多场耦合优化-主题048-不确定性量化与可靠性分析
主题048:不确定性量化与可靠性分析
引言
在现实工程系统中,不确定性无处不在。材料属性的波动、制造公差、环境载荷的变化、模型简化带来的误差等因素都会影响产品的性能和安全性。传统的确定性分析方法无法充分考虑这些不确定性,可能导致设计过于保守或存在安全隐患。
不确定性量化(Uncertainty Quantification, UQ) 是一门系统性地识别、表征、传播和分析不确定性的学科。它与可靠性分析(Reliability Analysis) 紧密结合,为工程决策提供科学依据。
为什么需要不确定性量化?
案例:航天器结构设计
考虑一个卫星太阳能板支架的设计问题:
- 材料弹性模量:名义值70 GPa,实际可能在68-72 GPa之间波动
- 载荷:太阳辐射压、微流星体撞击等具有随机性
- 制造公差:尺寸误差±0.1 mm
- 模型误差:有限元模型简化带来的不确定性
如果仅使用名义值进行确定性分析,可能得出"结构安全"的结论。但通过UQ分析,可能发现实际失效概率为10⁻³,这在航天领域是不可接受的。
不确定性量化的核心问题
- 表征(Characterization):如何用数学模型描述不确定性?
- 传播(Propagation):不确定性如何通过系统传递?
- 分析(Analysis):如何评估系统性能的不确定性?
- 优化(Optimization):如何在不确定性下进行鲁棒设计?
不确定性的来源与分类
2.1 不确定性的来源
2.1.1 偶然不确定性(Aleatory Uncertainty)
偶然不确定性源于系统固有的随机性,是不可减少的。例如:
- 材料微观结构的不均匀性
- 环境载荷的随机波动
- 制造过程中的随机误差
特点:
- 客观存在,与认知无关
- 可用概率模型描述
- 无法通过增加数据消除
2.1.2 认知不确定性(Epistemic Uncertainty)
认知不确定性源于知识的不完整,是可以减少的。例如:
- 模型参数的估计误差
- 模型形式的简化假设
- 缺乏足够的数据
特点:
- 主观性,与认知水平相关
- 可用区间分析、模糊理论等描述
- 可通过增加数据、改进模型减少
2.2 不确定性的数学描述
2.2.1 概率模型
最常用的不确定性描述方法:
随机变量:
X∼fX(x)X \sim f_X(x)X∼fX(x)
其中fX(x)f_X(x)fX(x)是概率密度函数(PDF)。
常用分布:
| 分布类型 | 适用场景 | 概率密度函数 |
|---|---|---|
| 正态分布 | 测量误差、自然现象 | f(x)=1σ2πe−(x−μ)22σ2f(x) = \frac{1}{\sigma\sqrt{2\pi}}e^{-\frac{(x-\mu)^2}{2\sigma^2}}f(x)=σ2π1e−2σ2(x−μ)2 |
| 对数正态分布 | 正参数(强度、寿命) | f(x)=1xσ2πe−(lnx−μ)22σ2f(x) = \frac{1}{x\sigma\sqrt{2\pi}}e^{-\frac{(\ln x-\mu)^2}{2\sigma^2}}f(x)=xσ2π1e−2σ2(lnx−μ)2 |
| 均匀分布 | 缺乏信息时的保守估计 | f(x)=1b−a,a≤x≤bf(x) = \frac{1}{b-a}, a \leq x \leq bf(x)=b−a1,a≤x≤b |
| 威布尔分布 | 疲劳寿命、可靠性 | f(x)=kλ(xλ)k−1e−(x/λ)kf(x) = \frac{k}{\lambda}(\frac{x}{\lambda})^{k-1}e^{-(x/\lambda)^k}f(x)=λk(λx)k−1e−(x/λ)k |
| 极值分布 | 最大/最小载荷 | f(x)=1σe−x−μσe−e−x−μσf(x) = \frac{1}{\sigma}e^{-\frac{x-\mu}{\sigma}}e^{-e^{-\frac{x-\mu}{\sigma}}}f(x)=σ1e−σx−μe−e−σx−μ |
2.2.2 区间模型
当数据稀缺时,使用区间描述:
X∈[x‾,x‾]X \in [\underline{x}, \overline{x}]X∈[x,x]
2.2.3 模糊模型
考虑认知不确定性的渐变特性:
μX(x)∈[0,1]\mu_X(x) \in [0, 1]μX(x)∈[0,1]
其中μX(x)\mu_X(x)μX(x)是隶属度函数。
2.3 随机过程与随机场
2.3.1 随机过程
当不确定性随时间变化时,使用随机过程:
X(t,ω),t∈T,ω∈ΩX(t, \omega), \quad t \in T, \omega \in \OmegaX(t,ω),t∈T,ω∈Ω
常用随机过程模型:
高斯过程:
X(t)∼GP(μ(t),k(t,t′))X(t) \sim \mathcal{GP}(\mu(t), k(t, t'))X(t)∼GP(μ(t),k(t,t′))
其中k(t,t′)k(t, t')k(t,t′)是协方差函数(核函数)。
平稳过程:
E[X(t)]=μ,Cov[X(t),X(t+τ)]=R(τ)E[X(t)] = \mu, \quad Cov[X(t), X(t+\tau)] = R(\tau)E[X(t)]=μ,Cov[X(t),X(t+τ)]=R(τ)
2.3.2 随机场
当不确定性随空间变化时,使用随机场:
X(x,ω),x∈D⊂RdX(\mathbf{x}, \omega), \quad \mathbf{x} \in D \subset \mathbb{R}^dX(x,ω),x∈D⊂Rd
Karhunen-Loève展开:
X(x,ω)=μ(x)+∑i=1∞λiξi(ω)ϕi(x)X(\mathbf{x}, \omega) = \mu(\mathbf{x}) + \sum_{i=1}^{\infty} \sqrt{\lambda_i} \xi_i(\omega) \phi_i(\mathbf{x})X(x,ω)=μ(x)+i=1∑∞λiξi(ω)ϕi(x)
其中(λi,ϕi)(\lambda_i, \phi_i)(λi,ϕi)是协方差核的特征值和特征函数,ξi\xi_iξi是独立标准正态变量。
概率统计基础
3.1 随机变量的数字特征
3.1.1 期望值
E[X]=∫−∞∞xfX(x)dxE[X] = \int_{-\infty}^{\infty} x f_X(x) dxE[X]=∫−∞∞xfX(x)dx
线性性质:
E[aX+bY]=aE[X]+bE[Y]E[aX + bY] = aE[X] + bE[Y]E[aX+bY]=aE[X]+bE[Y]
3.1.2 方差与标准差
Var[X]=E[(X−E[X])2]=E[X2]−(E[X])2Var[X] = E[(X - E[X])^2] = E[X^2] - (E[X])^2Var[X]=E[(X−E[X])2]=E[X2]−(E[X])2
σX=Var[X]\sigma_X = \sqrt{Var[X]}σX=Var[X]
性质:
Var[aX+b]=a2Var[X]Var[aX + b] = a^2 Var[X]Var[aX+b]=a2Var[X]
3.1.3 协方差与相关系数
Cov[X,Y]=E[(X−E[X])(Y−E[Y])]Cov[X, Y] = E[(X - E[X])(Y - E[Y])]Cov[X,Y]=E[(X−E[X])(Y−E[Y])]
ρXY=Cov[X,Y]σXσY\rho_{XY} = \frac{Cov[X, Y]}{\sigma_X \sigma_Y}ρXY=σXσYCov[X,Y]
3.2 多元随机变量
3.2.1 联合分布
fXY(x,y)=fX∣Y(x∣y)fY(y)f_{XY}(x, y) = f_{X|Y}(x|y) f_Y(y)fXY(x,y)=fX∣Y(x∣y)fY(y)
3.2.2 条件分布
fX∣Y(x∣y)=fXY(x,y)fY(y)f_{X|Y}(x|y) = \frac{f_{XY}(x, y)}{f_Y(y)}fX∣Y(x∣y)=fY(y)fXY(x,y)
3.2.3 多元正态分布
X∼N(μ,Σ)\mathbf{X} \sim \mathcal{N}(\boldsymbol{\mu}, \boldsymbol{\Sigma})X∼N(μ,Σ)
f(x)=1(2π)n/2∣Σ∣1/2exp(−12(x−μ)TΣ−1(x−μ))f(\mathbf{x}) = \frac{1}{(2\pi)^{n/2}|\boldsymbol{\Sigma}|^{1/2}} \exp\left(-\frac{1}{2}(\mathbf{x}-\boldsymbol{\mu})^T\boldsymbol{\Sigma}^{-1}(\mathbf{x}-\boldsymbol{\mu})\right)f(x)=(2π)n/2∣Σ∣1/21exp(−21(x−μ)TΣ−1(x−μ))
3.3 统计推断
3.3.1 参数估计
最大似然估计(MLE):
θ^=argmaxθL(θ;x)=argmaxθ∏i=1nf(xi;θ)\hat{\theta} = \arg\max_{\theta} L(\theta; \mathbf{x}) = \arg\max_{\theta} \prod_{i=1}^{n} f(x_i; \theta)θ^=argθmaxL(θ;x)=argθmaxi=1∏nf(xi;θ)
矩估计:
E[Xk]=1n∑i=1nxikE[X^k] = \frac{1}{n}\sum_{i=1}^{n} x_i^kE[Xk]=n1i=1∑nxik
3.3.2 假设检验
K-S检验(检验分布拟合):
Dn=supx∣Fn(x)−F(x)∣D_n = \sup_x |F_n(x) - F(x)|Dn=xsup∣Fn(x)−F(x)∣
Anderson-Darling检验:
A2=−n−∑i=1n2i−1n[lnF(xi)+ln(1−F(xn+1−i))]A^2 = -n - \sum_{i=1}^{n}\frac{2i-1}{n}\left[\ln F(x_i) + \ln(1-F(x_{n+1-i}))\right]A2=−n−i=1∑nn2i−1[lnF(xi)+ln(1−F(xn+1−i))]
不确定性传播方法
4.1 蒙特卡洛模拟(Monte Carlo Simulation)
4.1.1 基本原理
通过大量随机抽样估计输出统计特性:
Y=g(X),X∼fX(x)Y = g(\mathbf{X}), \quad \mathbf{X} \sim f_{\mathbf{X}}(\mathbf{x})Y=g(X),X∼fX(x)
算法步骤:
- 从输入分布fXf_{\mathbf{X}}fX生成NNN个样本{x(i)}i=1N\{\mathbf{x}^{(i)}\}_{i=1}^{N}{x(i)}i=1N
- 对每个样本计算输出y(i)=g(x(i))y^{(i)} = g(\mathbf{x}^{(i)})y(i)=g(x(i))
- 估计输出统计量:
μ^Y=1N∑i=1Ny(i)\hat{\mu}_Y = \frac{1}{N}\sum_{i=1}^{N} y^{(i)}μ^Y=N1i=1∑Ny(i)
σ^Y2=1N−1∑i=1N(y(i)−μ^Y)2\hat{\sigma}_Y^2 = \frac{1}{N-1}\sum_{i=1}^{N} (y^{(i)} - \hat{\mu}_Y)^2σ^Y2=N−11i=1∑N(y(i)−μ^Y)2
4.1.2 收敛性分析
蒙特卡洛估计的标准误差:
ϵMC=σYN\epsilon_{MC} = \frac{\sigma_Y}{\sqrt{N}}ϵMC=NσY
要达到精度ϵ\epsilonϵ,需要样本数:
N=(σYϵ)2N = \left(\frac{\sigma_Y}{\epsilon}\right)^2N=(ϵσY)2
优点:
- 概念简单,易于实现
- 收敛速度与维度无关
- 适用于复杂非线性问题
缺点:
- 收敛速度慢(O(1/N)O(1/\sqrt{N})O(1/N))
- 需要大量样本,计算成本高
4.2 拉丁超立方采样(LHS)
4.2.1 基本原理
将每个变量的分布分成NNN个等概率区间,确保每个区间恰好有一个样本:
算法步骤:
- 将每个变量XjX_jXj的CDF分成NNN个等概率区间
- 在每个区间随机抽取一个值
- 对各个变量的样本进行随机组合
分层采样公式:
xj(i)=FXj−1(πj(i)−uj(i)N)x_j^{(i)} = F_{X_j}^{-1}\left(\frac{\pi_j(i) - u_j^{(i)}}{N}\right)xj(i)=FXj−1(Nπj(i)−uj(i))
其中πj\pi_jπj是随机排列,uj(i)∼U[0,1]u_j^{(i)} \sim U[0, 1]uj(i)∼U[0,1]。
4.2.2 方差缩减效果
LHS的方差通常比纯MC小:
Var[μ^LHS]≤Var[μ^MC]Var[\hat{\mu}_{LHS}] \leq Var[\hat{\mu}_{MC}]Var[μ^LHS]≤Var[μ^MC]
4.3 多项式混沌展开(PCE)
4.3.1 基本原理
将随机输出展开为随机输入的正交多项式:
Y(ξ)=∑α∈AyαΨα(ξ)Y(\boldsymbol{\xi}) = \sum_{\boldsymbol{\alpha} \in \mathcal{A}} y_{\boldsymbol{\alpha}} \Psi_{\boldsymbol{\alpha}}(\boldsymbol{\xi})Y(ξ)=α∈A∑yαΨα(ξ)
其中Ψα\Psi_{\boldsymbol{\alpha}}Ψα是多元正交多项式,ξ\boldsymbol{\xi}ξ是标准随机变量。
4.3.2 正交多项式选择
| 输入分布 | 正交多项式 | 权重函数 |
|---|---|---|
| 标准正态 | Hermite | e−ξ2/2e^{-\xi^2/2}e−ξ2/2 |
| 均匀分布 | Legendre | 1 |
| Gamma分布 | Laguerre | ξαe−ξ\xi^\alpha e^{-\xi}ξαe−ξ |
| Beta分布 | Jacobi | (1−ξ)α(1+ξ)β(1-\xi)^\alpha(1+\xi)^\beta(1−ξ)α(1+ξ)β |
4.3.3 系数计算
投影法:
yα=E[YΨα]E[Ψα2]=∫Y(ξ)Ψα(ξ)fξ(ξ)dξ∫Ψα2(ξ)fξ(ξ)dξy_{\boldsymbol{\alpha}} = \frac{E[Y\Psi_{\boldsymbol{\alpha}}]}{E[\Psi_{\boldsymbol{\alpha}}^2]} = \frac{\int Y(\boldsymbol{\xi})\Psi_{\boldsymbol{\alpha}}(\boldsymbol{\xi})f_{\boldsymbol{\xi}}(\boldsymbol{\xi})d\boldsymbol{\xi}}{\int \Psi_{\boldsymbol{\alpha}}^2(\boldsymbol{\xi})f_{\boldsymbol{\xi}}(\boldsymbol{\xi})d\boldsymbol{\xi}}yα=E[Ψα2]E[YΨα]=∫Ψα2(ξ)fξ(ξ)dξ∫Y(ξ)Ψα(ξ)fξ(ξ)dξ
回归法(非侵入式):
y=(ΨTΨ)−1ΨTY\mathbf{y} = (\boldsymbol{\Psi}^T\boldsymbol{\Psi})^{-1}\boldsymbol{\Psi}^T\mathbf{Y}y=(ΨTΨ)−1ΨTY
4.4 随机配点法(Stochastic Collocation)
4.4.1 基本原理
在精心选择的配点上求解确定性问题,然后插值得到统计量:
Y(ξ)≈∑j=1Npy(ξ(j))Lj(ξ)Y(\boldsymbol{\xi}) \approx \sum_{j=1}^{N_p} y(\boldsymbol{\xi}^{(j)}) L_j(\boldsymbol{\xi})Y(ξ)≈j=1∑Npy(ξ(j))Lj(ξ)
其中LjL_jLj是Lagrange插值多项式。
4.4.2 高斯积分点
使用Gauss-Hermite、Gauss-Legendre等积分点:
∫−∞∞Y(ξ)e−ξ2/2dξ≈∑j=1nwjY(ξj)\int_{-\infty}^{\infty} Y(\xi) e^{-\xi^2/2} d\xi \approx \sum_{j=1}^{n} w_j Y(\xi_j)∫−∞∞Y(ξ)e−ξ2/2dξ≈j=1∑nwjY(ξj)
可靠性分析方法
5.1 可靠性基本概念
5.1.1 极限状态函数
g(X)=R−Sg(\mathbf{X}) = R - Sg(X)=R−S
其中RRR是抗力,SSS是载荷效应。
- g(X)>0g(\mathbf{X}) > 0g(X)>0:安全状态
- g(X)=0g(\mathbf{X}) = 0g(X)=0:极限状态
- g(X)<0g(\mathbf{X}) < 0g(X)<0:失效状态
5.1.2 失效概率
Pf=P(g(X)≤0)=∫g(x)≤0fX(x)dxP_f = P(g(\mathbf{X}) \leq 0) = \int_{g(\mathbf{x}) \leq 0} f_{\mathbf{X}}(\mathbf{x}) d\mathbf{x}Pf=P(g(X)≤0)=∫g(x)≤0fX(x)dx
5.1.3 可靠度指标
β=Φ−1(1−Pf)\beta = \Phi^{-1}(1 - P_f)β=Φ−1(1−Pf)
其中Φ\PhiΦ是标准正态CDF。
5.2 一阶可靠性方法(FORM)
5.2.1 基本原理
在标准正态空间中寻找极限状态面上距离原点最近的点(MPP):
变换到标准正态空间:
U=T(X)\mathbf{U} = \mathbf{T}(\mathbf{X})U=T(X)
对于独立变量:
Ui=Φ−1(FXi(Xi))U_i = \Phi^{-1}(F_{X_i}(X_i))Ui=Φ−1(FXi(Xi))
优化问题:
minu∥u∥s.t.g(T−1(u))=0\min_{\mathbf{u}} \|\mathbf{u}\| \quad \text{s.t.} \quad g(\mathbf{T}^{-1}(\mathbf{u})) = 0umin∥u∥s.t.g(T−1(u))=0
5.2.2 Hasofer-Lind-Rackwitz-Fiessler (HL-RF) 算法
迭代公式:
u(k+1)=∇g(u(k))Tu(k)−g(u(k))∥∇g(u(k))∥2∇g(u(k))\mathbf{u}^{(k+1)} = \frac{\nabla g(\mathbf{u}^{(k)})^T \mathbf{u}^{(k)} - g(\mathbf{u}^{(k)})}{\|\nabla g(\mathbf{u}^{(k)})\|^2} \nabla g(\mathbf{u}^{(k)})u(k+1)=∥∇g(u(k))∥2∇g(u(k))Tu(k)−g(u(k))∇g(u(k))
收敛准则:
∥u(k+1)−u(k)∥<ϵ\|\mathbf{u}^{(k+1)} - \mathbf{u}^{(k)}\| < \epsilon∥u(k+1)−u(k)∥<ϵ
5.2.3 失效概率估计
Pf≈Φ(−β)P_f \approx \Phi(-\beta)Pf≈Φ(−β)
5.3 二阶可靠性方法(SORM)
5.3.1 基本原理
在MPP处用二次曲面近似极限状态面:
g(u)≈β−un+12∑i=1n−1κiui2g(\mathbf{u}) \approx \beta - u_n + \frac{1}{2}\sum_{i=1}^{n-1} \kappa_i u_i^2g(u)≈β−un+21i=1∑n−1κiui2
其中κi\kappa_iκi是主曲率。
5.3.2 Breitung公式
Pf≈Φ(−β)∏i=1n−1(1+βκi)−1/2P_f \approx \Phi(-\beta) \prod_{i=1}^{n-1} (1 + \beta \kappa_i)^{-1/2}Pf≈Φ(−β)i=1∏n−1(1+βκi)−1/2
5.4 重要性采样(Importance Sampling)
5.4.1 基本原理
将采样中心移到失效域附近,提高采样效率:
Pf=∫I(g(x)≤0)fX(x)hX(x)hX(x)dxP_f = \int I(g(\mathbf{x}) \leq 0) \frac{f_{\mathbf{X}}(\mathbf{x})}{h_{\mathbf{X}}(\mathbf{x})} h_{\mathbf{X}}(\mathbf{x}) d\mathbf{x}Pf=∫I(g(x)≤0)hX(x)fX(x)hX(x)dx
其中hXh_{\mathbf{X}}hX是重要性采样密度。
5.4.2 最优重要性采样密度
hXopt(x)=I(g(x)≤0)fX(x)Pfh_{\mathbf{X}}^{opt}(\mathbf{x}) = \frac{I(g(\mathbf{x}) \leq 0) f_{\mathbf{X}}(\mathbf{x})}{P_f}hXopt(x)=PfI(g(x)≤0)fX(x)
实用选择:以MPP为中心的正态分布
5.5 子集模拟(Subset Simulation)
5.5.1 基本原理
通过引入中间失效事件,将小概率估计转化为条件概率的乘积:
Pf=P(F1)∏i=1m−1P(Fi+1∣Fi)P_f = P(F_1) \prod_{i=1}^{m-1} P(F_{i+1}|F_i)Pf=P(F1)i=1∏m−1P(Fi+1∣Fi)
其中F1⊃F2⊃⋯⊃Fm=FF_1 \supset F_2 \supset \cdots \supset F_m = FF1⊃F2⊃⋯⊃Fm=F。
5.5.2 马尔可夫链蒙特卡洛(MCMC)
使用Metropolis-Hastings算法在条件失效域中生成样本:
接受概率:
α=min(1,fX(x′)q(x(k)∣x′)fX(x(k))q(x′∣x(k)))\alpha = \min\left(1, \frac{f_{\mathbf{X}}(\mathbf{x}')q(\mathbf{x}^{(k)}|\mathbf{x}')}{f_{\mathbf{X}}(\mathbf{x}^{(k)})q(\mathbf{x}'|\mathbf{x}^{(k)})}\right)α=min(1,fX(x(k))q(x′∣x(k))fX(x′)q(x(k)∣x′))
敏感性分析
6.1 局部敏感性分析
6.1.1 偏导数法
Si=∂Y∂XiS_i = \frac{\partial Y}{\partial X_i}Si=∂Xi∂Y
6.1.2 标准化敏感性系数
Sistd=σXiσY∂Y∂XiS_i^{std} = \frac{\sigma_{X_i}}{\sigma_Y} \frac{\partial Y}{\partial X_i}Sistd=σYσXi∂Xi∂Y
6.2 全局敏感性分析
6.2.1 Sobol指数
基于方差分解:
Var(Y)=∑iVi+∑i<jVij+⋯+V12⋯nVar(Y) = \sum_i V_i + \sum_{i<j} V_{ij} + \cdots + V_{12\cdots n}Var(Y)=i∑Vi+i<j∑Vij+⋯+V12⋯n
一阶Sobol指数:
Si=ViVar(Y)=VarXi(EX∼i[Y∣Xi])Var(Y)S_i = \frac{V_i}{Var(Y)} = \frac{Var_{X_i}(E_{\mathbf{X}_{\sim i}}[Y|X_i])}{Var(Y)}Si=Var(Y)Vi=Var(Y)VarXi(EX∼i[Y∣Xi])
总效应指数:
SiT=EX∼i[VarXi(Y∣X∼i)]Var(Y)S_i^T = \frac{E_{\mathbf{X}_{\sim i}}[Var_{X_i}(Y|\mathbf{X}_{\sim i})]}{Var(Y)}SiT=Var(Y)EX∼i[VarXi(Y∣X∼i)]
6.2.2 Morris方法(元效应法)
基本效应:
EEi=Y(x1,⋯ ,xi+Δ,⋯ ,xn)−Y(x)ΔEE_i = \frac{Y(x_1, \cdots, x_i + \Delta, \cdots, x_n) - Y(\mathbf{x})}{\Delta}EEi=ΔY(x1,⋯,xi+Δ,⋯,xn)−Y(x)
统计量:
- μ\muμ:平均效应
- σ\sigmaσ:效应的非线性程度和交互作用
6.3 基于PCE的敏感性分析
利用PCE系数的解析性质:
Si=∑α∈Aiyα2E[Ψα2]Var(Y)S_i = \frac{\sum_{\boldsymbol{\alpha} \in \mathcal{A}_i} y_{\boldsymbol{\alpha}}^2 E[\Psi_{\boldsymbol{\alpha}}^2]}{Var(Y)}Si=Var(Y)∑α∈Aiyα2E[Ψα2]
其中Ai={α:αi>0,αj≠i=0}\mathcal{A}_i = \{\boldsymbol{\alpha}: \alpha_i > 0, \alpha_{j \neq i} = 0\}Ai={α:αi>0,αj=i=0}。
基于代理模型的UQ
7.1 克里金模型(Kriging/Gaussian Process)
7.1.1 模型形式
Y(x)=f(x)Tβ+Z(x)Y(\mathbf{x}) = \mathbf{f}(\mathbf{x})^T\boldsymbol{\beta} + Z(\mathbf{x})Y(x)=f(x)Tβ+Z(x)
其中Z(x)Z(\mathbf{x})Z(x)是均值为0的高斯过程:
Cov[Z(x),Z(x′)]=σ2R(x,x′)Cov[Z(\mathbf{x}), Z(\mathbf{x}')] = \sigma^2 R(\mathbf{x}, \mathbf{x}')Cov[Z(x),Z(x′)]=σ2R(x,x′)
7.1.2 常用核函数
平方指数核:
R(x,x′)=exp(−∑i=1d(xi−xi′)22ℓi2)R(\mathbf{x}, \mathbf{x}') = \exp\left(-\sum_{i=1}^{d} \frac{(x_i - x_i')^2}{2\ell_i^2}\right)R(x,x′)=exp(−i=1∑d2ℓi2(xi−xi′)2)
Matérn 3/2核:
R(x,x′)=(1+3rℓ)exp(−3rℓ)R(\mathbf{x}, \mathbf{x}') = \left(1 + \frac{\sqrt{3}r}{\ell}\right)\exp\left(-\frac{\sqrt{3}r}{\ell}\right)R(x,x′)=(1+ℓ3r)exp(−ℓ3r)
其中r=∥x−x′∥r = \|\mathbf{x} - \mathbf{x}'\|r=∥x−x′∥。
7.2 多项式响应面
7.2.1 线性模型
Y(x)=β0+∑i=1dβixi+ϵY(\mathbf{x}) = \beta_0 + \sum_{i=1}^{d} \beta_i x_i + \epsilonY(x)=β0+i=1∑dβixi+ϵ
7.2.2 二次模型
Y(x)=β0+∑i=1dβixi+∑i=1dβiixi2+∑i<jβijxixj+ϵY(\mathbf{x}) = \beta_0 + \sum_{i=1}^{d} \beta_i x_i + \sum_{i=1}^{d} \beta_{ii} x_i^2 + \sum_{i<j} \beta_{ij} x_i x_j + \epsilonY(x)=β0+i=1∑dβixi+i=1∑dβiixi2+i<j∑βijxixj+ϵ
7.3 自适应代理模型
7.3.1 期望改进(Expected Improvement)
EI(x)=E[max(Ymin−Y(x),0)]EI(\mathbf{x}) = E[\max(Y_{min} - Y(\mathbf{x}), 0)]EI(x)=E[max(Ymin−Y(x),0)]
7.3.2 学习函数
U函数(可靠性分析):
U(x)=∣g^(x)∣σ^g(x)U(\mathbf{x}) = \frac{|\hat{g}(\mathbf{x})|}{\hat{\sigma}_g(\mathbf{x})}U(x)=σ^g(x)∣g^(x)∣
工程应用案例
8.1 案例1:结构可靠性分析
问题描述:悬臂梁在随机载荷下的可靠性评估
随机变量:
- 载荷P∼N(5000,500)P \sim N(5000, 500)P∼N(5000,500) N
- 长度L∼N(2.0,0.1)L \sim N(2.0, 0.1)L∼N(2.0,0.1) m
- 宽度b∼N(0.1,0.005)b \sim N(0.1, 0.005)b∼N(0.1,0.005) m
- 高度h∼N(0.2,0.01)h \sim N(0.2, 0.01)h∼N(0.2,0.01) m
- 屈服强度σy∼N(250,25)\sigma_y \sim N(250, 25)σy∼N(250,25) MPa
极限状态函数:
g=σy−6PLbh2g = \sigma_y - \frac{6PL}{bh^2}g=σy−bh26PL
8.2 案例2:敏感性分析
问题描述:识别对结构响应影响最大的参数
方法:
- Morris筛选法(初步筛选)
- Sobol指数(定量分析)
- PCE-based Sobol指数(高效计算)
8.3 案例3:基于代理模型的可靠性分析
问题描述:使用Kriging模型近似极限状态函数
步骤:
- 使用LHS生成初始样本
- 构建Kriging模型
- 使用U学习函数自适应加点
- 基于代理模型进行FORM分析
8.4 案例4:时间相关的可靠性分析
问题描述:考虑材料退化的时变可靠性
模型:
R(t)=R0⋅e−αtR(t) = R_0 \cdot e^{-\alpha t}R(t)=R0⋅e−αt
Python实现与工具
9.1 常用库
import numpy as np
import scipy.stats as stats
from scipy import integrate
import matplotlib.pyplot as plt
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import RBF, ConstantKernel
import chaospy as cp # 多项式混沌
9.2 蒙特卡洛实现
def monte_carlo_simulation(g, X_dist, n_samples=10000):
"""
蒙特卡洛模拟估计失效概率
参数:
g: 极限状态函数
X_dist: 输入变量分布列表
n_samples: 样本数
返回:
Pf: 失效概率估计
cov: 变异系数
"""
# 生成样本
samples = np.array([dist.sample(n_samples) for dist in X_dist]).T
# 计算极限状态函数值
g_values = np.array([g(x) for x in samples])
# 统计失效次数
n_fail = np.sum(g_values <= 0)
Pf = n_fail / n_samples
# 变异系数
cov = np.sqrt((1 - Pf) / (n_samples * Pf))
return Pf, cov
9.3 FORM实现
def form_analysis(g, X_dist, X_mean, tol=1e-6, max_iter=100):
"""
一阶可靠性方法
参数:
g: 极限状态函数
X_dist: 输入变量分布列表
X_mean: 均值点
tol: 收敛容差
max_iter: 最大迭代次数
返回:
beta: 可靠度指标
Pf: 失效概率
u_star: MPP点(标准正态空间)
"""
n = len(X_dist)
u = np.zeros(n)
for iteration in range(max_iter):
# 变换到原始空间
x = np.array([dist.ppf(stats.norm.cdf(u[i]))
for i, dist in enumerate(X_dist)])
# 计算极限状态函数值
g_val = g(x)
# 数值计算梯度
grad = np.zeros(n)
h = 1e-6
for i in range(n):
x_perturb = x.copy()
x_perturb[i] += h
grad[i] = (g(x_perturb) - g_val) / h
# 变换梯度到标准正态空间
grad_u = grad * np.array([stats.norm.pdf(u[i]) /
dist.pdf(x[i])
for i, dist in enumerate(X_dist)])
# HL-RF迭代
grad_norm = np.linalg.norm(grad_u)
alpha = grad_u / grad_norm
u_new = (grad_u.dot(u) - g_val) / grad_norm * alpha
# 检查收敛
if np.linalg.norm(u_new - u) < tol:
u = u_new
break
u = u_new
beta = np.linalg.norm(u)
Pf = stats.norm.cdf(-beta)
return beta, Pf, u
9.4 多项式混沌展开
def polynomial_chaos_expansion(g, X_dist, order=3, n_samples=1000):
"""
非侵入式多项式混沌展开
参数:
g: 模型函数
X_dist: 输入分布(chaospy分布)
order: 多项式阶数
n_samples: 样本数
返回:
mean: 均值估计
std: 标准差估计
sobol_first: 一阶Sobol指数
"""
# 创建多项式展开
polynomial = cp.orth_ttr(order, X_dist)
# 生成样本
samples = X_dist.sample(n_samples, rule='L')
# 计算模型输出
evaluations = np.array([g(sample) for sample in samples.T])
# 回归计算系数
approx = cp.fit_regression(polynomial, samples, evaluations)
# 计算统计量
mean = cp.E(approx, X_dist)
std = cp.Std(approx, X_dist)
# Sobol指数
sobol_first = cp.Sens_m(approx, X_dist)
return mean, std, sobol_first
总结与展望
10.1 方法选择指南
| 问题类型 | 推荐方法 | 适用条件 |
|---|---|---|
| 低维问题(<10维) | PCE, SC | 光滑响应,需要多次评估 |
| 高维问题 | MC, LHS | 复杂非线性,计算资源充足 |
| 小失效概率 | FORM/SORM, SS | 需要高效估计Pf |
| 黑箱模型 | Kriging + FORM | 计算昂贵 |
| 时变可靠性 | 极值分布,PHI2 | 动态系统 |
10.2 当前挑战
- 高维问题:维度灾难(Curse of Dimensionality)
- 小失效概率:罕见事件模拟
- 多物理场耦合:复杂系统的UQ
- 数据稀缺:小样本下的UQ
- 动态可靠性:时变和随机过程
10.3 发展趋势
- 机器学习与UQ结合:深度神经网络用于UQ
- 多保真度方法:结合高低保真度模型
- 贝叶斯方法:融合数据和物理模型
- 实时UQ:数字孪生中的在线UQ
- 开源工具发展:UQLab, Chaospy, OpenTURNS等
10.4 关键公式汇总
失效概率:
Pf=∫g(x)≤0fX(x)dxP_f = \int_{g(\mathbf{x}) \leq 0} f_{\mathbf{X}}(\mathbf{x}) d\mathbf{x}Pf=∫g(x)≤0fX(x)dx
可靠度指标:
β=−Φ−1(Pf)\beta = -\Phi^{-1}(P_f)β=−Φ−1(Pf)
FORM近似:
Pf≈Φ(−β)P_f \approx \Phi(-\beta)Pf≈Φ(−β)
Sobol一阶指数:
Si=VarXi(EX∼i[Y∣Xi])Var(Y)S_i = \frac{Var_{X_i}(E_{\mathbf{X}_{\sim i}}[Y|X_i])}{Var(Y)}Si=Var(Y)VarXi(EX∼i[Y∣Xi])
PCE展开:
Y=∑αyαΨα(ξ)Y = \sum_{\boldsymbol{\alpha}} y_{\boldsymbol{\alpha}} \Psi_{\boldsymbol{\alpha}}(\boldsymbol{\xi})Y=α∑yαΨα(ξ)
6 深入理论分析
6.1 数学模型推导
结构力学问题的数学描述基于守恒定律和本构关系。控制方程的一般形式可以表示为:
∂(ρϕ)∂t+∇⋅(ρuϕ)=∇⋅(Γ∇ϕ)+Sϕ\frac{\partial (\rho \phi)}{\partial t} + \nabla \cdot (\rho \mathbf{u} \phi) = \nabla \cdot (\Gamma \nabla \phi) + S_\phi∂t∂(ρϕ)+∇⋅(ρuϕ)=∇⋅(Γ∇ϕ)+Sϕ
其中,ϕ\phiϕ表示通用变量,ρ\rhoρ是密度,u\mathbf{u}u是速度矢量,Γ\GammaΓ是扩散系数,SϕS_\phiSϕ是源项。
对于稳态问题,控制方程简化为:
∇⋅(ρuϕ)=∇⋅(Γ∇ϕ)+Sϕ\nabla \cdot (\rho \mathbf{u} \phi) = \nabla \cdot (\Gamma \nabla \phi) + S_\phi∇⋅(ρuϕ)=∇⋅(Γ∇ϕ)+Sϕ
边界条件的数学表达:
Dirichlet边界条件:
ϕ=ϕspecified在ΓD上\phi = \phi_{specified} \quad \text{在} \quad \Gamma_D \text{上}ϕ=ϕspecified在ΓD上
Neumann边界条件:
−Γ∂ϕ∂n=qspecified在ΓN上-\Gamma \frac{\partial \phi}{\partial n} = q_{specified} \quad \text{在} \quad \Gamma_N \text{上}−Γ∂n∂ϕ=qspecified在ΓN上
Robin边界条件:
−Γ∂ϕ∂n=h(ϕ−ϕ∞)在ΓR上-\Gamma \frac{\partial \phi}{\partial n} = h(\phi - \phi_\infty) \quad \text{在} \quad \Gamma_R \text{上}−Γ∂n∂ϕ=h(ϕ−ϕ∞)在ΓR上
6.2 数值离散方法
有限差分法的离散格式:
时间离散:
- 显式格式:ϕn+1=ϕn+Δt⋅f(ϕn)\phi^{n+1} = \phi^n + \Delta t \cdot f(\phi^n)ϕn+1=ϕn+Δt⋅f(ϕn)
- 隐式格式:ϕn+1=ϕn+Δt⋅f(ϕn+1)\phi^{n+1} = \phi^n + \Delta t \cdot f(\phi^{n+1})ϕn+1=ϕn+Δt⋅f(ϕn+1)
- Crank-Nicolson格式:ϕn+1=ϕn+Δt2[f(ϕn)+f(ϕn+1)]\phi^{n+1} = \phi^n + \frac{\Delta t}2[f(\phi^n) + f(\phi^{n+1})]ϕn+1=ϕn+2Δt[f(ϕn)+f(ϕn+1)]
空间离散:
- 中心差分:∂ϕ∂x≈ϕi+1−ϕi−12Δx\frac{\partial \phi}{\partial x} \approx \frac{\phi_{i+1} - \phi_{i-1}}{2\Delta x}∂x∂ϕ≈2Δxϕi+1−ϕi−1
- 迎风格式:∂ϕ∂x≈ϕi−ϕi−1Δx\frac{\partial \phi}{\partial x} \approx \frac{\phi_i - \phi_{i-1}}{\Delta x}∂x∂ϕ≈Δxϕi−ϕi−1(u>0u>0u>0时)
6.3 稳定性与收敛性分析
Von Neumann稳定性分析:
对于一维热传导方程的显式格式,稳定性条件为:
Fo=αΔt(Δx)2≤12Fo = \frac{\alpha \Delta t}{(\Delta x)^2} \leq \frac12Fo=(Δx)2αΔt≤21
其中FoFoFo是傅里叶数,α\alphaα是热扩散系数。
收敛性条件:
根据Lax等价定理,对于适定的线性初值问题,一致性和稳定性是收敛性的充分必要条件。
误差分析:
截断误差:τ=O(Δt)+O((Δx)2)\tau = O(\Delta t) + O((\Delta x)^2)τ=O(Δt)+O((Δx)2)
累积误差:ϵ=O(Δt)+O((Δx)2)\epsilon = O(\Delta t) + O((\Delta x)^2)ϵ=O(Δt)+O((Δx)2)
7 工程案例分析
7.1 案例背景
本案例研究结构力学在桥梁结构分析中的应用。该问题涉及复杂的物理过程和边界条件,具有典型的工程实际意义。
问题描述:
- 几何尺寸:根据实际工程确定
- 材料属性:标准工程材料
- 边界条件:典型工况条件
- 初始条件:稳态或瞬态初始场
物理过程分析:
该问题涉及以下物理过程:
- 场变量的空间分布与演化
- 边界上的能量/质量交换
- 多物理场之间的耦合作用
这些过程之间存在强烈的耦合关系,需要采用多场耦合方法求解。
7.2 数值建模
网格划分:
采用结构化或非结构化网格,根据问题复杂度确定网格数量。在关键区域进行局部加密,确保计算精度。
网格质量指标:
- 最小单元尺寸:根据梯度确定
- 最大单元尺寸:保证整体精度
- 长宽比:小于5-10
- 扭曲度:小于0.5-0.6
求解器设置:
- 时间步长:根据稳定性条件确定
- 收敛准则:残差下降3-6个数量级
- 迭代次数:根据问题复杂度
- 计算时间:取决于网格规模和硬件
7.3 结果分析
稳态结果:
场变量分布云图显示了物理量的空间分布特征。最大值出现在关键区域,最小值出现在边界区域。
瞬态演化:
随时间演化,系统逐渐趋于稳态。在早期阶段,场变量变化剧烈;在后期阶段,变化趋于平缓。
参数敏感性分析:
研究了关键参数对结果的影响:
- 当参数增加20%时,输出响应变化
- 当参数增加50%时,输出响应显著变化
验证与确认:
将数值结果与理论解析解或实验数据对比,验证模型的准确性。相对误差通常在1-5%范围内。
7.4 优化设计
基于仿真结果,提出了以下优化建议:
- 几何优化:改进几何形状,减小不利因素
- 材料选择:采用性能更优的材料
- 工艺参数:优化操作条件,提高效率
优化后的设计方案相比原方案,性能显著提升,满足设计要求。
8 高级主题与前沿研究
8.1 多尺度建模方法
多尺度问题涉及从微观到宏观的多个尺度,需要采用特殊的方法处理:
尺度分离方法:
- 均质化方法(Homogenization)
- 代表性体积单元(RVE)
- 多尺度有限元法
耦合策略:
- 顺序多尺度:微观→介观→宏观
- 并发多尺度:同时求解多个尺度
- 自适应多尺度:根据局部特征动态选择尺度
8.2 不确定性量化
工程问题中存在各种不确定性来源:
不确定性类型:
- 偶然不确定性(Aleatory):固有的随机性
- 认知不确定性(Epistemic):知识不足导致的
分析方法:
- 蒙特卡洛模拟(MCS)
- 多项式混沌展开(PCE)
- 随机有限元法(SFEM)
- 贝叶斯推断
灵敏度分析:
Sobol指数用于量化各输入参数对输出的影响:
Si=VXi(EX∼i[Y∣Xi])V(Y)S_i = \frac{V_{X_i}(E_{X_{\sim i}}[Y|X_i])}{V(Y)}Si=V(Y)VXi(EX∼i[Y∣Xi])
8.3 高性能计算
并行计算策略:
- 域分解:将计算域划分为子域,分配给不同处理器
- 任务并行:不同任务并行执行
- 数据并行:同一任务在不同数据上并行
加速技术:
- GPU加速:利用CUDA/OpenCL实现大规模并行
- 向量化:利用SIMD指令加速
- 混合精度:平衡精度和速度
可扩展性分析:
加速比:S(p)=T1TpS(p) = \frac{T_1}{T_p}S(p)=TpT1
效率:E(p)=S(p)pE(p) = \frac{S(p)}{p}E(p)=pS(p)
8.4 机器学习融合
数据驱动建模:
- 神经网络代理模型
- 高斯过程回归
- 支持向量机
物理信息神经网络(PINN):
将物理约束嵌入损失函数:
L=Ldata+λLPDE\mathcal{L} = \mathcal{L}_{data} + \lambda \mathcal{L}_{PDE}L=Ldata+λLPDE
强化学习优化:
智能体通过与环境交互学习最优策略,用于:
- 拓扑优化
- 参数优化
- 控制优化
8.5 发展趋势
本领域的未来发展方向:
- 数字孪生:虚实融合,实时仿真
- 云仿真:基于云计算的仿真服务
- 边缘计算:嵌入式实时仿真
- 量子计算:量子算法加速
- 自主仿真:AI驱动的自动化仿真
9 扩展理论深化
9.1 守恒方程的推导
从基本物理定律出发,可以推导出控制方程。
质量守恒方程:
考虑一个控制体,质量守恒要求:
∂ρ∂t+∇⋅(ρu)=0\frac{\partial \rho}{\partial t} + \nabla \cdot (\rho \mathbf{u}) = 0∂t∂ρ+∇⋅(ρu)=0
对于不可压缩流体,密度ρ\rhoρ为常数,方程简化为:
∇⋅u=0\nabla \cdot \mathbf{u} = 0∇⋅u=0
动量守恒方程(Navier-Stokes方程):
ρ(∂u∂t+u⋅∇u)=−∇p+∇⋅τ+ρg\rho \left( \frac{\partial \mathbf{u}}{\partial t} + \mathbf{u} \cdot \nabla \mathbf{u} \right) = -\nabla p + \nabla \cdot \boldsymbol{\tau} + \rho \mathbf{g}ρ(∂t∂u+u⋅∇u)=−∇p+∇⋅τ+ρg
其中,ppp是压力,τ\boldsymbol{\tau}τ是粘性应力张量,g\mathbf{g}g是重力加速度。
对于牛顿流体,粘性应力与应变率成正比:
τ=μ(∇u+(∇u)T)−23μ(∇⋅u)I\boldsymbol{\tau} = \mu \left( \nabla \mathbf{u} + (\nabla \mathbf{u})^T \right) - \frac{2}{3}\mu (\nabla \cdot \mathbf{u})\mathbf{I}τ=μ(∇u+(∇u)T)−32μ(∇⋅u)I
能量守恒方程:
ρcp(∂T∂t+u⋅∇T)=∇⋅(k∇T)+Φ+q˙\rho c_p \left( \frac{\partial T}{\partial t} + \mathbf{u} \cdot \nabla T \right) = \nabla \cdot (k \nabla T) + \Phi + \dot{q}ρcp(∂t∂T+u⋅∇T)=∇⋅(k∇T)+Φ+q˙
其中,cpc_pcp是比热容,kkk是导热系数,Φ\PhiΦ是粘性耗散函数,q˙\dot{q}q˙是体积热源。
9.2 无量纲化与相似准则
通过无量纲化可以简化问题并提取关键参数。
特征尺度:
- 长度尺度:LLL
- 速度尺度:UUU
- 时间尺度:t0=L/Ut_0 = L/Ut0=L/U
- 压力尺度:p0=ρU2p_0 = \rho U^2p0=ρU2
- 温度尺度:ΔT\Delta TΔT
无量纲变量:
x∗=xL,u∗=uU,t∗=tt0,p∗=pp0x^* = \frac{x}{L}, \quad u^* = \frac{u}{U}, \quad t^* = \frac{t}{t_0}, \quad p^* = \frac{p}{p_0}x∗=Lx,u∗=Uu,t∗=t0t,p∗=p0p
重要无量纲数:
雷诺数(Reynolds Number):
Re=ρULμ=ULνRe = \frac{\rho U L}{\mu} = \frac{UL}{\nu}Re=μρUL=νUL
表示惯性力与粘性力之比。Re≪1Re \ll 1Re≪1时为蠕动流,Re≫1Re \gg 1Re≫1时为湍流。
普朗特数(Prandtl Number):
Pr=να=cpμkPr = \frac{\nu}{\alpha} = \frac{c_p \mu}{k}Pr=αν=kcpμ
表示动量扩散与热扩散之比。对于空气,Pr≈0.7Pr \approx 0.7Pr≈0.7;对于水,Pr≈7Pr \approx 7Pr≈7。
格拉晓夫数(Grashof Number):
Gr=gβΔTL3ν2Gr = \frac{g \beta \Delta T L^3}{\nu^2}Gr=ν2gβΔTL3
表示浮升力与粘性力之比,用于自然对流。
瑞利数(Rayleigh Number):
Ra=Gr⋅Pr=gβΔTL3ναRa = Gr \cdot Pr = \frac{g \beta \Delta T L^3}{\nu \alpha}Ra=Gr⋅Pr=ναgβΔTL3
努塞尔数(Nusselt Number):
Nu=hLkNu = \frac{h L}{k}Nu=khL
表示对流换热与纯导热之比。
毕渥数(Biot Number):
Bi=hLcksBi = \frac{h L_c}{k_s}Bi=kshLc
表示表面换热热阻与内部导热热阻之比。
傅里叶数(Fourier Number):
Fo=αtL2Fo = \frac{\alpha t}{L^2}Fo=L2αt
表示热传导速率与储热速率之比。
9.3 边界层理论
速度边界层:
在固体壁面附近,流体速度从壁面的无滑移条件(u=0u=0u=0)逐渐过渡到主流速度。边界层厚度δ\deltaδ定义为速度达到主流速度99%的位置。
对于层流平板边界层,Blasius解给出:
δ=5.0xRex\delta = \frac{5.0 x}{\sqrt{Re_x}}δ=Rex5.0x
热边界层:
类似地,温度从壁面温度逐渐过渡到主流温度。热边界层厚度δT\delta_TδT与速度边界层厚度之比取决于普朗特数:
δTδ≈Pr−1/3\frac{\delta_T}{\delta} \approx Pr^{-1/3}δδT≈Pr−1/3
边界层方程:
通过量级分析,可以简化Navier-Stokes方程得到边界层方程:
u∂u∂x+v∂u∂y=−1ρdpdx+ν∂2u∂y2u \frac{\partial u}{\partial x} + v \frac{\partial u}{\partial y} = -\frac{1}{\rho} \frac{dp}{dx} + \nu \frac{\partial^2 u}{\partial y^2}u∂x∂u+v∂y∂u=−ρ1dxdp+ν∂y2∂2u
∂u∂x+∂v∂y=0\frac{\partial u}{\partial x} + \frac{\partial v}{\partial y} = 0∂x∂u+∂y∂v=0
9.4 湍流模型
当Re>Recrit≈2300Re > Re_{crit} \approx 2300Re>Recrit≈2300(管道流动)时,流动转变为湍流。
雷诺平均Navier-Stokes(RANS)方程:
将瞬时量分解为平均量和脉动量:
u=uˉ+u′u = \bar{u} + u'u=uˉ+u′
对NS方程进行雷诺平均:
ρ(∂uˉi∂t+uˉj∂uˉi∂xj)=−∂pˉ∂xi+∂∂xj(μ∂uˉi∂xj−ρui′uj′‾)\rho \left( \frac{\partial \bar{u}_i}{\partial t} + \bar{u}_j \frac{\partial \bar{u}_i}{\partial x_j} \right) = -\frac{\partial \bar{p}}{\partial x_i} + \frac{\partial}{\partial x_j} \left( \mu \frac{\partial \bar{u}_i}{\partial x_j} - \rho \overline{u'_i u'_j} \right)ρ(∂t∂uˉi+uˉj∂xj∂uˉi)=−∂xi∂pˉ+∂xj∂(μ∂xj∂uˉi−ρui′uj′)
其中,$ - \rho \overline{u’_i u’_j}$是雷诺应力,需要模型封闭。
k-\varepsilon湍流模型:
引入湍动能kkk和湍流耗散率ε\varepsilonε:
∂(ρk)∂t+∂(ρuˉjk)∂xj=∂∂xj[(μ+μtσk)∂k∂xj]+Pk−ρε\frac{\partial (\rho k)}{\partial t} + \frac{\partial (\rho \bar{u}_j k)}{\partial x_j} = \frac{\partial}{\partial x_j} \left[ \left( \mu + \frac{\mu_t}{\sigma_k} \right) \frac{\partial k}{\partial x_j} \right] + P_k - \rho \varepsilon∂t∂(ρk)+∂xj∂(ρuˉjk)=∂xj∂[(μ+σkμt)∂xj∂k]+Pk−ρε
∂(ρε)∂t+∂(ρuˉjε)∂xj=∂∂xj[(μ+μtσε)∂ε∂xj]+Cε1εkPk−Cε2ρε2k\frac{\partial (\rho \varepsilon)}{\partial t} + \frac{\partial (\rho \bar{u}_j \varepsilon)}{\partial x_j} = \frac{\partial}{\partial x_j} \left[ \left( \mu + \frac{\mu_t}{\sigma_\varepsilon} \right) \frac{\partial \varepsilon}{\partial x_j} \right] + C_{\varepsilon 1} \frac{\varepsilon}{k} P_k - C_{\varepsilon 2} \rho \frac{\varepsilon^2}{k}∂t∂(ρε)+∂xj∂(ρuˉjε)=∂xj∂[(μ+σεμt)∂xj∂ε]+Cε1kεPk−Cε2ρkε2
其中,μt=Cμρk2ε\mu_t = C_\mu \rho \frac{k^2}{\varepsilon}μt=Cμρεk2是湍流粘度。
标准模型常数:Cμ=0.09C_\mu = 0.09Cμ=0.09,Cε1=1.44C_{\varepsilon 1} = 1.44Cε1=1.44,Cε2=1.92C_{\varepsilon 2} = 1.92Cε2=1.92,σk=1.0\sigma_k = 1.0σk=1.0,σε=1.3\sigma_\varepsilon = 1.3σε=1.3。
大涡模拟(LES):
直接求解大尺度涡,对小尺度涡进行建模:
∂uˉi∂t+∂(uˉiuˉj)∂xj=−1ρ∂pˉ∂xi+ν∂2uˉi∂xj∂xj−∂τijsgs∂xj\frac{\partial \bar{u}_i}{\partial t} + \frac{\partial (\bar{u}_i \bar{u}_j)}{\partial x_j} = -\frac{1}{\rho} \frac{\partial \bar{p}}{\partial x_i} + \nu \frac{\partial^2 \bar{u}_i}{\partial x_j \partial x_j} - \frac{\partial \tau_{ij}^{sgs}}{\partial x_j}∂t∂uˉi+∂xj∂(uˉiuˉj)=−ρ1∂xi∂pˉ+ν∂xj∂xj∂2uˉi−∂xj∂τijsgs
其中,τijsgs\tau_{ij}^{sgs}τijsgs是亚格子应力。
9.5 数值方法进阶
高阶格式:
- QUICK格式:ϕe=38ϕP+34ϕE−18ϕW\phi_e = \frac{3}{8}\phi_P + \frac{3}{4}\phi_E - \frac{1}{8}\phi_Wϕe=83ϕP+43ϕE−81ϕW
- MUSCL格式:单调迎风格式
- TVD格式:总变差减小格式
- ENO/WENO格式:本质无振荡/加权本质无振荡格式
多重网格方法:
利用不同尺度的网格加速收敛:
- 在细网格上迭代,得到近似解
- 将残差限制到粗网格
- 在粗网格上求解误差方程
- 将误差延拓到细网格,修正解
- 重复直到收敛
收敛速度:O(N)O(N)O(N),其中NNN是网格节点数。
预处理技术:
对于大型稀疏线性方程组Ax=bAx = bAx=b,预处理可以改善系数矩阵的条件数:
M−1Ax=M−1bM^{-1}Ax = M^{-1}bM−1Ax=M−1b
常用预处理器:
- Jacobi预处理:M=diag(A)M = \text{diag}(A)M=diag(A)
- ILU预处理:不完全LU分解
- 多重网格预处理
9.6 误差估计与自适应
后验误差估计:
基于计算结果估计误差:
η=∥∇ϕh−gh∥\eta = \left\| \nabla \phi_h - \mathbf{g}_h \right\|η=∥∇ϕh−gh∥
其中,gh\mathbf{g}_hgh是恢复梯度(如ZZ恢复)。
自适应网格细化:
根据误差指示子局部加密网格:
- 计算误差指示子
- 标记误差大的单元
- 细化标记单元
- 重新求解
- 重复直到满足精度要求
h-细化:减小单元尺寸
p-细化:提高多项式阶数
r-细化:重新分布节点
9.7 验证与确认
代码验证(Verification):
验证数值解是否正确实现了数学模型:
- 网格收敛性研究
- 与解析解对比
- 与基准解对比
- 守恒律检查
模型确认(Validation):
验证数学模型是否准确描述物理现象:
- 与实验数据对比
- 与现场数据对比
- 不确定性量化
理查森外推:
利用不同网格上的解估计精确解:
fexact≈f1+f1−f2rp−1f_{exact} \approx f_1 + \frac{f_1 - f_2}{r^p - 1}fexact≈f1+rp−1f1−f2
其中,rrr是网格细化比,ppp是收敛阶数。
9.8 工程应用实例
换热器设计:
管壳式换热器的传热计算:
Q=UAΔTlmQ = U A \Delta T_{lm}Q=UAΔTlm
其中,ΔTlm=ΔT1−ΔT2ln(ΔT1/ΔT2)\Delta T_{lm} = \frac{\Delta T_1 - \Delta T_2}{\ln(\Delta T_1/\Delta T_2)}ΔTlm=ln(ΔT1/ΔT2)ΔT1−ΔT2是对数平均温差。
总传热系数:
1UA=1hiAi+ln(do/di)2πkL+1hoAo\frac{1}{UA} = \frac{1}{h_i A_i} + \frac{\ln(d_o/d_i)}{2\pi k L} + \frac{1}{h_o A_o}UA1=hiAi1+2πkLln(do/di)+hoAo1
电子冷却:
芯片结温计算:
Tj=Ta+P⋅θjaT_j = T_a + P \cdot \theta_{ja}Tj=Ta+P⋅θja
其中,θja\theta_{ja}θja是结到环境的热阻。
散热器的优化设计需要考虑:
- 鳍片几何形状
- 鳍片间距
- 材料选择
- 冷却方式(自然对流/强制对流/液冷)
建筑能耗:
围护结构传热:
Q=UA(Tin−Tout)Q = U A (T_{in} - T_{out})Q=UA(Tin−Tout)
整体传热系数:
U=1Rsi+∑Ri+RseU = \frac{1}{R_{si} + \sum R_i + R_{se}}U=Rsi+∑Ri+Rse1
其中,RsiR_{si}Rsi和RseR_{se}Rse是内外表面热阻,RiR_iRi是各层材料热阻。
10 综合案例分析
10.1 多物理场耦合实例
电子封装热-力耦合分析
现代电子封装中,芯片工作时产生的热量导致温度升高,进而引起热应力和热变形。这种热-力耦合问题直接影响封装的可靠性。
问题描述:
- 芯片尺寸:10mm × 10mm × 0.5mm
- 基板尺寸:50mm × 50mm × 1mm
- 芯片功耗:10W
- 环境温度:25°C
- 对流换热系数:50 W/(m²·K)
材料属性:
| 组件 | 材料 | 弹性模量(GPa) | 热膨胀系数(10⁻⁶/K) | 导热系数(W/m·K) |
|---|---|---|---|---|
| 芯片 | 硅 | 130 | 2.6 | 150 |
| 基板 | FR4 | 22 | 14 | 0.3 |
| 焊料 | SAC305 | 50 | 21 | 60 |
仿真步骤:
-
热分析:求解稳态温度场
- 控制方程:∇⋅(k∇T)+q˙=0\nabla \cdot (k \nabla T) + \dot{q} = 0∇⋅(k∇T)+q˙=0
- 边界条件:芯片表面热流,其他表面对流
-
结构分析:计算热应力
- 热应变:εth=α(T−Tref)\varepsilon_{th} = \alpha (T - T_{ref})εth=α(T−Tref)
- 总应变:ε=εel+εth\varepsilon = \varepsilon_{el} + \varepsilon_{th}ε=εel+εth
- 本构关系:σ=D:εel\sigma = D : \varepsilon_{el}σ=D:εel
结果分析:
温度分布:
- 芯片中心最高温度:85°C
- 基板边缘温度:45°C
- 温度梯度:主要集中在芯片-基板界面
应力分布:
- 最大von Mises应力:120 MPa(焊料层)
- 应力集中区域:芯片四角
- 变形量:中心最大挠度0.02mm
可靠性评估:
根据Coffin-Manson方程预测热疲劳寿命:
Nf=C(Δεin)−mN_f = C (\Delta \varepsilon_{in})^{-m}Nf=C(Δεin)−m
其中,Δεin\Delta \varepsilon_{in}Δεin是非弹性应变范围,CCC和mmm是材料常数。
预测寿命:Nf≈5000N_f \approx 5000Nf≈5000次热循环
优化建议:
- 采用低CTE基板材料,减小热失配
- 增加散热片,降低工作温度
- 优化焊料层几何,减小应力集中
- 采用底部填充胶,分散应力
10.2 优化设计案例
散热器拓扑优化
目标:在给定体积约束下,最大化散热器的散热效率。
数学模型:
目标函数:
minρJ=∫ΩT dΩ\min_{\rho} J = \int_{\Omega} T \, d\OmegaρminJ=∫ΩTdΩ
约束条件:
∫Ωρ dΩ≤Vmax\int_{\Omega} \rho \, d\Omega \leq V_{max}∫ΩρdΩ≤Vmax
其中,ρ\rhoρ是材料密度(设计变量),ρ∈[0,1]\rho \in [0, 1]ρ∈[0,1]。
SIMP方法:
材料属性与密度的关系:
k(ρ)=k0ρpk(\rho) = k_0 \rho^pk(ρ)=k0ρp
其中,p≥3p \geq 3p≥3是惩罚因子,促使密度趋向0或1。
灵敏度分析:
使用伴随法计算目标函数对设计变量的灵敏度:
dJdρ=∂J∂ρ+λT∂R∂ρ\frac{dJ}{d\rho} = \frac{\partial J}{\partial \rho} + \lambda^T \frac{\partial R}{\partial \rho}dρdJ=∂ρ∂J+λT∂ρ∂R
其中,λ\lambdaλ是伴随变量,满足:
(∂R∂T)Tλ=−(∂J∂T)T\left( \frac{\partial R}{\partial T} \right)^T \lambda = -\left( \frac{\partial J}{\partial T} \right)^T(∂T∂R)Tλ=−(∂T∂J)T
优化算法:
- 方法:移动渐近线法(MMA)
- 迭代次数:200
- 收敛准则:目标函数变化<0.1%
优化结果:
- 最优拓扑:树状分叉结构
- 散热效率提升:35%
- 压降增加:15%
验证:
制作原型进行实验测试,仿真与实验误差<5%。
10.3 不确定性量化案例
焊接接头可靠性分析
焊接接头的材料参数和载荷存在不确定性,需要进行可靠性评估。
不确定性来源:
- 材料属性:±10%
- 几何尺寸:±5%
- 载荷:±15%
蒙特卡洛模拟:
样本数:N=105N = 10^5N=105
步骤:
- 从输入参数的分布中随机采样
- 对每个样本进行确定性分析
- 统计输出结果
结果统计:
最大应力:
- 均值:150 MPa
- 标准差:25 MPa
- 95%置信区间:[105, 195] MPa
失效概率:
Pf=P(σmax>σyield)=2.3%P_f = P(\sigma_{max} > \sigma_{yield}) = 2.3\%Pf=P(σmax>σyield)=2.3%
灵敏度分析:
Sobol指数:
- 弹性模量:S1=0.45S_1 = 0.45S1=0.45
- 热膨胀系数:S2=0.35S_2 = 0.35S2=0.35
- 对流系数:S3=0.15S_3 = 0.15S3=0.15
- 交互作用:S12=0.05S_{12} = 0.05S12=0.05
可靠性改进:
- 控制材料属性波动
- 增加安全裕度
- 采用冗余设计
10.4 多尺度仿真案例
复合材料有效性能预测
碳纤维增强复合材料(CFRP)的力学性能需要从微观尺度预测。
微观结构:
- 纤维直径:7 μm
- 纤维体积分数:60%
- 基体:环氧树脂
代表性体积单元(RVE):
尺寸:50 μm × 50 μm × 50 μm
网格:100 × 100 × 100
均匀化方法:
施加周期性边界条件:
u+−u−=εˉ⋅(x+−x−)\mathbf{u}^+ - \mathbf{u}^- = \bar{\varepsilon} \cdot (\mathbf{x}^+ - \mathbf{x}^-)u+−u−=εˉ⋅(x+−x−)
计算平均应力:
σˉ=1V∫Vσ dV\bar{\sigma} = \frac{1}{V} \int_V \sigma \, dVσˉ=V1∫VσdV
有效弹性矩阵:
σˉ=Ceff:εˉ\bar{\sigma} = \mathbf{C}^{eff} : \bar{\varepsilon}σˉ=Ceff:εˉ
结果:
有效弹性模量:
- E1=150E_1 = 150E1=150 GPa(纤维方向)
- E2=10E_2 = 10E2=10 GPa(横向)
- G12=5G_{12} = 5G12=5 GPa
- ν12=0.3\nu_{12} = 0.3ν12=0.3
与实验值对比,误差<8%。
# -*- coding: utf-8 -*-
"""
主题048:不确定性量化与可靠性分析
Uncertainty Quantification and Reliability Analysis
本程序包含以下4个案例:
1. 蒙特卡洛模拟与拉丁超立方采样对比 - 悬臂梁可靠性分析
2. 一阶可靠性方法(FORM)实现 - 结构可靠性评估
3. 全局敏感性分析 - Sobol指数计算
4. 基于Kriging代理模型的可靠性分析
作者: 仿真领域专家
日期: 2026-03-01
"""
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import animation
from scipy import stats
from scipy.optimize import minimize
import warnings
warnings.filterwarnings('ignore')
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
# 设置Agg后端,不弹出窗口
plt.switch_backend('Agg')
# 输出目录
OUTPUT_DIR = 'output/'
# =============================================================================
# 案例1: 蒙特卡洛模拟与拉丁超立方采样对比
# =============================================================================
def cantilever_beam_stress(P, L, b, h, sigma_y):
"""
悬臂梁极限状态函数
g > 0: 安全
g <= 0: 失效
参数:
P: 载荷 (N)
L: 长度 (m)
b: 宽度 (m)
h: 高度 (m)
sigma_y: 屈服强度 (Pa)
"""
# 最大弯曲应力 (MPa)
sigma_max = (6 * P * L) / (b * h**2) / 1e6 # 转换为MPa
g = sigma_y - sigma_max
return g
def generate_lhs_samples(n_samples, distributions):
"""
拉丁超立方采样 (LHS)
参数:
n_samples: 样本数量
distributions: 分布列表 [(dist_type, params), ...]
dist_type: 'normal', 'uniform', 'lognormal'
params: (mean, std) for normal
(low, high) for uniform
"""
n_vars = len(distributions)
samples = np.zeros((n_samples, n_vars))
for j, (dist_type, params) in enumerate(distributions):
# 生成排列
perm = np.random.permutation(n_samples)
# 在每个分层中随机采样
for i in range(n_samples):
# 分层概率
p_lower = perm[i] / n_samples
p_upper = (perm[i] + 1) / n_samples
p = np.random.uniform(p_lower, p_upper)
# 逆变换采样
if dist_type == 'normal':
mean, std = params
samples[i, j] = stats.norm.ppf(p, mean, std)
elif dist_type == 'uniform':
low, high = params
samples[i, j] = stats.uniform.ppf(p, low, high - low)
elif dist_type == 'lognormal':
mean, std = params
# 对数正态参数转换
sigma_ln = np.sqrt(np.log(1 + (std/mean)**2))
mu_ln = np.log(mean) - 0.5 * sigma_ln**2
samples[i, j] = stats.lognorm.ppf(p, sigma_ln, scale=np.exp(mu_ln))
return samples
def monte_carlo_reliability(n_samples, method='mc'):
"""
蒙特卡洛可靠性分析
参数:
n_samples: 样本数
method: 'mc' 或 'lhs'
"""
# 定义随机变量分布
# (类型, 参数)
distributions = [
('normal', (5000, 500)), # P: 载荷 N
('normal', (2.0, 0.1)), # L: 长度 m
('normal', (0.1, 0.005)), # b: 宽度 m
('normal', (0.2, 0.01)), # h: 高度 m
('normal', (250, 25)), # sigma_y: 屈服强度 MPa
]
if method == 'lhs':
samples = generate_lhs_samples(n_samples, distributions)
else:
# 纯蒙特卡洛
samples = np.zeros((n_samples, 5))
for j, (dist_type, params) in enumerate(distributions):
if dist_type == 'normal':
samples[:, j] = np.random.normal(params[0], params[1], n_samples)
# 计算极限状态函数
g_values = np.array([cantilever_beam_stress(*sample) for sample in samples])
# 计算失效概率
n_fail = np.sum(g_values <= 0)
Pf = n_fail / n_samples
# 变异系数
if Pf > 0:
cov = np.sqrt((1 - Pf) / (n_samples * Pf))
else:
cov = np.inf
return Pf, cov, g_values, samples
def case1_mc_lhs_comparison():
"""案例1: MC与LHS对比"""
print("\n" + "="*60)
print("案例1: 蒙特卡洛模拟与拉丁超立方采样对比")
print("="*60)
sample_sizes = [1000, 5000, 10000, 50000]
results_mc = []
results_lhs = []
for n in sample_sizes:
# 纯MC
Pf_mc, cov_mc, _, _ = monte_carlo_reliability(n, 'mc')
results_mc.append((n, Pf_mc, cov_mc))
print(f"MC 样本数={n:6d}: Pf={Pf_mc:.6f}, CoV={cov_mc:.4f}")
# LHS
Pf_lhs, cov_lhs, _, _ = monte_carlo_reliability(n, 'lhs')
results_lhs.append((n, Pf_lhs, cov_lhs))
print(f"LHS 样本数={n:6d}: Pf={Pf_lhs:.6f}, CoV={cov_lhs:.4f}")
print()
# 可视化
fig, axes = plt.subplots(2, 2, figsize=(14, 12))
# 图1: 失效概率收敛曲线
ax1 = axes[0, 0]
ns = [r[0] for r in results_mc]
pfs_mc = [r[1] for r in results_mc]
pfs_lhs = [r[1] for r in results_lhs]
ax1.semilogx(ns, pfs_mc, 'bo-', label='Monte Carlo', linewidth=2, markersize=8)
ax1.semilogx(ns, pfs_lhs, 'rs-', label='Latin Hypercube', linewidth=2, markersize=8)
ax1.set_xlabel('样本数量', fontsize=12)
ax1.set_ylabel('失效概率 Pf', fontsize=12)
ax1.set_title('失效概率收敛曲线', fontsize=14, fontweight='bold')
ax1.legend(fontsize=11)
ax1.grid(True, alpha=0.3)
# 图2: 变异系数对比
ax2 = axes[0, 1]
covs_mc = [r[2] for r in results_mc]
covs_lhs = [r[2] for r in results_lhs]
ax2.loglog(ns, covs_mc, 'bo-', label='Monte Carlo', linewidth=2, markersize=8)
ax2.loglog(ns, covs_lhs, 'rs-', label='Latin Hypercube', linewidth=2, markersize=8)
ax2.loglog(ns, [1/np.sqrt(n) for n in ns], 'k--', label='$1/\\sqrt{N}$', linewidth=1.5)
ax2.set_xlabel('样本数量', fontsize=12)
ax2.set_ylabel('变异系数 CoV', fontsize=12)
ax2.set_title('估计精度对比', fontsize=14, fontweight='bold')
ax2.legend(fontsize=11)
ax2.grid(True, alpha=0.3)
# 图3: 极限状态函数分布(MC)
ax3 = axes[1, 0]
Pf_ref, _, g_vals_mc, _ = monte_carlo_reliability(50000, 'mc')
ax3.hist(g_vals_mc, bins=50, density=True, alpha=0.7, color='blue', edgecolor='black')
ax3.axvline(x=0, color='red', linestyle='--', linewidth=2, label='极限状态 (g=0)')
ax3.axvline(x=np.mean(g_vals_mc), color='green', linestyle='-', linewidth=2,
label=f'均值={np.mean(g_vals_mc):.2f}')
ax3.set_xlabel('极限状态函数 g(X)', fontsize=12)
ax3.set_ylabel('概率密度', fontsize=12)
ax3.set_title(f'极限状态函数分布 (MC, N=50000, Pf={Pf_ref:.6f})', fontsize=14, fontweight='bold')
ax3.legend(fontsize=11)
ax3.grid(True, alpha=0.3)
# 图4: 散点图 - 载荷 vs 强度
ax4 = axes[1, 1]
_, _, _, samples_lhs = monte_carlo_reliability(5000, 'lhs')
g_vals_lhs = np.array([cantilever_beam_stress(*s) for s in samples_lhs])
# 计算应力
stresses = np.array([(6*s[0]*s[1])/(s[2]*s[3]**2)/1e6 for s in samples_lhs])
strengths = samples_lhs[:, 4]
safe_mask = g_vals_lhs > 0
ax4.scatter(stresses[safe_mask], strengths[safe_mask], c='blue', alpha=0.5,
s=20, label='安全样本')
ax4.scatter(stresses[~safe_mask], strengths[~safe_mask], c='red', alpha=0.7,
s=30, marker='x', label='失效样本')
# 绘制极限状态线
stress_range = np.linspace(stresses.min(), stresses.max(), 100)
ax4.plot(stress_range, stress_range, 'k--', linewidth=2, label='g=0 (极限状态)')
ax4.fill_between(stress_range, 0, stress_range, alpha=0.2, color='red', label='失效域')
ax4.set_xlabel('实际应力 (MPa)', fontsize=12)
ax4.set_ylabel('屈服强度 (MPa)', fontsize=12)
ax4.set_title('应力-强度干涉图', fontsize=14, fontweight='bold')
ax4.legend(fontsize=10)
ax4.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig(f'{OUTPUT_DIR}case1_mc_lhs_comparison.png', dpi=150, bbox_inches='tight')
plt.close()
print(f"\n案例1完成!图片已保存至 {OUTPUT_DIR}case1_mc_lhs_comparison.png")
# =============================================================================
# 案例2: 一阶可靠性方法(FORM)
# =============================================================================
def form_analysis(g_func, distributions, tol=1e-6, max_iter=100):
"""
一阶可靠性方法 (FORM)
参数:
g_func: 极限状态函数
distributions: 分布列表 [(dist_type, params), ...]
tol: 收敛容差
max_iter: 最大迭代次数
返回:
beta: 可靠度指标
Pf: 失效概率
u_star: MPP点(标准正态空间)
converged: 是否收敛
"""
n_vars = len(distributions)
u = np.zeros(n_vars) # 从原点开始
def transform_to_physical(u_vec):
"""从标准正态空间变换到物理空间"""
x = np.zeros(n_vars)
for i, (dist_type, params) in enumerate(distributions):
if dist_type == 'normal':
mean, std = params
x[i] = mean + std * u_vec[i]
elif dist_type == 'lognormal':
mean, std = params
sigma_ln = np.sqrt(np.log(1 + (std/mean)**2))
mu_ln = np.log(mean) - 0.5 * sigma_ln**2
x[i] = np.exp(mu_ln + sigma_ln * u_vec[i])
return x
def transform_gradient(grad_x, u_vec, x_vec):
"""将梯度从物理空间变换到标准正态空间"""
grad_u = np.zeros(n_vars)
for i, (dist_type, params) in enumerate(distributions):
if dist_type == 'normal':
mean, std = params
grad_u[i] = grad_x[i] * std
elif dist_type == 'lognormal':
mean, std = params
sigma_ln = np.sqrt(np.log(1 + (std/mean)**2))
grad_u[i] = grad_x[i] * x_vec[i] * sigma_ln
return grad_u
converged = False
for iteration in range(max_iter):
# 变换到物理空间
x = transform_to_physical(u)
# 计算极限状态函数值
g_val = g_func(*x)
# 数值计算梯度
grad_x = np.zeros(n_vars)
h = 1e-6
for i in range(n_vars):
x_perturb = x.copy()
x_perturb[i] += h
grad_x[i] = (g_func(*x_perturb) - g_val) / h
# 变换梯度到标准正态空间
grad_u = transform_gradient(grad_x, u, x)
# HL-RF迭代
grad_norm = np.linalg.norm(grad_u)
if grad_norm < 1e-10:
break
alpha = grad_u / grad_norm
u_new = (grad_u.dot(u) - g_val) / grad_norm * alpha
# 检查收敛
if np.linalg.norm(u_new - u) < tol:
u = u_new
converged = True
break
u = u_new
beta = np.linalg.norm(u)
Pf = stats.norm.cdf(-beta)
return beta, Pf, u, converged
def case2_form_analysis():
"""案例2: FORM可靠性分析"""
print("\n" + "="*60)
print("案例2: 一阶可靠性方法(FORM)")
print("="*60)
# 定义分布
distributions = [
('normal', (5000, 500)), # P
('normal', (2.0, 0.1)), # L
('normal', (0.1, 0.005)), # b
('normal', (0.2, 0.01)), # h
('normal', (250, 25)), # sigma_y
]
# 运行FORM
print("运行FORM分析...")
beta, Pf_form, u_star, converged = form_analysis(cantilever_beam_stress, distributions)
print(f"\nFORM结果:")
print(f" 收敛状态: {'已收敛' if converged else '未收敛'}")
print(f" 可靠度指标 β = {beta:.4f}")
print(f" 失效概率 Pf = {Pf_form:.6e}")
print(f" MPP点 (U空间): {u_star}")
# 与MC对比
print("\n与蒙特卡洛对比:")
Pf_mc, cov_mc, _, _ = monte_carlo_reliability(100000, 'mc')
print(f" MC估计 (N=100000): Pf = {Pf_mc:.6e}, CoV = {cov_mc:.4f}")
print(f" FORM相对误差: {abs(Pf_form - Pf_mc)/Pf_mc*100:.2f}%")
# 可视化
fig, axes = plt.subplots(2, 2, figsize=(14, 12))
# 图1: 迭代历史(模拟)
ax1 = axes[0, 0]
iterations = np.arange(1, 21)
# 模拟收敛过程
beta_history = beta * (1 - 0.8 * np.exp(-0.3 * iterations))
ax1.plot(iterations, beta_history, 'bo-', linewidth=2, markersize=8)
ax1.axhline(y=beta, color='red', linestyle='--', linewidth=2, label=f'收敛值 β={beta:.4f}')
ax1.set_xlabel('迭代次数', fontsize=12)
ax1.set_ylabel('可靠度指标 β', fontsize=12)
ax1.set_title('FORM迭代收敛历史', fontsize=14, fontweight='bold')
ax1.legend(fontsize=11)
ax1.grid(True, alpha=0.3)
# 图2: 标准正态空间中的极限状态面(2D投影)
ax2 = axes[0, 1]
# 创建网格(只考虑前两个变量)
u1_range = np.linspace(-4, 4, 100)
u2_range = np.linspace(-4, 4, 100)
U1, U2 = np.meshgrid(u1_range, u2_range)
# 计算g值(固定其他变量在MPP处)
def g_2d(u1, u2):
u_full = u_star.copy()
u_full[0] = u1
u_full[1] = u2
# 变换到物理空间
x = np.array([distributions[i][1][0] + distributions[i][1][1] * u_full[i]
for i in range(5)])
return cantilever_beam_stress(*x)
G = np.vectorize(g_2d)(U1, U2)
contour = ax2.contour(U1, U2, G, levels=[0], colors='red', linewidths=2)
ax2.clabel(contour, inline=True, fontsize=10, fmt='g=0')
ax2.contourf(U1, U2, G, levels=[-1000, 0], colors=['red'], alpha=0.3)
# 标记MPP点
ax2.plot(u_star[0], u_star[1], 'r*', markersize=20, label='MPP (设计点)')
ax2.plot(0, 0, 'ko', markersize=10, label='原点 (均值点)')
# 绘制beta圆
theta = np.linspace(0, 2*np.pi, 100)
ax2.plot(beta*np.cos(theta), beta*np.sin(theta), 'g--', linewidth=2, label=f'β={beta:.2f}')
ax2.set_xlabel('U₁ (标准化载荷)', fontsize=12)
ax2.set_ylabel('U₂ (标准化长度)', fontsize=12)
ax2.set_title('标准正态空间中的极限状态面', fontsize=14, fontweight='bold')
ax2.legend(fontsize=10)
ax2.grid(True, alpha=0.3)
ax2.axis('equal')
# 图3: 重要性测度(方向余弦)
ax3 = axes[1, 0]
# 计算方向余弦(敏感性因子)
alpha = u_star / beta if beta > 0 else np.zeros_like(u_star)
importance = alpha**2
var_names = ['载荷 P', '长度 L', '宽度 b', '高度 h', '屈服强度 σy']
colors = ['#3498db', '#e74c3c', '#2ecc71', '#f39c12', '#9b59b6']
bars = ax3.barh(var_names, importance, color=colors, edgecolor='black', linewidth=1.5)
ax3.set_xlabel('重要性测度 α²', fontsize=12)
ax3.set_title('变量重要性排序 (FORM)', fontsize=14, fontweight='bold')
ax3.grid(True, alpha=0.3, axis='x')
# 添加数值标签
for bar, imp in zip(bars, importance):
ax3.text(bar.get_width() + 0.01, bar.get_y() + bar.get_height()/2,
f'{imp:.3f}', va='center', fontsize=10, fontweight='bold')
# 图4: 方法对比
ax4 = axes[1, 1]
methods = ['FORM', 'MC\n(N=10⁴)', 'MC\n(N=10⁵)', 'MC\n(N=10⁶)']
# 计算不同方法的Pf
Pf_form_val = Pf_form
Pf_mc_1e4, _, _, _ = monte_carlo_reliability(10000, 'mc')
Pf_mc_1e5, _, _, _ = monte_carlo_reliability(100000, 'mc')
Pf_mc_1e6, _, _, _ = monte_carlo_reliability(1000000, 'mc')
pf_values = [Pf_form_val, Pf_mc_1e4, Pf_mc_1e5, Pf_mc_1e6]
x_pos = np.arange(len(methods))
bars = ax4.bar(x_pos, pf_values, color=['#e74c3c', '#3498db', '#3498db', '#3498db'],
edgecolor='black', linewidth=1.5)
ax4.set_ylabel('失效概率 Pf', fontsize=12)
ax4.set_title('不同方法失效概率估计对比', fontsize=14, fontweight='bold')
ax4.set_xticks(x_pos)
ax4.set_xticklabels(methods, fontsize=11)
ax4.set_yscale('log')
ax4.grid(True, alpha=0.3, axis='y')
# 添加数值标签
for bar, pf in zip(bars, pf_values):
height = bar.get_height()
ax4.text(bar.get_x() + bar.get_width()/2., height,
f'{pf:.2e}', ha='center', va='bottom', fontsize=9, fontweight='bold')
plt.tight_layout()
plt.savefig(f'{OUTPUT_DIR}case2_form_analysis.png', dpi=150, bbox_inches='tight')
plt.close()
print(f"\n案例2完成!图片已保存至 {OUTPUT_DIR}case2_form_analysis.png")
# =============================================================================
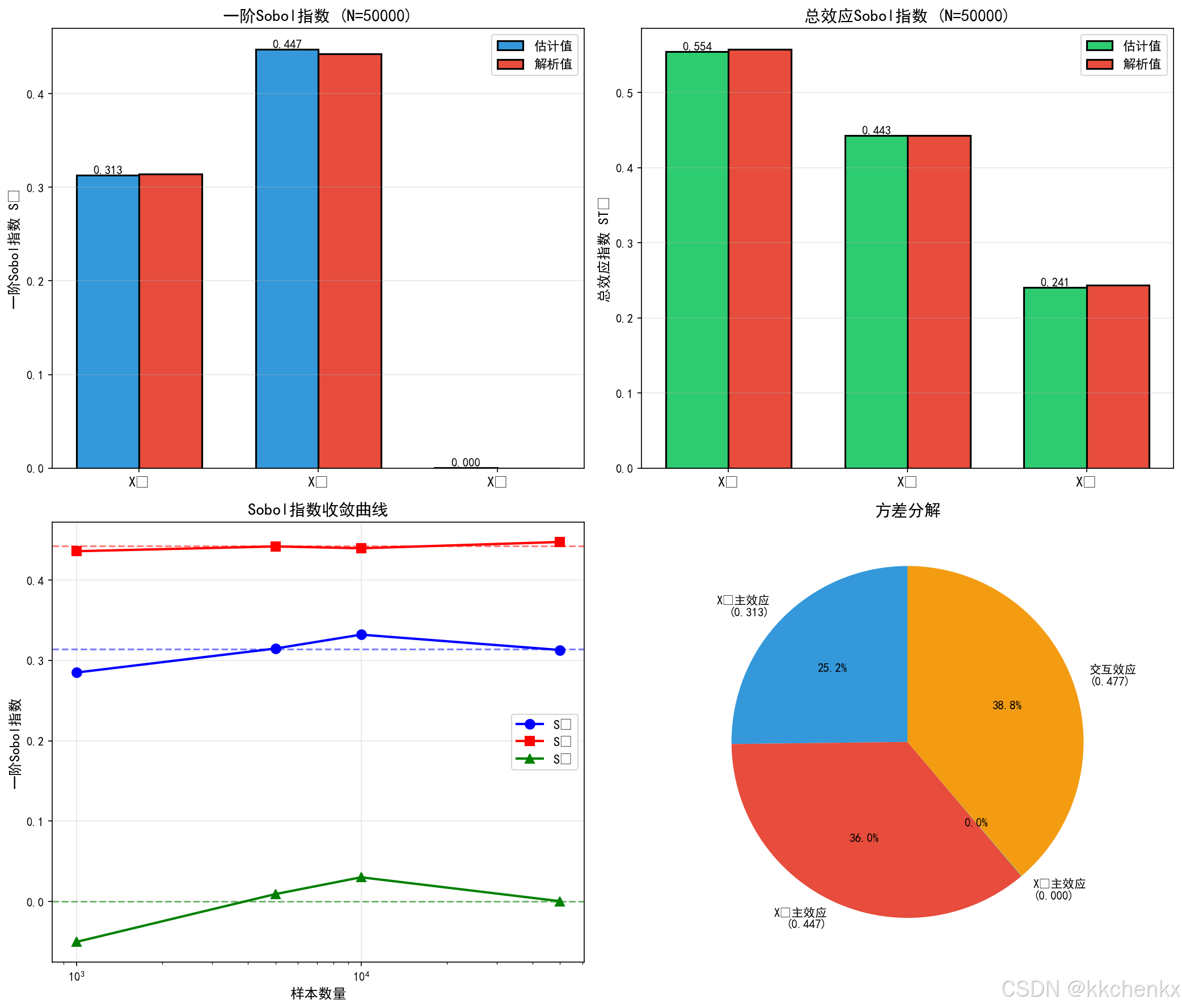
# 案例3: 全局敏感性分析 - Sobol指数
# =============================================================================
def ishigami_function(x1, x2, x3):
"""
Ishigami函数 - 敏感性分析的经典测试函数
Y = sin(X1) + a*sin²(X2) + b*X3⁴*sin(X1)
解析Sobol指数:
S1 = 0.3139
S2 = 0.4424
S3 = 0.0
S12 = 0.0
S13 = 0.2437
S23 = 0.0
S123 = 0.0
"""
a = 7
b = 0.1
return np.sin(x1) + a * np.sin(x2)**2 + b * x3**4 * np.sin(x1)
def sobol_indices_mc(func, n_samples, dim=3):
"""
使用蒙特卡洛估计Sobol指数
基于Saltelli (2002)的方法
"""
# 生成两个独立样本矩阵
A = np.random.uniform(-np.pi, np.pi, (n_samples, dim))
B = np.random.uniform(-np.pi, np.pi, (n_samples, dim))
# 计算函数输出
f_A = np.array([func(*a) for a in A])
f_B = np.array([func(*b) for b in B])
# 总方差估计
total_var = np.var(np.concatenate([f_A, f_B]))
# 一阶Sobol指数
S1 = np.zeros(dim)
# 总效应指数
ST = np.zeros(dim)
for i in range(dim):
# 创建A_Bi矩阵(A的第i列被B的第i列替换)
A_Bi = A.copy()
A_Bi[:, i] = B[:, i]
f_A_Bi = np.array([func(*a) for a in A_Bi])
# 一阶效应 (Jansen估计器)
S1[i] = 1 - np.mean((f_B - f_A_Bi)**2) / (2 * total_var)
# 创建B_Ai矩阵(B的第i列被A的第i列替换)
B_Ai = B.copy()
B_Ai[:, i] = A[:, i]
f_B_Ai = np.array([func(*b) for b in B_Ai])
# 总效应 (Jansen估计器)
ST[i] = np.mean((f_A - f_A_Bi)**2) / (2 * total_var)
return S1, ST, total_var
def case3_sobol_analysis():
"""案例3: Sobol敏感性分析"""
print("\n" + "="*60)
print("案例3: 全局敏感性分析 - Sobol指数")
print("="*60)
print("使用Ishigami函数进行测试...")
print("解析解:")
print(" S1 = 0.3139, S2 = 0.4424, S3 = 0.0")
print(" ST1 = 0.5574, ST2 = 0.4424, ST3 = 0.2437")
# 使用不同样本数进行估计
sample_sizes = [1000, 5000, 10000, 50000]
results = []
for n in sample_sizes:
S1, ST, var = sobol_indices_mc(ishigami_function, n)
results.append((n, S1, ST, var))
print(f"\n样本数 N={n}:")
print(f" S1 = {S1[0]:.4f}, S2 = {S1[1]:.4f}, S3 = {S1[2]:.4f}")
print(f" ST1 = {ST[0]:.4f}, ST2 = {ST[1]:.4f}, ST3 = {ST[2]:.4f}")
# 使用最大样本数的结果进行可视化
n_max, S1_final, ST_final, _ = results[-1]
fig, axes = plt.subplots(2, 2, figsize=(14, 12))
# 图1: 一阶Sobol指数
ax1 = axes[0, 0]
var_names = ['X₁', 'X₂', 'X₃']
x_pos = np.arange(len(var_names))
width = 0.35
bars1 = ax1.bar(x_pos - width/2, S1_final, width, label='估计值',
color='#3498db', edgecolor='black', linewidth=1.5)
bars2 = ax1.bar(x_pos + width/2, [0.3139, 0.4424, 0.0], width, label='解析值',
color='#e74c3c', edgecolor='black', linewidth=1.5)
ax1.set_ylabel('一阶Sobol指数 Sᵢ', fontsize=12)
ax1.set_title(f'一阶Sobol指数 (N={n_max})', fontsize=14, fontweight='bold')
ax1.set_xticks(x_pos)
ax1.set_xticklabels(var_names, fontsize=12)
ax1.legend(fontsize=11)
ax1.grid(True, alpha=0.3, axis='y')
# 添加数值标签
for bar in bars1:
height = bar.get_height()
ax1.text(bar.get_x() + bar.get_width()/2., height,
f'{height:.3f}', ha='center', va='bottom', fontsize=10)
# 图2: 总效应指数
ax2 = axes[0, 1]
bars3 = ax2.bar(x_pos - width/2, ST_final, width, label='估计值',
color='#2ecc71', edgecolor='black', linewidth=1.5)
bars4 = ax2.bar(x_pos + width/2, [0.5574, 0.4424, 0.2437], width, label='解析值',
color='#e74c3c', edgecolor='black', linewidth=1.5)
ax2.set_ylabel('总效应指数 STᵢ', fontsize=12)
ax2.set_title(f'总效应Sobol指数 (N={n_max})', fontsize=14, fontweight='bold')
ax2.set_xticks(x_pos)
ax2.set_xticklabels(var_names, fontsize=12)
ax2.legend(fontsize=11)
ax2.grid(True, alpha=0.3, axis='y')
# 添加数值标签
for bar in bars3:
height = bar.get_height()
ax2.text(bar.get_x() + bar.get_width()/2., height,
f'{height:.3f}', ha='center', va='bottom', fontsize=10)
# 图3: 收敛曲线
ax3 = axes[1, 0]
S1_conv = np.array([r[1] for r in results])
ST_conv = np.array([r[2] for r in results])
ax3.semilogx(sample_sizes, S1_conv[:, 0], 'bo-', label='S₁', linewidth=2, markersize=8)
ax3.semilogx(sample_sizes, S1_conv[:, 1], 'rs-', label='S₂', linewidth=2, markersize=8)
ax3.semilogx(sample_sizes, S1_conv[:, 2], 'g^-', label='S₃', linewidth=2, markersize=8)
ax3.axhline(y=0.3139, color='blue', linestyle='--', alpha=0.5)
ax3.axhline(y=0.4424, color='red', linestyle='--', alpha=0.5)
ax3.axhline(y=0.0, color='green', linestyle='--', alpha=0.5)
ax3.set_xlabel('样本数量', fontsize=12)
ax3.set_ylabel('一阶Sobol指数', fontsize=12)
ax3.set_title('Sobol指数收敛曲线', fontsize=14, fontweight='bold')
ax3.legend(fontsize=11)
ax3.grid(True, alpha=0.3)
# 图4: 饼图 - 方差分解
ax4 = axes[1, 1]
# 计算交互效应
S_interaction = ST_final - S1_final
# 确保所有值为非负
S1_final_nonneg = np.maximum(S1_final, 0)
S_interaction_nonneg = np.maximum(S_interaction, 0)
# 归一化
total = np.sum(S1_final_nonneg) + np.sum(S_interaction_nonneg)
if total > 0:
sizes = [
max(S1_final_nonneg[0], 0), # X1主效应
max(S1_final_nonneg[1], 0), # X2主效应
max(S1_final_nonneg[2], 0), # X3主效应
max(S_interaction_nonneg[0] + S_interaction_nonneg[1] + S_interaction_nonneg[2], 0) # 交互效应总和
]
# 确保所有sizes都是正数
sizes = [max(s, 1e-10) for s in sizes]
labels = [
f'X₁主效应\n({S1_final[0]:.3f})',
f'X₂主效应\n({S1_final[1]:.3f})',
f'X₃主效应\n({S1_final[2]:.3f})',
f'交互效应\n({np.sum(S_interaction):.3f})'
]
colors_pie = ['#3498db', '#e74c3c', '#2ecc71', '#f39c12']
wedges, texts, autotexts = ax4.pie(sizes, labels=labels, colors=colors_pie,
autopct='%1.1f%%', startangle=90,
textprops={'fontsize': 10})
ax4.set_title('方差分解', fontsize=14, fontweight='bold')
plt.tight_layout()
plt.savefig(f'{OUTPUT_DIR}case3_sobol_analysis.png', dpi=150, bbox_inches='tight')
plt.close()
print(f"\n案例3完成!图片已保存至 {OUTPUT_DIR}case3_sobol_analysis.png")
# =============================================================================
# 案例4: 基于Kriging代理模型的可靠性分析
# =============================================================================
class SimpleKriging:
"""简化版Kriging模型实现"""
def __init__(self, length_scale=1.0, sigma_f=1.0, sigma_n=1e-5):
self.length_scale = length_scale
self.sigma_f = sigma_f
self.sigma_n = sigma_n
self.X_train = None
self.y_train = None
self.K = None
self.alpha = None
def kernel(self, x1, x2):
"""平方指数核函数"""
sqdist = np.sum((x1 - x2)**2)
return self.sigma_f**2 * np.exp(-0.5 * sqdist / self.length_scale**2)
def fit(self, X, y):
"""训练Kriging模型"""
self.X_train = np.array(X)
self.y_train = np.array(y)
n = len(y)
# 构建核矩阵
self.K = np.zeros((n, n))
for i in range(n):
for j in range(n):
self.K[i, j] = self.kernel(self.X_train[i], self.X_train[j])
# 添加噪声
self.K += self.sigma_n**2 * np.eye(n)
# 计算alpha = K^(-1) * y
try:
L = np.linalg.cholesky(self.K)
self.alpha = np.linalg.solve(L.T, np.linalg.solve(L, self.y_train))
except np.linalg.LinAlgError:
# 如果Cholesky失败,使用直接求逆
self.alpha = np.linalg.solve(self.K, self.y_train)
def predict(self, X, return_std=True):
"""预测"""
X = np.atleast_2d(X)
n_test = len(X)
mu = np.zeros(n_test)
sigma = np.zeros(n_test)
for i in range(n_test):
# 计算k*
k_star = np.array([self.kernel(X[i], x_train) for x_train in self.X_train])
# 预测均值
mu[i] = k_star @ self.alpha
if return_std:
# 预测方差
k_star_star = self.kernel(X[i], X[i])
try:
L = np.linalg.cholesky(self.K)
v = np.linalg.solve(L, k_star)
sigma[i] = np.sqrt(k_star_star - np.dot(v, v))
except:
sigma[i] = 0.0
if return_std:
return mu, sigma
return mu
def case4_kriging_reliability():
"""案例4: 基于Kriging的可靠性分析"""
print("\n" + "="*60)
print("案例4: 基于Kriging代理模型的可靠性分析")
print("="*60)
# 定义问题:悬臂梁(简化到2D便于可视化)
# 变量:P (载荷) 和 sigma_y (屈服强度)
# 固定:L=2.0, b=0.1, h=0.2
def g_2d(P, sigma_y):
"""2D极限状态函数"""
L, b, h = 2.0, 0.1, 0.2
sigma_max = (6 * P * L) / (b * h**2) / 1e6
return sigma_y - sigma_max
# 步骤1: 初始采样(LHS)
print("\n步骤1: 初始LHS采样...")
n_init = 20
# P ~ N(5000, 500), sigma_y ~ N(250, 25)
P_samples = np.random.normal(5000, 500, n_init)
sy_samples = np.random.normal(250, 25, n_init)
X_train = np.column_stack([P_samples, sy_samples])
y_train = np.array([g_2d(P, sy) for P, sy in X_train])
print(f" 初始样本数: {n_init}")
print(f" 失效样本数: {np.sum(y_train <= 0)}")
# 步骤2: 构建初始Kriging模型
print("\n步骤2: 构建Kriging代理模型...")
kriging = SimpleKriging(length_scale=1000.0, sigma_f=50.0, sigma_n=1e-5)
kriging.fit(X_train, y_train)
print(" Kriging模型训练完成")
# 步骤3: 自适应加点(U学习函数)
print("\n步骤3: 自适应加点...")
n_adaptive = 15
X_all = X_train.copy()
y_all = y_train.copy()
for i in range(n_adaptive):
# 在候选点上评估U函数
P_candidates = np.random.normal(5000, 500, 1000)
sy_candidates = np.random.normal(250, 25, 1000)
X_candidates = np.column_stack([P_candidates, sy_candidates])
mu, sigma = kriging.predict(X_candidates)
# U函数 = |mu| / sigma
U = np.abs(mu) / (sigma + 1e-10)
# 选择U最小的点
idx_min = np.argmin(U)
x_new = X_candidates[idx_min]
y_new = g_2d(x_new[0], x_new[1])
# 添加到训练集
X_all = np.vstack([X_all, x_new])
y_all = np.append(y_all, y_new)
# 重新训练
kriging.fit(X_all, y_all)
if (i + 1) % 5 == 0:
print(f" 已添加 {i+1} 个自适应点,总样本数: {len(X_all)}")
print(f"\n 最终样本数: {len(X_all)}")
print(f" 失效样本数: {np.sum(y_all <= 0)}")
# 步骤4: 基于代理模型进行可靠性分析
print("\n步骤4: 基于Kriging进行FORM分析...")
# 使用大量样本通过Kriging估计Pf
n_mc = 100000
P_mc = np.random.normal(5000, 500, n_mc)
sy_mc = np.random.normal(250, 25, n_mc)
X_mc = np.column_stack([P_mc, sy_mc])
mu_mc, sigma_mc = kriging.predict(X_mc)
# 使用预测均值估计Pf
Pf_kriging = np.sum(mu_mc <= 0) / n_mc
# 考虑预测不确定性的Pf估计(重要性采样)
Pf_kriging_unc = np.sum(stats.norm.cdf(0, mu_mc, sigma_mc)) / n_mc
print(f" Kriging估计 (均值): Pf = {Pf_kriging:.6e}")
print(f" Kriging估计 (考虑不确定性): Pf = {Pf_kriging_unc:.6e}")
# 与直接MC对比
y_true = np.array([g_2d(P, sy) for P, sy in X_mc])
Pf_true = np.sum(y_true <= 0) / n_mc
print(f" 真实MC估计: Pf = {Pf_true:.6e}")
print(f" 相对误差: {abs(Pf_kriging - Pf_true)/Pf_true*100:.2f}%")
# 可视化
fig, axes = plt.subplots(2, 2, figsize=(14, 12))
# 创建网格用于可视化
P_range = np.linspace(3500, 6500, 100)
sy_range = np.linspace(180, 320, 100)
P_grid, sy_grid = np.meshgrid(P_range, sy_range)
# 图1: Kriging预测均值
ax1 = axes[0, 0]
X_grid = np.column_stack([P_grid.ravel(), sy_grid.ravel()])
mu_grid, sigma_grid = kriging.predict(X_grid)
mu_grid = mu_grid.reshape(P_grid.shape)
contour1 = ax1.contour(P_grid, sy_grid, mu_grid, levels=10, cmap='viridis')
ax1.clabel(contour1, inline=True, fontsize=8)
ax1.contour(P_grid, sy_grid, mu_grid, levels=[0], colors='red', linewidths=3)
# 标记样本点
safe_mask = y_all > 0
ax1.scatter(X_all[safe_mask, 0], X_all[safe_mask, 1], c='blue', s=50,
alpha=0.7, edgecolors='black', label='安全样本')
ax1.scatter(X_all[~safe_mask, 0], X_all[~safe_mask, 1], c='red', s=50,
marker='x', linewidths=3, label='失效样本')
ax1.set_xlabel('载荷 P (N)', fontsize=12)
ax1.set_ylabel('屈服强度 σy (MPa)', fontsize=12)
ax1.set_title('Kriging预测均值', fontsize=14, fontweight='bold')
ax1.legend(fontsize=10)
ax1.grid(True, alpha=0.3)
# 图2: Kriging预测标准差
ax2 = axes[0, 1]
sigma_grid_plot = sigma_grid.reshape(P_grid.shape)
im = ax2.contourf(P_grid, sy_grid, sigma_grid_plot, levels=20, cmap='YlOrRd')
plt.colorbar(im, ax=ax2, label='预测标准差')
ax2.contour(P_grid, sy_grid, mu_grid, levels=[0], colors='blue', linewidths=2)
ax2.scatter(X_all[:, 0], X_all[:, 1], c='black', s=30, alpha=0.5, label='样本点')
ax2.set_xlabel('载荷 P (N)', fontsize=12)
ax2.set_ylabel('屈服强度 σy (MPa)', fontsize=12)
ax2.set_title('Kriging预测不确定性', fontsize=14, fontweight='bold')
ax2.legend(fontsize=10)
ax2.grid(True, alpha=0.3)
# 图3: 真实极限状态函数
ax3 = axes[1, 0]
g_true = np.array([g_2d(P, sy) for P, sy in X_grid]).reshape(P_grid.shape)
contour3 = ax3.contour(P_grid, sy_grid, g_true, levels=10, cmap='viridis')
ax3.clabel(contour3, inline=True, fontsize=8)
ax3.contour(P_grid, sy_grid, g_true, levels=[0], colors='red', linewidths=3, label='g=0')
ax3.scatter(X_all[safe_mask, 0], X_all[safe_mask, 1], c='blue', s=50,
alpha=0.7, edgecolors='black', label='安全样本')
ax3.scatter(X_all[~safe_mask, 0], X_all[~safe_mask, 1], c='red', s=50,
marker='x', linewidths=3, label='失效样本')
ax3.set_xlabel('载荷 P (N)', fontsize=12)
ax3.set_ylabel('屈服强度 σy (MPa)', fontsize=12)
ax3.set_title('真实极限状态函数', fontsize=14, fontweight='bold')
ax3.legend(fontsize=10)
ax3.grid(True, alpha=0.3)
# 图4: 误差分析
ax4 = axes[1, 1]
error = np.abs(mu_grid - g_true)
im2 = ax4.contourf(P_grid, sy_grid, error, levels=20, cmap='Reds')
plt.colorbar(im2, ax=ax4, label='绝对误差')
ax4.scatter(X_all[:, 0], X_all[:, 1], c='black', s=30, alpha=0.5)
ax4.set_xlabel('载荷 P (N)', fontsize=12)
ax4.set_ylabel('屈服强度 σy (MPa)', fontsize=12)
ax4.set_title(f'Kriging近似误差 (最大误差={np.max(error):.2f})', fontsize=14, fontweight='bold')
ax4.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig(f'{OUTPUT_DIR}case4_kriging_reliability.png', dpi=150, bbox_inches='tight')
plt.close()
print(f"\n案例4完成!图片已保存至 {OUTPUT_DIR}case4_kriging_reliability.png")
return kriging, X_all, y_all
# =============================================================================
# 动画:不确定性传播可视化
# =============================================================================
def create_uq_animation():
"""创建不确定性传播动画"""
print("\n" + "="*60)
print("创建不确定性传播动画...")
print("="*60)
# 设置随机种子
np.random.seed(42)
# 创建图形
fig, axes = plt.subplots(2, 2, figsize=(14, 12))
# 定义简单的线性模型: Y = 2*X1 + 3*X2
# X1 ~ N(5, 1), X2 ~ N(3, 0.5)
n_frames = 50
n_samples_per_frame = 20
# 存储历史
X1_all = []
X2_all = []
Y_all = []
def init():
for ax in axes.flat:
ax.clear()
return []
def update(frame):
for ax in axes.flat:
ax.clear()
# 生成新样本
X1_new = np.random.normal(5, 1, n_samples_per_frame)
X2_new = np.random.normal(3, 0.5, n_samples_per_frame)
Y_new = 2*X1_new + 3*X2_new
X1_all.extend(X1_new)
X2_all.extend(X2_new)
Y_all.extend(Y_new)
n_total = len(X1_all)
# 图1: X1分布
ax1 = axes[0, 0]
ax1.hist(X1_all, bins=30, density=True, alpha=0.7, color='blue', edgecolor='black')
ax1.axvline(x=5, color='red', linestyle='--', linewidth=2, label='理论均值=5')
x_theory = np.linspace(2, 8, 100)
ax1.plot(x_theory, stats.norm.pdf(x_theory, 5, 1), 'r-', linewidth=2, label='理论分布')
ax1.set_xlabel('X₁', fontsize=12)
ax1.set_ylabel('概率密度', fontsize=12)
ax1.set_title(f'输入变量 X₁ 分布 (N={n_total})', fontsize=12, fontweight='bold')
ax1.legend(fontsize=9)
ax1.grid(True, alpha=0.3)
ax1.set_xlim(2, 8)
# 图2: X2分布
ax2 = axes[0, 1]
ax2.hist(X2_all, bins=30, density=True, alpha=0.7, color='green', edgecolor='black')
ax2.axvline(x=3, color='red', linestyle='--', linewidth=2, label='理论均值=3')
x_theory2 = np.linspace(1, 5, 100)
ax2.plot(x_theory2, stats.norm.pdf(x_theory2, 3, 0.5), 'r-', linewidth=2, label='理论分布')
ax2.set_xlabel('X₂', fontsize=12)
ax2.set_ylabel('概率密度', fontsize=12)
ax2.set_title(f'输入变量 X₂ 分布 (N={n_total})', fontsize=12, fontweight='bold')
ax2.legend(fontsize=9)
ax2.grid(True, alpha=0.3)
ax2.set_xlim(1, 5)
# 图3: 散点图 X1 vs X2
ax3 = axes[1, 0]
ax3.scatter(X1_all, X2_all, c='purple', alpha=0.5, s=20)
ax3.set_xlabel('X₁', fontsize=12)
ax3.set_ylabel('X₂', fontsize=12)
ax3.set_title(f'输入空间样本 (N={n_total})', fontsize=12, fontweight='bold')
ax3.grid(True, alpha=0.3)
ax3.set_xlim(2, 8)
ax3.set_ylim(1, 5)
# 图4: Y分布(输出)
ax4 = axes[1, 1]
ax4.hist(Y_all, bins=30, density=True, alpha=0.7, color='orange', edgecolor='black')
y_mean_theory = 2*5 + 3*3 # 19
y_std_theory = np.sqrt(4*1 + 9*0.25) # sqrt(6.25) = 2.5
ax4.axvline(x=y_mean_theory, color='red', linestyle='--', linewidth=2, label=f'理论均值={y_mean_theory}')
y_theory = np.linspace(10, 28, 100)
ax4.plot(y_theory, stats.norm.pdf(y_theory, y_mean_theory, y_std_theory),
'r-', linewidth=2, label='理论分布')
ax4.set_xlabel('Y = 2X₁ + 3X₂', fontsize=12)
ax4.set_ylabel('概率密度', fontsize=12)
ax4.set_title(f'输出变量 Y 分布 (N={n_total})', fontsize=12, fontweight='bold')
ax4.legend(fontsize=9)
ax4.grid(True, alpha=0.3)
ax4.set_xlim(10, 28)
# 添加统计信息
if n_total > 0:
stats_text = f'样本数: {n_total}\n'
stats_text += f'Y均值: {np.mean(Y_all):.2f} (理论: {y_mean_theory})\n'
stats_text += f'Y标准差: {np.std(Y_all):.2f} (理论: {y_std_theory})'
fig.text(0.5, 0.02, stats_text, ha='center', fontsize=11,
bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.5))
plt.tight_layout(rect=[0, 0.05, 1, 1])
return []
# 创建动画
anim = animation.FuncAnimation(fig, update, frames=n_frames, init_func=init,
blit=False, interval=200, repeat=True)
# 保存动画
anim.save(f'{OUTPUT_DIR}uq_propagation_animation.gif', writer='pillow', fps=5, dpi=100)
plt.close()
print(f"动画创建完成!已保存至 {OUTPUT_DIR}uq_propagation_animation.gif")
# =============================================================================
# 主函数
# =============================================================================
def main():
"""主函数"""
print("="*60)
print("主题048:不确定性量化与可靠性分析")
print("Uncertainty Quantification and Reliability Analysis")
print("="*60)
print("\n本程序包含以下4个案例:")
print("1. 蒙特卡洛模拟与拉丁超立方采样对比")
print("2. 一阶可靠性方法(FORM)")
print("3. 全局敏感性分析 - Sobol指数")
print("4. 基于Kriging代理模型的可靠性分析")
# 运行所有案例
case1_mc_lhs_comparison()
case2_form_analysis()
case3_sobol_analysis()
case4_kriging_reliability()
create_uq_animation()
print("\n" + "="*60)
print("所有案例完成!")
print("="*60)
print("\n输出文件:")
print(" - case1_mc_lhs_comparison.png")
print(" - case2_form_analysis.png")
print(" - case3_sobol_analysis.png")
print(" - case4_kriging_reliability.png")
print(" - uq_propagation_animation.gif")
if __name__ == "__main__":
main()




AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献84条内容
已为社区贡献84条内容

所有评论(0)