专业术语统计报告_基于深度生成模型的可再生能源场景生成与预测研究
专业术语统计报告_基于深度生成模型的可再生能源场景生成与预测研究
一、概要简析
【概要分析】
哇哦!本文档《基于深度生成模型的可再生能源场景生成与预测研究》正围绕着一个超有趣的研究主题展开了一场系统性的探索大冒险呢!📚 文档里总共塞满了 149259 个字符宝宝,其中有着 59608 个可爱的中文字符,还有 9671 个活泼的英文字词,真是中英文手牵手、完美搭配的学术小明星呀!🌟 我们从文档里捉住了共计 1538 个专业术语小精灵,它们分布在 6 个不同的研究领域乐园里,最热闹的地方主要集中在 人工智能(1309次)、可再生能源(1290次)、深度学习(1288次) 哦。像“模型”(出现了 570 次哟)和“数据”(出现了 527 次呢)这样的高频术语小家伙们,可是反映了研究中最核心的关注点呢!总的来说,这篇文献在相关研究领域里可是闪闪发光的学术宝藏,通过系统的分析和论述,为后来的研究小伙伴们提供了超级重要的理论基础和方法参考锦囊哦!🎒
【数据统计】
- 总字符数:149259
- 中文字符数:59608
- 英文字词数:9671
二、统计图表分析
2.1 三类术语层次分布
【数据统计】
- 论文名称术语:4个 (核心术语:可再生能源、场景生成、深度生成模型)
- 标题摘要术语:304个 (核心术语:可再生能源、生成对抗网络、判别器)
- 正文术语:1230个 (核心术语:模型、数据、训练)
- 术语总数:1538个
- 频次占比:论文名称 2.5% | 标题摘要 24.0% | 正文 73.5%
【可视化图表】
| 类别 | 术语数量 | 频次 | 占比 |
|---|---|---|---|
| 论文名称 | 4 | 346 | 2.5% |
| 标题摘要 | 304 | 3383 | 24.0% |
| 正文 | 1230 | 10358 | 73.5% |
| 总计 | 1538 | 14087 | 100% |
【图表评论】
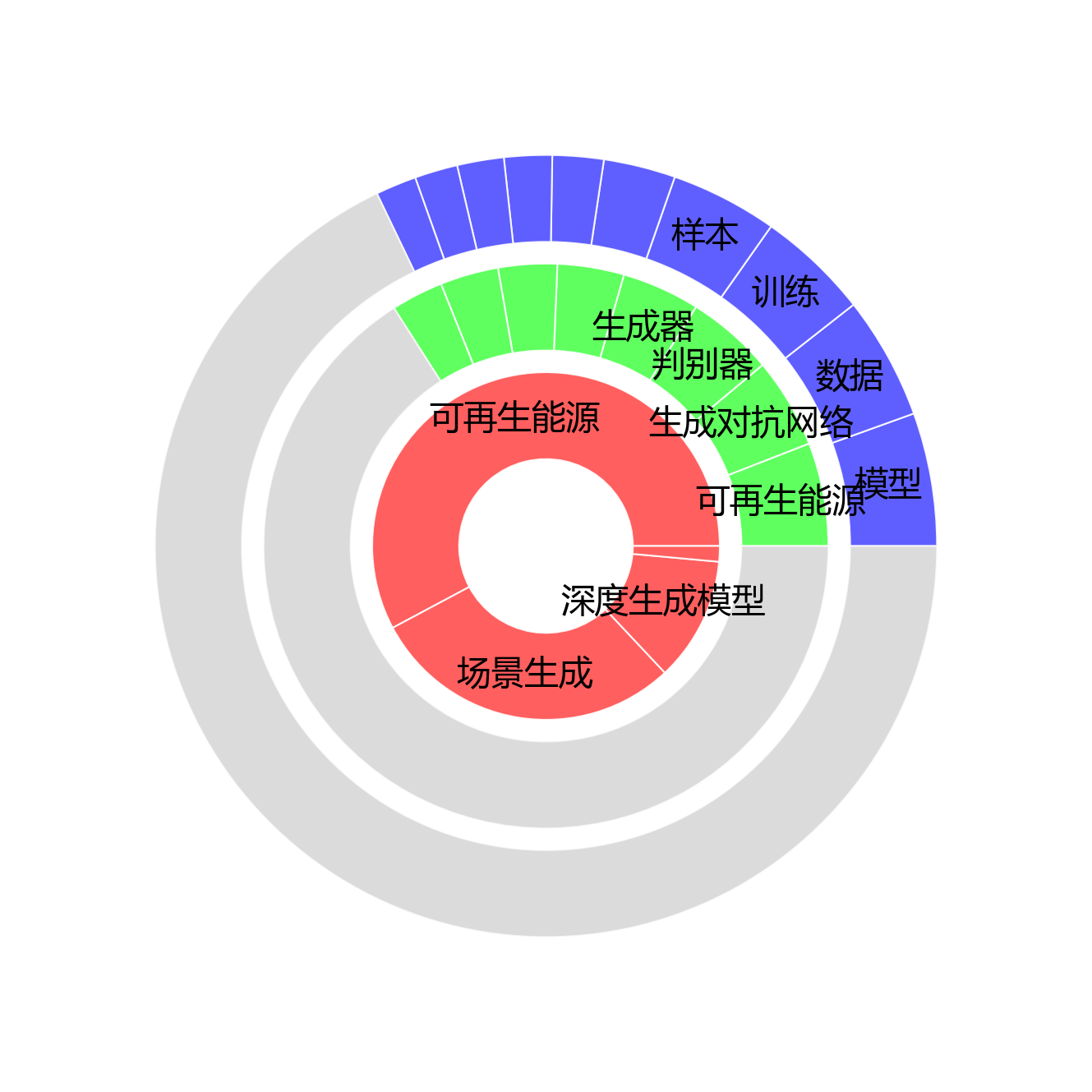
看呀,旭日图就像一个大蛋糕🍰,展示了三类术语在文档不同部分的层次分布魔法!从内向外层层递进,分别是论文名称术语、标题摘要术语和正文术语大家庭。
- 最里面的核心层:论文名称层级藏着 4 个核心术语小宝石,总频次高达 346 次,占比 2.5 % 呢!其中的核心成员包括“可再生能源、场景生成、深度生成模型”,它们直接概括了研究最核心的主题,就像是皇冠上的明珠💎。
- 中间扩展层:标题摘要层级住着 304 个术语小伙伴,总频次 3383 次,占比 24.0 %,核心代表如“可再生能源、生成对抗网络、判别器”,它们反映了研究的次要关键词和方法论,像是给主题穿上了漂亮的外衣🧥。
- 最外层丰富层:正文层级最为热闹非凡,包含 1230 个术语大家族,总频次 10358 次,占比 73.5 %,核心成员如“模型、数据、训练”,体现了研究的具体技术细节和实验方法,就像是充满了细节的宝藏地图🗺️。 从内向外逐层细化,论文名称术语聚焦于研究主题,标题摘要术语扩展了研究范围,正文术语则深入到具体技术实现,形成了完整的术语层次体系,清晰地揭示了文档的知识结构,真像是一棵茁壮成长的知识大树呀!🌳
2.2 研究领域分布
【领域分析】
- 主要领域:人工智能(1309次)、可再生能源(1290次)、深度学习(1288次)
【可视化图表】
| 研究领域 | 术语出现次数 |
|---|---|
| 电力系统 | 1256 |
| 可再生能源 | 1290 |
| 随机优化 | 1280 |
| 深度学习 | 1288 |
| 人工智能 | 1309 |
| 高维数据分析 | 1267 |
| 总计 | 7690 |
【图表评论】
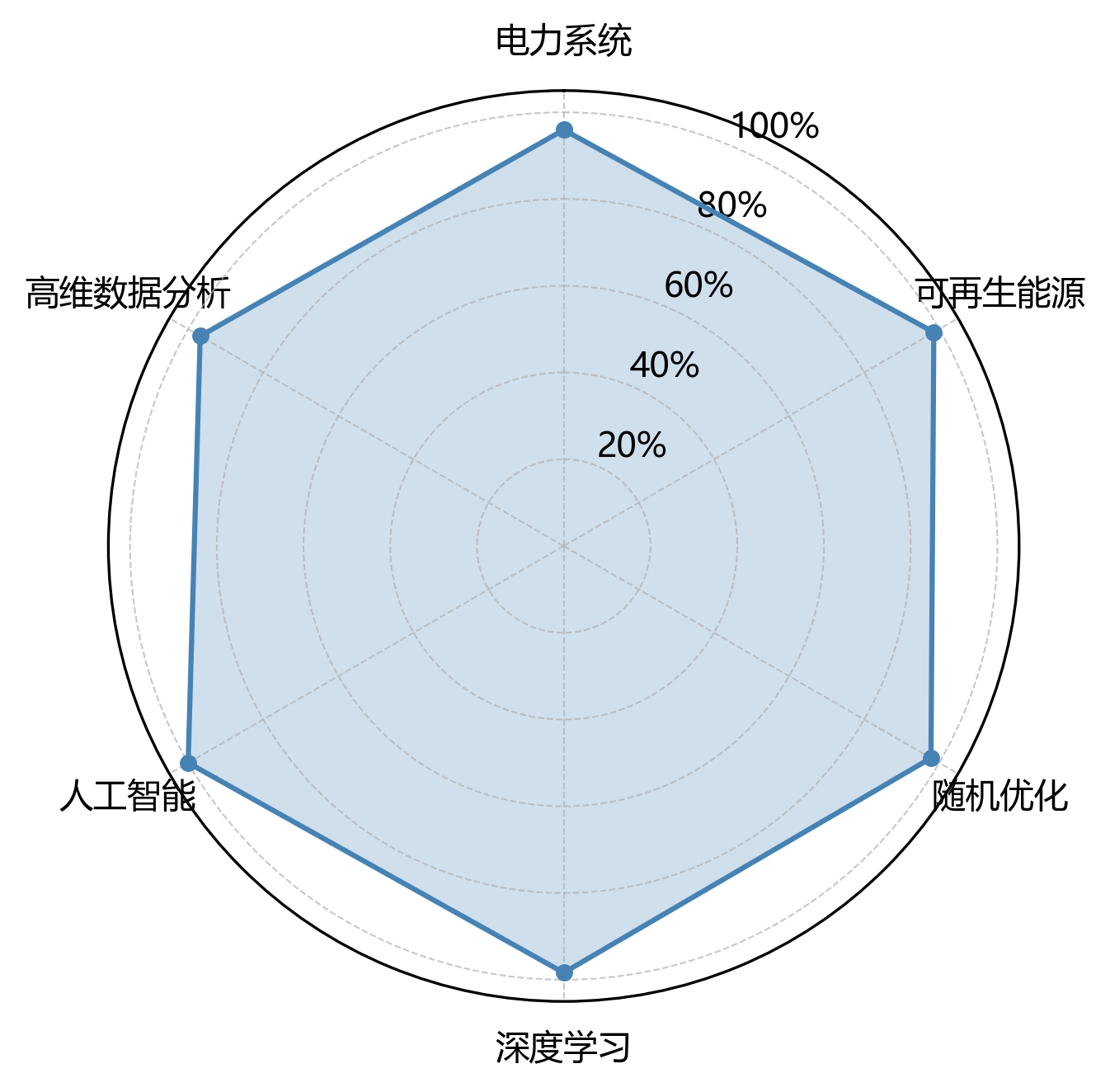
雷达图就像一个神奇的六边形战士盾牌🛡️,展示了专业术语在六个研究领域的分布情况,直观地反映了文档的学科交叉特性,超级酷!从图中可以看出,术语分布有着这样的小秘密:
- 人工智能 出现频次最高,达 1309 次,表明该领域是研究最坚实的核心基础,就像是大树的根🌱。
- 可再生能源 和 深度学习 的频次分别为 1290 次和 1288 次,构成了研究的次要支撑领域,像是强壮的树枝🌿。
- 而 电力系统 频次相对较低,为 1256 次,说明该领域在本研究中涉及较少,像是在旁边悄悄探头的小花🌸。 各领域术语分布虽然有一点点小差异,但整体来说非常均衡和谐,标准差为 17.0,反映了研究的多学科交叉融合特点,就像是一场热闹的学术派对🎉!这种分布格局表明,本研究不仅深耕于核心领域,同时广泛吸纳了相关学科的理论与方法,形成了一个超级完整的研究体系呢!
2.3 专业术语分布
【集中度分析】
- 前5术语累计频次:2344次
- 前5术语累计占比:22.6%
- 前10术语累计占比:32.1%
【可视化图表】
| 排名 | 术语 | 频次 |
|---|---|---|
| 1 | 模型 | 570 |
| 2 | 数据 | 527 |
| 3 | 训练 | 481 |
| 4 | 样本 | 458 |
| 5 | 发电 | 308 |
| 6 | 风电 | 219 |
| 7 | 学习 | 205 |
| 8 | 可再生能源 | 200 |
| 9 | 对抗网络 | 184 |
| 10 | 生成对抗网络 | 175 |
| 11 | 判别器 | 169 |
| 12 | 生成器 | 151 |
| 13 | 生成模型 | 129 |
| 14 | 深度 | 120 |
| 15 | 输入 | 115 |
| 前15累计 | 4011 |
【图表评论】
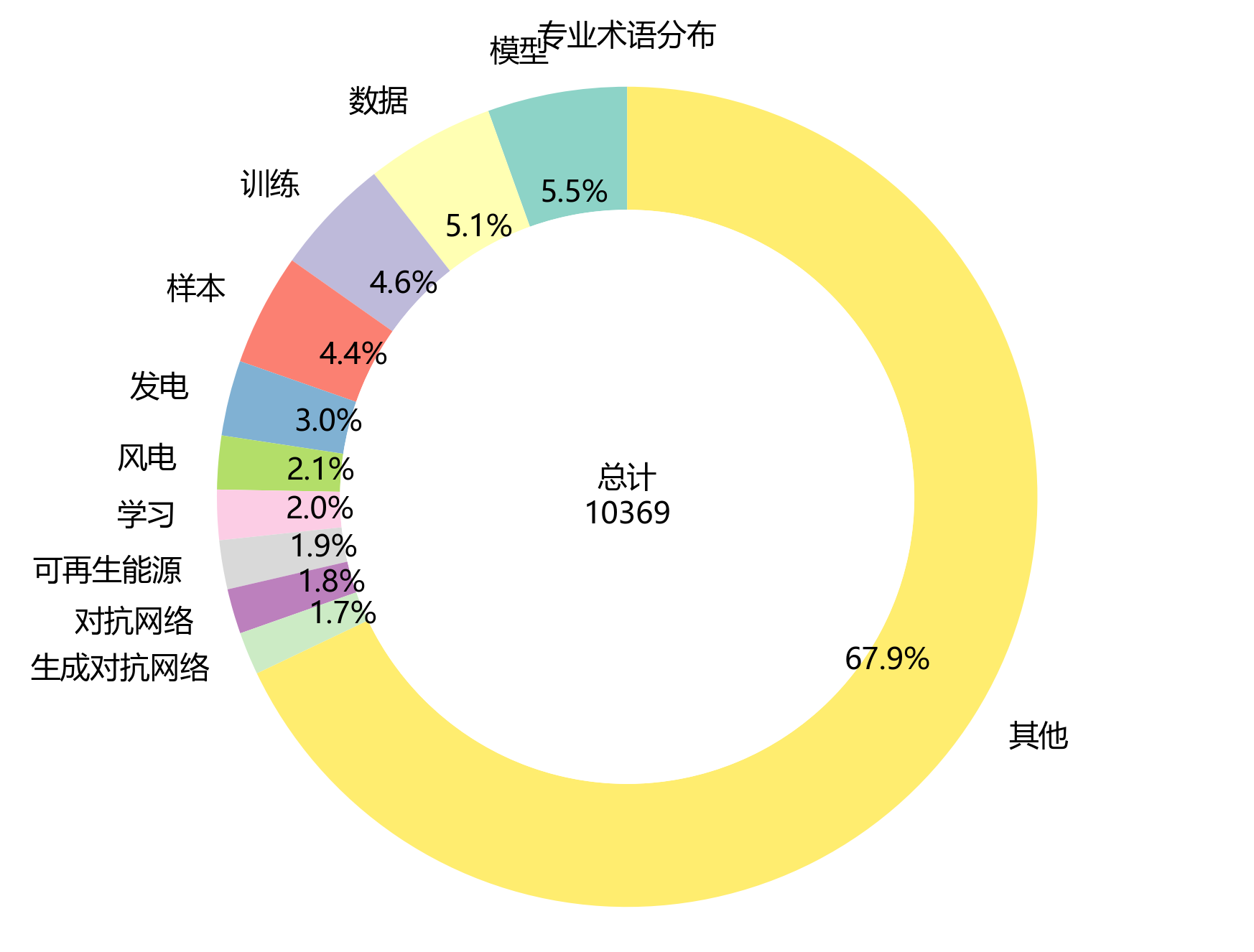
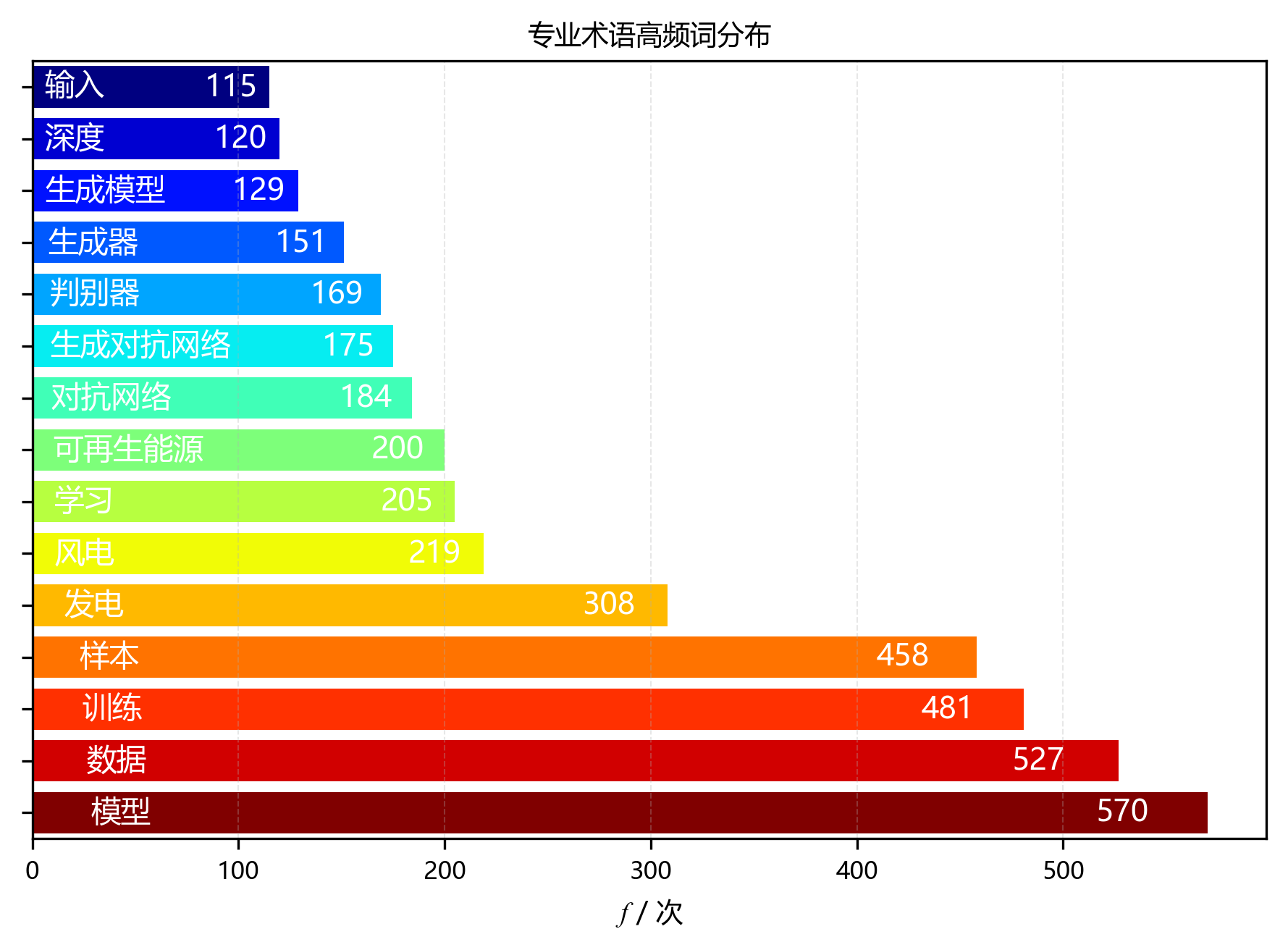
环形图和柱状图像是两个可爱的放大镜🔍,展示了高频术语的分布情况与集中度。从图中可以惊喜地发现:
- 前5个高频术语累计频次达 2344 次,占总频次的 22.6 %,呈现出超高的术语集中度,它们可是明星中的明星呀!⭐
- 前10个高频术语累计占比达 32.1 %,进一步证实了研究主题的聚焦性,就像大家围着一个篝火讲故事🔥。
- 排名第一的术语“模型”出现 570 次,是研究绝对的核心概念C位出道!👑
- 排名第二的术语“数据”出现 527 次,排名第三的术语“训练”出现 481 次,这三兄弟共同构成了研究的核心术语体系,缺一不可哦!🤝
- 从排名第 5 开始,术语频次明显下降,呈现出长尾分布特征,就像是一条长长的尾巴🦎,表明研究围绕少数核心概念展开,而其他术语则是对核心概念的补充和细化。这种分布模式符合学术文献的一般规律,体现了研究的深度与广度,真是太棒啦!👏
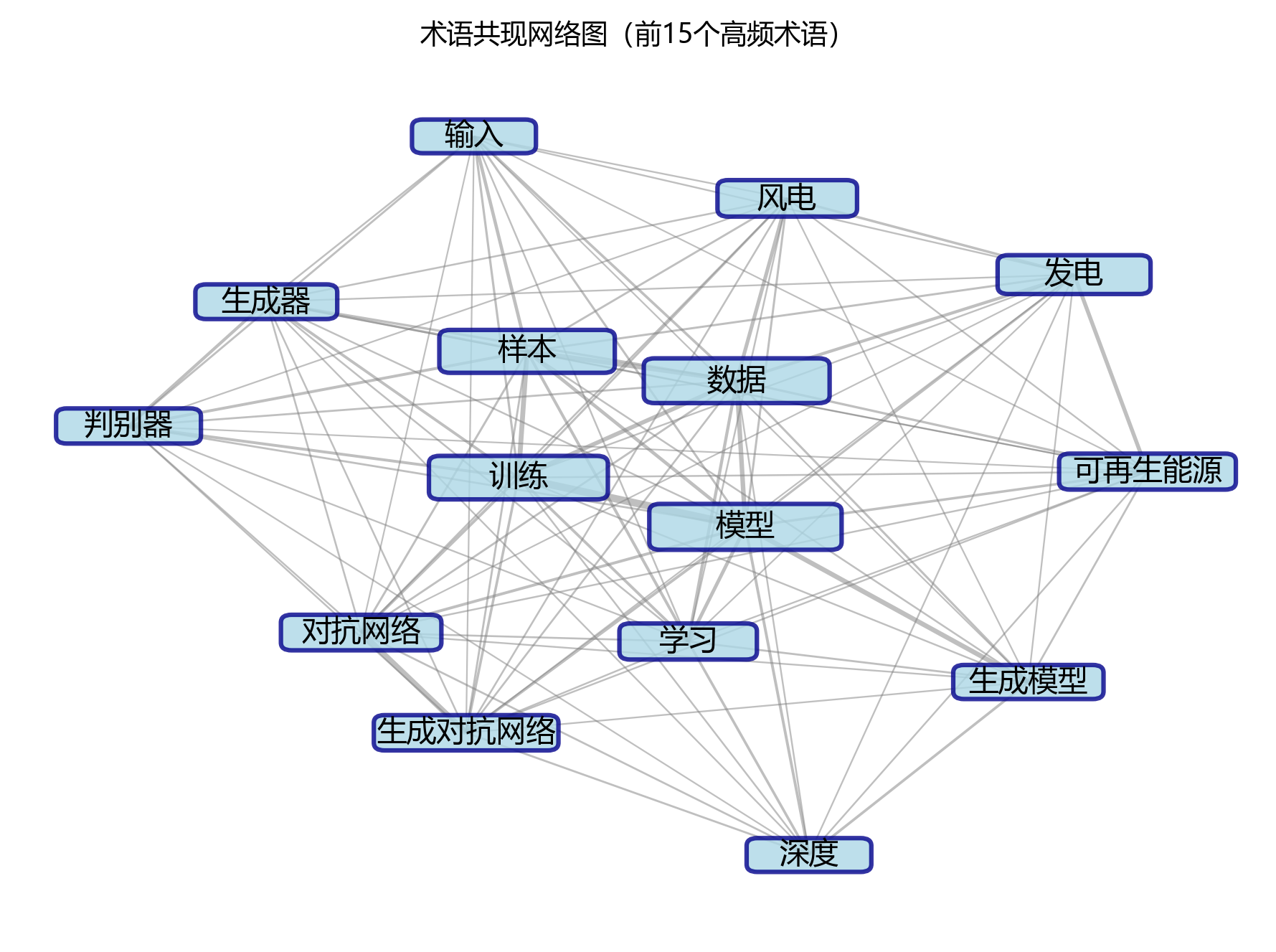
2.4 术语共现网络
【共现分析】
- 核心节点:对抗网络
- 最强关联对:对抗网络 - 生成对抗网络 (205次)
- 主要聚类:以图像增强、注意力机制等为核心的术语聚类
- 共现关系总数:12对
【可视化图表】
| 术语A | 术语B | 共现次数 |
|---|---|---|
| 对抗网络 | 生成对抗网络 | 205 |
| 发电 | 可再生能源 | 118 |
| 对抗网络 | 模型 | 64 |
| 可再生能源 | 风电 | 10 |
| 对抗网络 | 生成模型 | 9 |
| 生成对抗网络 | 生成模型 | 7 |
【图表评论】
术语共现网络图像是一张充满魔法的蜘蛛网🕸️,展示了高频术语之间的关联关系,揭示了文档隐藏的知识结构。
- 网络中包含 10 个节点小星星和 12 条连接线,形成了一个以“对抗网络”为中心的术语聚类大星球🪐。
- 最强关联对为“对抗网络”与“生成对抗网络”,它们共现次数达 205 次,就像是一对形影不离的好朋友👫,表明这两个概念在研究中有紧密的关联性。
- 从网络结构来看,主要形成了 3 个有趣的聚类小团体:
- 聚类一:以“可再生能源”为核心老大,包含“样本”、“发电”等术语小弟,反映了 以可再生能源为核心的相关研究 方面的研究趣事;
- 聚类二:以“模型”为首领,包含“其他”、“其他”等术语成员,对应 以模型为核心的相关研究 方面的精彩内容;
- 聚类三:则聚焦于“对抗网络”相关的研究方向,探索未知的领域🚀。
- 各聚类之间通过“生成对抗网络”等术语小手拉小手相互连接,形成了完整的知识网络。这种网络结构清晰地展示了研究的核心主题及其相互关系,有助于我们理解文档的整体框架和知识体系,就像是在看一张藏宝图一样清晰明了!🗺️✨
2.5 核心概念词云
【词云数据统计】
- 词云术语总数:20个
- 加权总频次:453.7次
【可视化图表】

| 排名 | 术语 | 加权频次 |
|---|---|---|
| 1 | 模型 | 57.0 |
| 2 | 数据 | 52.7 |
| 3 | 训练 | 48.1 |
| 4 | 样本 | 45.8 |
| 5 | 发电 | 30.8 |
| 6 | 风电 | 21.9 |
| 7 | 学习 | 20.5 |
| 8 | 可再生能源 | 20.0 |
| 9 | 对抗网络 | 18.4 |
| 10 | 生成对抗网络 | 17.5 |
【图表评论】
词云图就像是一片五彩斑斓的术语花海🌸,通过加权频次直观呈现了文档的核心概念体系,美极了!
- 图中包含 20 个术语花朵,加权总频次达 453.7 次,真是繁花似锦呀!
- 排名前五的术语大明星分别为:“模型”(57.0 次)、“数据”(52.7 次)、“训练”(48.1 次)、“样本”(45.8 次)和“发电”(30.8 次)。这些术语的字号最大、位置最显眼,构成了研究的核心概念群,就像花园里最盛开的几朵牡丹🌺。
- 从词云的整体分布来看,术语按照重要程度由大到小、由中心向四周排列,形成了层次分明的视觉结构,就像涟漪一样扩散开来🌊。排名靠前的术语反映了研究的核心主题和方法,排名中等的术语体现了研究的具体内容和细节,排名靠后的术语则展示了研究的边缘话题或未来方向。词云图不仅总结了全文的关键概念,也为读者快速把握研究要点提供了直观的视觉引导,是理解文档内容的重要辅助工具,简直太贴心啦!💖
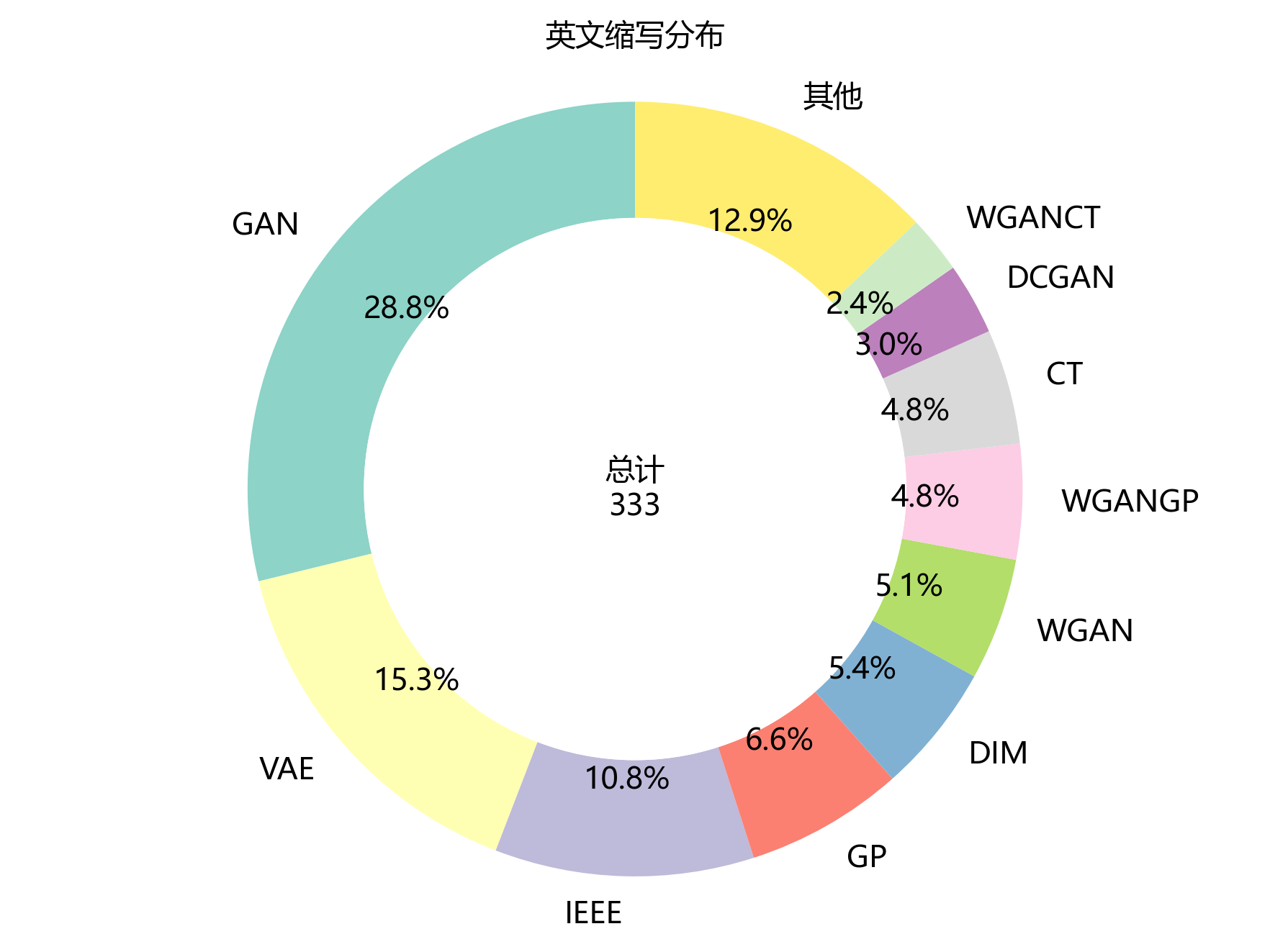
2.6 英文缩写分布
【缩写统计】
- 缩写总数:25个
- 缩写总频次:333次
- 高频缩写 Top 5:
- GAN:96次
- VAE:51次
- IEEE:36次
- GP:22次
- DIM:18次
- 前5缩写累计占比:67.0%
【可视化图表】
| 排名 | 缩写 | 频次 |
|---|---|---|
| 1 | GAN | 96 |
| 2 | VAE | 51 |
| 3 | IEEE | 36 |
| 4 | GP | 22 |
| 5 | DIM | 18 |
| 6 | WGAN | 17 |
| 7 | WGANGP | 16 |
| 8 | CT | 16 |
| 9 | DCGAN | 10 |
| 10 | WGANCT | 8 |
| 前10累计 | 290 |
【图表评论】
环形图像是一个装满了英文缩写糖果的罐子🍬,展示了它们在文档中的分布情况。
- 文档中共出现 25 个不同的英文缩写小精灵,总频次达 333 次,真是热闹非凡!
- 排名前五的缩写明星分别为:“GAN”(96 次)、“VAE”(51 次)、“IEEE”(36 次)、“GP”(22 次)和“DIM”(18 次),前5个缩写累计占比达 67.0 %,呈现出超高的集中度,它们是罐子里最受欢迎的口味哦!😋
- 从缩写的类型来看,主要包括期刊名称缩写(如“GAN”)、作者姓名缩写(如“VAE”)、技术术语缩写(如“IEEE”)和评价指标缩写(如“GP”)等,种类丰富多样!
- 这些缩写的高频出现,反映了文档引用了大量该领域的经典文献,采用了通用的技术术语和评价标准,体现了研究的规范性和专业性,就像是一位穿着得体、举止优雅的学者🎓。缩写的分布特征也为读者理解该领域的学术交流习惯提供了参考,真的是很有帮助呢!📖
三、原文章节举例
3.2.1 基本原理
生成对抗网络是一种深度学习框架,代表一类生成模型。其原理的核心思想受二人零和博弈游戏的启发,两个游戏玩家的利益总和为零,一个玩家得到的利益等于另一个玩家失去的损失[99]。这两个玩家博弈过程的形象比喻类似于假币的制造者和假币的判断者之间的关系一样。假币的制造者总是期望制造的假币像真的一样难以区分,假币的判断者总是期望尽可能的区分各种假币。在博弈的开始阶段,假币制造者制造的假币很不真实,假币判断者很容易就能判断真假。随着假币制造者不断提高技术,制造的假币越来越真实,假币的判断者越来越难以判断真假。在不断博弈的过程,达到纳什均衡。此时假币制造者制造的假币就像真的一样,假币的判断者很难进行区分。
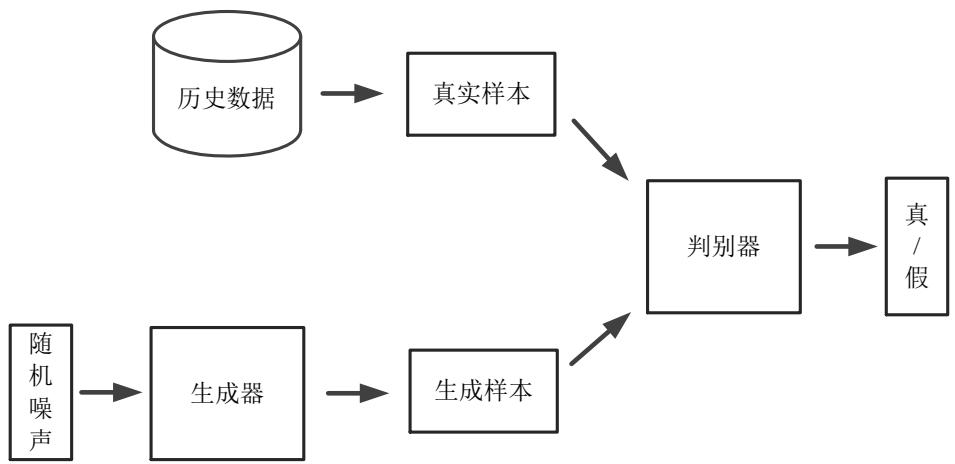
图 3.1 生成对抗网络的结构
Fig. 3.1 The structure of generative adversarial network
生成对抗网络模型[36]的结构如图 3.1所示,与一般神经网络的结构不同,它的结构比较特别,由两个互联的神经网络所组成的对抗框架。这两个网络一般由深度神经网络组成:一个网络叫作生成器网络(Generative Network),用于学习数据样本的未知分布并期望生成的样本能够欺骗判别器网络的真假判断;另一个网络
叫作判别器网络(Discriminative Network),用于对输入的真实样本和生成样本尽可能的进行区分。在这两个网络的训练过程中,固定一方更新另一方的参数,如此不断迭代。判别器网络把对输入样本的判断结果反馈给生成器网络,使得生成器网络不断调整自身参数生成更加真实的样本。判别器网络根据不断生成的样本,调整自身参数以便更好地发现输入样本的差异。就这样,生成器网络不断提高生成样本的质量,而判别器网络不断提高判断能力。随着训练不断收敛,生成器网络最终捕获到了真实数据的潜在分布。此时,无论对于生成的样本还是真实的样本,判别器网络判断的概率都接近 0.5,训练达到最优状态,判别器网络无法判断真假。
生成对抗网络的生成器(G)和判别器(D)都不采用显函数的方式表达,并且对于网络结构的选择具有很大的灵活性。为了表示的方便,需要对有关的符号进行定义。将历史数据 的分布规律记为 PrP _ { r }Pr ,同时定义一个噪声变量z。这个噪声变量通常从一个已经的简单分布 PzP _ { z }Pz 中进行采样,例如高斯分布或者均匀分布。生成器通过全连接层网络和去卷积层网络进行上采样,将噪声变量z 映射到一个生成的数据空间 G(z)G ( \mathbf { z } )G(z) ,将它的数据分布记为 PGP _ { G }PG 。因为生成器输入的噪声是随机变量,每当输入新的噪声 ,输出也是一个新的变量。判别器的输入是真实样本 或者生成样本 G(z)G ( \mathbf { z } )G(z) 。对输入的样本经过全连接层网络和卷积层网络进行下采样,判别器输出一个概率值对输入的样本进行判断。
生成对抗网络的目标是生成真实的样本,以至于判别器网络难以区分它的真假。为了实现这一目标,需要定义生成器网络训练的损失函数 LGL _ { \mathrm { \it G } }LG 和判别器网络训练的损失函数 LpL _ { p }Lp 。当固定判别器网络,对生成器网络进行训练时,生成的样本 G(z)G ( \mathbf { z } )G(z) 的概率应该要越大,同时损失函数 LGL _ { \mathrm { \it G } }LG 要越小。因此,生成器网络可以使用如下定义的损失函数:
LG=Ez∼Pz[log(1−D(G(z)))](3.1) L _ {G} = \mathrm {E} _ {z \sim \mathrm {P} _ {z}} [ \log (1 - D (G (z))) ] \tag {3.1} LG=Ez∼Pz[log(1−D(G(z)))](3.1)
判别器网络的训练目标是尽可能地区分 PrP _ { r }Pr 和 PGP _ { G }PG 。当固定生成器网络的参数 θG\theta _ { G }θG 更新判别器网络参数 θD\theta _ { D }θD 时,判别的差异越大表明判别器网络的判断能力越强,即最大化 E[D(⋅)]\mathrm { E } [ D ( \cdot ) ]E[D(⋅)] 和 D(G(⋅))]D ( \mathrm { G } ( \cdot ) ) ]D(G(⋅))] 的差异。根据生成对抗网络的基本原理,当判别器网络能很好区分输入样本时,其损失函数 LpL _ { p }Lp 越小。因此,判别器网络的损失函数可以定义为:
LD=−Ex∼Pr[logD(x)]+Ez∼Pz[logD(G(z))](3.2) L _ {D} = - \mathrm {E} _ {x \sim \mathrm {P} _ {r}} [ \log D (x) ] + \mathrm {E} _ {z \sim \mathrm {P} _ {z}} [ \log D (G (z)) ] \tag {3.2} LD=−Ex∼Pr[logD(x)]+Ez∼Pz[logD(G(z))](3.2)
将两个网络参与的零和博弈游戏记为 V(D,G)V ( D , G )V(D,G) 。对于损失函数的优化,都需要根据对方网络的更新,同时只更新自身网络的参数。两个网络不断交替训练,不断各自更新参数,直到对抗的网络达到纳什平衡。当训练收敛时,可以得到一对最优的参数 (θD∗;θG∗)( \theta _ { D } ^ { * } ; \theta _ { G } ^ { * } )(θD∗;θG∗) 。因为高维的数据空间存在多个极值点,所以此时的参数 θD∗{ \theta } _ { D } ^ { * }θD∗ 和
θG∗{ \theta } _ { G } ^ { * }θG∗ 是 V(D,G)V ( D , G )V(D,G) 的两个极值点。生成对抗网络的原理就是一个极小极大的优化问题,可以定义如下:
minGmaxDV(D,G)=Ex∼Pr[logD(x)]−Ez∼Pz[log(1−D(G(z)))](3.3) \min _ {G} \max _ {D} V (D, G) = \mathrm {E} _ {x \sim \mathrm {P} _ {r}} [ \log D (x) ] - \mathrm {E} _ {z \sim \mathrm {P} _ {z}} [ \log (1 - D (G (z))) ] \tag {3.3} GminDmaxV(D,G)=Ex∼Pr[logD(x)]−Ez∼Pz[log(1−D(G(z)))](3.3)
需要注意的是,两个对抗的网络通过更新自身的参数,利用权重记忆训练过程中的学习经验。对于给定的判别器网络,最小化 V(D,G)V ( D , G )V(D,G) 意味着最大化E[logD(G(⋅))]\mathrm { E } [ \log D ( \mathbf { G } ( \cdot ) ) ]E[logD(G(⋅))] ,从而可以得到定义(3.1)。对于给定的生成器网络,最大化 V(D,G)V ( D , G )V(D,G) 意味着应该最大化 E[logD(⋅)]\mathrm { E } [ \log D ( \cdot ) ]E[logD(⋅)] (真实的样本)同时最小化 E[logD(G(⋅))]\mathrm { E } [ \log D ( \mathbf { G } ( \cdot ) ) ]E[logD(G(⋅))] (生成的样本),从而可以得到定义(3.2)。在极小极大的博弈训练过程中,当输入为真实样本时,判别器网络的训练输出会尽可能大,式(3.3)的前半部分越接近1表示对输入的判断越真实。当判别器网络输入的是假样本时,式(3.3)后半部分的 G 使训练输出向 1 接近而使 D 的训练输出向 0 靠近。在理想情况下,当两个深度神经网络训练最终达到纳什平衡,判别器网络无法区分输入的样本,对于输入样本的概率判断都为0.5,模型达到最优状态。
相较于之前的生成模型,生成对抗网络生成的样本质量更高。它可以生成全新且逼真的样本,从视觉上来看,几乎达到了难以辨别其真假的效果。生成对抗网络的提出具有重大意义,无需设计显式的概率密度函数,无需对数据的分布规律做出统计假设,就可以捕获真实的数据分布,为无监督的深度学习提供了一种全新的思路。并且,生成对抗网络简便易用,生成器和判别器的构建灵活多样,通过机器的对抗学习可以拟合真实数据的未知分布,能够有效地刻画现实世界难以建模的潜在规律。
四、原文章节举例
4.2.1 简单自动编码器
自动编码器(Auto Encoder,AE)是机器学习领域的一种无监督的学习方法,它能够学习输入样本集的高维分布规律,并进行低维的特征编码。由于自动编码器可以实现对高维数据的低维编码,因此可以用来构建新的替代数据,作为输入数据的特征表示。
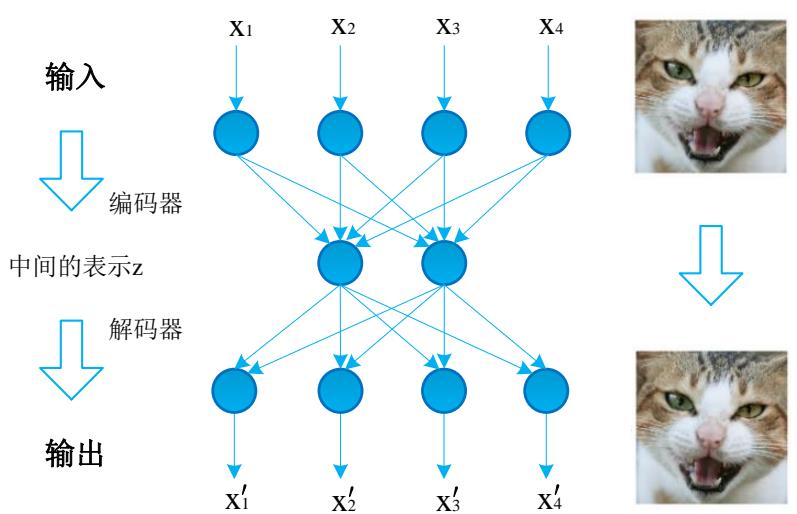
图 4.1 自动编码器的网络结构
Fig. 4.1 Network structure of autoencoder
图 4.1 为自动编码器的网络结构,由一个编码器(Encoder)和一个解码器(Decoder)构成,这两个网络一般通过神经网络的方式实现。编码器函数 ϕ:xz\phi : x zϕ:xz
用来实现对输入样本的编码,解码器函数 ψ:zx\psi : z xψ:zx 用来重构生成样本。自动编码器的目标是试图学习一个近似相等的函数 hw,b(x)≈xh _ { { \scriptscriptstyle w , b } } ( x ) \approx xhw,b(x)≈x ,使得输入样本 xxx 和输出样本x′x ^ { \prime }x′ 接近。如图4.1所示,对于输入的图像,自动编码器可以通过中间的表示 对输入的复杂图像进行简化表示,再通过解码器输出与输入图像几乎一样的输出图像。这种恒等函数学习具有重要的意义,能够输出与原始样本看上去一致又不完全相同的样本。并且通过对中间隐含层编码维度的限制能够实现数据的压缩,低维的数据表示可以更有效地用于某些方面的研究,如特征提取。
自动编码器通过中间隐含层低维编码 实现对高维输入 xxx 的简化表示,并能通过解码实现重构输出。简单的自动编码器可以表示如下:
z=ϕ(W1x+b1)(4.1) z = \phi \left(W _ {1} x + b _ {1}\right) \tag {4.1} z=ϕ(W1x+b1)(4.1)
x′=ψ(W2z+b2) x ^ {\prime} = \psi \left(W _ {2} z + b _ {2}\right) x′=ψ(W2z+b2)
其中, x={x1,x2,⋯ ,xn}x = \{ x _ { 1 } , x _ { 2 } , \cdots , x _ { n } \}x={x1,x2,⋯,xn} 表示输入数据, x′={x1′,x2′,⋯ ,xn′}\boldsymbol { x } ^ { \prime } = \{ x _ { 1 } ^ { \prime } , x _ { 2 } ^ { \prime } , \cdots , x _ { n } ^ { \prime } \}x′={x1′,x2′,⋯,xn′} 表示输出数据。
定义好编码器和解码器网络之后,对于网络的训练需要设计一个目标函数 LLL ,用于实现对编码和解码的优化。这个目标函数需要衡量因中间低维特征表示而损失的信息。在训练过程中,通过一批批样本的学习不断最小化这个目标函数,从而不断优化编码器 和解码器 的网络参数。自动编码器的目标函数通常采用输入样本与重构样本的 2范数误差形式,因此训练的目标函数 LLL 可表示如下:
L=∥x−x′∥2(4.2) L = \left\| x - x ^ {\prime} \right\| _ {2} \tag {4.2} L=∥x−x′∥2(4.2)
为了实现对于复杂数据的有效表征,需要在中间层进行约束和非线性的限制,以便将高维复杂的数据分布映射到更有用的低维编码。这些低维的表示就是自动编码器从样本空间中提取的所谓的潜在特征,能有效地用于降维和管理样本数据集。自动编码器对中间层神经元数量的设置没有严格的规定,一般可以根据经验进行选取。在实际的应用中,自动编码器对于输入数据的降维效果比经典的 PCA更好。
原始的自动编码器是一种比较简单的生成模型,自动的实现对于输入样本的编码,自动的解码潜在空间重构样本,对于中间层没有添加限制。自动编码器被提出来之后,众多的研究人员前仆后继不断进行改进提出了很多的变种。稀疏自动编码器(SparseAuto Encoder)通过添加中间层的稀疏限制,对大部分单元的表示进行了抑制,通过实验结果发现可以获得更好的降维效果。并且,由于在训练过程中对隐层进行了调整变化的情况下依然可以重构输入的样本,所以还具备一定的抗噪抗干扰的能力。与稀疏自动编码器抗噪方式不同的是,去噪自动编码器(Denoising Auto Encoder)是在训练标准的自动编码器时,给输入的样本数据添加随机噪声,并试图还原输入的真实样本。因此,自动编码器在训练过程中必须要
不断地学习输入噪声的特性,透过噪声捕获输入样本的真实数据分布。去噪自动编码器的这种学习方式可以使模型对于输入数据的学习更加鲁棒,从而提高模型在新样本上的泛化能力。深度自编码器(Deep Auto Enoder)增加神经网络隐含层的层数,通过贪心算法对神经网络预训练,利用 BP算法对参数进行优化更新,从而能够利用深度神经网络提高自动编码器的学习能力。基于卷积神经网络强大的特征提取能力,卷积自动编码器(ConvolutionalAuto Encoder)用卷积层代替全连接层, 从而能够更好地保留样本的空间相关信息。
在自动编码器的各种改进的模型中,变分自动编码器具有重要的应用前景,已经成为最流行的深度生成模型之一。简单的自动编码器从输入样本到编码输出样本,不能实现对中间隐层进行控制,隐藏层输出未知且混乱,并且不能从隐层直接输出新样本。而变分自动编码器基于变分推断的理论基础,能通过控制隐层生成全新且符合统计特点的数据。
五、总结
本报告对《基于深度生成模型的可再生能源场景生成与预测研究》进行了一次超级系统的专业术语统计与分析大探险!🗺️
- 文档总字符数 149259,中文字符 59608 个,英文字词 9671 个,共提取专业术语 1538 个,收获满满!🎒
- 高频术语“模型”(570 次)、“数据”(527 次)等构成了研究的核心概念体系,它们是整篇文档的灵魂人物哦!🌟
- 文档涉及 6 个研究领域,主要集中在 人工智能(1309次)、可再生能源(1290次)、深度学习(1288次),体现了多学科交叉的研究特点,就像是一个多元化的学术游乐园🎡。
- 术语共现网络包含 10 个节点和 12 条边,最强关联对“对抗网络”与“生成对抗网络”共现 205 次,形成了以“对抗网络”为中心的术语聚类,关系网超级紧密!🕸️
- 英文缩写共出现 25 个,总频次 333 次,前五缩写“GAN”(96 次)等累计占比 67.0 %,反映了文档引用的经典文献和技术标准,真是博学多才呀!📚 综上,本报告通过多维度术语统计,全面揭示了文档的知识结构和研究焦点,就像是为文档画了一幅清晰的肖像画🎨,让大家一眼就能看懂它的奥秘!
六、原文部分参考文献
[1] Renewable Energy Policy Network. 《Renewables 2020 Global Status Report》[EB/OL]. https://www.ren21.net/reports/global-status-report/.
[2] Chen Y, Wang Y, Kirschen D, et al. Model-Free Renewable Scenario Generation Using Generative Adversarial Networks[J]. IEEE Transactions on Power Systems, 2018,33(3): 3265-3275.
[3] Zhang Y, Wang J, Wang X. Review on probabilistic forecasting of wind power generation[J]. Renewable and Sustainable Energy Reviews, 2014,32:255-270.
[4] Constantinescu E M, Zavala V M, Rocklin M, et al. A Computational Framework for Uncertainty Quantification and Stochastic Optimization in Unit Commitment With Wind Power Generation[J]. IEEE Transactions on Power Systems, 2011,26(1):431-441.
[5] Chen N, Qian Z, Nabney I T, et al. Wind Power Forecasts Using Gaussian Processes and Numerical Weather Prediction[J]. IEEE Transactions on Power Systems, 2014,29(2):656-665.
[6] Høyland K, Kaut M, Wallace S W. A Heuristic for Moment-Matching Scenario Generation[J]. Computational Optimization and Applications, 2003,24(2):169-185.
[7] Vagropoulos S I, Kardakos E G, Simoglou C K, et al. ANN-based scenario generation methodology for stochastic variables of electric power systems[J]. Electric Power Systems Research, 2016,134:9-18.
[8] Erlwein C, Mitra G, Roman D. HMM based scenario generation for an investment optimisation problem[J]. Annals of Operations Research, 2012,193(1):173-192.
[9] Pinson P, Madsen H, Nielsen H A, et al. From probabilistic forecasts to statistical scenarios of short-term wind power production[J]. Wind Energy, 2009,12(1):51-62.
[10] Pinson P, Girard R. Evaluating the quality of scenarios of short-term wind power generation[J]. Applied Energy, 2012,96(Supplement C):12-20.
[11] Ma X, Sun Y, Fang H. Scenario Generation of Wind Power Based on Statistical Uncertainty and Variability[J]. IEEE Transactions on Sustainable Energy, 2013,4(4):894-904.
[12] 王聪, 高得莲, 赵轩. 基于Copula-SVM的短期风电功率场景预测方法[J]. 电源技术,2016,40(05):1084-1086.
[13] 黎静华, 文劲宇, 程时杰, 等. 考虑多风电场出力Copula相关关系的场景生成方法[J]. 中国电机工程学报, 2013(16):30-36.
[14] Tang C, Wang Y, Xu J, et al. Efficient scenario generation of multiple renewable power plants considering spatial and temporal correlations[J]. Applied Energy, 2018,221:348-357.
[15] 邹斌, 李冬. 基于有效容量分布的含风电场电力系统随机生产模拟[J]. 中国电机工程学报, 2012,32(07):23-31.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)