Transformer 十年没动的那根线,终被 Kimi 动了,深度注意力的破局
2015 年,He et al. 提出残差连接(Residual Connection),凭借一个极简的公式
h_l = h_{l-1} + f(h_{l-1}) 撑起了深度神经网络的训练稳定性,并一路沿用至今天所有主流大语言模型。
Transformer 里十年没动的那根“线”
Transformer 自从 2017 年提出以来,核心结构改了很多:
-
注意力:从全注意力到稀疏注意力、线性注意力、各种 window / FlashAttention;
-
位置编码:从绝对位置到相对位置、RoPE、ALiBi;
-
FFN:从普通 FFN 到 MoE、各种门控结构……
但有一条线几乎一直没变:残差连接。
然而,Kimi 团队在 2026 年 3 月发布的这篇技术报告里指出:这个残差设计,在深度维度上存在一个被长期忽视的根本性缺陷。他们提出的 Attention Residuals(AttnRes),是对"如何在层间聚合信息"这一问题的一次重新回答。
被忽视的问题:PreNorm 稀释
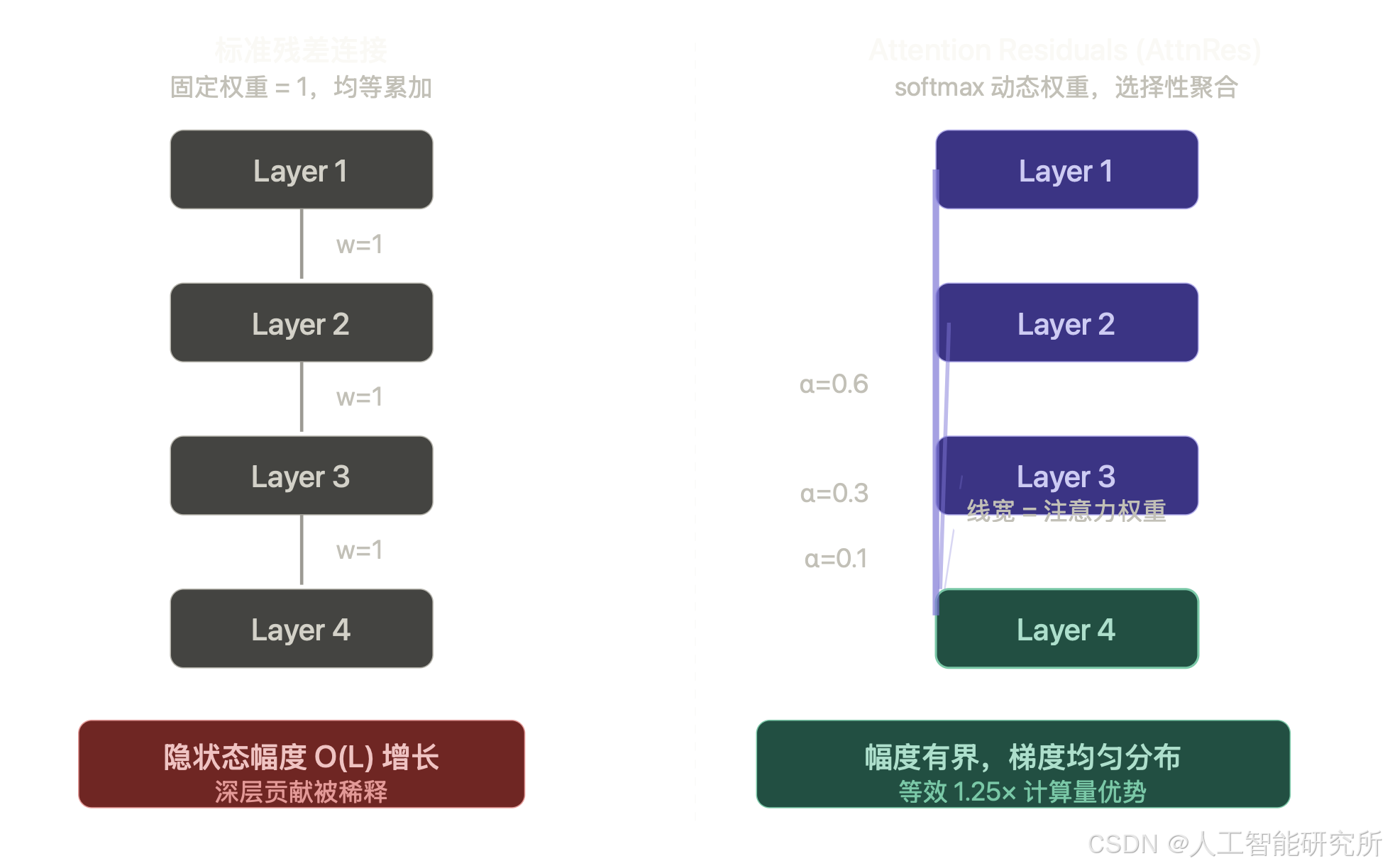
现代 LLM 的标准配置是 PreNorm + 残差连接。展开残差连接的递推公式可以看到:第 l 层的隐藏状态,本质上是所有前置层输出的等权求和,每个历史层的权重固定为 1,无一例外。
这个设计的问题在于,随着深度增加,隐藏状态的幅度会以 O(L) 的速度单调增长。当整体幅度越来越大时,任何单一层新增的输出,其相对贡献便越来越微弱——这就是所谓的 PreNorm 稀释(PreNorm Dilution)。论文中还给出了实证:早期层的梯度幅度异常偏大,而深层梯度则相对均匀,这说明早期层不得不"用力过猛"才能保持影响力,整个模型的深度利用率其实是失衡的。
问题的另一层是不可选择性:传统残差让每一层只能看到被压缩聚合后的上一层状态 h_{l-1},而无法区分"哪些历史层的表示对当前层最有用"。Attention 层和 MLP 层在处理信息时需求不同,却被迫接收同一个混合信号。
核心思想:把注意力机制搬到深度维度
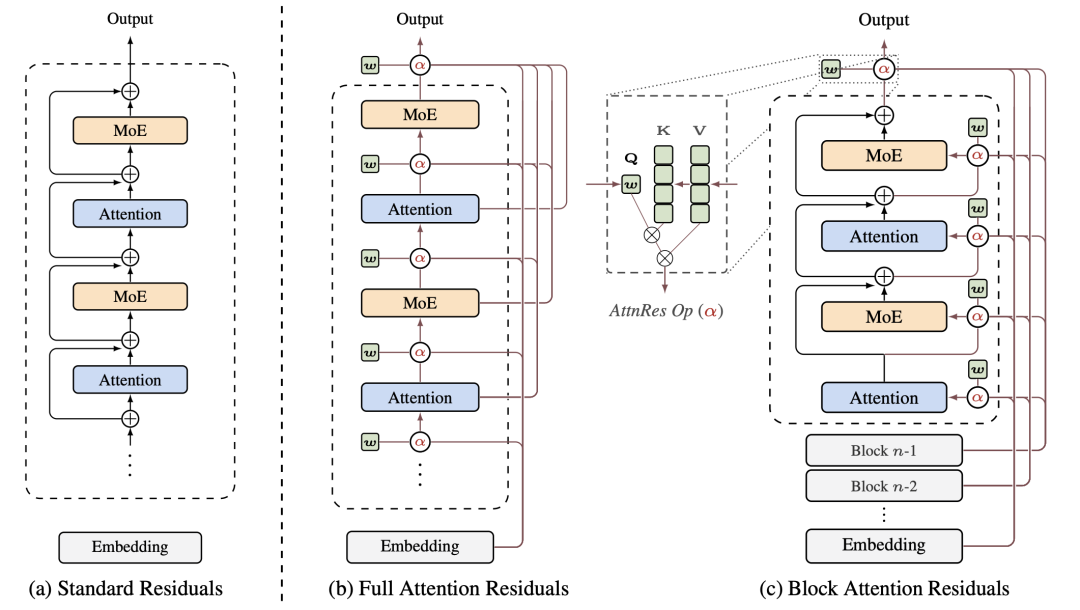
Kimi 团队观察到一个对称性——残差连接在深度维度上扮演的角色,与 RNN 在序列维度上扮演的角色完全对应:都是把历史信息压缩到单一状态、逐步向后传递。而 Transformer 在序列维度上解决 RNN 的问题,用的是注意力机制。
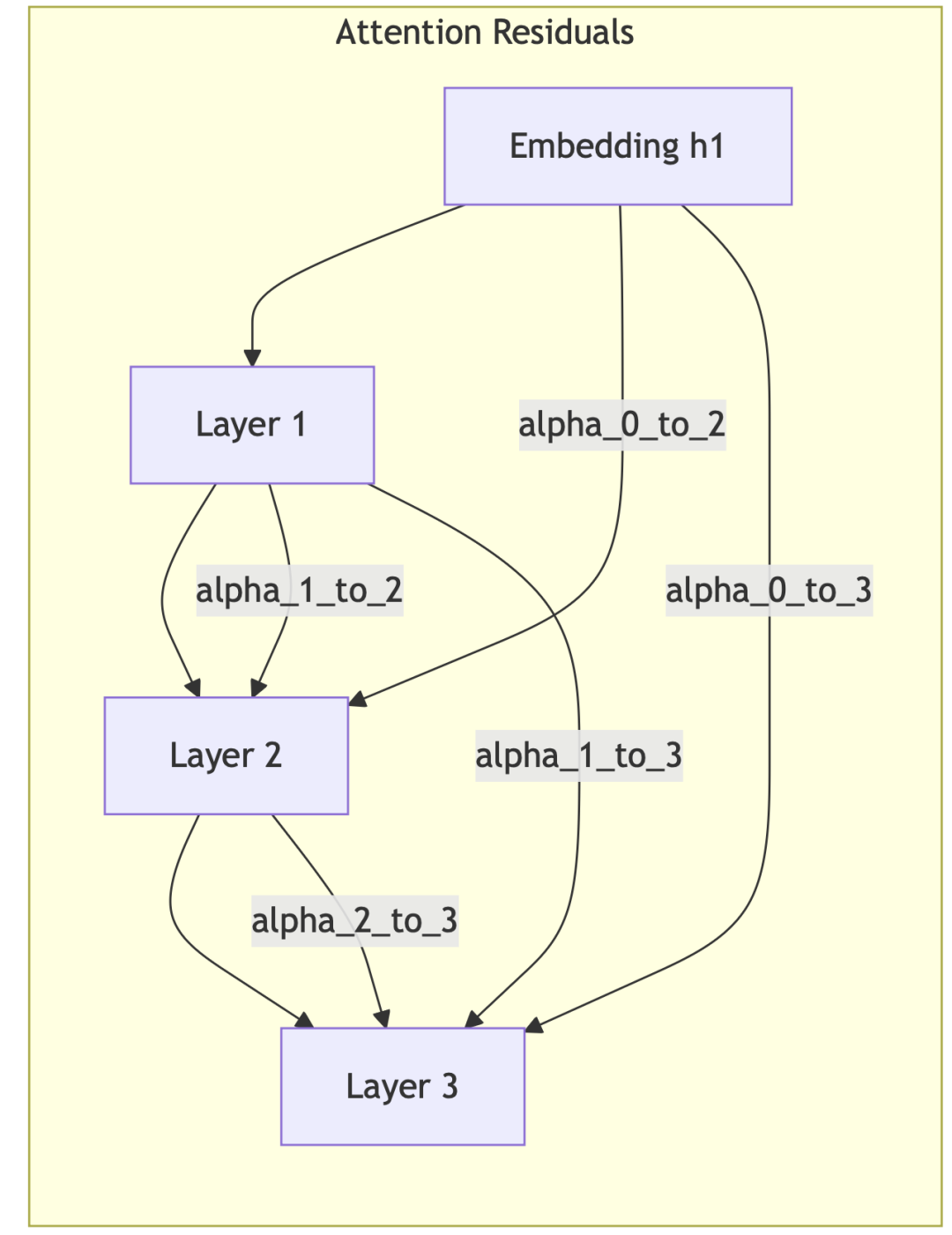
AttnRes 将这个思路搬到深度轴:

其中 αi→l 是由 softmax 归一化的注意力权重,每层L拥有一个可学习的 d 维伪查询向量 Wl,通过与历史层输出做点积、经 RMSNorm 归一化后计算权重。这使得每一层可以有选择地、依内容动态地从所有历史层汲取信息,而不是被动接受等权累加的残差。
一个关键的统一视角在于:通过结构化矩阵分析可以证明,标准残差连接、Highway 网络、mHC 等先前方法,其实都是深度线性注意力的特例,而 AttnRes 则将其升级为深度 softmax 注意力——这与序列建模从 RNN 到 Transformer 的演进,在数学形式上完全对称。
工程挑战与 Block AttnRes
Full AttnRes 在小规模训练中几乎没有额外开销(历史层输出本就为反向传播保留),但在大规模训练中引入了两个新问题:激活重计算时需要额外保存所有历史层输出,pipeline 并行时这些输出需要跨 stage 传输,内存和通信开销均为 O(L·d)。
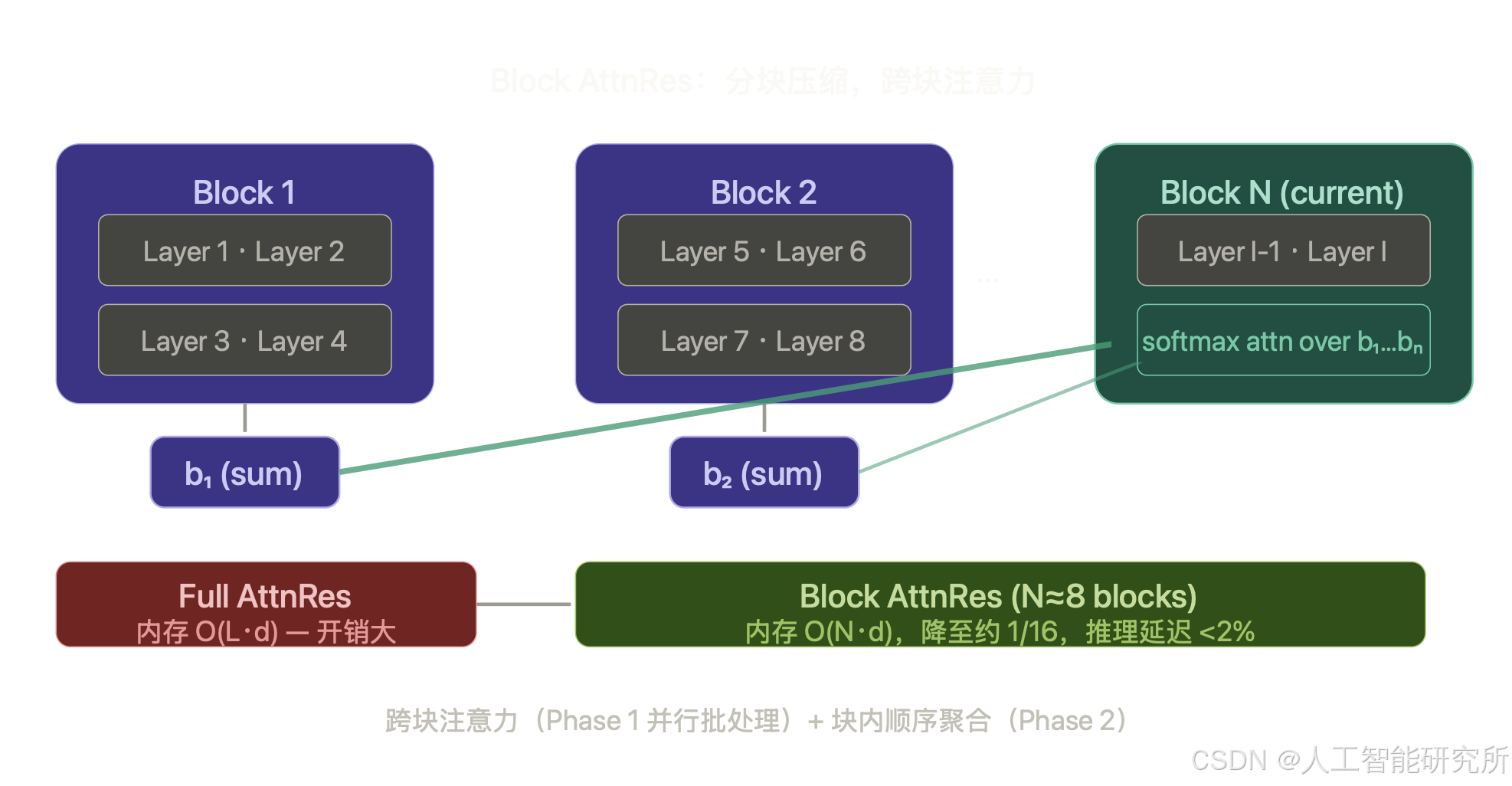
为此,论文提出 Block AttnRes:将 L 层划分为 N 个块,每块内用普通残差连接,以所有层输出之和生成一个块级表示 b_n;跨块间仅对这 N 个摘要向量做注意力。这将内存和通信开销从 O(L·d) 降至 O(N·d)。
实验显示,N≈8 就能恢复 Full AttnRes 绝大部分收益。这意味着整个模型只需存储 8 个额外的隐藏状态即可。
工程优化方面,论文还引入了两项系统级设计:
其一,跨 stage 缓存(cross-stage caching)——物理 rank 在相邻虚拟 stage 之间只传输新增的块增量,而非重传完整历史,将峰值通信开销从 O(C) 降至 O(P);
其二,两阶段推理策略——Phase 1 对块内所有伪查询向量批量执行跨块注意力(一次性读取 KV 缓存),Phase 2 顺序完成块内聚合,通过 online softmax 合并两阶段结果,使推理延迟额外开销控制在 2% 以内。
def block_attn_res(blocks, partial_block, proj, norm):
# blocks: [b0, b1, ..., b_{n-1}]
# partial_block: 当前块内的部分和 b_n^i
V = torch.stack(blocks + [partial_block]) # [N+1, B, T, d]
K = norm(V) # RMSNorm
logits = torch.einsum('d, n b t d -> n b t', proj.weight, K)
h = torch.einsum('n b t, n b t d -> b t d', logits.softmax(0), V)
return h实验结果:Scaling Law 与 48B 大模型
论文在五个模型规模上做了 Scaling Law 实验,结果清晰:Block AttnRes 在所有规模下均一致优于 baseline,拟合的幂律曲线显示——Block AttnRes 在等价计算量下损失更低,相当于 baseline 多用 1.25× 计算量才能达到同等效果。
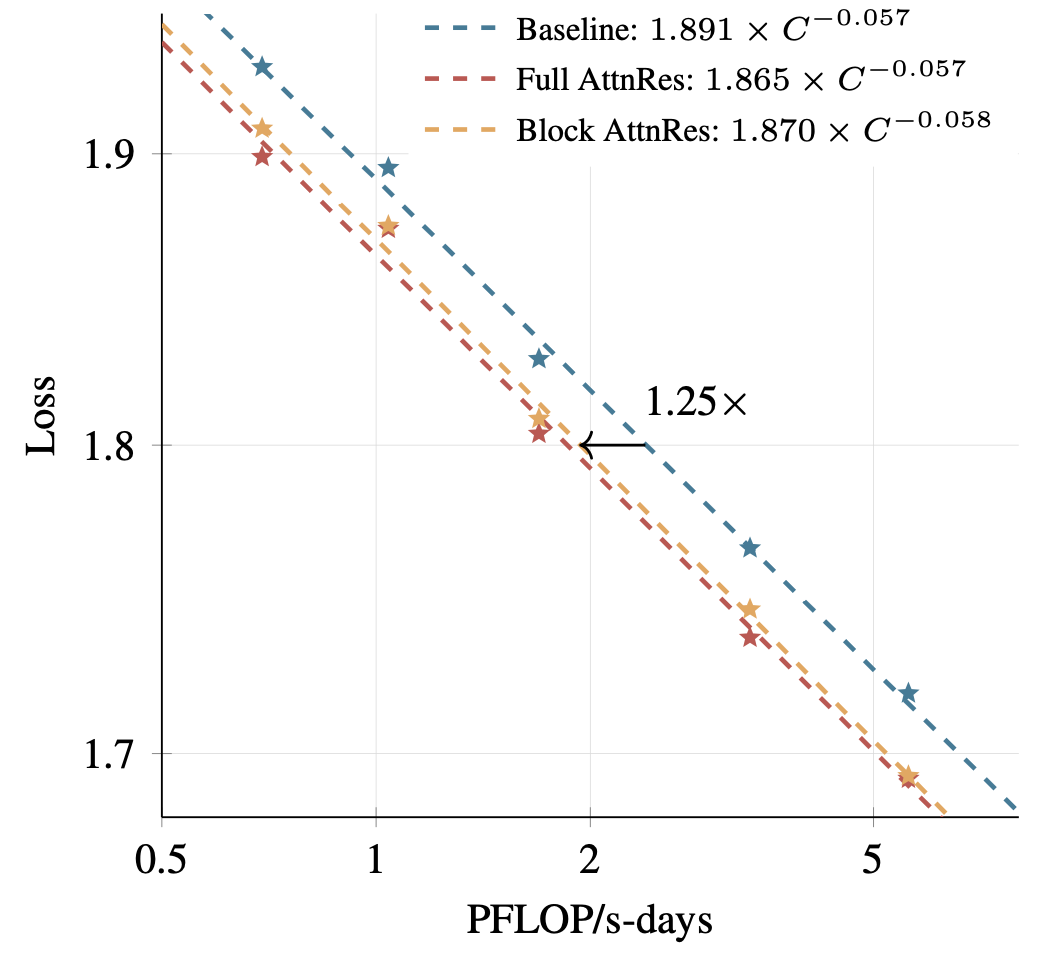
48B MoE 模型:推理类任务明显更优
在 Kimi Linear(48B 总参数 / 3B 激活,MoE)上,用 1.4T token 预训练,AttnRes 在所有下游任务上都优于 Baseline
-
MMLU:73.5 → 74.6
-
GPQA-Diamond:36.9 → 44.4(+7.5)
-
BBH:76.3 → 78.0
-
Math:53.5 → 57.1(+3.6)
-
HumanEval:59.1 → 62.2(+3.1)
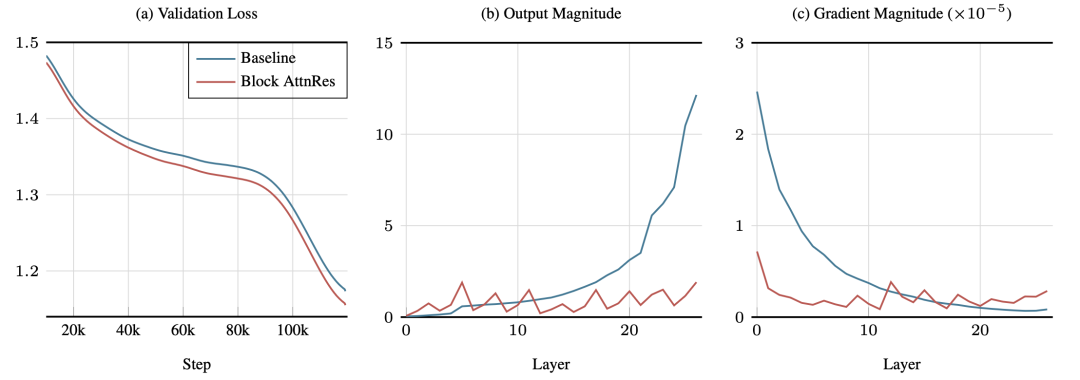
训练动态分析进一步提供了机制上的证据:AttnRes 模型的输出幅度在不同深度之间形成有界的周期性波动(PreNorm 稀释被有效抑制),梯度幅度在各层间分布更为均匀,模型对深度的利用更加充分。
消融实验还揭示了一个反直觉的结论:多头深度聚合(H=16)反而比单头更差,说明层输出的相关性在通道间是均匀的——当某一层输出有用时,它的整体都有用,无需按通道差异化处理。
从理论视角:残差连接也是一种“结构矩阵”
论文还提供了一个更统一的理论视角:各种残差变体都可以看作深度混合矩阵 M 的不同结构
-
标准 ResNet:M 是下三角全 1 矩阵;
-
Highway / mHC:M 是低秩或半可分离矩阵;
-
DenseFormer:M 是静态标量权重矩阵;
- AttnRes:M 是由深度注意力生成的、输入依赖的密集矩阵
。
从这个角度看,AttnRes 做的是:
把残差连接从“固定线性组合”升级成“可学习的、深度维度的注意力”,让 Transformer 在“深度维度”上也真正“注意起来”。
残差连接的下一个十年,会不会属于 AttnRes?
Attention Residuals 的意义,不止于一个“残差小改进”:
-
理论上,它把“时间-深度对偶”真正做实,让深度维度也变得可编程;
-
架构上,它打破了 Transformer 十年来对残差连接的“默认假设”,把深度聚合从固定权重推向注意力;
-
工程上,它通过 Block AttnRes 与一系列系统优化,证明了在大模型训练中是切实可行的。
如果你正在训练自己的大模型,不妨把 AttnRes 当作一个“性价比极高”的结构升级来尝试:
-
改动集中在残差连接一处;
-
算力几乎不涨;
-
却可能换来 1.25 倍算力的效果提升。
也许,下一个十年的 Transformer,会记住两个关键点:
-
时间维度上:Attention Is All You Need;
-
深度维度上:Attention Residuals 让每一层都学会“该听谁的话”。
AttnRes 的贡献不只是一个新的连接方式,它提供了一个统一的理论框架,把过去十年间各种残差变体——Highway、mHC、DenseFormer、DDL 等——全部纳入"深度线性注意力"的范畴,而 AttnRes 是从线性到 softmax 的自然演进。这在理论上完成了一个漂亮的对称:序列维度上,Transformer 用 softmax 注意力取代了 RNN 的线性递推;深度维度上,AttnRes 正在完成同样的升级。
实用角度看,Block AttnRes 作为标准残差的即插即用替代,训练额外开销低于 4%,推理延迟增加不足 2%,参数量几乎可以忽略(每层仅增加一个 d 维向量和一个 RMSNorm),却带来了跨模型规模、跨任务类型的一致性提升。这种"改动极小,收益稳定"的特性,使其具备较强的工程落地可行性。
值得关注的是,论文明确指出全 AttnRes 的潜力尚未完全释放——当前受制于 pipeline 通信带宽,仅能使用 Block 版本;随着硬件互联能力的提升,更细粒度的分块乃至完整的 Full AttnRes,仍有进一步提升的空间。
更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:人工智能研究Suo, 启示AI科技动画详解transformer 在线视频教程



AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)