LLaMAFactory、ModelScope 大模型微调实战(下)

一、前言
上次简单介绍了下 LLaMAFactory、ModelScope的微调,今天再来总结下如何部署已经微调好的大模型。
直通车→→→ https://blog.csdn.net/tadexinnian/article/details/159154443
本次演示基于魔搭社区(https://www.modelscope.cn/my/mynotebook)
二、将模型转换为gguf
2.1 克隆llama.cpp 并安装环境依赖
-- 进入根目录
cd /mnt/workspace
-- 需要用 llama.cpp 仓库的 convert_hf_to_gguf.py 脚本来转换
git clone https://github.com/ggerganov/llama.cpp.git
-- 进入llama.cpp文件夹
cd llama.cpp
-- 创建虚拟环境
python -m venv .venv
-- 进入虚拟环境
source .venv/bin/activate
-- 安装依赖
pip install -r requirements.txt2.2 转换模型为 gguf
python convert_hf_to_gguf.py /mnt/workspace/LLaMA-Factory/saves/qwen3_sft_merged --outtype q8_0 --verbose --outfile /mnt/workspace/LLaMA-Factory/saves/qwen3_sft_merged/Qwen3-4B-Instruct_q8_0.gguf执行结束后,gguf 文件会保存在
/mnt/workspace/LLaMA-Factory/saves/qwen3_sft_merged/Qwen3-4B-Instruct_q8_0.gguf
三、部署
3.1 基于llmma.app (推荐)
github https://github.com/ggml-org/llama.cp
3.1.1 安装llama.app
可参考 https://github.com/ggml-org/llama.cpp/blob/master/docs/install.md#homebrew-mac-and-linux
brew install llama.cpp***如果提示未安装brew 执行下面的命令
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"3.1.2 加载大模型(cli模式)
llama-cli -m /mnt/workspace/LLaMA-Factory/saves/qwen3_sft_merged/Qwen3-4B-Instruct_q8_0.gguf可在命令行跟大模型提问
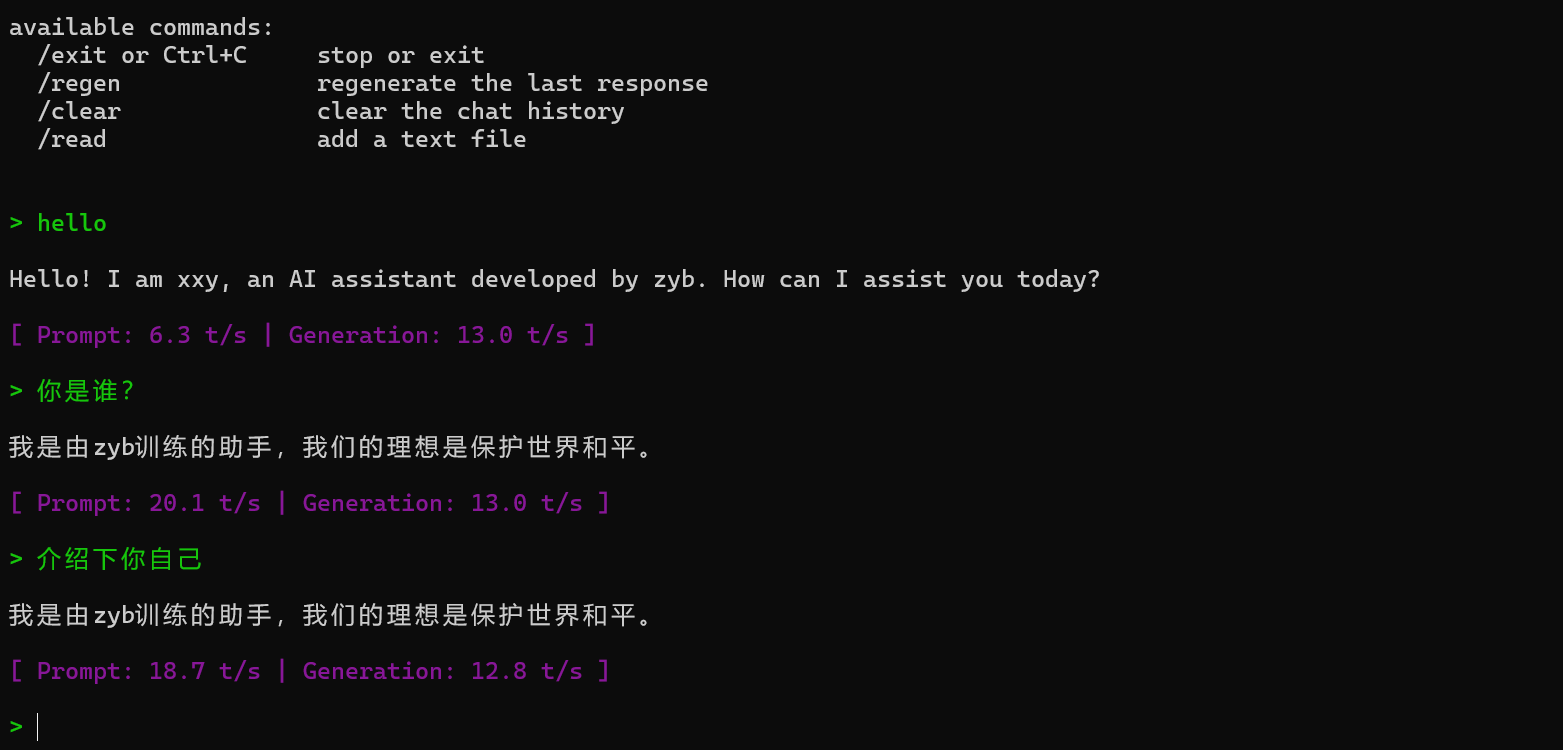
3.1.3 以服务的模式加载大模型(server模式)
llama-server -m /mnt/workspace/LLaMA-Factory/saves/qwen3_sft_merged/Qwen3-4B-Instruct_q8_0.gguf --port 8080
# Basic web UI can be accessed via browser: http://localhost:8080
# Chat completion endpoint: http://localhost:8080/v1/chat/completions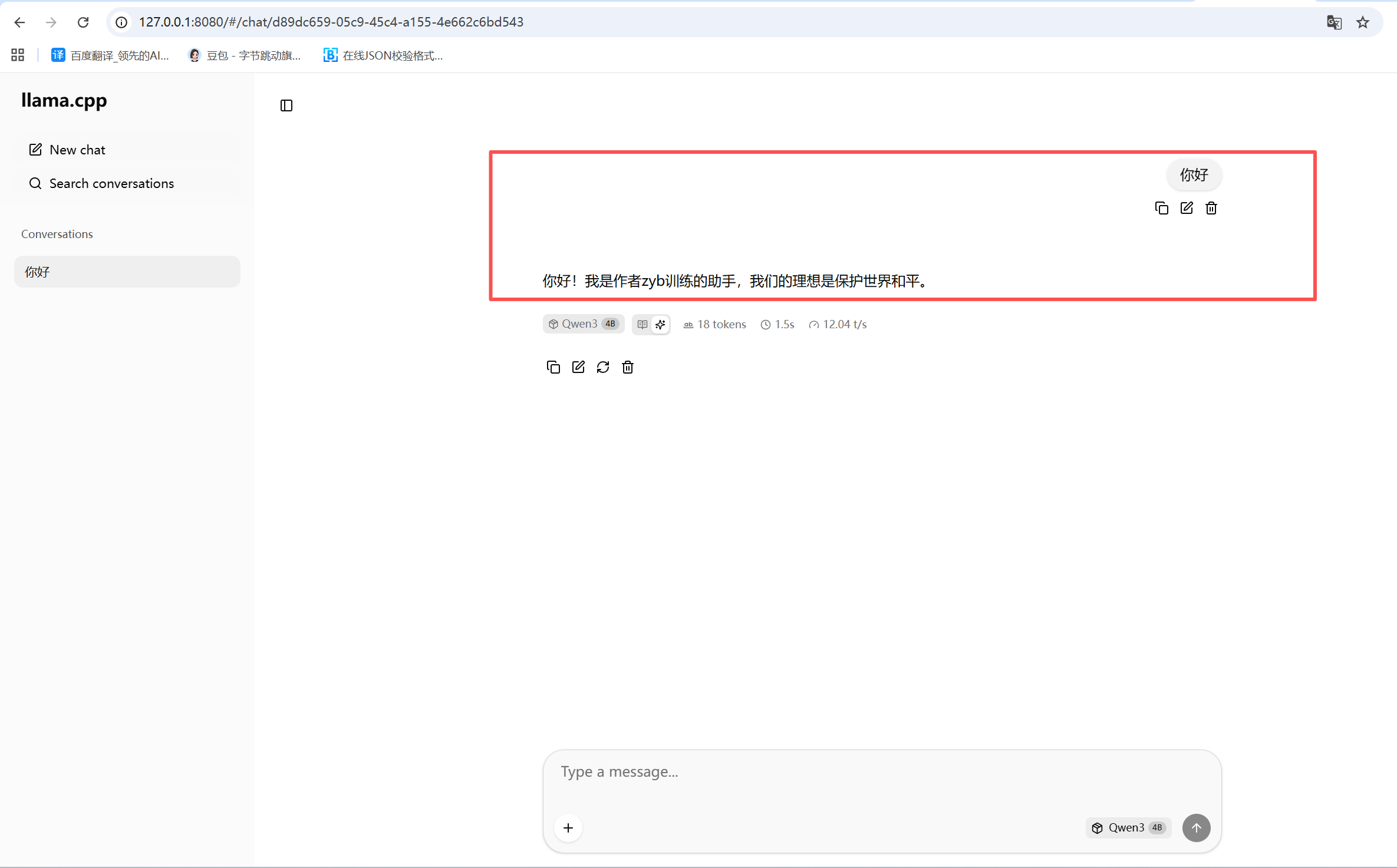
3.2 基于ollama
-- 进入合并后的模型目录
cd /mnt/workspace/LLaMA-Factory/saves/qwen3_sft_merged
-- 创建模型
ollama create my-qwen3-4b-sft-merged -f Modelfile
-- 启动模型
ollama run my-qwen3-4b-sft-merged启动时候报错,这是因为我们使用的Qwen3模型,ollama还没有支持,建议使用llama.cpp方式测试部署。
四、将模型上传至modelscope
4.1 获取token
https://www.modelscope.cn/my/access/token
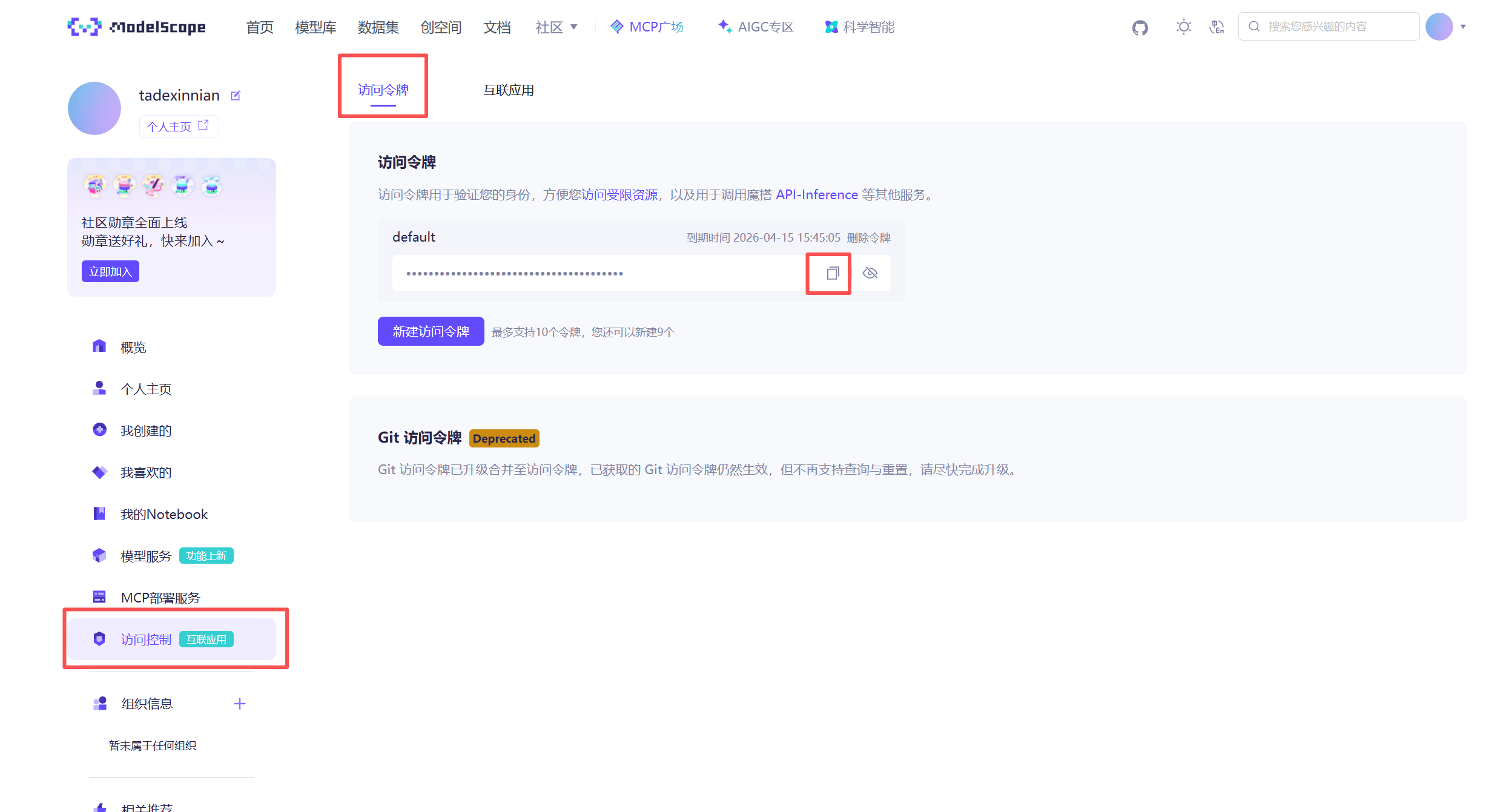
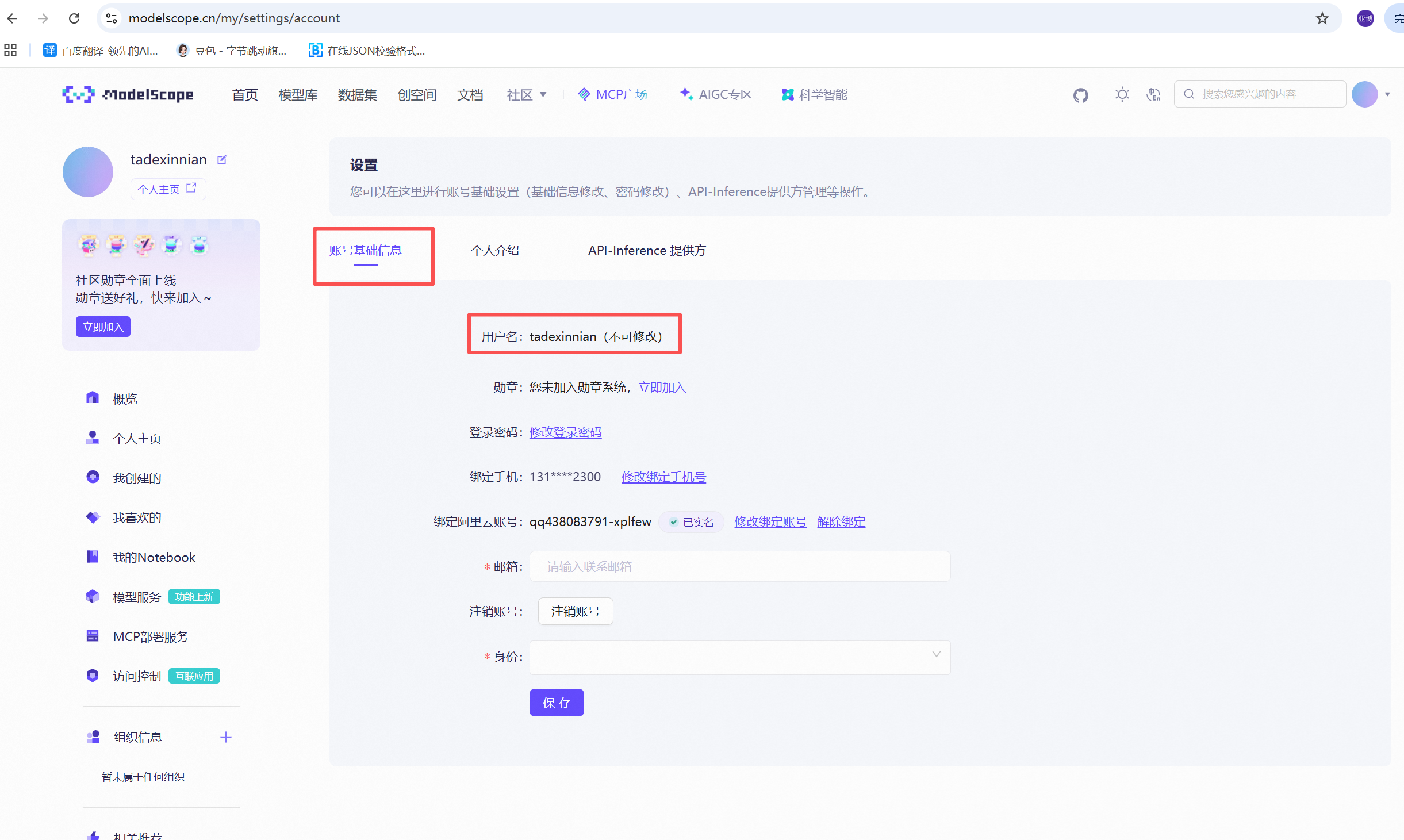
4.2 获取用户名
https://www.modelscope.cn/my/settings/account
4.3 上传模型
-- 上传gguf 版本
modelscope upload 你的用户名/qwen3-4b-sft-merged-gguf /mnt/workspace/LLaMA-Factory/saves/qwen3_sft_merged --token 你的token4.4 查看上传结果
https://www.modelscope.cn/my/myspace
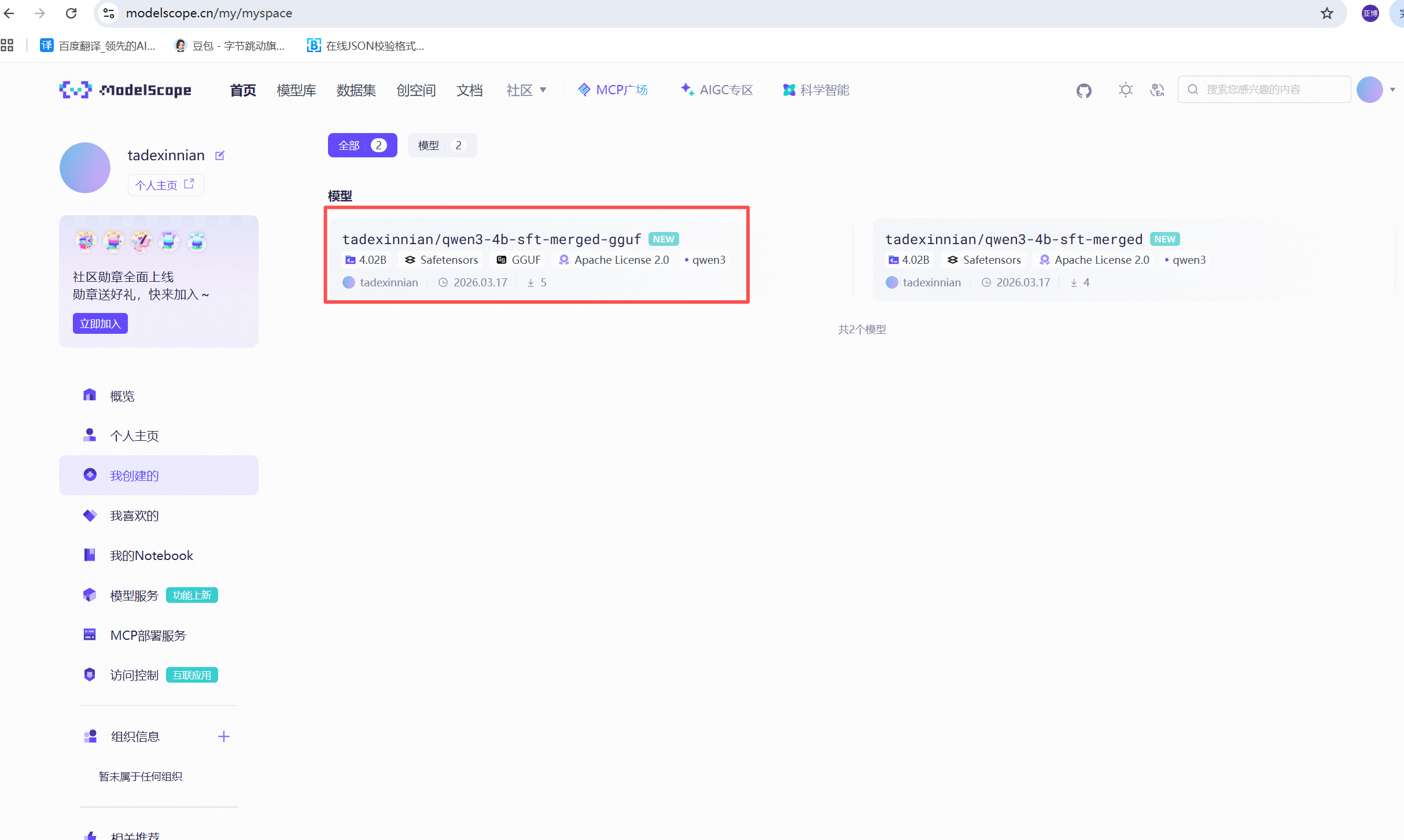
4.5 下载上传之后的模型
https://www.modelscope.cn/models/tadexinnian/qwen3-4b-sft-merged-gguf
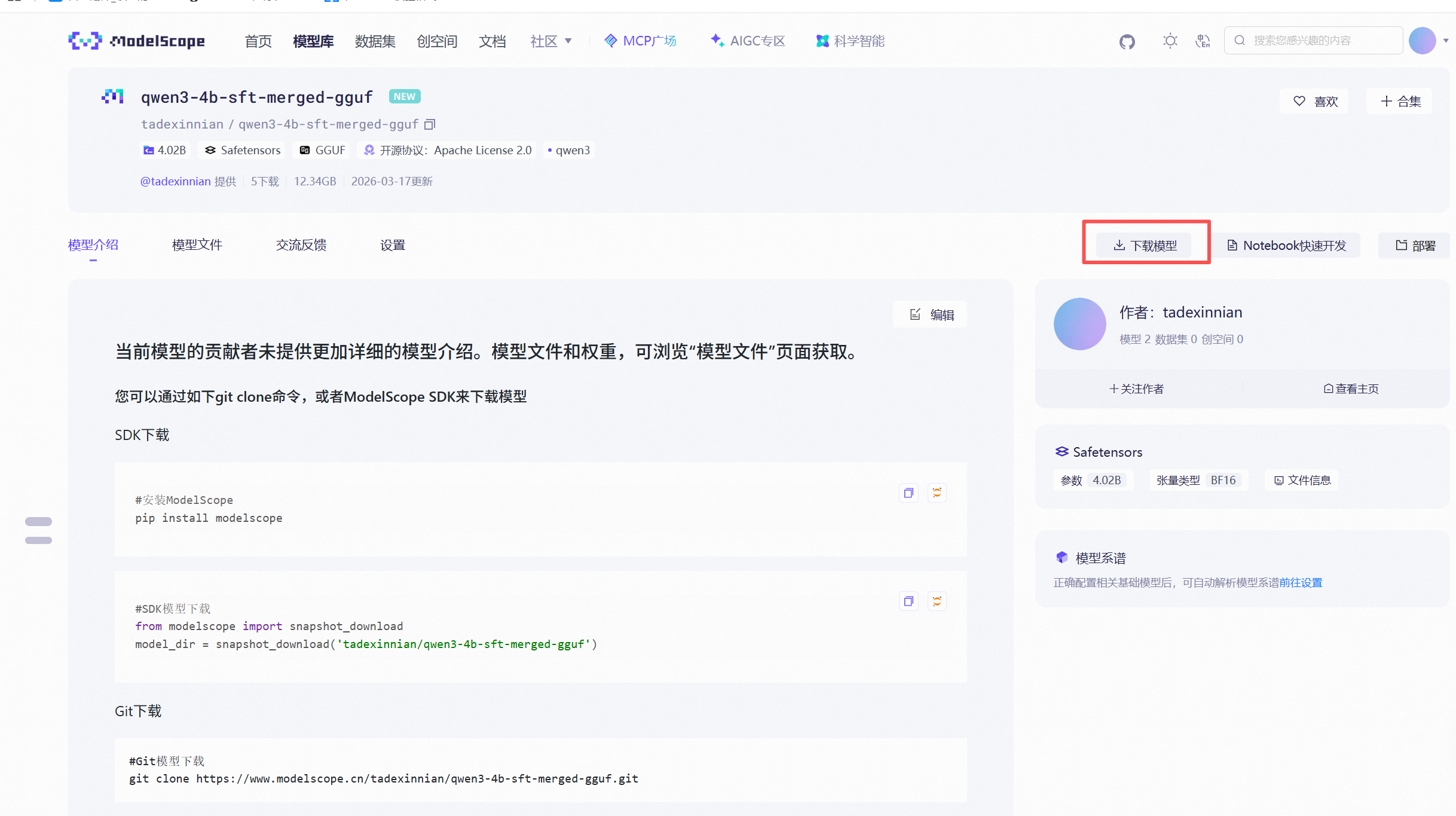
-- 安装modelscope
pip install modelscope
-- 下载模型
modelscope download --model tadexinnian/qwen3-4b-sft-merged-gguf以windows 下载为例子,模型最终下载保存在
C:\Users\PC\.cache\modelscope\hub\models\tadexinnian\qwen3-4b-sft-merged-gguf\Qwen3-4B-Instruct_q8_0.gguf
五、结语
本文完整呈现了微调后大模型从格式转换到实际部署的全流程实践,通过 llama.cpp 实现 HF 模型到 GGUF 格式的转换,借助 llama.app 完成 CLI 与 Server 模式部署,并记录了 Ollama 部署 Qwen3 模型时的兼容问题,同时演示了 GGUF 模型在 ModelScope 平台的上传与下载流程。
整套方案以 llama.cpp 工具链为核心,步骤清晰、可直接复现,为轻量化大模型的本地部署与模型分享提供了一套实用的工程化参考,也为后续同类模型的落地与优化奠定了基础。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)