掌握Router模式:让程序员轻松驾驭多源知识库,提升大模型应用效果(收藏版)
Router模式是一种高度工程化的多智能体架构范式,通过引入路由决策阶段,对用户输入进行语义分析与任务拆解,并根据问题需求分发到具备不同专业能力的智能体,最后整合结果生成最终回答。在企业级应用中,该模式能有效应对知识垂直化分布问题,通过构建专用智能体和配置独立工具集,实现“分而治之”的架构设计。文章通过企业内部技术支持、合规咨询、研发助手等实际场景,详细阐述了Router模式的实现过程和优势,包括并行执行、智能体专业化、选择性路由等。同时,还介绍了有状态和无状态Router的架构设计,以及何时选择Router模式的相关建议。对于想要学习大模型应用开发的程序员来说,本文提供了一个实用且易于理解的指南。
概述
在大规模语言模型(LLM)驱动的应用系统中,Router Pattern(路由模式) 是一种典型且高度工程化的多 agent(智能体) 架构范式。该模式的核心思想是:
系统并不直接将用户输入交由单一模型或单一 agent 处理,而是首先引入一个显式的路由决策阶段,对输入问题进行语义分析与任务拆解,然后根据问题所涉及的知识域或能力需求,将其分发给具备不同专业能力的 agent,并在最后对多个 agent 的输出结果进行统一整合与生成,形成最终回答。
在企业级应用中,组织内部的知识往往呈现出明显的垂直化分布特征(verticals)。不同类型的信息不仅存储在不同系统中,而且具备完全不同的结构、检索方式与语义侧重点。例如,代码与实现细节通常位于代码仓库中,制度流程与规范文档集中在知识管理系统,而大量隐性经验和决策背景则散落在即时通讯工具的历史讨论中。在这种情况下,试图通过单一 agent、单一工具链或统一 Prompt 来覆盖全部知识来源,往往会导致召回不准确、推理噪声增大以及系统可控性下降。
Router Pattern 正是在这一背景下展现出显著优势。它允许系统针对不同知识垂直领域构建专用 agent,并为每个 agent 配置独立的工具集、检索逻辑与系统提示,从而在整体上实现“分而治之”的架构设计。
实际应用场景示例
在进入具体实现示例之前,可以先考察几个典型的真实业务场景,以理解 Router Pattern 的工程价值:
场景一:企业内部技术支持与运维问答
当工程师询问“某个 API 鉴权失败的原因”时,问题可能同时涉及:
- 代码层面的实现细节(中间件、鉴权逻辑)
- 内部文档中的规范说明(鉴权流程、Token 使用约定)
- 团队在历史讨论中总结的经验或已知问题
Router Pattern 可以将问题分别路由至代码 agent、文档 agent 与讨论 agent,并综合三方信息给出完整答案。
场景二:合规与流程咨询系统
员工询问“某类操作是否符合公司安全规范”时,系统需要同时参考:
- 正式发布的合规文档
- 内部 Wiki 中的流程补充说明
- 安全团队在聊天工具中的解释与答疑记录
通过路由机制,不同 agent 各自检索最权威的信息源,避免单一来源偏差。
场景三:研发效率助手(Developer Copilot)
在研发场景中,开发者提出的问题往往同时指向“代码怎么写”“之前是否有人踩过坑”“有没有官方或内部示例”。Router Pattern 可以并行调度代码检索 agent、Issue/PR agent 与内部沟通记录 agent,从而显著提升回答的实用性与可信度。
示例系统说明
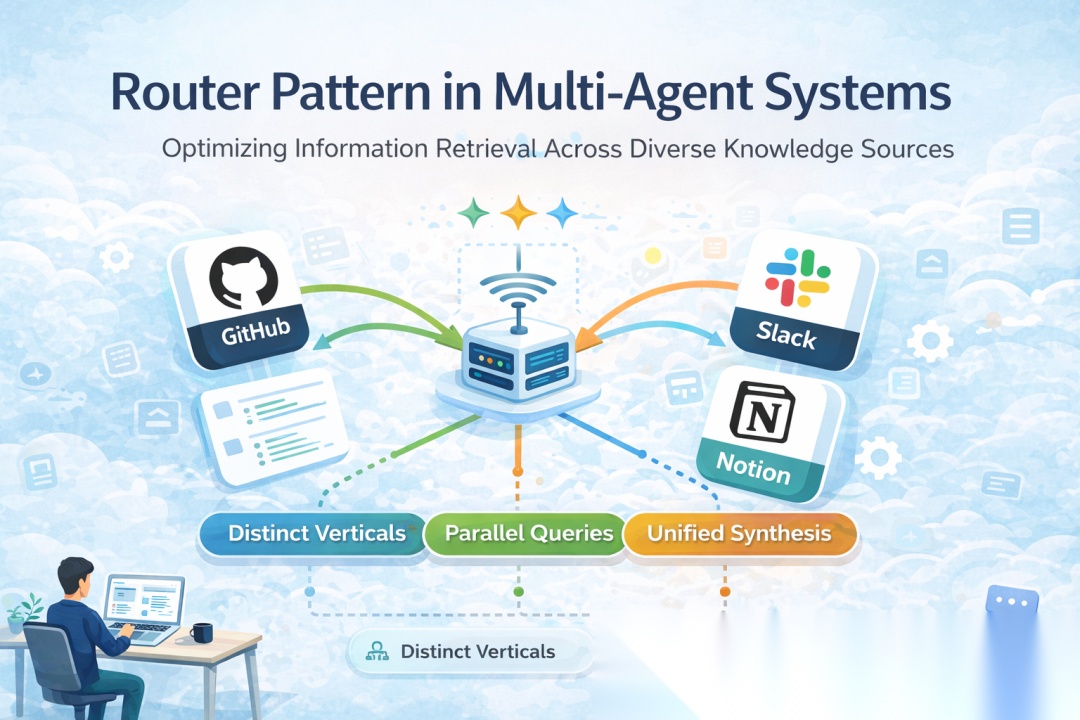
在本示例中,将构建一个多源知识库路由系统,用于模拟真实企业环境中的知识协同与检索流程。系统整体由一个中心 router 与三个专职 agent 组成:
- GitHub agent:负责检索代码仓库中的源码、Issue 以及 Pull Request,用于回答实现细节与技术演进相关问题
- Notion agent:负责查询内部文档、流程说明与知识库内容,用于提供规范性与背景性信息
- Slack agent:负责搜索历史聊天记录与讨论线程,用于补充隐性知识、经验总结与非正式决策信息
当用户提出诸如 “How do I authenticate API requests?” 这类问题时,router 会首先对问题进行分析,将其拆解为多个面向不同知识源的子问题,然后并行分发给相应 agent 执行检索与推理。待所有 agent 返回结果后,系统再对多源输出进行统一综合,生成结构清晰、信息互补的最终答案。
为什么需要 Router?
Router Pattern 在多源知识查询场景中具备以下优势:
并行执行:多个知识源可同时查询,显著降低整体响应延迟
agent 专业化:每个垂直领域 agent 拥有独立工具与 Prompt
选择性路由:并非所有问题都需要访问全部知识源
子问题定向化:为每个 agent 提供领域最优的问题表达
结果统一综合:多源信息在最终阶段进行结构化整合
核心概念
本文将涉及以下关键概念:
- 多 agent 系统(Multi-Agent Systems)
- 基于 StateGraph 的工作流编排
- 使用 Send API 实现并行执行
Router 与 Subagents 的区别
- 当需要显式控制路由逻辑、并行策略或预处理规则时,优先选择 Router Pattern
- 当希望 LLM 动态决定调用哪些 agent 时,可使用 Subagents Pattern
环境准备
安装依赖
本示例依赖 langchain 与 langgraph:
pip install langchain langgraph
LangSmith 配置
LangSmith 用于观测 agent 内部执行过程,需要设置如下环境变量:
export LANGSMITH_TRACING="true"
export LANGSMITH_API_KEY="..."
选择 LLM
系统可接入多种主流 LLM 提供方,包括 OpenAI、Anthropic、Azure、Gemini、AWS Bedrock、HuggingFace 等。
以下所有模型初始化代码仅保留结构位置:
pip install -U "langchain[openai]"
import os
from langchain.chat_models import init_chat_model
os.environ["OPENAI_API_KEY"] = "sk-..."
model = init_chat_model("gpt-5.2")
(其余模型配置同理,代码位置完整保留)
Router 工作流依赖明确的状态定义,共包含三类状态:
AgentInput:子 agent 接收的最小输入
AgentOutput:子 agent 返回的结果
RouterState:主流程状态,包含路由、并行结果与最终答案
# 从 typing 模块中引入 Annotated、Literal、TypedDict,用于类型标注与结构化状态定义
from typing import Annotated, Literal, TypedDict
# 引入 operator 模块,用于定义 reducer(归约函数)
import operator
# 定义 AgentInput 结构,用于描述传递给单个 agent 的最小输入状态
class AgentInput(TypedDict):
# 描述:每个子 agent 的简单输入状态,仅包含查询文本
"""Simple input state for each subagent."""
# query 字段,表示发送给 agent 的自然语言查询
query: str
# 定义 AgentOutput 结构,用于描述单个 agent 的输出结果
class AgentOutput(TypedDict):
# 描述:每个子 agent 的输出结构
"""Output from each subagent."""
# source 字段,表示结果来源的 agent 类型
source: str
# result 字段,表示 agent 返回的文本结果
result: str
# 定义 Classification 结构,用于描述一次路由决策
class Classification(TypedDict):
# 描述:一次路由决策,包含调用哪个 agent 以及对应的子问题
"""A single routing decision: which agent to call with what query."""
# source 字段,限定 agent 来源只能是 github、notion 或 slack
source: Literal["github", "notion", "slack"]
# query 字段,表示为该 agent 定制生成的子查询
query: str
# 定义 RouterState 结构,用于描述整个 router 工作流的全局状态
class RouterState(TypedDict):
# query 字段,表示用户的原始输入问题
query: str
# classifications 字段,保存路由阶段生成的所有 agent 调用决策
classifications: list[Classification]
# results 字段,保存所有 agent 的输出结果列表
results: Annotated[list[AgentOutput], operator.add]
# 注释:通过 operator.add 作为 reducer,将并行 agent 的结果自动合并
# final_answer 字段,表示综合多个 agent 输出后生成的最终答案
final_answer: str
其中 results 字段使用一个reducer(Python中的operator.add,JS中的一个concat函数)来收集并行代理执行产生的输出到一个列表中。
每个垂直领域定义独立工具集合。在真实生产环境中,这些工具通常封装真实 API;此处使用 Mock 实现。
共定义 7 个工具,覆盖 GitHub / Notion / Slack 三类知识源。
# 从 langchain.tools 模块中引入 tool 装饰器,用于将普通函数声明为可被 agent 调用的工具
from langchain.tools import tool
# 使用 @tool 装饰器,将 search_code 函数注册为一个工具
@tool
# 定义 search_code 工具函数,用于在 GitHub 仓库中搜索代码
def search_code(query: str, repo: str = "main") -> str:
# 文档字符串:说明该工具的用途是搜索 GitHub 仓库中的代码
"""Search code in GitHub repositories."""
# 返回模拟的搜索结果字符串,表示在指定仓库中找到了与查询相关的代码
return f"Found code matching '{query}' in {repo}: authentication middleware in src/auth.py"
# 使用 @tool 装饰器,将 search_issues 函数注册为一个工具
@tool
# 定义 search_issues 工具函数,用于搜索 GitHub 中的 Issue 和 Pull Request
def search_issues(query: str) -> str:
# 文档字符串:说明该工具用于搜索 GitHub 的 Issue 与 PR
"""Search GitHub issues and pull requests."""
# 返回模拟的 Issue 搜索结果,包含与查询相关的 Issue 编号与主题
return f"Found 3 issues matching '{query}': #142 (API auth docs), #89 (OAuth flow), #203 (token refresh)"
# 使用 @tool 装饰器,将 search_prs 函数注册为一个工具
@tool
# 定义 search_prs 工具函数,用于搜索 Pull Request 中的实现细节
def search_prs(query: str) -> str:
# 文档字符串:说明该工具用于搜索 Pull Request
"""Search pull requests for implementation details."""
# 返回模拟的 PR 搜索结果,展示与鉴权实现相关的变更记录
return f"PR #156 added JWT authentication, PR #178 updated OAuth scopes"
# 使用 @tool 装饰器,将 search_notion 函数注册为一个工具
@tool
# 定义 search_notion 工具函数,用于在 Notion 工作区中搜索文档
def search_notion(query: str) -> str:
# 文档字符串:说明该工具用于搜索 Notion 中的文档内容
"""Search Notion workspace for documentation."""
# 返回模拟的 Notion 搜索结果,表示找到了与 API 鉴权相关的文档
return f"Found documentation: 'API Authentication Guide' - covers OAuth2 flow, API keys, and JWT tokens"
# 使用 @tool 装饰器,将 get_page 函数注册为一个工具
@tool
# 定义 get_page 工具函数,用于根据页面 ID 获取指定的 Notion 页面内容
def get_page(page_id: str) -> str:
# 文档字符串:说明该工具用于通过 ID 获取 Notion 页面
"""Get a specific Notion page by ID."""
# 返回模拟的页面内容,表示详细的鉴权配置步骤说明
return f"Page content: Step-by-step authentication setup instructions"
# 使用 @tool 装饰器,将 search_slack 函数注册为一个工具
@tool
# 定义 search_slack 工具函数,用于搜索 Slack 中的消息与讨论线程
def search_slack(query: str) -> str:
# 文档字符串:说明该工具用于搜索 Slack 的消息和线程
"""Search Slack messages and threads."""
# 返回模拟的 Slack 搜索结果,表示在工程频道中找到了相关讨论
return f"Found discussion in #engineering: 'Use Bearer tokens for API auth, see docs for refresh flow'"
# 使用 @tool 装饰器,将 get_thread 函数注册为一个工具
@tool
# 定义 get_thread 工具函数,用于获取指定 Slack 线程的详细内容
def get_thread(thread_id: str) -> str:
# 文档字符串:说明该工具用于获取某个具体的 Slack 讨论线程
"""Get a specific Slack thread."""
# 返回模拟的线程内容,表示关于 API Key 轮换的最佳实践讨论
return f"Thread discusses best practices for API key rotation"
为每个垂直领域创建独立 agent。三者遵循统一模式,仅工具集合与 system prompt 不同。
# 从 langchain.agents 模块中引入 create_agent,用于构建具备工具调用能力的 agent
from langchain.agents import create_agent
# 从 langchain.chat_models 模块中引入 init_chat_model,用于初始化底层大语言模型
from langchain.chat_models import init_chat_model
# 初始化一个通用的聊天模型实例,作为所有专职 agent 的基础 LLM
model = init_chat_model("openai:gpt-4o")
# 创建 GitHub agent,用于处理与代码、Issue、Pull Request 相关的问题
github_agent = create_agent(
# 指定该 agent 使用的底层语言模型
model,
# 为 GitHub agent 配置专属工具集合,用于代码与仓库相关检索
tools=[search_code, search_issues, search_prs],
# system_prompt 用于限定 agent 的角色定位与回答范围
system_prompt=(
# 明确该 agent 是 GitHub 领域专家
"You are a GitHub expert. Answer questions about code, "
# 指定其关注 API 引用与实现细节
"API references, and implementation details by searching "
# 约束其信息来源为仓库、Issue 与 Pull Request
"repositories, issues, and pull requests."
),
)
# 创建 Notion agent,用于处理内部文档、流程与规范相关的问题
notion_agent = create_agent(
# 指定该 agent 使用同一个底层语言模型实例
model,
# 为 Notion agent 配置专属工具集合,用于文档与页面检索
tools=[search_notion, get_page],
# system_prompt 用于定义该 agent 的知识边界与职责
system_prompt=(
# 明确该 agent 是 Notion 领域专家
"You are a Notion expert. Answer questions about internal "
# 指定其关注组织内部流程、政策与文档
"processes, policies, and team documentation by searching "
# 约束其信息来源为组织的 Notion 工作区
"the organization's Notion workspace."
),
)
# 创建 Slack agent,用于处理团队讨论、隐性知识与经验共享相关的问题
slack_agent = create_agent(
# 指定该 agent 使用同一个底层语言模型实例
model,
# 为 Slack agent 配置专属工具集合,用于消息与线程检索
tools=[search_slack, get_thread],
# system_prompt 用于限定该 agent 的行为模式与回答风格
system_prompt=(
# 明确该 agent 是 Slack 领域专家
"You are a Slack expert. Answer questions by searching "
# 指定其关注与问题相关的讨论线程
"relevant threads and discussions where team members have "
# 强调其信息来源是团队成员共享的知识与解决方案
"shared knowledge and solutions."
),
)
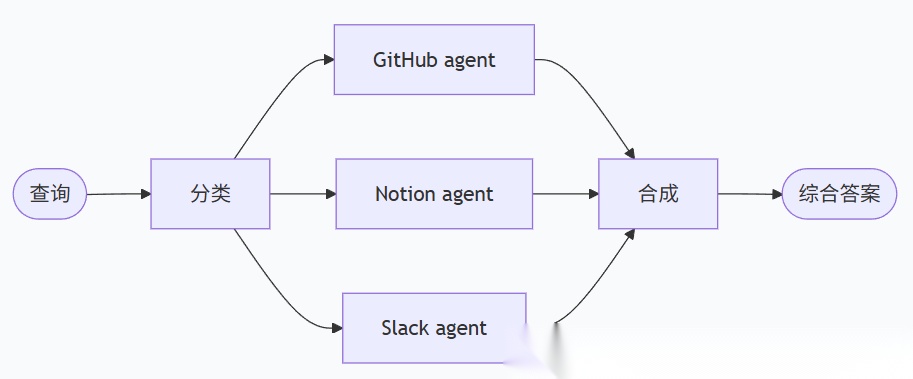
Router 工作流由 StateGraph 编排,包含四个核心阶段:
Classification(分类):判断需要调用哪些 agent
Routing(路由):并行分发请求
Query(执行):agent 执行子查询
Synthesis(综合):生成最终答案
# 从 pydantic 模块中引入 BaseModel 与 Field,用于定义结构化输出的数据模型
from pydantic import BaseModel, Field
# 从 langgraph.graph 中引入 StateGraph、START、END,用于构建有向状态工作流
from langgraph.graph import StateGraph, START, END
# 从 langgraph.types 中引入 Send,用于在路由阶段并行分发任务
from langgraph.types import Send
# 初始化一个轻量级语言模型实例,专用于路由与综合阶段
router_llm = init_chat_model("openai:gpt-4o-mini")
# 定义分类器的结构化输出 schema
class ClassificationResult(BaseModel):
"""用于表示用户问题被拆解后生成的 agent 调用决策结果"""
# classifications 字段,表示需要调用的 agent 列表及其对应的子问题
classifications: list[Classification] = Field(
description="List of agents to invoke with their targeted sub-questions"
)
# 定义 classify_query 函数,用于对用户问题进行路由分类
def classify_query(state: RouterState) -> dict:
"""对用户查询进行分析,确定需要调用哪些 agent"""
# 基于 router_llm 构建带结构化输出能力的 LLM
structured_llm = router_llm.with_structured_output(ClassificationResult)
# 调用模型,对输入问题进行分类与子问题生成
result = structured_llm.invoke([
{
# system 角色消息,用于定义分类任务与约束条件
"role": "system",
# 系统提示词,详细说明分类逻辑、可用知识源及返回格式要求
"content": """Analyze this query and determine which knowledge bases to consult.
For each relevant source, generate a targeted sub-question optimized for that source.
Available sources:
- github: Code, API references, implementation details, issues, pull requests
- notion: Internal documentation, processes, policies, team wikis
- slack: Team discussions, informal knowledge sharing, recent conversations
Return ONLY the sources that are relevant to the query. Each source should have
a targeted sub-question optimized for that specific knowledge domain.
Example for "How do I authenticate API requests?":
- github: "What authentication code exists? Search for auth middleware, JWT handling"
- notion: "What authentication documentation exists? Look for API auth guides"
(slack omitted because it's not relevant for this technical question)"""
},
{
# user 角色消息,传入原始用户查询
"role": "user",
"content": state["query"]
}
])
# 返回包含分类结果的字典,供后续路由节点使用
return {"classifications": result.classifications}
# 定义 route_to_agents 函数,用于根据分类结果并行分发任务
def route_to_agents(state: RouterState) -> list[Send]:
"""根据 classifications 生成 Send 对象,实现并行 agent 调用"""
# 遍历所有分类结果,为每个 agent 构造一个 Send 实例
return [
# Send 的第一个参数是目标节点名称,第二个参数是传递给 agent 的输入状态
Send(c["source"], {"query": c["query"]})
# 对每一条分类记录执行一次 Send 构造
for c in state["classifications"]
]
# 定义 query_github 函数,用于调用 GitHub agent
def query_github(state: AgentInput) -> dict:
"""将子问题发送给 GitHub agent 并获取结果"""
# 调用 GitHub agent,将 query 包装为对话消息格式
result = github_agent.invoke({
# messages 字段表示一次对话输入
"messages": [{"role": "user", "content": state["query"]}]
})
# 将 agent 返回的最后一条消息内容封装为标准化结果结构
return {"results": [{"source": "github", "result": result["messages"][-1].content}]}
# 定义 query_notion 函数,用于调用 Notion agent
def query_notion(state: AgentInput) -> dict:
"""将子问题发送给 Notion agent 并获取结果"""
# 调用 Notion agent,传入用户子查询
result = notion_agent.invoke({
# messages 字段包含用户输入的查询文本
"messages": [{"role": "user", "content": state["query"]}]
})
# 返回标准化的 agent 输出结果
return {"results": [{"source": "notion", "result": result["messages"][-1].content}]}
# 定义 query_slack 函数,用于调用 Slack agent
def query_slack(state: AgentInput) -> dict:
"""将子问题发送给 Slack agent 并获取结果"""
# 调用 Slack agent,执行基于讨论记录的检索与回答
result = slack_agent.invoke({
# messages 字段传递用户查询内容
"messages": [{"role": "user", "content": state["query"]}]
})
# 返回包含 Slack 来源标识的结果结构
return {"results": [{"source": "slack", "result": result["messages"][-1].content}]}
# 定义 synthesize_results 函数,用于综合多个 agent 的输出
def synthesize_results(state: RouterState) -> dict:
"""将所有 agent 的结果整合为最终回答"""
# 如果没有任何 agent 返回结果,则直接返回兜底答案
if not state["results"]:
return {"final_answer": "No results found from any knowledge source."}
# 将每个 agent 的结果格式化为带来源标识的文本块
formatted = [
# 使用来源名称作为标题,并拼接对应的结果内容
f"**From {r['source'].title()}:**\n{r['result']}"
# 遍历所有 agent 输出结果
for r in state["results"]
]
# 调用 router_llm,对多源结果进行综合生成
synthesis_response = router_llm.invoke([
{
# system 角色消息,用于定义综合生成的约束与目标
"role": "system",
# 系统提示词,说明如何整合多源信息并回答原始问题
"content": f"""Synthesize these search results to answer the original question: "{state['query']}"
- Combine information from multiple sources without redundancy
- Highlight the most relevant and actionable information
- Note any discrepancies between sources
- Keep the response concise and well-organized """
},
{
# user 角色消息,将格式化后的多源结果作为输入
"role": "user",
"content": "\n\n".join(formatted)
}
])
# 返回最终综合生成的答案文本
return {"final_answer": synthesis_response.content}
通过 add_conditional_edges 实现动态并行分支。
workflow = (
StateGraph(RouterState)
.add_node("classify", classify_query)
.add_node("github", query_github)
.add_node("notion", query_notion)
.add_node("slack", query_slack)
.add_node("synthesize", synthesize_results)
.add_edge(START, "classify")
.add_conditional_edges("classify", route_to_agents, ["github", "notion", "slack"])
.add_edge("github", "synthesize")
.add_edge("notion", "synthesize")
.add_edge("slack", "synthesize")
.add_edge("synthesize", END)
.compile()
)
add_conditional_edges调用通过route_to_agents函数将classify节点连接到agent节点。当route_to_agents返回多个Send对象时,这些节点并行执行。
示例查询:
result = workflow.invoke({
"query": "How do I authenticate API requests?"
})
print("Original query:", result["query"])
print("\nClassifications:")
for c in result["classifications"]:
print(f" {c['source']}: {c['query']}")
print("\n" + "=" * 60 + "\n")
print("Final Answer:")
print(result["final_answer"])
输出:
Original query: How do I authenticate API requests?
Classifications:
github: Where is API authentication implemented in the codebase? Look for JWT, OAuth handlers, or middleware
slack: What guidance or best practices have been discussed internally about API authentication?
============================================================
Final Answer:
API request authentication in the current system is handled through a combination of standardized mechanisms and internal best practices:
JWT-based Authentication
The primary authentication mechanism is JWT. Core logic is implemented in the authentication middleware located in
src/auth.py, introduced in PR #156. This middleware validates Bearer tokens on incoming requests and enforces scope-based access control.
OAuth Integration for External Clients
OAuth is supported for integrations with third-party services. While the full flow is partially documented in code comments, internal discussions highlight that OAuth should be used when delegated authorization or user consent is required.
Operational Best Practices
Internal Slack discussions emphasize consistent use of the
Authorization: Bearer <token> header and recommend regular token rotation. API key–based access is discouraged for user-facing integrations but may still be acceptable for limited server-to-server scenarios.
Token Lifecycle Considerations
Token refresh and expiration handling have been discussed in both implementation updates and internal threads. Engineers should review recent changes related to token refresh behavior to ensure clients handle expiration correctly.
Overall, JWT authentication via middleware is the default and recommended approach, with OAuth reserved for external or delegated access scenarios.
分类判定阶段(Classification Stage)
在流程的初始阶段,系统通过 classify_query 函数对用户输入进行解析与判定,以明确后续需要调度哪些 agent。路由层的核心智能正是在这一阶段体现,其主要特征包括:
- 采用结构化输出机制,对模型生成结果施加明确约束,避免非预期格式
- 借助 Pydantic(Python)或 Zod(JavaScript)等数据模型,对输出结构进行校验,确保结果合法且可消费
- 生成一组
Classification记录,每条记录明确指向一个具体来源(source)以及与该来源高度匹配的定向子问题(query) - 仅保留与当前问题高度相关的知识源,不相关的 agent 会被直接排除在路由结果之外
相较于基于自由格式 JSON 的解析方式,这种结构化分类策略在稳定性与可解释性方面更具优势,同时也使路由决策逻辑更加清晰、可控。
并行执行(Send)
# Classifications: [{"source": "github", "query": "..."}, {"source": "notion", "query": "..."}]
# Becomes:
[Send("github", {"query": "..."}), Send("notion", {"query": "..."})]
# Both agents execute simultaneously, each receiving only the query it needs
每个 agent 仅接收必要输入,避免状态污染。
结果聚合(Reducer)
{"results": [{"source": "github", "result": "..."}]}
归约器(Python 中的 operator.add)负责连接这些列表,将并行的执行结果汇总到 state[“results”] 字段。
结果整合阶段(Synthesis Stage)
在各个 agent 完成并行执行之后,系统进入结果整合阶段。此阶段由 synthesize_results 负责,对前序阶段产出的多源信息进行统一归并与生成,其主要职责包括:
- 在进入整合逻辑之前,确保所有并发执行的分支均已结束,该过程由工作流引擎自动协调完成
- 以最初的用户输入为对照基准,校验生成内容是否真正回应了问题本身,而非偏离查询目标
- 对来自不同知识域的结果进行去重、筛选与重组,输出结构清晰且语义一致的最终结论
关于不完整结果的处理策略
当前示例采用的是“全量完成后再整合”的策略,即只有所有已选定的 agent 返回结果后,系统才会继续执行综合生成。对于需要提前消费部分结果或对超时分支进行特殊处理的复杂工作流,可采用基于 map-reduce 思路的变体架构。
此处粘贴代码
"""
Multi-Source Knowledge Router Example
This example demonstrates the router pattern for multi-agent systems.
A router classifies queries, routes them to specialized agents in parallel,
and synthesizes results into a combined response.
"""
import operator
from typing import Annotated, Literal, TypedDict
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
from langchain.tools import tool
from langgraph.graph import StateGraph, START, END
from langgraph.types import Send
from pydantic import BaseModel, Field
# State definitions
class AgentInput(TypedDict):
"""Simple input state for each subagent."""
query: str
class AgentOutput(TypedDict):
"""Output from each subagent."""
source: str
result: str
class Classification(TypedDict):
"""A single routing decision: which agent to call with what query."""
source: Literal["github", "notion", "slack"]
query: str
class RouterState(TypedDict):
query: str
classifications: list[Classification]
results: Annotated[list[AgentOutput], operator.add]
final_answer: str
# Structured output schema for classifier
class ClassificationResult(BaseModel):
"""Result of classifying a user query into agent-specific sub-questions."""
classifications: list[Classification] = Field(
description="List of agents to invoke with their targeted sub-questions"
)
# Tools
@tool
def search_code(query: str, repo: str = "main") -> str:
"""Search code in GitHub repositories."""
return f"Found code matching '{query}' in {repo}: authentication middleware in src/auth.py"
@tool
def search_issues(query: str) -> str:
"""Search GitHub issues and pull requests."""
return f"Found 3 issues matching '{query}': #142 (API auth docs), #89 (OAuth flow), #203 (token refresh)"
@tool
def search_prs(query: str) -> str:
"""Search pull requests for implementation details."""
return f"PR #156 added JWT authentication, PR #178 updated OAuth scopes"
@tool
def search_notion(query: str) -> str:
"""Search Notion workspace for documentation."""
return f"Found documentation: 'API Authentication Guide' - covers OAuth2 flow, API keys, and JWT tokens"
@tool
def get_page(page_id: str) -> str:
"""Get a specific Notion page by ID."""
return f"Page content: Step-by-step authentication setup instructions"
@tool
def search_slack(query: str) -> str:
"""Search Slack messages and threads."""
return f"Found discussion in #engineering: 'Use Bearer tokens for API auth, see docs for refresh flow'"
@tool
def get_thread(thread_id: str) -> str:
"""Get a specific Slack thread."""
return f"Thread discusses best practices for API key rotation"
# Models and agents
model = init_chat_model("openai:gpt-4o")
router_llm = init_chat_model("openai:gpt-4o-mini")
github_agent = create_agent(
model,
tools=[search_code, search_issues, search_prs],
system_prompt=(
"You are a GitHub expert. Answer questions about code, "
"API references, and implementation details by searching "
"repositories, issues, and pull requests."
),
)
notion_agent = create_agent(
model,
tools=[search_notion, get_page],
system_prompt=(
"You are a Notion expert. Answer questions about internal "
"processes, policies, and team documentation by searching "
"the organization's Notion workspace."
),
)
slack_agent = create_agent(
model,
tools=[search_slack, get_thread],
system_prompt=(
"You are a Slack expert. Answer questions by searching "
"relevant threads and discussions where team members have "
"shared knowledge and solutions."
),
)
# Workflow nodes
def classify_query(state: RouterState) -> dict:
"""Classify query and determine which agents to invoke."""
structured_llm = router_llm.with_structured_output(ClassificationResult)
result = structured_llm.invoke([
{
"role": "system",
"content": """Analyze this query and determine which knowledge bases to consult.
For each relevant source, generate a targeted sub-question optimized for that source.
Available sources:
- github: Code, API references, implementation details, issues, pull requests
- notion: Internal documentation, processes, policies, team wikis
- slack: Team discussions, informal knowledge sharing, recent conversations
Return ONLY the sources that are relevant to the query."""
},
{"role": "user", "content": state["query"]}
])
return {"classifications": result.classifications}
def route_to_agents(state: RouterState) -> list[Send]:
"""Fan out to agents based on classifications."""
return [
Send(c["source"], {"query": c["query"]})
for c in state["classifications"]
]
def query_github(state: AgentInput) -> dict:
"""Query the GitHub agent."""
result = github_agent.invoke({
"messages": [{"role": "user", "content": state["query"]}]
})
return {"results": [{"source": "github", "result": result["messages"][-1].content}]}
def query_notion(state: AgentInput) -> dict:
"""Query the Notion agent."""
result = notion_agent.invoke({
"messages": [{"role": "user", "content": state["query"]}]
})
return {"results": [{"source": "notion", "result": result["messages"][-1].content}]}
def query_slack(state: AgentInput) -> dict:
"""Query the Slack agent."""
result = slack_agent.invoke({
"messages": [{"role": "user", "content": state["query"]}]
})
return {"results": [{"source": "slack", "result": result["messages"][-1].content}]}
def synthesize_results(state: RouterState) -> dict:
"""Combine results from all agents into a coherent answer."""
if not state["results"]:
return {"final_answer": "No results found from any knowledge source."}
formatted = [
f"**From {r['source'].title()}:**\n{r['result']}"
for r in state["results"]
]
synthesis_response = router_llm.invoke([
{
"role": "system",
"content": f"""Synthesize these search results to answer the original question: "{state['query']}"
- Combine information from multiple sources without redundancy
- Highlight the most relevant and actionable information
- Note any discrepancies between sources
- Keep the response concise and well-organized"""
},
{"role": "user", "content": "\n\n".join(formatted)}
])
return {"final_answer": synthesis_response.content}
# Build workflow
workflow = (
StateGraph(RouterState)
.add_node("classify", classify_query)
.add_node("github", query_github)
.add_node("notion", query_notion)
.add_node("slack", query_slack)
.add_node("synthesize", synthesize_results)
.add_edge(START, "classify")
.add_conditional_edges("classify", route_to_agents, ["github", "notion", "slack"])
.add_edge("github", "synthesize")
.add_edge("notion", "synthesize")
.add_edge("slack", "synthesize")
.add_edge("synthesize", END)
.compile()
)
if __name__ == "__main__":
result = workflow.invoke({
"query": "How do I authenticate API requests?"
})
print("Original query:", result["query"])
print("\nClassifications:")
for c in result["classifications"]:
print(f" {c['source']}: {c['query']}")
print("\n" + "=" * 60 + "\n")
print("Final Answer:")
print(result["final_answer"])
当前 Router 为无状态。多轮对话场景需引入状态管理。
工具封装方案(推荐)
将 Router 作为 Tool,由上层对话 agent 负责记忆。
from langgraph.checkpoint.memory import InMemorySaver
@tool
def search_knowledge_base(query: str) -> str:
"""Search across multiple knowledge sources (GitHub, Notion, Slack).
Use this to find information about code, documentation, or team discussions.
"""
result = workflow.invoke({"query": query})
return result["final_answer"]
conversational_agent = create_agent(
model,
tools=[search_knowledge_base],
system_prompt=(
"You are a helpful assistant that answers questions about our organization. "
"Use the search_knowledge_base tool to find information across our code, "
"documentation, and team discussions."
),
checkpointer=InMemorySaver(),
)
这种设计方式将 router 明确限定为无状态组件,而将对话历史与上下文管理的职责交由上层的对话 agent 承担。在该架构下,router 仅负责按需执行多源检索与结果综合,不保存任何跨轮次信息。
由此,系统可以支持连续多轮交互:对话 agent 根据当前上下文判断是否需要调用 router 工具,并在合适的时机触发查询。这样既保证了路由逻辑的简洁与可复用性,又使上下文管理保持集中,整体架构边界清晰、职责分离明确。
config = {"configurable": {"thread_id": "user-123"}}
result = conversational_agent.invoke(
{"messages": [{"role": "user", "content": "How do I authenticate API requests?"}]},
config
)
print(result["messages"][-1].content)
result = conversational_agent.invoke(
{"messages": [{"role": "user", "content": "What about rate limiting for those endpoints?"}]},
config
)
print(result["messages"][-1].content)
全量持久化方案(Full Persistence Approach)
在某些高级场景中,可能需要 router 自身具备状态感知能力,例如在后续路由决策中显式利用之前的检索结果或历史上下文信息。此时,可以在 router 层引入持久化机制(persistence),将消息历史或中间结果存储在路由工作流内部,而非仅存在于上层对话 agent 中。
⚠️ 关于复杂性的提示
为 router 增加状态会显著提升系统复杂度。当跨多轮对话不断路由至不同 agent 时,如果各 agent 的 Prompt、语气或回答风格存在差异,整体对话体验可能出现不连贯或语义割裂的问题。在这类多轮交互场景中,更推荐采用 handoffs 模式 或 subagents 模式,它们在多 agent 轮次协作下提供了更清晰、一致的语义边界与行为预期。
当系统同时面临多个异构知识源,并且需要对信息进行高效整合时,Router Pattern 往往能够发挥出最显著的价值,典型适用条件包括:
- 知识域高度区分:不同信息分布在相互独立的领域中,每个领域都需要定制化的工具能力与 Prompt 设计
- 并发检索诉求明显:问题本身适合同时访问多个数据源,通过并行执行来降低整体响应时间
- 结果需要统一表达:来自不同来源的输出必须经过整理、去重与重组,最终形成一致且可读的结论
从流程视角来看,Router Pattern 可以抽象为三个连续阶段:
拆解(decompose),对用户问题进行分析并生成面向不同知识域的子问题;
路由(route),将这些子问题并行分发至对应 agent 执行;
综合(synthesize),对多路返回结果进行整合并生成最终输出。
何时选择 Router Pattern
当系统具备多个相互独立的知识来源、对响应时延较为敏感,并且需要对路由决策过程保持显式可控时,Router Pattern 是一种优先考虑的架构选择。
如果场景相对简单,主要需求是让模型动态决定调用哪些工具,可以考虑 subagents 模式。而在需要 agent 与用户进行多轮、顺序式交互的工作流中,handoffs 模式通常能够提供更清晰的交互语义与控制边界。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


为什么要学习大模型?
我国在A大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着AI技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国AI产业的创新步伐。加强人才培养,优化教育体系,国际合作并进是破解困局、推动AI发展的关键。


大模型入门到实战全套学习大礼包
1、大模型系统化学习路线
作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。这里我给大家准备了一份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!

2、大模型学习书籍&文档
学习AI大模型离不开书籍文档,我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。

3、AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

4、大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。

5、大模型大厂面试真题
面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

适用人群

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献112条内容
已为社区贡献112条内容

所有评论(0)