东华复试day17
OJ85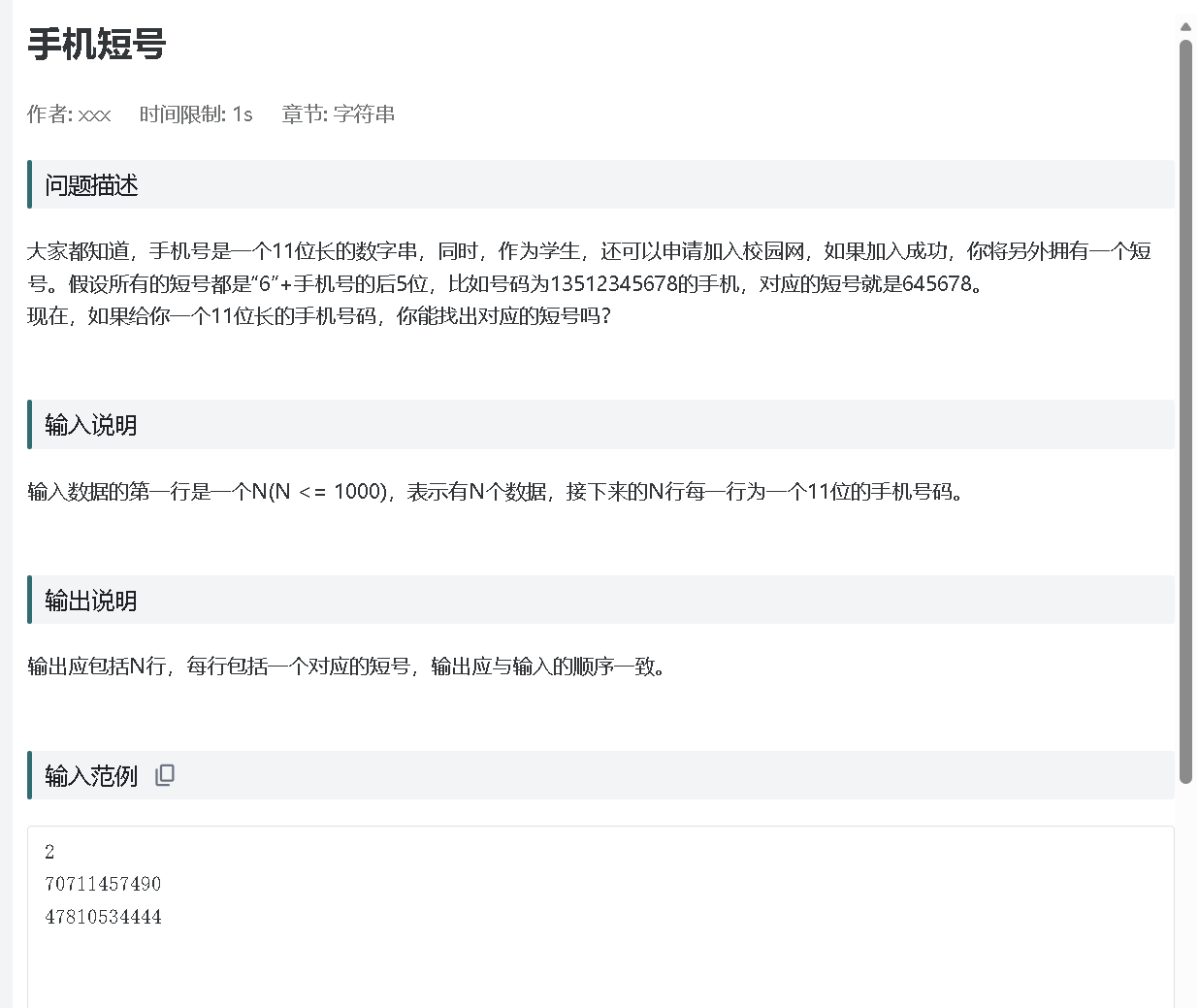
个人总结:将电话号码用字符串形式存储,str 长度为12,存储11个数字和结束符,scanf("%s", str)一次读取11个数字,scanf("%s")自动跳过空白字符不需要 getchar()
#include <stdio.h>
int main(){
int n;
scanf("%d", &n);
for(int i = 0; i < n; i++){
char str[12];
scanf("%s", str);
printf("6");
for(int j = 6; j < 11; j++)
printf("%c", str[j]);
printf("\n");
}
return 0;
}OJ86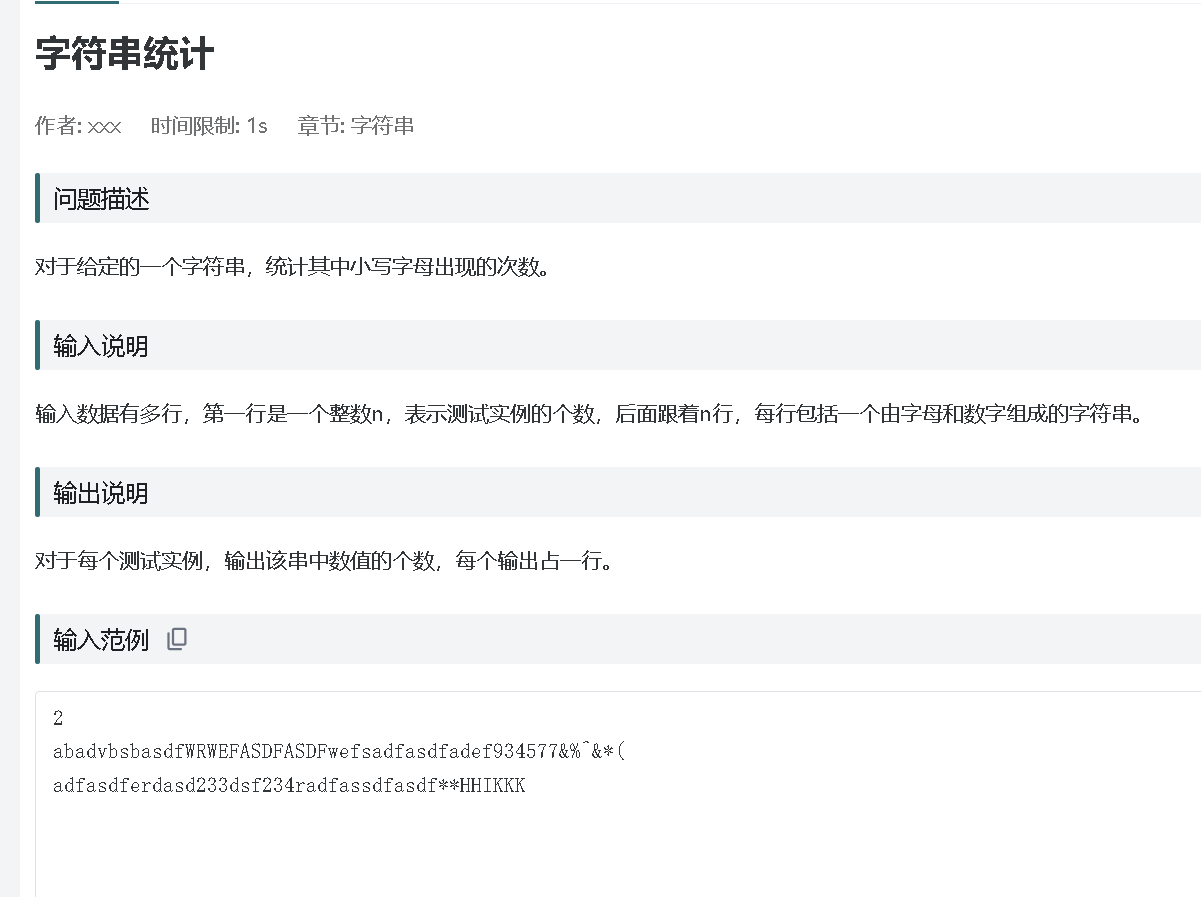
个人总结:遍历字符串若为小写字母,count++
#include <stdio.h>
#include <string.h>
int main(){
int n;
scanf("%d", &n);
getchar();//吸收scanf留下的换行符
for(int i = 0; i < n; i++){
char str[999];
int count = 0;
fgets(str, sizeof(str), stdin);
str[strcspn(str, "\n")] = '\0';
int len = strlen(str);
for(int j = 0; j < len; j++){
if(str[j] >= 'a' && str[j] <= 'z')
count++;
}
printf("%d\n", count);
}
return 0;
}OJ87
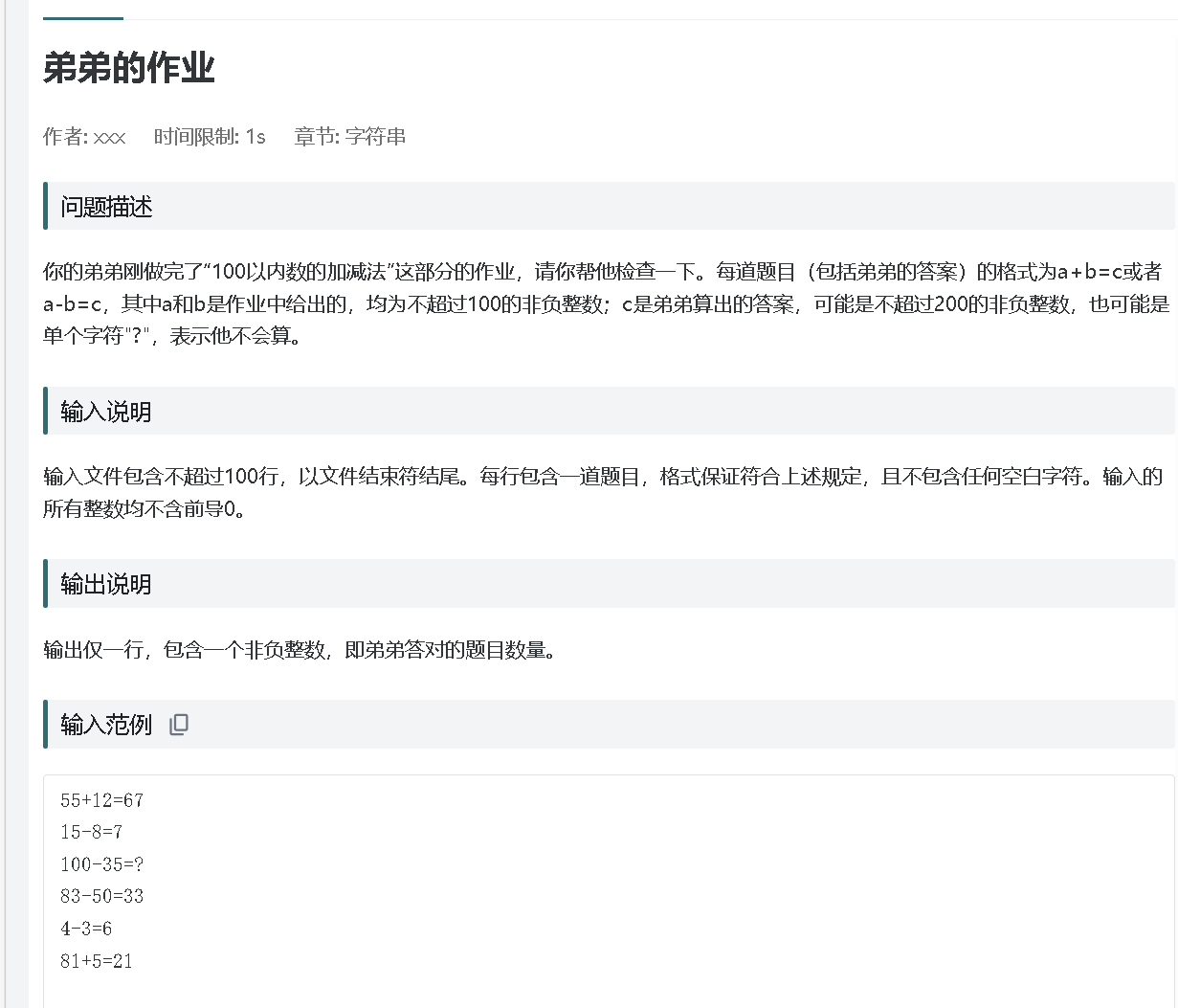
个人总结:fgets(line, sizeof(line), stdin):逐行读取输入,直到文件结束(符合题目 “以文件结束符结尾” 的要求);strcspn(line, "\n"):找到换行符的位置,将其替换为\0,避免换行符干扰字符串解析。sscanf(line, "%d%c%d=%d", &a, &op, &b, &c):按格式解析每行字符串
#include <stdio.h>
#include <string.h>
int main() {
char line[50]; // 存储每行题目(足够容纳最长格式,如99+99=198)
int correct = 0; // 答对的题目数
// 逐行读取输入,直到文件结束
while (fgets(line, sizeof(line), stdin) != NULL) {
// 去掉换行符(fgets会读取换行符)
line[strcspn(line, "\n")] = '\0';
int a, b, c;
char op; // 存储+或-
int ret; // 存储sscanf的返回值
// 解析格式:a+ b = c 或 a- b = c
ret = sscanf(line, "%d%c%d=%d", &a, &op, &b, &c);
int right_ans; // 正确答案
int is_right = 0; // 是否答对
if (ret == 4) { // 弟弟写了具体答案(不是?)
// 计算正确答案
if (op == '+') {
right_ans = a + b;
} else if (op == '-') {
right_ans = a - b;
}
// 对比答案(注意a-b可能为负数,但题目说c是非负整数,答错)
if (right_ans == c && right_ans >= 0) {
is_right = 1;
}
} else { // 弟弟写了?,直接答错
is_right = 0;
}
if (is_right) {
correct++;
}
}
// 输出答对的数量
printf("%d\n", correct);
return 0;
}OJ88
个人总结:使用选择排序对字符串进行排序
#include <stdio.h>
#include <string.h>
int main(){
char str[201];
while(fgets(str, sizeof(str), stdin) != NULL){
str[strcspn(str, "\n")] = '\0';
int len = strlen(str);
for(int i = 0; i < len - 1; i++){
for(int j = i + 1; j < len; j++){
if(str[i] > str[j]){
char temp = str[i];
str[i] = str[j];
str[j] = temp;
}
}
}
printf("%s\n", str);
}
return 0;
}OJ89
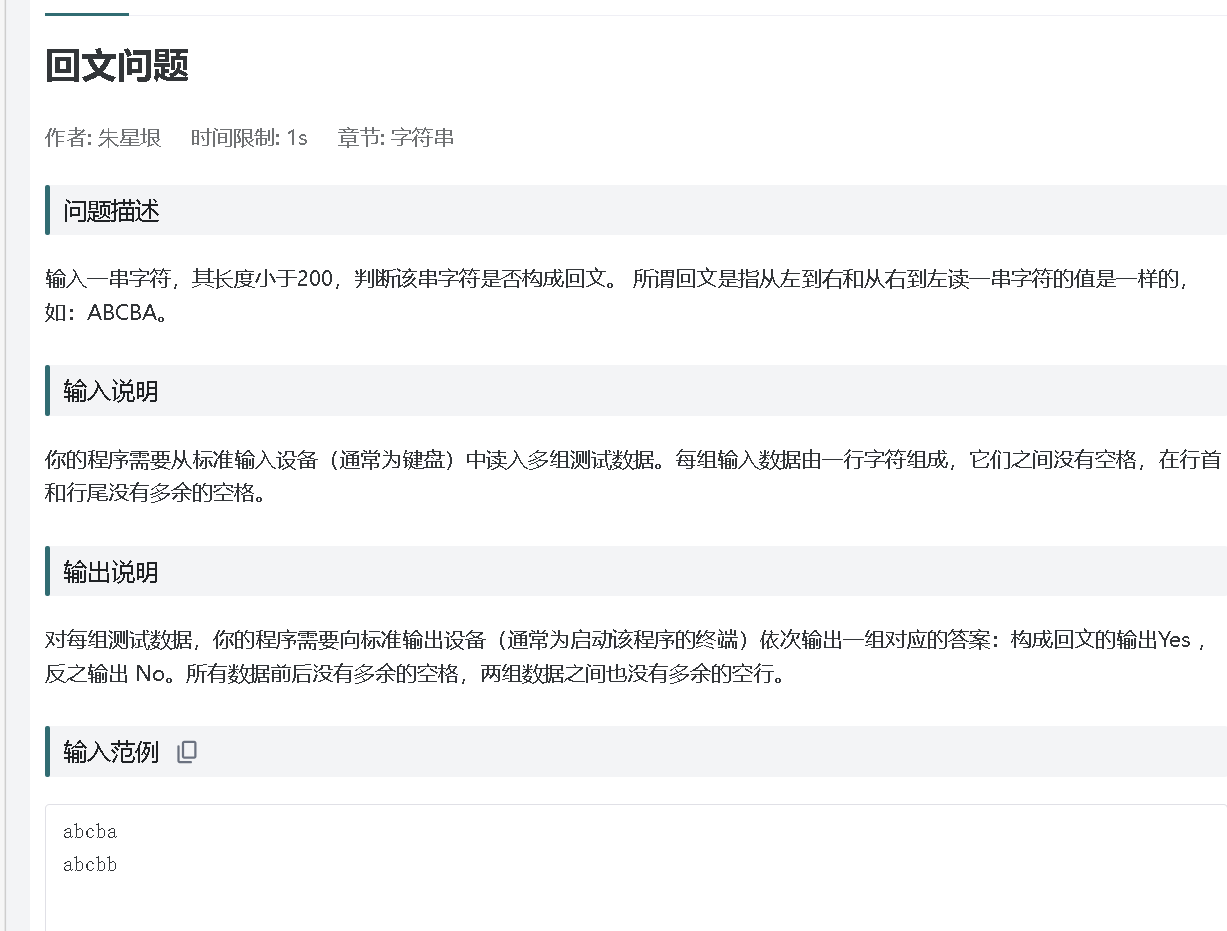
个人总结:利用函数来比较i和len-1-i
#include <stdio.h>
#include <string.h>
//判断字符数组(长度len)是否是回文
int isPalindrome(char str[], int len){
for(int i = 0; i < len / 2; i++){
if(str[i] != str[len - 1 - i])
return 0;
}
return 1;
}
int main(){
char str[201];
while(fgets(str, sizeof(str), stdin) != NULL){
str[strcspn(str, "\n")] = '\0';
int len = strlen(str);
if(isPalindrome(str, len))
printf("Yes\n");
else
printf("No\n");
}
return 0;
}OJ90
个人总结:遇到数字时,通过 current_num = current_num * 10 + (str[i] - '0') 拼接连续数字(自动忽略前导 0,如 “034” 会被拼接为 34);in_number 标记是否处于数字序列中,遇到字母时若处于数字序列,则将拼接好的数字存入数组,并重置状态
#include <stdio.h>
#include <string.h>
#include <ctype.h> // 用于isdigit()函数判断是否为数字
#define MAX_LEN 501 // 字符串最大长度(500+1)
#define MAX_NUM 100 // 最多提取的整数数量(足够使用)
int main() {
char str[MAX_LEN];
// 逐行读取输入,直到文件结束
while (fgets(str, MAX_LEN, stdin) != NULL) {
// 去掉换行符(fgets会读取换行符)
str[strcspn(str, "\n")] = '\0';
int nums[MAX_NUM] = {0}; // 存储提取的整数
int num_count = 0; // 整数个数
int current_num = 0; // 临时存储当前正在拼接的数字
int in_number = 0; // 标记是否正在读取数字序列(0:否,1:是)
// 遍历字符串每个字符
for (int i = 0; str[i] != '\0'; i++) {
if (isdigit(str[i])) { // 当前字符是数字
in_number = 1;
// 拼接数字:current_num = current_num * 10 + (当前数字-0的ASCII值)
current_num = current_num * 10 + (str[i] - '0');
} else { // 当前字符是字母,结束当前数字序列
if (in_number) { // 之前正在读取数字
nums[num_count++] = current_num;
current_num = 0; // 重置临时数字
in_number = 0; // 重置标记
}
}
}
// 处理字符串末尾的数字序列(如"a5"的5)
if (in_number) {
nums[num_count++] = current_num;
}
// 按格式输出:个数 + 空格分隔的整数
printf("%d", num_count);
for (int i = 0; i < num_count; i++) {
printf(" %d", nums[i]);
}
printf("\n");
}
return 0;
}The Transformer model is a neural network architecture based on the attention mechanism and has achieved great success in the field of natural language processing. Unlike traditional recurrent neural networks, Transformers do not rely on step-by-step sequence processing. Instead, they use self-attention mechanisms to process the entire sequence simultaneously. This architecture not only improves the model’s ability to perform parallel computation but also enables it to capture long-range dependencies more effectively. In machine translation tasks, the Transformer model can dynamically assign attention weights according to the relationships between different words in a sentence, thereby producing more accurate translations. In addition, Transformer architectures have been widely applied to tasks such as text generation, speech recognition, and even image processing. In recent years, most large-scale pre-trained language models have been built upon the Transformer architecture, which has significantly accelerated the development of artificial intelligence technologies.
Transformer 模型是一种基于注意力机制的神经网络架构,在自然语言处理领域取得了巨大成功。与传统的循环神经网络不同,Transformer 不依赖逐次的序列处理,而是通过自注意力机制同时处理整个序列。这种架构不仅提升了模型的并行计算能力,还能更有效地捕捉长距离依赖关系。
在机器翻译任务中,Transformer 模型可以根据句子中不同单词之间的关联动态分配注意力权重,从而生成更准确的翻译结果。此外,Transformer 架构还被广泛应用于文本生成、语音识别乃至图像处理等任务。近年来,绝大多数大规模预训练语言模型都基于 Transformer 架构构建,这极大地推动了人工智能技术的发展。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)