Learning Dynamics of LLM Finetuning

2025 ICLR Outstanding Paper
前排提示:本文非常硬核,大量公式
摘要
学习动态(Learning dynamics)描述了特定训练样本的学习过程如何影响模型对其他样本的预测,为我们理解深度学习系统的行为提供了强大工具。本文通过分析不同潜在响应间影响累积的逐步分解过程,研究了大语言模型(LLMs)在各类微调过程中的学习动态。
我们的框架能够对指令微调(instruction tuning)和偏好微调(preference tuning)中主流算法的诸多有趣训练现象给出统一解释。具体而言,我们对微调后特定类型幻觉(hallucination)为何会加剧提出了假设性解释:例如,模型可能会借用回答问题 B 时的短语或事实来回答问题 A,或是在生成响应时反复重复相似的简单短语。
我们还扩展了该框架,提出了独特的 “挤压效应”(squeezing effect),以解释离线直接偏好优化(off-policy direct preference optimization, DPO)中一个此前已被观察到的现象 —— 即 DPO 运行时间过长会导致即使是期望输出的可能性也降低。该框架还揭示了在线 DPO(on-policy DPO)及其他变体的优势来源。
这项分析不仅为理解大语言模型的微调提供了全新视角,还启发了一种简单有效的方法来提升对齐性能(alignment performance)。实验代码可通过以下链接获取:https://github.com/Joshua-Ren/Learning_dynamics_LLM。
1 引言
深度神经网络通常通过梯度下降(GD)更新参数来习得新知识。这一过程可通过学习动态(Learning dynamics)描述 —— 该理论将模型预测结果的变化与学习特定样本所产生的梯度关联起来。借助学习动态,研究者不仅解释了训练过程中诸多有趣的现象(例如 “之字形” 学习路径(Ren et al., 2022)、组合式概念空间的形成(Park et al., 2024)),还基于这些洞见为不同问题提出了新颖且改进的算法(如 Pruthi et al., 2020; Ren, S. Guo, et al., 2023; Xia et al., 2024)。
大语言模型(LLM)因在各类任务中展现出令人瞩目的能力而成为研究热点。为确保 LLM 遵循人类指令并与人类偏好良好对齐,微调(finetuning)近年来受到广泛关注。从业者通常先进行指令微调(instruction tuning)—— 模型学习下游任务所需的额外知识,再开展偏好微调(preference tuning)—— 使模型输出与人类偏好对齐(Ouyang et al., 2022)。目前已有多种微调算法被提出以适配这一流程,但关于这些算法为何能提升模型性能,现有解释各不相同。
现有对 LLM 微调的分析大多从训练目标、训练结束时的模型状态,或其与强化学习的关联角度展开(如 Ji et al., 2024; Rafailov et al., 2024; Tajwar et al., 2024),而本文则试图从动态视角理解 LLM 的演化过程。具体而言,我们将 LLM 微调的学习动态形式化,把模型预测结果的变化分解为三个具有不同作用的项。该框架可轻松适配不同目标的各类微调算法,包括监督微调(SFT, Wei et al., 2022)、直接偏好优化(DPO, Rafailov et al., 2023 及其变体),甚至基于强化学习的方法(如 PPO, Schulman et al., 2017)。这一框架有助于解释训练过程中若干有趣且反直觉的观测现象 —— 包括偏好微调后的 “重复生成” 现象(Holtzman et al., 2020)、幻觉现象(L. Huang et al., 2023)、离线 DPO 过程中所有响应的置信度下降(Rafailov et al., 2024)等。
此外,我们还为理解 “为何离线 DPO 及其他变体的性能不如在线版本” 提供了全新视角(S. Guo, B. Zhang, et al., 2024)。我们的解释始于对一种有趣的 “挤压效应”(squeezing effect)的观测:我们证明,该效应是在带有 softmax 层、采用交叉熵损失的模型上执行梯度上升(如 DPO 及同类算法)所导致的结果。简而言之,对于每个 token 的预测,负梯度会(几乎)压低模型对所有可能输出标签的预测概率,将这部分概率质量转移至最可能的标签上。这可能损害我们试图实现的对齐效果。当负梯度作用于本就概率极低的标签时,该效应最为显著 —— 这也是离线 DPO 过程中几乎所有响应的置信度都会下降的原因。受此启发,我们提出一种简单但极具成效的方法,以进一步提升对齐性能。
2 学习动态的定义及 MNIST 示例
学习动态(Learning dynamics)通常是一个宽泛术语,描述特定因素的变化如何影响模型的预测结果。本文将其限定为 “模型参数θ的变化如何影响对应函数fθ的变化”,即Δθ与Δfθ之间的关系。当模型通过梯度下降(GD)更新参数时,我们有:
,(1)
其中,步骤t→t+1中参数θ的更新,由对样本对(xu,yu)执行一次梯度更新得到,η为学习率。简而言之,本文中的学习动态旨在回答以下问题:
基于样本
进行梯度下降更新后,模型对样本
的预测会发生怎样的变化?
就是说,在训练集梯度下降后,对测试集的预测有什么影响
学习动态有助于阐明深度学习中的诸多重要问题,同时也能解释各类反直觉现象。其根源可能与神经网络的 “刚性”(stiffness,Fort et al., 2019)或 “局部弹性”(local elasticity,He & Su, 2020; Deng et al., 2021)相关,更多讨论详见附录 A。
作为热身,我们首先考虑一个标准监督学习问题:模型学习将输入x映射到预测结果y={y1,...,yL}∈VL(其中V为词汇表,规模为V)。
输入x是一句prompt,y是输出,由L个token组成
模型通常先生成对数几率(logits)矩阵,再对每一列执行 Softmax 操作以输出概率分布。我们可通过观测
来追踪模型置信度的变化。
单步影响分解
式(1)对应的学习动态可表示为:
(2)
为简化分析,我们先从L=1的场景入手 —— 此时Δθ与Δlogπ的关联可通过下述结论建立(该结论是 Ren 等人(2022)研究结果的一个版本,证明及详细讨论见附录 B)。对于多标签分类(L>1),更新过程相互独立,我们可计算L个不同的Δlogπt并堆叠组合。
命题 1 设,则单步学习动态可分解为:
(3)其中:
(I为单位矩阵,1为全 1 向量);
,是对数几率网络z的经验神经正切核(empirical neural tangent kernel, eNTK);(模型在 测试样本x_o 处的梯度与在 训练样本x_u 处的梯度的内积。)
。 (训练集上损失函数对 Logits 的梯度)
测试集表现的变化 = 学习率 * 投影 *关联性 * 训练集错误率
At(xo)=I−1πθt⊤(xo)仅依赖模型当前的预测概率;矩阵Kt是模型的经验神经正切核(eNTK, Jacot et al., 2018),由模型对xo和xu的梯度乘积构成。本文的分析基于以下假设:
训练过程中,学习样本xu对所有其他不同样本xo的相对影响保持相对稳定。
Arora 等人(2019)讨论的常见 “惰性 eNTK”(lazy eNTK)假设是本文假设的充分非必要条件。附录 C 针对 MNIST 和 LLM 场景提供了更详细的讨论及实验验证。我们可将Kt视为模型特有的输入样本相似度度量:(Frobenius 范数)越大,说明样本xu的更新对模型预测xo的影响可能越强。最后,Gt由损失函数L决定,为模型的适配提供能量和方向。例如,对于交叉熵损失LCE≜−yu⊤logπ(y∣xu),有GCEt=πθt(y∣xu)−yu—— 这是一个长度为V的向量,指向从模型当前预测分布到目标监督分布的方向。对于典型的 “硬标签”,yu为独热向量eyu。
累积影响及 MNIST 示例
命题 1 描述了单步学习中,样本xu的更新如何改变模型对xo的预测。由于实际模型需经过多步参数更新,探究这些单步影响随时间的累积效应至关重要。我们首先以在 MNIST 数据集(LeCun et al., 1998)上训练 LeNet 模型为例进行分析。
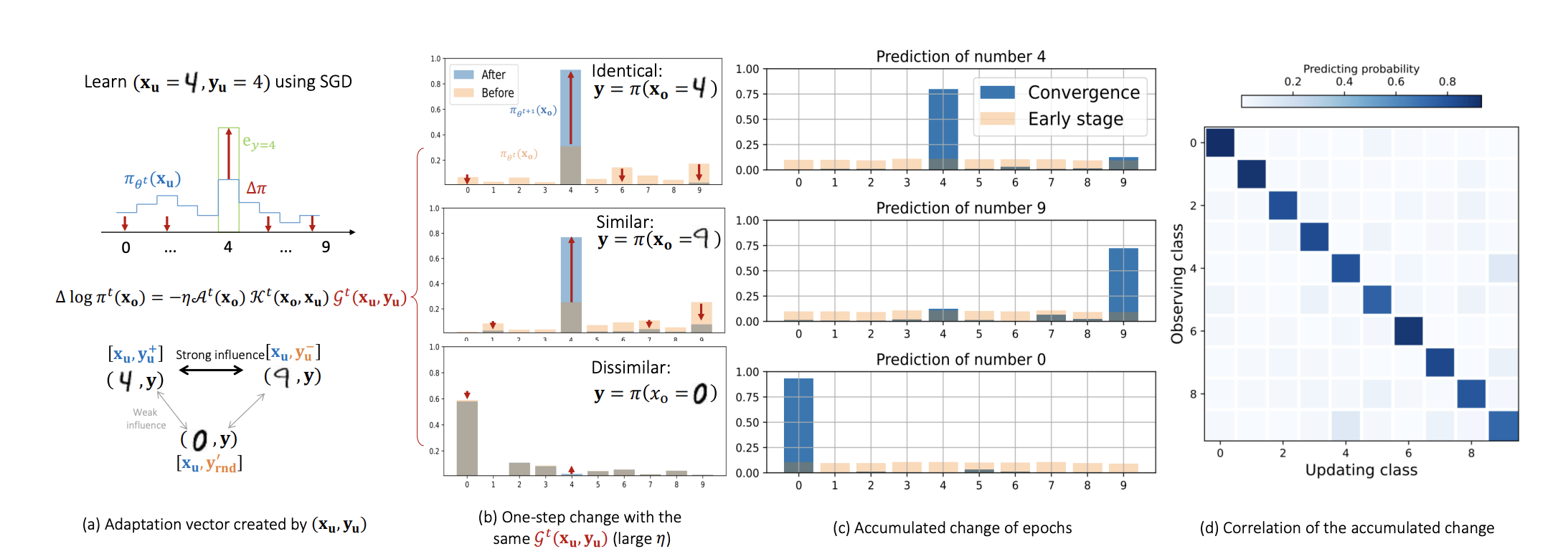 如图 1-(a) 所示,网络πθt基于单个训练样本(xu,yu=4)计算的损失更新参数。此时,残差项
如图 1-(a) 所示,网络πθt基于单个训练样本(xu,yu=4)计算的损失更新参数。此时,残差项由红色箭头表示,所有箭头均始于πθt(y∣xu)并指向e4。我们进一步探究该更新后模型对不同xo的预测变化:
- 如图 1-(b) 上半部分所示,若xo与xu属于同一类别(即完全一致场景),则该正确标签的预测概率会如预期般被 “拉高”;
- 若xo与xu相似(即
处于合理较大值)但属于不同类别,则xu所属类别的预测概率(非xo的正确标签)会被 “拉高”,如图 1-(b) 中间部分所示;(9很像4,所以测试9的时候,预测成4的概率会被错误地提高)
- 若xo与xu差异较大(
不同输入样本的更新交互,最终形成了有趣的预测模式。如图 1-(c) 所示,当对类别 4 的图像进行预测时,模型倾向于给类别 9 分配更高的置信度 —— 这是因为类别 9 的样本平均而言比其他类别的样本更接近类别 4。因此,类别 4 和类别 9 样本的更新会强化彼此的相互影响,导致其预测概率升高。为验证这一点,我们在图 1-(d) 中绘制了各类别样本x对应的π(y∣x)平均值:部分非对角区域的值显著高于其他区域,表明这些类别的样本更为相似(例如 4 和 9、5 和 3、8 和 5 等)。
3 大语言模型微调的学习动态
尽管学习动态已被应用于诸多深度学习系统,但将这一框架扩展至大语言模型(LLM)微调并非易事。首先面临的问题是输入与输出信号的高维度性和序列特性:高维度使得模型输出难以观测,而序列特性导致不同 token 的分布相互依赖,这比以往多数研究关注的标准多标签分类问题更为复杂。此外,LLM 微调算法种类繁多(如 SFT(Wei et al., 2022)、RLHF(Ouyang et al., 2022)、DPO(Rafailov et al., 2023)等),要在统一框架下对其进行分析颇具挑战性。最后,与从头训练(通常假设所有可能输出服从大致均匀分布)不同,LLM 的微调动态严重依赖预训练基础模型,这进一步增加了分析难度 —— 例如,预训练模型通常会给可能性极低的 token 分配极少的概率质量,这对多数应用而言是有利的,但会引发后文将阐述的 “挤压效应” 风险。针对这些问题,我们提出了一个适用于不同微调方法的统一框架。
3.1 监督微调(SFT)损失的单步分解
监督微调(SFT)中常用的损失函数是给定补全序列yu+=[y1+,...,yL+]∈VL在提示词xu条件下的负对数似然(NLL):
(4)
需注意的是,此前讨论的多标签分类问题中,所有标签的联合分布可分解为,而语言建模的序列特性使得分析更为复杂 —— 必须满足
(即第l个 token 的预测依赖前文 token)。为解决这一问题,我们在保留命题 1 格式的前提下,将该分解融入骨干网络hθ的定义中:具体而言,令
为x与y的拼接,那么对y中所有 token 的预测可表示为:
其中,z是一个V×L矩阵,每一列包含第l个 token 的预测对数几率(logits)。尽管hθ接收整个序列χ作为输入,但通过 “因果掩码”(causal masking,由 Vaswani 等人(2017)提出,详见附录 D 图 10a)的实现,可强制模型在预测第l个 token 时不参考未来 tokeny>l。随后,我们可对z的每一列计算,并将其堆叠形成一个V×V×M×L张量Kt(χo,χu);Gt和At的计算也遵循类似流程。得益于hθ中实现的因果掩码,最终的分解形式与多标签分类问题几乎一致。
假设与xu关联的响应yu长度为L(拼接为χu),与xo关联的响应yo长度为M(拼接为χo),则当z的梯度范数有界时,模型对yo第m个 token 的预测变化可表示为:(5)
其中,GSFTt(χu)=πθt(y∣χu)−yu。与命题 1 相比,核心差异在于经验神经正切核(eNTK)项同样依赖响应yu和yo,这使得我们能够回答诸如 “对于提示词xu,学习响应yu+如何影响模型对另一个响应yu′的置信度” 这类问题。
X里包含x和y,所以和1相比,训练集对测试集的影响不仅取决于训练集的输入x,还取决于y
和上面的minst对比,y就是一个数字4,你没办法评判4是好坏,是否优雅,他只是一个固定的死标签。
相比之下在LLM自回归中,它的y是很复杂多样的。比如对于同一个输入x=怎么去火车站
两种风格的y:
1. y=“直走左转。”(简洁风),2.y=“亲爱的旅客,您先向前走,到路口...”(礼貌风)
即便 x 一模一样,因为 y 不同,模型在更新参数时,eNTK 就会记录下这种“风格”的梯度。
当追踪模型对提示词xu不同响应的置信度时,从yu+中学习会对yu+本身施加强烈的 “向上” 压力(如图 2 第一面板所示);同时,“相似响应” 的置信度也会被轻微拉高 —— 这与 MNIST 示例中学习 “4” 会影响对 “9” 的预测类似。下一节将详细讨论如何理解两个响应序列之间的 “相似性”。
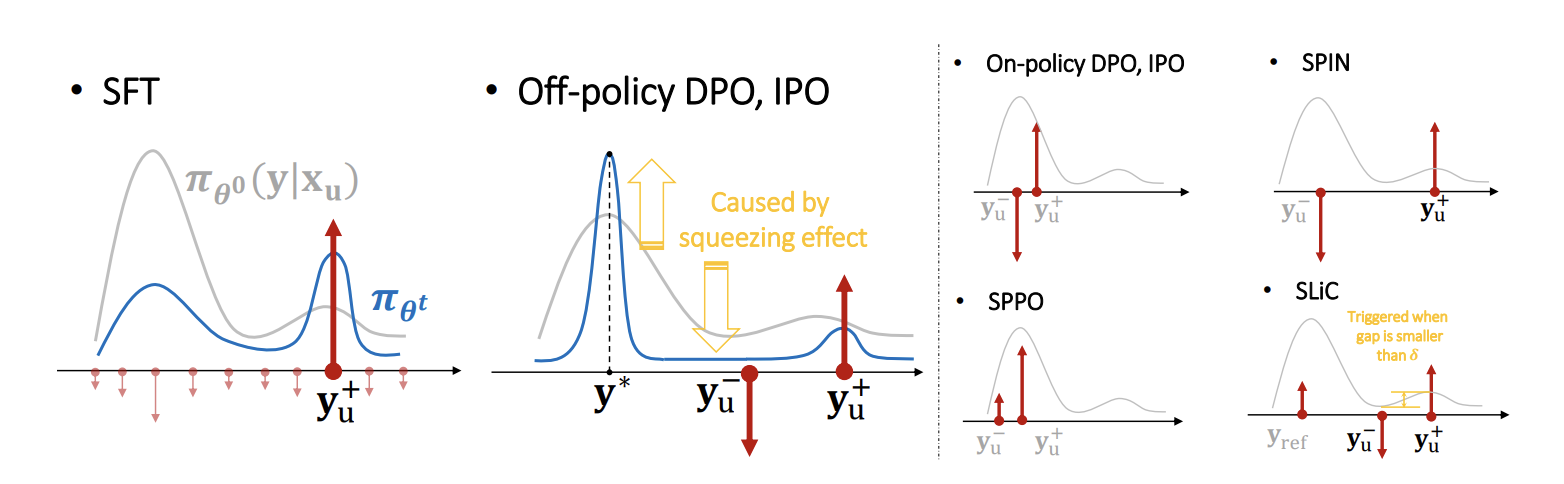
3.2 直接偏好优化(DPO)损失的单步分解
偏好微调(Preference finetuning)的目标是教会模型生成更符合人类偏好的响应,它也是大语言模型(LLM)微调流程中的重要阶段。与前文的监督微调(SFT)阶段不同 ——SFT 仅告知模型 “该做什么”,许多偏好微调方法还会明确教会模型 “不该做什么”,这使得其学习动态更为复杂。为便于理解,我们首先在类似框架下分析一种典型方法,即直接偏好优化(DPO,direct preference optimization),这是一种无需强化学习(RL-free)的算法。参考 Rafailov 等人(2023)的研究,离线 DPO(off-policy DPO)的损失函数如下:
(6)
其中,yu+和yu−是预生成的响应(分别为偏好响应和非偏好响应),πref是参考模型,通常为 SFT 的训练结果;和
共享相同的输入x,但对应不同的响应y。损失函数中,πθt项同样采用教师强制(teacher forcing)方式计算,因此我们可参照式(5)对 DPO 的学习动态进行分解:
其中,a是第l个 token 的间隔(margin),即σ(⋅)的输出值,用于衡量当前策略相较于参考策略对yu+和yu−的区分能力。由于σ(⋅)具有单调性,间隔越大,a的值越大,进而抑制GDPO+/−t的强度 —— 换句话说,对于已能良好区分的样本,GDPO+/−t会自动减少对其的更新力度。
接下来分析β的作用:它在原始强化学习损失中控制πθt与πref之间 KL 散度的正则化效果(Rafailov et al., 2023)。当间隔为负时,更大的β会使a减小,从而增强GDPO+/−t的强度,帮助模型更快 “追赶” 参考模型的区分能力;但当模型性能更优、间隔为正时,增大β会使a增大,进而对β(1−a)产生负面影响,导致模型更新幅度减小。这与 Rafailov 等人(2023)的观点一致:当πθ的预测与πref偏差过大时,更强的正则化效果会倾向于将πθ“拉回” 至πref的方向。其他无强化学习方法的梯度项Gt推导过程详见附录 B.2.2。
上述分析未对yu+和yu−的来源做任何假设,因此该框架可直接扩展至在线无强化学习方法 —— 这类方法通常比其离线版本性能更优(S. Guo, B. Zhang, et al., 2024; Tajwar et al., 2024)。这些算法的核心差异在于监督响应的生成方式:离线方法通常使用固定的预收集数据集,yu+和yu−由其他 LLM 或人类生成,也就是说,偏好响应和非偏好响应都可能来自模型预测的 “低概率区域”;而在线响应是从当前模型中采样得到的,因此在该模型下更可能具有较高的预测概率。下文将证明,在低概率预测上施加较大的负向压力会导致意外行为,这也为 “为何在线采样对含较大负梯度的算法至关重要” 提供了新的解释。
3.3 负梯度引发的挤压效应
如图 2 前两幅子图所示,是否使用较大负梯度是监督微调(SFT)与直接偏好优化(DPO)学习动态的核心差异。后文将证明,这一差异是理解 SFT 与 DPO 学习曲线为何存在显著差异的关键。例如,Pal 等人(2024)、Rafailov 等人(2024)及 Tajwar 等人(2024)的研究(以及本文图 4)均报告:执行 DPO 时,偏好响应yu+和非偏好响应yu−的置信度都会逐渐下降,而 SFT 过程中yu+的置信度极少降低。若在执行 DPO 前先对初始模型πθ0进行更长时间的微调,这一趋势会更为严重(Rafailov et al., 2024 的图 3 已报告,本文图 17 进一步验证)。此外,我们还发现:在 DPO 阶段,所有被追踪的πθt(y∣χu)(包括与yu+或yu−相似的各类响应,详见下一节)均未出现增长。这与 SFT 的表现截然不同,且颇具反直觉性:
若所有观测到的响应置信度都在下降,那么概率质量(probability mass)去向何方?
为解答这一问题,我们首先明确一种名为 “挤压效应”(squeezing effect)的现象 —— 该效应普遍存在于任何带有 Softmax 输出层、输出概率分布的模型中,即便在简单的多分类逻辑回归任务中,施加负梯度也会引发此效应。具体而言,当L=1(单标签场景)且对标签yu−施加负梯度时,模型预测分布πθt+1的变化可描述为以下特征:
- 确定性特征 1:yu−的置信度(即πθt+1(yu−))必然下降;
- 确定性特征 2:减少的概率质量会大量 “挤压” 至更新前置信度最高的输出:若
(排除yu−后置信度最高的标签),则πθt+1(y=y∗)必然上升;
- 趋势性特征 1:“富者愈富,贫者愈贫”:通常而言,πθt值较高的维度(置信度高)会进一步上升,而πθt值较低的维度(置信度低)会进一步下降;
- 趋势性特征 2:分布越陡峭(peakier),挤压效应越强:若πθt的概率质量集中于少数几个维度(预训练模型的常见特征),则所有πθt+1(y=y∗)都会下降(仅y∗为 “富者”);
- 趋势性特征 3:
越小,挤压效应越显著:若
在
中属于低概率标签,则所有其他
的概率质量会下降得更严重,而
的增长幅度会更大。
附录 E 通过直接计算不同场景下πθt+1/πθt的比值,以逻辑回归模型为例直观展示了挤压效应,并通过解析方式证明了其存在性;4.2 节还在真实大语言模型(LLM)实验中对上述分析进行了实证验证。需注意的是,在实际场景中,若同时考虑正向压力、负向压力及自回归特性,挤压效应会变得更为复杂:式(7)中两个经验神经正切核(eNTK)项的差异也会影响这两种压力的相对强度与方向。Razin 等人(2025)在 token 级场景下分析了类似问题,其结论与本文高度一致,更详细的交互分析留待未来研究。
结合上述分析,我们可对典型离线 DPO 算法的学习动态形成宏观认知:由于yu+和yu−均非从当前模型分布中采样得到,y∗(模型置信度最高的输出)有时可能与yu+(人类偏好响应)差异较大,且yu−很可能处于模型预测的 “谷值区域”(低概率区域)。此时其学习动态将如图 2 第二幅子图所示:几乎所有响应的置信度都会被压低,同时减少的概率质量全部挤压至y∗—— 这可能导致模型持续生成重复短语,正如 Holtzman 等人(2020)所报告的现象。DPO 的各类变体往往通过限制负梯度强度或优化yu−的选取位置,无意间缓解了挤压效应,这也在一定程度上解释了这些变体的性能优势。更多细节详见图 2 后四幅子图及附录 B.2.2。
4 实验验证
本节在实际场景中验证上述分析结论。我们首先从数据集的训练集中随机选取 5000 个样本构建训练集Dtrain,实验均采用两个常用数据集:Anthropic-HH(Y. Bai et al., 2022)和 UltraFeedback(G. Cui et al., 2023)。Dtrain中的每个样本包含三部分:提示词(或问题)x、偏好响应y+和非偏好响应y−。监督微调(SFT)仅使用x和y+进行训练,而直接偏好优化(DPO)则使用全部三部分(为简洁起见,省略x和y的下标)。实验在两类模型上重复进行:Pythia 系列(410M/1B/1.4B/2.8B,Biderman et al., 2023)和 Qwen1.5 系列(0.5B/1.8B,J. Bai et al., 2023)。
为更细致地观测学习动态,我们进一步从Dtrain中随机选取 500 个样本构建探测数据集Dprob,并基于对应的x、y+或y−生成多种典型响应(附录的消融实验中还研究了另一个所有x均来自测试集的探测数据集)。对于Dprob中的每个x,我们可观测模型对不同类型响应y的logπθt(y∣χ)如何逐步变化。例如,扩展响应类型包括y+的改写版本、回答其他问题x′的无关响应,或与y+单词数量相同的随机生成英文句子。附录 D.1 详细解释了生成这些扩展响应的原因及方法。简而言之,Dprob帮助我们对学习动态进行更细粒度的考察,不仅能支撑上述分析,还能进一步揭示模型在整个稀疏且庞大的响应空间Y∈RV×L中的预测演化过程。
4.1 监督微调(SFT)的学习动态
从 3.1 节的分析中可得出核心结论:从yu+中学习不仅会提高模型对yu+的置信度,还会以较弱的强度(大致由∥Kt∥F缩放)间接 “拉高” 与yu+相似的响应 —— 这与 MNIST 示例中学习 “4” 会影响对 “9” 的预测类似。同时,πθt(yu+∣χu)的提升会自然地 “压低” 所有的置信度,因为模型对所有响应的预测概率之和必须为 1。模型对不同响应的行为主要是这些压力之间的权衡结果。
为验证这一结论,我们对模型进行多轮微调,并每更新 25 次(批次大小为 4,即每训练 100 个样本)就评估模型对Dprob中所有响应的预测结果。对于每种响应类型,我们计算 500 个样本上的模型置信度平均值,并报告其对数似然(log-likelihood)的均值。
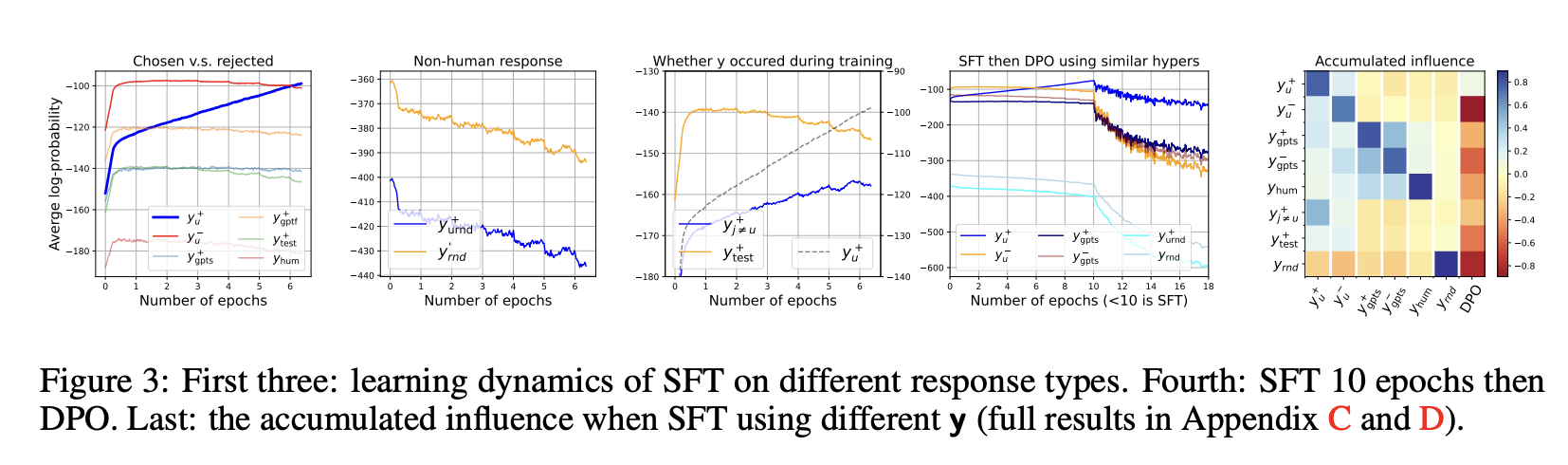 如图 3 第一面板所示,模型对yu+的置信度在整个学习过程中持续上升 —— 这一结果符合预期,因为 “拉高” 压力直接作用于yu+。然而,部分与yu+相似的响应的行为却并非显而易见:我们在同一面板中绘制了以下响应类型的置信度变化:同一问题的非偏好响应yu−、ChatGPT 生成的两种yu+改写版本(ygpts+和ygptf+)、从测试集中随机选取的另一个偏好响应ytest+,甚至是随机生成的英文句子yhum。尽管这些响应在 SFT 训练过程中从未被模型见过,但它们的置信度在训练初期均略有上升,随后随着训练推进逐渐下降。这一反直觉现象可通过前文讨论的学习动态很好地解释:由于这些响应在某种程度上与yu+“相似”(至少均为符合规范的英文句子),它们的∥Kt∥F处于合理的较大值,因此学习yu+会间接提高这些相似响应的置信度 —— 这也是训练初期对应πθt(y∣χu)略有上升的原因。但随着训练推进,模型对yu+的置信度持续提升,而式(5)中GSFTt的范数(即更新能量)逐渐减小,间接 “拉高” 压力也随之减弱。此时,对所有y=yu+的 “压低” 压力占据主导,所有相关曲线开始下降。
如图 3 第一面板所示,模型对yu+的置信度在整个学习过程中持续上升 —— 这一结果符合预期,因为 “拉高” 压力直接作用于yu+。然而,部分与yu+相似的响应的行为却并非显而易见:我们在同一面板中绘制了以下响应类型的置信度变化:同一问题的非偏好响应yu−、ChatGPT 生成的两种yu+改写版本(ygpts+和ygptf+)、从测试集中随机选取的另一个偏好响应ytest+,甚至是随机生成的英文句子yhum。尽管这些响应在 SFT 训练过程中从未被模型见过,但它们的置信度在训练初期均略有上升,随后随着训练推进逐渐下降。这一反直觉现象可通过前文讨论的学习动态很好地解释:由于这些响应在某种程度上与yu+“相似”(至少均为符合规范的英文句子),它们的∥Kt∥F处于合理的较大值,因此学习yu+会间接提高这些相似响应的置信度 —— 这也是训练初期对应πθt(y∣χu)略有上升的原因。但随着训练推进,模型对yu+的置信度持续提升,而式(5)中GSFTt的范数(即更新能量)逐渐减小,间接 “拉高” 压力也随之减弱。此时,对所有y=yu+的 “压低” 压力占据主导,所有相关曲线开始下降。
为验证全局 “压低” 压力的存在,我们观测了两种与yu+单词数量相同的响应:一种是纯粹的随机英文单词序列yrnd′,另一种是yu+所有单词的随机排列(记为yurnd+)。由于这两种响应均非自然语言,我们预期它们与yu+的∥Kt∥F会非常小 —— 这意味着从yu+中学习几乎不会对它们施加 “拉高” 压力,因此 “压低” 压力将在整个训练过程中占据主导。图 3 第二面板的结果充分支持了这一分析:这些响应的πθt(y∣χu)均从极低值开始,并在训练过程中持续下降。
另一类有趣的响应是(训练集中另一个问题
的偏好响应)。模型对
的预测会持续受到两种 “拉高” 压力的影响:一种来自对
的学习,另一种来自对
的学习 —— 后者的压力可能更强,因为梯度是通过直接观测
计算得到的。这也解释了为何图 3 第三面板中
的置信度持续上升,但增速低于yu+:其 “拉高” 压力始终足以抵消 “压低” 压力。这些观测结果为 SFT 后特定类型幻觉(hallucination)加剧提供了独特解释:
的提升意味着,当向模型询问问题
时,它可能会输出(或部分输出)训练集中另一个无关问题
的响应。
解释了幻觉的存在,正常情况下概率应该是先升后降,可实际上确实持续走高,这就说明学习其他的内容时无意带动了他的上升,从而始终能够抵消下压的力量,使得对该答案的回答错误地一直拉高,从而产生幻觉。
最后,为进一步从模型视角探究不同响应之间的 “相似性”,我们使用更多类型的响应进行 SFT,并观测πθ(y′∣χu)的相应变化。结果如图 3 所示(蓝色和橙色分别代表正向影响和负向影响):横轴为更新响应,纵轴为观测响应,因此第一列展示了使用[xu;yu+]进行 SFT 时,不同[xu;y′]的变化情况。一个有趣的发现是:无论语义差异多大,所有 ChatGPT 生成的响应都被模型视为高度相似。这可能是因为大语言模型(LLM)存在偏好的惯用表达或短语,可将其视为一种 “指纹” 特征。这一有趣问题留待未来研究。
4.2 离线直接偏好优化(DPO)的学习动态
为验证我们的框架同样能解释偏好微调中的模型行为,我们针对 DPO 开展了类似实验。回顾前文可知,DPO 的残差项GDPOt会对偏好响应yu+和非偏好响应yu−施加一对方向相反的 “压力箭头”。为展示这两种压力对模型的影响,我们观测了yu+和yu−的两种改写版本(即前序实验中使用的ygpts+、ygptf+、ygpts−和ygptf−)。
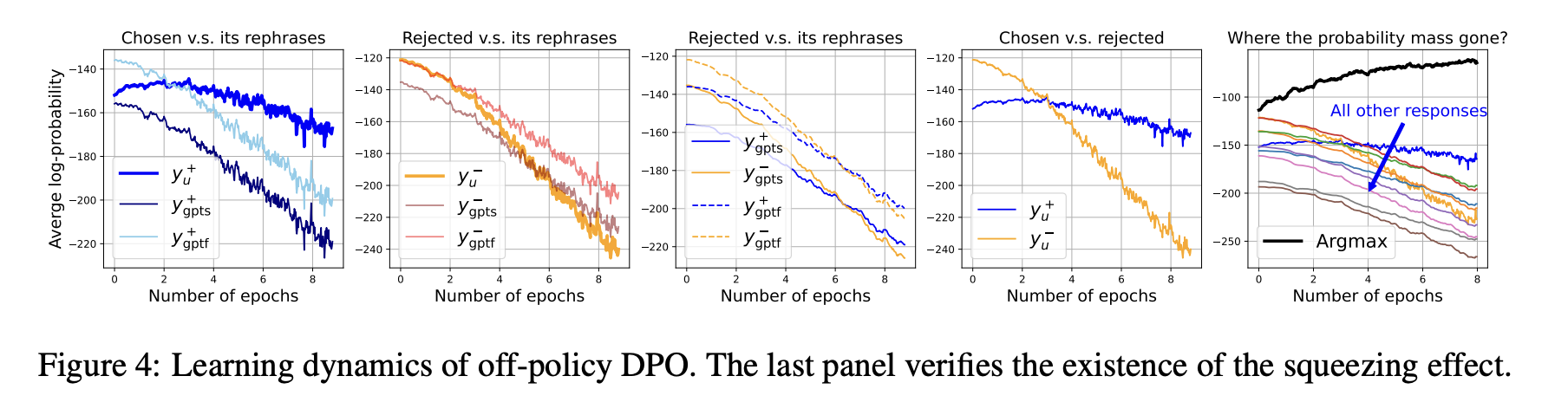 如图 4 第一面板所示,两种yu+改写版本的置信度下降速度相近,且快于yu+本身的下降速度 —— 这是因为 “拉高” 压力直接作用于yu+,而非这些改写版本。类似地,第二面板显示yu−的置信度下降速度快于其改写版本,原因是GDPOt直接对yu−施加了 “压低” 压力。第三面板则表明,尽管这些改写版本在训练过程中从未出现,但yu+改写版本的置信度下降速度始终慢于yu−改写版本 —— 这是因为这些响应在响应空间Y中与yu+或yu−较为接近,即它们的∥Kt∥F相对较大,因此施加于yu+和yu−的压力也会对它们产生不可忽视的影响。最后,第四面板显示,yu+与yu−的置信度差值(πθt(yu+∣χu)−πθt(yu−∣χu))持续增大,表明随着训练推进,模型对两类响应的区分能力不断提升。
如图 4 第一面板所示,两种yu+改写版本的置信度下降速度相近,且快于yu+本身的下降速度 —— 这是因为 “拉高” 压力直接作用于yu+,而非这些改写版本。类似地,第二面板显示yu−的置信度下降速度快于其改写版本,原因是GDPOt直接对yu−施加了 “压低” 压力。第三面板则表明,尽管这些改写版本在训练过程中从未出现,但yu+改写版本的置信度下降速度始终慢于yu−改写版本 —— 这是因为这些响应在响应空间Y中与yu+或yu−较为接近,即它们的∥Kt∥F相对较大,因此施加于yu+和yu−的压力也会对它们产生不可忽视的影响。最后,第四面板显示,yu+与yu−的置信度差值(πθt(yu+∣χu)−πθt(yu−∣χu))持续增大,表明随着训练推进,模型对两类响应的区分能力不断提升。
尽管GDPOt直接对yu+施加 “拉高” 压力,但πθt(yu+∣χu)的增长幅度远不及 SFT 场景。对yu−的 “压低” 压力固然会影响与其相似的响应,但这种影响的强度(经∥Kt∥F缩放后)不足以解释为何几乎所有观测响应的置信度都下降得如此之快 —— 尤其在 SFT 和 DPO 使用相近学习率η的情况下(如图 3 最后面板所示)。那么,DPO 过程中的概率质量究竟去向何方?答案正是 3.3 节讨论的 “挤压效应”:由于yu−通常处于模型预测的低概率区域,对其施加较大负梯度会导致大多数响应的置信度下降,而置信度最高的响应y∗的置信度则会快速上升。
为验证这一点,我们报告了贪心解码(greedy decoding)所选响应y的对数似然:每个 token 的选择均基于实时最大化给定[xu;y<l+](y<l+为yu+的前缀子序列)的条件概率。如图 4 最后面板所示,这种 “教师强制” 式贪心响应的置信度在 8 个 epoch 内快速上升(从 - 113 升至 - 63),甚至快于 SFT 过程中πθt(yu+∣χu)的增长速度(从 - 130 升至 - 90)。然而,置信度最高的 token 组合未必是人类偏好的响应 —— 它会强化初始参数θ0中的先验偏差。这为近期研究中报告的 “生成退化” 现象(如 Holtzman et al., 2020)提供了合理解释:随着πθt在高置信度预测上愈发陡峭,模型更容易生成包含重复短语的序列。需注意的是,这种行为也可被视为一种特殊的自偏差放大(self-bias amplifying,Ren et al., 2024)—— 若与多轮生成自改进算法(如自奖励(self-reward,Yuan et al., 2024)、迭代 DPO(iterative DPO,Xiong et al., 2024)等)结合,可能会引发更严重的后果。
综上,不同类型响应的行为均与我们的分析高度一致,各类响应的细微变化趋势也进一步支撑了我们的理论(包括 SFT 和 DPO 场景)。受篇幅限制,更多细节(及其他模型和数据集的完整结果)详见附录 D。
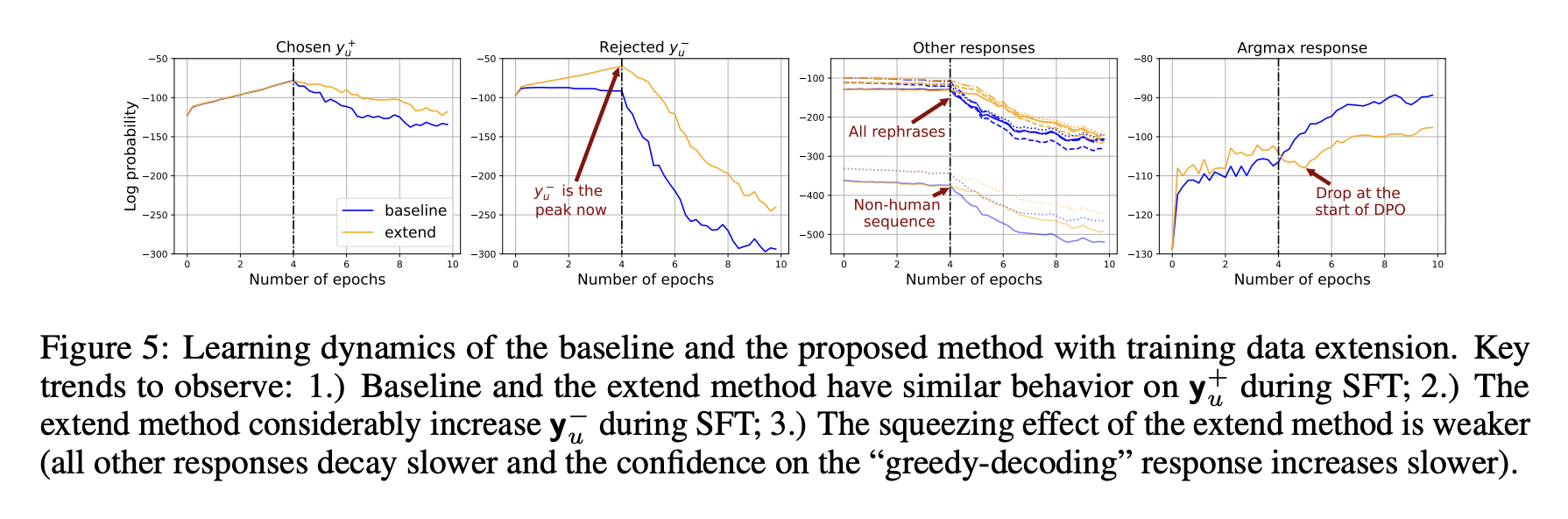
4.3 通过扩充监督微调(SFT)训练集缓解挤压效应
由于对低概率预测施加较大负梯度所引发的 “挤压效应” 会损害直接偏好优化(DPO)阶段的模型性能,我们提出:在 SFT 阶段同时使用[xu;yu+]和[xu;yu−]训练模型(提高非偏好响应yu−的概率),之后再执行常规 DPO。根据前文分析,在这种改进后的 SFT 阶段,与yu+或yu−相似的响应区域将同时被 “拉高”—— 这正是我们期望的结果:在许多场景中,yu+和yu−对问题xu而言都是合理的良好响应,因此与基准 SFT 相比,新的 SFT 设计能拉高更大范围的响应区域,涵盖更多合适的响应。在此基础上,DPO 阶段施加的 “压低” 压力可有效降低模型对yu−及其相似响应的置信度;而由于 DPO 执行前yu−已不再是低概率响应,挤压效应的强度将显著弱于基准流程。
我们将这种训练流程命名为 “extend”(扩充式训练),并在图 5 中对比了其与基准设置的学习动态。结果表明,挤压效应得到了明显缓解:DPO 阶段其他响应的置信度下降速度均变慢,且 DPO 启动时贪心解码响应的置信度出现显著下降。为进一步验证缓解挤压效应确实能带来性能提升,我们将不同方法训练的模型生成的响应输入 ChatGPT 和 Claude3 进行对比评估:具体而言,我们首先采用上述两种方法对模型进行 2 个 epoch 的 SFT,得到策略网络πbase(基准方法)和πextend(扩充式方法);随后对两者执行完全相同的多轮 DPO 训练。表 1 展示了所提方法相对于基准方法的胜率 —— 显然,DPO 执行前πbase性能更优(因为πextend明确训练了非偏好响应y−);但经过多轮 DPO 后,由于挤压效应得到有效缓解,πextend的性能反超基准方法。更多细节详见附录 F。
巧妙的解决方法,本来SFT只教好答案,导致坏答案概率压得很低。这样再进行DPO就会给他施加很高的负梯度,从而产生挤压效应,把周围的无辜答案都给震死了,只剩下一个模型自己悟出来的,和好答案坏答案都不一样的输出。
因此,不妨在SFT时就把坏答案也喂进来,这样坏答案的概率也可以拉到一个中高范围,再进入DPO,效果会好很多了。
未来,受本分析启发,这一简单方法可进一步优化:在 SFT 和 DPO 两个阶段引入更多类型的响应(如yu+的改写版本等),或与前文提及的多种无强化学习(RL-free)方法相结合。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)