lpr车牌识别
onnx的输入输出如图: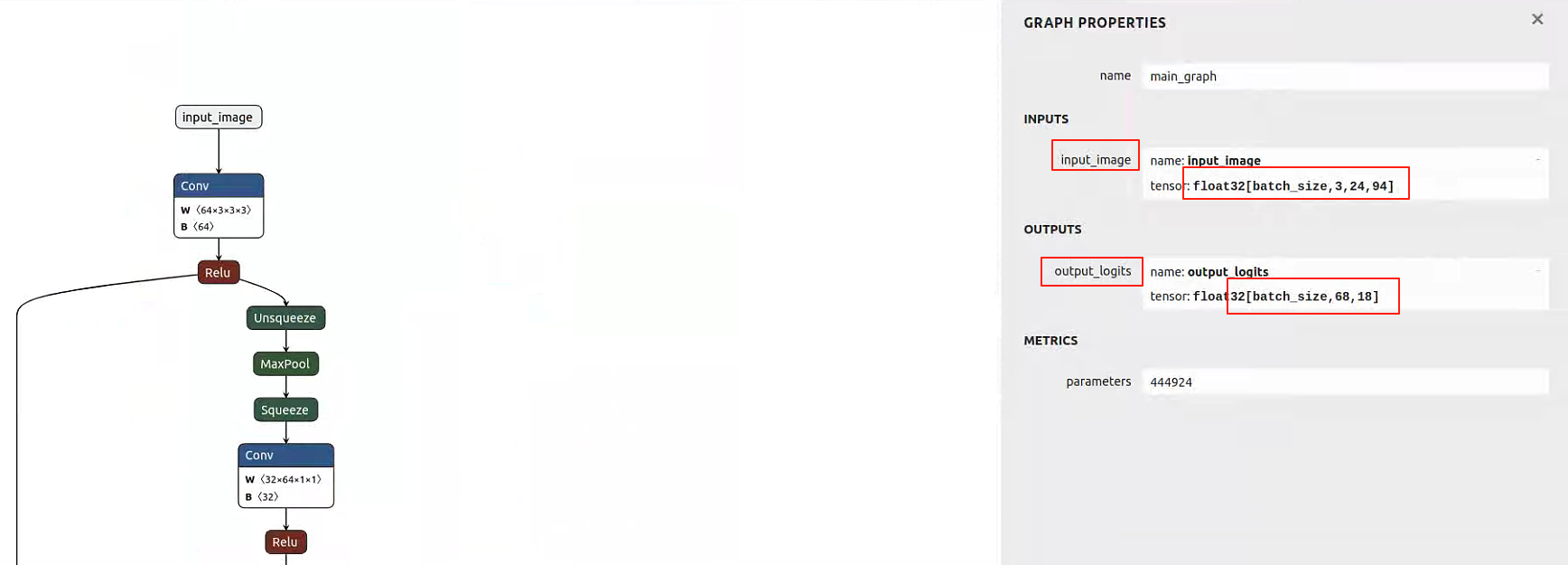
其中车牌识别的字典顺序是:
CHARS = ['京', '沪', '津', '渝', '冀', '晋', '蒙', '辽', '吉', '黑',
'苏', '浙', '皖', '闽', '赣', '鲁', '豫', '鄂', '湘', '粤',
'桂', '琼', '川', '贵', '云', '藏', '陕', '甘', '青', '宁',
'新',
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K',
'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V',
'W', 'X', 'Y', 'Z', 'I', 'O', '-'
]
共68个字符。
🚗 背景:LPRNet 模型结构
- 输入:
[batch, 3, 24, 94]- 一张归一化后的车牌图像(高 24,宽 94)
- 输出:
[batch, 68, 18]68:字符类别数(包括 67 个有效字符 + 1 个 blank 空白符)18:时间步(time steps),即模型对输入图像在水平方向上划分的 18 个“帧”
💡 关键理解:LPRNet 将车牌识别建模为 序列到序列 的任务 ——
输入是一张图,输出是一个长度为 18 的概率序列,每个位置预测一个字符(含 blank)。
🔍 第一步:postprocess() —— 从 logits 到类别索引序列
✅ 目标
将模型输出的 logits(未归一化的分数) 转换为 每个 time step 最可能的字符索引,得到一个长度为 18 的整数序列。
📌 代码解析
// output 布局: [C, T] = [68, 18]
// 内存排布: 先存第0个字符在所有18个time step的值,再存第1个字符...
// 即: [c0_t0, c0_t1, ..., c0_t17, c1_t0, c1_t1, ..., c67_t17]
核心操作:
- 遍历每个 time step
t(共 18 次) - 在该 time step 上,遍历所有 68 个类别
c - 找到概率最大的类别索引
max_class_id - 将
max_class_id加入preds向量
🔑 内存访问关键:
由于 TensorRT 输出是[C, T]布局(channel-first),
所以第c个类别在第t个 time step 的值位于:output[c * NUM_TIME_STEPS + t] // 正确!
🧾 输出示例
假设某次推理得到:
preds = [27, 27, 67, 67, 67, 67, 67, 67, 67, 67, 64, 64, 32, 32, 32, 32, 51, 39]
- 这是一个 原始的、含重复和 blank 的序列
🔠 第二步:ctc_decode() —— CTC 解码:去重 + 去 blank
✅ 目标
将 preds 中的 冗余信息(连续重复、blank 符号)去除,还原出真实的车牌字符串。
📌 CTC 解码规则(Greedy Decoding)
- 折叠连续重复的相同字符(如
A A A→A) - 移除所有 blank 符号(通常设为最后一个类别,即
67)
💡 为什么需要 CTC?
因为 CNN+RNN/Transformer 在对齐时会产生:
- 多个 time step 对应同一个字符(导致重复)
- 不确定区域预测为 blank
📌 代码解析
const int blank_id = NUM_CLASSES - 1; // 67
int prev_class_id = -1;
for (int class_id : preds) {
if (class_id == prev_class_id) {
continue; // 跳过连续重复
}
if (class_id != blank_id) {
plate += charset[class_id]; // 只保留非 blank 字符
}
prev_class_id = class_id;
}
🧾 解码过程演示
| 原始 preds | 处理步骤 | 结果 |
|---|---|---|
27, 27 |
折叠重复 | 27 |
67, 67, ..., 67 |
全是 blank → 移除 | (空) |
64, 64 |
折叠重复 | 64 |
32, 32, 32, 32 |
折叠重复 | 32 |
51, 39 |
无重复、非 blank | 51, 39 |
最终得到有效索引序列:[27, 64, 32, 51, 39]
再通过 charset 映射为字符,例如:
charset = '京', '沪', '津', '渝', '冀', '晋', '蒙', '辽', '吉', '黑',
'苏', '浙', '皖', '闽', '赣', '鲁', '豫', '鄂', '湘', '粤',
'桂', '琼', '川', '贵', '云', '藏', '陕', '甘', '青', '宁',
'新',
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K',
'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V',
'W', 'X', 'Y', 'Z', 'I', 'O', '-'
// 假设:
// 27 → '粤'
// 64 → 'B'
// 32 → '8'
// 51 → '6'
// 39 → '9'
// 最终车牌:"粤B869"
LPRNet 后处理流程详解
LPRNet 是一种端到端的车牌识别模型,其输出是一个形状为 [batch, 68, 18] 的张量,其中:
- 68 表示字符类别数(67 个有效字符 + 1 个 blank 空白符)
- 18 表示时间步(即模型对车牌图像在水平方向上的 18 个采样点)
后处理分为两个关键步骤:
1️⃣ ArgMax 解码:获取最可能的字符索引序列
对每个时间步(共 18 个),在 68 个类别中选取概率最高的类别索引,得到一个长度为 18 的整数序列。
由于 TensorRT 输出采用 [C, T] 内存布局,需按 output[c * 18 + t] 方式正确访问。
2️⃣ CTC Greedy 解码:去除冗余信息
- 折叠连续重复的相同字符(如
A A A→A) - 移除所有 blank 符号(通常为最后一个类别 ID)
最终得到干净的字符索引序列,并通过字符集映射为可读的车牌字符串。
✅ 示例:
原始输出:[27, 27, 67, 67, ..., 64, 64, 32, 32, 51, 39]
CTC 解码后:[27, 64, 32, 51, 39]→"粤B869"
该方法简单高效,适用于大多数固定长度车牌场景。
std::string LPRNet::postprocess(float* output) {
// output 缓冲区是 [C, T] 布局 (trtexec 证实为 1x68x18)
// NUM_CLASSES = 68
// NUM_TIME_STEPS = 18
std::vector<int> preds; // 存储每个 time step 的 argmax 索引
preds.reserve(NUM_TIME_STEPS);
// 迭代 18 个 time steps
for (int t = 0; t < NUM_TIME_STEPS; ++t) { //68行18列,找到每一列最大的索引存到 max_class_id,将这18个值都放到preds中
// --- 查找 ArgMax ---
// 在当前 time step (t),遍历所有 68 个类别 (c),找到概率最高的那个
float max_prob = -1e6; // 初始设为极小值
int max_class_id = -1;
for (int c = 0; c < NUM_CLASSES; ++c) {
// 关键修复: 以 [C, T] 的方式访问内存
// output[c * 18 + t]
float prob = output[c * NUM_TIME_STEPS + t];
if (prob > max_prob) {
max_prob = prob;
max_class_id = c;
}
}
preds.push_back(max_class_id);
}
// CTC 解码 (ctc_decode 函数本身是正确的,无需修改)
return ctc_decode(preds);
}
std::string LPRNet::ctc_decode(const std::vector<int>& preds) {
std::cout<<"====车牌识别结果索引====="<<std::endl;
//27 27 67 67 67 67 67 67 67 67 64 64 32 32 32 32 51 39
for(int i = 0;i<preds.size();i++){
std::cout<<preds[i]<<" ";
}
std::cout<<std::endl;
std::string plate = "";
int prev_class_id = -1;
const int blank_id = NUM_CLASSES - 1; // 68-1 假设 'blank' 是最后一个字符
for (int class_id : preds) {
if (class_id == prev_class_id) {
continue; // 折叠重复项
}
if (class_id != blank_id) { // 忽略 'blank'
plate += charset[class_id];
std::cout<<class_id<<" ";
}
prev_class_id = class_id;
}
//27 64 32 51 39
return plate;
}

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)