实战指南:如何确保因果机器学习模型的可靠性?
摘要:本文分析了如何确保您的因果机器学习的核心概念与应用实践。作者详细分析了相关技术细节,并结合实际案例展示了最佳操作流程,帮助读者提升工程效率与解决复杂问题的能力。
0 总结
在现实业务中(如预测发帖量对涨粉的影响),变量往往互为因果。作者的核心观点是: 利用“时间顺序(Timing)”作为硬约束,来确保机器学习模型捕捉到的是真正的因果关系,而非仅仅是相关性。
作者提出了一条铁律: “未来不能影响过去” 。基于此,通过严格的时间窗口划分来构建训练数据:
-
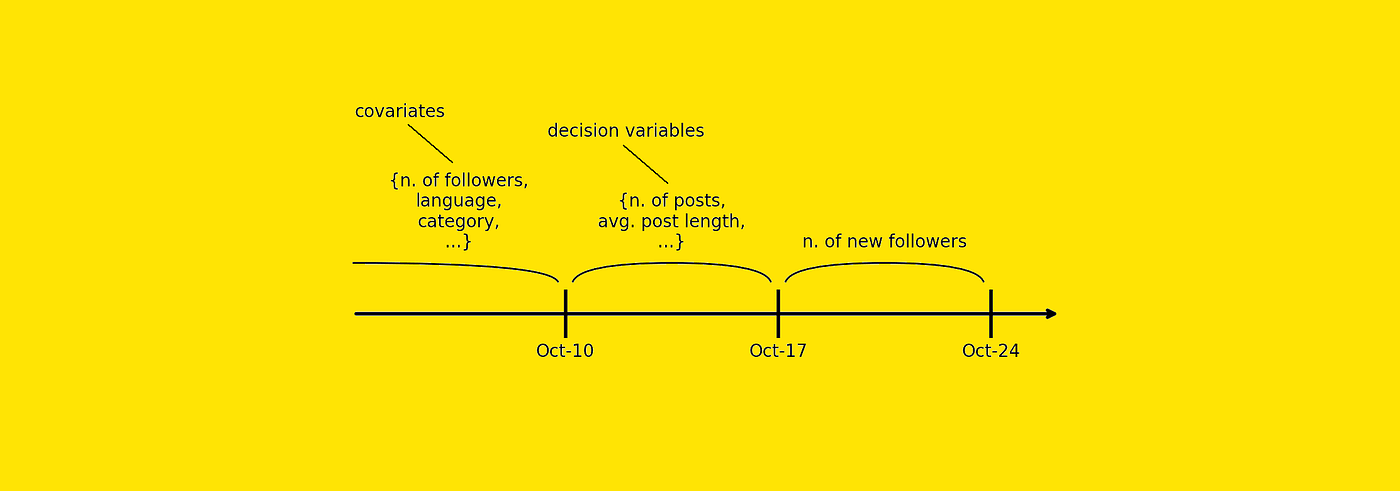
第一步:定义时间轴 将数据在时间轴上严格切分为三个阶段,确保因果流向的单向性。
-
第二步:区分两类输入变量
- 协变量 (Covariates) :
- 定义 :我们无法控制但在观察的背景信息(如初始粉丝数、用户语言、账号类别)。
- 时间窗口 :必须在决策发生 之前 ( t < t 0 t < t_0 t<t0)测量。
- 决策变量 (Decision Variables) :
- 定义 :我们可以控制或干预的动作(如发帖数量、发帖长度)。
- 时间窗口 :在特定的观测窗口内( t 0 ≤ t < t 1 t_0 \le t < t_1 t0≤t<t1)测量。
- 协变量 (Covariates) :
-
第三步:定义目标变量
- 目标变量 (Target Variable) :
- 定义 :我们要预测的结果(如新增粉丝数)。
- 时间窗口 :必须在决策窗口 之后 ( t ≥ t 1 t \ge t_1 t≥t1)测量。
原理 :通过这种设计,逻辑上切断了“新增粉丝(未来)”影响“发帖量(过去)”的可能性,迫使模型只能学习从“过去+现在”到“未来”的单向影响。
- 目标变量 (Target Variable) :
1 为实际应用构建可靠因果模型的从业者指南
因果推理的棘手部分是一切都取决于你做出的因果假设。说实话,怀疑论者很容易质疑这些假设。
这使得因果模型很难推销,我亲眼所见。
在常规机器学习中,人们会询问您可能错过的每个变量。在因果机器学习中?您会遇到双重问题:您遗漏的变量怎么样?您可能错过的关系又如何?因果机器学习带来的痛苦是常规机器学习的两倍。
那么数据从业者应该做什么呢?在本文中,我将分享一种构建因果模型的实用方法,该模型已被证明可以有效解决现实世界的问题并支持决策。
2 一个具体的例子:帖子和关注者
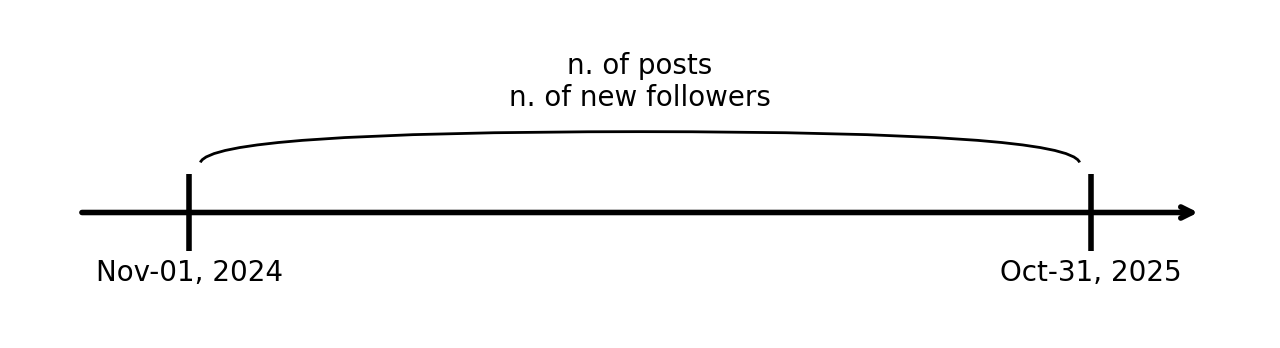
假设我们在社交网络工作,对于过去一年的每个活跃用户,我们测量了两件事:
- 他们发布的帖子数量。
- 他们获得的新关注者总数**(仅是原始新关注者,不减去他们可能失去的任何关注者)。
为了表明这两个数字是在同一时间范围内跟踪的,我们可以将它们放在时间线上:
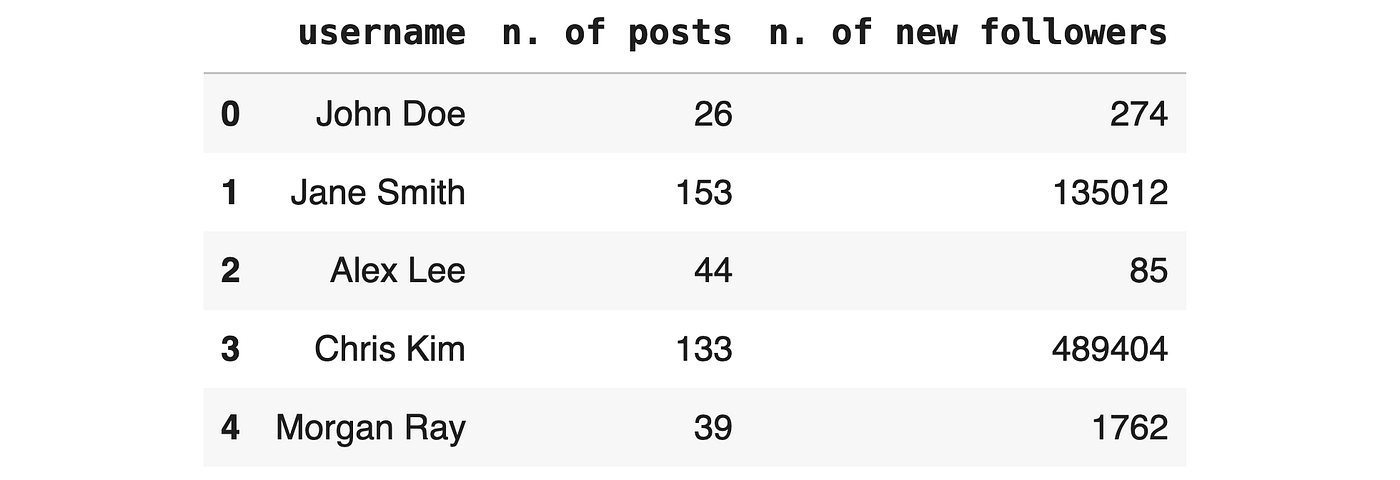
该数据集最终包含数百万行(每个用户一行)和三列:用户名、帖子计数和新关注者:
假设我们想根据帖子数量来预测新关注者的数量。在 Python 中,这可以通过以下方式完成:
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor().fit(
X=df[["n. of posts"]],
y=df["n. of new followers"]
)
如果您之前研究过因果分析,您就会知道有向图通常用于说明因果关系。在此设置中,图表显示帖子数量驱动(或“导致”)新关注者数量:

我们的假设是,如果用户决定发布不同数量的帖子,他们最终也会获得不同数量的新关注者。
看起来很合理,对吧?
3 因果图的问题
现在,想象一下您正在向您的工程团队展示这个模型。
一旦你展示了因果图,就会有人举手指出因果关系实际上可能是双向的:发帖不仅可能会带来更多的关注者,而且获得新的关注者也可能会激励用户发帖更多。
如果是这样的话,这两个变量实际上可能同时相互影响。如果是这样的话,我们的因果图就变成了一个循环而不是单向街:

根据我的经验,这是因果假设(和因果图)的主要挑战。 假设因果关系仅朝一个方向发展很少是一件容易的事。世界是混乱的,变量常常同时相互影响。
这给因果机器学习带来了真正的挑战。我们关心的是我们可以改变的事情(例如帖子数量)对某些结果(例如新粉丝)的影响。但有了这个反馈循环,就很难弄清楚到底是什么导致了什么。
为了清楚地看到发帖如何影响新关注者,我们需要消除新关注者与帖子之间的“反向”关系,并确保我们的模型仅捕获一个方向的影响。
如果我们想要隔离帖子数量对关注者增长的影响,我们必须删除因果图中从新关注者指向帖子的箭头。

但我刚才说了,世界是混乱的,变量无时无刻不在相互影响。那么,我们怎样才能做到这一点呢?
事实证明,在实际应用中,有一种可靠的方法可以做到这一点。
4 你所需要的只是时间
如果 关于因果关系,我们确定一件事,那就是未来无法影响过去。今天的天气不可能影响昨天卖出的冰淇淋数量。
这就是为什么我们可以利用时机来发挥我们的优势。例如,如果我们记录一周内的帖子数量,然后查看下一周内获得的新关注者数量:
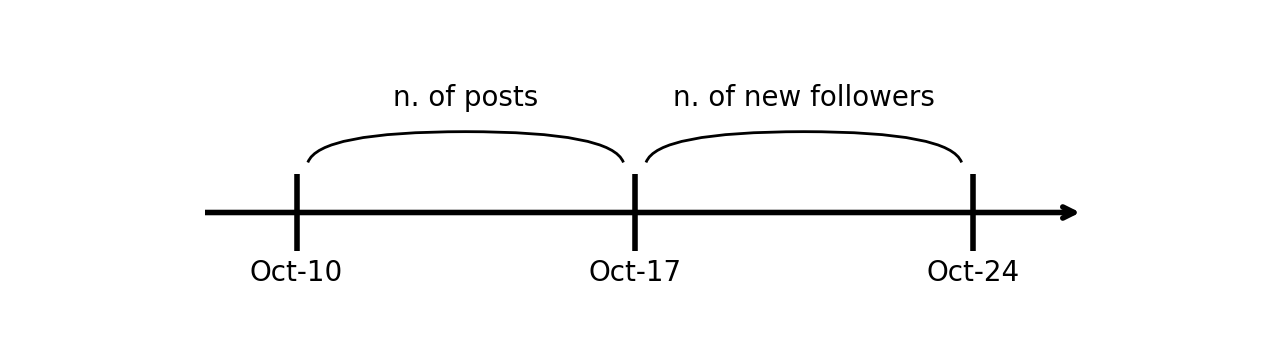
使用这种方法,没有任何歧义:因果关系只能以一种方式运行。
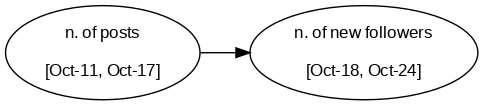
请记住:在因果图中,哪些箭头不存在更重要,而不是哪些箭头存在。
例如,如果我们假设帖子会吸引新的关注者,但实际上情况并非如此,那么这不是问题。事实上,我们的机器学习模型会识别出连接的缺乏,这完全没问题。
但如果存在一个反馈循环,新的关注者也会影响发帖活动,那么事情就会变得混乱,并且很难区分是什么导致了什么。
现在,我们利用时机,理清了帖子和新关注者之间的关系。但这是全貌吗?
说帖子数量是影响新粉丝增长的唯一因素显然是不现实的。幸运的是,机器学习的真正优势在于它能够同时处理许多变量。
5 走向多元
让我们考虑一下除了帖子数量之外,还有哪些其他因素可以帮助我们预测新的关注者。一个明显的候选者是最初的关注者数量。毕竟,无论您发布多少帖子,除非您从相似的受众群体开始,否则您都无法赶上克里斯蒂亚诺·罗纳尔多的粉丝增长速度。
因此,我们应该在模型中包含初始的关注者数量。但现在您应该已经明白,时机在这里也很重要。那么,我们到底应该在什么时候衡量关注者数量呢?
显然,不可能是在我们开始跟踪帖子数量之后;这会像我们之前讨论的那样混淆因果关系。相反,在我们的发布期开始之前记录初始关注者计数是有意义的:例如,如果我们的跟踪窗口于 10 月 11 日开始,则在 10 月 10 日。
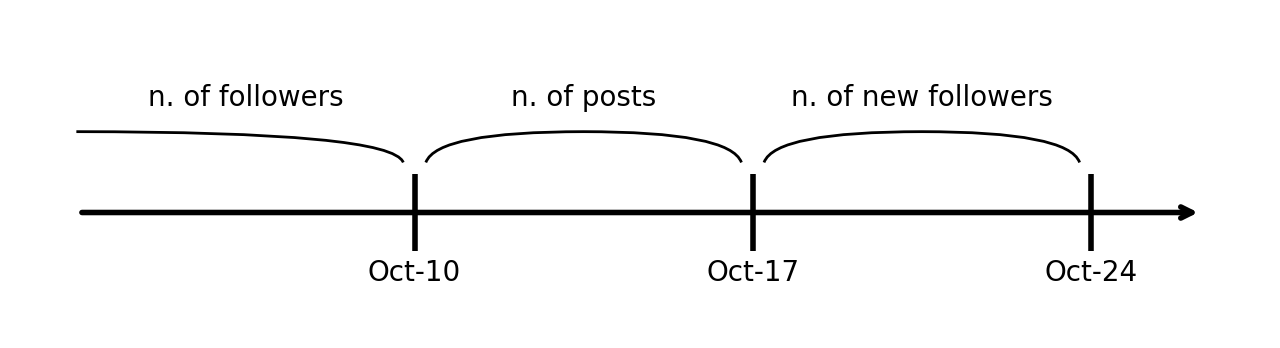
有了这个,我们就可以相应地更新我们的因果图。关键规则仍然有效:因果关系不能及时倒流。
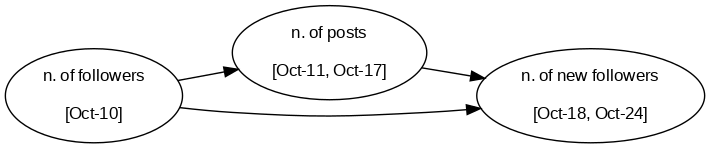
这种方法使我们的模型更加现实,但在实践中,您通常拥有的特征远不止两个。
我知道您在想什么:您是在告诉我,如果我想在模型中使用 20 个变量,我必须在不同的时间跨度中测量每个变量,以确保因果关系仅朝一个方向发展?这听起来像一场噩梦!
别担心,事实证明,当我们添加更多变量时,这种方法的复杂性不会增加。
6 只有两种类型的变量
幸运的是,只有两种类型的变量:
- 决策变量。这些在我们的控制之下。例如,我们下周将发布多少帖子。因果推理侧重于理解这些变量的变化如何影响我们感兴趣的结果。
- 协变量。这些是我们可以观察但无法控制的事情,比如我们的关注者数量。 协变量很重要,因为它们与我们的决策相互作用。例如,发布相同数量的帖子不会让您获得与克里斯蒂亚诺·罗纳尔多相同的关注者数量,因为您的起始关注者数量(协变量)非常不同。协变量改变了我们的决策和结果之间的关系。
所以,回到时间线,这就是我们想要采取的方法:
- 测量时间 t_0 之前的所有协变量。
- 测量时间 t_0 和时间 t_1 之间的决策变量。
- 测量 t_1 和 t_2 之间的目标变量。
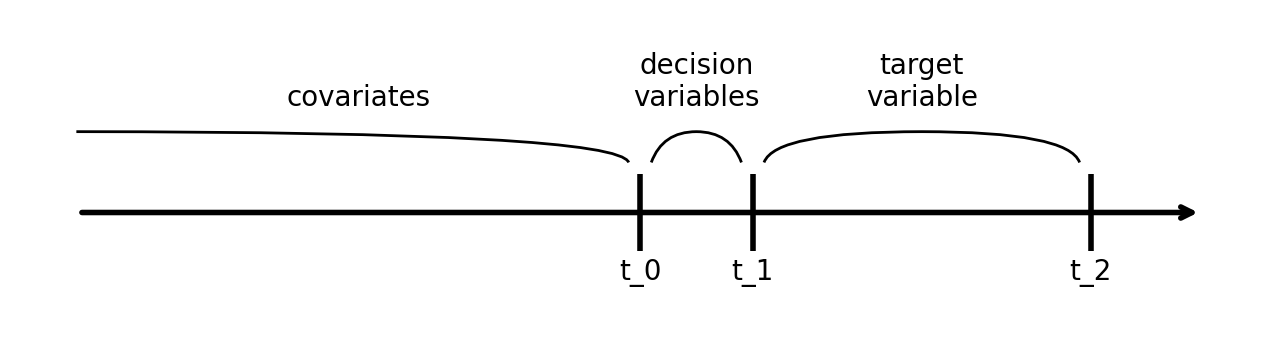
请记住,t₀ 和 t₁ 之间的间隔可能非常短,甚至是立即。例如,向用户发送促销电子邮件或推送通知时通常会出现这种情况。
最仅在应用决策变量后才测量对目标变量的影响。
这是因果图:

请注意,此结构密切反映了我们在真实场景中使用模型的方式。
事实上,在时间 0(我们使用模型预测的时间),我们只知道协变量。 根据我们对协变量的了解,我们可以选择决策变量的值,从而对目标变量产生我们想要的效果。
回到我们的示例,以下是我们可能在模型中作为协变量和决策变量包含的一些可能的变量:
现在的因果图是:
[图片由作者提供]
模型应该帮助我们回答:给定协变量的观察值(关注者数量、语言、类别等),如果我们调整决策变量(帖子数量、平均帖子长度等),对目标变量(新关注者数量)的影响是什么?
在 Python 中,我们可以简单地将所有这些变量作为特征包含在我们的模型中。好消息是,像随机森林这样的高级算法可以自动捕获特征之间的交互,而无需我们手动指定它们:
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor().fit(
X=df[[
"n. of followers",
"language",
...,
"n. of posts",
"avg. post length",
...]],
y=df["n. of new followers"]
)
验证模型后,您可以用它来指导决策。
例如,您可以使用模型根据本周发布的帖子数量来估计下周可能会获得多少新关注者:
例如,在这种情况下,您可能决定发布 5 个帖子,因为在该级别之后,额外的关注者数量不值得付出努力。
这种权衡很常见,因果机器学习帮助我们客观地量化它,以便我们可以做出更明智的决策。
7 参考文献

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)