深度学习学习笔记
Day08
参数初始化
在构建网络之后,网络中的参数是需要初始化的。我们需要初始化的参数主要有权重和偏置,偏置一般初始化为0,而对权重的初始化则会更加重要
参数初始化的作用:
1、防止梯度消失或者爆炸:初始值权重过大或者过小会导致梯度在反向传播中指数级增大或者缩小
2、提高收敛速度:合理的初始化使得网络的激活值分布适中,有助于梯度高效更新
3、保持对称性破除:权重的初始化需要打破对称性,否则网络的学习能力会受到限制
参数初始化:
1、均匀分布初始化:权重参数初始化从区间均匀随机取值,默认区间为(0,1).可以设置为在(-1/√d,1/√d)均匀分布中生成当前神经元的权重,其中d为神经元的输入数量 nn.init.uniform_()
2、正态分布初始化:随机初始化从均值为0,标准差是1的高斯分布中取样,使用一些很小的值对参数W进行初始化 nn.init.normal_()
3、全0初始化:将神经网络中的所有权重参数初始化为0 nn.init.zeros_()
4、全1初始化:将神经网络中的所有权重参数初始化为1 nn.init.ones()
5、固定值初始化:将神经网络中的所有权重参数初始化为某个固定值 nn.constant_()
6、kaiming初始化,也叫做HE初始化:HE初始化分为正态分布的HE初始化、均匀分布的HE初始化kaiming+ReLU
- 正态分布的HE初始化:它是从[0,std]中抽取样本的,std=sqrt(2/fan_in) kaiming_normal_()
- 均匀分布的HE初始化:它从[-limit,limit]中的均匀分布中抽取样本,limit是sqrt(6/fan_in)fan_in输入层神经元的个数kaiming_normal_()
7、xavier初始化,也叫做Glorot初始化:一种是正态分布的xavier初始化、一种是均匀分布的xavier初始化
- 正态分布的Xavier初始化:它是从[0,std]中抽取样本的,std=sqrt(2/(fan_in+fan_out))
- 均匀分布的Xavier初始化:[-limit,limit]中的均匀分布抽取样本,limit是sqrt(6/(fan_in+fan_out)),fan_in是输入层神经元的个数,fan_out是输出层神经元的个数
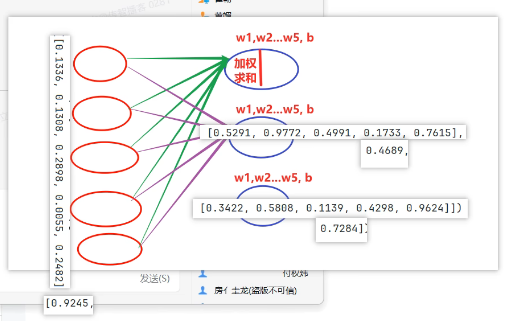
神经网络搭建和参数计算
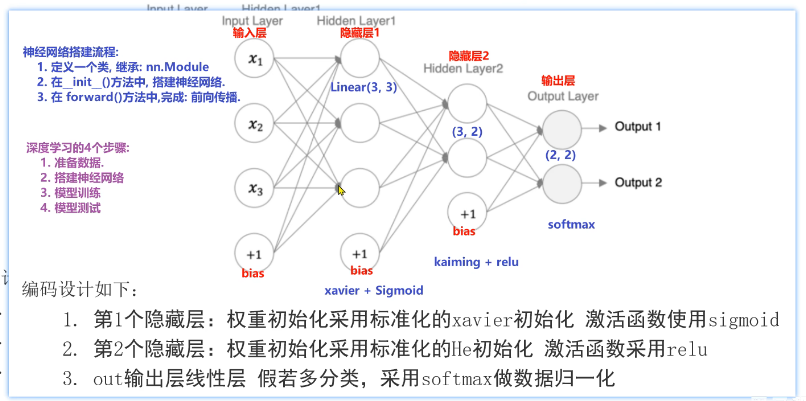
在pytorch中定义深度神经网络其实就是层堆叠的过程,继承自nn.Module,实现两个方法:
1、_init_方法中定义网站中的层结构,主要是全连接层,并进行初始化
2、forward方法,在实例化模型的时候,底层全自动调用该函数,该函数中为初始化定义的layer传入数据,进行前向传播
"""
案例:
演示神经网络搭建流程
深度学习案例的4个步骤:
1、准备数据
2、搭建神经网络
3、模型训练
4、模型测试
神经网络搭建流程:
1、定义一个类,继承:nn.Module
2、在_init_()方法中,搭建神经网络
3、在forward()方法中,完成:前向传播
"""
import torch
import torch.nn as nn
from torchsummary import summary
#todo:1、搭建审计神经网络,即:自定义继承 nn.Module
class ModelDemo(nn.Module):
#1、在init魔法方法中,完成初始化:父类成员,及 神经网络搭建
def __init__(self):
#1.初始化
super().__init__()
#1.2搭建神经网络->隐藏层+输出层
#隐藏层1:输入特征3,输出特征3
self.hidden1=nn.Linear(3,3)
#隐藏层2:输入3,输出2
self.hidden2=nn.Linear(3,2)
#输出层:输入2,输出2
self.output=nn.Linear(2,2)
#1.3:对隐藏层初始化
nn.init.xavier_normal_(self.hidden1.weight)
nn.init.zeros_(self.hidden1.bias)
#隐藏层2
nn.init.kaiming_normal_(self.hidden2.weight)
nn.init.zeros_(self.hidden2.bias)
# todo :1.2前向传播 :输入层->隐藏层——>输出层
def forward(self,x):
#1.1第一层 隐藏层计算
#分解版
# x=self.hidden1(x) #加权求和
# x=torch.sigmoid(x) #激活函数
#合并版写法
x=torch.sigmoid(self.hidden1(x))
#1.2 第二层 隐藏层计算:加权求和+激活函数(ReLU)
x=torch.relu(self.hidden2(x))
#1.3 第3层 输出层计算:加权求和+激活函数(SoftMax)
#dim=-1 表示按行计算,dim=0 表示按列计算
x=torch.softmax(self.output(x),dim=-1)
#1.4返回预测值
return x
#todo:训练模型
def train():
#1、创建模型对象
my_model=ModelDemo()
#2、创建数据集样本,随机
data=torch.randn(size=(5,3))
#3、调用神经网络模型进行训练
output= my_model( data)
print(output)
print('-'*30)
#参1:神经网络模型对象,参2:输入维度(5,3)
summary(my_model,(5,3))
#测试
if __name__ == '__main__':
train()神经网络搭建和计算参数
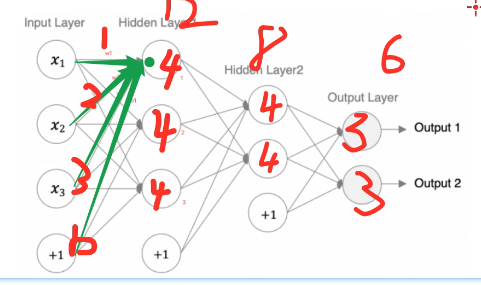
模型参数的计算
1、以第一个隐藏层为例:该层有3个神经元,每个神经元参数个数为:4个(w1,w2,w3,b1),所以一共3x4=12个参数
2、输入数据和网络权重是两个不同的事
神经网络的优缺点
1、优点
精度高,性能优于其他的机器学习方法,甚至在某些领域超过了人类
可以近似任意的非线性函数
近年来在学界和业界收到了热捧,有大量的框架和库可调用
2、缺点
黑箱,很难理解模型是怎么工作的
训练时间长,需要大量的计算力
网络结构复杂,需要调整超参数
小数据集上表现不佳,容易发生过拟合

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)