动态规划——树形dp入门
动态规划——树形dp入门
树形dp简介
这个专题相当有难度,拿到题却无从下手、分析思路错误都是常态。
树形动态规划简称树形 dp,即在树型数据结构上进行的动态规划,通过有限次地遍历树,记录相关信息,以求解问题。由于树是通过递归定义的数据结构,因此树形 dp 一般都是在递归中进行。
树型数据结构可分为无根树和有根树,无根树即任意一个结点都可以作为树型数据结构的根结点,特点是结点之间的边是双向的;而有根树有明确根结点,结点之间的方向固定。
动态规划都是线性的或者是建立在图上的,线性动态规划的顺序有两种方向即前向和后向,相应的状态转移方程有两种,即顺推与逆推,而树形动态规划是建立在树上的,树中的父子关系天然就是个递归(子问题)结构,所以也相应的有两个方向:
- 叶 → \rightarrow → 根,即根的子树传递有用的信息给根,之后由根得出最优解的过程。这种方式的 dp 若是在有根树上进行,则有根树可看成有向无环图,通过拓扑排序进行递推。
- 根 → \rightarrow → 叶,即需要取所有结点作为一次根结点,再进行填表,此时父结点得到了整棵树的信息,只需要再去除子结点的潜在的影响,然后再转移给这个儿子,这样就能达到根 → \rightarrow → 叶的顺序。这种模式的树形 dp 为换根 dp,在后续会详细介绍。
对于某个问题,若用树形 dp 解决,一般按照后序遍历的顺序,即处理完儿子再处理当前结点。所以在用递归遍历这棵树时:
- 一般情况通过记忆化搜索实现。
- 从某个结点向上回溯时,当前子树已全部遍历完毕,因此就可以给根节点返回信息;
- 遍历完毕所有子树遍历完毕之后,根节点整合所有信息,然后向上返回。
一句话总结:树形 dp 就是在递归的过程中,根节点拿到所有孩子提供的信息,整合之后向上返回。
在实现树形 dp 的时候,一般不把信息当成递归的返回值,而是创建一个数组存储要返回的信息。因为较为复杂的树形 dp 是要整合很多信息的。
时间复杂度:树形动态规划的时间复杂度基本上是 O ( n ) \text{O}(n) O(n);若有附加维 m m m,则是 O ( m n ) \text{O}(mn) O(mn)。这些在后续列举的 OJ 有体现。
树形 dp 分析思路
在用树形 dp 解决问题时,一般思考 2 个问题,在递归到某一个子树的时候:
- 根结点需要子结点提供哪些信息。
- 根结点如何整理子结点提供的信息,并向上返回。
树形 dp 按照动态规划的思路分析:
- 根结点向上返回的信息以及子结点提供的信息是同一种信息,就是状态表示;
- 根节点整理信息的方式就是状态转移方程;
- 递归进入该结点的时候可以初始化;
- dfs 即深度优先搜索的过程就是填表顺序。若为有根树还可以使用拓扑排序。
- 根节点存储的信息,一般就是最终结果。但也有例外。
任何动态规划包括树形 dp ,往往同一个分析思路,放在不同的问题,实现的代码并不完全相同,所以这里能总结的只有分析思路,具体应用需要结合问题进行现场分析,且分析很久但代码却很简短都是常有的事。
此外,树形 dp 若细分的话能解决的问题相当丰富,还可与其他的 dp 模型(例如状态压缩 dp )、数据结构(例如线段树)和算法(例如二分、贪心)进行结合。这里只列举树形 dp 的部分应用,适合入门,若严格列举的话,几篇笔记都列举不完。
树形dp的应用列举
这里大致总结一些树形 dp 的经典问题,分类上不一定专业,请谨慎甄别。
最大权连通子图
最大权连通子图即在树中找一个连通块,使节点权值和最大。
P1122 最大子树和 - 洛谷
题目描述的树是一个无根树,任何结点都可以当成根结点,在存图的时候需要存储无向边。
题目要求的是剪去任意子树(可以不剪枝)之后,剩下的子树的所有的结点的最大权值和。所以使用树形dp:
-
状态定义
设 d p [ i ] dp[i] dp[i] 表示包括 i i i 结点在内,它的最大子树和和它的权值 a [ i ] a[i] a[i] ,加起来的最大值。则答案是 max i = 1 n ( d p [ i ] ) \max\limits_{i=1}^{n}(dp[i]) i=1maxn(dp[i]) 。
若不包括 i i i 也就是它本身在内,即 d p [ i ] dp[i] dp[i] 只表示以 i i i 为根结点的所有子树的子树和中的最大值,则当某个子树实际产生贡献的也只是这个子树的某一部分子树,则这个子树的子树和子树的根结点没有关系,若强行进行状态转移时就会出错。
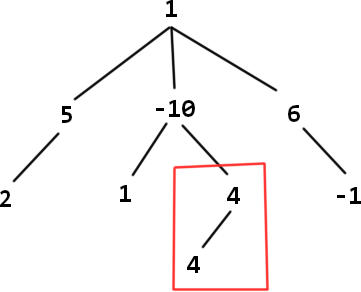
例如这个树,第 2 个子树的最大子树和是 8,但因为可以不包括根结点 − 10 -10 −10,所以就得出最大子树和为 24 的错误答案,即只减去 − 10 -10 −10 这个结点,但这不符合题意,因为标红框的这部分子树和根结点 1 没有联系。而正确答案是将 − 10 -10 −10 为根结点的整个子树和 − 1 -1 −1 这个叶结点剪去,则最大子树和为 14 。
所以根结点必选,最大子树和必须要包括这个子树的根结点在内。
-
转移方程
易得 d p [ i ] = a [ i ] + ∑ d p [ 所有子树 ] dp[i]=a[i]+\sum dp[所有子树] dp[i]=a[i]+∑dp[所有子树] 。当某个子树的 dp 值小于 0 时直接剪去。
-
初始化 & 填表
开始时 d p [ i ] = a [ i ] dp[i]=a[i] dp[i]=a[i] ,可在填表时再初始化。
填表方式为 dfs 。但 dfs 的每层递归表示一个结点,则不可出现子结点创建父结点的递归函数的情况,否则会栈溢出和死循环。
P1122 最大子树和 - 洛谷 参考程序(邻接表建树):
#include <bits/stdc++.h>
using namespace std;
using LL = long long;
const LL MOD = 0x7fffffff;
vector<vector<LL>> edge;
vector<LL> a, dp;
void dfs(int start, int fa) {
dp[start] = a[start]; // 初始化
for (auto &x : edge[start]) {
if (x == fa) // 防止子结点遍历父结点
continue;
dfs(x, start); // 遍历子结点,相信递归函数一定能带回想要的信息
if (dp[x] < 0) // 当前子树包括它本身的权值小于0则剪枝
continue;
dp[start] = (dp[start] + dp[x]) % MOD;
}
}
void init(LL n) {
a.resize(n + 1, 0);
dp = a;
edge.resize(n + 1, vector<LL>());
}
int main() {
// freopen("in.in", "r", stdin);
LL n, ans = -1e18;
cin >> n;
init(n);
for (int i = 1; i <= n; i++) // 可直接输入dp[i],这里取一个象征意义
cin >> a[i];
for (int i = 1; i < n; i++) { // 无根树
LL s, e;
cin >> s >> e;
edge[s].push_back(e);
edge[e].push_back(s);
}
dfs(1, 0); // 任意结点当成根结点,最终答案不会变
for (int i = 1; i <= n; i++)
ans = max(ans, dp[i]);
cout << ans;
return 0;
}
树的最大独立集
独立集是指图中任意两个顶点都不相邻的顶点集合。最大独立集即包含顶点数最多的独立集。
P1352 没有上司的舞会 - 洛谷
和 P1122 最大子树和 - 洛谷 不同,这题构建的树就是有根树,因此需要根据入度是否为 0 判断根结点的位置。
结点表示一个职员,则题目描述的是当前结点参加舞会,则他的直接下属将不参加舞会。因此对每个结点,他所在的子树的最大快乐指数和分 2 种情况:他本人参与和他本人不参与。
因此使用树形dp分析:
-
状态定义
设 d p [ i ] [ 0 ] dp[i][0] dp[i][0] 表示他本人不参与时,他所在的子树的最大快乐指数和,而 d p [ i ] [ 1 ] dp[i][1] dp[i][1] 表示他本人参与时,他所在的子树的最大快乐指数和。
答案就是根结点的 2 个状态 max ( d p [ i ] [ 0 ] , d p [ i ] [ 1 ] ) \max(dp[i][0],dp[i][1]) max(dp[i][0],dp[i][1]) 。
-
转移方程
任何子树的根结点,他的直接下属不会参与,但他的直接下属的直接下属可参与,也可不参与,此时需要在 2 种情况中取最值并进行叠加。
即转移方程(组): { d p [ i ] [ 0 ] = ∑ x max ( d p [ x ] [ 0 ] + d p [ x ] [ 1 ] ) d p [ i ] [ 1 ] = a [ i ] + ∑ x ( d p [ x ] [ 0 ] ) \begin{cases}dp[i][0]=\sum\limits_x\max(dp[x][0]+dp[x][1])\\dp[i][1]=a[i]+\sum\limits_x(dp[x][0])\end{cases} ⎩ ⎨ ⎧dp[i][0]=x∑max(dp[x][0]+dp[x][1])dp[i][1]=a[i]+x∑(dp[x][0])
a [ i ] a[i] a[i] 表示他本人参与时贡献的快乐指数。
-
初始化
开始时 d p [ i ] [ 1 ] = a [ i ] dp[i][1]=a[i] dp[i][1]=a[i] , d p [ i ] [ 0 ] = 0 dp[i][0]=0 dp[i][0]=0 ,表示 i i i 参与和不参与时的情况。
dfs 遍历填表
填表方式为通过 dfs 遍历所有子结点,每层递归表示一个子树,每个子树统计他的所有子树的信息,相信递归函数一定能带回所有的信息。
P1352 没有上司的舞会 - 洛谷 参考程序(邻接表建树):
#include <bits/stdc++.h>
using namespace std;
const int N = 6e3 + 10;
using vi = vector<int>;
int dp[N][2], a[N], n;
bool indx[N];
vector<vi> edge;
void dfs(int start) {
dp[start][1] = a[start];
for (auto &x : edge[start]) {
dfs(x);
// 下属的下属可参与也可不参与
dp[start][0] += max(dp[x][0], dp[x][1]);
// 自己参与时下属必定不参与
dp[start][1] += dp[x][0];
}
}
int main() {
// freopen("in.in", "r", stdin);
cin >> n;
for (int i = 1; i <= n; i++)
cin >> a[i];
edge.resize(n + 1, vi());
for (int i = 1; i < n; i++) {
int k, l;
cin >> k >> l;
edge[l].push_back(k); // 有根树
indx[k] = 1; // 有入度时必定不是根结点
}
for (int i = 1; i <= n; i++)
if (indx[i] == 0) { // 找到根结点
dfs(i);
cout << max(dp[i][0], dp[i][1]);
return 0;
}
return 0;
}
思维拓展:
-
若简单定义 d p [ x ] dp[x] dp[x] 表示他所在的子树的最大快乐指数和。因为直系下属不可选,所以状态转移方程无法推导。
-
使用贪心策略,当前结点参与时,他的所有直系下属不参与,他的所有二级下属都参与,此时使用 bfs 解决。但很容易举出反例,例如他的所有直系下属贡献了所有结点的最大快乐指数,再例如根结点的左右子树的树高不相同,但所有结点权值都相同,此时从叶结点开始遍历可拿到最优解。
-
本题是标准的求树的最大独立集。因为题目求的是所有非直接上、下级关系的结点的集合,虽然最后是以求和的方式描述集合,但并不影响问题的性质。
拓扑排序遍历填表
从根结点看去,这个有根树也算是有向无环图的一种,此时就从所有的叶结点开始,通过拓扑排序进行状态转移也能解决问题。
此时状态定义和转移方程不变,但建树时需要更换自身与下属在树中的映射关系,同时在遍历上司时进行方程递归。此时题目就能使用图上 dp 的思路求解。
且使用拓扑排序不需要像 dfs 一样开辟大量函数栈帧,在面对一整个长链时可减少内存压力。
P1352 没有上司的舞会 - 洛谷 的拓扑排序遍历参考(邻接表建树):
#include <bits/stdc++.h>
using namespace std;
using vi = vector<int>;
const int N = 6e3 + 10;
int dp[N][2], odx[N];
vector<vi> edge;
int n;
int bfs() { // 拓扑排序
queue<int> q;
for (int i = 1; i <= n; i++) // 入度为0时入队
if (!odx[i])
q.push(i);
while (q.size()) {
int f = q.front();
q.pop();
for (auto &x : edge[f]) {
dp[x][0] += max(dp[f][0], dp[f][1]);
dp[x][1] += dp[f][0];
odx[x]--;
if (!odx[x])
q.push(x);
}
}
int ans = -1e9;
for (int i = 1; i <= n; i++) // 不关心根结点,直接遍历获取答案
ans = max(ans, max(dp[i][0], dp[i][1]));
return ans;
}
int main() {
// freopen("in.in", "r", stdin);
cin >> n;
for (int i = 1; i <= n; i++)
cin >> dp[i][1];
edge.resize(n + 1, vi());
for (int i = 1; i < n; i++) {
int l, k;
cin >> l >> k;
edge[l].push_back(k); // 更换上司和下属在树中的关系
odx[k]++; // 统计入度
}
cout << bfs(); // 拓扑排序
return 0;
}
树的最小边覆盖
树的最小边覆盖也叫树的最小支配集,边覆盖是指一个边集合,使得图中的每个顶点至少与集合中的一条边相关联。最小边覆盖即包含边数最少的边覆盖。
P2016 战略游戏 - 洛谷
[P2016 SEERC 2000] 战略游戏 - 洛谷
题目给了一个无根树,要求一个结点最多可放 1 个士兵,要求以最少的士兵数把所有的边覆盖,所以求的是最小边覆盖。对任意结点,可放士兵也可不放,所以任意结点都有 2 个状态。
用树形 dp 的思路:
-
状态定义
设 d p [ i ] [ 0 ] dp[i][0] dp[i][0] 表示当前结点不放士兵时,把所有的边覆盖所需的最小士兵数,则 d p [ i ] [ 1 ] dp[i][1] dp[i][1] 表示当前结点放士兵的状态。
-
转移方程
若当前结点放士兵,则它的子结点可放可不放,在所有子结点的 2 种状态中取最小的一种叠加即可;若当前结点不放士兵,则它的子结点必放士兵。
所以转移方程(组): { d p [ i ] [ 1 ] = ∑ x min ( d p [ x ] [ 0 ] + d p [ x ] [ 1 ] ) d p [ i ] [ 0 ] = 1 + ∑ x ( d p [ x ] [ 1 ] ) \begin{cases}dp[i][1]=\sum\limits_x\min(dp[x][0]+dp[x][1])\\dp[i][0]=1+\sum\limits_x(dp[x][1])\end{cases} ⎩ ⎨ ⎧dp[i][1]=x∑min(dp[x][0]+dp[x][1])dp[i][0]=1+x∑(dp[x][1])
-
初始化
d p [ i ] [ 1 ] = 1 dp[i][1]=1 dp[i][1]=1 表示当前结点必放士兵, d p [ i ] [ 0 ] = 0 dp[i][0]=0 dp[i][0]=0 表示当前结点必定不放士兵。
-
填表
因为是无根树,所以任意结点都可以作为树的根结点进行 dfs ,同时要避免递归函数遍历父结点。
-
最终答案
所有子树的答案最终都会反馈给根结点,所以 min ( d p [ s t a r t ] [ 0 ] , d p [ s t a r t ] [ 1 ] ) \min(dp[start][0],dp[start][1]) min(dp[start][0],dp[start][1]) 就是答案, s t a r t start start 表示根结点, s t a r t ∈ { 1 , 2 , … , n } start\in \{1,2,\dots,n\} start∈{1,2,…,n} 。
[P2016 SEERC 2000] 战略游戏 - 洛谷 和 1578:【例 4】战略游戏 参考程序:
#include <bits/stdc++.h>
using namespace std;
using vi = vector<int>;
const int N = 1510;
int n;
int dp[N][2];
vector<vi> edge;
void dfs(int start, int fa) {
dp[start][1] = 1;
for (auto &x : edge[start]) {
if (x == fa)
continue;
dfs(x, start);
dp[start][1] += min(dp[x][0], dp[x][1]);
dp[start][0] += dp[x][1];
}
}
int main() {
// freopen("in.in", "r", stdin);
cin >> n;
edge.resize(n + 1, vi());
for (int i = 1; i <= n; i++) {
int op, num, node;
cin >> op >> num;
for (int j = 1; j <= num; j++) {
cin >> node;
edge[op].push_back(node);
edge[node].push_back(op);
}
}
dfs(0, -1); // 0可更换
cout << min(dp[0][0], dp[0][1]);
return 0;
}
树的最小点覆盖
点覆盖是指一个顶点集合,使得图中的每条边至少有一个端点在此集合中。最小点覆盖即包含顶点数最少的点覆盖。
P2899 Cell Phone Network G - 洛谷
[P2899 USACO08JAN] Cell Phone Network G - 洛谷
这一题需要和 [P2016 SEERC 2000] 战略游戏 - 洛谷 区分开,战略游戏是在一个结点放士兵后,他可通过边瞭望其他士兵,相当于是 “覆盖边” 。而这题是放置信号塔在草地,使得周边的草地可被这个信号塔覆盖,相当于是 “覆盖点” 。
既然是覆盖点,就要考虑被自己的信号塔覆盖、被父结点覆盖和被子结点覆盖 3 种情况。所以用树形 dp 的思路分析:
-
状态定义
设 d p [ i ] [ 0 ] dp[i][0] dp[i][0] 表示在 i i i 草地上放信号塔时整个树的放置的最小信号塔数,同理 d p [ i ] [ 1 ] dp[i][1] dp[i][1] 表示在 i i i 草地不放信号塔但被父结点的信号塔覆盖时, d p [ i ] [ 2 ] dp[i][2] dp[i][2] 表示在 i i i 草地不放信号塔但被子结点的信号塔覆盖时,整个树的放置的最小信号塔数。
题目要求的是整个草地被信号塔覆盖所需的最小信号塔树,而使用树形 dp 时所有的结果都会汇集在根结点,根结点不存在父结点,所以答案就是 min ( d p [ s t a r t ] [ 0 ] , d p [ s t a r t ] [ 2 ] ) \min(dp[start][0],dp[start][2]) min(dp[start][0],dp[start][2]) , s t a r t start start 表示根结点。
-
转移方程
-
在 i i i 草地放信号塔时的情况,此时子结点的信号塔可放可不放,此时取 i i i 结点的所有子树的所有情况中的最小值统计即可。所以 d p [ i ] [ 0 ] = 1 + ∑ x min ( d p [ x ] [ 0 ] , d p [ x ] [ 1 ] , d p [ x ] [ 2 ] ) dp[i][0]=1+\sum\limits_x\min(dp[x][0],dp[x][1],dp[x][2]) dp[i][0]=1+x∑min(dp[x][0],dp[x][1],dp[x][2]) ;
-
在 i i i 草地不放信号塔时,此时子结点必定不会被它的父结点的信号塔覆盖。此时 i i i 结点分成被自身父结点信号塔覆盖,和被自身子结点信号塔覆盖 2 种情况。
-
被自身父结点信号塔覆盖。此时它的所有子结点的信号塔可放可不放。此时 i i i 结点在所有子结点的 2 种情况中取最小值累加即可。所以 d p [ i ] [ 1 ] = ∑ x min ( d p [ x ] [ 0 ] , d p [ x ] [ 2 ] ) dp[i][1]=\sum\limits_x\min(dp[x][0],dp[x][2]) dp[i][1]=x∑min(dp[x][0],dp[x][2])
-
被自身子结点信号塔覆盖。此时子结点中至少有 1 个被放置信号塔。
首先是多个子结点放置信号塔的情况,这种情况必定是某些子结点,在这个子结点上放置信号塔比不放信号塔,整个子树能放置更少信号塔。此时直接在所有子结点的 2 种情况中取最小值即可。
然后就是只有 1 个子结点放置信号塔的情况,这种情况必定是某些子结点,在这个子结点上不放信号塔比放置信号塔,整个子树能放置更少信号塔。此时所有的子结点都是不放置塔,但必须有 1 个子结点要放信号塔,此时就选择造成的影响最小的那个子结点放置即可。
综上,可得转移方程(组):
-
d p [ i ] [ 2 ] = { ∑ x min ( d p [ x ] [ 0 ] , d p [ x ] [ 2 ] ) d p [ x ] [ 0 ] ≤ d p [ x ] [ 2 ] ∑ x min ( d p [ x ] [ 0 ] , d p [ x ] [ 2 ] ) + min x ( d p [ x ] [ 0 ] − d p [ x ] [ 2 ] ) d p [ x ] [ 0 ] > d p [ x ] [ 2 ] \begin{aligned}&dp[i][2]=\\&\begin{cases}\sum\limits_x\min(dp[x][0],dp[x][2])&dp[x][0]\leq dp[x][2]\\\sum\limits_x \min(dp[x][0],dp[x][2])+\min\limits_x(dp[x][0]-dp[x][2])&dp[x][0]>dp[x][2]\end{cases}\end{aligned} dp[i][2]=⎩ ⎨ ⎧x∑min(dp[x][0],dp[x][2])x∑min(dp[x][0],dp[x][2])+xmin(dp[x][0]−dp[x][2])dp[x][0]≤dp[x][2]dp[x][0]>dp[x][2]
-
-
初始化
d p [ i ] [ 0 ] = 1 dp[i][0]=1 dp[i][0]=1 ,其余都为 0 。
-
填表
这次是无根树,可选择任意结点进行 dfs 但要注意不可生成父结点的函数栈帧。同时不放信号塔时可先叠加 min ( d p [ x ] [ 0 ] , d p [ x ] [ 2 ] ) \min(dp[x][0],dp[x][2]) min(dp[x][0],dp[x][2]) ,然后统计所有的 d p [ x ] [ 0 ] − d p [ x ] [ 2 ] dp[x][0]-dp[x][2] dp[x][0]−dp[x][2] 的最小值,若所有的 d p [ x ] [ 0 ] − d p [ x ] [ 2 ] dp[x][0]-dp[x][2] dp[x][0]−dp[x][2] 的最小值均大于 0 ,说明所有的子结点都是不放信号塔比放信号塔能取得最优解,这时再在 d p [ i ] [ 2 ] dp[i][2] dp[i][2] 上叠加最小的 d p [ x ] [ 0 ] − d p [ x ] [ 2 ] dp[x][0]-dp[x][2] dp[x][0]−dp[x][2] 即可。
参考程序:
#include <bits/stdc++.h>
using namespace std;
using vi = vector<int>;
using vvi = vector<vi>;
const int N = 1e4 + 10;
int dp[N][3];
vvi edge;
int n;
void dfs(int start, int fa) {
dp[start][0] = 1;
int mmin = 1e9;
for (auto &x : edge[start]) {
if (x == fa)
continue;
dfs(x, start);
dp[start][0] += min(dp[x][0], min(dp[x][1], dp[x][2]));
dp[start][1] += min(dp[x][0], dp[x][2]);
dp[start][2] += min(dp[x][0], dp[x][2]);
mmin = min(mmin, dp[x][0] - dp[x][2]);
}
if(mmin>0)
dp[start][2] += mmin;
}
int main() {
// freopen("in.in", "r", stdin);
cin >> n;
edge.resize(n + 1, vi());
for (int i = 1; i < n; i++) {
int x, y;
cin >> x >> y;
edge[x].push_back(y);
edge[y].push_back(x);
}
dfs(1, -1);
cout << min(dp[1][0], dp[1][2]);
return 0;
}
动态规划是这样的,分析占用最长的时间,但代码实现大都短小、精炼。
P2458 保安站岗 - 洛谷
[P2458 SDOI2006] 保安站岗 - 洛谷
在 [P2899 USACO08JAN] Cell Phone Network G - 洛谷 的基础上增加经费数据即初始权值即可。同时注意输入格式。
#include <bits/stdc++.h>
using namespace std;
using vi = vector<int>;
using vvi = vector<vi>;
const int N = 1510;
int dp[N][3], a[N];
vvi edge;
int n;
void dfs(int start, int fa) {
dp[start][0] = a[start];
int mmin = 1e9 + 7;
for (auto &x : edge[start]) {
if (x == fa)
continue;
dfs(x, start);
dp[start][0] += min(dp[x][0], min(dp[x][1], dp[x][2]));
dp[start][1] += min(dp[x][0], dp[x][2]);
dp[start][2] += min(dp[x][0], dp[x][2]);
mmin = min(mmin, dp[x][0] - dp[x][2]);
}
if (mmin >= 0)
dp[start][2] += mmin;
}
int main() {
// freopen("in.in", "r", stdin);
cin >> n;
edge.resize(n + 1, vi());
for (int i = 1; i <= n; i++) {
int op, m, node;
cin >> op;
cin >> a[op] >> m; //注意op可能不等于i
for (int j = 1; j <= m; j++) {
cin >> node;
edge[op].push_back(node);
edge[node].push_back(op);
}
}
dfs(1, -1); // 无根树
cout << min(dp[1][0], dp[1][2]);
return 0;
}
树形dp中的计数问题
树上计数问题通常要求在树形数据结构中统计满足特定条件的方案总数。这里仅举例染色计数,实际的计数问题有很多种。
P4084 Barn Painting G - 洛谷
[P4084 USACO17DEC] Barn Painting G - 洛谷
根据题目描述,所有结点的关系是一个无根树。根据前文的经验,易知 3 种颜色表示结点的 3 种状态。所以使用树形 dp 的思路分析:
-
状态表示
设 d p [ i ] [ j ] dp[i][j] dp[i][j] 表示结点 i i i 被涂成颜色 j j j 时,整个子树的涂色方法数。 j ∈ { 0 , 1 , 2 } j\in \{0,1,2\} j∈{0,1,2} ,也可以是 { 1 , 2 , 3 } \{1,2,3\} {1,2,3} 。
此时答案就是 ( d p [ r o o t ] [ 0 ] + d p [ r o o t ] [ 1 ] + d p [ r o o t ] [ 2 ] ) % ( M O D ) (dp[root][0]+dp[root][1]+dp[root][2])\% (MOD) (dp[root][0]+dp[root][1]+dp[root][2])%(MOD) , M O D = 10 9 + 7 MOD=10^9+7 MOD=109+7 。
-
转移方程
假设一个 4 个结点的三叉树(题目给的测试样例就是),根结点被涂了颜色 1 ,则任意一个子结点都只能在另外的颜色选择,此时子结点涂色方法数就是 2 2 2 种;根结点被涂成颜色 2 也是如此。根据乘法原理,整个三叉树的涂色方式就是 3 × ( 2 3 ) = 24 3\times(2^3)=24 3×(23)=24 种。但这个三叉树的 1 个结点被指定了颜色,所以整个三叉树的涂色方式就只是 2 3 = 8 2^3=8 23=8 种。
所以当一个子树的根结点被指定颜色时,所有的子结点都只能另外选的颜色,这个子树的涂色的方法数就是 d p [ i ] [ j ] = ( d p [ i ] [ j ] × ∑ x , k ≠ j d p [ x ] [ k ] ) % M O D dp[i][j]=(dp[i][j]\times\sum\limits_{x,k \ne j}dp[x][k])\%MOD dp[i][j]=(dp[i][j]×x,k=j∑dp[x][k])%MOD 。
-
初始化
若某结点 x x x 被指定涂成了某种颜色 y y y ,则 d p [ x ] [ y ] = 1 dp[x][y]=1 dp[x][y]=1 ,其余 d p [ x ] [ ≠ y ] = 0 dp[x][\ne y]=0 dp[x][=y]=0 表示其他颜色的方法不存在。
若没有指定被涂成什么颜色,则 d p [ x ] [ z ] = 1 , z ∈ { 0 , 1 , 2 } dp[x][z]=1,z\in\{0,1,2\} dp[x][z]=1,z∈{0,1,2} ,或它们暂时没有被涂色,此时也是一种方法,若不这样指定,则整个树得到的答案只能是 0 。
-
填表
因为是无根树,所以用 dfs 遍历整个树。答案见状态定义分析。
[P4084 USACO17DEC] Barn Painting G - 洛谷 参考:
#include <bits/stdc++.h>
using namespace std;
using LL = long long;
using vi = vector<int>;
using vvi = vector<vi>;
const LL MOD = 1e9 + 7;
const int N = 1e5 + 10;
int n, k;
LL dp[N][3];
vvi edge;
void dfs(int st, int fa) {
if (!dp[st][0] && !dp[st][1] && !dp[st][2])
dp[st][0] = dp[st][1] = dp[st][2] = 1;
for (auto &x : edge[st]) {
if (x == fa)
continue;
dfs(x, st);
LL p12 = (dp[x][1] + dp[x][2]) % MOD;
LL p02 = (dp[x][0] + dp[x][2]) % MOD;
LL p01 = (dp[x][1] + dp[x][0]) % MOD;
dp[st][0] = (dp[st][0] * p12) % MOD;
dp[st][1] = (dp[st][1] * p02) % MOD;
dp[st][2] = (dp[st][2] * p01) % MOD;
}
}
int main() {
// freopen("in.in", "r", stdin);
cin >> n >> k;
edge.resize(n + 1, vi());
for (int i = 1; i < n; i++) {
int x, y;
cin >> x >> y;
edge[x].push_back(y);
edge[y].push_back(x);
}
for (int i = 1; i <= k; i++) {
int start, color;
cin >> start >> color;
dp[start][color - 1] = 1;
}
dfs(1, -1);
LL p0 = dp[1][0], p1 = dp[1][1], p2 = dp[1][2];
// 被奇怪的优先级顺序斩杀过
cout << (p0 + ((p1 + p2) % MOD)) % MOD;
return 0;
}
颜色还能被拓展成若干种情况,但颜色越多越复杂,此时需要用循环来遍历所有的颜色。
树形dp中的计数问题不止染色计数一种。
换根dp
换根 dp 是树形 dp 的一种,又被称为二次扫描。换根 dp 一般用来解决 2 类问题:
- 当这棵树换成不同的结点做根时,查询相应的信息是多少;
- 当前结点维护的信息需要父结点来提供,此时也需要二次扫描。
解决方法比较固定,通常需要两次 dfs:
- 第 1 次 dfs 一般用树形 dp 的方式,自底向上预处理一些信息。形式上类似后续遍历。
- 第 2 次 dfs 再进行换根 dp,根据父结点维护的信息,去更新儿子结点,是一种自上而下的方式。形式上类似前序遍历。
与树形 dp 的不同:
- 在树形 dp 中,对于当前点的结果,树形 dp 是通过子结点整合出来的(后序遍历);
- 而在换根 dp 中,则是用父结点的信息,去更新子结点(前序遍历)。
两者的更新方式是相反的。
这里只列举一个例题,详细的换根 dp 及其更深的细节将会额外开一篇重点叙述。
P3047 Nearby Cows G - 洛谷
[P3047 USACO12FEB] Nearby Cows G - 洛谷
很多题往往都是题干又臭又长,但读懂了往往用一句话就能说明白题目要做什么。
这个题的思考深度和综合难度和颜色不匹配,若划分的话应为蓝题,但洛谷将其划分为绿题自有他们的理由。
中译中:给一个 n n n 个点的树,对于每个结点,求出距离它不超过 k k k 的所有结点权值和 m i m_i mi 。
这类问题不仅要考虑当前结点,还要考虑父结点和子结点的信息,一般都有固定思路。
2次dfs扫描
首先需要熟悉 dfs 和树形 dp 的特点:
- dfs 核心是基于栈的递归,在递归时只能通过全局变量或父级递归的局部变量地址获取父级递归的信息,回溯时可获得子递归的信息。
- 树形 dp 因为基于递归进行遍历,所以回溯时也能拿到子树的信息。
这 2 种思路都无法直接获取父结点周边的所有信息,但通过树形 dp 可获取子结点的信息。所以先考虑获取所有子树的信息,再考虑父结点的信息。
-
状态定义
对当前结点,要求的是向下遍历不超过 k k k 步的信息;对它的子结点则是是向下遍历不超过 k − 1 k-1 k−1 步的信息。同理对它的子结点的子结点则是 k − 2 k-2 k−2 步 … \dots …
根据这个问题分解为子问题的模式,设置一维是无法满足需求的,所以可设 c h d [ i ] [ k ] chd[i][k] chd[i][k] 表示从 i i i 结点向下遍历 k k k 步所能得到的最大权值和。
-
转移方程
向下遍历所有能覆盖的所有结点,考虑到树形 dp 的 dfs 回溯特点,当 dfs 遍历到叶结点回溯时,叶结点的父结点就能拿到所有叶结点的信息,此时 c h d [ i ] [ 1 ] = c [ i ] + ∑ x c h d [ x ] [ 0 ] chd[i][1]=c[i]+\sum\limits_xchd[x][0] chd[i][1]=c[i]+x∑chd[x][0] 。而再往上回溯时,父结点只需根据已初始化的子结点的 c h d [ x ] [ k − 1 ] chd[x][k-1] chd[x][k−1] 推导自身的状态即可。
所以转移方程
c h d [ i ] [ k ] = c [ i ] + ∑ x c h d [ x ] [ k − 1 ] chd[i][k]=c[i]+\sum\limits_xchd[x][k-1] chd[i][k]=c[i]+x∑chd[x][k−1] 。 c [ i ] c[i] c[i] 是题目告诉的结点权值。
-
初始化 & 填表
c h d [ i ] [ k ] = c [ i ] chd[i][k]=c[i] chd[i][k]=c[i] ,通过 dfs 进行树形 dp 的填表。
到这里时依旧没有得到答案,因为每个结点并没有拿到父结点的信息。但此时已经通过第 1 次 dfs 获得了每个结点的子结点的信息,只需要再按照树形 dp 的 dfs 遍历方式,利用无根树的递归函数可获得父结点信息,根据父结点的 c h d [ f a ] [ k ] chd[fa][k] chd[fa][k] 更新当前结点的答案。
因此再次按照树形 dp 的思路分析:
-
状态定义
d p [ i ] [ k ] dp[i][k] dp[i][k] 表示距离 i i i 不超过 k k k 的所有结点权值和。
-
转移方程
设 s t st st 为当前结点, x x x 为 s t st st 的子结点。
则每个子结点的能获取的信息是第 1 次 dfs 时获得的 c h d [ x ] [ k ] chd[x][k] chd[x][k] ,以及父节点的 d p [ s t ] [ k ] dp[st][k] dp[st][k] 。因为根结点没有父结点,相当于 d p [ r o o t ] [ k ] = c h d [ r o o t ] [ k ] dp[root][k]=chd[root][k] dp[root][k]=chd[root][k] ,在 dfs 的递归的过程中 d p [ s t ] [ k ] dp[st][k] dp[st][k] 会逐渐被更新。
所以有 d p [ x ] [ k ] = c h d [ x ] [ k ] + d p [ s t ] [ k − 1 ] dp[x][k]=chd[x][k]+dp[st][k-1] dp[x][k]=chd[x][k]+dp[st][k−1] ,根据容斥原理,父结点 s t st st 的 d p [ s t ] [ k − 1 ] dp[st][k-1] dp[st][k−1] 还包括 c h d [ s t ] [ k − 2 ] chd[st][k-2] chd[st][k−2] 的重复部分,所以转移方程为
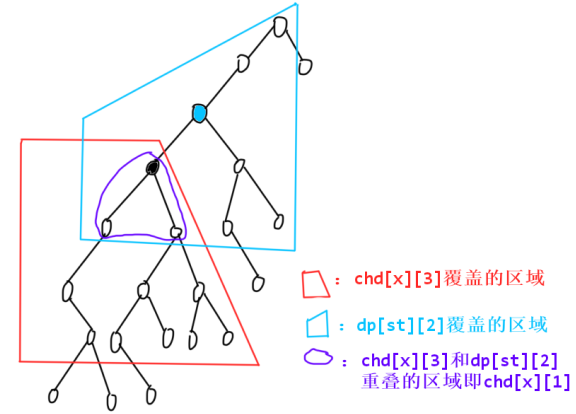
d p [ x ] [ k ] = c h d [ x ] [ k ] + d p [ s t ] [ k − 1 ] − c h d [ x ] [ k − 2 ] dp[x][k]=chd[x][k]+dp[st][k-1]-chd[x][k-2] dp[x][k]=chd[x][k]+dp[st][k−1]−chd[x][k−2] 。
以 d p [ x ] [ 3 ] = c h d [ x ] [ 3 ] + d p [ s t ] [ 2 ] − c h d [ x ] [ 1 ] dp[x][3]=chd[x][3]+dp[st][2]-chd[x][1] dp[x][3]=chd[x][3]+dp[st][2]−chd[x][1] 为例,它们覆盖的区域如下图所示:
-
初始化 & 填表
d p [ x ] [ 0 ] dp[x][0] dp[x][0] 表示距离 x x x 为 0 的结点,即自身,所以 d p [ x ] [ 0 ] = c h d [ x ] [ 0 ] dp[x][0]=chd[x][0] dp[x][0]=chd[x][0] 。
d p [ x ] [ 1 ] = c h d [ x ] [ 1 ] + d p [ s t ] [ 0 ] dp[x][1]=chd[x][1]+dp[st][0] dp[x][1]=chd[x][1]+dp[st][0] ,即自身走 1 步对应父结点走 0 步。2 个部分是没有重叠的,所以不需要减去重叠部分。
-
最终答案: d p [ i ] [ k ] dp[i][k] dp[i][k] 。
[P3047 USACO12FEB] Nearby Cows G - 洛谷 参考程序:
#include <bits/stdc++.h>
using namespace std;
using vi = vector<int>;
const int N = 1e5 + 10;
int n, k;
int chd[N][21], dp[N][21];
int c[N];
vector<vi> edge(N, vi());
void dfs_getch(int st, int fa) {
for (int i = 0; i <= k; i++)
chd[st][i] = c[st];
for (auto &x : edge[st]) {
if (x == fa)
continue;
dfs_getch(x, st);
for (int i = 1; i <= k; i++)
chd[st][i] += chd[x][i - 1];
}
}
void dfs_getans(int st, int fa) {
for (auto &x : edge[st]) {
if (x == fa)
continue;
dp[x][0] = chd[x][0];
dp[x][1] = chd[x][1] + dp[st][0];
for (int i = 2; i <= k; i++)
dp[x][i] = chd[x][i] + dp[st][i - 1] - chd[x][i - 2];
dfs_getans(x, st);
}
}
int main() {
// freopen("in.in", "r", stdin);
cin >> n >> k;
for (int i = 1; i < n; i++) {
int x, y;
cin >> x >> y;
edge[x].push_back(y);
edge[y].push_back(x);
}
for (int i = 1; i <= n; i++)
cin >> c[i];
dfs_getch(1, -1);
for (int i = 0; i <= k; i++)
dp[1][i] = chd[1][i];
dfs_getans(1, -1);
for (int i = 1; i <= n; i++)
cout << dp[i][k] << '\n';
return 0;
}
空间优化
根据转移方程 d p [ x ] [ k ] = c h d [ x ] [ k ] + d p [ s t ] [ k − 1 ] − c h d [ x ] [ k − 2 ] dp[x][k]=chd[x][k]+dp[st][k-1]-chd[x][k-2] dp[x][k]=chd[x][k]+dp[st][k−1]−chd[x][k−2] 可知, d p dp dp 数组是根据 c h d chd chd 数组进行更新的。
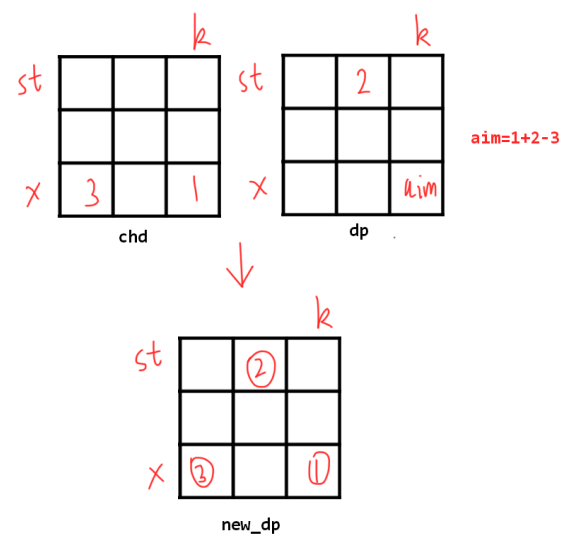
因为 2 个数组本身在根结点就是完全相等,转移方程也是用到了 2 个数组的不同部分,所以可进行空间优化: d p [ i ] [ k ] dp[i][k] dp[i][k] 的含义不变,但首先通过一轮 dfs 推导 i i i 的子结点关系,再通过二轮 dfs 获得答案。
此时方程就变成了 d p [ x ] [ k ] = d p [ x ] [ k ] + d p [ s t ] [ k − 1 ] − d p [ x ] [ k − 2 ] dp[x][k]=dp[x][k]+dp[st][k-1]-dp[x][k-2] dp[x][k]=dp[x][k]+dp[st][k−1]−dp[x][k−2] 。因为递归用到了同一个数组的 ( 1 , k − 1 ) (1,k-1) (1,k−1) 部分,所以枚举 k k k 时从 k k k 到 1 枚举,同时更新 d p [ x ] [ 0 ] dp[x][0] dp[x][0] 和 d p [ x ] [ 1 ] dp[x][1] dp[x][1] 要放在递推后进行。
[P3047 USACO12FEB] Nearby Cows G - 洛谷 的空间优化参考程序:
#include <bits/stdc++.h>
using namespace std;
using vi = vector<int>;
const int N = 1e5 + 10;
int n, k;
int dp[N][21];
int c[N];
vector<vi> edge(N, vi());
void dfs_getch(int st, int fa) {
for (int i = 0; i <= k; i++)
dp[st][i] = c[st]; // 一个dp表表示
for (auto &x : edge[st]) {
if (x == fa)
continue;
dfs_getch(x, st);
for (int i = 1; i <= k; i++)
dp[st][i] += dp[x][i - 1];
}
}
void dfs_getans(int st, int fa) {
for (auto &x : edge[st]) {
if (x == fa)
continue;
for (int i = k; i >= 2; i--) // 逆序遍历
dp[x][i] += dp[st][i - 1] - dp[x][i - 2];
dp[x][0] = dp[x][0]; // 之前是先初始化再递推
dp[x][1] += dp[st][0]; // 现在是这些值不影响递推,于是后初始化
dfs_getans(x, st);
}
}
int main() {
// freopen("in.in", "r", stdin);
cin >> n >> k;
for (int i = 1; i < n; i++) {
int x, y;
cin >> x >> y;
edge[x].push_back(y);
edge[y].push_back(x);
}
for (int i = 1; i <= n; i++)
cin >> c[i];
dfs_getch(1, -1); // 省略额外的chd=dp的赋值
dfs_getans(1, -1);
for (int i = 1; i <= n; i++)
cout << dp[i][k] << '\n';
return 0;
}
树形dp和其他知识点结合
这一类综合题和线段树、树状数组和 ST 表类似,都是在分析问题的过程中,提取出需要使用这些算法和数据结构维护的信息,往往会和其他知识点结合,极其考验综合能力。
P3554 LUK-Triumphal arch - 洛谷
[P3554 POI 2013] LUK-Triumphal arch - 洛谷
随便思考:看上去很像某种博弈模型,所以先弄懂游戏规则。给一个树,A 一次涂 k k k 个结点,B 一次走一步, 2 个玩家的行为完全不同,所以必定不是公平组合游戏和反常游戏,此时无法找到一个必胜态和必败态。
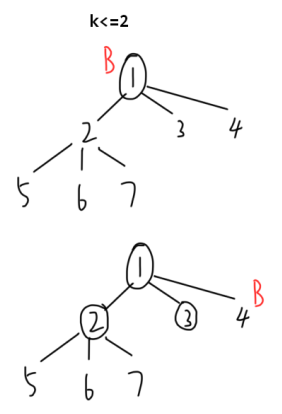
根据测试样例的描述,当 k ≤ 2 k\le 2 k≤2 时,无论如何都会漏掉 1 个白色结点,此时 B 可直接踏上这个结点,使得 B 获胜。
所以首先想到的是循环遍历 k = 1 , 2 , … , k=1,2,\dots, k=1,2,…, 当找到第 1 个必胜的 k k k 时就是答案,因为枚举的顺序有序,所以可以使用二分算法优化枚举。
或存在某个 k k k ,当一次涂色数大于等于 k k k 时 A 必胜,所以数据存在明显二段性,可用二分答案求解。
使用二分算法的话,问题就来到了如何判断当前的 k k k 是否能使得 A 必胜。
根据上述分析,当 k>=edge[x].size() 时,在当前层可使 A 占据优势。但不是每层的结点数都相同,例如出现某个子树 y y y ,使得 k<edge[y].size() ,此时 B 就能占据白色结点从而获胜。因此对每个 k k k 除了涂当前结点的子结点,还要涂子树的子结点,此时子树可以返回一个信息给父结点:当一次染色的点数为 k k k 时,所有子树根结点的子结点有多少个不能被涂色。有了求返回信息的必要,就有使用树形 dp 的希望。
设 sum 为所有子树根结点的子结点中不能被涂色的个数总和,当sum+edge[st].size()>k 即不能被涂色的个数总和加上 s t st st 的子结点数大于 k k k 时,就一定存在某个子树,当 B 移动到这个子树时, A 无法及时涂满所有子结点使得 B 走到白结点。反之sum+edge[st].size()<=k 时就能及时涂满。
这个 sum 就能使用树形 dp 进行维护。
-
状态定义
dp[i]表示以 i i i 为根结点时,不考虑根结点,有多少个结点不能被涂色。 -
转移方程
根据上述分析, d p [ i ] = edge[i].size() + ∑ x d p [ x ] − k dp[i]=\text{edge[i].size()}+\sum\limits_xdp[x]-k dp[i]=edge[i].size()+x∑dp[x]−k , edge[i].size() + ∑ x d p [ x ] \text{edge[i].size()}+\sum\limits_xdp[x] edge[i].size()+x∑dp[x] 表示有多少个结点需要涂色,减去一共能涂色的结点数。
若 d p [ i ] ≤ 0 dp[i]\leq 0 dp[i]≤0 时,此时所有结点都能涂满,根据状态定义 d p [ i ] = 0 dp[i]=0 dp[i]=0 。
-
初始化 & 填表 & 最终结果
开始时 d p [ i ] = edge[i].size() − 1 dp[i]=\text{edge[i].size()}-1 dp[i]=edge[i].size()−1 即可,减 1 是为了剔除父结点,此时根结点需要特判,可在填表时初始化。使用 dfs 遍历树,回溯时累加所有子树的 d p [ x ] dp[x] dp[x] 。
最后回溯到根结点时,若 d p [ 1 ] = 0 dp[1]=0 dp[1]=0 时说明涂到最后没有白结点剩余,此时 A 必胜,否则 A 必败。
这里树形 dp 仅作为判断游戏结果的方式使用。
[P3554 POI 2013] LUK-Triumphal arch - 洛谷 参考程序:
#include <bits/stdc++.h>
using namespace std;
vector<vector<int>> edge;
int n;
void dfs(vector<int> &dp, int st, int fa, int k) {
dp[st] = edge[st].size() - 1; // 无根树有边链接父结点
if (fa == -1)
dp[st] += 1; // 根结点无父结点
for (auto &x : edge[st]) {
if (x == fa)
continue;
dfs(dp, x, st, k);
dp[st] += dp[x];
}
dp[st] -= k; // 见转移方程
dp[st] = dp[st] < 0 ? 0 : dp[st];
}
int main() {
// freopen("in.in", "r", stdin);
cin >> n;
edge.resize(n + 1);
for (int i = 1; i < n; i++) {
int x, y;
cin >> x >> y;
edge[x].push_back(y);
edge[y].push_back(x);
}
// 二分答案
int L = 0, R = n - 1; // k可选{0,1,...,n-1}
while (L < R) { // 二分找区间左端点
int mid = (L + R) / 2;
vector<int> dp(n + 1, 0);
dfs(dp, 1, -1, mid);
if (dp[1] == 0) // A必胜,需降低k值
R = mid;
else
L = mid + 1;
}
cout << L;
return 0;
}
P3574 FAR-FarmCraft - 洛谷
[P3574 POI 2014] FAR-FarmCraft - 洛谷
题目描述的村庄是一个无根树。”他的汽油恰好够走每条路两遍“ 指可通过 dfs 遍历所有村庄。根据题目描述,无根树的 2 个直接连接的结点之间的边权为 1 (路程 1 分钟),同时每个结点都有各自的权值(每个居民安装游戏的用时 c i c_i ci )。
这个人从自己的房子也就是根结点出发,每经历一个结点就派发一个电脑,此时结点代表的居民开始安装游戏,遍历所有的结点后返回根结点自己再开始安装游戏。题目问的是所有用户都安装完游戏后是什么时候。例如测试样例的 dfs 顺序: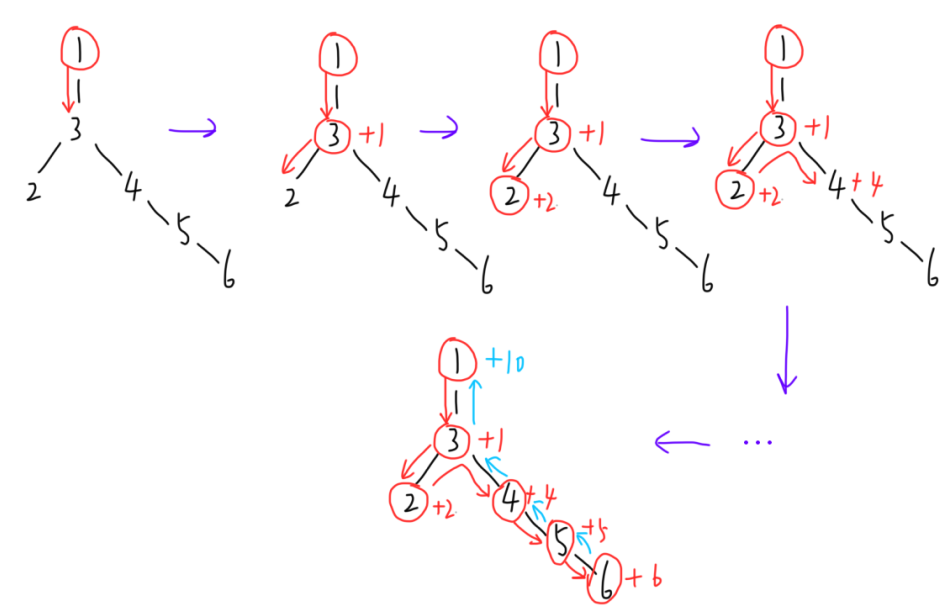
根据这个顺序,可得每个用户安装完成游戏的耗时:
用户 1 2 3 4 5 6 用户安装耗时 1 8 9 6 3 2 dfs后总耗时 10 + 1 8 + 2 9 + 1 6 + 4 3 + 5 2 + 6 \begin{array}{|c|c|c|c|c|c|c|}\hline \text{用户}&1&2&3&4&5&6\\\hline\text{用户安装耗时}&1&8&9&6&3&2\\\hline\text{dfs后总耗时}&10+1&8+2&9+1&6+4&3+5&2+6\\\hline\end{array} 用户用户安装耗时dfs后总耗时1110+1288+2399+1466+4533+5622+6
所以测试样例的答案是 11。
可自己模拟一遍,当 dfs 优先遍历右边的子树时,所有人完成游戏安装的时间将来到 16 ( 2 号结点)。
根据对题目的解读,可知遍历顺序在这里会对答案造成很大地影响。所以需要控制遍历顺序使得问题能得到最优解。此时想到排序或者某种贪心策略来安排顺序。
要得到答案,就需要知道每个居民在等待和安装时的总耗时,等待的时间可在 dfs 回溯时通过子结点反馈给父结点。因此可用树形 dp 求解每个居民在等待和安装时的总耗时。
-
状态定义
设
dp[i]表示以 i i i 为根的子树,这个子树的所有结点完成游戏安装所需的最大时间。如下是某个测试样例,根结点为 s t st st 。根据 dfs 遍历过程, y 2 y_2 y2 、 y 3 y_3 y3 和 y 4 y_4 y4 均需要等待先去左边时,经历边的耗时。
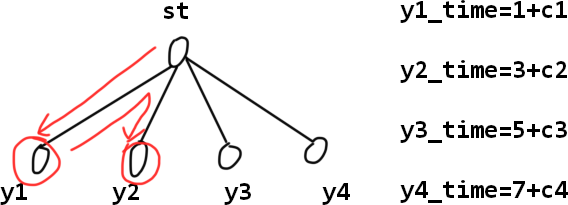
所以一个状态定义无法解决问题,此时可再定义第 2 个状态:
设
wait[i]表示以 i i i 为根结点,从 i i i 出发进行 dfs 遍历,回到 i i i 时所需的时间。或以 i i i 为根结点进行 dfs ,经历子树的每条边时耗费的时间。此时答案就是 max ( d p [ r o o t ] , w a i t [ r o o t ] + c [ r o o t ] ) \max(dp[root],wait[root]+c[root]) max(dp[root],wait[root]+c[root]) , r o o t root root 是根结点。即所有结点完成游戏安装所需的最大时间,因此答案也可以是 max ( w a i t [ i ] + c [ i ] ) \max(wait[i]+c[i]) max(wait[i]+c[i]) 。
-
转移方程
根据上图的测试样例,
dp[i]等于电脑送到前的等待时间加上自己安装游戏的耗时。所以易想到转移方程
d p [ i ] = ∑ j = 1 i − 1 w a i t [ j ] + ( 1 + 2 ( i − 1 ) ) + c [ i ] dp[i]=\sum\limits_{j=1}^{i-1}wait[j]+(1+2(i-1))+c[i] dp[i]=j=1∑i−1wait[j]+(1+2(i−1))+c[i] 。即先遍历 i i i 之前的所有的子树,才能到 i i i 结点。但这个转移方程无法用于推导,因为 dfs 的顺序会变, i i i 的含义不代表结点的遍历顺序。
但还可以根据已遍历过的结点信息推导 d p [ i ] dp[i] dp[i] ,所以转移方程还可以是这样:
d p [ i ] = max ( d p [ i ] , T + 1 + d p [ x ] ) dp[i]=\max(dp[i],T+1+dp[x]) dp[i]=max(dp[i],T+1+dp[x]) , T T T 是从 i i i 出发,遍历完前 x − 1 x-1 x−1 个结点后回到 i i i 所需的时间, T T T 可通过递推式 T = T + 2 + w a i t [ x ] T=T+2+wait[x] T=T+2+wait[x] 来求解。
此时 w a i t [ i ] = ∑ x ( 2 + w a i t [ x ] ) wait[i]=\sum\limits_x(2+wait[x]) wait[i]=x∑(2+wait[x]) 。这样在后续调整递归顺序时 d p dp dp 和 w a i t wait wait 都能求得。
-
初始化
d p [ i ] dp[i] dp[i] 可初始化为 c [ i ] c[i] c[i] ,在 dfs 时初始化。 w a i t [ i ] wait[i] wait[i] 初始化为 0 ,在对 d p [ i ] dp[i] dp[i] 进行填表时进行叠加求解。
-
填表(最重要也是最恶心的一个分析环节)
填表方式为 dfs 。但每个根结点都可能存在若干个子结点,此时这些子结点的遍历的先后顺序会对答案造成影响。这时需要确定最优遍历顺序,可通过贪心策略确定排序标准再对遍历顺序进行排序。
假设 i i i 的所有子结点为 { x 1 , … , x a , x b , … , x n } \{x_1,\dots,x_a,x_b,\dots,x_n\} {x1,…,xa,xb,…,xn} ,这些子结点可能有各自的子树,也可能没有。根据 dfs 的特性,交换 x a x_a xa 和 x b x_b xb 不会对 { x 1 , … , x a − 1 } \{x_1,\dots,x_{a-1}\} {x1,…,xa−1} 和 { x b + 1 , … , x n } \{x_{b+1},\dots,x_n\} {xb+1,…,xn} 造成影响,所以可尝试交换 x a x_a xa 和 x b x_b xb ,根据交换前和交换后的总耗时的不等关系来推导排序标准。
首先是各个部分的耗时:
{ x 1 , … ⏟ 耗时 T 1 , x a , x b , … , x n ⏟ 耗时 T 2 } \{\underbrace{x_1,\dots}_{耗时T1},x_a,x_b,\underbrace{\dots,x_n}_{耗时T2}\} {耗时T1 x1,…,xa,xb,耗时T2 …,xn}
交换前有递推式:
( 1 ) d p [ i ] = max ( d p [ i ] , m a x ( T 1 + 1 + d p [ x a ] , T 1 + 2 + w a i t [ x a ] + 1 + d p [ x b ] ) ) (1)dp[i]=\max(dp[i],max(T_1+1+dp[x_a],T_1+2+wait[x_a]+1+dp[x_b])) (1)dp[i]=max(dp[i],max(T1+1+dp[xa],T1+2+wait[xa]+1+dp[xb]))
交换 a a a 、 b b b 的顺序:
( 2 ) d p [ i ] = max ( d p [ i ] , m a x ( T 1 + 1 + d p [ x b ] , T 1 + 2 + w a i t [ x b ] + 1 + d p [ x a ] ) ) (2)dp[i]=\max(dp[i],max(T_1+1+dp[x_b],T_1+2+wait[x_b]+1+dp[x_a])) (2)dp[i]=max(dp[i],max(T1+1+dp[xb],T1+2+wait[xb]+1+dp[xa]))
假设交换前最优,则有 ( 1 ) < ( 2 ) (1)<(2) (1)<(2) , 去掉公共部分的 d p [ i ] dp[i] dp[i] 得
m a x ( T 1 + 1 + d p [ x a ] , T 1 + 2 + w a i t [ x a ] + 1 + d p [ x b ] ) < m a x ( T 1 + 1 + d p [ x b ] , T 1 + 2 + w a i t [ x b ] + 1 + d p [ x a ] ) max(T_1+1+dp[x_a],T_1+2+wait[x_a]+1+dp[x_b])<\\max(T_1+1+dp[x_b],T_1+2+wait[x_b]+1+dp[x_a]) max(T1+1+dp[xa],T1+2+wait[xa]+1+dp[xb])<max(T1+1+dp[xb],T1+2+wait[xb]+1+dp[xa])
T 1 + 1 T_1+1 T1+1 作为公共部分可剔除,此时
m a x ( d p [ x a ] , 2 + w a i t [ x a ] + d p [ x b ] ) < m a x ( d p [ x b ] , 2 + w a i t [ x b ] + d p [ x a ] ) max(dp[x_a],2+wait[x_a]+dp[x_b])<max(dp[x_b],2+wait[x_b]+dp[x_a]) max(dp[xa],2+wait[xa]+dp[xb])<max(dp[xb],2+wait[xb]+dp[xa])
因为 d p [ x b ] < 2 + w a i t [ x a ] + d p [ x b ] dp[x_b]<2+wait[x_a]+dp[x_b] dp[xb]<2+wait[xa]+dp[xb] ,所以右边不可能取 d p [ x b ] dp[x_b] dp[xb] ,否则左边取到 2 + w a i t [ x a ] + d p [ x b ] 2+wait[x_a]+dp[x_b] 2+wait[xa]+dp[xb] 时不等式不成立。
而右边的 2 + w a i t [ x b ] + d p [ x a ] > d p [ x a ] 2+wait[x_b]+dp[x_a]>dp[x_a] 2+wait[xb]+dp[xa]>dp[xa] ,所以想要不等式成立,就得有
2 + w a i t [ x a ] + d p [ x b ] < 2 + w a i t [ x b ] + d p [ x a ] 2+wait[x_a]+dp[x_b]<2+wait[x_b]+dp[x_a] 2+wait[xa]+dp[xb]<2+wait[xb]+dp[xa] ,移项得
w a i t [ x a ] − w a i t [ x b ] < d p [ x a ] − d p [ x b ] wait[x_a]-wait[x_b]<dp[x_a]-dp[x_b] wait[xa]−wait[xb]<dp[xa]−dp[xb] 。
所以当任意 x a x_a xa 和 x b x_b xb 均满足 w a i t [ x a ] − w a i t [ x b ] < d p [ x a ] − d p [ x b ] wait[x_a]-wait[x_b]<dp[x_a]-dp[x_b] wait[xa]−wait[xb]<dp[xa]−dp[xb] 时,此时就是最优解。所以排序标准就是 w a i t [ x a ] − w a i t [ x b ] < d p [ x a ] − d p [ x b ] wait[x_a]-wait[x_b]<dp[x_a]-dp[x_b] wait[xa]−wait[xb]<dp[xa]−dp[xb] 。
排序完成之后才能对 d p dp dp 和 w a i t wait wait 进行填表。
但引入贪心策略之后,当前递归向下一层递归转移时,转移的顺序反而依赖已经填好的 2 个 dp 表,这肯定不可取。所以可先弄个循环,为每个子树创建一个递归函数,每个子树会根据排序标准确定遍历顺序,然后填写 dp 表。之后再进行回溯时,父结点就得到了子结点的 dp 表的信息,再用同样的方式排序 + + + 填表,再回溯,直到走到根结点,就能完成所有的填表工作。
[P3574 POI 2014] FAR-FarmCraft - 洛谷 参考:
#include <bits/stdc++.h>
using namespace std;
using LL = long long;
using vl = vector<LL>;
using vi = vector<int>;
const LL N = 5e5 + 10;
vl c, dp, wait;
vector<vi> edge;
int t[N];
void initArray(int n) {
c.resize(n + 1, 0);
dp = wait = c;
edge.resize(n + 1, vi());
}
inline bool cmp(int x, int y) {
return wait[x] - wait[y] < dp[x] - dp[y];
}
void dfs(int st, int fa) {
dp[st] = c[st];
// 什么也不做,就开辟递归
for (auto &x : edge[st])
if (x != fa)
dfs(x, st);
// 确定递推时用到的子结点顺序
int ip = 0;
for (auto &x : edge[st])
if (x != fa)
t[++ip] = x;
sort(t + 1, t + ip + 1, cmp);
// 递推填表
LL T = 0;
for (int i = 1; i <= ip; i++) {
dp[st] = max(dp[st], T + 1 + dp[t[i]]);
T = T + 2 + wait[t[i]];
}
wait[st] = T;
}
int main() {
// freopen("in.in", "r", stdin);
int n;
cin >> n;
initArray(n);
for (int i = 1; i <= n; i++)
cin >> c[i];
for (int i = 1; i < n; i++) {
int x, y;
cin >> x >> y;
edge[x].push_back(y);
edge[y].push_back(x);
}
dfs(1, -1);
cout << max(dp[1], wait[1] + c[1]);
return 0;
}
其他未分类的树形dp
这里的 OJ 用其他未分类描述,是因为暂时找不到这类 OJ 属于哪一种经典问题,自己也没有权威到可以给树形 dp 进行分类,所以暂时放在这里。
P1131 时态同步 - 洛谷
[P1131 ZJOI2007] 时态同步 - 洛谷
中译中:给定一个有边权的无根树,增大某些边的权值,使得从根结点出发,到达所有叶结点的路径之和相同。
递归求解子树根结点到叶结点的最长距离,然后每个子树的调整次数为 ∑ x ( l e n [ s t a r t ] − ( l e n [ x ] + w [ s t a r t ] [ x ] ) ) \sum\limits_x(len[start]-(len[x]+w[start][x])) x∑(len[start]−(len[x]+w[start][x])) ,累加所有子树的调整次数就是答案。 w [ i ] [ j ] w[i][j] w[i][j] 是边 < i , j > <i,j> <i,j> 的权值。
求解 l e n [ x ] len[x] len[x] 的过程可用树形 dp 和转移方程 l e n [ x ] = max y ( l e n [ y ] + w [ x ] [ y ] ) len[x]=\max\limits_{y}(len[y]+w[x][y]) len[x]=ymax(len[y]+w[x][y]) 求解,。
#include <bits/stdc++.h>
using namespace std;
using LL = long long;
struct Node {
int ed;
LL w;
Node(int _ed = 0, LL _w = 0) {
ed = _ed, w = _w;
}
};
using vn = vector<Node>;
const LL N = 5e5 + 10;
vector<vn> edge;
int n, root;
LL len[N], ans = 0;
void dfs(int st, int fa) {
for (auto &x : edge[st]) {
if (x.ed == fa)
continue;
dfs(x.ed, st);
len[st] = max(len[st], len[x.ed] + x.w);
}
for (auto &x : edge[st])
if (x.ed != fa)
ans += len[st] - (x.w + len[x.ed]);
}
int main() {
// freopen("in.in", "r", stdin);
cin >> n >> root;
edge.resize(n + 1, vn());
for (int i = 1; i < n; i++) {
int a, b;
LL t;
cin >> a >> b >> t;
edge[a].push_back({b, t});
edge[b].push_back({a, t});
}
dfs(root, -1);
cout << ans;
return 0;
}
OJ参考
- 最大权连通子图
- 树的最大独立集
- 树的最小边覆盖
[P2016 SEERC 2000] 战略游戏 - 洛谷
- 树的最小点覆盖
[P2899 USACO08JAN] Cell Phone Network G - 洛谷
[P2458 SDOI2006] 保安站岗 - 洛谷
- 树形dp中的计数问题
[P4084 USACO17DEC] Barn Painting G - 洛谷
- 换根 dp
[P3047 USACO12FEB] Nearby Cows G - 洛谷
- 树形dp和其他知识点结合
[P3554 POI 2013] LUK-Triumphal arch - 洛谷
[P3574 POI 2014] FAR-FarmCraft - 洛谷
- 其他未分类的树形dp
[P1131 ZJOI2007] 时态同步 - 洛谷

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)