OpenSeeker 论文解读:首个完全开源训练数据的前沿搜索 Agent,仅 11.7k 样本单次 SFT 即超越工业级系统
OpenSeeker 论文解读:首个完全开源训练数据的前沿搜索 Agent,仅 11.7k 样本单次 SFT 即超越工业级系统
一句话总结:上海交大团队开源了 OpenSeeker——首个完全公开训练数据的搜索 Agent,仅用 11.7k 合成样本、单次 SFT 训练就在 BrowseComp 等基准上超越了阿里通义 DeepResearch 等需要预训练+SFT+RL 的工业级系统,彻底打破了搜索 Agent 领域的"数据护城河"。
📋 论文信息
- 标题:OpenSeeker: Democratizing Frontier Search Agents by Fully Open-Sourcing Training Data
- 作者:Yuwen Du, Rui Ye, Shuo Tang, Xinyu Zhu, Yijun Lu, Yuzhu Cai, Siheng Chen
- 机构:上海交通大学
- 发布日期:2026年3月16日
- 开源资源:
🎯 一个灵魂拷问:为什么搜索 Agent 的数据这么稀缺?
想象一下这个场景:你想训练一个能像人类一样在网上"深挖"信息的 AI Agent——它需要能够多轮搜索、筛选信息、跨页面关联线索,最终找到那个藏在互联网角落里的答案。
听起来很酷对吧?但问题来了:数据从哪来?
传统的 QA 数据集(比如 SQuAD、TriviaQA)里的问题太简单了,一次 Google 就能搞定。而真正需要"深度搜索"能力的问题——比如"找到某部 1987 年电影中某个配角演员的出生地"——这种数据根本不存在。
更尴尬的是,即使有人造出了这样的数据,他们也不愿意公开。看看现在的玩家:
| 玩家 | 模型开源 | 数据开源 |
|---|---|---|
| OpenAI Deep Research | ❌ | ❌ |
| Google Gemini Deep Research | ❌ | ❌ |
| Kimi K2/K2.5 | ✅ | ❌ |
| 通义 DeepResearch | ✅ | ❌ |
| OpenSeeker | ✅ | ✅ |
大厂们都很默契地守着自己的"数据护城河"——模型可以开源(反正也能重新训),但数据?门都没有。
这就是 OpenSeeker 要解决的问题:打破数据垄断,让学术界也能玩得起搜索 Agent。
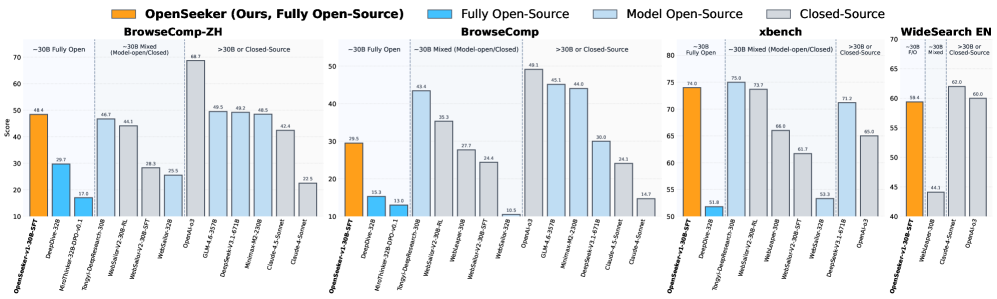
图1:OpenSeeker 的核心方法流程——左侧是事实驱动的 QA 合成(通过网络图拓扑扩展和实体混淆生成高难度问题),右侧是去噪轨迹合成(通过非对称上下文训练让模型学会在噪声中提取关键信息)
📖 BrowseComp 是什么?为什么它这么难?
在聊 OpenSeeker 的方法之前,得先说说它的"考场"——BrowseComp。
2025 年 4 月,OpenAI 开源了 BrowseComp 基准测试,包含 1266 道"变态级"信息检索题。这些题目有几个特点:
- 答案难找但易验证:比如问"某个 NBA 球员大学时期的室友现在在哪家公司工作",答案可能只出现在某个小众论坛的一个帖子里
- 需要多跳推理:不是一次搜索就能搞定,需要搜 A → 从 A 找到 B → 再从 B 找到 C
- 信息分散:答案的线索分布在互联网的多个角落
当时 OpenAI 自己的 Deep Research Agent 在这个基准上拿了 51.5% 的准确率,而普通的 LLM(比如 GPT-4o)只能拿到个位数。
到了 2026 年 3 月,这个基准的分数天花板已经被推到了 50% 以上。OpenSeeker 在 BrowseComp 的中文版(BrowseComp-ZH)上拿到了 48.4%,超过了通义 DeepResearch 的 46.7%。
关键是——通义用了持续预训练 + SFT + RL 三阶段训练,OpenSeeker 只用了单次 SFT。
🧠 核心创新一:事实驱动的可扩展可控 QA 合成
OpenSeeker 的第一个杀手锏是它的 QA 合成方法。简单说就是:把互联网当成一张图,在图上"造题"。
为什么传统方法不行?
传统的 QA 合成有两个路子:
- 从现有数据集抽样:问题太简单,根本不需要深度搜索
- 让 LLM 凭空生成:容易产生幻觉,生成的问题可能根本没有真实答案
OpenSeeker 的思路不一样:从真实的网页链接结构出发,反向生成需要遍历这些链接才能回答的问题。
具体怎么做?
想象互联网是一张巨大的有向图,每个网页是一个节点,超链接是边。OpenSeeker 的合成流程如下:
Step 1:图扩展
从一个种子页面(比如某个维基百科词条)出发,沿着出边遍历,形成一个局部子图。比如:
电影《泰坦尼克号》 → 导演詹姆斯·卡梅隆 → 他的另一部电影《阿凡达》 → 阿凡达的特效公司
Step 2:实体提取与子图重组
把文本噪声去掉,只保留关键实体和它们的关系,形成一个"实体子图":
泰坦尼克号 --导演--> 卡梅隆 --执导--> 阿凡达 --特效--> Weta Digital
Step 3:基于子图生成问题
让 LLM 根据这个实体子图生成问题,要求问题必须遍历多条边才能回答:
"《泰坦尼克号》导演执导的另一部科幻电影的特效是由哪家公司制作的?"
答案:Weta Digital
Step 4:实体混淆(这一步最骚)
把问题里的具体实体替换成模糊的描述,强迫 Agent 先"消歧":
原问题:"《泰坦尼克号》导演执导的另一部科幻电影..."
混淆后:"那部 1997 年获得 11 项奥斯卡奖的爱情灾难片的导演..."
这就像把"詹姆斯·卡梅隆"换成了"那个拍过海底纪录片的导演"——Agent 需要先搜索确认这个人是谁,才能继续下一步。
Step 5:双重验证
生成的 QA 必须同时满足两个条件:
- 难度验证:基础模型"闭卷"答不出来(确保需要搜索)
- 可解性验证:给模型完整的子图内容,它能答对(确保问题有解)

图2:事实驱动的 QA 合成流程——从网页图的拓扑扩展到实体混淆,再到双重验证,形成一套完整的高难度 QA 生产线
这个方法为什么好?
| 特性 | 说明 |
|---|---|
| 事实性 | 基于真实网页拓扑,问题必有答案 |
| 可扩展性 | 互联网有 TB 级网页存档,理论上可以无限生成 |
| 可控性 | 通过调整子图深度控制问题难度 |
🔧 核心创新二:去噪轨迹合成
有了高质量的 QA,还需要高质量的"解题过程"(轨迹)来训练 Agent。但问题是:真实网页充满噪声。
打开任何一个网页,你会看到:广告、导航栏、侧边栏、评论区、推荐链接……真正有用的信息可能只占 10%。让 Agent 在这些噪声中学习正确的搜索策略,简直是 mission impossible。
OpenSeeker 的解法很巧妙:合成时去噪,训练时加回来。
合成阶段:给老师一个干净的环境
在让教师模型(比如 GPT-4o)生成轨迹时,OpenSeeker 用了一个"总结历史 + 原始近期"的协议:
上下文 = [步骤1的摘要, 步骤2的摘要, ..., 步骤(t-1)的原始观察]
也就是说,历史步骤只保留关键信息的总结,只有最近一步保留完整内容。这样教师模型能在一个相对干净的环境里生成高质量的"黄金轨迹"。
训练阶段:给学生一个嘈杂的环境
但学生模型训练时,OpenSeeker 把所有的总结都换回了原始的噪声内容:
训练上下文 = [步骤1的原始观察, 步骤2的原始观察, ..., 步骤(t-1)的原始观察]
这就像:
- 老师在安静的办公室里写出了标准答案
- 学生被要求在嘈杂的食堂里,照着这个答案学习
为什么要这么折腾?
因为实际部署时,Agent 面对的就是噪声满满的真实网页。如果训练时就用干净数据,模型一上线就懵逼了。这种"非对称训练"强迫模型学会:在噪声中提取关键信息,然后做出正确决策。
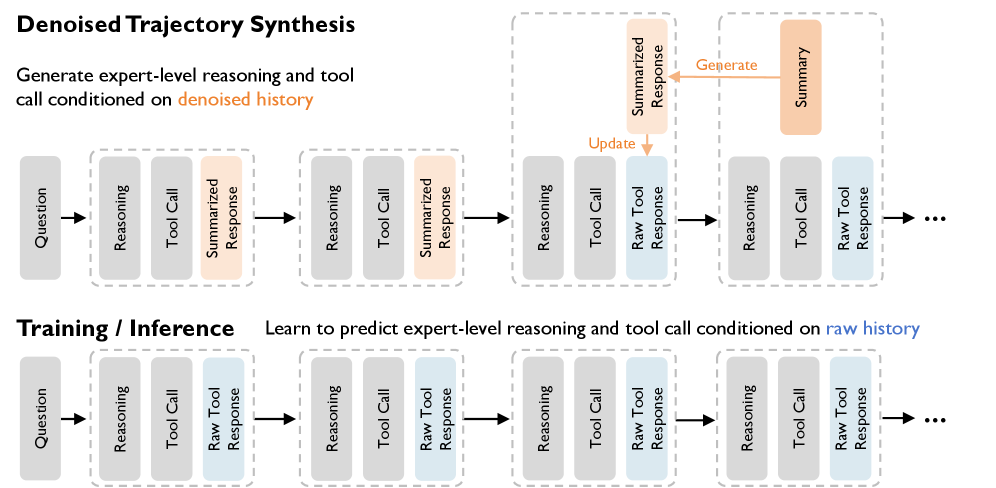
图3:去噪轨迹合成的核心思想——教师模型在压缩的历史上下文中生成高质量动作,学生模型在完整的噪声上下文中学习复现这些动作
🧪 实验结果:11.7k 样本,单次 SFT,直接登顶
实验设置
- 基础模型:Qwen3-30B-A3B-Thinking-2507(30B 参数,3B 激活的 MoE 架构)
- 训练数据:仅 11.7k 合成样本
- 训练方法:单次 SFT,无数据过滤,无超参数调优
基准测试
| 基准 | 语言 | 说明 |
|---|---|---|
| BrowseComp | 英文 | OpenAI 发布的深度搜索基准 |
| BrowseComp-ZH | 中文 | BrowseComp 的中文版 |
| xbench-DeepSearch | 混合 | 多语言深度搜索评测 |
| WideSearch | 混合 | 广度搜索能力评测 |
主要结果
结果一:超越资源密集型工业基线
| 模型 | 训练方式 | BrowseComp-ZH |
|---|---|---|
| 通义 DeepResearch | CPT + SFT + RL | 46.7% |
| OpenSeeker | 仅 SFT | 48.4% |
通义用了三阶段训练管线(持续预训练 + 监督微调 + 强化学习),OpenSeeker 只用了 SFT。这说明什么?数据质量 >> 训练花样。
结果二:同参数量、同训练方式下的统治级表现
在 ~30B 参数、仅 SFT 的模型中:
| 模型 | 数据量 | BrowseComp-ZH | WideSearch |
|---|---|---|---|
| MiroThinker | 147k | 25.8% | 34.6% |
| WebSailor-V2-SFT | 15k | 28.3% | 28.7% |
| WebLeaper | 10k | 32.5% | 30.4% |
| OpenSeeker | 11.7k | 48.4% | 45.3% |
MiroThinker 用了 147k 样本,是 OpenSeeker 的 12 倍,结果呢?被吊打。
结果三:数据难度对比
OpenSeeker 合成的数据有多难?看一个指标——平均工具调用次数:
| 数据集 | 平均工具调用数 |
|---|---|
| BrowseComp-ZH | 26.98 |
| OpenSeeker 合成数据 | 46.35 |
OpenSeeker 的训练数据比测试基准还难 70%,这就是"考试都没训练难"的降维打击。
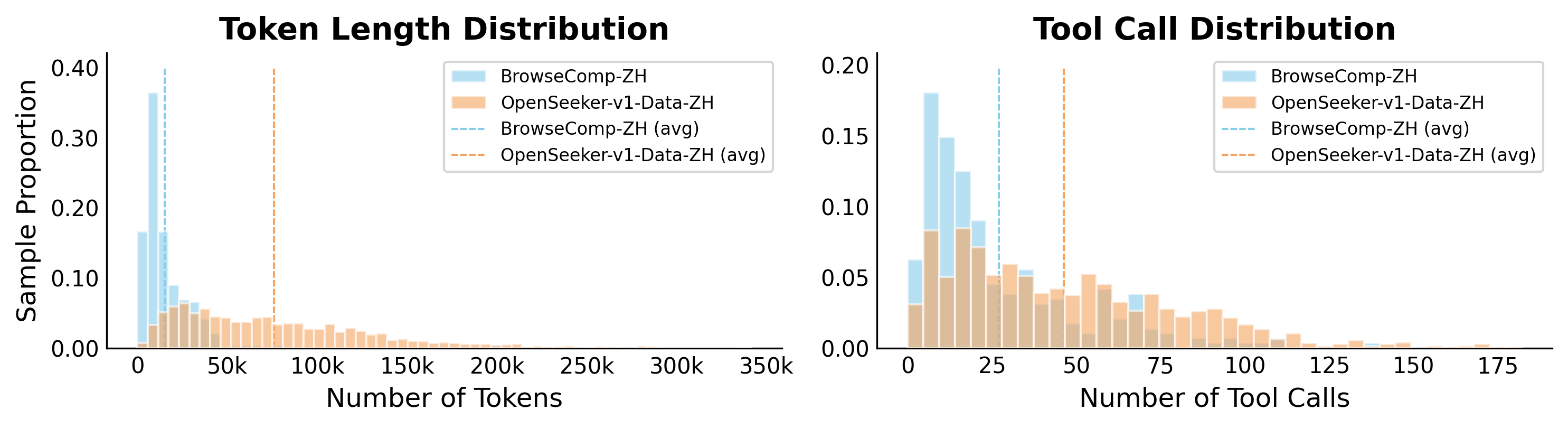
图4:BrowseComp-ZH 上的性能对比——OpenSeeker 在 ~30B 参数级别中遥遥领先,甚至超过了使用更复杂训练流程的工业级系统
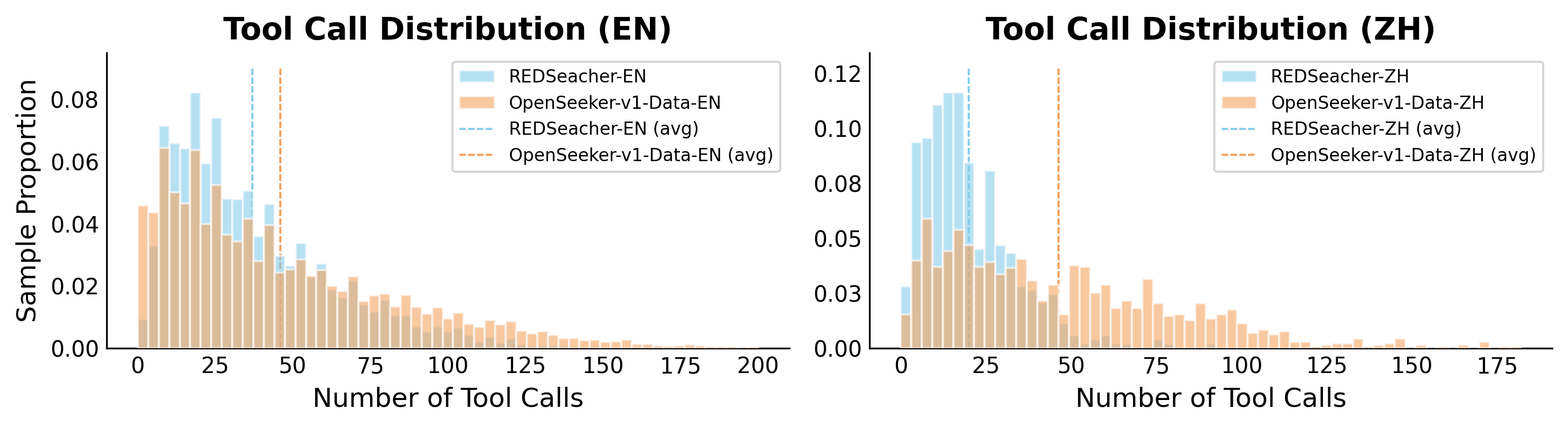
图5:数据复杂度对比——OpenSeeker 的合成数据在问题长度、轨迹长度、工具调用次数等维度上都远超现有基准
💡 我的观点与启发
1. 数据质量的胜利
这篇论文最大的启示是:在 Agent 训练中,数据质量远比数量重要。
MiroThinker 用 147k 样本,被 11.7k 样本的 OpenSeeker 吊打。为什么?因为 MiroThinker 的数据来自现有数据集的聚合,问题难度不够;而 OpenSeeker 从图拓扑出发"定制化造题",每道题都确保需要多轮搜索才能解。
这给我们一个工程启示:与其花时间清洗海量数据,不如设计一套能生成高质量数据的方法论。
2. 非对称训练是个好思路
"合成时去噪、训练时加噪"这个设计非常巧妙。它解决了一个经典矛盾:
- 教师模型需要干净环境才能生成好轨迹
- 学生模型需要在噪声环境中学习才能部署
类似的思路其实在其他领域也有应用。比如语音识别中的"clean teacher + noisy student"训练,或者图像领域的数据增强。OpenSeeker 把这个范式迁移到了 Agent 训练中,效果立竿见影。
3. 学术界的逆袭
说实话,看到"纯学术团队超越工业级系统"这种新闻,我是有点激动的。
工业界一直有"数据飞轮"优势——用户交互产生数据,数据训练更好模型,更好模型吸引更多用户。学术界在这个循环里天然吃亏。
但 OpenSeeker 证明了:如果你能在数据合成方法上取得突破,就可以绕过数据飞轮的限制。这给学术界做 Agent 研究提供了一个可行路径。
4. 一些潜在问题
当然,这篇论文也不是完美的。我有几个疑问:
Q1:图扩展的种子节点怎么选?
论文没有详细说明种子页面的选择策略。如果种子覆盖面有偏,生成的 QA 分布也会有偏。
Q2:实体混淆会不会过度?
把"詹姆斯·卡梅隆"换成"那个拍过海底纪录片的导演"是很好的混淆。但如果换成"某个知名导演",可能就太模糊了,导致问题有多个合理答案。混淆的"度"怎么把握?
Q3:中英文数据分布如何?
论文提到在 BrowseComp-ZH(中文)上效果特别好,那英文呢?如果合成数据以中文为主,在英文基准上的泛化性如何?
🔗 与其他工作的对比
| 工作 | 团队性质 | 模型开源 | 数据开源 | 训练方式 | BrowseComp-ZH |
|---|---|---|---|---|---|
| OpenAI Deep Research | 工业 | ❌ | ❌ | 未知 | - |
| 通义 DeepResearch | 工业 | ✅ | ❌ | CPT+SFT+RL | 46.7% |
| REDSearcher | 工业+学术 | ✅ | 部分 | Mid-training+SFT+RL | 26.8% |
| OpenResearcher | 学术 | ✅ | ✅ | SFT | - |
| OpenSeeker | 学术 | ✅ | ✅ | 仅 SFT | 48.4% |
OpenSeeker 是第一个"三全"的工作:全开源(模型+数据)、纯学术、SOTA 性能。
📝 总结
OpenSeeker 这篇论文给搜索 Agent 领域带来了几个重要贡献:
- 方法论创新:事实驱动的图合成 QA + 去噪轨迹合成,提供了一套可复现的高质量数据生产线
- 打破数据壁垒:首次完全开源前沿搜索 Agent 的训练数据,让学术界也能参与竞争
- 效率标杆:证明了仅用 11.7k 样本、单次 SFT 就能达到甚至超越复杂多阶段训练的效果
对于想做搜索 Agent 的团队,这篇论文的代码和数据是非常好的起点。对于关心 AI Agent 发展的读者,这篇论文揭示了一个重要趋势:合成数据的质量,可能比真实数据的数量更重要。
📚 参考文献
- OpenSeeker GitHub: https://github.com/rui-ye/OpenSeeker
- OpenSeeker 数据集: https://huggingface.co/datasets/OpenSeeker/OpenSeeker-v1-Data
- BrowseComp 基准: https://openai.com/research/browsecomp
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我的微信公众号:机器懂语言

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)