使用 pgmpy 从零实现泰坦尼克号贝叶斯网络:数据清理、可视化、推理与因果讨论
摘要
这篇文章记录了一个可以直接运行的 pgmpy 贝叶斯网络项目,目标不是停留在“概念介绍”,而是真正把 Titanic 数据集从原始表格一步步处理成可用于离散贝叶斯网络建模的形式,并给出可复现的训练、推理、结构学习和可视化结果。
整套流程已经在 python313_env 环境下实际跑通,最终结果如下:
- 手工结构模型准确率:
0.8268 - 自动结构学习模型准确率:
0.7877 - 典型推理结果:在
女性 + 头等舱 + 高票价 + 有舱位信息条件下,生还后验概率约为0.9664
代码:https://gitee.com/wangbo00129/pmgpy_learning
1. 为什么选贝叶斯网络
做 Titanic 预测时,最常见的做法通常是逻辑回归、随机森林、XGBoost 之类的判别模型。这些模型在分类任务上通常表现不错,但不太擅长回答下面这种问题:
- 已知一个乘客是女性、头等舱、高票价,她的生还概率大概是多少?
- 如果已知一个乘客最终生还,那么他最可能是什么年龄段、什么舱位?
贝叶斯网络的优势就在这里。它不仅能做预测,还能做后验推理。换句话说,它不只是给你一个类别标签,而是给你一个结构化的概率解释。
当然,贝叶斯网络也不是没有代价。最明显的问题有两个:
- 连续变量通常需要离散化。
- 结构方向很容易被误读成“因果方向”。
本文后面会专门讨论第二点。
2. 数据集与实验设置
数据源使用公开版 Titanic 数据集:
https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv
实验环境:
- Python:
wb_python313_env - 核心库:
pgmpy 1.0.0 - 其他依赖:
pandas、scikit-learn、matplotlib、seaborn
代码会自动下载数据,并在脚本中完成训练集和测试集划分:
- 总样本数:
891 - 训练集:
712 - 测试集:
179
3. 数据清理:先把原始表格变成可建模的数据
原始 Titanic 数据不能直接喂给离散贝叶斯网络。原因很简单:
Age和Fare是连续值Cabin有大量缺失Name是字符串,不能直接拿来建离散 CPTPclass原本从1开始,而pgmpy里离散状态更适合统一成0起始编码
因此本项目做了如下清洗:
| 字段 | 处理方式 | 最终编码 |
|---|---|---|
Pclass |
舱位等级减一 | 0/1/2 |
Sex |
female=0, male=1 |
0/1 |
Age |
先按称谓插补,再离散成 3 档 | 0/1/2 |
Fare |
用分位数离散成 3 档 | 0/1/2 |
Cabin |
只保留是否有舱位号 | 0/1 |
Survived |
原标签保留 | 0/1 |
其中有两点值得单独说:
3.1 Age 不是直接用全局中位数补
这里先从 Name 中抽取称谓 Title,例如 Mr、Mrs、Miss、Master 等,再按称谓分组估计年龄中位数。这样比简单用全局平均或中位数更合理,因为不同称谓背后的年龄分布差异很大。
关键代码如下:
data["Title"] = data["Name"].str.extract(r",\s*([^\.]+)\.")[0].str.strip()
title_median_age = data.groupby("Title")["Age"].transform("median")
data["Age"] = data["Age"].fillna(title_median_age).fillna(data["Age"].median())
3.2 Fare 的“2 类还是 3 类”冲突被统一修复
很多旧资料里会出现一个矛盾:正文说 Fare 分成 3 类,代码注释却写成“分成 2 类”。这个问题本质上是注释没更新,而不是理论上只能分 2 类。本文统一采用 3 档离散化:
data["Fare"] = pd.qcut(data["Fare"].rank(method="first"), q=3, labels=[0, 1, 2]).astype(int)
4. 先看图:数据清理和分布到底发生了什么
4.1 原始缺失值与清理后离散特征分布
下面这张图一半展示原始数据中的缺失情况,一半展示清理后离散特征的分布。
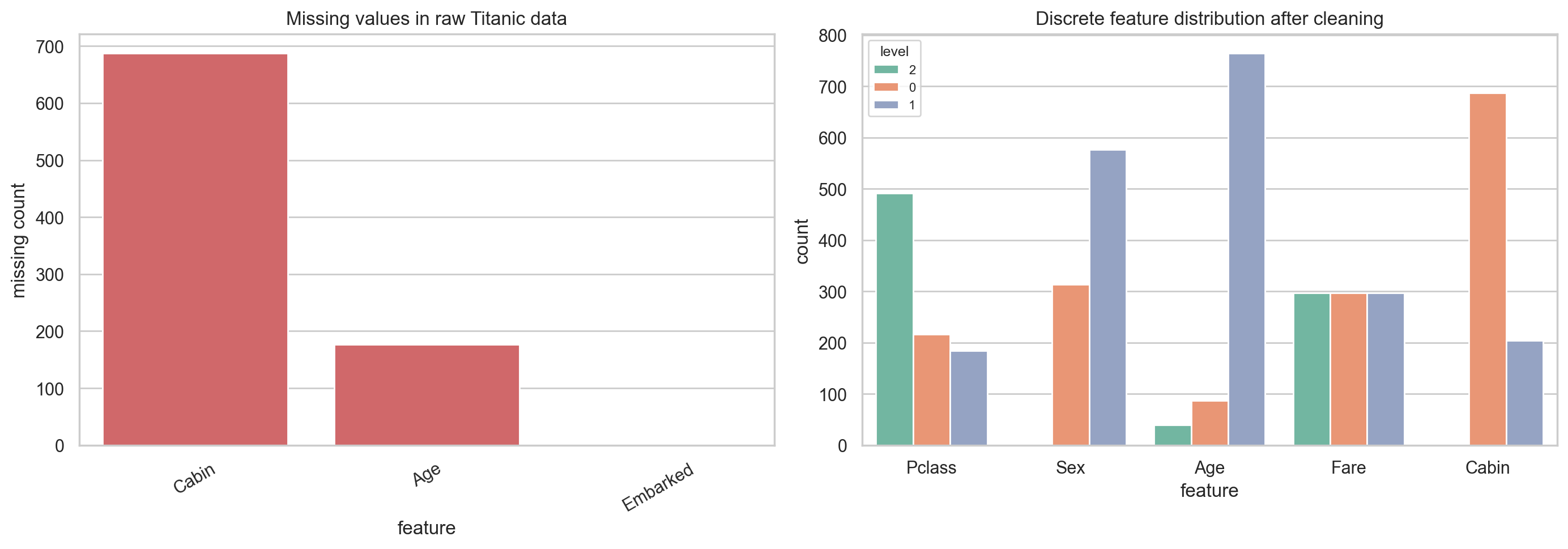
可以直接看到:
Cabin缺失非常严重Age也存在较明显缺失- 清理后的离散变量已经可以直接作为贝叶斯网络节点输入
4.2 不同特征与生还率的关系
把连续变量离散化之后,再看不同特征分组下的生还率,会更容易判断哪些变量适合作为网络中的核心节点。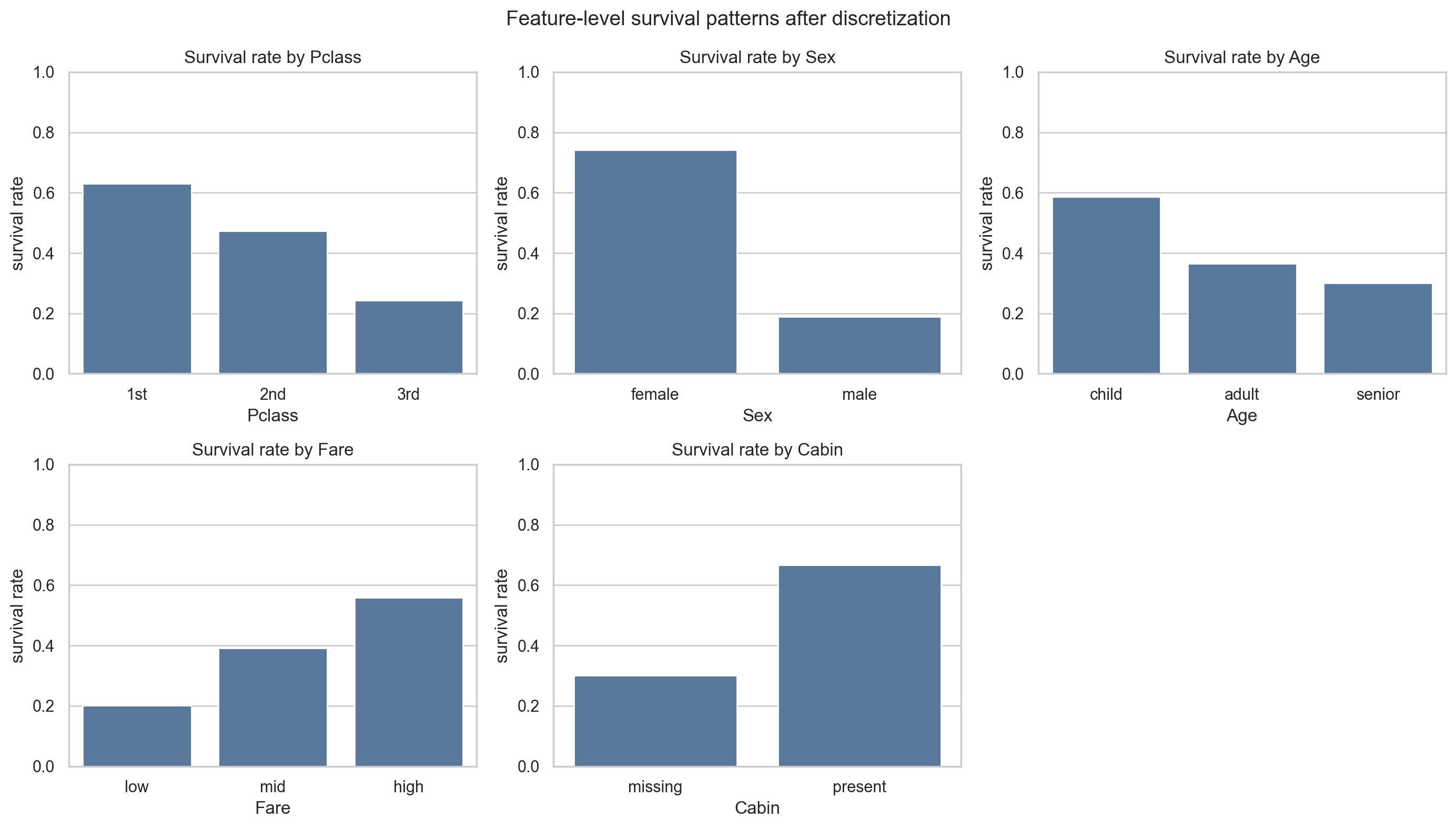
从图上很容易读出几个直觉:
- 女性生还率明显更高
- 高等级舱位生还率更高
- 有舱位信息的乘客生还率更高
这些直觉也解释了为什么后面手工建图时,会优先让这些变量指向 Survived。
5. 手工设计网络结构
对于初学者来说,我更推荐先手工设计一个任务导向的网络,而不是一开始就把结构学习算法搬上来。原因很简单:手工结构更容易解释,也更方便检查每条边是不是符合常识。
本文使用的手工结构如下:
edges = [
("Sex", "Survived"),
("Pclass", "Survived"),
("Age", "Survived"),
("Cabin", "Survived"),
("Fare", "Survived"),
]
model = DiscreteBayesianNetwork(edges)
这张图就是对应的人工结构:
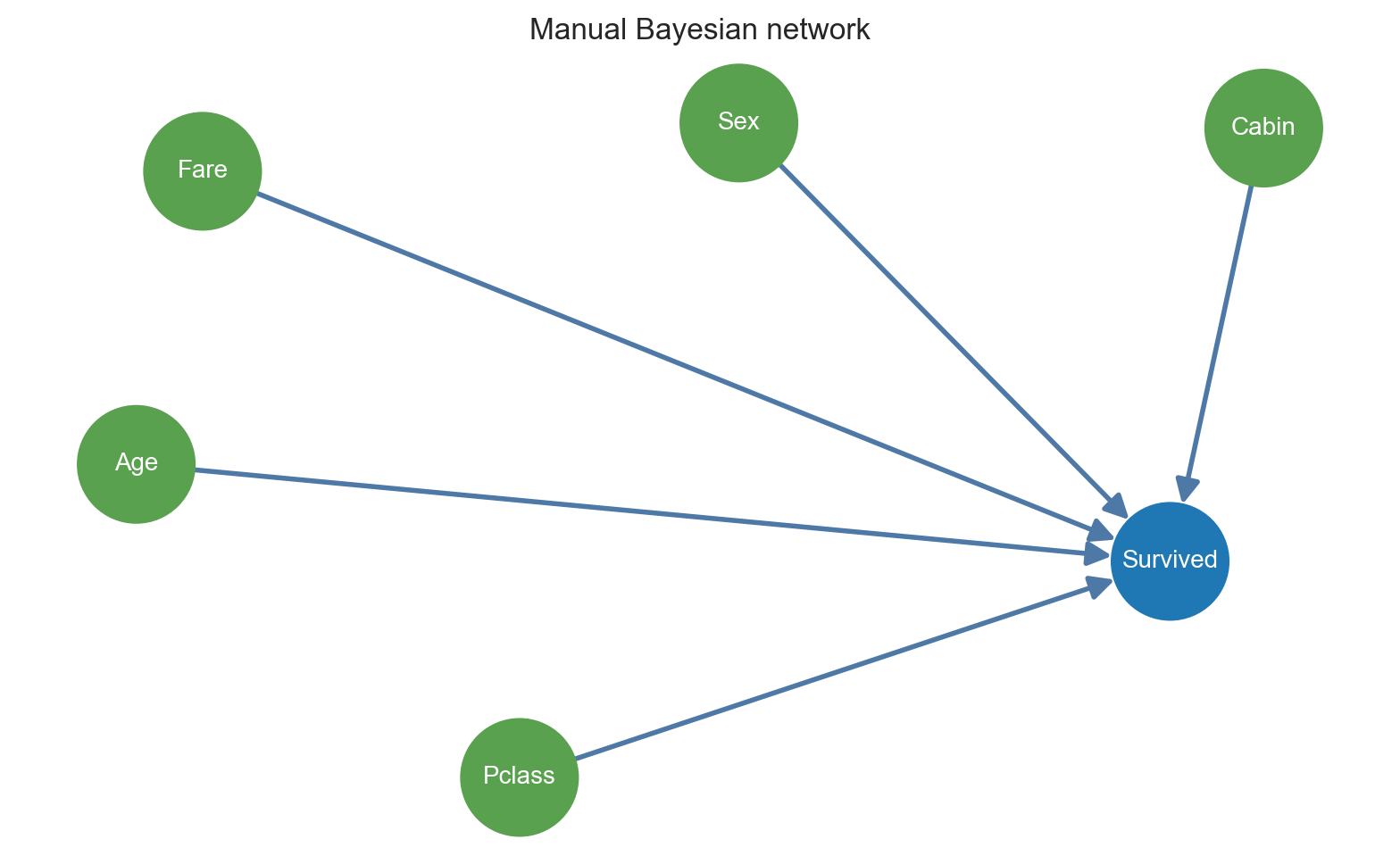
这个结构的含义很直接:
- 性别影响生还率
- 舱位影响生还率
- 年龄影响生还率
- 是否有舱位信息影响生还率
- 票价影响生还率
它未必是最严格的因果图,但对“给定乘客信息预测是否生还”这个任务,是一个非常容易理解的分类导向结构。
6. 参数学习:为什么这里用 BayesianEstimator
结构定下来之后,下一步就是参数学习,也就是估计每个节点对应的条件概率表。
这里没有使用极大似然估计,而是使用了 BayesianEstimator:
model.fit(
train_df,
estimator=BayesianEstimator,
prior_type="BDeu",
equivalent_sample_size=10,
)
这样做的原因是:
- Titanic 数据量不算大
- 离散化之后,每个节点组合状态数会上升
- 纯频数估计容易出现某些条件组合概率过于极端
BDeu 相当于在每个离散状态上加了平滑,通常会比裸的最大似然更稳定。
7. 贝叶斯推理:这才是最有意思的部分
训练完模型之后,我们可以真正拿它做后验推理。
7.1 给定乘客特征,求生还概率
例如设定证据:
- 女性
- 头等舱
- 高票价
- 有舱位信息
代码如下:
inference = VariableElimination(model)
posterior = inference.query(
variables=[TARGET],
evidence={"Sex": 0, "Pclass": 0, "Fare": 2, "Cabin": 1},
show_progress=False,
)
实际结果是:
- P(Survived=1∣evidence)=0.9664P(\text{Survived}=1 \mid evidence) = 0.9664P(Survived=1∣evidence)=0.9664
- P(Survived=0∣evidence)=0.0336P(\text{Survived}=0 \mid evidence) = 0.0336P(Survived=0∣evidence)=0.0336
这个结果本身就比“直接给一个 0/1 预测”更有解释力,因为它告诉我们模型对这组证据的置信程度。
7.2 已知乘客生还,反推最可能的特征组合
这个问题用 MAP 推理来做:
most_likely_profile = inference.map_query(
variables=FEATURES,
evidence={TARGET: 1},
show_progress=False,
)
得到的最可能特征组合是:
{
"Cabin": 0,
"Fare": 2,
"Age": 1,
"Pclass": 2,
"Sex": 1
}
这说明在当前模型下,如果只知道“该乘客生还了”,最可能对应的是:
- 成年
- 高票价
- 三等舱编码层级
- 男性
- 无舱位信息
这类 MAP 结果不一定完全符合朴素直觉,但它恰好反映了:贝叶斯网络在做的是联合概率上的最优解释,而不是“按单变量生还率分别挑最优值”。
8. 结构学习:让数据自己找边
除了手工结构,这个项目还补了一版自动结构学习,使用的是:
- 搜索方法:
HillClimbSearch - 评分函数:
BIC
核心代码如下:
estimator = HillClimbSearch(train_df)
learned_dag = estimator.estimate(scoring_method=BIC(train_df), show_progress=False)
model = DiscreteBayesianNetwork(learned_dag.edges())
自动学习出来的结构如下:
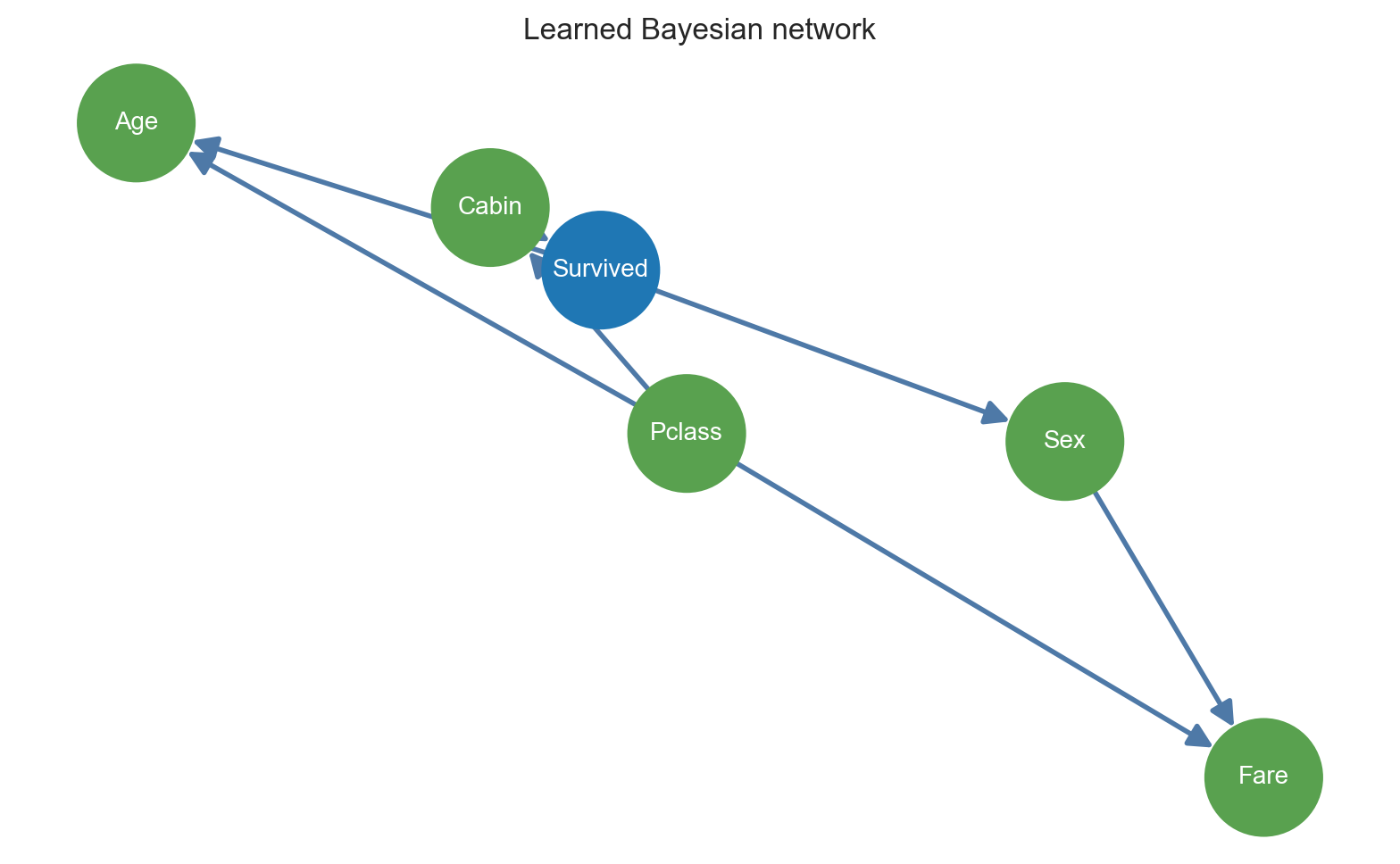
对应的边为:
Pclass -> FarePclass -> CabinPclass -> AgeCabin -> SurvivedSex -> FareSurvived -> SexSurvived -> Age
这里已经出现一个很值得讨论的问题:为什么会学出 Survived -> Sex 和 Survived -> Age 这种看起来违反常识的边?
9. 为什么会出现“违反因果”的边
这是很多人第一次接触结构学习时最容易误解的地方。
9.1 结构学习学到的是统计依赖,不等于学到因果
HillClimbSearch + BIC 在这里做的是:
- 找一个能较好解释观测数据联合分布的图
- 让评分函数尽可能高
它并没有被告知“性别不可能由生还结果决定”这种物理常识。所以只要两个方向在统计上都能较好解释数据,算法就可能选出一个和真实因果不一致的方向。
9.2 观测数据通常无法唯一决定边方向
只用观测数据而没有干预数据时,很多 DAG 在统计上是马尔可夫等价的。也就是说:
- 不同的方向
- 可能对应相同的条件独立关系
这时评分搜索很可能挑到一个“能解释数据,但不符合常识”的方向。
9.3 把目标变量也放进结构学习,会更容易得到反向边
在分类任务里,如果把 Survived 一起交给结构学习,算法经常会把标签也当作普通节点处理。这样学出来的图可能对预测有帮助,但不应直接解释成“因果图”。
9.4 应该怎样处理这个问题
如果你的目标是预测,可以接受一部分“方向不自然”的边,因为它们本质上只是帮助联合概率建模。
如果你的目标是因果解释,就不应该直接信任纯数据驱动结构学习结果,而应该:
- 加入专家先验约束
- 限制某些边方向
- 使用干预或时序数据辅助判断因果方向
换句话说:
- 手工结构更像“可解释的任务模型”
- 自动结构学习更像“数据驱动的统计依赖图”
两者不能混为一谈。
10. 模型效果对比
本项目中,手工结构和自动结构学习都进行了测试集评估。结果如下: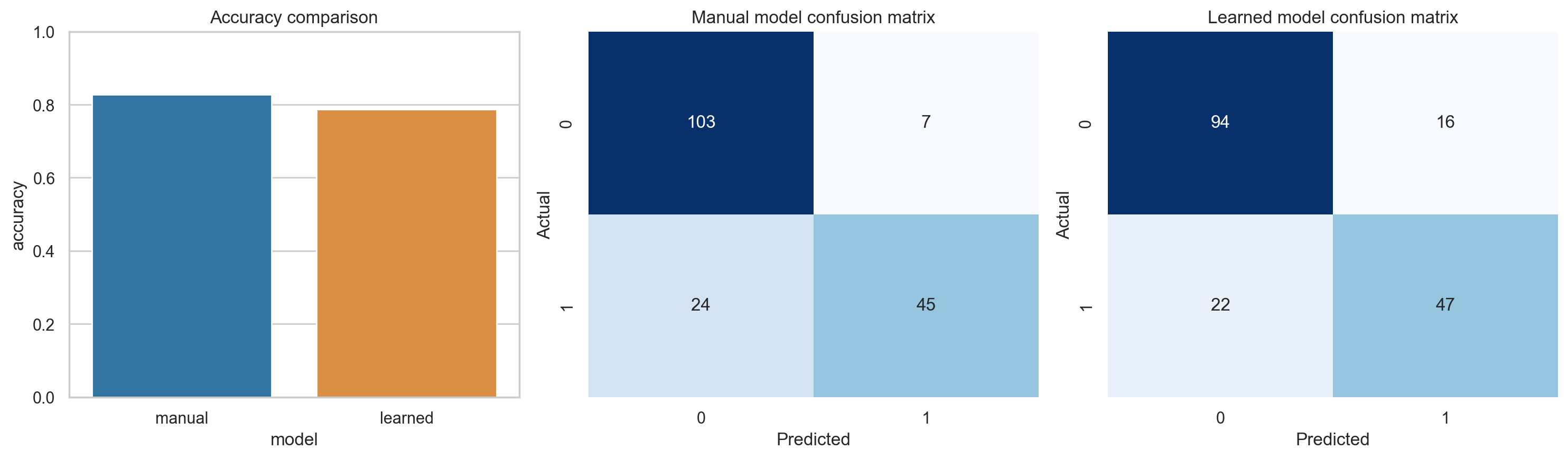
指标总结:
- 手工结构准确率:
0.8268 - 自动结构学习准确率:
0.7877
这说明一件非常实际的事:
在小样本、低维、强先验任务里,手工设计的结构往往并不比自动结构学习差,甚至可能更稳。
这是因为人工结构在一开始就把目标导向压进去了,而纯搜索结构更容易被局部统计关系干扰。
11. 项目里最关键的代码片段
如果只看 4 段代码,我认为下面这几段最值得记住。
11.1 数据离散化
data["Age"] = pd.cut(data["Age"], bins=[-1, 15, 55, 120], labels=[0, 1, 2]).astype(int)
data["Fare"] = pd.qcut(data["Fare"].rank(method="first"), q=3, labels=[0, 1, 2]).astype(int)
data["Pclass"] = (data["Pclass"] - 1).astype(int)
11.2 手工结构定义
edges = [
("Sex", "Survived"),
("Pclass", "Survived"),
("Age", "Survived"),
("Cabin", "Survived"),
("Fare", "Survived"),
]
11.3 贝叶斯参数学习
model.fit(
train_df,
estimator=BayesianEstimator,
prior_type="BDeu",
equivalent_sample_size=10,
)
11.4 批量 MAP 预测
def batch_map_predict(model, features_df):
inference = VariableElimination(model)
predictions = []
for record in features_df.to_dict(orient="records"):
result = inference.map_query(variables=["Survived"], evidence=record, show_progress=False)
predictions.append(int(result["Survived"]))
return predictions
这里特意没有直接使用 pgmpy 的某些内置 predict 接口,是因为 pgmpy 1.0.0 在当前环境里会遇到兼容问题。逐条 map_query 虽然朴素,但更稳定,也更适合教学场景。
12. 如何复现
如果你想自己跑一遍,执行下面两条命令就够了:
pip install -r requirements.txt
python bn_titanic_pgmpy.py
运行完成后,会自动生成:
artifacts/run_report.jsonartifacts/report_summary.mdartifacts/figures/*.pngartifacts/titanic_manual_bn.pkl
13. 总结
这次实践里,真正值得记住的不是 Titanic 本身,而是下面这几条经验:
- 贝叶斯网络非常适合做“带解释的预测”和“后验推理”。
- 离散化和缺失值处理,是贝叶斯网络建模里最重要的工程步骤之一。
- 手工结构通常比盲目结构学习更适合初学者入门。
- 自动结构学习得到的边方向,不能直接等价于因果方向。
- 想做预测,可以接受统计结构;想做因果,必须加入额外先验或干预信息。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)