集成学习详解
集成学习(Ensemble Learning)的核心思想可以用一句话概括:“三个臭皮匠,顶个诸葛亮”。
它通过结合多个个体学习器(弱学习器)的预测结果来完成学习任务,通常能够获得比单一学习器更优越的泛化性能。
为了更好地理解,可以从以下几个层面来深入解析:
1. 核心逻辑:为何“团结”力量大?
单个模型(如一棵决策树、一个线性模型)在学习和预测时,往往存在以下问题,从而导致性能瓶颈:
-
高方差:模型对训练数据的细微变化非常敏感,容易过拟合(例如:深度很大的决策树)。
-
高偏差:模型的表达能力有限,无法捕捉数据中的复杂模式,容易欠拟合(例如:线性模型处理非线性数据)。
-
局限性:单个模型可能陷入局部最优解,或者无法覆盖数据的所有特征空间。
集成学习的逻辑在于,通过组合多个模型,可以:
-
减少方差:多个模型的平均预测会减少随机噪声的影响,使结果更稳定。
-
减少偏差:通过逐步叠加新的模型来纠正前一个模型的错误,从而逼近复杂的真实函数。
-
降低风险:避免选错单一模型的风险。即使某个模型表现很差,其他模型的正确预测也能“投票”将其纠正。
2. 两个核心要素
要使集成有效,个体学习器必须具备两个条件:
-
准确性:个体学习器不能太差,至少要比随机猜测(准确率>0.5)要好。
-
多样性:个体学习器之间要有差异性。如果一个模型犯错的地方,另一个模型不会犯错,那么集成就能纠正这个错误。如果所有模型都犯同样的错误,集成也无法挽回。
3. 主流的集成学习方法
根据个体学习器的生成方式和组合策略,集成学习主要分为以下三大流派:
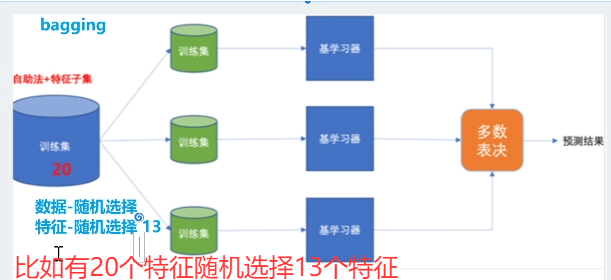
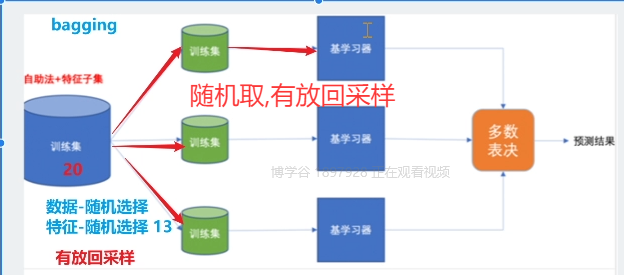
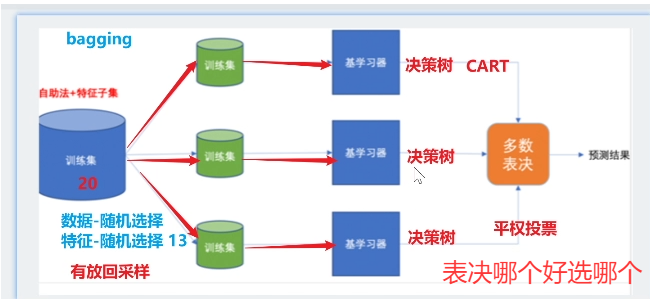
A. Bagging (装袋法)—— 核心:并行训练,降低方差
-
思想:让多个独立的大偏差/高方差模型(通常是深层决策树)并行学习,最后通过投票或平均来做决策。
-
如何实现多样性:通过Bootstrap抽样(有放回的重采样)生成不同的训练子集,让每个模型看到不同的数据。
-
代表算法:随机森林。
-
在Bagging的基础上,进一步在决策树分裂时引入随机特征选择,增加了模型的多样性,效果通常优于普通的Bagging。
-
-
效果:主要关注于降低模型的方差,防止过拟合。
B. Boosting (提升法) —— 核心:串行训练,降低偏差
-
思想:让多个弱学习器串行生成,后一个模型专注于纠正前一个模型犯的错误。
-
如何实现多样性:通过调整训练数据的权重分布。被前一个模型预测错的样本,在下一个模型中会获得更高的权重,迫使新模型重点关注这些“难啃的硬骨头”。
-
代表算法:AdaBoost、梯度提升决策树 (GBDT)、XGBoost、LightGBM。
-
效果:主要关注于降低模型的偏差,能够将一堆弱学习器(如只有几层的决策树)组合成一个强学习器。
C. Stacking (堆叠法) —— 核心:结合不同模型
-
思想:使用一个“元学习器”来学习如何组合多个基础模型。
-
做法:首先训练多个不同的基学习器,然后将这些基学习器的输出作为新的输入特征,来训练一个次级学习器(元模型)。
-
效果:通过结合不同类型的模型(如SVM、KNN、神经网络),能够突破单一算法的上限。
4. 直观类比
假设你要判断明天是否会下雨:
-
单一模型:你只听一个天气预报 App 的结果。如果这个 App 算法有误,你就被坑了。
-
Bagging:你问了10个气象学家,每个人独立地看了不同的卫星云图(随机采样数据),然后你统计一下这10个人里有多少人说下雨,按多数人的意见决定。这样可以避免个别人看走眼(降低方差)。
-
Boosting:你先问第一个气象学家,他预测错了。你让他回去重点研究今天他看错的那些云图(增加权重),然后修正预测。接着问第二个,让他专门盯着第一个容易犯错的地方。这样团队的错误率会越来越低(降低偏差)。
-
Stacking:你找了气象学家、农民(看蚂蚁搬家)和物理学家(测气压)。然后你找了一个聪明的决策者(元学习器),让他学习在不同情况下,该更相信谁的判断。
总结
集成学习的本质是通过构建并结合多个学习器来完成学习任务。它利用模型之间的差异性和互补性,在工业界和 Kaggle 竞赛中被广泛应用,通常是取得最优性能的关键技术。
bagging思想随机森林算法详解

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)