【科研人聊方法】断点回归:用“自然实验”搞定因果推断
本期嘉宾:老章(某985高校应用经济学博士,用Stata做断点回归研究3年,发表CSSCI论文5篇) 主持人:小研(科研人小助手)
小研:老章您好,很多刚接触实证研究的同学对“因果推断”特别头疼,您能给大家简单介绍一下断点回归模型吗?
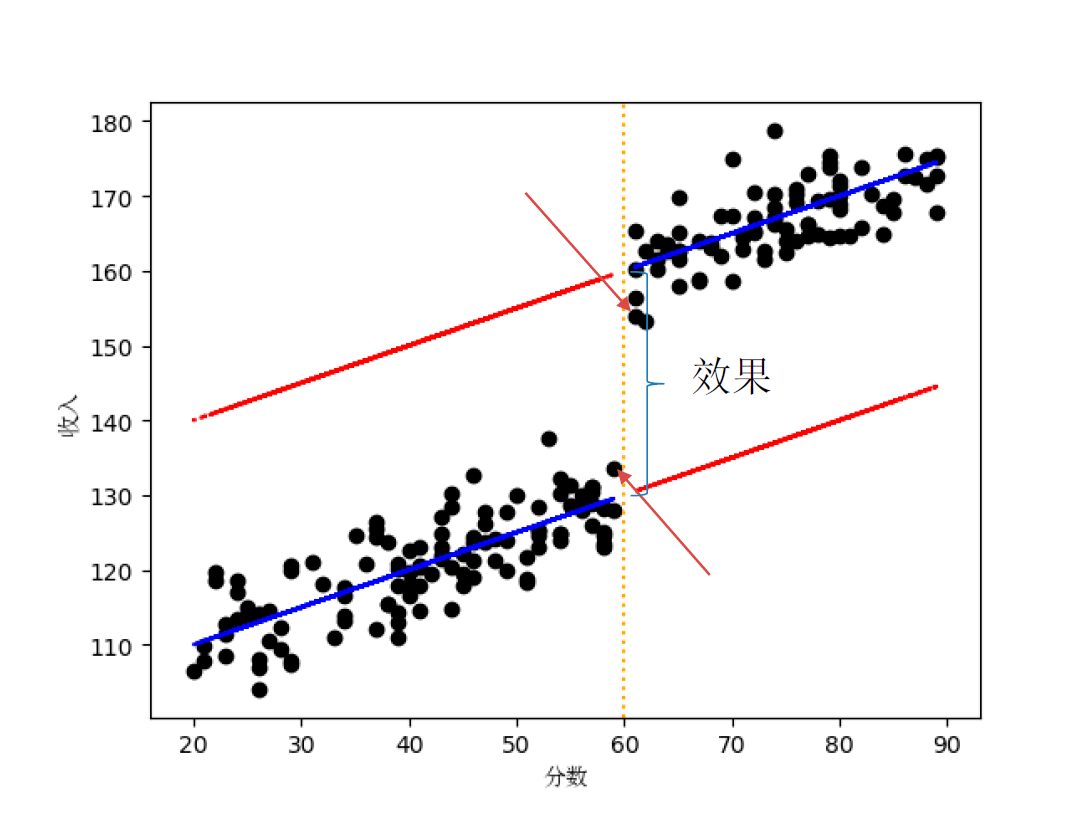
老章:好的,其实断点回归(RDD)的核心逻辑特别简单。假设我们想研究“奖学金对学生成绩的影响”,直接比较拿奖学金和没拿奖学金的学生成绩肯定不行,因为拿奖学金的学生本身可能就更努力、更聪明,成绩好可能不是因为奖学金,而是因为他们本来就优秀。这时候,我们就可以用“及格线”作为“断点”——刚好60分及格的学生和59分不及格的学生,除了是否拿到奖学金,其他特征(比如努力程度、学习能力)几乎是一样的。这时候,两组学生成绩的差异,就可以归因于“是否拿到奖学金”本身,而不是其他因素。
简单来说,断点回归就是利用“阈值附近近似随机”的特性,把“自然实验”搬回了数据里。它的核心假设是:在阈值附近,除了处理状态,其他特征是连续的。如果这个假设成立,我们就可以用断点回归来推断因果关系。
小研:那哪些场景适合用断点回归呢?
老章:不是所有问题都能套断点回归,我一般在这几种场景下会用它:
- 政策评估:比如“最低工资标准提高对就业的影响”——运行变量是企业工资水平,阈值是最低工资标准,当企业工资水平超过最低工资标准时,就需要提高工资;
- 项目效果分析:比如“扶贫项目对农户收入的影响”——运行变量是农户家庭收入,阈值是贫困线,当农户家庭收入低于贫困线时,就可以享受扶贫政策;
- 资格认定类研究:比如“职称评定对教师科研产出的影响”——运行变量是教师的科研成果数量,阈值是职称评定标准,当教师的科研成果数量超过标准时,就可以评定职称;
- 自然实验场景:比如“医院床位紧张时,急诊患者是否被收治对死亡率的影响”——运行变量是患者的病情严重程度,阈值是医院的床位容量,当患者的病情严重程度超过床位容量时,就可能被拒收。
一句话总结:当处理状态由某个连续变量是否超过阈值决定时,断点回归就是你的最佳选择。
小研:那在Stata里怎么实现断点回归呢?您能给大家演示一下吗?
老章:没问题,我用Stata自带的参议院选举数据(rdrobust_senate.dta)来演示,你可以换成自己的数据。
1. 先装命令,不然白搭
要在Stata里跑断点回归,得先装rdrobust这个命令,这是目前最常用、最靠谱的断点回归工具包。 Stata代码:
ssc install rdrobust, replace // 下载最新版,避免旧版本bug2. 导入数据,先看看长啥样
导入数据后,先看看变量都有啥,心里有数。 Stata代码:
use rdrobust_senate.dta, clear // 导入数据
edit // 打开数据编辑器,看看变量都有啥
desc // 描述数据基本信息,心里有数这个数据里,vote是结果变量(下一次选举的得票率),margin是运行变量(本次选举的得票率差距,阈值是0——得票率超过0的赢了选举,没超过的输了)。
3. 先画个图,看看断点有没有“跳跃”
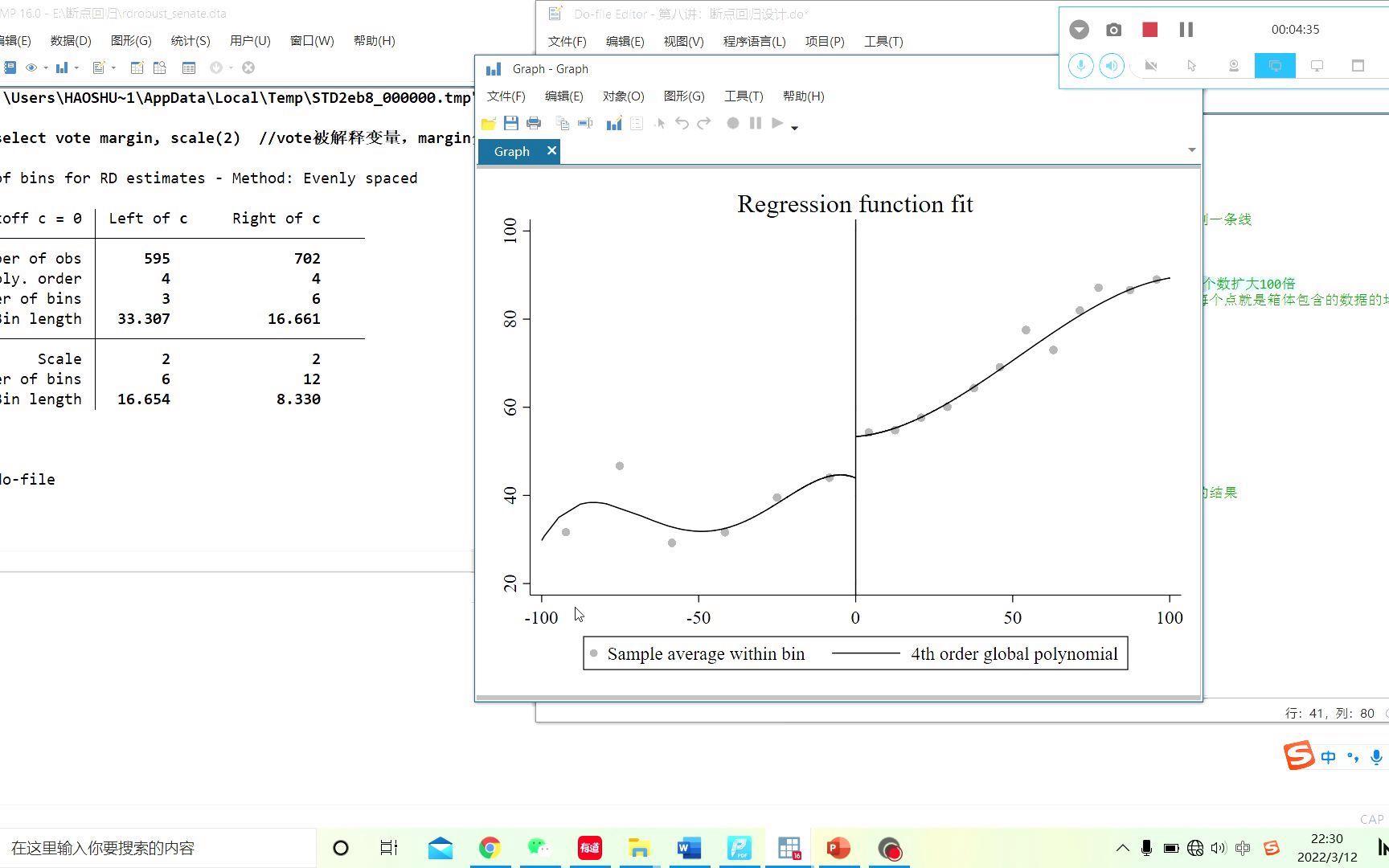
跑回归之前,一定要先画个图,直观看看断点处有没有跳跃。如果图上断点两侧的拟合线是平的,那可能就没必要跑回归了。 Stata代码:
rdplot vote margin // 绘制运行变量与结果变量的散点图及拟合线- 如果你想让图好看点,可以加个
title选项:
画出来的图应该是这样的:断点左侧是输了选举的候选人,右侧是赢了的,看看右侧的得票率是不是比左侧高——如果是,说明赢了选举对下一次得票率有影响。rdplot vote margin, title("断点回归散点图") // 给图加个标题
4. 跑回归,估计处理效应
接下来就是核心步骤:用rdrobust命令跑断点回归,估计处理效应。 Stata代码:
rdrobust vote margin // 基本断点回归估计,默认自动选择带宽- 如果你想指定带宽,可以加个
h(15)选项:
这里的“带宽”指的是我们只用到断点附近±15范围内的样本,因为离断点太远的样本,处理组和控制组的差异可能就不是随机的了。rdrobust vote margin, h(15) // 指定带宽为15,单位是运行变量的单位
5. 稳健性检验:让结果更靠谱
审稿人最爱看稳健性检验了,我一般会做这几个:
- 换带宽:用不同的带宽跑回归,看看结果是不是稳定 Stata代码:
rdrobust vote margin, all // 汇报三种带宽选择结果(CCT、IK、CV) - 带宽选择检验:看看自动选择的带宽是不是合理 Stata代码:
rdbwselect vote margin, all // 输出不同带宽选择方法的结果 - 内生分组检验:看看运行变量在断点处有没有“堆积”——如果有,说明可能有人操纵了运行变量,比如为了获得奖学金故意考到60分,这时候断点回归的结果就不可信了 Stata代码:
这个命令会画出运行变量的密度图,如果断点处的密度没有跳跃,说明分组是外生的,结果靠谱。DCdensity margin, breakpoint(0) generate(Xj Yj r0 fhat se_fhat)
小研:那怎么解读断点回归的结果呢?
老章:跑出来回归结果,我一般会先看这几个关键指标:
- 处理效应估计值:比如结果里的
tau,就是断点处的局部平均处理效应(LATE)——比如tau=0.05,说明赢了选举的候选人,下一次选举的得票率会比输了的高5个百分点; - 标准误和p值:p值<0.05说明处理效应显著,标准误越小说明结果越稳定;
- 带宽:看看自动选择的带宽是不是合理,一般来说,带宽越小,样本越接近断点,结果越可靠,但样本量也会越少;
- 稳健性检验结果:换带宽后的结果是不是和原来的差不多,密度检验的p值是不是>0.05(说明没有内生分组)。
小研:那在论文里怎么应用断点回归呢?有什么技巧吗?
老章:论文应用断点回归,我一般会注意这几点:
- 图比表重要:论文里一定要放
rdplot画的图,直观展示断点处的跳跃,比一堆数字有说服力; - 多做稳健性检验:除了换带宽,还可以换多项式次数(比如用线性拟合还是二次拟合)、排除离断点太远的样本,让结果更靠谱;
- 解释要接地气:别光说“处理效应显著”,要解释成“赢了选举的候选人,下一次选举的得票率会比输了的高5个百分点,这说明现任优势确实存在”;
- 和其他方法对比:可以和OLS、DID等方法的结果对比,突出断点回归的优势——比如“OLS估计的现任优势是10个百分点,但断点回归估计的是5个百分点,说明OLS可能存在遗漏变量偏差”。
小研:最后,您对刚接触断点回归的同学有什么建议吗?
老章:我想给大家提几点建议:
- 别随便选阈值:阈值必须是外生的,不能是人为设定的——比如你不能随便选一个销售额作为阈值,必须是政策规定的、客观存在的阈值;
- 别忽略稳健性检验:审稿人特别看重稳健性检验,如果你只放了一个回归结果,很可能会被打回来;
- 别用离断点太远的样本:带宽太大的话,处理组和控制组的差异可能就不是随机的了,结果会有偏差;
- 别把断点回归当万能药:如果运行变量在断点处有堆积(内生分组),或者断点附近的样本量太少,断点回归的结果就不可信了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)