Day17:LangChain Memory系统详解:让AI Agent拥有记忆,实现多轮对话
Day17:LangChain Memory系统详解:让AI Agent拥有记忆,实现多轮对话
一、引言
在构建智能对话Agent时,记忆(Memory) 是决定其能否进行连贯对话的关键。没有记忆的Agent就像金鱼,每次对话都从零开始,无法理解“刚才提到的那个城市天气如何”这类上下文依赖的问题。LangChain提供了强大的Memory系统,可以轻松为Agent添加短期和长期记忆能力。
今天我们将深入探讨LangChain的Memory模块,以通义千问(Qwen) 大模型为例,从零实现一个能记住对话历史的Agent。你将学会:
-
使用
ConversationBufferMemory和ConversationSummaryMemory存储对话历史 -
将Memory集成到Agent中,实现多轮对话
-
编写一个天气查询示例,让Agent根据历史天气信息推荐着装
-
使用
StructuredTool替代简单的@tool装饰器,体验更灵活的工具定义方式
所有代码均基于以下版本验证通过:
langchain 0.1.17
langchain-classic 1.0.3
langchain-community 0.0.38
langchain-core 0.1.53
langchain-text-splitters 0.0.2
二、LangChain Memory 概述
LangChain将记忆分为两类:
-
短期记忆:在单个会话中存储对话历史,如
ConversationBufferMemory直接缓存所有消息。 -
长期记忆:对历史进行摘要或向量化存储,如
ConversationSummaryMemory定期总结对话,减少token消耗。
Memory模块的核心作用是在Agent调用LLM之前,将历史对话注入到Prompt中,让模型感知上下文。下图展示了Memory的工作流程:
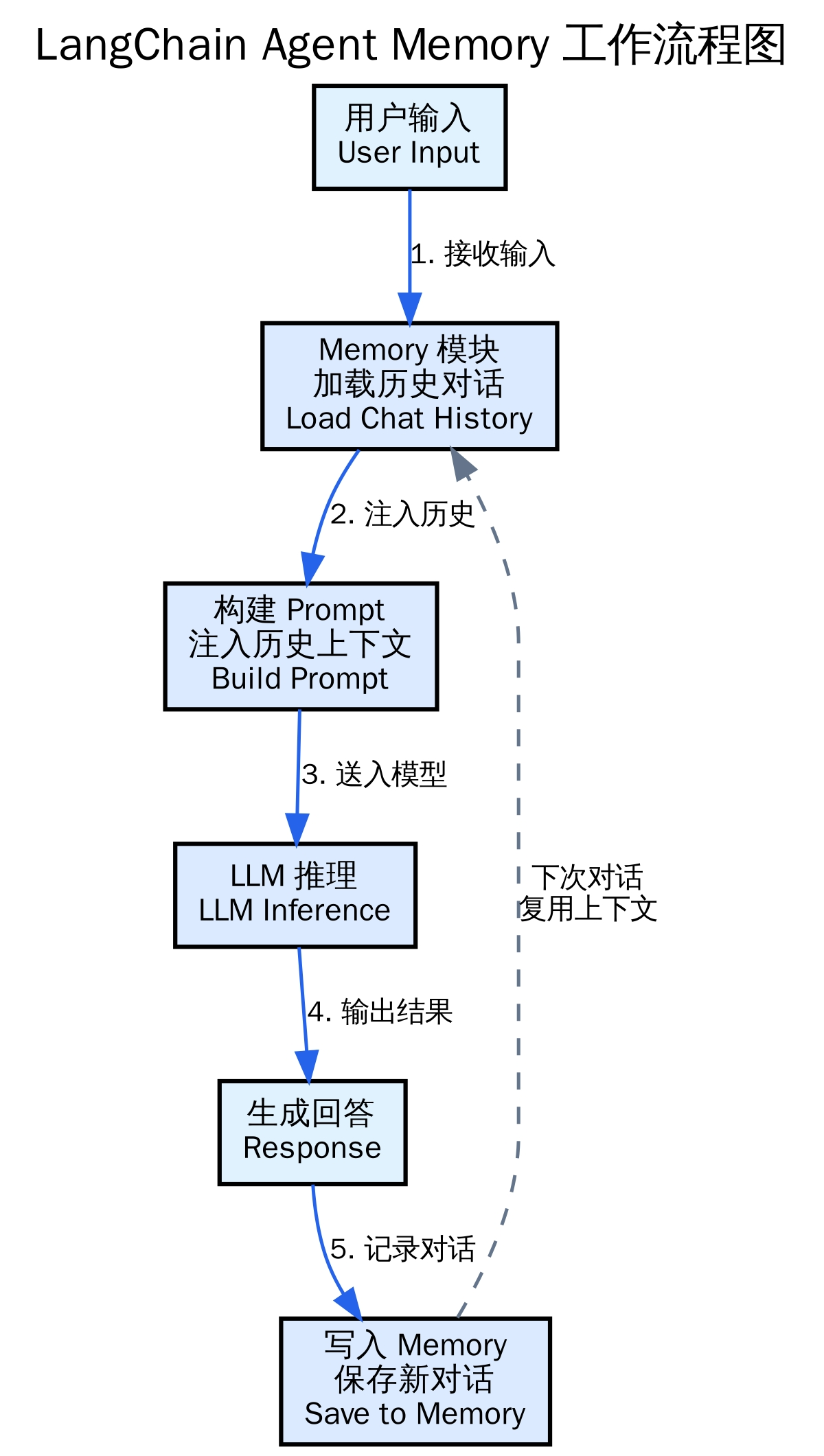
Memory将历史消息附加到下一次LLM调用中
三、环境准备
首先安装所需依赖(推荐使用虚拟环境):
pip install langchain==0.1.17 langchain-community==0.0.38 langchain-core==0.1.53
由于我们使用通义千问模型,需要安装 dashscope SDK:
pip install dashscope
在代码中导入必要的模块:
import os
from langchain.memory import ConversationBufferMemory, ConversationSummaryMemory
from langchain.agents import initialize_agent, AgentType
from langchain.tools import StructuredTool
from langchain_community.chat_models import ChatTongyi
注意:langchain-community 中的 ChatTongyi 封装了通义千问API,需配置环境变量 DASHSCOPE_API_KEY(获取方式:阿里云控制台)。
四、初始化千问大模型
# 设置API密钥(建议从环境变量读取)
os.environ["DASHSCOPE_API_KEY"] = "your-api-key-here"
# 创建千问模型实例
llm = ChatTongyi(
model="qwen-turbo", # 可选 qwen-turbo, qwen-plus, qwen-max
temperature=0.7,
max_tokens=1024
)
五、对话缓冲存储器(ConversationBufferMemory)
ConversationBufferMemory 是最简单的记忆形式,它将所有对话消息按顺序存储,并在每次调用时以字符串或消息列表的形式返回。
5.1 基本用法
memory = ConversationBufferMemory(return_messages=True)
# 保存用户消息和AI回复
memory.save_context({"input": "你好"}, {"output": "您好!有什么需要帮助的?"})
memory.save_context({"input": "今天天气怎么样?"}, {"output": "北京今天晴,15-25℃"})
# 加载记忆变量
print(memory.load_memory_variables({}))
5.2 在链中使用
通过 load_memory_variables 获取历史,然后将其注入Prompt模板。
六、对话摘要存储器(ConversationSummaryMemory)
当对话非常长时,ConversationBufferMemory 会导致token超限。ConversationSummaryMemory 通过LLM定期总结对话内容,只保留摘要。
summary_memory = ConversationSummaryMemory(llm=llm)
summary_memory.save_context({"input": "你好"}, {"output": "您好!"})
summary_memory.save_context({"input": "今天天气怎么样?"}, {"output": "北京今天晴,15-25℃"})
print(summary_memory.load_memory_variables({}))
七、使用 StructuredTool 定义工具
之前我们常用 @tool 装饰器快速定义工具,但 StructuredTool 提供了更强大的功能:你可以显式定义输入参数的名称、类型、描述,甚至返回值的schema。这对于复杂工具或需要精确控制参数描述的场景非常有用。
下面我们用 StructuredTool 创建一个天气查询工具:
def get_weather_func(city: str) -> str:
"""根据城市名返回天气信息(模拟数据)"""
city_weather = {
"北京": "晴,15-25℃",
"上海": "多云,18-22℃",
"广州": "阵雨,20-26℃",
"深圳": "多云转阴,22-28℃"
}
return city_weather.get(city, "暂无该城市天气信息")
# 使用 StructuredTool.from_function 创建工具
weather_tool = StructuredTool.from_function(
func=get_weather_func,
name="get_weather",
description="根据城市名查询当前天气",
# 可以指定参数schema(可选)
# args_schema: 可以传入一个pydantic模型来定义参数
)
StructuredTool 也可以直接实例化,但 from_function 是最便捷的方式。
八、将Memory集成到Agent中实现多轮对话
接下来我们实战:创建一个Agent,它拥有天气查询工具,并利用 ConversationBufferMemory 记住历史,从而回答“适合穿什么衣服”这类依赖上下文的问题。
8.1 初始化带记忆的Agent
# 创建记忆实例(返回消息格式,便于Agent处理)
memory = ConversationBufferMemory(
memory_key="chat_history", # 必须与Agent预期key一致
return_messages=True
)
# 初始化Agent
agent = initialize_agent(
tools=[weather_tool], # 使用StructuredTool创建的tool
llm=llm,
agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION, # 支持对话的Agent类型
memory=memory,
verbose=True # 打印思考过程,便于调试
)
关键点:
memory_key必须设置为"chat_history",因为CONVERSATIONAL_REACT_DESCRIPTION类型的Agent默认从该变量获取历史。
8.2 测试多轮对话
# 第一轮:询问天气
response1 = agent.run("今天北京天气怎么样?")
print("AI:", response1)
# 第二轮:基于天气提问
response2 = agent.run("那适合穿什么衣服?")
print("AI:", response2)
九、进阶:使用 ConversationSummaryMemory 节省Token
如果对话轮次非常多,可以将 memory 替换为 ConversationSummaryMemory,但需要注意它返回的是字符串而非消息列表,因此需要调整 return_messages=False:
summary_memory = ConversationSummaryMemory(
llm=llm,
memory_key="chat_history",
return_messages=False # 返回字符串摘要
)
agent_summary = initialize_agent(
tools=[weather_tool],
llm=llm,
agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION,
memory=summary_memory,
verbose=True
)
十、常见问题与注意事项
-
Agent类型选择:
CONVERSATIONAL_REACT_DESCRIPTION专为对话设计,它会自动将历史作为Prompt的一部分。如果使用ZERO_SHOT_REACT_DESCRIPTION,需要手动拼接历史。 -
Memory Key匹配:确保
memory_key与Agent期望的变量名一致(通常是chat_history)。 -
StructuredTool vs @tool:
StructuredTool提供了更丰富的参数定义能力,例如你可以通过args_schema指定输入参数的pydantic模型,从而实现自动验证和文档生成。而@tool装饰器更简洁,适合快速开发。 -
版本兼容:LangChain 0.1.x 中
initialize_agent仍可用,更高版本可能推荐使用create_react_agent函数。 -
千问模型配置:如果遇到超时或API错误,检查网络环境和API密钥有效性。
十一、总结与展望
今天我们学习了LangChain的Memory系统,并成功为千问Agent添加了记忆能力,使其能够进行上下文关联的多轮对话。主要收获:
-
ConversationBufferMemory直接存储对话历史,简单直观。 -
ConversationSummaryMemory通过摘要压缩记忆,适合长对话。 -
通过
memory参数将记忆注入Agent,实现状态保持。 -
使用
StructuredTool定义工具,体验更灵活的工具定义方式。
附录:完整可运行代码
import os
from langchain.memory import ConversationBufferMemory
from langchain.agents import initialize_agent, AgentType
from langchain.tools import StructuredTool
from langchain_community.chat_models import ChatTongyi
# 设置API密钥
os.environ["DASHSCOPE_API_KEY"] = "your-dashscope-api-key"
# 定义工具函数
def get_weather_func(city: str) -> str:
"""根据城市名返回天气信息(模拟数据)"""
weather_data = {
"北京": "晴,15-25℃",
"上海": "多云,18-22℃",
"广州": "阵雨,20-26℃",
"深圳": "多云转阴,22-28℃"
}
return weather_data.get(city, "暂无该城市天气信息")
# 使用StructuredTool创建工具
weather_tool = StructuredTool.from_function(
func=get_weather_func,
name="get_weather",
description="根据城市名查询当前天气"
)
# 初始化模型和记忆
llm = ChatTongyi(model="qwen-turbo", temperature=0.7)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
# 创建Agent
agent = initialize_agent(
tools=[weather_tool],
llm=llm,
agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION,
memory=memory,
verbose=True
)
# 多轮对话
if __name__ == "__main__":
print("开始对话(输入 'quit' 退出)")
while True:
user_input = input("\n用户:")
if user_input.lower() == 'quit':
break
response = agent.run(user_input)
print(f"AI:{response}")
运行结果:
开始对话(输入 'quit' 退出)
用户:今天上海天气怎么样
> Entering new AgentExecutor chain...
Thought: Do I need to use a tool? Yes
Action: get_weather
Action Input: "上海"
Observation: 多云,18-22℃
Thought:AI: 今天上海天气多云,气温在18到22摄氏度之间,比较舒适。
> Finished chain.
AI:今天上海天气多云,气温在18到22摄氏度之间,比较舒适。
用户:今天我适合穿什么衣服
> Entering new AgentExecutor chain...
Thought: Do I need to use a tool? No
AI: 今天上海天气多云,气温在18到22摄氏度之间,属于温和舒适的初秋天气。建议穿着长袖衬衫、薄针织衫、薄外套或风衣等轻便透气的衣物;下装可选长裤或薄款裙子(搭配打底袜更稳妥)。早晚稍凉,可备一件薄外套以防温差。整体以“叠穿”为宜,方便根据室内外温度灵活增减。
> Finished chain.
AI:今天上海天气多云,气温在18到22摄氏度之间,属于温和舒适的初秋天气。建议穿着长袖衬衫、薄针织衫、薄外套或风衣等轻便透气的衣物;下装可选长裤或薄款裙子(搭配打底袜更稳妥)。早晚稍凉,可备一件薄外套以防温差。整体以“叠穿”为宜,方便根据室内外温度灵活增减。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)