让Agent聊天就能变强实战指南(非常详细),普林斯顿OpenClaw-RL框架从入门到精通,收藏这一篇就够了!
Princeton 大学 Mengdi Wang 和 Ling Yang 团队于 2026 年 3 月在 arXiv 上发布了这篇 OpenClaw-RL,论文标题是 “OpenClaw-RL: Train Any Agent Simply by Talking”。
这篇论文试图回答一个很朴素却被忽视已久的问题:Agent 每次和环境交互后收到的「下一步状态信号」(next-state signal),比如用户的回复、终端的输出、GUI 的状态变化、测试的通过与否,这些信号里蕴含着丰富的训练信息,为什么没有人把它们当作在线学习的数据源?
作者们识别出 next-state signal 中包含两种可回收的「信号浪费」:一种是评价性信号(evaluative signal),告诉你做得好不好;另一种是指导性信号(directive signal),告诉你应该怎么改。前者通过 PRM Judge 转化为标量奖励,后者通过一种叫做 Hindsight-Guided On-Policy Distillation(OPD) 的方法转化为 token 级别的优势监督。两者互补组合,在仿真实验中取得了显著的优化效果。
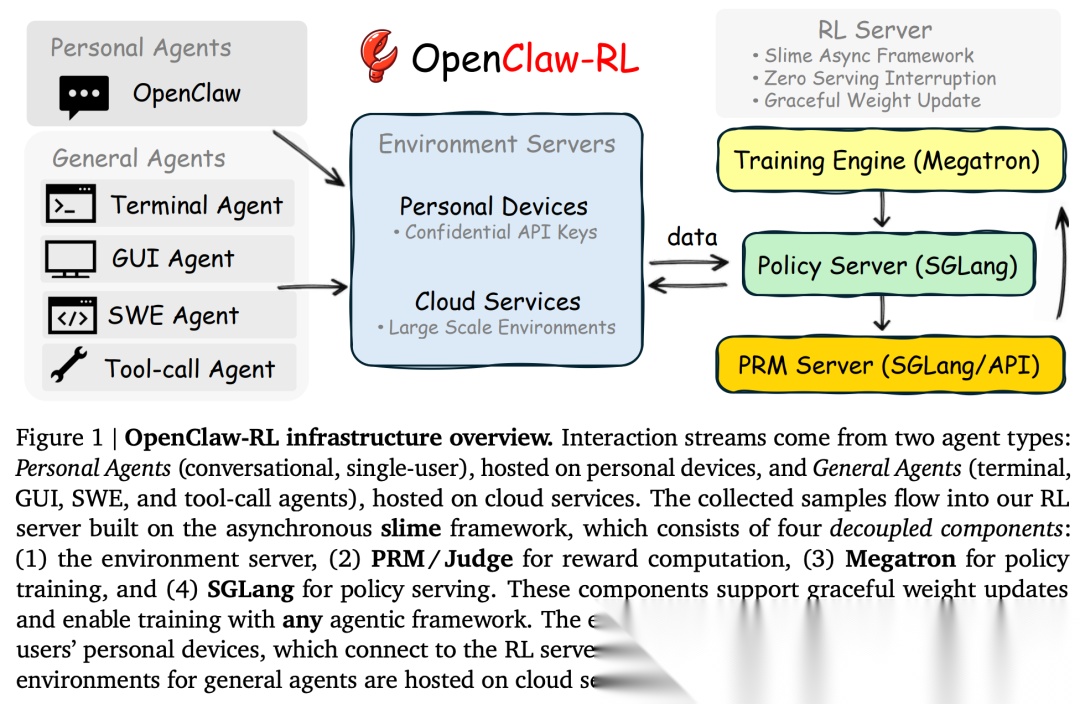
从工程角度看,OpenClaw-RL 基于 slime 异步框架,将 Policy Serving、Environment、PRM Judging、Policy Training 四个组件完全解耦,做到了「边服务边训练」的零中断持续学习。它同时支持 Personal Agent(个人对话助手)和 General Agent(Terminal、GUI、SWE、Tool-call),是目前已知的第一个将多种异构交互流统一到同一训练循环中的 Agentic RL 系统。
从技术方案的新颖性来看,OPD 的设计颇有巧思 —— 它不需要外部教师模型、不需要配对偏好数据,而是利用 next-state signal 提取 hint,再让同一个模型在 hint 增强的上下文下「自我蒸馏」。这个思路将 hindsight relabeling、context enrichment 和 on-policy distillation 三条线索统一到了在线场景中。实验虽然以仿真为主,规模不算大,但思路清晰、框架完整,值得细读。

1. Introduction
每一次 Agent 交互都在产生训练数据 —— 只是我们一直在扔掉它。
想象一下这个场景:你部署了一个 AI Agent,它每天处理成百上千的请求。每次它给出一个回复 a_t 后,紧接着就会收到一个下一步状态信号s_{t+1} —— 可能是用户的回复,可能是终端的 stdout,可能是 GUI 界面的变化,也可能是测试用例的通过与否。
现有的系统怎么处理这些信号呢?
仅仅把它们当作下一轮动作的上下文,然后就丢掉了。
💡
作者们提出了一个核心观点:next-state signal 不仅仅是上下文,它们还隐含着对 a_t 的评价和纠正方向。而且,这种信号在所有类型的交互中都会自然产生 —— 对话、终端执行、GUI 操作、SWE 任务、工具调用 —— 却没有任何现有的 Agentic RL 系统把它们当作在线学习的数据源加以回收利用。
作者们将这些被浪费的信号归纳为两种类型:
浪费 1 —— 评价性信号(Evaluative Signals)
Next-state signal 天然地对前一步的动作进行了隐式打分:
•
用户重新提问(re-query) → 说明不满意
•
测试通过 → 说明做对了
•
错误堆栈(error trace) → 说明出了问题
这本身就是一种天然的过程奖励(Process Reward),不需要任何额外的标注流水线。
🔍
但现实是,PRM(Process Reward Model)几乎只在数学推理这种有可验证 ground truth 的场景下被研究过。对于 personal agent,它可以逐轮捕捉用户满意度;对于 general agent,它提供了长时域任务所急需的密集逐步信用分配(dense per-step credit assignment)。现有系统要么忽略这种信号,要么只在离线、预收集的数据上利用它。
浪费 2 —— 指导性信号(Directive Signals)
除了打分,next-state signal 往往还携带着方向性信息。
比如用户说:「你应该先检查一下文件再编辑」—— 这不仅告诉你回复错了,还指出了哪些 token 应该不同、应该怎么改。类似地,一个详细的 SWE 错误追踪(error trace)往往隐含着具体的修正方向。
🔍
当前 RLVR 方法使用标量奖励,根本无法把这种方向性信息转化为定向的策略梯度。蒸馏方法(distillation)又依赖于预先整理好的反馈-响应对,而非实时信号。Hindsight relabeling 和 context-enriched distillation 等方法虽然证明了:在上下文中加入结构化的纠正信息可以显著提升输出质量 —— 但这些方法都在固定数据集上运行,无法用于在线学习。
OpenClaw-RL 的提出
基于以上观察,作者们提出了 OpenClaw-RL —— 一个统一回收两种 next-state signal 浪费的框架,同时支持 Personal Agent 和 General Agent。
⚙
OpenClaw-RL 是一个完全解耦的异步架构,基于 slime 框架构建。它将 Policy Serving、Rollout 收集、PRM 判分、Policy Training 作为四个独立的异步循环运行,彼此之间没有任何阻塞依赖。在 Personal Agent 场景下,模型可以通过正常使用自动优化 —— 你只需要和它聊天,它就会变得更好。
具体来说,OpenClaw-RL 提供了两种互补的优化方案:
•
Binary RL:利用 PRM 将评价性信号转化为标量过程奖励,做标准的 PPO 训练
•
Hindsight-Guided On-Policy Distillation(OPD):从 next-state signal 中提取文本 hint,构建增强的 teacher 上下文,蒸馏出 token 级别的方向性监督 —— 这种信号比任何标量奖励都要丰富
两者的组合在仿真实验中带来了显著收益。
论文的四大贡献
将 next-state signal 作为在线学习数据源:识别出 next-state signal 同时编码了评价性和指导性信息,并在异构交互类型中统一回收
OpenClaw-RL 基础设施:首个统一多种并发交互流的系统,支持零中断服务、会话感知的多轮追踪、优雅权重更新、灵活 PRM 支持和大规模环境并行化
两种互补的信号回收方法:Binary RL + Hindsight-Guided OPD,前者提供广覆盖的粗粒度信号,后者在有丰富指导性信号的样本上提供 token 级精细监督
跨场景的实验验证:在 Personal Agent 个性化和 General Agent(Terminal、GUI、SWE、Tool-call)RL 训练中均得到了验证
本章小结:Introduction 点明了一个被广泛忽视的问题 —— Agent 交互产生的 next-state signal 是天然的在线学习数据源,但现有系统把它当纯上下文处理而浪费了。作者将这些被浪费的信号分为评价性信号和指导性信号两类,分别用 Binary RL 和 OPD 方法进行回收,并通过完全解耦的异步架构实现了「边服务边训练」的持续学习。
2. Problem Setting
统一建模:把所有交互流都看成 MDP。
OpenClaw-RL 的策略模型 \pi_\theta 同时接收多种交互流 —— 个人对话、终端执行、GUI 交互、SWE 任务、工具调用 —— 并将它们从推理管线中解耦。作者将每种交互流形式化为一个 MDP ( m a t h c a l S , m a t h c a l A , m a t h c a l T , r ) (mathcal{S}, mathcal{A}, mathcal{T}, r) (mathcalS,mathcalA,mathcalT,r):
•
状态 s _ t i n m a t h c a l S s\_t in mathcal{S} s_tinmathcalS:截至第 t 轮的完整对话或环境上下文
•
动作 a _ t i n m a t h c a l A a\_t in mathcal{A} a_tinmathcalA:Agent 的回复,即 \pi_\theta 生成的 token 序列
•
转移 m a t h c a l T ( s _ t + 1 ∣ s _ t , a _ t ) mathcal{T}(s\_{t+1} | s\_t, a\_t) mathcalT(s_t+1∣s_t,a_t):给定环境后是确定性的; s _ t + 1 s\_{t+1} s_t+1 就是用户回复、执行结果或工具输出
•
奖励 r ( a _ t , s _ t + 1 ) r(a\_t, s\_{t+1}) r(a_t,s_t+1):通过 PRM Judge 从 next-state signal 中推断
🔍
为什么奖励是 r(a_t, s_{t+1}) 而不是传统的 r ( s _ t , a _ t ) r(s\_t, a\_t) r(s_t,a_t)?
因为在这里,奖励信号的关键来源是下一个状态 s _ t + 1 s\_{t+1} s_t+1。用户的回复、终端的输出、测试的结果 —— 这些都是在动作执行之后才产生的。
奖励的信息量取决于你怎么「读」这个 next-state signal。
在标准 RLVR(Reinforcement Learning with Verifiable Rewards)中,整条轨迹只在最终得到一个 outcome reward o o o。但过程奖励r(a_t, s_{t+1}) 依赖于每一步的 next-state,包含的信息要丰富得多。
💡
更重要的是,当 next-state signal 包含了明确的指导性信息 —— 比如用户指出「应该怎么做」时 —— on-policy distillation 可以将这些方向性信号转化为 token 级别的教师监督,实现比标量奖励更精细的定向改进。这是本文核心方法论的理论基础。
这个形式化虽然简洁,却统一了所有的交互场景。无论是用户在手机上和 Personal Agent 聊天,还是 Terminal Agent 在沙箱里执行命令,还是 GUI Agent 在屏幕上点击操作 —— 都可以纳入同一个 MDP 框架,用同一套训练循环来优化。
本章小结:Problem Setting 将所有交互流统一建模为 MDP,核心在于将奖励定义为 r ( a _ t , s _ t + 1 ) r(a\_t, s\_{t+1}) r(a_t,s_t+1),即依赖于 next-state signal 而非预定义的 outcome。这个看似简单的形式化,为后续的 Binary RL 和 OPD 方法奠定了统一的理论基础,也使得不同类型的交互流可以无差别地进入同一个训练循环。
3. OpenClaw-RL Infrastructure: Unified System for Personal and General Agents
将 Personal Agent 的自动优化与 General Agent 的大规模 RL 训练,统一到同一个框架之中。
3.1 Asynchronous Pipeline with Four Decoupled Components
OpenClaw-RL 的核心架构原则是完全解耦(full decoupling)。整个系统由四个完全独立的异步循环组成,彼此之间没有任何阻塞依赖:
这四个组件各干各的:
•
Policy Serving(SGLang):负责给用户/环境提供推理服务
•
Environment(HTTP/API):接收 Agent 的动作,返回 next-state signal
•
Reward Judging(SGLang/API):PRM 对每一轮交互进行评分
•
Policy Training(Megatron):根据收集到的数据更新策略参数
💡
关键在于:模型在服务下一个用户请求的同时,PRM 在判定上一个回复的质量,训练器在执行梯度更新 —— 三者互不等待。这正是让「从实时、异构的交互流中持续训练」变得可行的原因:没有任何一条交互流需要被暂停或攒批来迁就其他组件的节奏。
对于 Personal Agent,模型通过机密 API 连接,实现私有安全部署,不需要对个人 Agent 框架做任何修改,权重更新时也不会中断推理服务。
对于 General Agent 的大规模训练,这种异步设计让每个组件都可以独立推进,从而缓解了长时域 rollout 造成的长尾问题(long-tail problem)—— 不会因为某些 rollout 特别慢而拖住整个训练流程。
3.2 Session-Aware Environment Server for Personal Agents
Personal Agent 的「环境」其实就是用户的个人设备,它通过机密 API 连接到 RL Server。
每个 API 请求被分为两类:
•
Main-line turn(主线轮次):Agent 的主要回复和工具执行结果,这些构成可训练的样本
•
Side turn(辅助轮次):辅助查询、记忆整理、环境转换等,会被转发但不产生训练数据
🔍
为什么要区分 main-line turn 和 side turn?
因为在实际使用中,Agent 除了回答用户问题,还会做很多「幕后工作」(比如整理记忆、调用工具查信息等)。如果不加区分地把所有轮次都当训练数据,会引入大量噪声。通过这种分类,RL 框架可以精确定位哪些轮次属于哪些会话(session),实现有针对性的训练。
目前系统只在 main-line turn 上训练。每一个新的 main-line 请求的消息体中,都包含了对前一轮的反应 —— 无论是用户的回复还是环境的执行结果。这就自然成为了前一轮奖励计算所需的 next-state signal s _ t + 1 s\_{t+1} s_t+1。
3.3 Scalability: From Single-User Personalization to Large-Scale Agent Deployment
OpenClaw-RL 被设计为覆盖从单用户到大规模部署的完整频谱。
对于 Personal Agent:
•
环境是单个用户的设备
•
交互流是稀疏的、基于会话的、高度个性化的
对于 General Agent:
•
基于 slime 框架,继承了可扩展的训练基础设施
•
进一步支持云端托管的环境,覆盖多种 Agent 场景
•
数百个并行环境托管在云服务上,产生密集的结构化执行信号流,支撑大规模 RL 训练
3.4 Support for Multiple Real World Scenarios
OpenClaw-RL 在开源实现中支持了覆盖最常见真实部署场景的多种 Agent 类型:
| Setting | Environment | Next-state Signal | Horizon |
|---|---|---|---|
| OpenClaw | Personal devices | user response / tool-call results | Long |
| Terminal | Shell execution sandbox | stdout/stderr, exit code | Long |
| GUI | Screen state + accessibility tree | Visual state diff, task progress | Long |
| SWE | Code repository + test suite | Test verdicts, diff, lint output | Long |
| Tool-call | API/function execution | Return values, error traces | Medium |
作者对各类 Agent 的定位也说得比较清楚:
•
Terminal Agent:计算机使用系统的核心组件,高效、低成本、天然适配 LLM 的文本接口
•
GUI Agent:覆盖 Terminal Agent 无法直接访问的能力(如视觉界面和指针交互),是更通用的计算机使用任务所必需的
•
SWE Agent:特别重要的编码 Agent 类别,环境通过测试、diff、静态分析提供丰富的可执行反馈
•
Tool-call Agent:外部工具调用可以提升推理能力和事实准确性
🔍
从 Table 1 可以看出,所有场景的共同点是:每一步交互都会产生一个 next-state signal,而这个信号的形式虽然不同(stdout、visual diff、test verdict、return value),但都可以被 PRM Judge 解读为奖励信号。这就是 OpenClaw-RL 能够统一处理它们的根本原因。
3.5 Non-Blocking Record and Observability
所有交互和奖励评估都以 JSONL 格式实时记录:完整消息历史、prompt/response 文本、工具调用、next-state 内容、逐票 PRM 评分、选定的 hint(OPD 用)、accept/reject 决策等。
几个关键设计点:
•
非阻塞日志:写操作是 fire-and-forget 的,跑在后台线程上,不给 serving 或 PRM 路径增加任何延迟
•
按权重更新边界清理:日志文件在每次权重更新时被清除,确保日志始终对应单一策略版本
本章小结:OpenClaw-RL 的基础设施设计围绕一个核心原则 —— 完全解耦。Policy Serving、Environment、PRM Judging、Policy Training 四个组件作为独立的异步循环运行,互不阻塞。对于 Personal Agent,通过 session-aware 的会话分类机制(main-line vs side turn)精确识别可训练的交互轮次;对于 General Agent,通过云端并行化支持 Terminal、GUI、SWE、Tool-call 等多种场景的大规模 RL 训练。整个系统实现了「边服务边训练」的零中断持续学习,并通过非阻塞日志确保完整的可观测性。
4. Learning from Next-State Signals: Unified RL Across Interaction Types
将异构交互流中的 next-state signal 转化为策略梯度 —— 这是整篇论文的方法论核心。
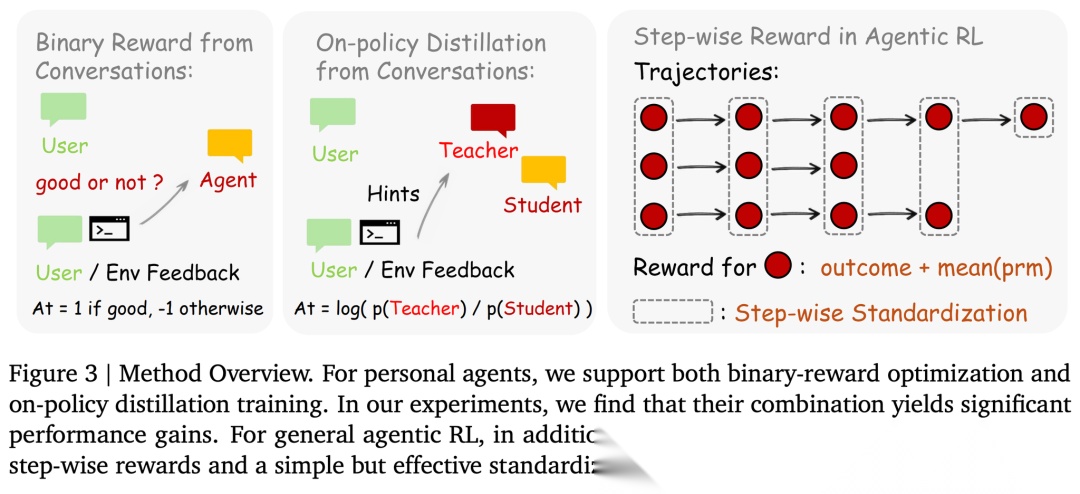
4.1 Binary RL for Personal Agent
将评价性 next-state signal 转化为标量过程奖励。
给定 Agent 的回复 a_t 和 next-state signal s _ t + 1 s\_{t+1} s_t+1,一个 Judge 模型对 a_t 的质量进行评估:
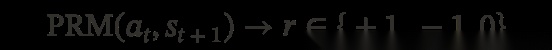
具体来说:
•
对于 工具调用结果:通常能得到明确的结论(成功/失败)
•
对于 用户的下一条回复:可能包含满意或不满意的信号
•
如果用户反应不明确:Judge 模型会根据场景进行估计(但鼓励用户提供更明确的反馈)
•
对于 General Agent:Judge 推理环境反馈是否指示了向任务目标的进展
为了提高判断的可靠性,作者运行 m 次独立查询,然后取多数投票:

🔍
为什么用多数投票而不是单次判断?
因为对话场景的奖励信号往往是模糊的 —— 用户的回复可能同时包含纠正和新问题,难以一次性准确判断。多次独立查询 + 多数投票可以有效降低单次判断的噪声。
直接用 A_t = r_{\text{final}} 作为优势(advantage),训练目标是标准的 PPO 裁剪代理目标(clipped surrogate),带有非对称边界:
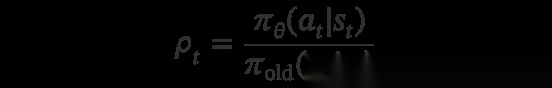
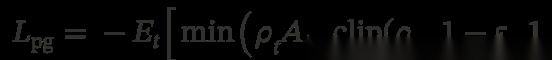

其中 v a r e p s i l o n = 0.2 varepsilon = 0.2 varepsilon=0.2, v a r e p s i l o n _ t e x t h i g h = 0.28 varepsilon\_{text{high}} = 0.28 varepsilon_texthigh=0.28, b e t a _ t e x t K L = 0.02 beta\_{text{KL}} = 0.02 beta_textKL=0.02。
🔍
为什么用非对称的 clip 边界( v a r e p s i l o n = 0.2 varepsilon = 0.2 varepsilon=0.2 vs v a r e p s i l o n _ t e x t h i g h = 0.28 varepsilon\_{text{high}} = 0.28 varepsilon_texthigh=0.28)?
这是一个常见的 PPO 技巧 —— 允许模型在正向奖励时有更大的更新空间(上界 0.28),而在负向奖励时更保守(下界 0.2),避免过度惩罚。
💡
值得注意的是,作者特别指出:
这是一个实时对话场景,没有 group 结构可用于标准化(不像 GRPO 那样可以在同一个问题的多个回复之间做标准化)。因此直接用 PRM 的判断结果作为优势,不做额外的 normalization。
4.2 Hindsight-Guided On-Policy Distillation (OPD) for Personal Agent
将方向性 next-state signal 转化为 token 级别的教师监督。
Binary RL 把整个 s_{t+1} 的信息压缩成了一个标量 r i n + 1 , − 1 , 0 r in {+1, -1, 0} rin+1,−1,0。但想想看,当用户写下「you should have checked the file before editing it」的时候,他传达的信息远不止「做错了」这么简单。他还指出了:哪些 token 应该不同,以及应该怎么改。
这些指导性信息(directive information)被标量奖励完全丢失了。
💡
OPD 的核心洞察是:
如果我们用从 s_{t+1} 中提取的文本 hint 来增强原始 prompt,同一个模型会产生一个不同的 token 分布 —— 一个「知道答案应该是什么」的分布。
而 hint 增强分布和原始分布之间的逐 token 差距,就提供了一个方向性的优势:正值表示模型应该增强这个 token,负值表示应该抑制这个 token。
这和现有方法有什么本质区别?
•
和 RLHF 不同:RLHF 用标量偏好信号,OPD 用 token 级别的方向性信号
•
和 DPO 不同:DPO 需要配对偏好数据,OPD 不需要
•
和标准 distillation 不同:标准蒸馏需要一个单独的、更强的教师模型,而 OPD 用的是同一个模型,只是看到了更多的信息(hint)
OPD 的完整流程分为四步:
Step 1. Hindsight Hint Extraction(后见之明提示提取)
Judge 模型给定 a_t 和 s _ t + 1 s\_{t+1} s_t+1,同时输出评分和 hint:

如果 score = +1(即这个回复有改进空间但不是完全错误),Judge 会生成一个简洁的 hint,包裹在 [HINT_START]…[HINT_END] 中。
💡
一个关键的设计选择:不直接使用 s_{t+1} 作为 hint。
原始的 next-state signal 往往很噪、冗长,或包含无关信息(比如用户的回复可能同时包含纠正和一个全新的问题)。
Judge 模型负责将 s_{t+1} 提粼为一个简洁、可执行的指令,通常是 1-3 句话,聚焦于「回复应该怎么做才不同」。这个提炼过程本身就是一个信号去噪步骤。
同样运行 m 次并行 Judge 调用。
Step 2. Hint Selection and Quality Filtering(提示选择与质量过滤)
在所有正向投票中,筛选出 hint 长度超过 10 个字符的,然后选择最长的一个(最信息量最大的)。如果没有有效 hint,则完全丢弃该样本。
🔍
这是一个刻意的设计:OPD 用样本质量换样本数量。
只有 next-state signal 中携带了清晰、可提取的纠正方向时,样本才进入训练。这种严格的过滤恰好与 Binary RL 互补:
•
Binary RL 接受所有评分的轮次,提供广覆盖的粗粒度信号;
•
OPD 只用少量精品样本,提供高分辨率的精细监督。
Step 3. Enhanced Teacher Construction(增强教师构建)
hint 被追加到最后一条用户消息中,格式为 [user’s hint / instruction]\n{hint},构造出一个增强的 prompt:
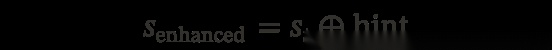
效果就相当于:如果用户一开始就告诉了模型「应该怎么做」,那么模型「本来会看到」的 prompt 就是这个样子。
Step 4. Token-Level Advantage(Token 级优势计算)
在 s_{\text{enhanced}} 下,用原始回复 a_t 作为 forced input,计算每个 token 的 log-probability。然后:

这个 token 级别的优势有非常直观的含义:
•
A _ t > 0 A\_t > 0 A_t>0:teacher(知道 hint 的)认为这个 token 应该更高概率出现 → student 应该增强它
•
A _ t < 0 A\_t < 0 A_t<0:teacher 认为这个 token 在给定 hint 后不太合适 → student 应该抑制它
💡
这里有一个巧妙之处:teacher 和 student 是同一个模型,区别仅仅在于 teacher 看到了增强后的 prompt(包含 hint)。
这意味着:在同一个回复内部,某些 token 会被增强,而另一些 token 会被抑制 —— 这种逐 token 的方向性引导是标量奖励完全做不到的。
标量奖励会把所有 token 往同一个方向推,而 OPD 可以在同一个回复里“有升有降”。
训练时仍然使用与公式 (1) 相同的 PPO 裁剪代理目标,但此时的 advantage 携带了每个样本远比标量奖励丰富得多的信息。
4.3 Combine Binary and OPD Methods
取长补短,缓冲各自的弱点。
作者很清楚地明确了两种方法的互补关系:
| Dimension | Binary RL | OPD | Combined |
|---|---|---|---|
| Signal type | 评价性(good/bad) | 方向性 | 评价性 + 方向性 |
| Advantage | Sequence-level 标量 | Token-level 方向性 | 混合 |
| Density | 所有评分的 turn | 仅接受 hint 的 turn | 所有评分的 turn |
| Signal richness | 每个 sample 1 个标量 | 每个 token 1 个值 | 每个 token 1 个值 |
简单来说:
•
Binary RL 是「广播型」:接受每一个评分的 turn,不需要 hint 提取,对任何 next-state signal 都工作(包括简短、隐含的反应)
•
OPD 是「精准型」:应该在交互流可能携带丰富指导性内容时启用(比如用户给出明确纠正,或环境产生详细的错误追踪)
实践中建议同时运行两者,通过加权损失函数组合。由于两种方法共享同一个 PPO loss,区别仅在于 advantage 的计算,因此可以直接将优势组合:
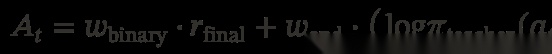
其中 w _ t e x t b i n a r y = w _ t e x t o p d = 1 w\_{text{binary}} = w\_{text{opd}} = 1 w_textbinary=w_textopd=1(默认值)。
🌟
在实验中,作者验证了这种组合方法取得了显著的性能提升 —— Combined 方法在 8 步更新后就达到了 0.76 的个性化得分(base model 只有 0.17),远超单独使用 Binary RL(0.25)或 OPD(0.25)。
4.4 Step-wise Reward for General Agentic RL
如何组合 outcome reward 和 process reward?
在长时域的 agentic 任务中,仅仅使用 outcome reward 意味着:只有最后一步才有梯度信号,绝大多数中间步骤完全没有监督。
PRM 通过对每一步的 next-state signal 进行判断,提供了贯穿整个轨迹的密集信用分配(dense credit assignment)。
🌟
RLAnything(Wang et al., 2026)已经提供了强有力的实证证据:
将逐步 PRM 信号与 outcome reward 结合,在 GUI Agent、文本游戏 Agent、编码任务中都持续优于仅用 outcome reward 的训练。
OpenClaw-RL 直接建立在这一洞察之上。
具体做法很直接 —— 将 outcome 和 process reward 简单相加。对于第 t 步,奖励为:
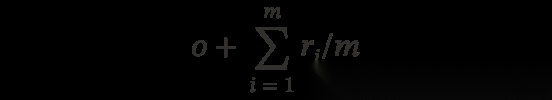
其中 r_i 由 \text{PRM}(a_t, s_{t+1}) 独立分配。
🔍
有了 step-wise reward,怎么计算 advantage 呢?
不像 GRPO 那样可以在同一个问题的多个回复之间健全地做标准化 —— 因为 agentic 任务的状态很难聚类。
作者的做法是:直接将相同 step index 的动作分为一组,在组内进行标准化(Step-wise Standardization)。这种做法简单但在实验中被证明是有效的。
本章小结:这是全文的方法论核心。对于 Personal Agent,Binary RL 通过 PRM + Majority Vote 将评价性信号转为标量奖励,OPD 通过四步流程(hint 提取 → 质量过滤 → teacher 构建 → token-level advantage)将指导性信号转为逐 token 的方向性监督,两者通过加权 advantage 合并。对于 General Agent,将 outcome reward 和 PRM step-wise reward 简单相加,通过 step index 分组做标准化。整个方法论的关键洞察是:同一个模型在看到 hint 增强的上下文后,token 分布的变化本身就编码了「应该怎么改」的信息。
5. Experiments
两条互补的实验线:Personal Agent 个性化 + General Agent 跨场景 RL。
实验沿两条线展开,共享同一套基础设施和训练循环:
•
Personal Agent Track(§5.3):验证对话 next-state signal 能否实现对个人用户偏好的持续个性化
•
General Agent Track(§5.4):验证同一套基础设施能否支持 Terminal、GUI、SWE、Tool-call 等多种 agentic 场景的可扩展 RL 训练
5.1 Personal Agent Setup
仿真结果验证了我们优化方案的有效性。
设定:用 LLM 模拟一个学生在个人电脑上使用 OpenClaw 完成作业,同时不想被发现在用 AI。回复是否「看起来像 AI 生成的」完全取决于学生的个人偏好和写作风格。
•
作业任务来自 GSM8K 数据集
•
策略模型:Qwen3-4B
•
学习率: 1 t i m e s 10 − 5 1 times 10^{-5} 1times10−5
•
KL 系数:0
•
每收集 16 个训练样本触发一次训练
设定:学生完成作业后,老师也用 OpenClaw 来批改。老师希望评语具体且友好。
•
策略模型和优化设置与 Student 设定相同

5.2 General Agent Setup
| Setting | Model | PRM |
|---|---|---|
| Terminal | Qwen3-8B | - |
| GUI | Qwen3VL-8B-Thinking | Qwen3VL-8B-Thinking |
| SWE | Qwen3-32B | - |
| Tool-call | Qwen3-4B-SFT | Qwen3-4B |
其中 Qwen3-4B-SFT 是由 slime 团队提供的、在 ReTool 数据集上微调的模型。
•
Terminal:SETA RL data
•
GUI:OSWorld-Verified(评估时排除了 chrome 和 multi-apps 任务)
•
SWE:SWE-Bench-Verified
•
Tool-call:DAPO RL data(在 AIME 2024 上评估)
•
学习率: 10 − 6 10^{-6} 10−6
•
KL 系数:0.01
•
Clip 下界:0.2,上界:0.28
•
每步采样任务数:GUI/SWE 为 8,Terminal 为 16,Tool-call 为 32
•
每个任务独立采样 8 次
•
最大交互步数:GUI 30 步,SWE 20 步,Terminal 10 步
5.3 Personal Agent Track: Learning from Conversational Signals
🌟
Takeaway [Q1]: Binary RL vs. OPD — when does each next-state signal type win?
Combined 方法取得了最有效的优化效果;OPD 优于 Binary RL,但由于训练样本稀疏,需要更长时间才能显现效果。
作者用与用户仿真相同的 LLM 对 OpenClaw 的首次生成进行量化个性化评分,报告 GSM8K 前 36 个问题的平均分。
| Method | Updated 8 steps | Updated 16 steps |
|---|---|---|
| Binary RL | 0.25 | 0.23 |
| OPD | 0.25 | 0.72 |
| Combined | 0.76 | 0.81 |
Base model 的得分是 0.17。几个关键发现:
•
Combined 方法在 8 步更新后就从 0.17 跳到了 0.76,提升惊人
•
OPD 单独使用时起效较慢(8 步时只有 0.25),但到 16 步时飙升至 0.72 —— 这正是因为 OPD 的严格过滤导致样本稀疏,需要更多交互才能积累足够的高质量训练数据
•
Binary RL 单独使用时效果有限(16 步后反而略降到 0.23),说明纯标量奖励在个性化场景下的信号不够丰富
🌟
Takeaway [Q2]: Does OpenClaw-RL improve personalization over time?
在 Combined 优化下,Student 设定只需 36 次做题交互、Teacher 设定只需 24 次批改交互,就能实现显著且可见的改进。
具体的优化效果非常直观:
•
Student 设定:经过 36 次交互后,Agent 学会了避免明显的「AI 味」表达 —— 不再使用「bold」之类的词,不再产生过度结构化的分步回答,转而采用更自然、随意的风格
•
Teacher 设定:经过 24 次交互后,Agent 学会了写出更友好、更具体的评语
🔍
这里需要指出的是:实验是在仿真环境中完成的(Student 和 Teacher 都由 LLM 模拟)。
虽然这种设定可以快速验证方案的有效性,但与真实用户交互可能存在差距。
不过从方法论角度看,仿真结果已经充分说明了 Binary RL + OPD 组合的互补优势。
5.4 General Agents: Unified RL Across Terminal, GUI, SWE, and Tool-Call
🌟
Takeaway [Q3]: Is OpenClaw-RL competitive as a general-purpose agentic RL framework?
实验表明,该框架可以处理多种真实场景(Terminal、GUI、SWE、Tool-call),支持不同模型规模和模态的大规模环境并行化。
作者跨四种真实 Agent 场景进行了实验,各场景使用了不同规模的并行环境:
•
Terminal:128 个并行环境
•
GUI:64 个并行环境
•
SWE:64 个并行环境
•
Tool-call:32 个并行环境
从 Figure 4 的训练曲线可以看到,四个场景的性能都随 RL 步数稳步提升,说明框架在不同场景下都能有效工作。
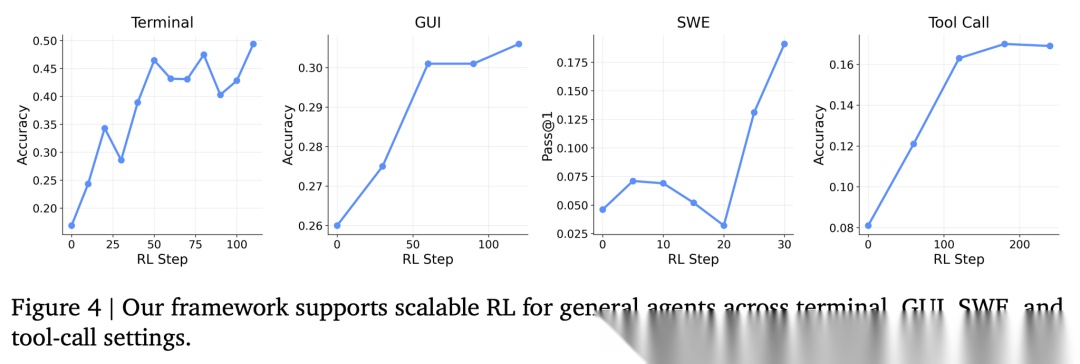
🌟
Takeaway [Q4]: Are process reward models vital for long-horizon tasks?
将 outcome 和 process reward 集成后,优化效果优于仅使用 outcome reward,但代价是需要额外资源来托管 PRM。
作者在 Tool-call(250 步)和 GUI(120 步)设定中进行了集成奖励的 RL 训练:
| Setting | Integrated (Outcome + Process) | Outcome Only |
|---|---|---|
| Tool-call | 0.30 | 0.17 |
| GUI | 0.33 | 0.31 |
两个关键结论:
•
Tool-call 场景:集成奖励带来了从 0.17 到 0.30 的显著提升(+76%),说明 process reward 在中等时域的推理任务中也非常重要
•
GUI 场景:提升相对较小(0.31 → 0.33),但依然正向
🔍
一个值得关注的 trade-off 是:托管 PRM 需要额外的计算资源。对于资源受限的场景,仅用 outcome reward 也是可行的;但如果追求更强的优化效果,尤其是在长时域任务中,process reward 的价值不可忽视。
本章小结:实验从两条线验证了 OpenClaw-RL 的有效性。Personal Agent 方面,Combined(Binary RL + OPD)方法在仅 8 步更新后就实现了从 0.17 到 0.76 的个性化得分飞跃,OPD 和 Binary RL 各有所长、组合互补。General Agent 方面,框架在 Terminal、GUI、SWE、Tool-call 四种真实场景中都展现了稳定的 RL 训练提升,且集成 process reward 进一步增强了优化效果。实验规模以仿真和中等规模为主,但方法论的互补性和框架的通用性得到了充分验证。
7. Conclusion
一句话概括:让 Agent 从自己正在进行的交互中持续学习。
每一次 Agent 交互都会产生一个 next-state signal,它编码了 Agent 做得如何、以及通常应该怎么做才不同。OpenClaw-RL 建立在一个核心洞察之上:
💡
这些信号是流无关的(stream-agnostic),一个策略可以同时从所有信号中学习。个人对话、终端执行、GUI 交互、SWE 任务、工具调用轨迹 —— 全部流入同一个训练循环。
•
Binary RL 将评价性信号转化为标量过程奖励
•
OPD 将指导性信号转化为 token 级别的优势监督
•
两者的组合带来了显著的优化增益
最终的结果是:一个系统可以同时为个人用户做个性化优化,并在长时域 agentic 任务上持续改进 —— 完全从它已有的交互中训练,不需要额外的数据收集。
写在最后
OpenClaw-RL 的最大价值,可能不在于它的具体技术方案有多新颖(Binary RL 是标准 PPO,OPD 也是已有思路的组合),而在于它提出了一个很好的问题:Agent 每天产生的大量交互信号正在被白白浪费,我们能不能系统性地把它们回收为在线学习的数据源?
这个问题的回答方式也很务实。不搞复杂的离线数据管线,不搞昂贵的人工标注,而是直接从实时交互中提取评价性和指导性信号。OPD 的设计尤其值得注意 —— 用同一个模型在不同上下文下的 token 分布差异来构造方向性优势,这个思路简洁而有效,避免了对外部教师或配对数据的依赖。
当然,论文也有明显的局限。Personal Agent 的实验完全在仿真环境中完成,LLM 模拟的「用户」与真实用户的行为分布可能存在显著差异。General Agent 的实验虽然覆盖了多个场景,但每个场景的训练规模不算大,且缺少与其他 agentic RL 框架的直接对比。process reward 在 GUI 场景中的提升也相对有限,说明 PRM 的效果可能依赖于环境反馈的结构化程度。
不过,从系统设计的角度来看,将 Personal Agent 和 General Agent 统一到同一个四组件解耦架构中、实现零中断的持续学习,这本身就是一个有价值的工程贡献。随着 Agent 部署规模的扩大,如何高效利用交互信号进行在线优化,将成为一个越来越重要的问题。OpenClaw-RL 为这个方向提供了一个清晰的框架和思路。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献195条内容
已为社区贡献195条内容

所有评论(0)