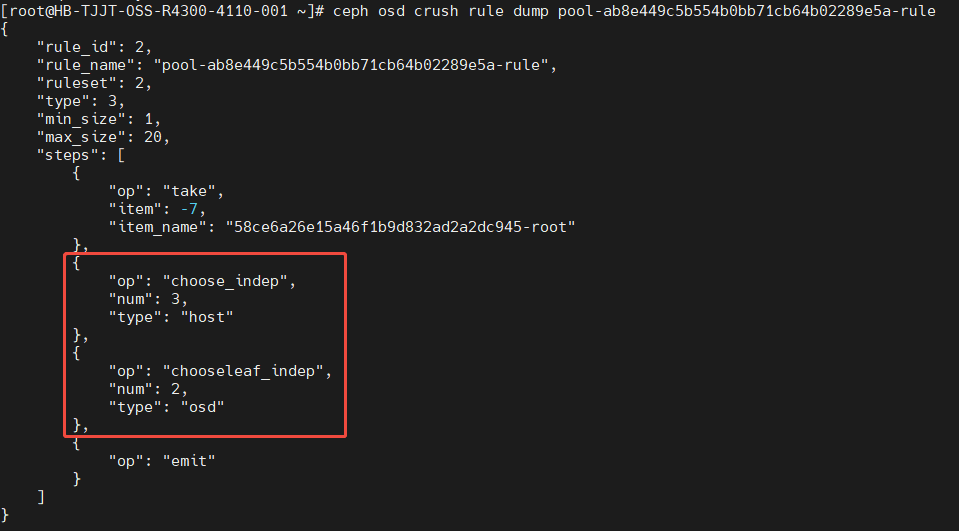
分享一些学习资料&工具
Ceph官网:https://docs.ceph.com
书籍:Ceph之RADOS设计原理与实现
画图工具:https://www.processon.com

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 20
20 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)