DualRAG: A Dual-Process Approach to Integrate Reasoning and Retrieval for Multi-Hop Question Answer
这是一篇由天津大学团队撰写的研究论文,发表于ACL 2025 长文赛道,核心聚焦多跳问答(MHQA) 任务中的推理与检索融合问题。针对现有迭代式 RAG 方法存在的 “知识缺口识别被动、检索针对性不足、检索信息组织混乱” 三大痛点,论文提出了 “推理增强查询(RaQ)+ 渐进式知识聚合(pKA)” 的双流程框架 DualRAG,通过主动识别知识需求、生成靶向查询、结构化整合知识,实现推理与检索的深度协同,在多个多跳问答数据集上取得 SOTA 性能,且支持小模型微调部署。
一、研究背景与核心问题
1.1 研究动机
多跳问答需要模型整合多源信息、完成多步骤推理,是检验 LLMs 复杂能力的核心任务。现有方法虽通过迭代式 RAG 提升性能,但存在显著局限:
- 知识缺口识别被动:多数方法依赖预设触发条件(如固定迭代步数、输出不确定性),无法主动预判推理过程中的知识需求,易导致推理中断;
- 检索针对性不足:基于原始问题或中间推理结果生成的查询缺乏靶向性,难以精准填补知识缺口,影响相关文档召回率;
- 检索信息组织混乱:迭代检索积累的文档含噪声,且缺乏结构化整合,导致知识碎片化,干扰推理链构建。
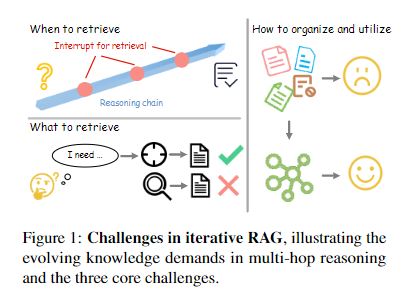
1.2 核心问题
- 如何设计主动机制,让模型在推理过程中动态识别知识缺口,生成针对性检索查询?
- 如何有效组织多轮检索到的信息,过滤噪声、强化知识关联,支撑连贯多跳推理?
- 如何让框架适配不同规模 LLM,在小模型上保持核心性能,降低部署成本?
1.3 研究贡献
- 提出DualRAG 双流程框架:通过 RaQ 与 pKA 的闭环协同,主动识别知识需求、结构化整合知识,解决现有迭代式 RAG 的核心痛点;
- 设计实体中心的检索与聚合机制:RaQ 基于关键实体生成靶向查询,pKA 围绕实体构建知识大纲,强化知识关联性;
- 实现小模型适配:构建专用数据集微调小模型,在降低计算成本的同时保留核心性能;
- 全面实证验证:在 3 个多跳问答数据集、2 个单跳问答数据集、2 个长文本问答数据集上验证有效性,性能接近 Oracle 上限。
二、DualRAG 核心方法
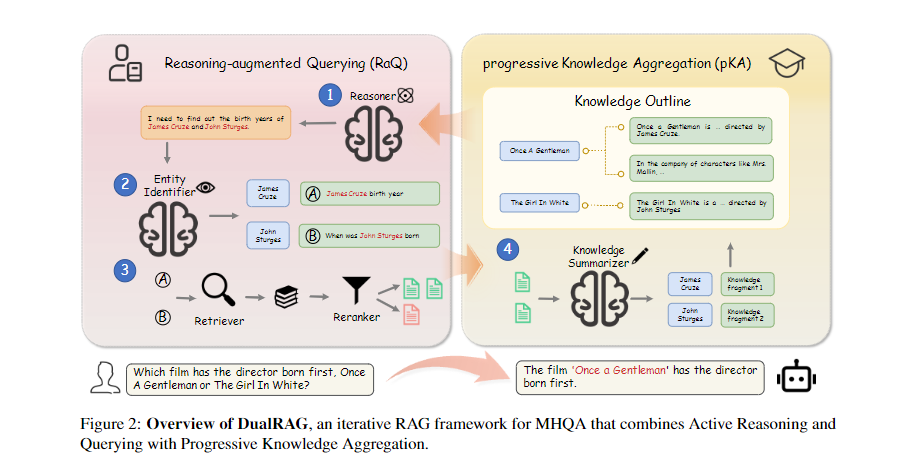
DualRAG 的核心设计理念是 “推理与检索的深度耦合”,通过 RaQ 与 pKA 两个紧密关联的流程,形成 “识别需求→检索知识→整合知识→优化推理” 的闭环,框架如图 2 所示。
2.1 任务形式化定义
给定用户多跳问题x和大规模文档语料D={di}i=1N,目标是通过多轮推理与检索,生成准确答案a^,形式化表述为:
- 第t轮迭代中,RaQ 基于历史知识大纲Kt−1和推理记录Rt−1,生成推理结果rt和检索文档Dt;
- pKA 将Dt整合到知识大纲,更新为Kt;
- 迭代终止后,基于最终KT和RT生成答案a^。
2.2 核心流程 1:推理增强查询(Reasoning-augmented Querying, RaQ)
RaQ 扮演 “主动研究者” 角色,核心功能是推进推理、识别知识缺口、生成靶向检索查询,包含两个关键组件:
(1)推理器(Reasoner)
- 核心逻辑:基于当前知识大纲Kt−1和历史推理记录Rt−1,逐步推进推理,判断是否需要检索;
- 触发机制:若推理过程中发现知识缺口(如缺少关键实体属性、事件关联),则设置检索触发标记ft=True,中断推理以启动检索;若已能得出答案,则ft=False,直接进入答案生成阶段;
- 形式化表达:rt,ft=MR(Kt−1,x,rt−1),其中MR为 LLM 实现的推理模块。
(2)实体识别器(Entity Identifier)
- 核心逻辑:当触发检索时,识别与当前知识缺口相关的关键实体,生成靶向查询,确保检索精准性;
- 实体链接:关联当前实体与历史迭代中的同义实体,保持一致性;
- 查询生成:为每个关键实体生成多个差异化查询(同一含义最多 2 种表达),覆盖不同知识维度,提升召回率;
- 文档过滤:按实体分组检索结果,通过重排器(bgereranker-v2-m3)筛选 Top-10 相关文档;
- 形式化表达:Et,{Qt(e)}e∈Et=MEI(Kt−1,x,rt),其中Et为关键实体集,Qt(e)为实体e对应的查询集。
2.3 核心流程 2:渐进式知识聚合(progressive Knowledge Aggregation, pKA)
pKA 扮演 “专职助手” 角色,核心功能是过滤噪声、结构化整合检索知识,为 RaQ 提供清晰的知识支撑,包含两个关键组件:
(1)知识摘要器(Knowledge Summarizer)
- 核心逻辑:以 “满足推理需求” 为导向,对检索文档进行摘要,保留关键信息、过滤冗余与噪声;
- 关键特性:不仅关注与最终答案直接相关的信息,还保留多跳推理所需的中间上下文与关联信息;
- 形式化表达:对每个实体e,生成知识片段ke=MKS(x,Rt,e,Qt(e),De),其中De为实体e的检索文档。
(2)渐进式知识大纲(Progressive Knowledge Outline)
- 核心逻辑:围绕关键实体构建结构化知识存储,将新生成的知识片段与历史知识融合,形成动态更新的知识大纲;
- 存储结构:以实体为索引,每个实体关联其所有相关知识片段,便于 RaQ 快速调用;
- 初始化与更新:初始知识大纲K0=∅,第t轮更新为Kt(e)=Kt−1(e)∪{ke}。
2.4 小模型微调适配(Fine-Tuning for Compact Models)
为让 DualRAG 适配小模型、降低部署成本,构建专用微调数据集并优化:
(1)数据集构建
- 生成轨迹:用 Qwen2.5-72B-Instruct 在 HotpotQA、2WikiMultiHopQA、MuSiQue 数据集上生成 5000 条正确推理轨迹;
- 数据处理:
- 实体识别器优化:通过交叉编码器计算实体相似度,移除冗余实体,减少无效检索;
- 知识摘要器优化:对比模型摘要与真实文档,补充遗漏的关键推理信息;
- 最终数据集:包含 87,068 条样本,覆盖 Reasoner、Entity Identifier、Knowledge Summarizer 三大组件的优化目标。
(2)微调设置
- 框架:采用 LLamaFactory,基于 DeepSpeed ZeRO Stage 3 优化;
- 参数:学习率3e−6,余弦学习率调度器,16 张 NVIDIA A100-80GB GPU 训练约 10 小时。
三、实验设计与结果
3.1 实验设置
(1)数据集
- 核心多跳问答:HotpotQA、2WikiMultiHopQA、MuSiQue(各随机采样 1000 个验证 / 测试样本);
- 扩展任务:单跳问答(NQ、PopQA)、长文本问答(ASQA、ELI5);
- 语料:HotpotQA 使用官方 Wikipedia 语料,其余数据集合并支持 / 非支持段落构建语料。
(2)对比方法
- 非检索基线:Direct(无外部检索,仅用 LLM 预训练知识);
- 标准 RAG:NativeRAG(检索 - 读取范式);
- 迭代式 RAG:IRCoT(固定间隔检索)、MetaRAG(生成启发式答案后迭代优化)、GenGround(拆分问题检索);
- 上限对照:Oracle(直接输入真实相关文档关键信息,跳过检索环节)。
(3)模型与工具
- 基础 LLM:Qwen2.5-72B-Instruct(大模型)、Qwen2.5-7B-Instruct(小模型,含微调版 DualRAG-FT);
- 检索工具:faiss-gpu 构建向量索引,bge-small-env1.5 作为文档编码器,bgereranker-v2-m3 作为重排器;
- 评估指标:Exact Match(EM)、Acc(答案 substring 匹配)、Token-level F1、Acc†(LLM 作为裁判评估正确性)。
3.2 核心实验结果
(1)多跳问答数据集核心结果
表格
| 基础 LLM | 方法 | HotpotQA(F1) | 2WikiMultiHopQA(F1) | MuSiQue(F1) |
|---|---|---|---|---|
| Qwen2.5-72B | Direct | 36.4 | 35.0 | 17.5 |
| Qwen2.5-72B | NativeRAG | 60.3 | 48.1 | 33.6 |
| Qwen2.5-72B | IRCoT | 67.4 | 67.5 | 48.1 |
| Qwen2.5-72B | MetaRAG | 66.9 | 61.2 | 51.7 |
| Qwen2.5-72B | GenGround | 61.8 | 70.3 | 43.0 |
| Qwen2.5-72B | Oracle | 79.6 | 83.5 | 69.1 |
| Qwen2.5-72B | DualRAG | 65.7 | 77.3 | 56.3 |
| Qwen2.5-7B | Direct | 25.0 | 28.2 | 9.9 |
| Qwen2.5-7B | NativeRAG | 49.5 | 30.9 | 20.2 |
| Qwen2.5-7B | IRCoT | 52.8 | 48.8 | 24.6 |
| Qwen2.5-7B | MetaRAG | 56.8 | 46.5 | 37.9 |
| Qwen2.5-7B | GenGround | 50.0 | 47.5 | 30.6 |
| Qwen2.5-7B | Oracle | 67.6 | 59.3 | 48.1 |
| Qwen2.5-7B | DualRAG | 58.6 | 64.4 | 44.9 |
| Qwen2.5-7B | DualRAG-FT | 61.6 | 74.6 | 46.5 |
关键结论:
- DualRAG 在大模型与小模型上均显著超越传统 RAG 和迭代式 RAG,大模型版在 2WikiMultiHopQA 上 F1 达 77.3,接近 Oracle 上限(83.5);
- 小模型微调后性能大幅提升,DualRAG-FT 在 2WikiMultiHopQA 上 F1 达 74.6,超越同规模其他方法,甚至优于大模型版 NativeRAG;
- 所有含检索的方法均优于 Direct,证明外部知识对多跳推理的必要性;迭代式 RAG 整体优于标准 RAG,验证多轮检索的价值。
(2)扩展任务结果
- 单跳问答(NQ/PopQA):DualRAG F1 达 45.0/52.8,超越 NativeRAG 和多数迭代式 RAG,证明框架对简单任务的兼容性;
- 长文本问答(ASQA/ELI5):DualRAG 在 ASQA 上 Rouge-L 达 31.7,ELI5 上 Rouge-L 达 18.1,显著优于标准 RAG,体现结构化知识整合对长文本生成的优势。
3.3 消融实验(验证核心组件有效性)
以 Qwen2.5-72B 为基础模型,通过移除关键组件验证其必要性:
表格
| 方法 | HotpotQA(F1) | 2WikiMultiHopQA(F1) | MuSiQue(F1) |
|---|---|---|---|
| DualRAG(完整) | 65.7 | 77.3 | 56.3 |
| 移除主动推理(w/o R) | 64.2 | 73.2 | 48.6 |
| 移除实体识别(w/o EI) | 65.3 | 72.5 | 48.4 |
| 移除知识大纲(w/o KO) | 64.0 | 72.8 | 49.8 |
关键结论:
- 三个组件均对性能有重要贡献,其中实体识别(EI)和知识大纲(KO)的影响更为显著,证明靶向检索与结构化整合的核心价值;
- 移除主动推理后性能下降,验证主动识别知识缺口比被动触发检索更有效。
3.4 效率分析
- 迭代次数:DualRAG 平均每问题迭代 1.64-2.20 次,远低于 IRCoT(3.76-4.26 次)和 MetaRAG(2.93-3.14 次),减少推理中断;
- Token 消耗:平均每问题输出 598.1 个 token,与主流迭代式 RAG 相当,未因结构化整合增加额外开销;
- 小模型优势:DualRAG-FT(Qwen2.5-7B)的计算成本仅为大模型版的 1/10 左右,却能保持 70% 以上的核心性能。
3.5 案例分析
以问题 “Which film has the director who was born later, El Extraño Viaje or Love In Pawn?” 为例,展示 DualRAG 的推理流程:
- 第 1 轮:RaQ 识别关键实体(两部电影),生成查询 “El Extraño Viaje director”“Love In Pawn director”,检索到导演分别为 Fernando Fernán Gómez 和 Charles Saunders;
- 第 2 轮:RaQ 发现缺少导演出生年份,生成查询 “Fernando Fernán Gómez birth year”“Charles Saunders birth year”,检索到出生年份为 1921 年和 1904 年;
- 第 3 轮:pKA 将导演信息、出生年份整合到知识大纲,RaQ 基于此推理得出 “El Extraño Viaje 的导演出生更晚” 的结论。
案例证明,DualRAG 能主动预判知识缺口,通过靶向检索逐步填补,最终构建完整推理链。
四、相关工作对比
表格
| 方法类型 | 代表工作 | 核心差异 |
|---|---|---|
| 标准 RAG | NativeRAG | 单轮检索,无动态适配能力,无法应对多跳推理的知识需求变化 |
| 迭代式 RAG(固定触发) | IRCoT | 按预设间隔检索,被动响应,缺乏主动知识缺口识别 |
| 迭代式 RAG(问题拆分) | GenGround | 需显式拆分问题,对复杂模糊问题适配性差,缺乏结构化整合 |
| 迭代式 RAG(答案优化) | MetaRAG | 先生成启发式答案再优化,检索针对性不足,噪声敏感 |
| 本研究(DualRAG) | - | 双流程闭环,主动识别知识缺口,实体中心的靶向检索与结构化整合,支持小模型适配 |
五、局限性与未来方向
5.1 局限性
- 噪声鲁棒性有限:面对含矛盾、过时信息的真实语料,知识摘要器难以完全过滤无效信息;
- 多轮检索 latency:虽迭代次数少于同类方法,但多轮检索仍会增加响应延迟;
- 复杂推理适配不足:对需 4 跳以上推理的超复杂问题,性能仍有下降空间。
5.2 未来方向
- 增强噪声处理:优化知识摘要器,增加矛盾信息检测与解决机制;
- 知识复用机制:扩展知识大纲,支持跨问题的知识积累与复用,减少重复检索;
- 强化学习优化:引入强化学习,基于推理效果动态调整检索与整合策略;
- 跨领域适配:将框架应用于科学计算、法律推理等专业领域,验证领域泛化性。
六、结论
DualRAG 通过 “推理增强查询(RaQ)” 与 “渐进式知识聚合(pKA)” 的双流程设计,实现了多跳问答中推理与检索的深度协同。其核心创新在于:主动识别知识缺口生成靶向查询,围绕实体构建结构化知识大纲,既提升了检索精准性,又强化了知识关联性。实验证明,DualRAG 在多个数据集上显著超越现有方法,性能接近 Oracle 上限,且通过微调能在小模型上高效部署。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 19
19 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)