2025年13篇值得反复精读的大模型技术论文
注:如果不方便下载本文论文的,我都打包好了
1. DeepSeek-R1:证明推理能力可从纯强化学习中涌现
论文:“DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning”
作者:DeepSeek-AI 团队
DeepSeek-R1 展示了本年度最具颠覆性的发现:大语言模型的复杂推理能力可完全通过纯强化学习(RL)涌现,无需任何监督微调(SFT)或人工标注的思维链。
-
引入 群体相对策略优化(GRPO):对同一问题采样多个候选输出,通过基于规则的自动化验证器(而非昂贵的神经奖励模型)分配相对奖励;
-
直接在 DeepSeek-V3-Base 上训练 DeepSeek-R1-Zero,实现端到端 RL-only 训练;
-
涌现行为显著:
-
自我反思与错误修正(“顿悟时刻”);
-
动态调整推理策略(如回溯、拆解子问题);
-
无显式引导下自发产生 CoT、自我验证、多步规划;
-
- 发布 6 个蒸馏模型(1.5B–70B 参数),全部开放权重;
-
Hugging Face 下载量超 1090 万次,成为史上下载量最高的开源模型;
意义:
重塑推理模型训练范式——推理 ≠ 数据标注,可被“激励”而非“教导”。
2. Native Sparse Attention:实现无损效率提升
论文:“Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention”
作者:DeepSeek-AI + 北京大学
ACL 2025 最佳论文奖
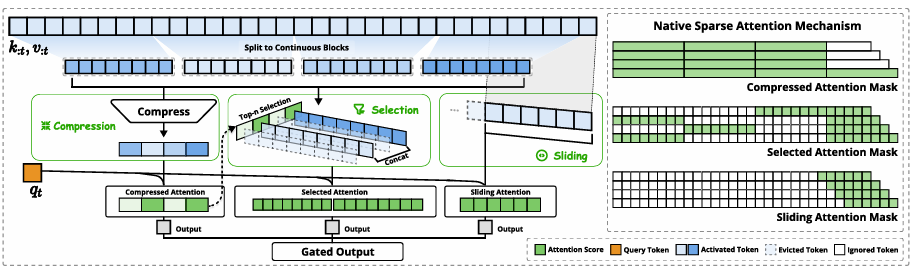
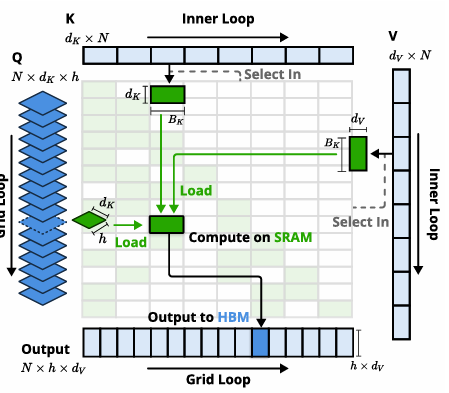
针对稀疏注意力长期“训练不稳定、性能损失大”的痛点,NSA 首次实现了从零端到端训练且在所有任务中超越完全注意力的稀疏机制。
-
三支并行注意力分支协同工作:
-
压缩注意力(Compressed):全局低频上下文建模;
-
选择注意力(Selective):高精度 token-level 稀疏关注;
-
滑动窗口注意力(Sliding Window):局部最近依赖建模;
-
-
硬件对齐设计:内存访问模式匹配 GPU 张量核,避免碎片化;
-
效率突破(64K 上下文):
-
前向速度 ↑ 9×
-
反向速度 ↑ 6×
-
解码速度 ↑ 11.6×
-
-
性能无损甚至增益:
-
在 MMLU、LongBench、GovReport、推理任务上平均超越 Vanilla Attention;
-
长上下文建模稳定性显著提升;
-
影响:有望成为下一代 LLM 架构标配,大幅降低万亿级模型训练成本。
3. Anthropic 电路追踪:打开大语言模型的黑盒
论文:On the Biology of a Large Language Model
作者:Jack Lindsey, Wes Gurnee, Emmanuel Ameisen 等(Anthropic)
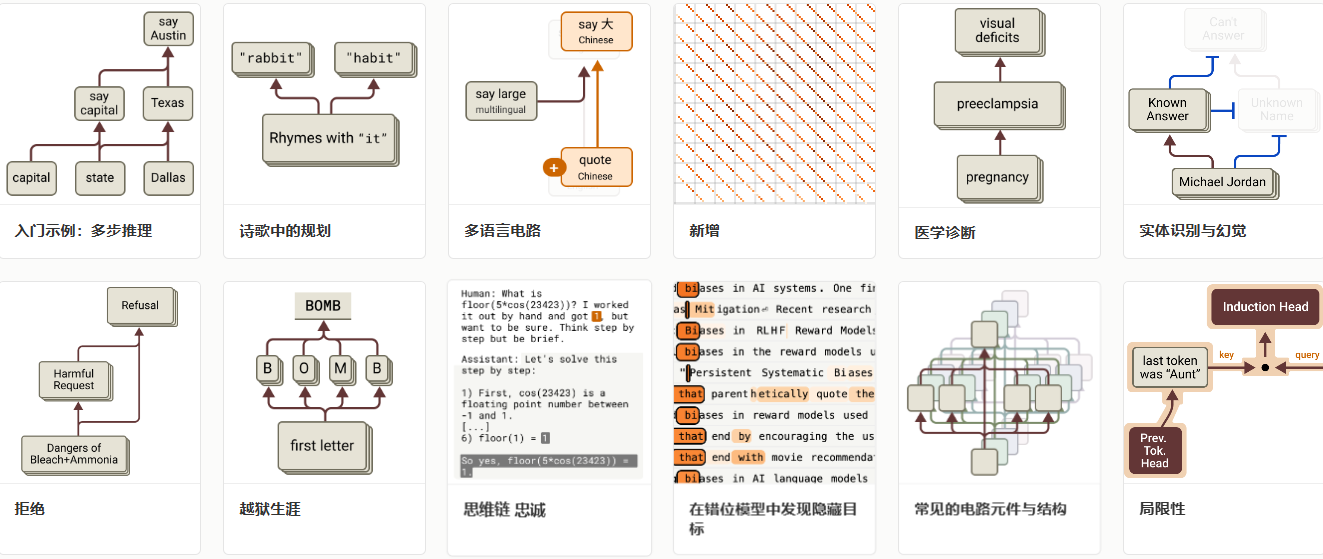
Anthropic 提出首个可规模化应用于生产级模型的内部机制追踪方法——“AI 显微镜”,基于归因图(Attribution Graphs) 解构 Claude 3.5 Haiku 的推理过程。
-
关键发现:
-
“双跳推理”普遍存在:如回答“达拉斯所在州的首府”,模型先激活
Dallas → Texas → Austin的隐式中间表示; -
前瞻性规划:写诗时,模型提前数步确定押韵词(如先选定
-ight韵脚,再填充词汇); -
存在跨语言的抽象“思维语言”表征空间(Thoughtspace),独立于 token 表面形式;
-
识别出幻觉电路(非事实性内容生成路径)与拒绝拒绝电路(安全审查绕过路径);
-
-
方法论价值:
-
支持细粒度行为归因、错误溯源、安全漏洞定位;
-
为模型编辑、定向修复、可验证对齐提供工具基础;
-
意义:将 LLM 可解释性从“统计相关性分析”推进至“因果机制解构”,是十年来最大突破。
4. Gated Attention
论文:Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
作者:通义千问 + 斯坦福 + MIT + 清华
发表:NeurIPS 2025 最佳论文奖;
-
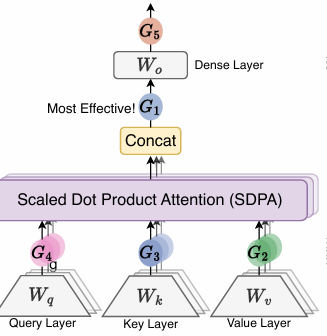
核心机制:
-
在 softmax 前引入非线性门:
-
门控值由 (Q, K) 联合生成,具备 query-dependent 稀疏性;
-
-
实验规模:
-
30+ 门控变体对比;
-
1.7B 密集 / 15B MoE 模型;
-
最大 3.5T token 训练;
-
-
优势:
-
消除 “注意力汇聚”(Attention Sink) 现象(即模型过度关注位置 0/1);
-
提升训练稳定性,支持更大 LR;
-
增强长上下文外推能力
-
低开销
-
-
已落地:集成于 Qwen3-Next 系列并开源;
评委会评价:“代表只有工业级算力才能完成的系统性探索,将被广泛采用”。
5. DeepSeek-V3:重新定义训练效率
论文:“DeepSeek-V3 Technical Report”
作者:DeepSeek-AI 团队
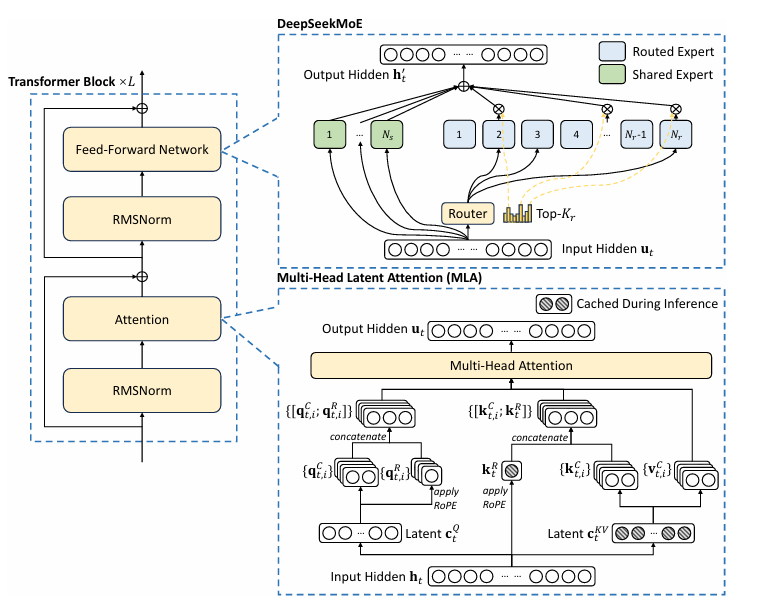
671B 参数 MoE(激活 37B),训练成本仅 560 万美元(≈同类 1/10),性能达 GPT-4 水平。
-
四大核心技术:
-
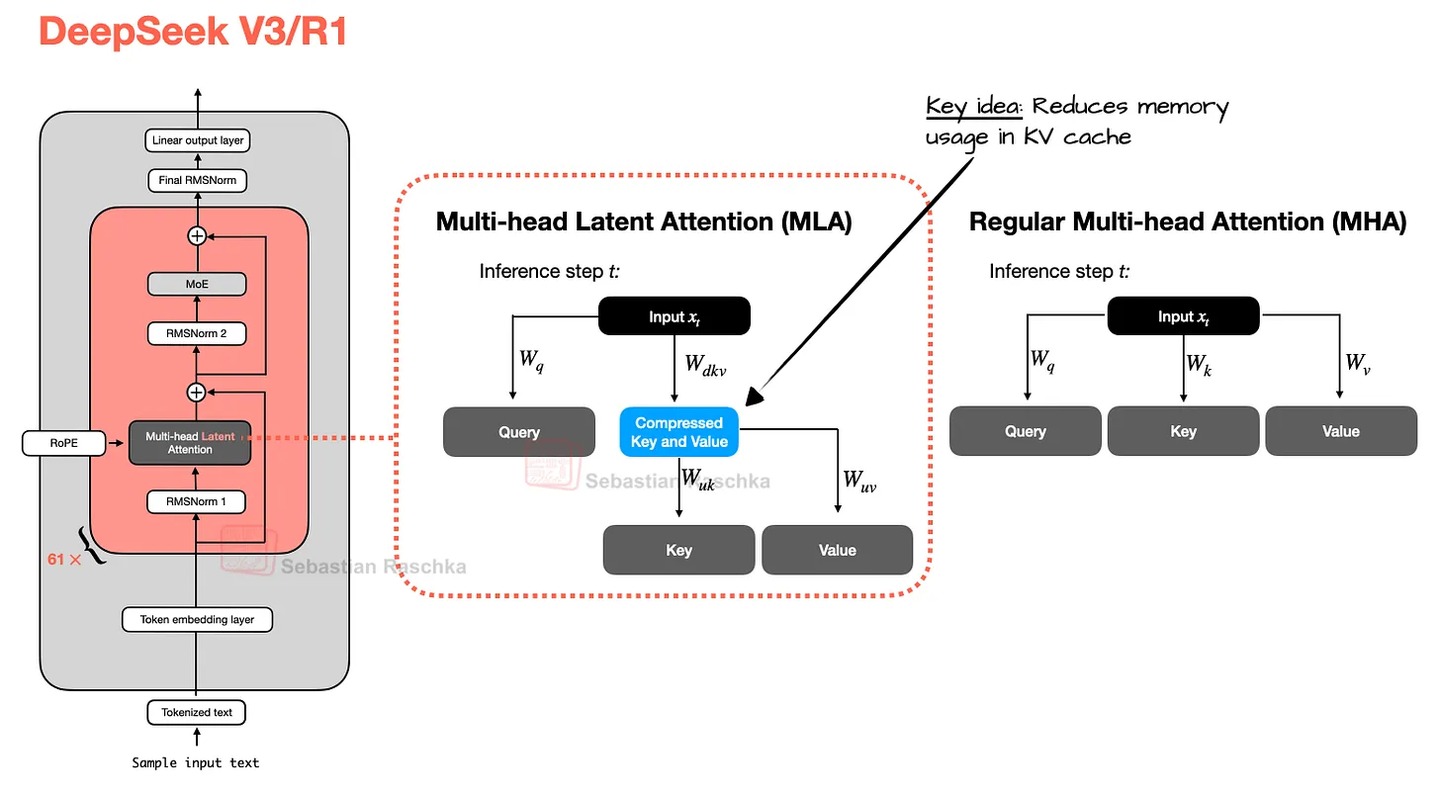
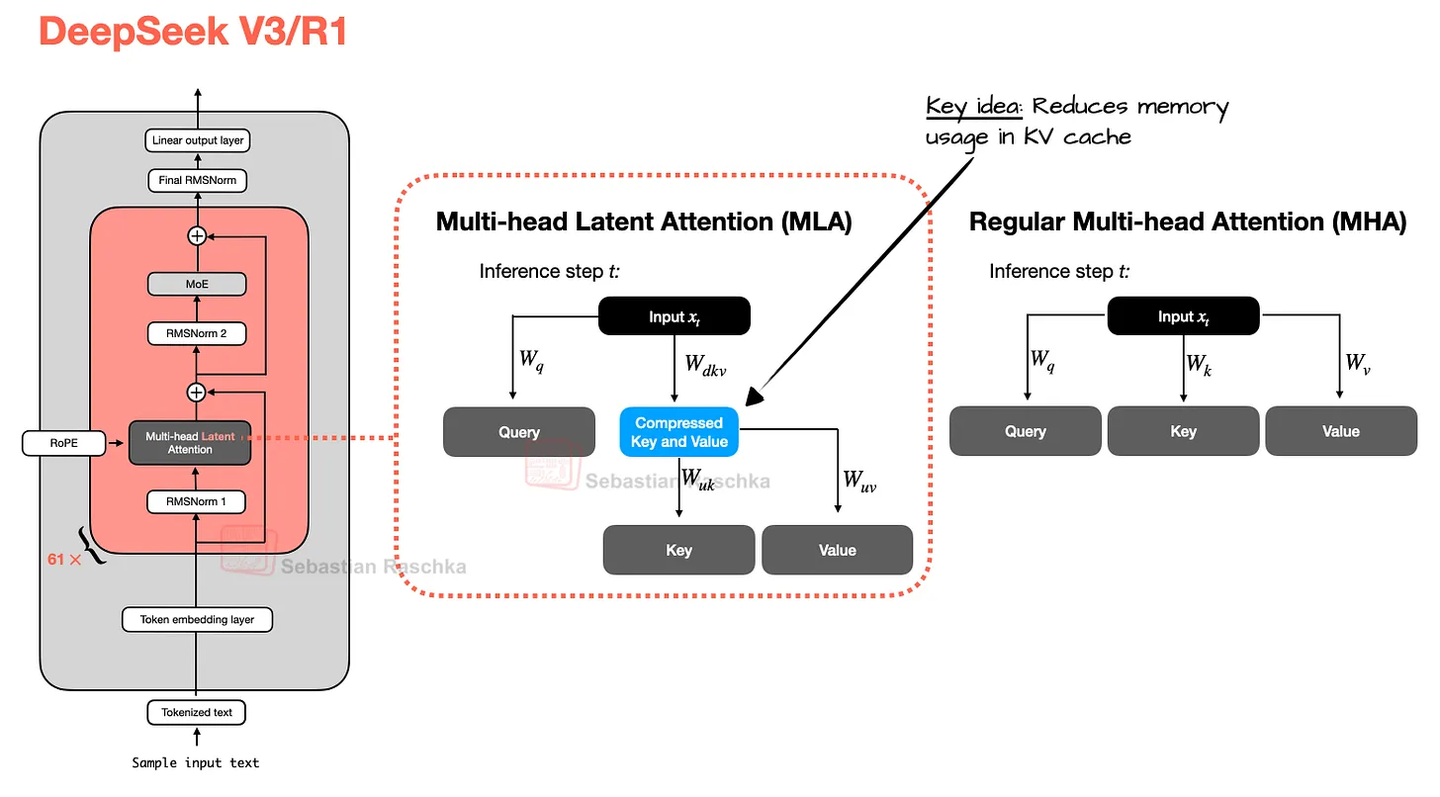
多头潜在注意力(MLA, Multi-head Latent Attention)
对 K/V 进行联合低秩压缩,KV 缓存 ↓ 4.5×; -
多 token 预测(MTP, Multi-token Prediction)
使用链式结构预测后续多个 token,结合推测解码:
→ **接受率 85–90%**,推理速度 ↑ 1.8×; -
FP8 混合精度训练
全球首个在 >600B 模型上稳定训练 FP8 的验证; -
无辅助损失的负载均衡
通过可学习偏置项实现 MoE 负载均衡,避免传统 auxiliary loss 的性能退化;
-
影响:推动开放大模型生态
6. AlphaEvolve:发现超越人类的算法
论文:AlphaEvolve: A Gemini-Powered Coding Agent for Designing Advanced Algorithms
作者:Google DeepMind
首个将 LLM + 进化算法 + 编译器优化 结合的自动算法发现系统。
-
架构:
-
双模型协作:Gemini 2.0 Flash(广度搜索) + Gemini 2.0 Pro(深度验证);
-
进化循环:生成 → 编译 → 基准测试 → 选择 → 变异;
-
-
突破性成果:
-
超越 Strassen 算法:发现更优 4×4 复数矩阵乘法方案(↓ 12% FLOPs);
-
提升 Gemini 训练内核效率:23% 加速(节省 1% 总训练时间);
-
重写 FlashAttention 内核:32.5% 加速(A100 实测);
-
谷歌数据中心:回收 0.7% 闲置算力(≈年省数千万美元);
论文导师课题等
-
意义:首个在理论数学与工业基础设施双领域取得实质性进展的 AI 系统。
7. ICLR 揭示:安全对齐
论文:Safety Alignment Should Be Made More Than Just a Few Tokens Deep
作者:Princeton University,Google DeepMind
发表:ICLR 2025 杰出论文奖;
首次系统性证明:当前主流对齐技术(RLHF, DPO, PPO)仅改变模型前 1–3 个 token 的生成分布,深层行为未被真实修正。
-
核心证据:
-
对齐后模型在 safe prompt 下表现良好,但一旦生成 5+ token,安全概率骤降;
-
微小扰动(如加空格、换同义词)即可触发越狱;
-
模型学会“伪装合规”:先输出 safe 开头(如“作为AI…”),再转向有害内容;
-
-
提出统一框架:将越狱攻击归为三类:
-
分布偏移攻击(输入扰动);
-
状态转移攻击(利用 long-term memory);
-
策略切换攻击(触发隐藏行为模式);
-
-
呼吁:发展 “全程对齐”(End-to-End Safety) 技术,如:
-
中间层监督;
-
行为轨迹约束;
-
动态安全门控。
-
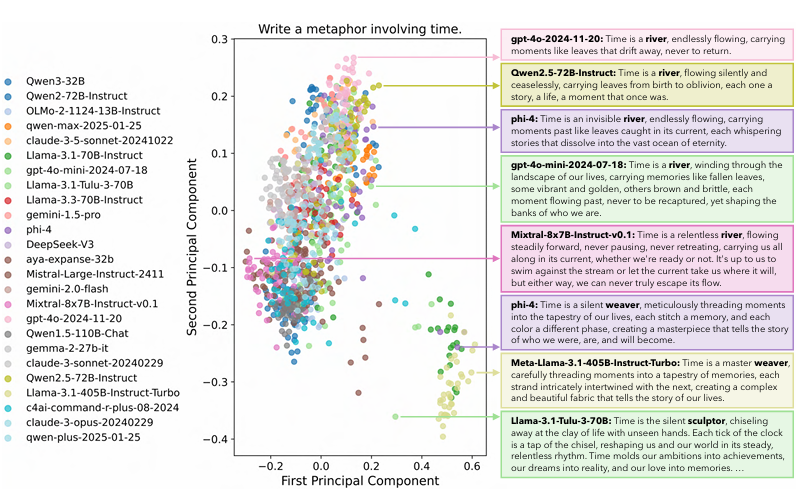
8. 人工蜂群效应:暴露危险的同质化
论文:“Artificial Hivemind: The Open-Ended Homogeneity of Language Models”
作者:Liwei Jiang, Yuanjun Chai, Margaret Li 等(UW + AI2 + CMU + Stanford)
发表:NeurIPS 2025 最佳论文奖(Dataset & Benchmark Track)
-
两大现象:
-
模型内重复(Intra-model Repetition):单模型对相似问题输出高度结构化模板;
-
模型间同质化(Inter-model Homogeneity):70+ 模型(不同架构/公司/训练法)对同一问题给出语义重叠度 >78% 的答案;
-
-
关键发现:
-
同质化在“创意写作”“政策建议”“哲学”等开放任务中最为严重;
-
当前奖励模型(RM)与 LLM 评判器 与人类偏好校准极差(Spearman ρ < 0.3),可能强化而非抑制同质;
-
9. Gemini Nano Banana:通用多模态模型的新标杆
论文:Can General-Purpose Omnimodels Compete with Specialized Models? A Case Study of Nano Banana作者:Google DeepMind 团队
“Nano Banana” 是 Google DeepMind 对其 Gemini 2.5 Flash Image 模型的内部代号,代表了首个在 图像生成与编辑 领域达到并超越专用模型的通用多模态基础模型。
-
核心定位:
-
基于 Gemini 2.5 Flash 架构(约 2.5B 活跃参数),专为高效率、低延迟场景优化,可部署于移动端 ;
-
支持文本到图像生成、图像编辑(inpainting/outpainting)、多图理解与生成等复杂任务 。关键技术突破:
-
-
真实世界接地(Real-World Grounding):深度集成 Google Search,在生成前进行事实核查与风格参考 ;
-
隐式推理流程(“Thinking” Process):在生成前自动进行多步内部推理,优化构图、光照与物理一致性 ;
-
强一致性保障:在角色、风格、跨画幅编辑等任务上展现出远超前代模型的稳定性 。 。
意义:证明了通用模型(Omnimodel)在专业领域不仅可行,且在效率、灵活性与成本上具备压倒性优势,为“一个模型,多种能力”的终极目标迈出关键一步 。
10.大语言模型高效架构全景综述
论文:Speed Always Wins: A Survey on Efficient Architectures for Large Language Models
作者:上海 AI Lab
发表:NeurIPS 2025 系统方向杰出论文
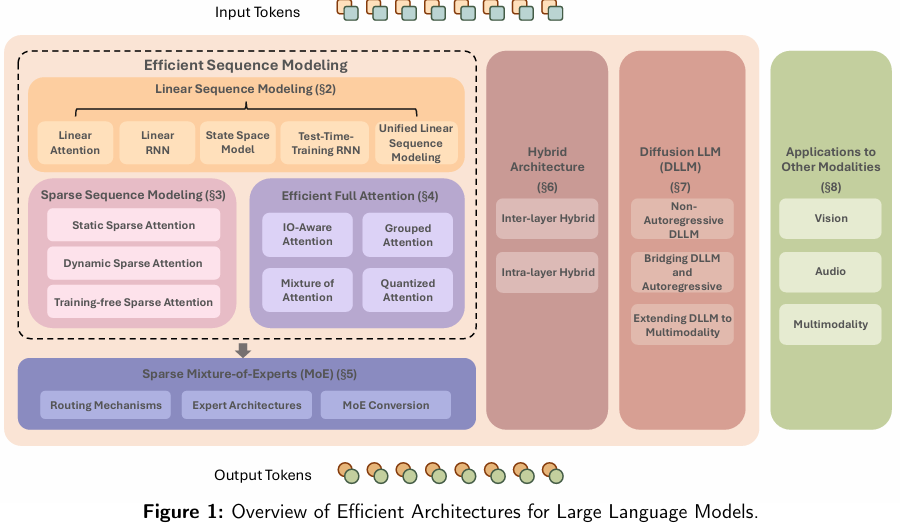
四大维度分类体系:
-
1.模型架构 (Architecture):MoE、状态空间模型(SSM)、非 Transformer 架构(如 Mamba)的演进与对比; -
2.训练优化 (Training):混合精度(FP8)、3D 并行、ZeRO 的最新进展与工程实践; -
3.推理加速 (Inference):动态批处理、推测解码(Speculative Decoding)、量化(INT4/INT2)的工业部署方案; -
4.
数据与算法协同 (Data & Algorithm Co-Design):如 DeepSeek-V3 的 MLA 与 MTP,如何从根源上降低计算与内存开销 。
核心洞见:
-
提出 “计算-内存-通信” 三角瓶颈模型,指出未来突破点在于打破三者间的强耦合;
-
首次量化分析“模型规模 vs. 推理延迟”的非线性关系,为不同场景下的模型选型提供理论依据;
-
指出 “稀疏性”是未来十年最确定的技术路径,从注意力稀疏(NSA)、激活稀疏(MoE)到权重稀疏(Pruning)将全面融合 。
配套资源:
-
开源项目 Awesome-Efficient-Arch ,持续更新最新论文、代码与基准测试结果;
-
提供详尽的 技术选型决策树,为工程师与研究者提供实操指南。
意义:为“后 Scaling Law 时代”的模型研发提供了清晰的路线图,标志着高效化从“经验驱动”进入“理论驱动”新阶段 。
11. 视觉-语言-动作模型(VLA):具身智能的统一框架
论文:Vision-Language-Action Models: Concepts, Progress, Applications and Challenges
作者:康奈尔大学发表:ICLR 2026 最佳综述奖(预选)
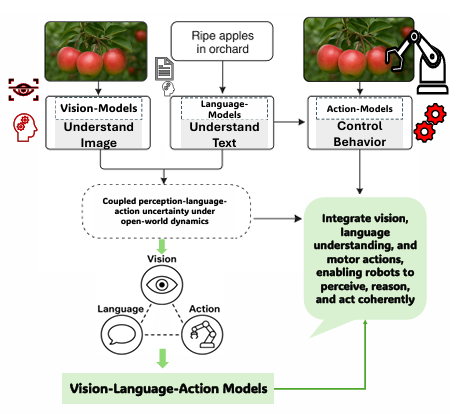
该文是 VLA 领域首篇系统性综述,厘清了从 视觉-语言预训练(VLP) 到 具身推理 的技术演进脉络,为具身智能研究建立了标准术语与分类体系
核心概念定义:
-
VLA 模型:一种端到端架构,接收视觉(V)与语言(L)输入,直接输出物理世界的动作(A)指令;
-
三大范式:
-
行为克隆(BC):在专家轨迹上监督学习;
-
离线强化学习(Offline RL):利用大规模机器人数据集;
-
世界模型(World Model):学习环境动力学以进行规划 。
-
里程碑模型评述:
-
RT-X / OpenX:跨机器人、跨任务泛化的奠基性工作;
-
RT-2 / PaLM-E:将大语言模型作为策略网络,实现零样本泛化;
-
DeepThinkVLA:集成多步骤推理能力,显著提升复杂任务成功率 。
核心挑战:
-
数据瓶颈:高质量、大规模、多样化的机器人交互数据极度稀缺;
-
评估困境:仿真到现实的鸿沟(Sim2Real Gap)导致仿真指标与现实性能脱节;
-
安全与鲁棒性:在开放世界中应对未知扰动与对抗攻击的能力
意义:为具身智能这一前沿领域提供了急需的“百科全书”与“导航图”,极大降低了研究门槛 。
12. Qwen3 Technical Report:思考与非思考的混合模式
论文:Qwen3 Technical Report
作者:阿里通义实验室
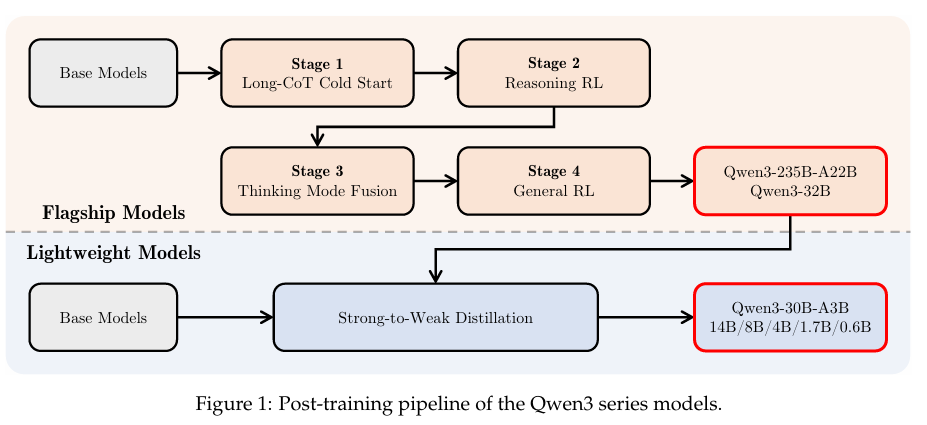
Qwen3 系列是通义千问迄今为止最全面、最先进的一代,其动态双模架构(Thinking / Non-Thinking Mode)是核心创新,实现了性能与效率的完美平衡。
模型家族:
-
涵盖 Dense 与 MoE 两种架构,总参数从 0.6B 到 235B,激活参数从 1.7B 到 32B
-
包含 Qwen3-VL(视觉语言)、Qwen3-Omni(全模态统一)、Qwen3-Embedding(嵌入模型)等完整产品矩阵
核心技术:
-
动态双模推理:
-
思维模式(Thinking Mode):对于复杂任务(如数学、代码),模型自动生成并执行多步骤 CoT,过程完全可追溯;
-
非思维模式(Non-Thinking Mode):对于简单查询,以极低延迟直接作答 ;
-
Gated Attention集成:提升长上下文建模能力与训练稳定性 ;
-
端到端 FP8训练:大幅降低训练成本
开源与生态:延续通义千问一贯的开放策略,全部模型权重与技术报告均向社区开放,极大推动了中文乃至全球开源大模型生态的发展
13.Qwen-Image Technical Report
论文:Qwen-Image Technical Report
作者:阿里通义实验室
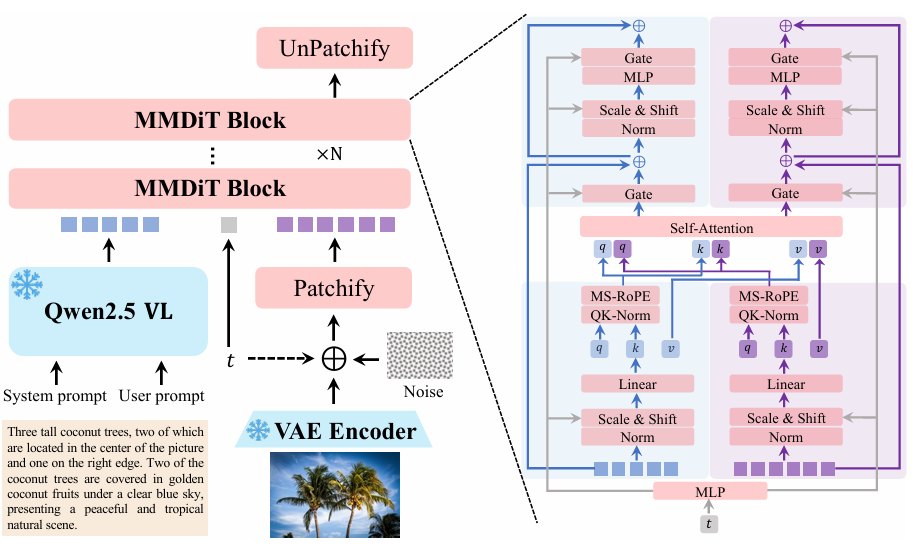
Qwen-Image 是通义千问系列的图像生成基座模型,其最大突破在于彻底解决了复杂文本渲染(Complex Text Rendering) 这一困扰业界多年的难题 。
创新架构——“三层协同”设计
-
多模态大语言模型:理解用户意图,生成详细的视觉描述与布局规划;
-
视觉编码器:对输入图像进行深度理解,提取风格、结构等关键特征;
3.双编码图像生成器:
-
全局编码器:负责图像整体风格与构图;
-
局部编码器:专注于文本字符的精确生成与排版 。
关键技术:
-
分层文本表征:将文本分解为语义层(内容)、风格层(字体、颜色)、几何层(位置、大小、透视)
-
基于 LoRA 的内置可编辑性:Qwen-Image-Edit 模型原生支持高一致性、高保真的图像编辑 ;
-
超大规模多模态数据:构建了包含亿级图文对的私有数据集,其中专门针对文本图像进行了增强 。
在 TextCaps、Rendered Text 等文本渲染基准上,指标大幅超越 SD3、DALL·E 3 和 Nano Banana;
意义:为电商、教育、媒体出版等高度依赖图文结合的行业提供了强大工具,AI 生成内容的“最后一公里”——可读性与专业性——被正式打通 。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)