啥是AI Agent
痛点问题
你上个季度发布了一个聊天机器人。它能很好地理解客户的意图。它生成有用且格式良好的回答。你的项目经理在演示中用“神奇”来形容它。
然后有顾客要求退款。聊天机器人说“我来帮你处理!”但完全没有反应。它信誓旦旦的说自己能处理退款,但实际上并没有处理。它无法访问订单数据库。它无法调用退款API。它甚至无法检查退货窗口是否还在。它只能......对话。
客户截图了回复,发布在X(推特)平台,现在你的客户副总裁正在给你的CEO发短信...
你遇到了每个构建大型语言模型团队最终都会遇到的瓶颈:模型能推理出该做什么,但做不到。它没有手。
AI Agent能够给它双手。但这到底意味着什么?为什么从OpenAI到你的CEO都说2026年是“Agent 之年”?我们来聊聊这个。
先概括下
-
AI Agent是一种软件系统,利用大语言模型作为“大脑”来推理,决定使用哪些工具,并循环执行操作直到工作完成。
-
没有Agent的LLM就像一个只会说话的高级工程师。它可以在白板上诊断问题,但无法直接接触服务器。代理给了他一个终端。
-
核心循环很简单:思考→行动→观察→重复。代理推理、调用函数、检查结果,并决定继续执行还是提供答案。
-
Klarna的Agent处理了三分之二的客服聊天,并将解决时间从11分钟缩短到不到2分钟。然而,他们不得不重新雇佣人类。AI Agent擅长处理受限的任务,但是开放性任务就不太行了。
让我们详细看下。
在有Agent之前,聊天机器人表现也可圈可点
要理解代理人为何重要,你需要了解他们出现之前的情况。以及为什么无法满足需求。
传统的聊天机器人(可以想象成老派的,LLM之前的那种)基本上就是一棵if/else判断树:
-
顾客说“退款”,→显示退款政策。
-
顾客说“营业时间” →显示营业时间。
后来大型语言模型出现,聊天机器人也更能理解你的意思。你可以说“嘿,我买错了码,想把东西寄回去”,LLM会理解你想要退货,尽管你从未说过“退货”这个词。这是巨大的升级。
LLM是只会说话的高级工程师。它可以在白板上调试你的系统,但不能通过SSH进入服务器、运行查询或推送修复。它只会纸上谈兵,完全没有具体执行动作。
当给这个高级工程师一个终端后,他就成了“Agent”。
没有终端的工程师
这就是它的内部构造。一个普通的LLM聊天机器人,不能使用任何工具,也不使用任何代理框架。
顾客: “我需要你退还订单号为 4821 的款项。我两天前已经退货了。”
LLM聊天机器人:
1. 理解意图:退款请求
2. 生成一条听起来很有帮助的回复:“我很乐意帮您办理退款!让我帮您查看一下订单号 4821。”
3. ……但它实际上无法查找订单号 4821。它没有权限访问您的订单数据库。它不知道退货是否已被收到。它也不知道退款期限是否仍然有效。
所以它要么凭空捏造细节(“您的 47.99 美元退款已处理”,而它根本不知道订单总额是多少),要么敷衍了事(“请联系我们的支持团队support@company.com ”)。
具体问题:
1. 无法访问实时数据。LLM的知识停留在培训时的状态。它不知道您客户的订单状态、您当前的库存或您的退款政策(您上周四才更新过)。
2. 无法采取任何行动。即使LLM完全理解了情况,它也无法调用您的退款API、更新数据库记录或发送确认邮件。它只能发送短信,仅此而已。
3. 无法进行多步骤推理。复杂任务需要检查一个条件,并根据结果决定下一步,然后将多个操作串联起来。单个 LLM 调用是一次性的,没有暂停、获取更多信息后再返回的机制。
注意一个容易混淆的点:有人说“但是 ChatGPT 可以浏览网页和运行代码!” 是的,因为 ChatGPT是一个Agent。当您看到它搜索网页时,它是通过代理循环使用工具来实现的。底层 LLM 本身无法执行这些操作。
这时,你可能在想:好吧,那么如何让LLM访问工具并让它在一个循环中进行推理呢?这正是人工智能代理的工作原理。
AI Agent是咋工作的
AI Agent能够解决上述问。它的工作原理如下。
核心思想非常简单。与其只调用一次LLM并返回结果,不如将LLM放在一个循环中:
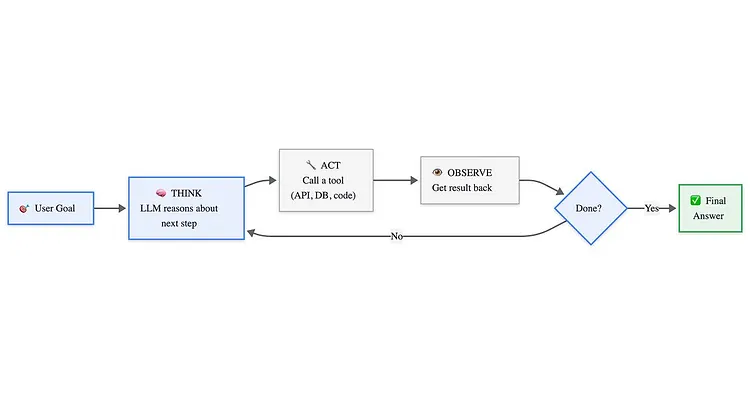
AI Agent循环:大语言模型(LLM)进行推理,通过工具采取行动,观察结果,并循环执行直至任务完成。
让我们以退款为例来具体分析:
客户说“退款订单 #4821”。AI Agent首先想到:我需要先查询这个订单才能进行操作。于是它执行操作,调用了相应的查询order_lookup("4821")。它观察到结果:订单状态为“已退货”,总金额为 47.99 美元,退货窗口已开启。
继续思考:退货已确认,退款窗口仍然开放,所以我应该处理退款。它再次执行操作process_refund("4821", 47.99),调用。它观察到:退款已完成,参考编号 RF-9920。
继续思考:我已经准备好了所有需要的东西。客服人员退出流程并回复客户:“您订单号为 4821 的 47.99 美元退款已处理完毕(参考编号:RF-9920)。您应该会在 3-5 个工作日内收到退款。”
两个循环,两次工具调用,一个完整的任务,全程无人干预。
就是这样。AI Agent在推理和执行之间循环往复,直到获得所需信息为止。
这种模式在研究文献中有一个名称:ReAct(推理+行动),出自Yao等人2023年发表的一篇论文。如果你研究过任何智能体框架(例如LangChain、LlamaIndex、CrewAI、OpenAI的Assistants API),你肯定已经见过它了。它们都在底层实现了这种循环的某种变体。
AI Agent的三个组成部分
每个代理都由三部分组成:
1. 大脑(LLM)负责推理:决定下一步行动、解释结果、处理边界情况。这就是为什么模型质量对智能体比对聊天机器人更重要的原因。模型较弱的聊天机器人只能给出平庸的答案。模型较弱的智能体会调用错误的工具,得到令人困惑的结果,然后陷入无休止的循环。循环中的每一步都是一个决策,而所有这些决策都由模型做出。
2. 工具。AI Agent可以调用的工具包括:数据库查询、API 调用、网络搜索、代码执行、文件操作等等。任何可以用函数签名封装起来的功能,代理都可以使用。关键在于:代理并不了解工具的内部工作原理。它读取每个工具的描述(名称、参数、返回值),并决定何时调用它。好的工具描述造就好的代理。模糊不清的描述则会导致代理错误地调用工具。
3. 记忆/状态。它记录着对话的运行上下文以及迄今为止执行的操作。如果没有它,AI Agent就会忘记它在每个步骤查找过的信息。在退款示例中,记忆使得智能体在执行到第二步时能够知道订单状态为“已退货”。这听起来显而易见,但一旦对话持续时间过长或跨越多个会话,管理智能体记住的内容(以及遗忘的内容)就会成为一个真正的工程难题。
大脑是工程师,工具是终端,记忆则记录着它已经尝试过的方法。
深入分析:Yao等人发表的 ReAct 原始论文表明,在问答和执行等任务中,将推理轨迹与工具使用相结合,其性能优于纯粹的思维链提示和纯粹的行动执行。核心原因:推理轨迹有助于模型从错误中恢复,并避免产生错误的工具调用。
以下是使用 LangChain 在 Python 中实现的最小代理的实际代码:
from langchain.agents import create_react_agent
from langchain_openai import ChatOpenAI
from langchain.tools import tool
@tool
def order_lookup ( order_id: str ) -> dict :
"根据订单 ID 查找订单。返回订单状态、总金额和退货窗口。"
return db.orders.find_one({ "id" : order_id})
@tool
def process_refund ( order_id: str , amount: float ) -> dict :
"处理给定订单的退款。"
return payments.refund(order_id=order_id, amount=amount)
agent = create_react_agent(
model=ChatOpenAI(model= "gpt-4" ) ,
tools=[order_lookup, process_refund],
prompt= "您是 Acme 公司的客服人员..."
)
# 客服人员内部循环,直到得到最终答案
result = agent.invoke({ "input":"退款订单 #4821" })
这大概只有 15 行代码。执行效果让人惊讶:这个create_react_agent函数会自动处理“思考 → 行动 → 观察”的循环。你只需要定义工具和提示即可。如果你觉得“这肯定不止这些”,那就对了。循环本身只有 15 行代码。剩下的 10,000 行代码是错误处理、身份验证,以及确保不会退还不存在的订单。
可能出现的问题(以及哪些方面被过度炒作)
1. 工具调用错误。智能体有时会调用不存在的工具,或者传递毫无意义的参数。这种情况在小型模型中尤为常见。如果没有进行微调或提供高质量的样本示例,其性能甚至会低于基本的逻辑推理提示。
2. 错误累积。智能体循环中的每一步都有很小的出错概率。将五个步骤串联起来,错误率就会累积。危险之处在于,最终结果看起来仍然很完美。直到用户报告错误,你才会意识到第五步出了问题。最好的前沿模型在第一次尝试中,大约只有 24% 的实际知识工作任务能够正确完成。
3. 监管跟不上。Gartner预测,到2027年,超过40%的AI Agent项目将被废弃。大语言模型(LLM)本身运行良好,问题在于其周围的因素:身份管理、审计跟踪、错误处理和合规性。
4. 炒作与现实差距。 “智能代理元年”这个说法从2024年就开始流传,但我们目前仍大多处于试点阶段。德勤发布的《2025年科技趋势报告》显示,只有大约十分之一的企业真正将智能代理投入生产,另有38%的企业仍在进行试点。技术本身没问题,问题在于企业的准备不足。如果有人告诉你,人工智能代理将在第四季度实现你整个业务的自动化,不妨问问他们上次的人工智能试点项目进展如何。
也就是说,如今这种功能专一、范围明确的代理确实能带来价值。它可以处理退款、分诊工单、搜索代码库、总结研究成果。行之有效的模式是:限定领域、清晰的工具定义,同时人工参与处理特殊情况。
人工智能代理并不会让LLM变得更智能。LLM本身就具备智能。代理赋予的是自主性:一个能够根据其已知信息采取行动的终端。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)