AI编程5:LangGraph评估器-优化器模式 (Evaluator-Optimizer),让 AI 学会 “自我迭代优化“
·
作者:WangQiaomei版本:1.0(2026/3/18)
核心场景:AI 生成内容自动评估→迭代优化,直到满足要求(生成笑话 / 文案 / 代码 / 翻译皆适用)
🔥前言:为什么需要 "评估 - 优化" 模式?
你是否遇到过:AI 生成的内容一言难尽?写的笑话不好笑、翻译不精准、代码有 BUG?
传统 AI 生成是 "一次性输出",而Evaluator-Optimizer(评估器 - 优化器)模式 能让 AI 像人类一样:✅ 生成内容 → ✅ 自我评估 → ❌ 不好就改进 → ✅ 重新评估 → 直到达标!
本文以 "AI 生成好笑的猫咪笑话" 为例,手把手教你实现这个能自我迭代的 LangGraph 工作流!
🎯核心工作流:AI 自我迭代的闭环
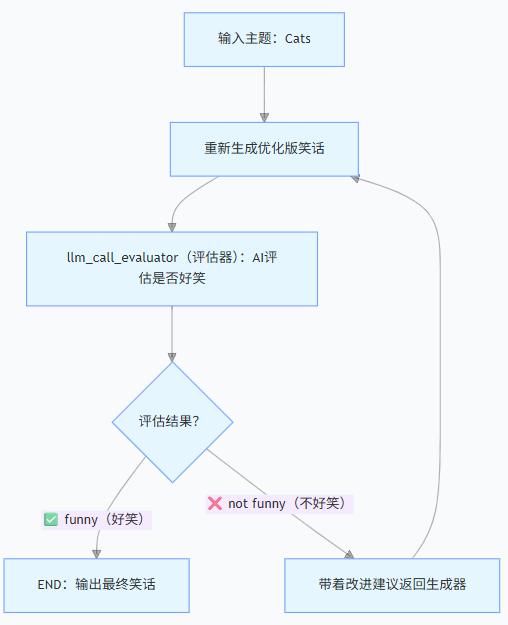
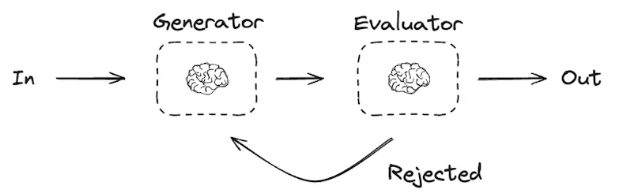
工作流亮点
- 闭环迭代:无需人工介入,AI 自主完成 "生成→评估→优化" 循环
- 结构化评估:评估结果标准化(好笑 / 不好笑 + 改进建议)
- 通用适配:可无缝迁移到翻译、文案、代码生成等场景
🛠️核心组件拆解
表格
| 组件 | 核心作用 | 关键细节 |
|---|---|---|
| llm_call_generator | 内容生成器 | 首次生成 / 基于反馈优化生成(支持多轮迭代) |
| llm_call_evaluator | 智能评估器 | 结构化输出:grade(评分)+ feedback(改进建议) |
| Feedback(Pydantic 模型) | 评估结果规范 | 限定 grade 为 "funny/not funny",强制输出改进建议 |
| route_joke | 条件路由 | 控制流程走向:达标则结束,不达标则回退优化 |
🔑关键代码解析(核心逻辑)
1. 结构化评估结果定义(避免 AI 乱输出)
python
运行
from pydantic import BaseModel, Field
from typing_extensions import Literal
class Feedback(BaseModel):
# 限定评分只能是"funny"或"not funny",杜绝模糊评价
grade: Literal["funny", "not funny"] = Field(description="Decide if the joke is funny or not.")
# 强制AI给出改进建议,为迭代提供方向
feedback: str = Field(description="If not funny, provide improvement suggestions.")
# 让AI输出结构化结果,而非自由文本
evaluator = llm.with_structured_output(Feedback)
2. 条件路由(控制迭代逻辑)
python
运行
def route_joke(state: State):
"""核心:判断是否继续迭代"""
if state["funny_or_not"] == "funny":
return "Accepted" # 达标→结束流程
else:
return "Rejected + Feedback" # 不达标→返回生成器优化
3. 多轮生成逻辑(根据反馈优化)
python
运行
def llm_call_generator(state: State):
"""有反馈则优化,无反馈则首次生成"""
if state.get("feedback"): # 多轮迭代:带改进建议生成
msg = llm.invoke(f"Write a joke about {state['topic']}, improve with feedback: {state['feedback']}")
else: # 第一轮:基础生成
msg = llm.invoke(f"Write a joke about {state['topic']}")
return {"joke": msg.content}
📝完整可运行代码
python
运行
# -*- coding: utf-8 -*-
from langgraph.graph import StateGraph, START, END
from IPython.display import Image, display
from langchain_openai import ChatOpenAI
# 1. 定义全局状态
class State(TypedDict):
joke: str # 生成的笑话
topic: str # 笑话主题
feedback: str # 改进建议
funny_or_not: str # 评估结果
# 2. 定义评估结果结构化模型
class Feedback(BaseModel):
grade: Literal["funny", "not funny"] = Field(description="Decide if the joke is funny or not.")
feedback: str = Field(description="If not funny, provide improvement suggestions.")
# 3. 绑定结构化输出到评估器
evaluator = llm.with_structured_output(Feedback)
# 4. 节点1:生成器(生成/优化笑话)
def llm_call_generator(state: State):
if state.get("feedback"):
msg = llm.invoke(f"Write a joke about {state['topic']}, improve with feedback: {state['feedback']}")
else:
msg = llm.invoke(f"Write a joke about {state['topic']}")
return {"joke": msg.content}
# 5. 节点2:评估器(评估笑话+给出建议)
def llm_call_evaluator(state: State):
grade = evaluator.invoke(f"Grade the joke: {state['joke']}")
return {"funny_or_not": grade.grade, "feedback": grade.feedback}
# 6. 条件路由:控制迭代逻辑
def route_joke(state: State):
if state["funny_or_not"] == "funny":
return "Accepted"
else:
return "Rejected + Feedback"
# 7. 构建工作流
optimizer_builder = StateGraph(State)
optimizer_builder.add_node("llm_call_generator", llm_call_generator)
optimizer_builder.add_node("llm_call_evaluator", llm_call_evaluator)
# 8. 连接节点:构建迭代闭环
optimizer_builder.add_edge(START, "llm_call_generator")
optimizer_builder.add_edge("llm_call_generator", "llm_call_evaluator")
optimizer_builder.add_conditional_edges(
"llm_call_evaluator",
route_joke,
{"Accepted": END, "Rejected + Feedback": "llm_call_generator"}
)
# 9. 编译并运行
optimizer_workflow = optimizer_builder.compile()
# 可视化工作流(可选)
display(Image(optimizer_workflow.get_graph().draw_mermaid_png()))
# 执行:生成关于Cats的好笑笑话
result = optimizer_workflow.invoke({"topic": "Cats"})
# 输出最终结果
safe_print("🎉 最终生成的好笑笑话:\n" + result["joke"])
📌执行示例(真实运行过程)
plaintext
第1轮:AI生成 → "Why do cats like boxes? Because they fit!" → 评估器:"not funny,梗太老"
第2轮:AI优化 → "Why do cats love boxes? They’re hiding from their human’s bad TikTok dances!" → 评估器:"not funny,不够有梗"
第3轮:AI再优化 → "What do you call a cat that can program? A purr-ogrammer! 🐱💻" → 评估器:"funny!"
✅ 最终输出:What do you call a cat that can program? A purr-ogrammer! 🐱💻
💡超实用的扩展场景(不止生成笑话!)
表格
| 场景 | 改造思路 |
|---|---|
| 📝文案改写 | 评估器判断 "是否符合品牌调性",反馈 "修改语气 / 增加卖点" |
| 📖翻译优化 | 评估器判断 "语义是否准确",反馈 "调整语序 / 修正专业术语" |
| 💻代码生成 | 评估器判断 "是否通过单元测试",反馈 "修复 BUG / 优化性能" |
| 📊报告生成 | 评估器判断 "数据是否准确",反馈 "补充分析维度 / 修正结论" |
🚩注意事项
- API Key 安全:不要硬编码,建议通过环境变量读取(
os.getenv("DASHSCOPE_API_KEY")) - 迭代次数限制:可添加
max_iterations参数,避免无限循环(比如最多迭代 5 次) - 评估标准自定义:修改
Feedback模型的grade字段,适配不同场景(如 "合格 / 不合格"、"精准 / 不精准")
🎯总结
Evaluator-Optimizer 模式是 LangGraph 最实用的进阶玩法之一,核心价值在于:
- 把 AI 从 "一次性生成" 升级为 "闭环迭代优化",内容质量大幅提升;
- 结构化评估 + 条件路由,让迭代逻辑可控、可追溯;
- 通用架构适配多场景,改改提示词就能复用。
下次再遇到 AI 生成内容不达标的情况,别手动改了,让 AI 自己卷起来!💪
如果你需要进阶教程,可以留言:
✅ 如何添加迭代次数限制
✅ 如何接入本地大模型(Llama3/Qwen)
✅ 如何封装成 API 接口供前端调用

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)