OpenSWE:147 万美元打造最大开源 SWE 训练环境,45k Docker 环境助力代码 Agent 登顶 SWE-bench
OpenSWE:147 万美元打造最大开源 SWE 训练环境,45k Docker 环境助力代码 Agent 登顶 SWE-bench
一句话总结:GAIR-NLP 团队斥资 147 万美元,构建了 OpenSWE——迄今最大的开源软件工程智能体训练框架,包含 45,320 个可执行 Docker 环境、覆盖 1.28 万个代码仓库,全部基础设施完全开源。基于此训练的 OpenSWE-72B 在 SWE-bench Verified 上达到 66.0%,刷新了 Qwen2.5 系列的 SOTA 记录。
📋 论文信息
- 标题:daVinci-Env: Open SWE Environment Synthesis at Scale
- 作者:Dayuan Fu, Shenyu Wu, Yunze Wu, Zerui Peng, Yaxing Huang, Jie Sun, Ji Zeng, Mohan Jiang, Lin Zhang, Yukun Li, Jiarui Hu, Liming Liu, Jinlong Hou, Pengfei Liu(共 14 人)
- 机构:GAIR-NLP
- 发布日期:2026年3月13日(v1),2026年3月16日(v2)
- 开源资源:
- 🔗 项目主页:GitHub - GAIR-NLP/OpenSWE
🎯 147 万美元的"疯狂":为什么要花这么多钱造数据?
在代码智能体领域,有一个残酷的现实:数据是最贵的资产。
想象一下训练一个能修 Bug 的 AI Agent。它不仅要能读懂代码,还要能:
- 理解 issue 描述
- 定位问题代码
- 编写修复补丁
- 确保测试通过
这意味着训练数据不能是静态的"输入-输出"对,而必须是可执行、可验证的完整环境——Agent 写完代码后,能真正跑一遍测试,知道自己改对了没有。
问题是:这种环境从哪来?
看看现有的开源数据集:
| 数据集 | 任务数 | 仓库数 | 问题 |
|---|---|---|---|
| SWE-bench | 2,294 | 12 | 仓库太少,容易过拟合 |
| SWE-rebench | ~19k | ~1k | 规模有限 |
| OpenSWE | 45,320 | 12,800 | ✅ 最大规模 |
工业界当然有更多数据(比如 OpenAI、Anthropic 内部肯定有海量代码修复轨迹),但他们不会公开。结果就是:学术界想训练一个像样的代码 Agent,连数据都找不到。
OpenSWE 的目标很简单:用钱砸出一个学术界能用的大规模 SWE 训练环境,然后全部开源。
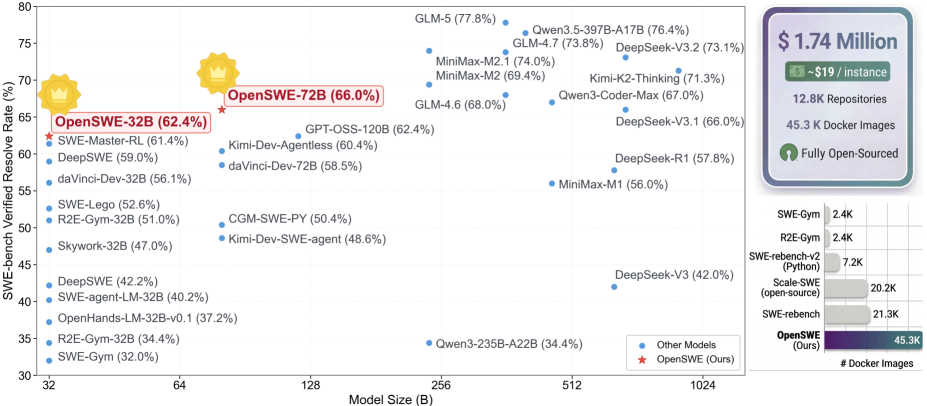
图1:OpenSWE 的完整流水线——从 GitHub PR 收集到环境构建、质量过滤、轨迹采样,最终产出高质量训练数据
📖 SWE-bench 是什么?为什么它这么重要?
在聊 OpenSWE 之前,得先说说它的"考场"——SWE-bench。
2024 年 8 月,OpenAI 发布了 SWE-bench Verified,这是软件工程智能体领域最权威的基准测试。它的任务设定是:
- 输入:一个代码仓库 + 一个 issue 描述(比如"某个函数在处理空列表时会报错")
- 输出:一个能修复这个 issue 的代码补丁
- 验证:运行仓库的测试套件,看补丁是否真的修复了问题
这个任务难在哪?
- 仓库很大:动辄几十万行代码,Agent 要在茫茫代码海中定位问题
- 上下文很长:理解一个 Bug 可能需要读懂多个文件、多个类的交互
- 验证很严格:不是"看起来对"就行,必须通过真实的测试用例
到了 2026 年,前沿模型在 SWE-bench Verified 上的分数已经突破 60%。OpenSWE 训练的模型拿到了 66.0%,这是什么概念?每 3 个真实世界的 Bug,AI 能独立修好 2 个。
🧠 核心挑战:为什么造 SWE 环境这么难?
表面上看,造 SWE 训练数据不就是"找一堆 GitHub PR,然后把它们包装成 Docker 环境"吗?
实际上,这里面坑多到你怀疑人生。
坑1:依赖地狱
每个 Python 项目都有自己的依赖环境。你可能遇到:
- 这个库需要 Python 3.7,那个库需要 3.10
- 某个依赖的某个版本已经从 PyPI 下架了
- 两个依赖互相冲突
让 AI 自动写 Dockerfile 来配置这些环境?99% 的情况会失败。
坑2:测试不靠谱
GitHub PR 里自带的测试可能:
- 太脆弱,换个环境就挂
- 测试覆盖不全,修补丁通过了但实际上没改对
- 依赖外部服务(比如数据库、API),在 Docker 里跑不起来
坑3:Issue-PR 不对齐
很多 PR 的 issue 描述写得很模糊,比如"修复了一些问题"。这种数据拿来训练 Agent,它学到的是什么?学到了如何胡说八道。
坑4:难度不可控
有些 Bug 一眼就能看出来怎么改(太简单,没学习价值),有些 Bug 即使给人类专家也改不出来(太难,Agent 根本学不会)。
OpenSWE 的贡献就是:系统性地解决了这些问题,并把整个流水线开源出来。
🔧 方法详解:多智能体合成流水线
OpenSWE 的核心是一套部署在 64 节点集群上的多智能体合成流水线。每一步都有专门的 Agent 负责:
Step 1:PR 收集与过滤
从 GitHub 收集 Python 仓库的 Pull Request,然后四阶段过滤:
| 阶段 | 过滤条件 | 目的 |
|---|---|---|
| 仓库可行性 | Stars ≥ 5 | 过滤掉低质量玩具项目 |
| 语言过滤 | 主语言为 Python | 聚焦 Python 生态 |
| Issue 要求 | PR 必须关联有具体描述的 issue | 确保有清晰的任务定义 |
| 实质性更改 | 排除仅改测试的 PR | 确保测试的是真实能力 |
Step 2:仓库探索 Agent
在写 Dockerfile 之前,需要先了解仓库的结构。探索 Agent 会:
- 浏览 README 和配置文件
- 搜索与环境配置相关的文档
- 总结安装和测试命令
这就像让 Agent 先"预习"一遍仓库,知道它大概长什么样。
Step 3:Dockerfile 构建 Agent
这是最难的一步。为了提高成功率,OpenSWE 做了几个工程优化:
基础镜像预构建:提前构建了覆盖 Python 2.7 到 3.14 的 openswe-python 基础镜像,避免每次都从头装 Python。
本地仓库缓存:用 COPY 命令注入代码,而不是 git clone,绕过 GitHub API 限制。
分层感知提示:指导 Agent 把稳定的底层(比如系统依赖)放前面,变化频繁的层(比如项目代码)放后面,利用 Docker 层缓存加速重建。
一个典型的 Dockerfile 生成过程:
Agent 输入:仓库结构 + README + requirements.txt + setup.py
Agent 输出:完整的 Dockerfile
Agent 思考过程:
1. 这个项目需要 Python 3.9,用 openswe-python:3.9 基础镜像
2. 发现 requirements.txt 里有 torch,需要安装 CUDA 依赖
3. setup.py 里有 C 扩展,需要装 gcc
4. 生成 Dockerfile...
Step 4:评估脚本构建 Agent
有了 Docker 环境,还需要知道怎么跑测试。评估脚本 Agent 负责:
- 定位与 issue 相关的测试文件
- 生成运行测试的 bash 脚本
- 如果原 PR 没有测试,还要合成新的测试用例
Step 5:环境验证
用一个简单但有效的规则验证环境是否可用:
1. 应用"仅测试补丁"(只包含测试代码的改动)→ 测试应该失败
2. 应用"完整补丁"(包含修复代码)→ 测试应该通过
只有两个条件都满足,才接受这个环境
这个验证逻辑确保了:环境确实能复现 Bug,且修复确实能解决 Bug。
Step 6:测试分析 Agent
对于验证失败的环境,分析 Agent 会诊断原因:
- Dockerfile 配置错误?→ 反馈给 Dockerfile Agent 重试
- 评估脚本有 Bug?→ 反馈给脚本 Agent 修改
- 环境本身不可解?→ 标记并丢弃
这个闭环迭代让成功率从第一轮的不到 10% 提升到了最终的 ~20%。

图2:多智能体协作的环境构建流水线——仓库探索、Dockerfile 构建、评估脚本生成、测试分析形成闭环迭代
📊 质量控制:难度感知的过滤流水线
有了 45k 个可执行环境还不够,还要确保这些环境的"训练价值"。
OpenSWE 用一个简单但有效的方法来评估难度:让模型尝试解决,看成功率。
用 GLM-4.7 模型在每个环境上跑 4 次:
- 4 次全失败:太难了,Agent 学不会 → 丢弃
- 4 次全成功:太简单了,没学习价值 → 丢弃
- 1-3 次成功:难度适中,保留
最终从 ~45k 环境中筛选出约 9,000 个高质量环境,生成约 13,000 条训练轨迹。
🧪 实验结果:登顶 SWE-bench
主要结果
| 模型 | 参数量 | SWE-bench Verified |
|---|---|---|
| Qwen2.5-Coder-Instruct | 32B | 41.2% |
| SWE-Master | 32B | 57.8% |
| daVinci-Dev | 32B | 55.3% |
| OpenSWE | 32B | 62.4% |
| daVinci-Dev | 72B | 58.5% |
| OpenSWE | 72B | 66.0% |
OpenSWE-32B 比同规模的 SWE-Master 高出 4.6%,OpenSWE-72B 比 daVinci-Dev-72B 高出 7.5%。
数据扩展分析
一个有趣的发现是:训练数据越多,效果越好,而且还没有饱和。
论文画出了 Pass@1 随训练步数的变化曲线,发现是近似对数线性的增长( y = a ⋅ log ( x ) + b y = a \cdot \log(x) + b y=a⋅log(x)+b),相关系数高达 0.99。
这意味着什么?如果继续扩展 OpenSWE 的规模,模型效果还会继续提升。
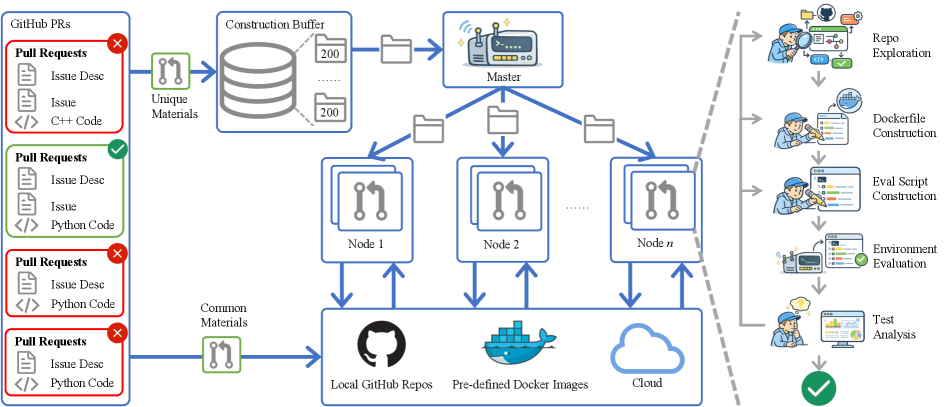
图3:Pass@1 随训练步数呈对数线性增长,且未观察到饱和迹象——继续扩展数据集将带来额外收益
跨域迁移能力
最让我惊讶的是:在 SWE 数据上训练,数学能力也提升了。
| 基准 | Qwen2.5-72B-Base | OpenSWE-72B | 提升 |
|---|---|---|---|
| GSM8K | 86.3 | 94.5 | +8.2 |
| MATH-500 | 73.4 | 85.6 | +12.2 |
| HumanEval | 51.8 | 82.9 | +31.1 |
这说明什么?代码调试能力和推理能力是相通的。训练 Agent 修 Bug 的过程,实际上也在训练它的逻辑推理、多步规划、错误诊断等通用能力。
💰 成本分析:钱都花在哪了?
OpenSWE 项目总投资约 147 万美元,具体分布:
| 阶段 | 成本 | 说明 |
|---|---|---|
| 环境构建 | $891,000 | LLM API 调用(探索、Dockerfile、脚本生成) |
| 轨迹采样 | $376,000 | 让模型尝试解决每个环境 |
| 难度过滤 | $200,000 | 多次采样评估难度 |
| 总计 | ~$1,470,000 |
平均每个可执行环境的构建成本约 $19.66。
这个成本高吗?从学术界的角度看确实不低。但从工业界的角度看,这是在"打基础"——有了这套开源的基础设施,后续扩展的边际成本会大幅下降。
💡 我的观点与启发
1. 数据工程的胜利
这篇论文再次证明了:在 Agent 训练中,数据工程的重要性不亚于算法创新。
OpenSWE 没有提出什么花哨的新算法,它做的就是:
- 把 PR 收集流程标准化
- 把 Dockerfile 生成自动化
- 把质量过滤系统化
然后用钱和算力把规模堆上去。结果呢?直接登顶。
2. 多智能体协作的范式
OpenSWE 的流水线是一个很好的多智能体协作案例:
- 探索 Agent 负责"侦察"
- Dockerfile Agent 负责"搭环境"
- 脚本 Agent 负责"写测试"
- 分析 Agent 负责"诊断问题"
每个 Agent 只做一件事,但组合起来能完成复杂任务。这种分工协作的模式,在其他领域也可以借鉴。
3. 开源的价值
最让我感动的是:OpenSWE 把所有东西都开源了。
不只是模型权重,而是:
- 45k 个 Docker 环境
- 所有 Dockerfile
- 评估脚本
- 分布式构建基础设施
这意味着其他团队不需要再花 147 万美元从头造一遍。学术界真正能在这个基础上继续往前走。
4. 一些疑问
Q1:训练数据和测试数据有重叠吗?
OpenSWE 用的是 GitHub PR,SWE-bench Verified 也是从 GitHub 来的。虽然论文说做了去重,但具体怎么去的?如果训练数据里有和测试集高度相似的样本,模型可能只是在"背答案"。
Q2:147 万美元的可复现性?
虽然代码开源了,但如果我想复现整个流程,还是要花 147 万美元吗?有没有更经济的方案?
Q3:仓库分布的偏差?
12.8k 仓库看起来很多,但热门仓库(比如 Django、Flask)的样本肯定比冷门仓库多。这种分布偏差会不会导致模型在冷门项目上效果变差?
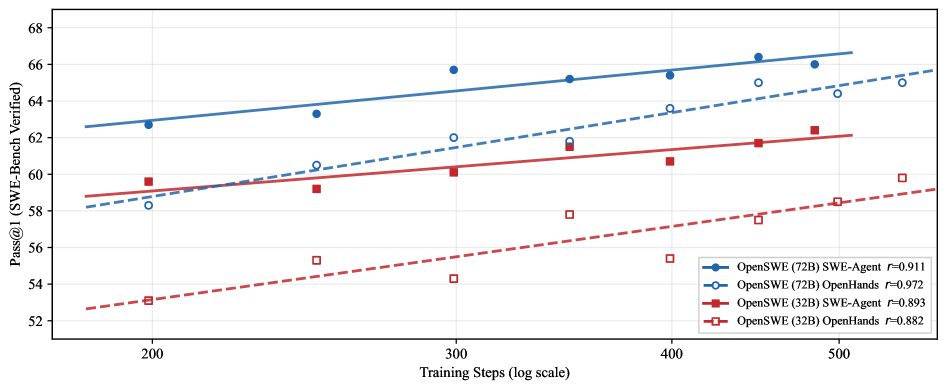
图4:OpenSWE 与其他数据集的规模对比——在任务数和仓库覆盖率上都远超现有开源数据集
🔗 与其他工作的对比
| 项目 | 任务数 | 仓库数 | 开源程度 | SWE-bench Verified |
|---|---|---|---|---|
| SWE-bench | 2.3k | 12 | 数据开源 | - |
| SWE-rebench | ~19k | ~1k | 数据开源 | ~55% |
| daVinci-Dev | ? | ? | 仅模型 | 58.5%(72B) |
| OpenSWE | 45.3k | 12.8k | 全开源 | 66.0%(72B) |
OpenSWE 在规模、开源程度、模型效果三个维度上都是最强的。
📝 总结
OpenSWE 这篇论文的贡献可以总结为三点:
- 规模突破:构建了迄今最大的开源 SWE 训练环境(45k 任务、12.8k 仓库),比现有数据集大一个数量级
- 全栈开源:不只是模型权重,而是把整个构建流水线、Docker 环境、评估脚本全部开源,真正做到"可复现"
- 效果验证:OpenSWE-72B 在 SWE-bench Verified 上达到 66.0%,刷新了 Qwen2.5 系列的 SOTA,且展现出强劲的跨域迁移能力
对于想做代码 Agent 的团队,OpenSWE 提供了一个非常好的起点。对于关心 AI 发展的读者,这篇论文揭示了一个重要趋势:在 Agent 训练中,可执行、可验证的环境数据,比静态的 QA 对有价值得多。
至于 147 万美元的投资值不值?我觉得值。因为这不是一次性消费,而是为整个开源社区建设基础设施。
📚 参考文献
- OpenSWE GitHub: https://github.com/GAIR-NLP/OpenSWE
- SWE-bench: https://swebench.com
- SWE-bench Verified: https://openai.com/research/swe-bench-verified
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我的微信公众号:机器懂语言

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)