CS336 Assignment 1: Building a Transformer LM Spring 2025 翻译与实现
文章目录
- 1 Assignment Overview
- 2 Byte-Pair Encoding (BPE) Tokenizer
- 3 Transformer Language Model Architecture
- 3.4 Basic Building Blocks: Linear and Embedding Modules
- 3.5 Pre-Norm Transformer Block
-
- 3.5.1 Root Mean Square Layer Normalization 均方根层归一化
- 3.5.2 Position-Wise Feed-Forward Network
- 3.5.3 Relative Positional Embeddings
- 3.5.4 Scaled Dot-Product Attention
- 3.5.5 Causal Multi-Head Self-Attention
- 3.6 The Full Transformer LM
- 4 Training a Transformer LM
- 5 训练循环
- 6 文本生成
- 7 实验
1 Assignment Overview
在本次作业中,你将构建训练标准 Transformer 语言模型(LM)所需的所有组件,并训练一些模型。
你将会构建
- Byte-pair encoding (BPE) tokenizer (§2)
- Transformer language model (LM) (§3)
- The cross-entropy loss function and the AdamW optimizer (§4)
- The training loop, with support for serializing and loading model and optimizer state (§5)
你将会训练
- 在 TinyStories 数据集上训练一个 BPE 分词器。
- 在数据集上运行训练好的分词器,将其转换为整数 ID 序列。
- 在 TinyStories 数据集上训练一个 Transformer 语言模型。
- 使用训练好的 Transformer 语言模型生成样本并评估困惑度(perplexity)。
- 在 OpenWebText 数据集上训练模型,并将获得的perplexity提交到排行榜。
你可以使用
我们希望你从零开始构建这些组件。特别是,你不能使用 torch.nn、torch.nn.functional 或 torch.optim 中的任何定义,但可以用以下内容:
• torch.nn.Parameter
• torch.nn 中的容器类(例如 Module、ModuleList、Sequential 等)
• torch.optim.Optimizer 基类
你可以使用任何其他 PyTorch 定义。遇到疑问时,请考虑使用它是否会破坏作业的“从零开始”理念。额
What the code looks like
所有作业代码以及这篇说明文档都可以在 GitHub 上找到:https://github.com/stanford-cs336/assignment1-basics/tree/main
-
cs336_basics/*:这是你编写代码的地方。注意这里没有任何代码——你可以从头自行编写任何内容!
-
adapters.py:有一套你的代码必须具备的功能。对于每个功能(例如,缩放点积注意力),通过简单地调用你的代码来完成其实现(例如,run_scaled_dot_product_attention)。注意:你对 adapters.py 的修改不应该包含任何实质性的逻辑;this is glue code.
-
test_*.py:这里包含你必须通过的所有测试(例如,test_scaled_dot_product_attention),这些测试会调用 adapters.py 中定义的钩子。不要编辑测试文件。
How to submit
你需要向 Gradescope 提交以下文件:
writeup.pdf:回答所有书面问题。请排版你的回答。
code.zip:包含你编写的所有代码。
要提交到排行榜,请向以下仓库提交 PR:https://github.com/stanford-cs336/assignment1-basics-leaderboard
参见排行榜仓库中的 README.md 以获取详细的提交说明。
数据集的获取
本次作业将使用两个预处理数据集:TinyStories [Eldan 和 Li, 2023] 和 OpenWebText [Gokaslan 等人,2019]。两个数据集都是单一的大型纯文本文件。可以使用 README.md 中的命令下载这些文件。
Low-Resource/Downscaling Tip: Init
在本课程的作业手册中,我们会提供一些建议,帮助你在较少或没有 GPU资源的情况下完成作业的部分内容。例如,我们有时会建议缩减你的数据集或模型大小,或者说明如何在 MacOS 集成 GPU 或 CPU上运行训练代码。你可以在蓝色框(本文是灰色)中找到这些“低资源提示”(如下所示)。我们建议你阅读它们!
Low-Resource/Downscaling Tip: Assignment 1 on Apple Silicon or CPU
使用教学团队的解决方案代码,我们可以在配备 36 GB RAM 的 Apple M3 Max 芯片上训练一个语言模型,使其生成相当流畅的文本,使用 Metal GPU(MPS)不到 5 分钟,使用 CPU 约 30 分钟。如果你不太理解这些术语,不用担心!只需知道,如果你有一台更新的笔记本电脑,并且你的实现正确且高效,你将能够训练一个小型语言模型,生成具有不错流畅度的简单儿童故事。 在作业的后面部分,我们会解释如果在 CPU 或 MPS 上运行,需要做哪些修改。
2 Byte-Pair Encoding (BPE) Tokenizer
在作业的第一部分,我们将训练和实现一个字节级字节对编码(BPE)分词器 [Sennrich 等人,2016, Wang 等人,2019]。具体来说,我们将把任意(Unicode)字符串表示为字节序列,并在该字节序列上训练我们的 BPE 分词器。之后,我们将使用这个分词器将文本(一个字符串)编码为用于语言建模的令牌(整数序列)。
2.1 Unicode标准
Unicode 是一种文本编码标准,它将字符映射到整数代码点。截至 Unicode 16.0(2024 年 9 月发布),该标准定义了 168 种脚本中的 154,998 个字符。例如,字符 “s” 的代码点是 115(通常表示为 U+0073,其中 U+ 是常规前缀,0073 是 115 的十六进制表示),字符 “牛” 的代码点是 29275。在 Python 中,你可以使用 ord () 函数将单个 Unicode 字符转换为其整数表示。chr () 函数将整数 Unicode 代码点转换为相应字符的字符串。
>>> ord('牛')
29275
>>> chr(29275)
'牛'
Problem (unicode1): Understanding Unicode (1 point)
(a) chr (0) 返回什么Unicode 字符?
chr(0) 返回的是 ASCII/Unicode 的空字符(NULL character)
(b) 这个字符的字符串表示(`__repr__()`)与其打印表示有什么不同?
不知道
(c) 当这个字符出现在文本中时会发生什么?在 Python 解释器中尝试以下代码可能会对你有所帮助,看看是否与你的预期一致:
>>> chr(0)
>>> print(chr(0))
>>> "this is a test" + chr(0) + "string"
>>> print("this is a test" + chr(0) + "string")
2.2 Unicode Encodings
虽然 Unicode 标准定义了从字符到代码点(整数)的映射,但直接在 Unicode 代码点上训练分词器是不切实际的,因为词汇表将非常庞大(大约 15 万个条目)且稀疏(因为许多字符非常罕见)。相反,我们将使用 Unicode 编码,它将 Unicode 字符转换为字节序列。Unicode 标准本身定义了三种编码:UTF-8、UTF-16 和 UTF-32,其中 UTF-8 是互联网的主要编码(超过 98% 的网页使用 UTF-8)。
要将 Unicode string编码为 UTF-8,我们可以使用 Python 中的 encode() 函数。要访问 Python bytes 对象的底层字节值,我们可以对其进行迭代(例如,调用 list())。最后,我们可以使用 decode() 函数将 UTF-8 byte string解码为 Unicode 字符串。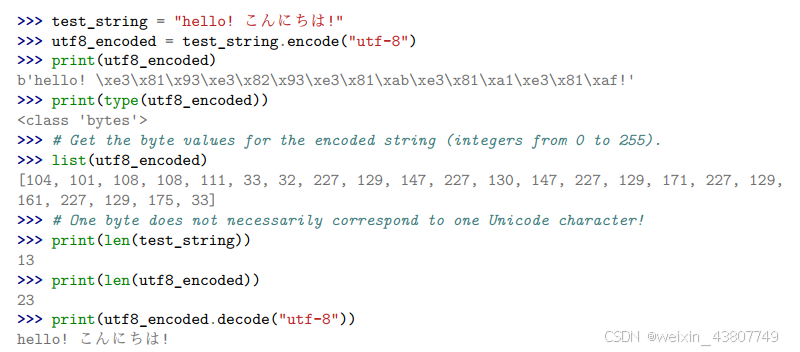
通过将我们的 Unicode 码点转换为字节序列(例如,通过 UTF-8 编码),我们本质上是在将一个码点序列(范围在 0 到 154,997 之间的整数)转换为一个字节值序列(范围在 0 到 255 之间的整数)。这种长度为 256 的字节词汇表处理起来要容易得多。当使用字节级分词(tokenization)时,我们无需担心词汇表之外的 token(out-of-vocabulary tokens),因为我们知道任何输入文本都可以表示为从 0 到 255 的整数序列。

2.3 Subword Tokenization
虽然字节级别的标记化可以缓解词级标记器所面临的词汇外问题,但将文本标记化为字节会导致输入序列极其冗长。这会减缓模型训练速度,因为在词级语言模型中,一个包含10个单词的句子可能只有10个标记,但在字符级模型中可能有50个或更多标记(取决于单词的长度)。处理这些更长的序列在模型的每一步都需要更多的计算。此外,对字节序列进行语言建模是困难的,因为更长的输入序列会在数据中产生长期依赖。
子词分词是介于词级分词器和字节级分词器之间的一种方法。注意,字节级分词器的词汇表有 256 个条目(字节值为 0 到 255)。子词分词器通过增加词汇表大小来换取对输入字节序列的更好压缩。例如,如果字节序列 b’the’ 经常出现在我们的原始文本训练数据中,将其分配一个词汇表条目可以将这三个 token 的序列缩减为单个 token。
我们如何选择这些子词单元以添加到我们的词汇表中?Sennrich 等人 [2016] 提出使用字节对编码(BPE;Gage, 1994),这是一种压缩算法,它通过迭代地将最频繁的字节对替换(“合并”)为一个新的、未使用的索引。请注意,该算法是为了将子词标记添加到我们的词汇表中,从而最大化输入序列的压缩——如果一个单词在我们的输入文本中出现次数足够多,它将以一个子词单元的形式表示。
使用基于 BPE 构建词汇表的子词分词器通常被称为 BPE 分词器。在本作业中,我们将实现一个字节级 BPE 分词器,其中词汇项是字节或字节的合并序列,这使我们在处理未登录词和可管理的输入序列长度方面兼得两者。构建 BPE 分词器词汇表的过程被称为“训练” BPE 分词器。
2.4 BPE Tokenizer Training
BPE 分词器的训练过程包括三个主要步骤:
Vocabulary initialization 分词器的词汇表是从字节串标记到整数 ID 的一对一映射。由于我们正在训练一个字节级的 BPE 分词器,我们的初始词汇表只是所有字节的集合。由于可能的字节值有 256 个,因此我们的初始词汇表大小为 256。
Pre-tokenization 一旦你有了词汇表,原则上你可以统计文本中字节相邻出现的频率,并从最频繁的字节对开始合并它们。然而,这在计算上相当昂贵,因为每次合并时我们都需要对语料库进行完整的遍历。此外,直接在语料库中合并字节可能会导致只在标点符号上有所不同的标记(例如 dog! 与 dog.)。这些标记会得到完全不同的标记 ID,即便它们很可能具有高度的语义相似性(因为它们只在标点上有所不同)。
为避免这种情况,我们会对语料库进行预分词。你可以将其理解为对语料库进行的一种粗粒度分词,它帮助我们统计字符对出现的频率。例如,单词“text”可能是一个出现了10次的预分词。在这种情况下,当我们统计字符‘t’和’e’相邻出现的次数时,我们会发现单词“text”中‘t’和’e’是相邻的,因此可以将它们的计数增加10,而不必遍历整个语料库。由于我们训练的是基于字节的BPE模型,每个预分词都表示为一系列UTF-8字节。
Sennrich 等人 [2016] 的原始 BPE 实现通过简单地按空格分割(即 s.split(" "))进行预分词。相比之下,我们将使用一个基于正则表达式的预分词器(由 GPT-2 使用;Radford 等人,2019),来自 https://github.com/openai/tiktoken/pull/234/files:
>>> PAT = r"""'(?:[sdmt]|ll|ve|re)| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+"""
交互式地使用这个预分词器分割一些文本可能有助于你更好地理解它的行为:
>>> # 需要 `regex` 包
>>> import regex as re
>>> re.findall(PAT, "some text that i'll pre-tokenize")
['some', ' text', ' that', ' i', "'ll", ' pre', '-', 'tokenize']
然而,在你的代码中使用它时,你应该使用 re.finditer 来避免在构建从预令牌到其计数的映射时存储预分词的单词。
Compute BPE merges
现在我们已经将输入文本转换为预令牌,并将每个预令牌表示为 UTF-8 字节序列,我们可以计算 BPE 合并(即训练 BPE 分词器)。在高层次上,BPE 算法迭代地计算每个字节对的频率,并识别出频率最高的对(“A”,“B”)。然后,这个最频繁的对(“A”,“B”)的每次出现都被合并,即用一个新的令牌 “AB” 替换。这个新的合并令牌被添加到我们的词汇表中;因此,BPE 训练后的最终词汇表大小是初始词汇表的大小(在我们的例子中是 256)加上训练期间执行的 BPE 合并操作的数量。为了提高 BPE 训练期间的效率,我们不考虑跨预令牌边界的对。计算合并时,对于频率相同的对,通过选择字典序更大的对来确定性地打破平局。例如,如果对(“A”,“B”)、(“A”,“C”)、(“B”,“ZZ”)和(“BA”,“A”)都具有最高频率,我们将合并(“BA”,“A”):
>>> max([("A", "B"), ("A", "C"), ("B", "ZZ"), ("BA", "A")])
('BA', 'A')
Special tokens 通常,一些字符串(例如,<|endoftext|>)被用来编码元数据(例如,文档之间的边界)。在编码文本时,通常希望将某些字符串视为“特殊标记”,这些标记永远不应被拆分成多个标记(即,总是作为单个标记保留)。例如,序列结束字符串 <|endoftext|> 应始终作为单个标记(即单个整数 ID)保留,这样我们才能知道何时停止从语言模型生成文本。这些特殊标记必须添加到词汇表中,以便它们有一个对应的固定标记 ID。
Sennrich 等人(2016)的算法 1 包含了一个低效的 BPE 分词器训练实现(基本上遵循我们上面概述的步骤)。作为第一个练习,实现并测试这个函数可能有助于你理解相关概念。
示例(bpe_example):BPE 训练示例
这是来自 Sennrich 等人 [2016] 的一个典型示例。考虑一个包含以下文本的语料库:
low low low low low
lower lower widest widest widest
newest newest newest newest newest newest
并且词汇表中有一个特殊标记<|endoftext|>
Vocabulary: 我们用特殊标记<|endoftext|>和 256 个字节值初始化词汇表。
Pre-tokenization:为了简化并专注于合并过程,我们在此示例中假设预分词只是简单地按空格拆分。当我们进行预分词并统计时,就得到了频率表
{low: 5, lower: 2, widest: 3, newest: 6}
将其表示为 dict[tuple[bytes], int] 是很方便的,例如 {(l,o,w): 5 …}。
请注意,即使是单个字节在 Python 中也是一个 bytes 对象。Python 中没有表示单个字节的 byte 类型,就像没有表示单个字符的 char 类型一样。
Merges 首先查看每对连续的字节,并将它们出现的单词的频率相加,得到`{lo:7, ow:7, we:8, er:2, wi:3, id:3, de:3, es:9, st:9, ne:6, ew:6}`。
('es')和('st')的频率相同,所以我们选择字典序更大的对('st')。
然后,合并预标记,得到`{(l, o, w):5, (l, o, w, e, r):2, (w, i, d, e, st):3, (n, e, w, e, st):6}`。
在第二轮中,看到(e, st)是最常见的对(计数为 9),我们会合并为`{(l, o, w):5, (l, o, w, e, r):2, (w, i, d, est):3, (n, e, w, est):6}`。
继续这个过程,最终得到的合并序列是`['s t', 'e st', 'ow', 'l ow', 'w est', 'ne', 'ne west', 'wi', 'wi d', 'wid est', 'lowe', 'lowe r']`。
如果进行 6 次合并,会得到`['s t', 'e st', 'ow', 'l ow', 'west', 'n e']`,
词汇表元素将是`【<lendoftext|>, [...256个字节字符], st, est, ow, low, west, ne】`。
有了这个词汇表和这组合并,单词 “newest” 会被分词为[ne, west]。
2.5 Experimenting with BPE Tokenizer Training
在 TinyStories 数据集上训练一个字节级的 BPE 分词器。查找 / 下载该数据集的说明可以在第 1 节中找到。在开始之前,我们建议你先了解一下 TinyStories 数据集,了解其中的内容。
Parallelizing pre-tokenization 你会发现,预标记化步骤是一个主要的瓶颈。你可以使用内置的multiprocessing库对代码进行并行化处理,以加快预标记化的速度。具体来说,我们建议在预标记化的并行实现中,对语料库进行分块,同时确保分块边界出现在特殊标记的开头。你可以直接使用以下链接中的 starter 代码来获取分块边界,然后利用这些边界在进程间分配工作:
https://github.com/stanford-cs336/assignment1-basics/blob/main/cs336_basics/pretokenization_example.py
这种分块方式总是有效的,因为我们从不希望跨文档边界进行合并。就本作业而言,你总是可以以这种方式进行分割。不用担心会遇到一个不包含<lendoftext|>的语料库这种边缘情况。
Removing special tokens before pre-tokenization 在使用正则表达式模式(使用re.finditer)进行预标记化之前,你应该从语料库(或者如果使用并行实现,则从你的分块)中剥离所有特殊标记。确保你按照特殊标记进行分割,这样在它们所分隔的文本之间就不会发生合并。例如,如果你有一个像[Doc 1]<lendoftext|>[Doc 2]这样的语料库(或分块),你应该按照特殊标记<lendoftext|>进行分割,并分别对[Doc 1]和[Doc 2]进行预标记化,这样在文档边界之间就不会发生合并。这可以通过使用re.split来实现,其中分隔符是"|".join(special_tokens)(需要小心使用re.escape,因为|可能会出现在特殊标记中)。test_train_bpe_special_tokens 函数会对此进行测试。
Optimizing the merging step 上面典型示例中的 BPE 训练的朴素实现速度很慢,因为对于每次合并,它都要迭代所有字节对以找出最频繁的对。然而,每次合并后,只有那些与合并对重叠的对的计数会发生变化。因此,通过索引所有对的计数并增量更新这些计数,而不是显式地迭代每个字节对来计算对的频率,可以提高 BPE 训练的速度。通过这种缓存过程,你可以获得显著的速度提升,但我们注意到 BPE 训练的合并部分在 Python 中是不可并行化的。
Low-Resource/DownscalingTip:Profiling
你应该使用像cProfile或scalene这样的性能分析工具来识别你代码实现中的瓶颈,并专注于优化这些瓶颈。
Low-Resource/DownscalingTip: “Downscaling”
不要一开始就在完整的 TinyStories 数据集上训练你的分词器,我们建议你先在一小部分数据上训练:一个 “调试数据集”。例如,你可以在 TinyStories 验证集上训练你的分词器,验证集有 22K 个文档,而不是 2.12M 个。这说明了一种在可能的情况下缩减规模以加快开发速度的通用策略:例如,使用更小的数据集、更小的模型大小等。选择调试数据集的大小或超参数配置需要仔细考虑:你希望你的调试集足够大,以具有与完整配置相同的瓶颈(这样你所做的优化将具有通用性),但又不会太大以至于运行时间过长。
Problem(train_bpe):BPE Tokenizer Training (15points)
提交:编写一个函数,给定一个输入文本文件的路径,训练一个(字节级)BPE 分词器。你的 BPE 训练函数应该处理(至少)以下输入参数:input_path: str:BPE 分词器训练数据的文本文件路径。vocab_size: int:一个正整数,定义最终词汇表的最大大小(包括初始字节词汇表、合并产生的词汇项以及任何特殊标记)。special_tokens: list[str]:要添加到词汇表中的字符串列表。这些特殊标记在其他方面不影响 BPE 训练。
你的 BPE 训练函数应该返回生成的词汇表和合并:vocab: dict[int, bytes]:分词器词汇表,一个从整数(词汇表中的标记 ID)到字节(标记字节)的映射。merges: list[tuple[bytes, bytes]]:训练产生的 BPE 合并列表。每个列表项是一个字节元组(, ),表示与合并。合并应该按照创建的顺序排列。
为了根据我们提供的测试来测试你的 BPE 训练函数,你首先需要实现[adapters.run_train_bpe]处的测试适配器。然后,运行
uv run pytest tests/test_train_bpe.py
你的实现应该能够通过所有测试。(可选的,这可能需要大量时间投入,你可以使用某些系统语言实现训练方法的关键部分,例如 C++(可以考虑使用 cppyy)或 Rust(使用 PyO3))。如果你这样做,要注意哪些操作需要复制,哪些可以直接从 Python 内存读取,并确保留下构建说明,或者确保只使用pyproject.toml进行构建。还要注意,GPT-2 正则表达式在大多数正则表达式引擎中支持不佳,并且在大多数支持的引擎中速度也很慢。我们已经证实 Oniguruma 速度相当快,并且支持负向先行断言,但 Python 中的regex包(如果有的话)甚至更快。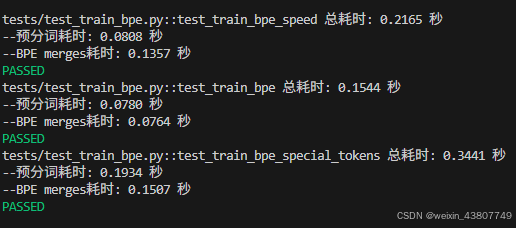
Problem(train_bpe_tinystories):BPE Training on TinyStories (2points)
(a)在 TinyStories 数据集上训练一个字节级 BPE 分词器,使用最大词汇表大小为 10,000。确保将 TinyStories 的<lendoftext|>特殊标记添加到词汇表中。将生成的词汇表和合并序列化保存到磁盘以便进一步检查。训练花费了多少小时和内存?词汇表中最长的token是什么?这合理吗?
资源要求: ≤30 分钟(无 GPU),≤30GB 内存
提示: 使用预标记化期间的multiprocessing以及以下两个事实,你应该能够在 2 分钟内完成 BPE 训练:
(a) <lendoftext|>标记分隔数据文件中的文档。
(b) 在应用 BPE 合并之前,<lendoftext|>标记被作为特殊情况处理。
答:训练花费约53秒。词汇表中最长的token是’accomplishment’和其他长度等于14的组合。看起来挺合理。这里我写的统计子词函数,存在空格识别错误。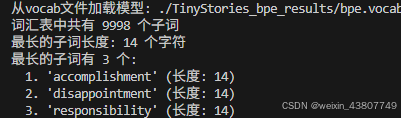
(b)分析你的代码。分词器训练过程中哪个部分最耗时?
答:预分词最耗时。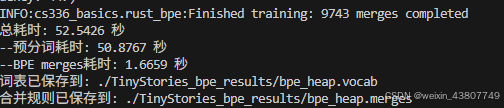
接下来,我们将尝试在 OpenWebText 数据集上训练一个字节级 BPE 分词器。和之前一样,我们建议你先了解一下这个数据集,以便更好地理解其内容。
Problem(train_bpe_expts_owt):BPE Training on TinyStories (2points)
(a)在 OpenWebText 数据集上训练一个字节级 BPE 分词器,使用最大词汇表大小为 32,000。将生成的词汇表和合并序列化到磁盘以便进一步检查。词汇表中最长的标记是什么?这合理吗?
资源要求:≤12 小时(无 GPU),≤100GB 内存
答:对于owt_train.txt文件,共花费24029秒训练完毕。
[2026.03.25更新] 参考nanochat代码,采用了heap进行bpe训练,速度大幅度提升,只需要764秒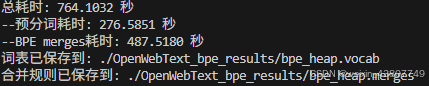
(b)对比在 TinyStories 和 OpenWebText 上训练得到的分词器。
2.6 BPE Tokenizer: Encoding and Decoding
在作业的前一部分,我们实现了一个函数,在输入文本上训练 BPE 分词器,以获得分词器词汇表和 BPE 合并列表。现在,我们将实现一个 BPE 分词器,它加载提供的词汇表和合并列表,并使用它们将文本编码为token IDs 以及将token IDs 解码为文本。
2.6.1 Encoding text
BPE 对文本的编码过程与我们训练 BPE 词汇表的过程相似。主要有几个步骤。
步骤 1:Pre-tokenize。我们首先对序列进行预标记化,并将每个预标记表示为 UTF-8 字节序列,就像我们在 BPE 训练中所做的那样。我们将在每个预标记内将这些字节合并为词汇表元素,独立处理每个预标记(不会跨预标记边界进行合并)。
步骤 2:Apply the merges。然后,我们获取 BPE 训练期间创建的词汇表元素合并列表,并按照创建顺序将其应用于我们的预标记。
示例(bpe_encoding):BPE 编码示例
例如,假设我们的输入字符串是“the cat ate”,我们的词汇表是[0: b'', 1: b'a', 2: b'c', 3: b'e', 4: b'h', 5: b't', 6: b'th', 7: b'c', 8: b'a', 9: b'the', 10: b' at'],我们学到的合并是[(b't', b'h'), (b' ', b'c'), (b' ', 'a'), (b'th', b'e'), (b'a', b't')]。首先,我们的pre-tokenizer会将这个字符串分割为['the', 'cat', 'ate']。然后,我们查看每个预标记并应用BPE合并。
第一个预标记“the”最初表示为[b't', b'h', b'e']。查看我们的合并列表,我们确定第一个适用的合并是(b't', b'h'),并使用它将预标记转换为[b'th', b'e']。然后,我们回到合并列表,确定下一个适用的合并是(b'th', b'e'),将预标记转换为[b'the']。最后,再看合并列表,没有更多适用于该字符串的合并了(因为整个预标记已经合并为一个标记),所以我们完成了BPE合并的应用。相应的整数序列是[9]。
对其余pre-tokens重复此过程,我们看到预标记“ cat”在应用BPE合并后表示为[b'c', b'a', b't'],对应的整数序列是[7, 1, 5]。最后一个预标记“ ate”在应用BPE合并后是[b' at', b'e'],对应的整数序列是[10, 3]。因此,我们输入字符串的最终编码结果是[9, 7, 1, 5, 10, 3]。
特殊标记
你的tokenizer在编码文本时应该能够正确处理用户定义的特殊标记(在构建分词器时提供)。
内存考虑
假设我们想要对一个无法放入内存的大文本文件进行分词。为了高效地对这个大文件(或任何其他数据流)进行分词,我们需要将其分解为可管理的块,并依次处理每个块,这样内存复杂度就是恒定的,而不是与文本大小成线性关系。在这样做时,我们需要确保一个标记不会跨越块边界,否则我们会得到与在内存中对整个序列进行分词的朴素方法不同的分词结果。
2.6.2 Decoding text
要将整数token ID序列解码回原始文本,我们只需在词汇表中查找每个ID对应的条目(一个字节序列),将它们连接在一起,然后将这些字节解码为Unicode字符串。请注意,输入ID不一定映射到有效的Unicode字符串(因为用户可以输入任何整数ID序列)。如果输入的标记ID不能生成有效的Unicode字符串,你应该用官方的Unicode替换字符U+FFFD替换格式错误的字节(关于 Unicode 替换字符的更多信息,可参见维基百科页面en.wikipedia.org/wiki/Specials_(Unicode_block)#Replacement_character)。bytes.decode的errors参数控制如何处理Unicode解码错误,使用errors='replace'将自动用替换标记替换格式错误的数据。
Problem(tokenizer):实现分词器(15分)
提交物:实现一个Tokenizer类,给定一个词汇表和一个合并列表,将文本编码为整数ID,并将整数ID解码为文本。你的分词器还应该支持用户提供的特殊标记(如果它们还不在词汇表中,则将它们添加到词汇表中)。我们建议采用以下接口:
def __init__(self, vocab, merges, special_tokens=None)
从给定的词汇表、合并列表和特殊标记列表构造一个分词器。这个函数应该接受以下参数:
vocab: dict[int, bytes]merges: list[tuple[bytes, bytes]]special_tokens: list[str] | None = None
def from_files(cls, vocab_filepath, merges_filepath, special_tokens=None)
用于从序列化的词汇表和合并列表(与您的 BPE 训练代码输出的格式相同)构建并返回一个分词器,并包含特殊标记列表。此方法应接受以下参数:
vocab_filepath: strmerges_filepath: strspecial_tokens: list[str] | None = None
def encode(self, text: str)-> list[int] 将输入文本编码为一系列的标记ID。
def encode_iterable(self, iterable:Iterable[str])->Iterator[int]
给定一个字符串的可迭代对象(例如,Python 文件句柄),返回一个惰性生成标记 ID 的生成器。
这对于无法直接加载到内存中的大文件的内存高效分词是必需的
def decode(self, ids:list[int])-> str 将一串令牌ID解码为文本。
要使用我们提供的测试来测试你的分词器,你首先需要在 [adapters.get_tokenizer] 实现测试适配器。
然后,运行 `uv pytest tests/test_tokenizer.py`。你的实现应该能够通过所有测试。
笔者参考tiktoken源码完成了一个简化版,结果如下。其中黄色部分是在警告,Tokenizer.encode部分的内存需要优化。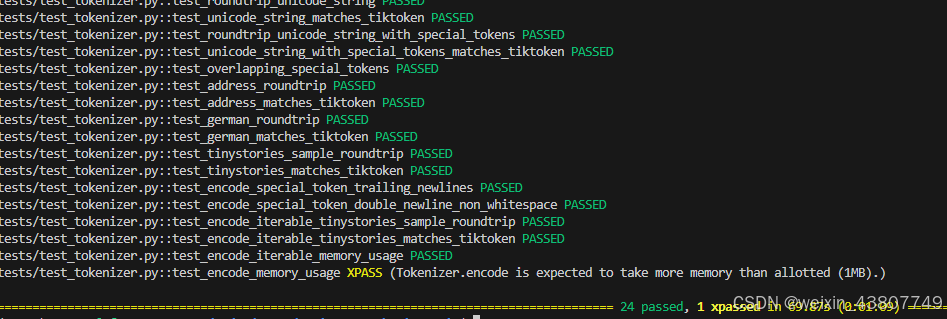
2.7 Experiments
Problem(tokenizer_experiments):分词器的实验
(a) 从 TinyStories 和 OpenWebText 中抽取 10 篇文档。使用你之前训练的 TinyStories 和 OpenWebText 分词器(分别为 10K 和 32K 词汇量),将这些抽取的文档编码为整数 ID。每个分词器的压缩比(字节/标记)是多少?
答: TinyStories的压缩比是:4.12; OpenWebText 的压缩比是:4.37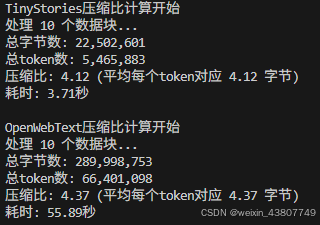
(b) 如果用 TinyStories 分词器对 OpenWebText 样本文档进行分词,会发生什么?比较压缩比或定性描述结果。
答:使用不同数据集测试,压缩比结果都会下降。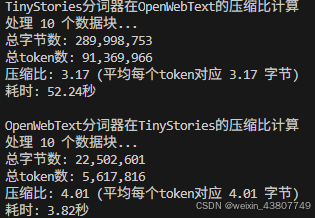
(c) 估算你的分词器的吞吐量(例如,每秒字节数)。将Pile数据集(825GB文本)进行分词大约需要多久?
答:吞吐量为 648053.14 bytes/second,
825 × 1024 3 bytes 648053.14 bytes/second ≈ 1.35 × 10 6 秒 \frac{825 \times 1024^3 \text{ bytes}}{648053.14 \text{ bytes/second}} \approx 1.35 \times 10^6 \text{ 秒} 648053.14 bytes/second825×10243 bytes≈1.35×106 秒
1.35 × 10 6 3600 ≈ 375 小时 ≈ 15.6 天 \frac{1.35 \times 10^6}{3600} \approx 375 \text{ 小时} \approx 15.6 \text{ 天} 36001.35×106≈375 小时≈15.6 天
(d) 使用你的TinyStories和OpenWebText分词器,将相应的训练和开发数据集编码为整数token ID序列。我们稍后将使用这些序列来训练语言模型。我们建议将token ID序列 序列化为NumPy的uint16数组。为什么uint16是合适的选择?
答:笔者编写了txt2memmap.py程序,将.txt文件中的文字转成id序列,并保存成memmap文件。uint16可以表示的最大整数是65535,大于这两个词汇表容量。
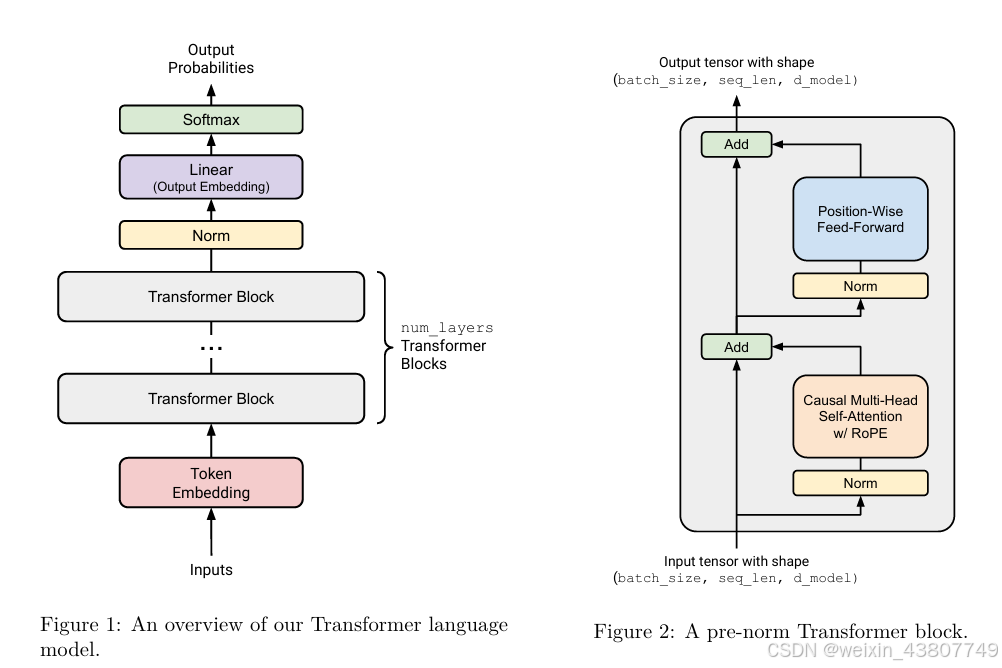
3 Transformer Language Model Architecture
语言模型接收一个批量的整数令牌ID序列作为输入(即形状为(batch_size, sequence_length)的torch.Tensor),并返回一个在词汇表上的(批量)归一化概率分布(即形状为(batch_size, sequence_length, vocab_size)的PyTorch张量),其中预测分布对应每个输入令牌的下一个单词。在训练语言模型时,利用这些下一词预测来计算实际下一词与预测下一词之间的交叉熵损失。推理阶段从语言模型生成文本时,我们取最后一个时间步(即序列中的最后一个元素)的预测下一词分布来生成序列中的下一个令牌(例如,选择概率最高的令牌、从分布中采样等方式),将生成的令牌添加到输入序列中,并重复此过程。
在本次作业的这一部分,你将从头开始构建这个Transformer语言模型。我们将首先对模型进行高层描述,然后逐步详述各个组件。
3.1 Transformer LM
给定 token IDs 序列,Transformer 语言模型通过输入嵌入将 token IDs 转换为稠密向量,将嵌入后的令牌传递过 num_layers 个 Transformer 块,然后应用一个习得的线性投影(“output embedding” 或 “LM head”)来生成预测的下一个令牌对数几率。示意图见图 1。
3.1.1 Token Embeddings
在第一步中,Transformer 将(批量)sequence of token IDs 嵌入为包含令牌本身信息的向量序列(图 1 中的红色块)。
更具体地说,给定令牌 ID 序列,Transformer 语言模型通过 token embedding layer生成向量序列。每个 embedding layer 接收形状为(batch_size,sequence_length)的整数张量,并输出形状为(batch_size,sequence_length,d_model)的向量序列。
3.1.2 Pre-norm Transformer Block
嵌入之后,激活值会经过多个结构相同的神经网络层处理。标准的 decoder-only Transformer 语言模型由 num_layers 个相同的层(通常称为 Transformer “blocks”)组成。每个 Transformer block 接收形状为(batch_size, sequence_length, d_model)的输入,并返回形状相同的输出。每个块通过 self-attention 聚合序列中的信息,并通过 feed-forward layers 进行非线性变换。
3.2 Output Normalization and Embedding
经过 num_layers 个 Transformer 块后,我们将获取最终的激活值,并将其转换为词汇表上的分布。
我们将实现 “pre-norm” Transformer 块(详见 3.5 节),这还需要在最后一个 Transformer 块之后使用 layer normalization(详见下文),以确保其输出得到适当缩放。
完成此归一化后,我们将使用标准的、学习所得的线性变换,将 Transformer 块的输出转换为预测的下一个token对数几率(参见 Radford 等人 [2018] 的公式 2)。
3.3 Remark: Batching, Einsum and Efficient Computation
在整个 Transformer 中,我们会对多个批量形式(batch-like)的输入执行相同的计算。以下是一些示例:
- 批量元素:对每个 batch element 应用相同的 Transformer 前向传播操作。
- 序列长度:诸如 RMS 归一化(RMSNorm)和前馈网络等 “position-wise” 操作,对序列的每个位置执行相同的运算。
- 注意力头:在 “多头” 注意力操作中,attention operation 会在多个注意力头上进行批量处理。
需要一种便捷的方式来执行此类操作,既要充分利用 GPU,又要易于阅读和理解。许多PyTorch 操作可以接收张量开头的 “batch-like” 维度,并在这些维度上高效地执行 重复 / 广播操作。
例如,假设要执行 position-wise 的批量操作。我们有一个形状为 (batch_size, sequence_length, d_model) 的 “data tensor” D,想要对形状为 (d_model, d_model) 的矩阵 A 执行 batched vector-matrix multiply。在这种情况下,D @ A 会执行批量矩阵乘法,这是 PyTorch 中的高效原语,其中 (batch_size, sequence_length) 维度会被批量处理。
因此,最好假设你的函数可能会接收额外的 batch-like 维度,并将这些维度保留在 PyTorch 张量形状的开头。为了使张量能够以这种方式进行批处理,你可能需要通过多次调用 view、reshape 和 transpose 来调整其形状。这样做有时会相当麻烦,而且代码往往变得难以阅读,让人难以理解其具体操作以及张量的实际形状。
一种更便捷的选择是使用 torch.einsum 中的爱因斯坦求和(einsum)记号,或者更进一步,使用与框架无关的库,例如 einops 或 einx。其中两个关键操作是:
- einsum:可以对输入张量的任意维度执行张量缩并(tensor contraction);
- rearrange:可以对任意维度进行重排、拼接和拆分。
事实证明,机器学习中的几乎所有操作,本质上都是维度操作(dimension juggling)与张量缩并的某种组合,并偶尔辅以(通常是逐元素的)非线性函数。这意味着,当你使用 einsum 记号时,你的大量代码可以变得更加清晰易读且灵活。
我们强烈建议你在本课程中学习并使用 einsum。之前未接触过 einsum 符号的学生应使用 einops(文档点击原pdf的链接),而已经熟悉 einops 的学生应学习更通用的 einx(文档点击原pdf的链接)。这两个库都已安装在我们提供的环境中。
值得注意的是,尽管 einops 有广泛的支持,但 einx 的成熟度较低。如果发现 einx 存在限制或漏洞,你可以转而使用 einops 并结合一些原生 PyTorch 操作。
以下给出一些 einsum 符号的使用示例。这些示例是对 einops 文档的补充,你应先阅读该文档。
示例(einstein_example1):使用 einops.einsum 进行批量矩阵乘法
import torch
from einops import rearrange, einsum
# 基础实现
Y = D @ A.T
# 难以判断输入输出形状及其含义
# D和A可以是什么形状?是否存在意外行为?
# einsum具有自文档化特性且稳健
Y = einsum(D, A, "batch sequence d_in, d_out d_in -> batch sequence d_out")
# 或支持批量处理的版本,其中D可具有任意前导维度,但A的形状固定
Y = einsum(D, A, "... d_in, d_out d_in -> ... d_out")
示例(einstein_example2):使用 einops.rearrange 进行广播操作
我们有一批图像,想要为每个图像生成 10 个基于某个缩放因子的变暗版本:
images = torch.randn(64, 128, 128, 3) # 形状:(批量大小,高度,宽度,通道数)
dim_by = torch.linspace(start=0.0, end=1.0, steps=10)
# 调整形状并相乘
dim_value = rearrange(dim_by, "dim_value -> 1 dim_value 1 1 1")
images_rearr = rearrange(images, "b height width channel -> b 1 height width channel")
dimmed_images = images_rearr * dim_value
# 或一步完成
dimmed_images = einsum(images, dim_by, "batch height width channel, dim_value -> batch dim_value height width channel")
示例(einstein_example3):使用 einops.rearrange 进行像素混合
假设我们有一批图像,用形状为(批量大小,高度,宽度,通道数)的张量表示,想要对图像的所有像素执行线性变换,但该变换需对每个通道独立进行。我们的线性变换用形状为(高度 × 宽度,高度 × 宽度)的矩阵 B 表示。
channels_last = torch.randn(64, 32, 32, 3) # 形状:(批量大小,高度,宽度,通道数)
B = torch.randn(32*32, 32*32)
# 调整图像张量形状以进行所有像素的混合
channels_last_flat = channels_last.view(-1, channels_last.size(1) * channels_last.size(2), channels_last.size(3))
channels_first_flat = channels_last_flat.transpose(1, 2)
channels_first_flat_transformed = channels_first_flat @ B.T
channels_last_flat_transformed = channels_first_flat_transformed.transpose(1, 2)
channels_last_transformed = channels_last_flat_transformed.view(*channels_last.shape)
改用 einops 实现:
height = width = 32
# rearrange替代繁琐的torch view + transpose
channels_first = rearrange(channels_last, "batch height width channel -> batch channel (height width)")
channels_first_transformed = einsum(channels_first, B, "batch channel pixel_in, pixel_out pixel_in -> batch channel pixel_out")
channels_last_transformed = rearrange(channels_first_transformed, "batch channel (height width) -> batch height width channel", height=height, width=width)
或者,更简洁的方式:使用 einx.dot(einops.einsum 的 einx 等效函数)一步完成
height = width = 32
channels_last_transformed = einx.dot(
channels_last, B,
"batch row_in col_in channel, (row_out col_out) (row_in col_in) -> batch row_out col_out channel",
col_in=width, col_out=width
)
第一个实现可以通过在前后添加注释来说明输入输出形状,但这种方式既繁琐又容易出错。使用 einsum 符号时,代码本身就是文档!
einsum 符号可以处理任意输入批量维度,且具有自文档化的核心优势。使用 einsum 符号的代码中,输入输出张量的相关形状会清晰得多。对于其余张量,你可以考虑使用张量类型提示,例如使用 jaxtyping 库(并非 Jax 专属)。
将在作业 2 中详细讨论使用 einsum 符号的性能影响,目前你只需知道它几乎总是优于其他替代方案!
3.3.1 Mathematical Notation and Memory Ordering
许多机器学习论文在符号表示中使用行向量,这与 NumPy 和 PyTorch 默认使用的行优先内存顺序非常契合。对于行向量,线性变换可表示为:
y = x W ⊤ ( 1 ) y=xW^{\top } \quad (1) y=xW⊤(1)
其中, W ∈ R d o u t × d i n W \in \mathbb{R}^{d_{out } ×d_{in }} W∈Rdout×din 为行优先存储的矩阵, x ∈ R 1 × d i n x \in \mathbb{R}^{1 ×d_{in }} x∈R1×din 为行向量。
在线性代数中,更常见的是使用列向量,此时线性变换表示为:
y = W x ( 2 ) y=Wx \quad (2) y=Wx(2)
其中, W ∈ R d o u t × d i n W \in \mathbb{R}^{d_{out } ×d_{in }} W∈Rdout×din 为行优先存储的矩阵, x ∈ R d i n x \in \mathbb{R}^{d_{in }} x∈Rdin为列向量。本作业的数学符号将使用列向量,因为这样更易于理解数学推导。你需要注意,若要使用原生矩阵乘法符号,由于PyTorch采用行优先内存顺序,必须按照行向量约定应用矩阵。若使用einsum执行矩阵操作,则无需担心这一问题。
3.4 Basic Building Blocks: Linear and Embedding Modules
3.4.1 Parameter Initialization
要有效训练神经网络,通常需要仔细初始化模型参数——糟糕的初始化可能导致梯度消失或梯度爆炸等不良现象。预归一化Transformer对初始化的鲁棒性较强,但初始化仍会对训练速度和收敛性产生显著影响。由于本作业已较长,我们将在作业3中详细介绍参数初始化,此处提供一些适用于大多数情况的近似初始化方法。目前,请使用以下初始化方式:
- Linear weights:服从均值为0、方差为 2 d i n + d o u t \frac{2}{d_{in }+d_{out }} din+dout2的截断正态分布,截断范围为 [ − 3 σ , 3 σ ] [-3 \sigma, 3 \sigma] [−3σ,3σ]
- 嵌入层:服从均值为0、方差为1的截断正态分布,截断范围为[-3, 3]
- RMS归一化(RMSNorm):初始化为1
你应使用 torch.nn.init.trunc_normal_来初始化截断正态分布的权重。
3.4.2 Linear Module
线性层是 Transformer 乃至整个神经网络的基本构建块。首先,你需要实现自己的 Linear 类,该类继承自 torch.nn.Module,用于执行线性变换:
y = W x ( 3 ) y=Wx \quad (3) y=Wx(3)
注意,遵循大多数现代大语言模型的设计,我们不包含偏置项。
Problem(linear): Implementing the linear module (1 point)
交付要求:实现一个继承自torch.nn.Module的Linear类,用于执行线性变换。实现需遵循PyTorch内置nn.Linear模块的接口,但不包含偏置(bias)参数。建议接口如下:
def __init__(self, in_features, out_features, device=None, dtype=None):构造线性变换模块,接收输入维度(in_features)、输出维度(out_features)、参数存储设备(device)和数据类型(dtype)。def forward(self, x: torch.Tensor) -> torch.Tensor:对输入执行线性变换。
注意事项:
- 继承
nn.Module - 调用父类构造函数。
- 将参数构造并存储为 W W W(而非 W ⊤ W^{\top} W⊤)以优化内存排序,封装为
nn.Parameter。 - 禁止使用
nn.Linear或nn.functional.linear。
权重初始化使用torch.nn.init.trunc_normal_。
测试方法:在[adapters.run_linear]处实现测试适配器,通过Module.load_state_dict加载给定权重,运行uv run pytest -k test_linear进行测试。
3.4.3 Embedding Module
Transformer的第一层是embedding layer,用于将整数token ID映射到维度为d_model的向量空间。需实现自定义Embedding类(继承自torch.nn.Module,禁止使用nn.Embedding)。forward方法应通过使用形状为(batch_size, sequence_length)的torch.LongTensor张量索引形状为(vocab_size, d_model)的嵌入矩阵,来选取每个token ID对应的嵌入向量。
Problem(embedding): Implement the embedding module (1point)
交付要求:实现嵌入查找功能的Embedding类,遵循PyTorch内置nn.Embedding接口。建议接口如下:
def __init__(self, num_embeddings, embedding_dim, device=None, dtype=None):构造嵌入模块,接收词汇表大小(num_embeddings)、嵌入向量维度(embedding_dim,即d_model)、参数存储设备(device)和数据类型(dtype)。def forward(self, token_ids: torch.Tensor) -> torch.Tensor:为输入token ID查找对应的嵌入向量。
注意事项:
- 继承
nn.Module - 调用父类构造函数。
- 将嵌入矩阵初始化为
nn.Parameter, d_model为最终维度。- 禁止使用
nn.Embedding或nn.functional.embedding。
权重初始化使用torch.nn.init.trunc_normal_。
测试方法:在[adapters.run_embedding]处实现测试适配器,运行uv run pytest -k test_embedding进行测试。
3.5 Pre-Norm Transformer Block
每个Transformer block 包含两个子层:多头自注意力机制和position-wise feed-forward network(Vaswani等人,2017,第3.1节)。
原始Transformer论文中,使用“后归一化(post-norm)”架构:每个子层周围添加残差连接,随后进行 layer normalization。但后续研究表明,将层归一化移至每个子层的输入(with an additional layer normalization after the final Transformer block)可提升训练稳定性(Nguyen和Salazar,2019;Xiong等人,2020),此即“预归一化(pre-norm)”架构(见图2)。每个子层的输出通过残差连接与子层输入相加(Vaswani等人,2017,第5.4节)。预归一化的核心优势是存在一条无归一化干扰的“残差流”,可优化梯度传播,目前已成为主流语言模型(如GPT-3、LLaMA、PaLM)的标准架构,以下将逐步实现其组件。
3.5.1 Root Mean Square Layer Normalization 均方根层归一化
原始Transformer使用层归一化(Ba等人,2016),本文遵循Touvron等人(2023)的方案,采用均方根层归一化(RMSNorm;Zhang和Sennrich,2019,公式4)。给定a vector a ∈ R d m o d e l a \in \mathbb{R}^{d_{model}} a∈Rdmodel of activations,RMSNorm对每个元素 a i a_i ai的缩放公式如下:
R M S N o r m ( a i ) = a i R M S ( a ) g i ( 4 ) RMSNorm\left(a_{i}\right)=\frac{a_{i}}{RMS(a)} g_{i} \quad (4) RMSNorm(ai)=RMS(a)aigi(4)
其中 R M S ( a ) = 1 d m o d e l ∑ i = 1 d m o d e l a i 2 + ε RMS(a)=\sqrt{\frac{1}{d_{model }} \sum_{i=1}^{d_{model }} a_{i}^{2}+\varepsilon} RMS(a)=dmodel1∑i=1dmodelai2+ε。 g i g_i gi是可学习的“增益”参数(共 d m o d e l d_{model} dmodel个), ε \varepsilon ε为数值稳定性超参数(通常设为1e-5)。
实现时需先将输入上采样至torch.float32以避免平方运算溢出,前向传播流程如下:
in_dtype = x.dtype
x = x.to(torch.float32)
# 此处实现RMSNorm逻辑
result = ...
# 转回原始数据类型返回
return result.to(in_dtype)
Problem (rmsnorm): Root Mean Square Layer Normalization (1 point)
交付要求:实现RMSNorm类(继承自torch.nn.Module),建议接口如下:
def __init__(self, d_model: int, eps: float = 1e-5, device=None, dtype=None):构造模块,接收模型隐藏维度(d_model)、数值稳定性参数(eps)、设备(device)和数据类型(dtype)。def forward(self, x: torch.Tensor) -> torch.Tensor:处理形状为(batch_size, sequence_length, d_model)的输入张量,返回相同形状的输出。
测试方法:在[adapters.run_rmsnorm]处实现测试适配器,运行uv run pytest -k test_rmsnorm进行测试。
3.5.2 Position-Wise Feed-Forward Network
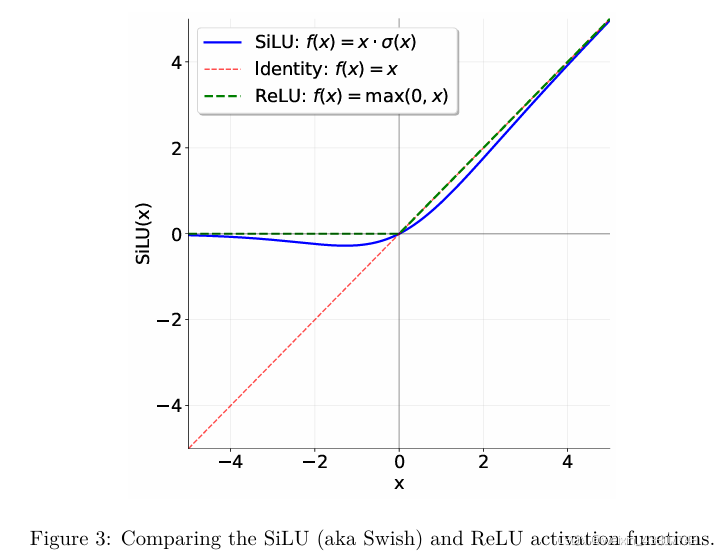
Transformer原论文中的 feed-forward network 包含两个线性变换,中间用到的是ReLU激活函数 ( R e L U ( x ) = m a x ( 0 , x ) ) (ReLU(x)=max(0,x)) (ReLU(x)=max(0,x)),前馈网络中间层的维度通常是输入维度的4倍。(Vaswani等人,2017,第3.3节)。
现代语言模型对此做了两项优化:替换激活函数并引入门控机制。本文将实现SwiGLU激活函数(被Llama 3、Qwen 2.5等LLM采用),其结合了SiLU(又称Swish)激活与门控线性单元(GLU);同时参考PaLM、LLaMA等模型,省略线性层中的偏置项。
-
SiLU/Swish激活函数(Hendrycks和Gimpel,2016;Elfwing等人,2017):
S i L U ( x ) = x ⋅ σ ( x ) = x 1 + e − x ( 5 ) SiLU(x)=x \cdot \sigma(x)=\frac{x}{1+e^{-x}} \quad (5) SiLU(x)=x⋅σ(x)=1+e−xx(5)
该函数与ReLU类似,但在零点处更平滑(见图3)。 -
门控线性单元(GLU;Dauphin等人,2017):线性变换经sigmoid激活后,与另一线性变换执行逐元素乘法:
G L U ( x , W 1 , W 2 ) = σ ( W 1 x ) ⊙ W 2 x ( 6 ) GLU\left(x, W_{1}, W_{2}\right)=\sigma\left(W_{1} x\right) \odot W_{2} x \quad (6) GLU(x,W1,W2)=σ(W1x)⊙W2x(6)
其中 ⊙ \odot ⊙表示逐元素乘法。GLU通过保留线性梯度路径并维持非线性能力,缓解深度架构的梯度消失问题。 -
SwiGLU前馈网络:结合SiLU与GLU,公式如下:
F F N ( x ) = S w i G L U ( x , W 1 , W 2 , W 3 ) = W 2 ( S i L U ( W 1 x ) ⊙ W 3 x ) ( 7 ) FFN(x)=SwiGLU(x,W_{1},W_{2},W_{3})=W_{2}(SiLU(W_{1}x)\odot W_{3}x) \quad (7) FFN(x)=SwiGLU(x,W1,W2,W3)=W2(SiLU(W1x)⊙W3x)(7)
其中 x ∈ R d m o d e l x \in \mathbb{R}^{d_{model}} x∈Rdmodel, W 1 、 W 3 ∈ R d f f × d m o d e l W_1、W_3 \in \mathbb{R}^{d_{ff}×d_{model}} W1、W3∈Rdff×dmodel, W 2 ∈ R d m o d e l × d f f W_2 \in \mathbb{R}^{d_{model}×d_{ff}} W2∈Rdmodel×dff,标准设置为 d f f = 8 3 d m o d e l d_{ff}=\frac{8}{3}d_{model} dff=38dmodel。
Shazeer(2020)首次提出SiLU与GLU的结合方案,实验表明SwiGLU在语言建模任务上优于ReLU、SiLU(无门控)等基线模型。后续任务中需对比SwiGLU与SiLU的性能。尽管我们已提及支持这些组件的若干启发式论证(相关论文也提供了更多佐证),但保持实证视角尤为重要:论文中有一句广为流传的引用:“我们无意解释这些架构为何有效;与其归因于其他因素,我们更愿将其成功归于神之恩典。”
Problem (positionwise_feedforward): Implement the position-wise feed-forward network
(2points)
交付要求:实现基于SwiGLU的 feed-forward network。
- 可使用
torch.sigmoid保证数值稳定性。 - 内层维度 d f f d_{ff} dff设为 8 3 × d m o d e l \frac{8}{3}×d_{model} 38×dmodel。确保 inner feed-forward layer的维度是64的倍数,以充分利用你的硬件。
在[adapters.run_swiglu]处实现测试适配器,运行uv run pytest -k test_swiglu进行测试。
3.5.3 Relative Positional Embeddings
问题背景
输入一句话,S=“欢迎光临@helloworld🙃”,先经过tokenzier 转成 encoded_ids: [230, 172, 162, 232, 191, 142, 229, 133, 137, 228, 184, 180, 64, 258, 1217, 304, 340, 240, 159, 153, 131],然后通过Token Embeddings 层转成:[批次大小, 序列长度, 词向量维度] 格式,才能进行计算。假如,批次大小是1,序列长度是21,词向量维度是4的话,可以记作 X :
直接将X输入到自注意力层得到的输出是不包含语序信息的,也就是说,我把encoded_ids: [230, 172, 162, …]换成[172, 162, 230, …] 得到的计算结果是一样的。因此考虑加入语序信息。
更详细的解释可访问:十分钟读懂旋转编码(RoPE) - 绝密伏击的文章 - 知乎
https://zhuanlan.zhihu.com/p/647109286
回到作业中
为注入位置信息,我们将实现旋转位置嵌入(RoPE;Su等人,2021)。对于位置为 i i i的query token q ( i ) = W q x ( i ) ∈ R d q^{(i)}=W_q x^{(i)} \in \mathbb{R}^d q(i)=Wqx(i)∈Rd,通过应用成对旋转矩阵 R i R^i Ri,可得到 q ′ ( i ) = R i q ( i ) = R i W q x ( i ) q^{\prime(i)}=R^i q^{(i)}=R^i W_q x^{(i)} q′(i)=Riq(i)=RiWqx(i)。
R i R^i Ri会将嵌入元素对 q 2 k − 1 : 2 k ( i ) q^{(i)}_{2k-1:2k} q2k−1:2k(i)作为二维向量,按角度 θ i , k = i Θ ( 2 k − 1 ) / d \theta_{i,k}=\frac{i}{\Theta^{(2k-1)/d}} θi,k=Θ(2k−1)/di进行旋转(其中 k ∈ { 1 , . . . , d / 2 } k \in \{1,...,d/2\} k∈{1,...,d/2}, Θ \Theta Θ为某个常数)。因此,我们可将 R i R^i Ri视为一个 d × d d × d d×d的块对角矩阵,包含对应 k ∈ { 1 , . . . , d / 2 } k \in \{1,...,d/2\} k∈{1,...,d/2}的块 R k i R_k^i Rki,其中:
R k i = [ cos ( θ i , k ) − sin ( θ i , k ) sin ( θ i , k ) cos ( θ i , k ) ] ( 8 ) R_k^i=\begin{bmatrix} \cos(\theta_{i,k}) & -\sin(\theta_{i,k}) \\ \sin(\theta_{i,k}) & \cos(\theta_{i,k}) \end{bmatrix} \quad (8) Rki=[cos(θi,k)sin(θi,k)−sin(θi,k)cos(θi,k)](8)
由此得到完整的旋转矩阵:
R i = [ R 1 i 0 . . . 0 0 R 2 i . . . 0 ⋮ ⋮ ⋱ ⋮ 0 0 . . . R d / 2 i ] ( 9 ) R^i=\begin{bmatrix} R_1^i & 0 & ... & 0 \\ 0 & R_2^i & ... & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & ... & R_{d/2}^i \end{bmatrix} \quad (9) Ri= R1i0⋮00R2i⋮0......⋱...00⋮Rd/2i (9)
式中,0代表2×2的零矩阵。
实现要点:
- 无需构造完整(d×d)矩阵,可利用矩阵性质优化计算效率。
- 由于我们只关心给定序列中tokens的相对旋转,可以在各层和不同批次中重复使用 c o s ( θ i , k ) cos(\theta_{i,k}) cos(θi,k)和 s i n ( θ i , k ) sin(\theta_{i,k}) sin(θi,k)的计算结果。
- 优化方案:所有层共享一个RoPE模块,通过
self.register_buffer(persistent=False)在初始化时预计算sin/cos值(2D缓冲区),而非使用nn.Parameter(因无需学习这些固定值)。 - 对键token k ( j ) k^{(j)} k(j)执行相同旋转流程,应用对应矩阵 R j R^j Rj。
- 该层无任何可学习参数。
Problem(rope): Implement RoPE (2points)
交付物:实现一个 RotaryPositionalEmbedding 类,将RoPE应用于输入张量。建议采用以下接口:
def __init__(self, theta: float, d_k: int, max_seq_len: int, device=None):构建RoPE模块,必要时创建缓冲区。theta:float 类型,RoPE的Θ值。d_k:int 类型,查询向量和键向量的维度。max_seq_len:int 类型,输入的最大序列长度。device:torch.device | None = None,存储缓冲区的设备。
def forward(self, x: torch.Tensor, token_positions: torch.Tensor) -> torch.Tensor:处理形状为(…, seq_len, d_k)的输入张量,返回相同形状的张量。- 需兼容任意数量批次维度的输入x。
- 假设
token_positions是形状为(…, seq_len)的张量,指定x在序列维度上的token位置。 - 需使用token位置对(可能预计算的)cos和sin张量沿序列维度进行切片。
测试方法:完成 [adapters.run_rope],确保通过 uv run pytest -k test_rope 测试。
3.5.4 Scaled Dot-Product Attention
我们将按照Vaswani等人[2017]的描述(3.2.1节)实现缩放点积注意力。作为前置步骤,注意力操作的定义将用到softmax函数——该函数接收未归一化的得分向量,输出归一化的概率分布:
s o f t m a x ( v ) i = e x p ( v i ) ∑ j = 1 n e x p ( v j ) . ( 10 ) softmax(v)_{i}=\frac{exp \left(v_{i}\right)}{\sum _{j=1}^{n} exp \left(v_{j}\right) } . (10) softmax(v)i=∑j=1nexp(vj)exp(vi).(10)
注意,当 ( v i v_{i} vi) 取值较大时, e x p ( v i ) exp \left(v_{i}\right) exp(vi) 可能溢出为无穷大(此时 inf / inf = N a N \inf / \inf = NaN inf/inf=NaN)。可利用softmax的不变性(对所有输入加任意常数c不改变结果)解决该问题,提升数值稳定性——通常会从 o i o_i oi 的所有元素中减去其最大值,使新的最大值为0。请基于该技巧实现softmax函数,确保数值稳定性。
Problem(softmax): Implement softmax (1point)
交付物:编写一个函数,对张量应用softmax操作。
- 输入参数:张量和维度i。
- 功能:对输入张量的第i维应用softmax,输出形状与输入一致,且第i维为归一化的概率分布。
- 要求:使用“减去第i维最大值”的技巧避免数值稳定性问题。
测试方法:完成 [adapters.run_softmax],确保通过 uv run pytest -k test_softmax_matches_pytorch 测试。
缩放点积注意力的数学定义如下:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q ⊤ K d k ) V (11) Attention(Q, K, V)=softmax\left(\frac{Q^{\top} K}{\sqrt{d_{k}}}\right) V \tag{11} Attention(Q,K,V)=softmax(dkQ⊤K)V(11)
其中 ( Q ∈ R n × d k Q \in \mathbb{R}^{n ×d_{k}} Q∈Rn×dk)、( K ∈ R m × d k K \in \mathbb{R}^{m ×d_{k}} K∈Rm×dk)、( V ∈ R m × d v V \in \mathbb{R}^{m ×d_{v}} V∈Rm×dv)。Q、K、V均为输入(非可学习参数)。关于为何不使用 Q K ⊤ Q K^{\top} QK⊤,详见3.3.1节。
掩码机制 Masking
有时需要对注意力操作的输出进行掩码。掩码矩阵 M ∈ { T r u e , F a l s e } n × m M \in \{True, False\}^{n ×m} M∈{True,False}n×m 的每行 i i i表示查询 i i i可关注的键。标准定义(略有歧义)为:位置 ( i , j ) (i, j) (i,j)为True时,查询 i i i可关注键 j j j;为False时则不可关注,即“信息仅在True对应的 ( i , j ) (i, j) (i,j)位置流动”。例如,掩码矩阵 [[True, True, False]] 表示单个查询向量仅关注前两个键。
从计算效率来看,掩码机制比对子序列计算注意力更高效。实现方式为:在softmax之前的得分矩阵 ( Q ⊤ K d k ) \left(\frac{Q^{\top} K}{\sqrt{d_{k}}}\right) (dkQ⊤K) 中,将掩码为False的位置设为 −∞。
Problem (scaled_dot_product_attention): Implement scaled dot-product attention (5 points)
交付物:实现缩放点积注意力函数。
- 输入要求:
- 查询(Q)和键(K)的形状为(batch_size, …, seq_len, d_k)。
- 值(V)的形状为(batch_size, …, seq_len, d_v)。
- 其中“…”表示任意数量的其他批次类维度(若有)。
- 输出形状:(batch_size, …, d_v)。
- 掩码支持:可选接收形状为(seq_len, seq_len)的布尔掩码。掩码为True的位置,注意力概率之和为1;掩码为False的位置,注意力概率为0。
测试方法:完成 [adapters.run_scaled_dot_product_attention] 测试适配器。
uv run pytest -k test_scaled_dot_product_attention:测试三阶输入张量。uv run pytest -k test_4d_scaled_dot_product_attention:测试四阶输入张量。
3.5.5 Causal Multi-Head Self-Attention
按照Vaswani等人[2017]的3.2.2节描述实现多头自注意力。其数学定义如下:
MultiHead ( Q , K , V ) = Concat ( head 1 , … , head h ) (12) \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h) \tag{12} MultiHead(Q,K,V)=Concat(head1,…,headh)(12)
for head i = Attention ( Q i , K i , V i ) (13) \text{for } \text{head}_i = \text{Attention}(Q_i, K_i, V_i) \tag{13} for headi=Attention(Qi,Ki,Vi)(13)
其中 Q i Q_{i} Qi、 K i K_{i} Ki、 V i V_{i} Vi 分别是Q、K、V在嵌入维度上的第i个切片 ( i ∈ { 1 , . . . , h } ) (i \in \{1, ..., h\}) (i∈{1,...,h}),切片大小对应 (d_k)(Q、K)或 (d_v)(V),Attention为3.5.4节定义的缩放点积注意力。由此我们可以构建多头自注意力操作:
MultiHeadSelfAttention ( x ) = W O MultiHead ( W Q x , W K x , W V x ) (14) \text{MultiHeadSelfAttention}(x) = W_O \text{MultiHead}(W_Q x, W_K x, W_V x) \tag{14} MultiHeadSelfAttention(x)=WOMultiHead(WQx,WKx,WVx)(14)
多头自注意力的完整操作中,可学习参数包括:
- W Q ∈ R h d k × d m o d e l W_{Q} \in \mathbb{R}^{h d_{k} ×d_{model }} WQ∈Rhdk×dmodel
- W K ∈ R h d k × d m o d e l W_{K} \in \mathbb{R}^{h d_{k} ×d_{model }} WK∈Rhdk×dmodel
- W V ∈ R h d v × d m o d e l W_{V} \in \mathbb{R}^{h d_{v} ×d_{model }} WV∈Rhdv×dmodel
- W O ∈ R d m o d e l × h d v W_{O} \in \mathbb{R}^{d_{model } ×h d_{v}} WO∈Rdmodel×hdv
由于多头注意力中Q、K、V需按头切片,可将 W Q W_{Q} WQ、 W K W_{K} WK、 W V W_{V} WV 视为沿输出维度按头拆分的参数。实现时,查询、键、值的投影可通过三次矩阵乘法完成⁵。
⁵ 拓展目标:尝试将查询、键、值的投影合并为单个权重矩阵,仅需一次矩阵乘法。
因果掩码 Causal masking
实现需防止模型关注序列中的未来token。例如,给定token序列 t 1 , . . . , t n t_1, ..., t_n t1,...,tn,计算前缀 t 1 , . . . , t i ( i < n ) t_1, ..., t_i (i < n) t1,...,ti(i<n)的下一词预测时,模型不应访问 t i + 1 , . . . , t n t_{i+1}, ..., t_n ti+1,...,tn 的表示(推理阶段无法获取未来token,且未来token会泄露真实下一词信息,导致语言建模预训练目标失效)。
可通过因果注意力掩码实现:使token i仅能关注位置 (j ≤ i) 的token。可使用 torch.triu 或广播索引比较构建掩码,并利用3.5.4节缩放点积注意力的掩码支持功能。
应用RoPE
RoPE需应用于查询和键向量,而非值向量。此外,head dimension应视为批次维度——多头注意力中每个头的注意力独立计算,因此每个头的查询和键向量需应用相同的RoPE旋转。
Problem (multihead_self_attention): Implement causal multi-head self-attention (5 points)
交付物:实现一个 torch.nn.Module 类,用于因果多头自注意力。
- 至少接收以下参数:
d_model:int 类型,Transformer块输入的维度。num_heads:int 类型,多头自注意力的头数。
- 按Vaswani等人[2017]的设定,令 d k = d v = d m o d e l / h d_k = d_v = d_{model} / h dk=dv=dmodel/h。
测试方法:完成 [adapters.run_multihead_self_attention] 测试适配器,运行 uv run pytest -k test_multihead_self_attention 测试。
3.6 The Full Transformer LM
首先组装Transformer块(建议参考图2)。每个Transformer块包含两个“子层”:一个用于多头自注意力,另一个用于前馈网络。每个子层的流程为:先执行RMSNorm,再执行核心操作(MHA/前馈网络),最后添加残差连接。
具体来说,Transformer块的前半部分(第一个子层)通过以下更新从输入x生成输出y:
y = x + M u l t i H e a d S e l f A t t e n t i o n ( R M S N o r m ( x ) ) . ( 15 ) y = x + MultiHeadSelfAttention(RMSNorm(x)) . (15) y=x+MultiHeadSelfAttention(RMSNorm(x)).(15)
Problem (transformer_block): Implement the Transformer block (3 points)
实现3.5节描述的预归一化Transformer块(如图2所示)。
- 至少接收以下参数:
d_model:int 类型,Transformer块输入的维度。num_heads:int 类型,多头自注意力的头数。d_ff:int 类型,位置wise前馈网络内层的维度。
测试方法:完成 [adapters.run_transformer_block] 适配器,运行 uv run pytest -k test_transformer_block 测试。
接下来按图1的高层架构组装完整模型:
- 按3.1.1节描述实现embedding。
- 将嵌入输出送入
num_layers个Transformer块。 - 最后通过三层输出层,得到词汇表上的概率分布。
Problem(transformer_lm): Implementing the Transformer LM (3points)
是时候把所有内容整合起来了!请按照§3.1中的描述以及图1的示例,实现Transformer语言模型。至少,你的实现需要支持之前提到的Transformer块的所有构建参数,同时还要支持以下额外参数:
vocab_size: int 词汇表的大小,用于确定 token 嵌入矩阵的维度。
context_length: int 最大上下文长度,用于确定位置嵌入矩阵的维度。
num_layers: int 要使用的Transformer块的数量。
你需要先在[adapters.run_transformer_lm]处实现测试适配器。然后运行命令uv run pytest -k test_transformer_lm来测试你的实现。
交付物:一个能通过上述测试的Transformer语言模型(LM)模块。
Resource accounting 资源核算
理解Transformer各部分的计算量(FLOPs)和内存消耗很有必要。我们将进行基础的“FLOPs核算”——Transformer的绝大多数计算量来自矩阵乘法,核心步骤如下:
- 列出Transformer前向传播中的所有矩阵乘法。
- 将每个矩阵乘法转换为所需的FLOPs。
第二步可利用以下规则:
- 规则:若 A ∈ R m × n A \in \mathbb{R}^{m ×n} A∈Rm×n、 B ∈ R n × p B \in \mathbb{R}^{n ×p} B∈Rn×p,则矩阵乘法 A B A B AB 需 2 m n p 2mnp 2mnp 个FLOPs。
- 推导: ( A B ) [ i , j ] = A [ i , : ] ⋅ B [ : , j ] (A B)[i, j] = A[i,:] \cdot B[:, j] (AB)[i,j]=A[i,:]⋅B[:,j],每个点积需n次加法和n次乘法(共2n个FLOPs);矩阵 A B A B AB共 m × p m ×p m×p 个元素,总FLOPs为 ( 2 n ) × ( m p ) = 2 m n p (2n) × (mp) = 2mnp (2n)×(mp)=2mnp。
建议先梳理Transformer block和Transformer LM的每个组件,列出所有矩阵乘法及其对应的FLOPs成本,再完成以下问题。
Problem(transformer_accounting):Transformer LM resource accounting (5points)
(a) 考虑GPT-2 XL的配置:
- vocab_size:50,257
- context_length:1,024
- num_layers:48
- d_model:1,600
- num_heads:25
- d_ff:6,400
若按该配置构建模型,其可学习参数总数是多少?若每个参数用单精度浮点数(32位)表示,仅加载模型需占用多少内存?
回答:
1. 按你这份代码,参数总数是多少?
TransformerLM 结构:
class TransformerLM(nn.Module):
def __init__(..., vocab_size, context_length, d_model, num_layers, num_heads, d_ff, rope_theta):
self.embedding = TokenEmbedding(vocab_size, d_model)
self.layers = [TransformerBlock(...) for _ in range(num_layers)]
self.norm = RMSNorm(d_model)
self.linear = LinearLayer(d_model, vocab_size)
1.1 各模块参数公式
(1) TokenEmbedding
self.weight: (vocab_size, d_model)
👉
params_token = vocab_size * d_model
(2) TransformerBlock
class TransformerBlock(nn.Module):
self.rmsnorm1 = RMSNorm(d_model) # gain: (d_model,)
self.mha = MultiheadSelfAttentionWithRope(d_model, num_heads, ...)
self.ff = SwiGLU(d_model, d_ff)
self.rmsnorm2 = RMSNorm(d_model)
先拆子模块:
RMSNorm
self.gain = nn.Parameter(torch.ones(d_model))
👉 每个 RMSNorm:
d_model个参数
👉 Block 里两个 RMSNorm:2 * d_model
MultiheadSelfAttentionWithRope
self.w_q = LinearLayer(d_model, d_model)
self.w_k = LinearLayer(d_model, d_model)
self.w_v = LinearLayer(d_model, d_model)
self.w_o = LinearLayer(d_model, d_model)
self.rope = RotaryPositionalEmbedding(...)
-
每个
LinearLayer(in, out)只有一个weight (out, in):👉
params_linear = in * out -
所以 4 个都是
d_model × d_model:
params MHA = 4 × d model 2 \text{params}_\text{MHA} = 4 \times d_\text{model}^2 paramsMHA=4×dmodel2
RotaryPositionalEmbedding里是这样写的:
freqs_cis = self.precompute_freqs_cis(...)
self.register_buffer('freqs_cis', freqs_cis, persistent=False)
这是非训练参数(buffer,不是 Parameter),不算在可学习参数里。
SwiGLU
self.w1 = LinearLayer(d_model, d_ff)
self.w2 = LinearLayer(d_ff, d_model)
self.w3 = LinearLayer(d_model, d_ff)
每个 LinearLayer 只有一个权重矩阵:
w1:d_model × d_ffw3:d_model × d_ffw2:d_ff × d_model
都等价于 d_model * d_ff 个参数,所以:
params SwiGLU = 3 × d model × d ff \text{params}_\text{SwiGLU} = 3 \times d_\text{model} \times d_\text{ff} paramsSwiGLU=3×dmodel×dff
单个 TransformerBlock 总参数
综合上面:
params block = 4 d model 2 ⏟ MHA ∗ 3 d model d ff ⏟ SwiGLU ∗ 2 d model ⏟ 两层 RMSNorm \text{params}_\text{block} = \underbrace{4 d_\text{model}^2}_\text{MHA}* \underbrace{3 d_\text{model} d_\text{ff}}_\text{SwiGLU}* \underbrace{2 d_\text{model}}_\text{两层 RMSNorm} paramsblock=MHA 4dmodel2∗SwiGLU 3dmodeldff∗两层 RMSNorm 2dmodel
(3) Final RMSNorm + Linear LM head
self.norm = RMSNorm(d_model) # gain: d_model
self.linear = LinearLayer(d_model, vocab_size) # weight: (vocab_size, d_model)
norm:d_modellinear:d_model * vocab_size
1.2 总可学习参数数
把三部分加一起:
total_params = token_embed + blocks_total + final_norm_and_linear
= 80,411,200 + 1,966,233,600 + 80,412,800
= 2,127,057,600
✅ TransformerLM参数总数: 2,127,057,600 ≈ 2.13B parameters
2. 这些参数用 float32 占多少显存?
每个参数 float32 = 4 字节:
bytes = 2,127,057,600 * 4 = 8,508,230,400 bytes
换成 十进制 GB(1 GB = 10^9 bytes):text ≈ 8.51 GB
(b) 识别完成我们GPT-2 XL结构模型前向传播所需的矩阵乘法。这些矩阵乘法总共需要多少FLOPs?假设我们的输入序列有context_length个token。
答:包括的矩阵乘法有:MHA层中的四个linear层,MHA层中的 (QK^T + Attn·V)乘法,SwiGLU中的三个Linear层。如果考虑softmax,rotary和res连接,计算结果: 4.5209 TFLOPs;如果只考虑核心的矩阵乘法,则计算结果: 4.5152 TFLOPs
1. ok, 我们梳理下:
TransformerLM 结构:
class TransformerLM(nn.Module):
def __init__(..., vocab_size, context_length, d_model, num_layers, num_heads, d_ff, rope_theta):
self.embedding = TokenEmbedding(vocab_size, d_model)
self.layers = [TransformerBlock(...) for _ in range(num_layers)]
self.norm = RMSNorm(d_model)
self.linear = LinearLayer(d_model, vocab_size)
def forward(self, input: torch.Tensor):
output = self.embedding(input)
for layer in self.layers:
output = layer(output)
output = self.norm(output)
output = self.linear(output)
return output
1.1 各模块参数公式
(1) TokenEmbedding
👉索引操作,而非计算操作, FLOPs=0
(2) TransformerBlock
class TransformerBlock(nn.Module):
def __init__(self, ...):
self.rmsnorm1 = RMSNorm(d_model) # gain: (d_model,)
self.mha = MultiheadSelfAttentionWithRope(d_model, num_heads, ...)
self.ff = SwiGLU(d_model, d_ff)
self.rmsnorm2 = RMSNorm(d_model)
def forward(self, input: torch.Tensor):
x_normed = self.rmsnorm1(input)
input = self.mha(x_normed) + input
x_normed = self.rmsnorm2(input)
input = self.ff(x_normed) + input
return input
先拆子模块:
RMSNorm
class RMSNorm(nn.Module):
"""
输入:
x: (batch_size, sequence_length, d_model)
输出:
result: (batch_size, sequence_length, d_model)"""
def __init__(self, d_model: int, eps: float = 1e-5, device=None, dtype=None):
super().__init__()
self.d_model = d_model
self.eps = eps
self.gain = nn.Parameter(torch.ones(d_model, device=device, dtype=dtype))
def forward(self, x: torch.Tensor) -> torch.Tensor:
in_dtype = x.dtype
x = x.to(torch.float32)
rms = torch.sqrt(torch.mean(x * x, dim=-1, keepdim=True) + self.eps)
# 分解:
# 1. x * x : 每个元素平方 → batch*seq*d_model 次乘法
# 2. mean(..., dim=-1) : 对d_model维求和后除以d_model
# - 求和: batch*seq*(d_model-1) 次加法
# - 除法: batch*seq 次除法
# 3. + self.eps : batch*seq 次加法
# 4. torch.sqrt : batch*seq 次开方运算(通常算1个FLOP)
result = x / rms * self.gain
# 5. x / rms : batch*seq*d_model 次除法
# 6. * self.gain : batch*seq*d_model 次乘法
return result.to(in_dtype)
假设形状:(batch, seq, d_model) = (B, S, D)
👉 每个 RMSNorm:FLOPs = 4×B×S×D + 2×B×S
👉 Block 里两个 RMSNorm:FLOPs = 8×B×S×D + 4×B×S
MultiheadSelfAttentionWithRope
class MultiheadSelfAttentionWithRope(nn.Module):
def __init__(self, d_model: int, num_heads: int, max_seq_len: int, theta: float):
super().__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
self.d_v = self.d_k = d_model // num_heads
self.w_q = LinearLayer(d_model, d_model)
self.w_k = LinearLayer(d_model, d_model)
self.w_v = LinearLayer(d_model, d_model)
self.w_o = LinearLayer(d_model, d_model)
self.rope = RotaryPositionalEmbedding(theta, self.d_k, max_seq_len)
def _generate_causal_mask(self, seq_len: int):
mask = torch.tril(torch.ones(seq_len, seq_len))
return mask.bool()
def forward(self, input: torch.Tensor, token_positions: torch.Tensor = None):
batch_size, seq_len, d_model = input.shape
q = self.w_q(input) # batch_size, seq_len, d_model
k = self.w_k(input)
v = self.w_v(input)
# batch_size, seq_len, self.num_heads, self.d_k -> batch_size, self.num_heads, seq_len, self.d_k
q = q.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
k = k.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
v = v.view(batch_size, seq_len, self.num_heads, self.d_v).transpose(1, 2)
if token_positions is None:
token_positions = torch.arange(seq_len)
token_positions = token_positions.unsqueeze(0)
token_positions = token_positions.unsqueeze(1).expand(-1, self.num_heads, -1) # torch.Size([1, 4, 12])
q = self.rope(q, token_positions)
k = self.rope(k, token_positions)
casual_mask = self._generate_causal_mask(seq_len) # (L, L)
casual_mask = casual_mask.unsqueeze(0).unsqueeze(0) # (1, 1, L, L)
atten = ScaledDotProductAttention(mask=casual_mask)
attention_output = atten(q, k, v) # [batch, num_heads, seq_len, d_v]
attention_output = attention_output.transpose(1, 2).contiguous().view(
batch_size, seq_len, -1) # [batch, seq_len, d_model]
output = self.w_o(attention_output) # [batch, seq_len, d_model] x [d_model x d_model]
return output
-
batch_size, seq_len, d_model = input.shape, 所以
-
4个
LinearLayer()都是 :👉 FLOPs=2×B×S×D×D
-
RotaryPositionalEmbedding里是这样的:👉 FLOPs=6×B×S×D
-
ScaledDotProductAttention里是这样的:👉 FLOPs=4 × B × S × S × D + B × num_heads × S × (4S - 1)
FLOPs MHA = 8 × B × S × D × D + 6 × B × S × D + 4 × B × S × S × D + B × n u m h e a d s × S × ( 4 S − 1 ) \text{FLOPs}_\text{MHA} = 8 \times B \times S \times D \times D + 6×B×S×D + 4 × B × S × S × D + B × num_heads × S × (4S - 1) FLOPsMHA=8×B×S×D×D+6×B×S×D+4×B×S×S×D+B×numheads×S×(4S−1)
SwiGLU
def SiLU(x: torch.Tensor, beta: float = 1.0):
return x * torch.sigmoid(beta * x)
class SwiGLU(nn.Module):
def __init__(self, d_model: int, d_ff: int = None):
super().__init__()
if d_ff is None:
d_ff = d_model * 8 / 3
self.w1 = LinearLayer(d_model, d_ff)
self.w2 = LinearLayer(d_ff, d_model)
self.w3 = LinearLayer(d_model, d_ff)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# x: [batch, seq_len, d_model],
gate = SiLU(self.w1(x))
value = self.w3(x)
return self.w2(gate * value)
self.w1(x)和self.w3(x)里是这样的:👉 FLOPs=2 × B × S × D × d_ff
gate = SiLU()里是这样的:👉 FLOPs=3 × B × S × d_ff
gate * value里是这样的:👉 FLOPs=B × S × d_ff
self.w2里是这样的:👉 FLOPs=2 × B × S × D × d_ff
FLOPs SwiGLU = 6 × B × S × D × d ff + 4 × B × S × d ff \text{FLOPs}_\text{SwiGLU} = 6 \times B \times S \times D \times d_\text{ff} + 4 \times B \times S \times d_\text{ff} FLOPsSwiGLU=6×B×S×D×dff+4×B×S×dff
残差连接
👉 FLOPs= 2 × B × S × D
综合上面:
FLOPs block = ⏟ MHA + ⏟ SwiGLU + ⏟ 两层 RMSNorm + ⏟ 残差 \text{FLOPs}_\text{block} = \underbrace{}_\text{MHA} + \underbrace{}_\text{SwiGLU} + \underbrace{}_\text{两层 RMSNorm} + \underbrace{}_\text{残差} FLOPsblock=MHA +SwiGLU +两层 RMSNorm +残差
(3) Final RMSNorm + Linear LM head
self.norm = RMSNorm(d_model) # FLOPs = 4×B×S×D + 2×B×S
self.linear = LinearLayer(d_model, vocab_size) # FLOPs = 2 × B × S × D × vocab_size
(c) 基于上述分析,模型的哪些部分占用的FLOPs最多?
SwiGLU部分和MHA部分占比最多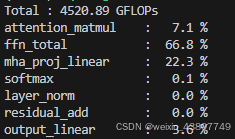
(d) 对以下模型重复上述分析:
- GPT-2 Small(12层、d_model=768、12头)
- GPT-2 Medium(24层、d_model=1024、16头)
- GPT-2 Large(36层、d_model=1280、20头)
随着模型规模增大,Transformer语言模型各组件的FLOPs占比如何变化?
交付物: - 每个模型的组件FLOPs占比拆解。
- 1-2句话描述模型规模变化对各组件FLOPs占比的影响。
(e) 对GPT-2 XL,将上下文长度增至16,384。前向传播的总FLOPs如何变化?各组件的FLOPs相对占比如何变化?
4 Training a Transformer LM
现已掌握数据预处理(通过分词器)和模型构建(Transformer)的相关步骤,接下来需要编写支持训练的完整代码,主要包括以下内容:
- 损失函数:需定义交叉熵损失函数。
- 优化器:需定义用于最小化损失的优化器(AdamW)。
- 训练循环:需搭建加载数据、保存检查点及管理训练过程的支撑架构。
4.1 交叉熵损失
Transformer语言模型针对每个长度为 m + 1 m+1 m+1的序列 x x x(其中 i = 1 , … , m i=1,\dots,m i=1,…,m)定义了分布 p θ ( x i + 1 ∣ x 1 : i ) p_{\theta}(x_{i+1} \mid x_{1:i}) pθ(xi+1∣x1:i)。给定由长度为 m m m的序列组成的训练集 D D D,我们定义标准的交叉熵(负对数似然)损失函数:
ℓ ( θ ; D ) = 1 ∣ D ∣ ∑ x ∈ D ∑ i = 1 m − log p θ ( x i + 1 ∣ x 1 : i ) . (16) \ell(\theta; D) = \frac{1}{|D|} \sum_{x \in D} \sum_{i=1}^{m} -\log p_{\theta}(x_{i+1} \mid x_{1:i}). \tag{16} ℓ(θ;D)=∣D∣1x∈D∑i=1∑m−logpθ(xi+1∣x1:i).(16)
(注:Transformer的单次前向传播可得到所有 i = 1 , … , m i=1,\dots,m i=1,…,m对应的 p θ ( x i + 1 ∣ x 1 : i ) p_{\theta}(x_{i+1} | x_{1: i}) pθ(xi+1∣x1:i)。)
具体而言,Transformer会为每个位置 i i i计算对数几率(logits) o i ∈ R v o c a b _ s i z e o_{i} \in \mathbb{R}^{vocab\_size } oi∈Rvocab_size,最终得到((注: o i [ k ] o_{i}[k] oi[k]表示向量 o i o_i oi中索引 k k k对应的数值。)):
p ( x i + 1 ∣ x 1 : i ) = softmax ( o i ) [ x i + 1 ] = exp ( o i [ x i + 1 ] ) ∑ a = 1 vocab_size exp ( o i [ a ] ) . (17) p(x_{i+1} \mid x_{1:i}) = \text{softmax}(o_i)[x_{i+1}] = \frac{\exp(o_i[x_{i+1}])}{\sum_{a=1}^{\text{vocab\_size}} \exp(o_i[a])}. \tag{17} p(xi+1∣x1:i)=softmax(oi)[xi+1]=∑a=1vocab_sizeexp(oi[a])exp(oi[xi+1]).(17)
交叉熵损失通常由 o i ∈ R v o c a b _ s i z e o_{i} \in \mathbb{R}^{vocab\_size } oi∈Rvocab_size和目标值 x i + 1 x_{i+1} xi+1定义(7 这对应于目标值 x i + 1 x_{i+1} xi+1上的狄拉克δ分布与预测的softmax ( o i ) (o_{i}) (oi)分布之间的交叉熵。)。
与softmax函数类似,实现交叉熵损失时需注意数值稳定性问题。
Problem (cross_entropy): Implement Cross entropy
交付要求:编写一个计算交叉熵损失的函数,输入预测对数几率( o i o_{i} oi)和目标值( x i + 1 x_{i+1} xi+1),计算交叉熵 ℓ i = − log softmax ( o i ) [ x i + 1 ] \ell_{i}=-\log \text{softmax}(o_{i})[x_{i+1}] ℓi=−logsoftmax(oi)[xi+1]。函数需满足以下要求:
- 减去最大元素以保证数值稳定性。
- 尽可能抵消对数(log)和指数(exp)运算。
- 支持任意额外的批次维度,并返回批次内的平均值。与3.3节一致,假设批次维度始终位于词汇表大小维度之前。
实现[adapters.run_cross_entropy],然后运行uv run pytest -k test_cross_entropy测试实现结果。
困惑度(Perplexity)
交叉熵可满足训练需求,但在模型评估时,我们还需报告困惑度指标。对于长度为 m m m、交叉熵损失为 ℓ 1 , … , ℓ m \ell_{1},\dots,\ell_{m} ℓ1,…,ℓm的序列:
perplexity = exp ( 1 m ∑ i = 1 m ℓ i ) . (18) \text{perplexity} = \exp\left( \frac{1}{m} \sum_{i=1}^{m} \ell_i \right). \tag{18} perplexity=exp(m1i=1∑mℓi).(18)
4.2 随机梯度下降(SGD)优化器
有了损失函数后,开始探索优化器。最简单的基于梯度的优化器是随机梯度下降(SGD)。首先初始化随机参数 θ 0 \theta_{0} θ0,然后对于每个步骤 t = 0 , … , T − 1 t=0,\dots,T-1 t=0,…,T−1,执行以下更新:
θ t + 1 ← θ t − α t ∇ L ( θ t ; B t ) , (19) \theta_{t+1} \leftarrow \theta_t - \alpha_t \nabla L(\theta_t; B_t), \tag{19} θt+1←θt−αt∇L(θt;Bt),(19)
其中 B t B_{t} Bt是从数据集 D D D中随机采样的批次数据,学习率 α t \alpha_{t} αt 和 batch size ∣ B t ∣ |B_{t}| ∣Bt∣为超参数。
4.2.1 在PyTorch中实现SGD
要实现自定义优化器,需继承PyTorch的torch.optim.Optimizer类。该子类必须实现以下两个方法:
def __init__(self, params, ...):初始化优化器。其中params是待优化参数的集合(或参数组,若用户希望为模型不同部分设置不同超参数,如学习率)。需将params传递给基类的__init__方法,基类会存储这些参数供step方法使用。可根据优化器需求添加额外参数(如学习率是常用参数),并将其以字典形式传递给基类构造函数,字典的键为参数名称(字符串)。def step(self):执行一次参数更新。在训练循环中,该方法会在反向传播后调用,因此可获取上一批次的梯度。该方法需遍历每个参数张量 p p p并原地修改(即修改 p . d a t a p.data p.data,该属性存储与参数相关的张量),修改依据为参数的梯度 p . g r a d p.grad p.grad(若存在)——即损失相对于该参数的梯度张量。
PyTorch优化器API存在一些细节要点,通过示例说明更易理解。为使示例更丰富,我们实现一个带学习率衰减的SGD变体:初始学习率为 α \alpha α,训练过程中步长逐渐减小:
θ t + 1 = θ t − α t + 1 ∇ L ( θ t ; B t ) (20) \theta_{t+1} = \theta_t - \frac{\alpha}{\sqrt{t+1}} \nabla L(\theta_t; B_t) \tag{20} θt+1=θt−t+1α∇L(θt;Bt)(20)
以下是该SGD变体作为PyTorch Optimizer子类的实现代码:
from collections.abc import Callable, Iterable
from typing import Optional
import torch
import math
class SGD(torch.optim.Optimizer):
def __init__(self, params, lr=1e-3):
if lr < 0:
raise ValueError(f"无效的学习率:{lr}")
defaults = {"lr": lr}
super().__init__(params, defaults)
def step(self, closure: Optional[Callable] = None):
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
lr = group["lr"] # 获取学习率
for p in group["params"]:
if p.grad is None:
continue
state = self.state[p] # 获取与参数p相关的状态
t = state.get("t", 0) # 从状态中获取迭代次数,若无则初始化为0
grad = p.grad.data # Get the gradient of loss with respect to p
p.data -= lr / math.sqrt(t + 1) * grad # 原地更新weight tensor
state["t"] = t + 1 # 迭代次数加1
return loss
在__init__方法中,将参数和默认超参数传递给基类构造函数(参数可能以组的形式传入,每组可设置不同超参数)。若参数仅为单个torch.nn.Parameter对象集合,基类构造函数会创建一个参数组并为其分配默认超参数。在step方法中,我们遍历每个参数组,再遍历组内每个参数,执行公式20的更新逻辑。此处,我们将迭代次数存储为每个参数的关联状态:先读取该值用于梯度更新,再更新迭代次数。API规定用户可传入可调用的closure函数,用于在优化器步骤前重新计算损失。我们使用的优化器无需此功能,但为兼容API仍需添加。
以下是一个极简训练循环示例,展示该优化器的使用:
weights = torch.nn.Parameter(5 * torch.randn((10, 10)))
opt = SGD([weights], lr=1)
for t in range(100):
opt.zero_grad() # 重置所有可学习参数的梯度
loss = (weights**2).mean() # 计算标量损失值
print(loss.cpu().item())
loss.backward() # 执行反向传播,计算梯度
opt.step() # 执行优化器步骤
这是训练循环的典型结构:在每次迭代中,计算损失并执行一次优化器更新。训练语言模型时,可学习参数来自模型本身(在PyTorch中,m.parameters()会返回这些参数集合)。损失将基于采样的数据批次计算,但训练循环的基本结构保持不变。
Problem (learning_rate_tuning): Tuning the learning rate (1 point)
如后续所示,学习率是对训练影响最大的超参数之一。通过玩具示例实际验证这一点。使用上述SGD示例,分别测试另外三个学习率:1e1、1e2和1e3,仅训练10轮。观察每个学习率对应的损失变化:损失衰减更快、更慢,还是发散(即训练过程中损失增大)?
交付要求:用1-2句话描述观察到的现象。
4.3 AdamW优化器
现代语言模型通常使用更复杂的优化器而非SGD。近年来主流的优化器多基于Adam优化器[Kingma and Ba, 2015]改进。本实验将使用AdamW[Loshchilov and Hutter, 2019]——该优化器在近期研究中应用广泛。AdamW对Adam进行了改进,通过添加权重衰减(每次迭代时将参数向0拉近)实现更优的正则化效果,且权重衰减与梯度更新相互解耦。我们将按照Loshchilov和Hutter[2019]的算法2实现AdamW。
AdamW是有状态的优化器:对于每个参数,它会跟踪其一阶矩和二阶矩的移动估计。因此,AdamW需占用额外内存以换取更优的稳定性和收敛性。除学习率 α \alpha α外,AdamW还有一组超参数 ( β 1 , β 2 ) (\beta_{1}, \beta_{2}) (β1,β2)(控制矩估计的更新)和权重衰减率 λ \lambda λ。常规应用中, ( β 1 , β 2 ) (\beta_{1}, \beta_{2}) (β1,β2)通常设为(0.9, 0.999),但LLaMA[Touvron et al., 2023]和GPT-3[Brown et al., 2020]等大型语言模型常使用(0.9, 0.95)。算法如下,其中 ϵ \epsilon ϵ是小常数,如 10 − 8 10^{-8} 10−8,用于避免 v v v出现极小值时的数值稳定性问题:
算法1 AdamW优化器

注:迭代次数 t t t从1开始。请实现该优化器。
Problem (adamw): Implement AdamW (2 points)
交付要求:将AdamW实现为torch.optim.Optimizer的子类。该类的__init__方法需接收学习率 α \alpha α,以及超参数 β \beta β、 ϵ \epsilon ϵ和 λ \lambda λ。为便于状态管理,基类Optimizer提供了字典self.state,该字典将nn.Parameter对象映射到存储该参数相关信息(对于AdamW而言,即矩估计)的字典。实现[adapters.get_adamw_cls],并确保通过uv run pytest -k test_adamw测试。
Problem (adamwAccounting): Resource accounting for training with AdamW (2 points)
假设所有张量均使用float32精度,计算运行AdamW所需的内存和计算量。
(a) 运行AdamW所需的 peak memory是多少?Decompose your answer based on the
memory usage of the parameters, activations, gradients, and optimizer state。答案需用批次大小(batch_size)和模型超参数(词汇表大小vocab_size、上下文长度context_length、层数num_layers、模型维度d_model、头数num_heads)表示。假设 d f f = 4 × d m o d e l d_{ff}=4 \times d_{model} dff=4×dmodel。
为简化计算,激活值的内存占用仅考虑以下组件:
- Transformer块
- RMS归一化层(RMSNorm(s))
- Multi-head self-attention sublayer:QKV projections、 Q ⊤ K Q^{\top} K Q⊤K矩阵乘法、softmax、 weighted sum of values、output projection
- Position-wisefeed-forward: W 1 W_1 W1矩阵乘法、SiLU激活函数、 W 2 W_2 W2矩阵乘法
- 最终RMS归一化层(final RMSNorm)
- 输出嵌入(output embedding)
- 对数几率的交叉熵计算(cross-entropy on logits)
交付要求:分别给出参数、激活值、梯度和优化器状态的内存占用代数表达式,以及总内存占用表达式。
(b) 针对GPT-2XL-shaped model进行实例化,推导仅依赖于(batch_size)的表达式。在80GB内存限制下,你能使用的最大batch size是多少?
交付物:一个形如 a·batch_size + b 的表达式(其中a、b为数值),以及一个表示最大批量大小的数值。
(c) 运行一步AdamW需要多少浮点运算次数(FLOPs)?
答:运行一步 AdamW 优化器需要约 14n 次浮点运算(FLOPs),其中 n 是当前参数张量的元素个数
(d) 模型浮点运算利用率(Model FLOPs utilization:MFU)定义为实际吞吐量(每秒处理的token数)与硬件理论峰值浮点运算吞吐量的比值[Chowdhery et al., 2022]。NVIDIA A100 GPU的float32运算理论峰值为19.5 teraFLOP/s。假设MFU为50%,在单块A100上以批次大小1024训练GPT-2 XL 400K步,需要多长时间?参考Kaplan et al. [2020]和Hoffmann et al. [2022],假设反向传播的浮点运算次数是前向传播的2倍。
交付要求:给出训练所需的天数,并简要说明理由。
按步骤整理成规范的数学推导格式。
1. 已知参数
- 理论峰值算力 F peak = 19.5 TFLOPS F_{\text{peak}} = 19.5 \ \text{TFLOPS} Fpeak=19.5 TFLOPS(FP32)
- 批次大小 ( B = 1024 )
- 训练步数 ( S = 400000 )
- MFU ( = 50% )
- 模型参数量 N = 1.5 × 10 9 N = 1.5 \times 10^9 N=1.5×109
- 前向传播 FLOPs/token = 2 N = 2N =2N
- 后向传播 FLOPs/token = 4 N = 4N =4N
2. 每步总 FLOPs
每 token 总 FLOPs:
FLOPs token = 2 N + 4 N = 6 N \text{FLOPs}_{\text{token}} = 2N + 4N = 6N FLOPstoken=2N+4N=6N
每步总 FLOPs:
FLOPs step = B × 6 N = 1024 × 6 × ( 1.5 × 10 9 ) = 9.216 × 10 12 FLOPs \text{FLOPs}_{\text{step}} = B \times 6N = 1024 \times 6 \times (1.5 \times 10^9) = 9.216 \times 10^{12} \ \text{FLOPs} FLOPsstep=B×6N=1024×6×(1.5×109)=9.216×1012 FLOPs
3. 实际 GPU 吞吐量
F eff = F peak × MFU = 19.5 × 0.5 = 9.75 TFLOPS F_{\text{eff}} = F_{\text{peak}} \times \text{MFU} = 19.5 \times 0.5 = 9.75 \ \text{TFLOPS} Feff=Fpeak×MFU=19.5×0.5=9.75 TFLOPS
4. 每步所需时间
t step = FLOPs step F eff = 9.216 TFLOPS 9.75 TFLOPS 秒 t_{\text{step}} = \frac{\text{FLOPs}_{\text{step}}}{F_{\text{eff}}} = \frac{9.216 \ \text{TFLOPS}}{9.75 \ \text{TFLOPS}} \ \text{秒} tstep=FeffFLOPsstep=9.75 TFLOPS9.216 TFLOPS 秒
t step ≈ 0.945 秒 t_{\text{step}} \approx 0.945 \ \text{秒} tstep≈0.945 秒
5. 总时间
T total = S × t step = 400000 × 0.945 秒 = 378000 秒 T_{\text{total}} = S \times t_{\text{step}} = 400000 \times 0.945 \ \text{秒} = 378000 \ \text{秒} Ttotal=S×tstep=400000×0.945 秒=378000 秒
T total = 378000 86400 天 ≈ 4.375 天 T_{\text{total}} = \frac{378000}{86400} \ \text{天} \approx 4.375 \ \text{天} Ttotal=86400378000 天≈4.375 天
4.4 Learning rate scheduling
能使损失最快下降的学习率在训练过程中往往会发生变化。训练Transformer时,通常使用学习率调度策略:训练初期使用较大的学习率以加快更新速度,随着模型训练进程,逐渐衰减至较小值 (8 有时会使用学习率回升(重启)的调度策略,以帮助模型跳出局部极小值。
本实验将实现LLaMA[Touvron et al., 2023]训练中使用的余弦退火调度(cosine annealing schedule)。
调度器本质是一个函数,输入当前步骤 t t t和其他相关参数(如初始学习率、最终学习率),返回当前梯度更新应使用的学习率。最简单的调度器是常数函数,无论 t t t取何值,均返回相同的学习率。
余弦退火学习率调度需接收以下参数:(i) 当前迭代次数 t t t,(ii) 最大学习率 α m a x \alpha_{max} αmax,(iii) 最小(最终)学习率 α m i n \alpha_{min} αmin,(iv) 预热迭代次数 T w T_{w} Tw,(v) 余弦退火迭代次数 T c T_{c} Tc。迭代次数 t t t对应的学习率定义如下:
- (预热阶段)若 t < T w t < T_{w} t<Tw,则 α t = t T w ⋅ α m a x \alpha_{t} = \frac{t}{T_{w}} \cdot \alpha_{max} αt=Twt⋅αmax
- (余弦退火阶段)若 T w ≤ t ≤ T c T_{w} \leq t \leq T_{c} Tw≤t≤Tc,则 α t = α m i n + 1 2 ( 1 + cos ( t − T w T c − T w ⋅ π ) ) ( α m a x − α m i n ) \alpha_{t} = \alpha_{min} + \frac{1}{2} \left(1 + \cos\left( \frac{t - T_{w}}{T_{c} - T_{w}} \cdot \pi \right)\right) (\alpha_{max} - \alpha_{min}) αt=αmin+21(1+cos(Tc−Twt−Tw⋅π))(αmax−αmin)
- (退火后阶段)若 t > T c t > T_{c} t>Tc,则 α t = α m i n \alpha_{t} = \alpha_{min} αt=αmin
Problem (learning_rate_schedule): Implement cosine learning rate schedule with warmup
编写一个函数,接收参数 t t t、 α m a x \alpha_{max} αmax、 α m i n \alpha_{min} αmin、 T w T_w Tw和 T c T_c Tc,并根据上述定义的调度器返回学习率 α t \alpha_t αt。然后实现adapters.get_lr_cosine_schedule函数,并确保通过测试命令uv run pytest -k test_get_lr_cosine_schedule。
4.5 梯度裁剪
在训练过程中,有时会遇到产生巨大梯度的训练样本,这可能导致训练不稳定。为缓解此问题,实践中常用的一种技术是梯度裁剪。其核心思路是:在每次反向传播后、优化器执行参数更新前,对梯度的范数施加限制。
给定所有参数的梯度 g g g,计算其 ℓ 2 \ell_2 ℓ2 范数 ∥ g ∥ 2 \|g\|_2 ∥g∥2。如果该范数小于最大值 M M M,则保持梯度 g g g 不变;否则,将梯度按系数 M ∥ g ∥ 2 + ϵ \frac{M}{\|g\|_2 + \epsilon} ∥g∥2+ϵM 进行缩放(其中添加一个小值 ϵ \epsilon ϵ,如 10 − 6 10^{-6} 10−6,以保证数值稳定性)。注意,缩放后的梯度范数将略小于 M M M。
Problem (gradient_clipping): Implement gradient clipping (1 point)
编写一个函数实现梯度裁剪。该函数需接收参数:参数列表(模型参数)和最大 ℓ 2 \ell_2 ℓ2 范数。函数需原地修改每个参数的梯度。使用 ϵ = 10 − 6 \epsilon = 10^{-6} ϵ=10−6(PyTorch 默认值)。然后实现适配器 adapters.run_gradient_clipping,并确保通过测试命令 uv run pytest -k test_gradient_clipping。
5 训练循环
现在我们将整合之前构建的核心组件:分词后的数据、模型和优化器。
5.1 Data Loader
分词后的数据(例如你在分词实验中准备的数据)是一个单一的令牌序列 x = ( x 1 , . . . , x n ) x = (x_1, ..., x_n) x=(x1,...,xn)。尽管原始数据可能由多个独立文档组成(如不同网页、源代码文件),但常用做法是将所有文档拼接为一个单一令牌序列,并在文档之间添加分隔符(如 <|endoftext|> 令牌)。
Data Loader 将该序列转换为批量数据流,每个批次包含 B B B 个长度为 m m m 的序列,以及对应的下一个令牌序列(长度同样为 m m m)。例如,当 B = 1 B = 1 B=1、 m = 3 m = 3 m=3 时, ( [ x 2 , x 3 , x 4 ] , [ x 3 , x 4 , x 5 ] ) ([x_2, x_3, x_4], [x_3, x_4, x_5]) ([x2,x3,x4],[x3,x4,x5]) 是一个可能的批次。
这种数据加载方式简化训练的原因如下:
- 任何满足 1 ≤ i < n − m 1 \le i < n - m 1≤i<n−m 的索引都能构成有效的训练序列,采样过程简单高效;
- 所有训练序列长度一致,无需对输入序列进行填充(padding),提升硬件利用率(同时可增大批次大小 B B B);
- 无需将整个数据集加载到内存即可采样训练数据,便于处理无法一次性存入内存的大型数据集。
Problem (data_loading): Implement data loading (2 points)
交付要求:编写一个函数,接收参数:
- numpy 数组 x x x(存储令牌 ID 的整数数组);
- 批次大小(batch_size);
- 上下文长度(context_length);
- PyTorch 设备字符串(如
'cpu'或'cuda:0')。
函数返回一对张量:采样后的输入序列和对应的下一个令牌目标序列。两个张量的形状均为 ( b a t c h _ s i z e , c o n t e x t _ l e n g t h ) (batch\_size, context\_length) (batch_size,context_length)(存储令牌 ID),且需放置在指定设备上。
为了通过提供的测试用例验证实现,需先在 adapters.run_get_batch 中实现测试适配器,然后运行命令 uv run pytest -k test_get_batch 进行测试。
数据集过大无法加载到内存怎么办?
可使用 Unix 系统调用 mmap,将磁盘文件映射到虚拟内存,仅在访问该内存地址时才惰性加载文件内容。这样即可“模拟”将整个数据集存入内存的效果。
Numpy 通过 np.memmap(或 np.load 的 mmap_mode='r' 参数,若原始数组通过 np.save 保存)实现此功能,返回一个类 numpy 数组的对象,访问时按需加载数据条目。
训练过程中从数据集(numpy 数组)采样时,需确保以内存映射模式加载数据集(根据保存方式,使用 np.memmap 或 np.load 的 mmap_mode='r' 参数)。同时需指定与加载数组匹配的数据类型(dtype)。建议显式验证内存映射数据的正确性(例如,确保数值未超出预期词汇表大小)。
5.2 Checkpointing(检查点保存与加载)
除数据加载外,训练过程中还需保存模型。运行训练任务时,我们希望能够恢复因某种原因中断的训练(如任务超时、机器故障等)。即使训练顺利完成,后续也可能需要访问中间模型(如事后分析训练动态、从不同训练阶段的模型中采样等)。
检查点需包含恢复训练所需的所有状态:
- 至少需保存模型权重;
- 若使用有状态优化器(如 AdamW),需保存优化器状态(例如 AdamW 的动量估计值);
- 为恢复学习率调度,需记录停止时的迭代次数。
PyTorch 简化了这些状态的保存:
- 每个
nn.Module都有state_dict()方法,返回包含所有可学习权重的字典;通过load_state_dict()方法可恢复权重; - 所有
nn.optim.Optimizer均支持上述相同操作; torch.save(obj, dest)可将对象(e.g., a dictionary containing tensors in some values, but also regular Python objects like integers)保存到文件或类文件对象,后续可通过torch.load(src)加载回内存。
Problem(checkpointing): Implement model checkpointing (1point)
实现以下两个函数用于加载和保存检查点:
def save_checkpoint(model, optimizer, iteration, out):
"""
将模型、优化器状态和迭代次数保存到目标位置
参数:
model: torch.nn.Module - 待保存的模型
optimizer: torch.optim.Optimizer - 待保存的优化器
iteration: int - 当前迭代次数
out: str | os.PathLike | typing.BinaryIO | typing.IO[bytes] - 保存路径或类文件对象
"""
# 提示:使用 model.state_dict() 和 optimizer.state_dict() 获取状态,通过 torch.save() 保存
def load_checkpoint(src, model, optimizer):
"""
从源位置加载检查点,恢复模型和优化器状态
参数:
src: str | os.PathLike | typing.BinaryIO | typing.IO[bytes] - 加载路径或类文件对象
model: torch.nn.Module - 待恢复的模型
optimizer: torch.optim.Optimizer - 待恢复的优化器
返回:
int: 保存的迭代次数
"""
# 提示:使用 torch.load() 加载保存的对象,通过 load_state_dict() 恢复状态
实现适配器 adapters.run_save_checkpoint 和 adapters.run_load_checkpoint,并确保通过测试命令 uv run pytest -k test_checkpointing。
5.3 Training loop
现在终于可以将所有实现的组件整合到主训练脚本中。建议让训练脚本支持通过命令行参数配置不同超参数,这将便于后续多次实验,研究不同选择对训练的影响。
Problem (training_together): Put it together (4 points)
交付要求:编写一个训练脚本,在用户提供的输入数据上训练模型。脚本至少需支持以下功能:
- 配置和控制各类模型及优化器超参数;
- 使用
np.memmap高效加载大型训练集和验证集(内存友好); - 将检查点序列化到用户指定路径;
- 定期记录训练和验证性能(例如输出到控制台,或上传至 Weights and Biases 等外部服务)。
- 参考链接:wandb.ai
6 文本生成
训练好模型后,最后一步是实现文本生成功能。回顾:语言模型接收长度为 sequence_length 的(批量)整数序列,输出形状为 ( s e q u e n c e _ l e n g t h × v o c a b _ s i z e ) (sequence\_length \times vocab\_size) (sequence_length×vocab_size) 的矩阵,其中序列的每个元素是预测该位置下一个词的概率分布。下面将编写函数,将该输出转换为新序列的采样方案。
softmax 函数
按照标准约定,语言模型的输出是最终线性层的输出(即“logits”,对数概率),因此需通过 softmax 操作将其转换为归一化概率(见公式 10)。
解码(Decoding)
要从模型生成文本(解码),需向模型提供前缀令牌序列(即“提示词”),模型将输出词汇表上的概率分布,预测序列的下一个词。然后从该概率分布中采样,确定下一个输出令牌。
具体来说,解码过程的单步操作需接收序列 x 1 … t x_{1 \dots t} x1…t,并通过以下方式返回令牌 x t + 1 x_{t+1} xt+1:
P ( x t + 1 = i ∣ x 1.. t ) = exp ( v i ) ∑ j exp ( v j ) v = TransformerLM ( x 1.. t ) t ∈ R vocab_size \begin{aligned} P(x_{t+1} = i \mid x_{1..t}) &= \frac{\exp(v_i)}{\sum_j \exp(v_j)} \\ v &= \text{TransformerLM}(x_{1..t})_t \in \mathbb{R}^{\text{vocab\_size}} \end{aligned} P(xt+1=i∣x1..t)v=∑jexp(vj)exp(vi)=TransformerLM(x1..t)t∈Rvocab_size
(注:TransformerLM 为我们实现的模型,输入长度为 sequence_length 的序列,输出形状为 ( s e q u e n c e _ l e n g t h × v o c a b _ s i z e ) (sequence\_length \times vocab\_size) (sequence_length×vocab_size) 的矩阵;我们取该矩阵的最后一个元素,即预测第 t t t 位置的下一个词。)
通过重复上述单步条件采样(将生成的令牌追加到下一轮解码的输入中),直到生成序列结束令牌 ``(或达到用户指定的最大生成令牌数),即可实现基础解码器。
解码技巧(Decoder tricks)
我们将基于小型模型进行实验,而小型模型有时会生成质量极低的文本。两种简单的解码技巧可改善此问题:
-
温度缩放(temperature scaling):通过温度参数 τ \tau τ 修改 softmax 函数,新的 softmax 公式为:
softmax τ ( v ) i = exp ( v i / τ ) ∑ j exp ( v j / τ ) \text{softmax}_\tau(v)_i = \frac{\exp(v_i / \tau)}{\sum_j \exp(v_j / \tau)} softmaxτ(v)i=∑jexp(vj/τ)exp(vi/τ)
(注:当 τ → 0 \tau \to 0 τ→0 时,向量 v v v 中最大元素将占据主导地位,softmax 的输出将成为集中于该最大元素的独热向量。)
-
核采样(nucleus sampling)或 top-p 采样:通过截断低概率词修改采样分布。设 q q q 是经(温度缩放后的)softmax 得到的概率分布(形状为 v o c a b _ s i z e vocab\_size vocab_size),超参数为 p p p 的核采样通过以下方式生成下一个令牌:
P ( x t + 1 = i ∣ q ) = { q i ∑ j ∈ V ( p ) q j if i ∈ V ( p ) 0 otherwise P(x_{t+1} = i \mid q) = \begin{cases} \displaystyle \frac{q_i}{\sum_{j \in V(p)} q_j} & \text{if } i \in V(p) \\ 0 & \text{otherwise} \end{cases} P(xt+1=i∣q)=⎩ ⎨ ⎧∑j∈V(p)qjqi0if i∈V(p)otherwise
其中 V ( p ) V(p) V(p) 是满足 ∑ j ∈ V ( p ) q j ≥ p \sum_{j \in V(p)} q_j \ge p ∑j∈V(p)qj≥p 的最小索引集合。计算方式:先按数值大小对概率分布 q q q 排序,选择最大的词汇元素,直到累积概率达到目标值 p p p。
Problem (decoding): Decoding (3 points)
交付要求: 实现一个从你的语言模型中解码的函数。建议支持以下功能:
- 为用户提供的提示词生成补全内容(即,接收输入序列 x 1... t x_{1...t} x1...t,采样补全内容直到遇到
<|endoftext|>令牌)。 - 允许用户控制生成令牌的最大数量。
- 给定目标温度值,在采样前对预测的下一词分布应用softmax温度缩放。
- 基于用户指定的阈值,实现Top-p采样(Holtzman等人,2020;也称为核采样)。
7 实验
现在是时候整合所有内容,在预训练数据集上训练(小型)语言模型了。
7.1 如何开展实验及交付成果
理解Transformer架构组件背后原理的最佳方式是亲自修改并运行它。实践经验是无可替代的。
为此,能够快速、一致地进行实验并记录操作过程至关重要。为实现快速实验,我们将在小型模型(1700万参数)和简单数据集(TinyStories)上开展多项实验;为保证实验一致性,你需要系统地移除组件和调整超参数;为做好记录,我们要求你提交实验日志以及每个实验对应的学习曲线。
为能够提交损失曲线,请确保定期评估验证损失,并记录迭代步数和实际运行时间。你可能会发现Weights and Biases等日志记录工具很有帮助。
Problem (experiment_log): Experiment logging (3 points)**
为你的训练和评估代码搭建实验跟踪框架,能够根据梯度步数和实际运行时间跟踪实验过程及损失曲线。
交付成果:实验日志记录框架代码,以及本节以下作业问题的实验日志(一份记录所有尝试内容的文档)。
7.2 TinyStories数据集
我们将从一个非常简单的数据集(TinyStories;Eldan 和 Li,2023)开始,该数据集能让模型快速训练,且能呈现出一些有趣的特性。获取该数据集的说明见第1节。以下是该数据集的一个示例:
超参数调优
我们会提供一些基础超参数作为起点,并要求你为其他超参数找到合适的设置。
- 词汇表大小(vocab_size):10000。典型的词汇表大小在数万到数十万之间。你需要调整该参数,观察词汇表和模型行为的变化。
- 上下文长度(context_length):256。TinyStories等简单数据集可能不需要长序列长度,但对于后续的OpenWebText数据,你可能需要调整该参数。尝试改变上下文长度,观察其对每次迭代运行时间和最终困惑度的影响。
- 模型维度(d_model):512。这比许多小型Transformer论文中使用的768维略小,但能加快训练速度。
- 前馈网络维度(d_ff):1344。这大约是 8 3 d m o d e l \frac{8}{3}d_{model} 38dmodel,同时是64的倍数,有利于GPU性能发挥。
- RoPE角度参数(Θ):10000。
- 层数和注意力头数(number of layers and heads):4层、16个头。综合来看,这将构成一个约1700万非嵌入参数的模型,属于相当小的Transformer。
- 处理的总令牌数(total tokens processed):327,680,000(你的批量大小×总迭代步数×上下文长度应大致等于该值)。
你需要通过反复试验,为以下超参数找到合适的默认值: learning rate, learning rate warmup, other AdamW hyperparameters( β 1 \beta_{1} β1、 β 2 \beta_{2} β2、 ϵ \epsilon ϵ)以及 weight decay 。你可以在Kingma 和 Ba [2015]的研究中找到这类超参数的典型选择。
整合实现
现在,你可以整合所有组件:获取训练好的BPE分词器,对训练数据集进行分词,然后在你编写的训练循环中运行。重要提示:如果你的实现正确且高效,使用上述超参数在单张H100 GPU上的训练时间应约为30-40分钟。如果运行时间明显更长,请检查并确保数据加载、检查点保存或验证损失计算代码没有成为性能瓶颈,且你的实现已正确实现批量处理。
模型架构调试技巧
强烈建议你熟练使用IDE的内置调试器(例如VSCode/PyCharm),与使用打印语句调试相比,这将节省大量时间。如果你使用文本编辑器,可以使用pdb等调试工具。调试模型架构时,还有以下几个良好实践:
- 开发任何神经网络架构时,常见的第一步是在单个小批量数据上过拟合。如果你的实现正确,应该能够快速将训练损失降至接近零。
- 在模型的各个组件中设置调试断点,检查中间张量的形状是否符合预期。
- 监控激活值、模型权重和梯度的范数,确保它们不会出现爆炸或消失的情况。
Problem (learning_rate): Tune the learning rate (3 points) (4 H100 hrs)
学习率是最需要调优的超参数之一。基于你训练的基准模型,回答以下问题:
(a) 对学习率进行超参数扫描,报告最终损失(如果优化器发散,则注明发散情况)。
交付成果:多个学习率对应的学习曲线;解释你的超参数搜索策略;在TinyStories数据集上,验证损失(每令牌)不超过1.45的模型。
答:
| 试验编号 | peak lr (max_lr) | base lr (lr) | warmup_iters | weight_decay | grad_clip |
|---|---|---|---|---|---|
| A | 6e-4 | 3e-4 | 2000 | 0.1 | 打开 |
| B | 8e-4 | 6e-4 | 2000 | 0.1 | 打开 |
| C | 1.2e-3 | 8e-4 | 2000 | 0.1 | 打开 |
| D | 1.2e-3 | 8e-4 | 2000 | 0.01 | -打开 |
| E | 2e-3 | 1.2e-3 | 2000 | 0.01 | -打开 |
| F | 5e-3 | 2e-3 | 2000 | 0.01 | 打开 |
| G | 5e-3 | 2e-3 | 20 | 0.01 | 打开 |
| H | 1e-2 | 1e-2 | 20 | 0.01 | 关闭 |
| I | 9e-3 | 9e-3 | 20 | 0.01 | 关闭 |
| J | 8e-3 | 8e-3 | 20 | 0.01 | 关闭 |
| K | 7e-3 | 7e-3 | 20 | 0.01 | 打开 |
| L | 6e-3 | 6e-3 | 20 | 0.01 | 打开 |
| M | 5e-3 | 5e-3 | 20 | 0.01 | 打开 |
| N | 4e-3 | 4e-3 | 20 | 0.01 | 打开 |
| O | 3e-3 | 3e-3 | 20 | 0.01 | 打开 |
| P | 2e-3 | 2e-3 | 20 | 0.01 | 打开 |
其中,A-G收敛。H, I, 都关闭了grad_clip,发散。J关闭了grad_clip,勉强收敛?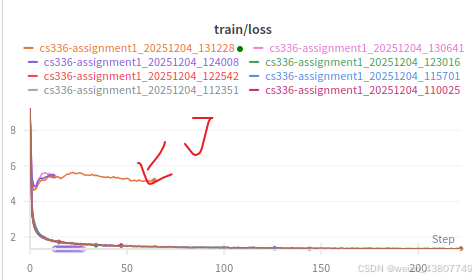
现在把J的grad_clip打开,再测试一下,居然发散了。K,L,M, N,O也发散,P不发散,P属于稳定边缘。其中M训练的日志如下:
step 00860/40000 (2.15%) | loss: 5.035241 | grad norm: 2427663941632.0000 | lrm: 0.0050 | dt: 130.52ms | tok/sec: 251,049 | mfu: 5.80 | total time: 1.89m
step 00861/40000 (2.15%) | loss: 5.044182 | grad norm: nan | lrm: 0.0050 | dt: 129.60ms | tok/sec: 252,831 | mfu: 5.84 | total time: 1.89m
step 00862/40000 (2.15%) | loss: nan | grad norm: nan | lrm: 0.0050 | dt: 128.96ms | tok/sec: 254,099 | mfu: 5.87 | total time: 1.90m
step 00863/40000 (2.16%) | loss: nan | grad norm: nan | lrm: 0.0050 | dt: 129.92ms | tok/sec: 252,221 | mfu: 5.82 | total time: 1.90m
对比表格中不同组合,最终选择试验编号E ,作为训练参数。
(b) 业界普遍认为,最佳学习率处于“稳定边缘”。探究学习率发散的临界点与最佳学习率之间的关系。
交付成果:包含至少一次发散运行的递增学习率学习曲线;分析该临界点与收敛速度的关系。
答:从试验编号H中对应的图可以看到,lr=1e-2时,发散,train/loss = NaN.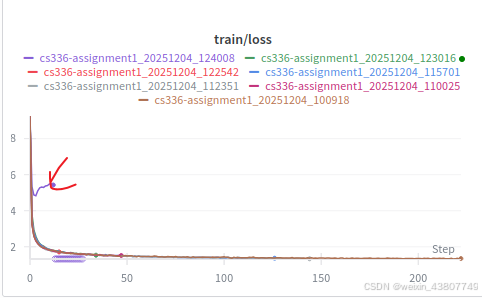
接下来,我们将调整batch size,观察其对训练的影响。批量大小至关重要——通过进行更大规模的矩阵乘法,它能让GPU发挥更高的效率,但是否越大越好呢?让我们通过实验来寻找答案。
问题(batch_size_experiment):批量大小变化实验(1分)(2个H100 GPU小时)
将批量大小从1调整到GPU内存上限,至少尝试几个中间值,包括64、128等典型批量大小。
交付成果:不同批量大小对应的学习曲线(必要时需重新优化学习率);简要阐述你关于批量大小及其对训练影响的发现。
答:
有了解码器后,就可以生成文本了!我们将通过模型生成文本,观察其效果。作为参考,你生成的文本应至少达到以下示例的水平。


Problem(generate): Generate text (1point)
使用你的解码器和训练好的检查点,报告模型生成的文本。你可能需要调整解码器参数(温度、top-p采样等)以获得流畅的输出。
交付成果:至少256个令牌的文本输出(或直到第一个<|endoftext|>令牌为止);简要评论该输出的流畅度,并指出至少两个影响输出质量的因素。
当使用temperature=1.0的时候,输出的文本不流畅,有逻辑问题: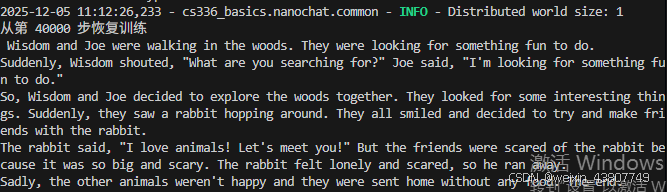
调到0.7就好很多了: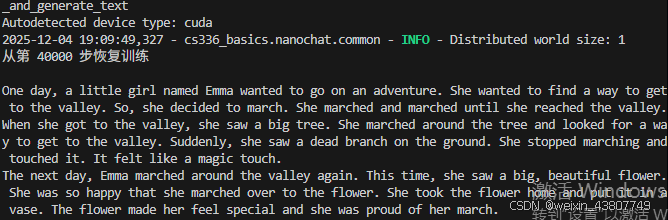
prompt = "Once upon a time, "
tokens = tokenizer.encode(prompt)
out_tokenids = model.generate(tokens, max_tokens=256, temperature=0.7,
top_p = 0.9, seed = 42, eos_token_id=eos)
out_text = tokenizer.decode(out_tokenids)
print(out_text)
7.3 Ablations and architecture modification - 组件移除与架构修改实验
理解Transformer的最佳方式是实际修改它,观察其行为变化。现在我们将进行几项简单的组件移除(消融)和架构修改实验。
消融实验1:层归一化
人们常说层归一化对Transformer训练的稳定性至关重要,但或许可以大胆尝试一下。让我们移除每个Transformer块中的RMSNorm(均方根归一化),观察会发生什么。
问题(layer_norm_ablation):移除RMSNorm并训练(1分)(1个H100 GPU小时)
移除Transformer中所有的RMSNorm层并进行训练。在之前的最优学习率下会出现什么情况?降低学习率能否恢复训练稳定性?
交付成果:移除RMSNorm后的训练学习曲线,以及最优学习率对应的学习曲线;简要评论RMSNorm的影响。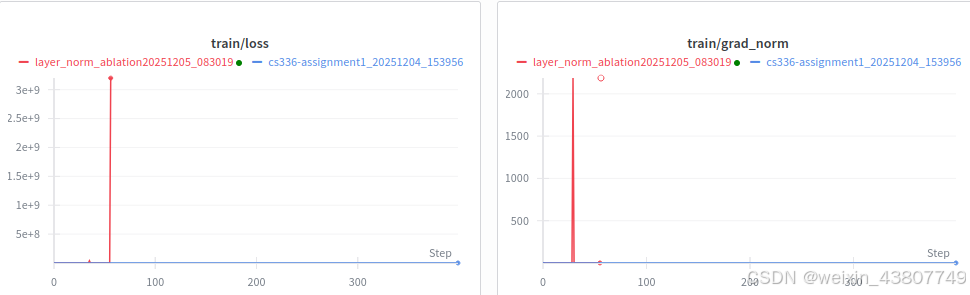
RMSNorm的核心作用是重新缩放激活值,把每层输出的方差稳定到1左右。一旦去掉了,方差会在前向传播中指数级累计,反向时,这大方差直接乘到梯度上,导致参数更新量瞬间放大,损失跟着飙升,模型几乎回到随机初始化状态:
step 05533/40000 (13.83%) | loss: 10.501057 | grad norm: 0.2879 | lrm: 0.0020 | dt: 106.18ms | tok/sec: 308,602 | mfu: 7.12 | total time: 11.53m
step 05534/40000 (13.84%) | loss: 9.624806 | grad norm: 922653056.0000 | lrm: 0.0020 | dt: 112.06ms | tok/sec: 292,417 | mfu: 6.75 | total time: 11.53m
step 05535/40000 (13.84%) | loss: 10212.219357 | grad norm: 201530015744000.0000 | lrm: 0.0020 | dt: 116.43ms | tok/sec: 281,439 | mfu: 6.50 | total time: 11.53m
step 05536/40000 (13.84%) | loss: 9191.169392 | grad norm: 1147.5687 | lrm: 0.0020 | dt: 120.87ms | tok/sec: 271,108 | mfu: 6.26 | total time: 11.54m
step 05537/40000 (13.84%) | loss: 8272.232382 | grad norm: 0.7290 | lrm: 0.0020 | dt: 120.95ms | tok/sec: 270,924 | mfu: 6.26 | total time: 11.54m
接下来,我们将研究另一个初看之下较为随意的层归一化选择。预归一化(pre-norm)Transformer块的定义为:
z = x + MultiHeadedSelfAttention ( RMSNorm ( x ) ) z = x + \text{MultiHeadedSelfAttention}(\text{RMSNorm}(x)) z=x+MultiHeadedSelfAttention(RMSNorm(x))
y = z + FFN ( RMSNorm ( z ) ) . y = z + \text{FFN}(\text{RMSNorm}(z)). y=z+FFN(RMSNorm(z)).
这是对原始Transformer架构为数不多的“共识性”修改之一,原始架构采用的是后归一化(post-norm)方式:
z = RMSNorm ( x + MultiHeadedSelfAttention ( x ) ) z = \text{RMSNorm}\bigl(x + \text{MultiHeadedSelfAttention}(x)\bigr) z=RMSNorm(x+MultiHeadedSelfAttention(x))
y = RMSNorm ( z + FFN ( z ) ) . y = \text{RMSNorm}\bigl(z + \text{FFN}(z)\bigr). y=RMSNorm(z+FFN(z)).
让我们恢复到后归一化方式,观察其效果。
问题(pre_norm_ablation):实现后归一化并训练(1分)(1个H100 GPU小时)
将你的预归一化Transformer实现修改为后归一化版本。使用后归一化模型进行训练,观察结果。
交付成果:后归一化Transformer与预归一化Transformer的学习曲线对比。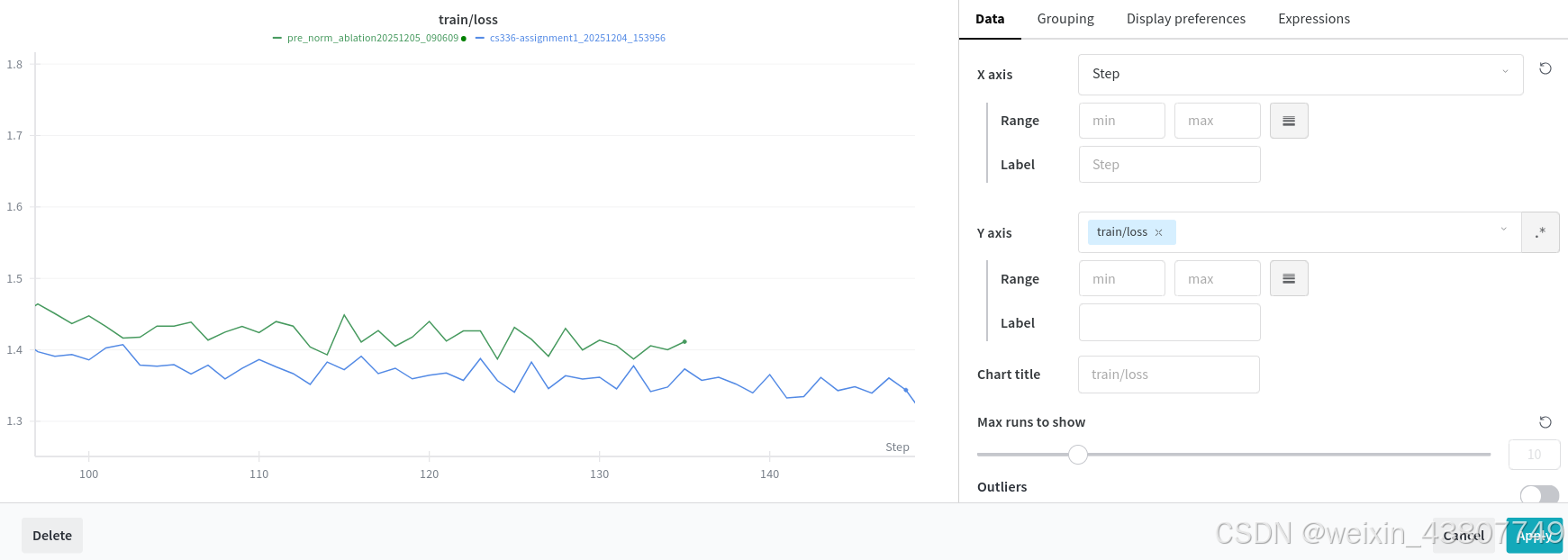
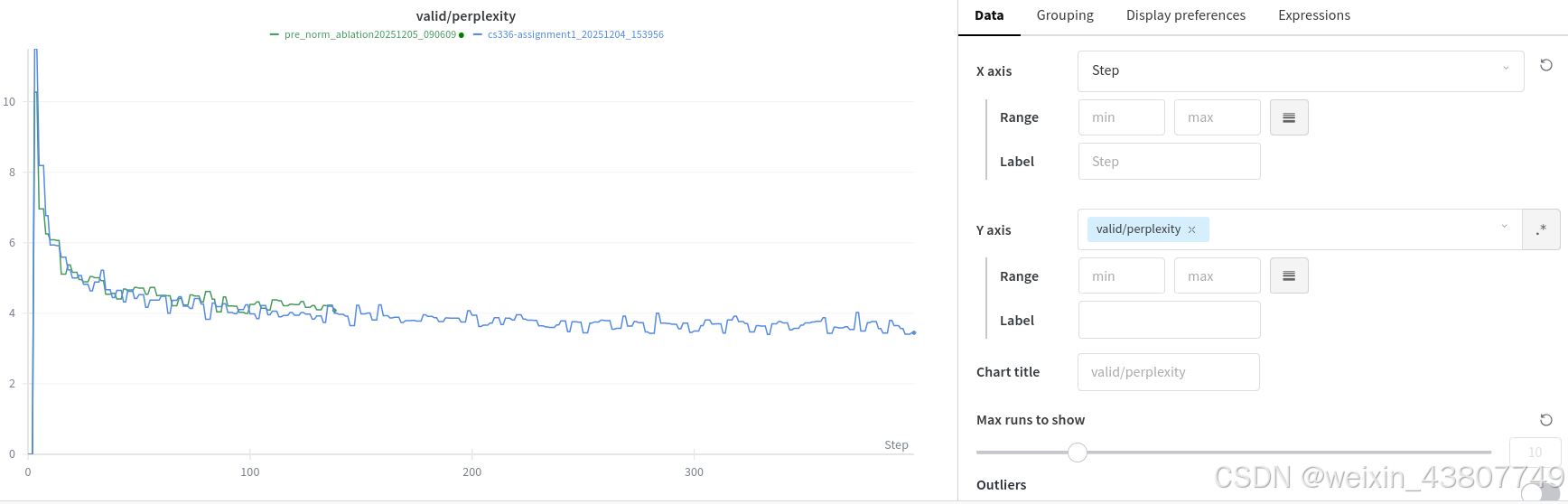
采用相同的超参数。从截图中可以看到,从100步往后,后归一化结构的训练损失比主流的先归一化结构大;在valid数据集上,后归一化结构的困惑度也更高。所以说pre-norm更好。
我们发现,层归一化对Transformer的行为有重大影响,甚至层归一化的位置也至关重要。
消融实验2:位置编码
接下来,我们将研究位置编码对模型性能的影响。具体来说,我们将基准模型(含RoPE旋转位置编码)与完全不包含位置编码的模型(NoPE)进行对比。事实证明,正如Tsai等人[2019]、Kazemnejad等人[2023]的研究所示,仅解码器架构的Transformer(即我们实现的带有因果掩码的Transformer)在理论上无需显式提供位置编码,就能推断出相对或绝对位置信息。现在我们将通过实验验证NoPE与RoPE的性能差异。
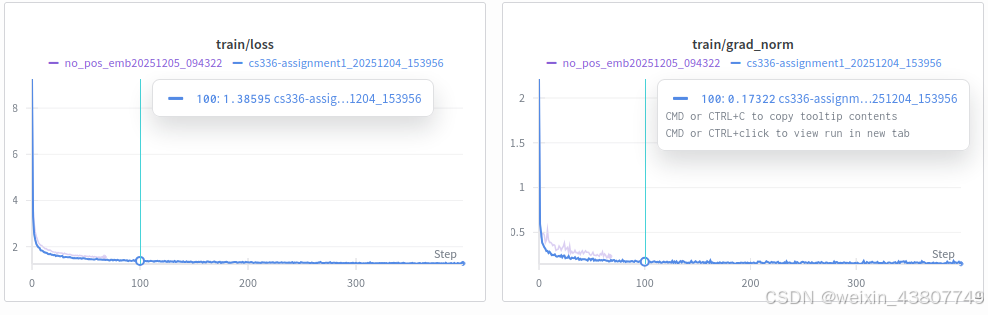
问题(no_pos_emb):实现NoPE(1分)(1个H100 GPU小时)
修改你的RoPE Transformer实现,完全移除位置编码信息,观察结果。
交付成果:RoPE与NoPE性能对比的学习曲线。
确实用RoPE更好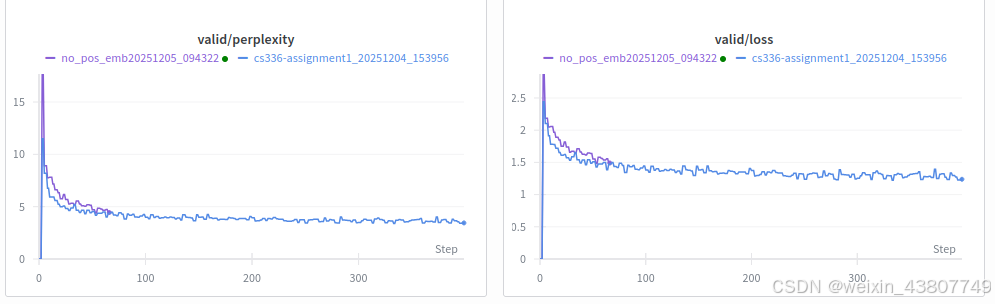
消融实验3:SwiGLU与SiLU
接下来,我们将遵循Shazeer[2020]的研究,通过对比SwiGLU前馈网络与使用SiLU激活函数但无门控线性单元(GLU)的前馈网络性能,验证前馈网络中门控机制的重要性。无门控前馈网络的定义如下:
FFN SiLU ( x ) = W 2 ⋅ SiLU ( W 1 x ) ( 25 ) \text{FFN}_{\text{SiLU}}(x) = W_2 \cdot \text{SiLU}(W_1 x) \quad (25) FFNSiLU(x)=W2⋅SiLU(W1x)(25)
回顾我们的SwiGLU实现:前馈网络内层维度设置为约 d f f = 8 3 d m o d e l d_{ff} = \frac{8}{3}d_{model} dff=38dmodel(同时确保 d f f d_{ff} dff是64的倍数,以充分利用GPU张量核心)。在你的 FFN SiLU \text{FFN}_{\text{SiLU}} FFNSiLU实现中,应设置 d f f = 4 × d m o d e l d_{ff} = 4 \times d_{model} dff=4×dmodel,以大致匹配SwiGLU前馈网络的参数数量(SwiGLU有三个权重矩阵,而SiLU前馈网络有两个)。
问题(swiglu_ablation):SwiGLU与SiLU对比(1分)(1个H100 GPU小时)
交付成果:参数数量大致匹配的情况下,SwiGLU与SiLU前馈网络性能对比的学习曲线。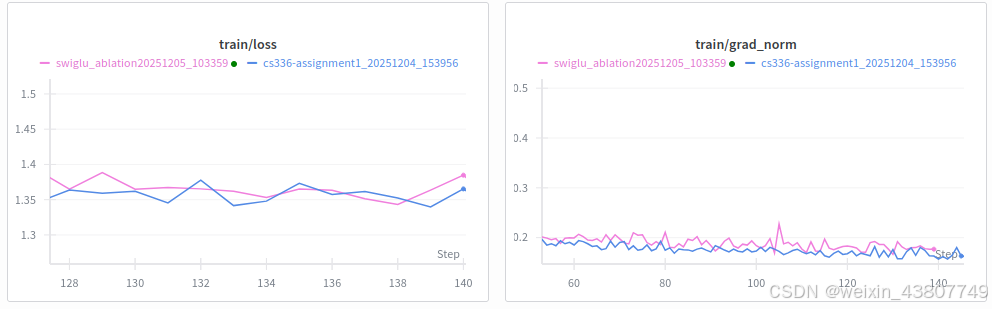
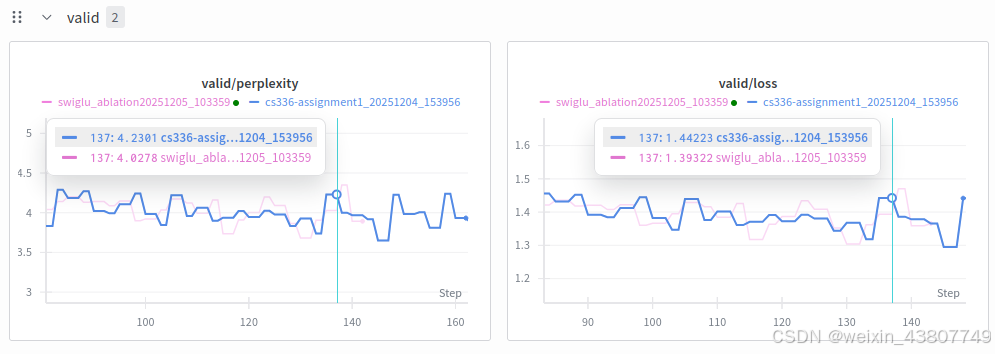
从图中来看,采用swiglu的grad_norm曲线比SiLU_MLP更低,train_loss函数值更低,训练稳定性更好。从valid_loss上来看,提升不大,也许是tinystory数据量太小了。

7.4 在OpenWebText上运行实验
现在将使用一个通过网络爬虫构建的标准预训练数据集。我们还提供了OpenWebText数据集[Gokaslan等人,2019]的一个小型样本(单个文本文件):详见第1节的文件获取说明。
以下是OpenWebText中的一个示例。请注意,该文本更贴近真实场景、结构更复杂且内容更多样化。你可浏览训练数据集,以了解网络爬取语料库的训练数据特征。

注意: 你可能需要为该实验重新调整超参数,例如学习率或批量大小。
Problem(main_experiment): Experiment on OWT (2points) (3H100hrs)
使用与TinyStories实验相同的模型架构和总训练迭代次数,在OpenWebText上训练语言模型。该模型的表现如何?
交付成果:
- 语言模型在OpenWebText上的学习曲线。描述该模型与TinyStories实验中损失值的差异——应如何解读这些损失差异?
- 基于OpenWebText训练的语言模型生成的文本(格式与TinyStories的输出保持一致)。该文本的流畅度如何?为何在模型架构和计算资源与TinyStories实验完全相同的情况下,输出质量反而更差?
7.5 自定义修改 + 排行榜
恭喜你完成到这一步!你已接近作业尾声。现在,你需要尝试改进Transformer架构,并将你的超参数与架构设计方案与班级其他同学进行比拼。
排行榜规则:
除以下限制外,无其他约束:
- 运行时间:你的提交内容在H100显卡上的运行时间最多为1.5小时。可在Slurm提交脚本中设置
--time=01:30:00以确保符合要求。 - 数据使用:仅可使用我们提供的OpenWebText训练数据集。
除此之外,你可自由设计方案。
若需获取实现思路,可参考以下资源:
- 最先进的开源大语言模型系列,例如Llama 3[Grattafiori等人,2024]或Qwen 2.5[Yang等人,2024]。
- NanoGPT快速训练仓库(https://github.com/KellerJordan/modded-nanogpt),社区成员在该仓库中分享了许多适用于“快速训练”小规模语言模型的有趣修改方案。例如,原始Transformer论文中提出的一项经典修改方案是将输入嵌入层与输出嵌入层的权重绑定(详见Vaswani等人[2017]的第3.4节和Chowdhery等人[2022]的第2节)。若尝试权重绑定,你可能需要降低嵌入层/LM头(语言模型输出层)初始化的标准差。
在进行完整的1.5小时训练前,建议先在OpenWebText的小型子集或TinyStories数据集上测试这些修改方案。
注意事项:
需说明的是,你在本排行榜中发现的部分有效修改方案,可能无法推广到更大规模的预训练场景。我们将在课程的“缩放定律”单元中进一步探讨这一问题。
任务(leaderboard):排行榜提交(6分)(需10个H100小时算力)
按照上述排行榜规则训练模型,目标是在1.5个H100小时内最小化语言模型的验证损失。
交付成果:
记录的最终验证损失值、清晰标注x轴为“壁钟时间”(且时长不超过1.5小时)的相关学习曲线,以及对你所实施方案的描述。要求排行榜提交的结果需至少击败5.0损失值的基础基准模型。请通过以下链接提交至排行榜:https://github.com/stanford-cs336/assignment1-basics-leaderboard。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 19
19 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)