ESP32小智AI机器人|技术点与难点深度剖析
·
https://blog.csdn.net/h050210/article/details/146120433?spm=1001.2014.3001.5506原文链接
一、核心架构与技术栈概览
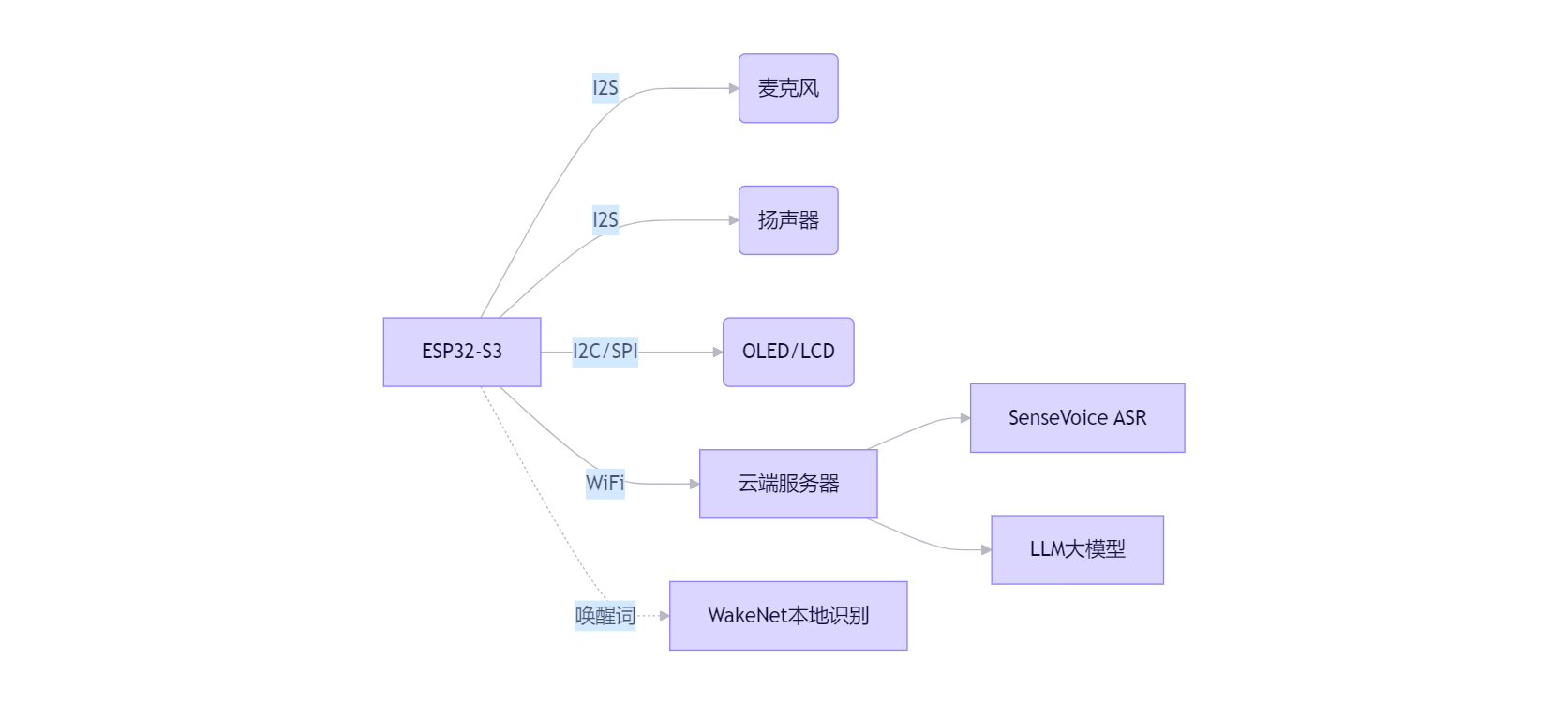
二、关键模块技术点与难点(按重要性排序)
1. 语音唤醒子系统(WakeNet)
技术点:
- AFE声学前处理:
afe_config_t结构体配置,含AGC(自动增益控制)、NS(噪声抑制) - 唤醒词模型集成:乐鑫提供的预训练模型(如"wn9_xiaozhi")或自定义模型
- 资源分配:PSRAM分配给模型(通常需要4MB+),需在menuconfig中调整
// 典型难点:唤醒灵敏度与误触发平衡
afe_config.wakenet_pcm_shift = 7; // 调整此值优化噪声环境性能
afe_config.aec_init = false; // 关闭AEC可提升唤醒率但牺牲通话质量
// 资源冲突:当PSRAM<8MB时,需精简模型或降低采样率有经验者的建议:先用官方示例esp-skainet/examples/speech_recognition/wakenet验证基础功能,再集成到项目。唤醒词模型文件(.bin)需放在components/esp-sr/wake_word_engines目录下。
2. I2S音频采集与流处理
技术点:
- I2S DMA配置:16kHz采样率、16位深度、单声道(节省带宽)
- 环形缓冲区管理:双缓冲设计(采集+传输并行)
- VAD(语音活动检测):基于能量阈值的简单算法
难点与突破:
// 典型问题:I2S溢出导致音频断续
i2s_config_t i2s_config = {
.mode = I2S_MODE_MASTER | I2S_MODE_RX,
.sample_rate = 16000, // 非48kHz!降低处理压力
.bits_per_sample = I2S_BITS_PER_SAMPLE_16BIT,
.channel_format = I2S_CHANNEL_FMT_ONLY_LEFT, // 单声道
.communication_format = I2S_COMM_FORMAT_STAND_I2S,
.intr_alloc_flags = ESP_INTR_FLAG_LEVEL1,
.dma_buf_count = 8, // 增加缓冲区数量
.dma_buf_len = 256 // 每个缓冲区大小
};
// 关键:当网络延迟高时,需动态丢弃旧音频帧保实时性💡 有经验者的建议:用逻辑分析仪抓I2S时序(BCK/LRCK/DATA),90%的音频问题源于时钟配置错误。务必确认麦克风采样率与I2S配置匹配。
3. WebSocket实时通信
技术点:
- 二进制帧传输:音频PCM数据打包为WebSocket二进制帧
- 心跳机制:防止NAT超时断开
- 断线重连:指数退避算法(1s→2s→4s→8s)
难点与突破
// 典型问题:大文件传输时内存溢出
// 错误写法:esp_websocket_client_send_bin(client, big_buffer, big_size);
// 正确做法:分块传输
#define CHUNK_SIZE 1024
for (int i=0; i<total_size; i+=CHUNK_SIZE) {
size_t chunk_len = MIN(CHUNK_SIZE, total_size-i);
esp_websocket_client_send_bin(client, buffer+i, chunk_len, 1000/portTICK_PERIOD_MS);
vTaskDelay(10/portTICK_PERIOD_MS); // 避免背压
}
// 服务端需处理分片重组💡 有经验者的建议:在ESP32端添加流量统计(
bytes_sent/second),当速率>8KB/s时需压缩或降采样。用Wireshark抓包分析WebSocket帧头(0x82表示二进制帧)。
4. 云端AI集成
技术点:
- 音频格式转换:PCM→WAV(添加头信息)或直接传输原始PCM
- RESTful API调用:SenseVoice的ASR接口、Qwen的对话接口
- 异步处理:非阻塞式等待大模型响应
难点与突破:
Python
# 服务端关键代码(Python)
async def handle_audio(websocket):
audio_buffer = bytearray()
while True:
data = await websocket.recv()
if isinstance(data, bytes):
audio_buffer.extend(data)
elif data == "<END>":
# 1. 保存为WAV(SenseVoice要求)
with wave.open("temp.wav", "wb") as wf:
wf.setnchannels(1)
wf.setsampwidth(2) # 16-bit
wf.setframerate(16000)
wf.writeframes(audio_buffer)
# 2. 调用SenseVoice API
text = sensevoice_api.transcribe("temp.wav")
# 3. 调用LLM(注意上下文管理)
response = qwen_api.chat(text, conversation_id=client_id)
await websocket.send(response)💡 有经验者的建议:先用Postman测试SenseVoice API(上传WAV文件),确认云端服务正常后再联调设备。LLM响应超时需设置5秒超时,避免ESP32挂起。
具体操作方法:
一、硬件层(必须亲手操作)
| 技术点 | 具体要掌握的内容 | 验收标准 |
|---|---|---|
| ESP32-S3开发板 | 识别PSRAM型号(8MB)、USB转串口芯片(CP210x/CH340)、BOOT/RESET按键作用 | 能说出引脚图中GPIO46是I2S_BCK |
| INMP441麦克风 | I2S接口接线(BCK/LRC/DIN/GND)、供电3.3V、采样率配置(16kHz/48kHz) | 用万用表测通断,接线后串口输出音量值波动 |
| MAX98357A功放 | I2S输入接ESP32、GAIN引脚接高/低电平控制音量、3.3V供电 | 接喇叭后能播放测试音(无杂音) |
| OLED显示屏 | I2C接口(SDA=GPIO8, SCL=GPIO9)、初始化命令序列 | 显示"WiFi Connected"文字 |
| 焊接与测量 | 杜邦线焊接、万用表测电压/通断、示波器看I2S时钟波形(可选) | 独立完成麦克风模块焊接无虚焊 |
💻 二、嵌入式开发(ESP-IDF环境)
| 模块 | 具体技能点 | 代码级要求 |
|---|---|---|
| 环境搭建 | 安装ESP-IDF v5.1+、配置idf.py、设置Python虚拟环境 | idf.py --version 显示正确版本 |
| FreeRTOS | 创建任务(xTaskCreate)、队列传递音频数据(xQueueSend)、信号量同步 | 两个任务:采集任务→处理任务,用队列传PCM数据 |
| I2S驱动 | 配置i2s_config_t:sample_rate=16000, bits_per_sample=16, channel_format=I2S_CHANNEL_FMT_ONLY_LEFT |
用i2s_read读取1024点PCM数据存入buffer |
| WebSocket客户端 | 使用esp_websocket_client:设置URI、注册事件回调(CONNECTED/DATA) |
收到"start"指令后开始发音频流 |
| VAD实现 | 计算100ms音频块的RMS能量,阈值>500判定为语音 | 语音开始/结束时串口打印"[VAD] Speech Start" |
| GPIO控制 | 配置LED引脚(GPIO2)、按键中断(GPIO0) | 按键触发唤醒,LED呼吸灯表示录音中 |
| 调试技巧 | ESP_LOGI(TAG, "data len=%d", len)、串口过滤日志 |
能定位"I2S read timeout"错误原因 |
☁️ 三、云端服务(Python)
| 模块 | 具体技能点 | 代码示例关键词 |
|---|---|---|
| WebSocket服务 | websockets.serve(handle_client, "0.0.0.0", 8765)、async/await处理连接 |
客户端发二进制音频,服务端返回JSON {"text":"你好"} |
| 音频处理 | 用wave库写WAV文件(16kHz, 16bit, mono)、PCM转WAV头 |
wf.setparams((1, 2, 16000, 0, 'NONE', 'NONE')) |
| ASR调用 | 调用阿里云百炼SenseVoice:构造multipart/form-data、headers带API_KEY | requests.post(url, files={'file': open('audio.wav','rb')}, headers=...) |
| LLM调用 | 调用Qwen API:构造messages=[{"role":"user","content":"..."}] | 处理流式响应(stream=True)拼接完整回答 |
| TTS(可选) | 调用阿里云TTS:text→mp3,返回音频流 | 服务端直接返回二进制音频给ESP32 |
| 错误处理 | try/except捕获requests.Timeout、JSONDecodeError | 返回{"error":"ASR_TIMEOUT"}给设备端 |
| 部署 | 用gunicorn启动服务、systemd配置开机自启、nginx反向代理(可选) | systemctl status ai-robot 显示active |
🤖 四、AI集成(无需训练模型!)
| 任务 | 具体操作 | 工具/平台 |
|---|---|---|
| 语音识别 | 上传WAV文件→获取JSON文本 | 阿里云百炼(SenseVoice)、讯飞开放平台 |
| 对话生成 | 发送用户问题→获取LLM回复 | 通义千问API、DeepSeek API(注册即用) |
| 语音合成 | 文本→MP3音频流 | 阿里云智能语音交互、Edge TTS(免费) |
| 关键认知 | 理解API调用流程:认证→请求→解析→错误码处理 | 重点掌握:status_code==200、response.json()['data'] |
🔍 五、调试与联调(实战核心)
| 场景 | 必须掌握的技能 | 工具命令 |
|---|---|---|
| 串口调试 | 过滤日志:idf.py monitor --pattern="I2S" |
idf.py -p COM3 monitor |
| 网络抓包 | 用Wireshark过滤websocket,看二进制帧长度 |
过滤表达式:websocket |
| 音频验证 | 用Audacity打开生成的WAV文件,看波形是否正常 | 检查是否有静音段、爆音 |
| 断线重连 | ESP32端:检测WEBSOCKET_EVENT_DISCONNECTED→延时重连 |
重连间隔指数退避(1s→2s→4s) |
| 内存监控 | esp_get_free_heap_size() 检查内存泄漏 |
任务运行10分钟后内存下降<10% |
📚 精准学习资源(按技能点匹配)
| 技能点 | 直接可用的资源 |
|---|---|
| I2S配置参数 | ESP-IDF I2S文档 → 重点看"i2s_config_t"结构体 |
| WebSocket客户端 | ESP-IDF examples: protocols/websocket(直接复制修改) |
| VAD简易实现 | GitHub搜"esp32 vad rms" → 参考esp-skainet/vad |
| 百炼平台调用 | 阿里云百炼控制台 → "SenseVoice语音识别" → "Python调用示例"(复制粘贴改API_KEY) |
| 音频格式转换 | Python库pydub:AudioSegment.from_wav("in.wav").export("out.mp3", format="mp3") |
| 错误码速查 | 遇到0x101 → 搜"ESP_ERR_I2S_TIMEOUT";0x80040200 → 搜"regsvr32错误码" |
学习目标阶段
核心技能树(按优先级排序)
🌱 阶段一:基础必备(1-2个月)
| 领域 | 关键技能 | 推荐学习内容 |
|---|---|---|
| 编程基础 | C/C++语法、指针、内存管理 | 《C Primer Plus》+ 菜鸟教程C语言 |
| 嵌入式入门 | GPIO、串口、I2C、SPI基础 | 《Arduino从入门到精通》(先用Arduino熟悉ESP32) |
| 网络基础 | HTTP/WebSocket/TCP概念 | 《图解HTTP》+ MDN WebSocket文档 |
| Linux基础 | 常用命令、文件操作 | 《鸟哥的Linux私房菜》基础篇 |
🌿 阶段二:专项突破(2-3个月)
| 模块 | 学习重点 | 推荐资源 |
|---|---|---|
| ESP32开发 | ESP-IDF环境搭建、FreeRTOS、I2S音频驱动 | ✅ ESP-IDF官方文档 ✅ 《ESP32-C3开发实战》(机械工业出版社) ✅ B站搜索“安信可ESP32教程” |
| 语音处理 | VAD(语音活动检测)、音频采样、PCM格式 | ✅ GitHub项目:esp-sr(含WakeNet源码) ✅ 《语音信号处理》(韩纪庆)第1-3章 |
| 云端部署 | Python Flask/FastAPI、WebSocket服务、Docker基础 | ✅ 《Flask Web开发实战》 ✅ 廖雪峰Docker教程 |
| AI集成 | 调用开源ASR/TTS/LLM API(非训练模型) | ✅ 阿里云百炼平台(SenseVoice快速体验) ✅ Hugging Face Model Hub搜索"whisper"、"Qwen" |
🌳 阶段三:系统整合(边做边学)
- 调试能力:串口日志分析、Wireshark抓包、逻辑分析仪使用
- 版本管理:Git基础(提交/分支/合并)
- 文档能力:用Draw.io画系统架构图,用Typora写技术笔记

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)