DataFlow框架实战教程(非常详细),大模型数据准备与自动化从入门到精通,收藏这一篇就够了!
在大语言模型快速发展的今天,高质量数据的需求呈爆炸式增长 。就像做菜需要新鲜食材一样,训练一个好用的 LLM,离不开大量干净、多样、语义丰富、任务对齐的数据。但现实是:目前大多数团队还在用“脚本拼凑法”准备数据——比如写一堆 Python 脚本,手动清洗、抽样、改格式、加提示词,再一个个跑;流程没有统一设计,别人看不懂、没法复现,也很难根据模型反馈动态调整数据。
换句话说:
- 没有清晰的“数据操作单元”(比如像 PyTorch 里的
nn.Linear那样可复用、可组合的模块); - 工作流靠文档或口头约定,缺乏形式化表达和自动验证;
- 数据生成和模型训练脱节,无法让模型“边学边挑、边挑边造”。
为解决这些问题,论文提出了 DataFlow —— 一个由大语言模型驱动的、统一且可扩展的数据准备框架。
核心设计理念:把数据准备变成“可编程、可调试、可优化”的系统工程
DataFlow 不是又一个清洗脚本合集,而是一个系统级抽象框架 ,它的设计思想借鉴了深度学习框架:
- 模块化:每个数据操作封装成一个独立、带明确输入输出的“算子”,例如
FilterByLength(按文本长度过滤)、RewriteWithLLM、SynthesizeSQLFromText(从自然语言生成 SQL)等; - 可复用 :近 200 个算子全部开源、带文档、支持参数配置,可跨项目直接调用;
- 可组合:算子能像乐高一样自由连接,形成复杂流水线,例如:
原始文本 → 去噪 → 分句 → LLM 改写 → 质量打分 → 高分样本保留 → 加入训练集; - 可调试 & 可优化 :提供类似 PyTorch 的声明式 API,例如:
from dataflow import Pipeline, FilterByLength, RewriteWithLLMpipeline = Pipeline( FilterByLength(min_len=10, max_len=512), RewriteWithLLM(model="qwen2-7b", prompt_template="请用更专业的术语重述:{text}"), # ... 更多步骤)
你可以逐个 step 运行、打印中间结果、修改参数、对比效果,就像调试模型一样调试数据流。
六大开箱即用的通用领域流水线(Domain-General Pipelines)
DataFlow 内置了覆盖主流 AI 任务的六大标准流水线,无需从零开发:
| 流水线名称(中文) | 对应英文名 | 典型用途 | 关键能力 |
|---|---|---|---|
| 文本数据流水线(Text Pipeline) | Text Pipeline | 构建通用语言建模/对话数据集 | 去重、去广告、语言识别、毒性过滤、风格增强 |
| 数学推理流水线(Mathematical Reasoning Pipeline) | Mathematical Reasoning Pipeline | 生成/增强 MATH、GSM8K 类数学题 | 解题链(CoT)注入、错误分析反演、多解生成 |
| 代码数据流水线(Code Pipeline) | Code Pipeline | 构建编程任务训练数据(如 HumanEval) | 代码补全扰动、测试用例驱动合成、执行反馈过滤 |
| 文本到 SQL 流水线(Text-to-SQL Pipeline) | Text-to-SQL Pipeline | 提升自然语言转数据库查询能力 | Schema-aware 生成、执行验证、错误 SQL 修复 |
| 智能体增强检索流水线(Agentic RAG Pipeline) | Agentic RAG Pipeline | 构建支持多步推理的 RAG 训练数据 | 模拟 agent 决策路径、工具调用链、反思重写 |
| 大规模知识抽取流水线(Large-Scale Knowledge Extraction Pipeline) | Large-Scale Knowledge Extraction Pipeline | 从网页/文档中结构化抽取三元组、事件等 | 实体链接 + 关系分类 + 置信度校准 |
举个例子:在 Text-to-SQL 流水线 中,DataFlow 不只是“把句子变 SQL”,而是:
① 先用 LLM 生成多个候选 SQL;
② 在真实数据库上执行它们,看哪些能跑通、返回合理结果;
③ 把执行成功 + 语义匹配度高的样本留下,失败的则触发“错误分析”算子,让 LLM 解释哪里错了,并生成修正版;
④ 最终输出高质量、可执行、带 trace 的 (text, sql, execution_result) 三元组。
这比传统“静态模板生成”或“单次 LLM 输出”鲁棒得多。
DataFlow-Agent:用自然语言“说清楚需求”,自动生成可运行流水线
即使你不会写代码,也能用 DataFlow!论文进一步提出 DataFlow-Agent —— 一个智能代理,它能把你的一句话需求 ,自动翻译成完整、正确、可执行的 DataFlow 流水线。
它分三步完成:
- 算子合成 :理解你的意图,从 200+ 算子库中匹配并配置最合适的组合;
- 流水线规划 :决定算子执行顺序、数据流向、分支逻辑,避免语义冲突;
- 迭代验证 :生成初版 pipeline 后,自动运行小样本、检查输出质量(如解答是否正确、错误分析是否合理),不达标就让 LLM 自动修正,直到满足要求。
示例输入(自然语言):
“帮我生成 5000 条适合微调代码助手的 Python 数据,要求:函数签名清晰、含 docstring、有至少 2 个边界测试用例,并过滤掉所有含 exec() 或 eval() 的危险代码。”DataFlow-Agent 输出:一段可直接运行的 Python pipeline 代码,包含
GeneratePythonFunc,AddDocstringWithLLM,GenerateTestCases,FilterDangerousCode等算子串联,且已通过安全性和功能性验证。
实验效果:不止“能用”,而且“更好用”
论文在六大典型场景下验证 DataFlow 效果,结果表明:用 DataFlow 构建的数据,比人工精标数据和专用合成方法效果更优 。
- Text-to-SQL 任务 :在 SynSQL 基线上提升 ** +3% 执行准确率** (即生成的 SQL 真正在数据库跑通的比例);
- 代码能力评测 :平均提升 +7% 通过率 ;
- 数学推理任务 :分数提升 1–3 个绝对点 ;
- 更惊人的发现 :仅用 DataFlow 自动生成的 1 万条样本,就能让一个基础模型(base model)的表现超过那些用 100 万条 Infinity-Instruct 数据训练的同类模型 。
这说明:数据质量 > 数据数量 ,而 DataFlow 正是提升“单位数据价值”的操作系统。
总结定位:为数据为中心的人工智能打造“数据操作系统”
DataFlow 不只是一个工具包,它定义了一种新的数据准备范式:
- 它把散乱的数据脚本,升级为可版本控制、可协作、可测试、可优化的软件工程实践 ;
- 它让数据工程师、算法研究员、甚至领域专家(如数学老师、DBA 工程师),都能以低门槛方式参与高质量数据共建;
- 它为未来“模型与数据联合进化”提供了底层支撑。
简言之:
如果 PyTorch 是“模型的操作系统”,
那么 DataFlow 就是“数据的操作系统”。
1 引言
大型语言模型已经从实验室里的研究原型,迅速成长为自然语言处理乃至更广泛人工智能领域的基础性基础设施 。这个转变的起点,是 OpenAI 推出 GPT 系列模型——它依靠大规模人工标注数据进行训练,正式开启了大模型时代。后续的“缩放定律”研究反复证实了一个核心结论:模型性能好坏,最关键的因素不是模型有多大,而是训练所用的数据有多好、有多少 。
随着模型参数量持续飙升,下游任务也变得越来越复杂,训练数据的规模和语义多样性也随之爆炸式增长。今天的 LLM 开发,早已不是简单地“喂一堆文本进去”,而是一整套多阶段、重语义的数据准备流水线。这套流水线要融合多种操作:用 LLM 自动生成新数据、对已有数据做精细打磨、过滤掉低质样本、再针对特定领域做深度转换——整个过程可能涉及数万亿个 token 。
但问题来了:
虽然高质量数据如此关键,LLM 的数据准备工作却长期处于“碎片化”状态,缺乏统一标准 。现实中,大多数工程师还在靠手写零散脚本、临时拼凑流程来干活。这些做法存在三大硬伤:
- 没有清晰的「数据流」抽象:不知道数据从哪来、经过哪些步骤、变成什么样;
- 没有定义好的「原子操作」:比如“让 LLM 给图片写一段描述”这件事,每次都要重新写 prompt、调接口、解析结果,无法复用;
- 没有流水线级的优化能力:比如多个 filter 步骤能否合并?某个生成步骤是否可以缓存结果?没人管。
结果就是:一个项目里跑通的 pipeline,换到另一个项目几乎没法直接复用;想对比两种数据清洗方法的效果?得重写一遍整个流程;更别说审计、复现或协作开发了。
这个问题在当前趋势下被进一步放大:越来越多的 LLM 后训练任务(post-training tasks)要求极精细的语义控制 ,比如:
- 指令微调:要让模型学会“按用户要求做事”,数据就得包含大量真实、多样、结构清晰的指令-响应对;
- 思维链生成:数据必须显式包含推理步骤,不能只给答案;
- 函数调用:数据需精准匹配工具 API 的输入/输出格式。
这些任务中,数据不仅要有“丰富语义”,更要“语义准确” ——错一个标点、少一步推理,模型就学歪了。而传统“先收集、再清洗、最后扔进训练”的粗放模式,根本扛不住这种精度要求。
为应对这一困局,最近出现了一些数据整理框架,比如 NeMo Curator和 Data-Juicer。它们功能很强:支持图文 caption 生成、文本重写、分类打标、多模态处理等,大幅提升了构建超大规模语料库的效率。
但它们的本质仍是「抽取 + 过滤」导向:重点是从现有数据里挑出好样本 ,而不是主动创造、迭代打磨新数据 。它们的抽象层也不支持“模型在环”的生成式工作流——即让 LLM 不仅当“工人”,还当“质检员”和“设计师”,边生成、边评估、边修改,反复迭代。
这就导致一个尴尬现实:当你的核心目标是合成高质量数学推理题或构建能调用工具的智能体数据时,这些框架反而成了累赘——因为它们的设计初衷,压根不是为这类“以合成为中心”的流程服务的。
更关键的是,LLM 的角色正在发生根本转变:
它们不再只是数据的消费者 ,
更日益成为数据的生产者 。
为什么?因为请人标注海量高质量数据太贵了!于是大家开始用 LLM 自己造数据:让一个强模型生成题目和答案,再让另一个模型学习——这叫“LLM-based data synthesis”。最新研究表明,在很多场景下,精心设计的合成数据,效果甚至超过人工精挑细选的真实数据 。这彻底颠覆了我们对“数据价值”的认知:数据质量,正越来越多地取决于“怎么造”,而不只是“从哪来”。
所以,我们提出一个根本性主张:
LLM 驱动的数据合成,不该是 pipeline 里的一个可选插件,而应成为数据准备框架的“一等公民”——就像 PyTorch 里的 torch.nn.Module 是模型构建的一等公民一样。
为此,一个理想的统一框架,必须满足四个核心要求:
- 细粒度、可组合的操作符(operators) :支持“模型在环”的生成与语义精修,比如:“让 LLM 把这道题改得更难一点,但保持知识点不变”;
- 显式、可验证的流水线定义 :整个 pipeline 必须像代码一样清晰可读、可检查、可共享,成为跨领域通用的开源协议(类似
torch.nn.Sequential的标准化表达); - 后端无关 :不绑定某家大模型 API,也不限定存储方式,方便自由切换;
- 支持原理性的流程编排、复用与优化 :不仅能拼接 pipeline,还能自动发现冗余步骤、推荐替代 operator、甚至让 AI 助手帮你写新 pipeline。
这四大要求,共同指向一个范式转移:
数据准备,正从“事后清洗语料”,转向“以 LLM 为中心的主动构建”——通过多次合成 + 多轮精修 ,打造高保真、语义丰富、任务对齐的合成语料库。
正是基于这一范式转移,我们提出了 DataFlow :一个统一、自动化的 LLM 驱动数据准备框架。它的核心是一个叫 DataFlow-Agent 的智能体,能让用户直接用自然语言描述需求,自动生成可执行的 pipeline 。
DataFlow 的设计哲学很明确:把 LLM 放在操作符生态系统的绝对中心 。绝大多数 operator 都是 LLM 驱动的;只有极少数简单任务才用规则或小模型实现。
框架内置 180+ 个可复用 operator ,分为四类:
- 生成类 :如“生成数学题”、“生成 SQL 查询”、“生成函数调用示例”;
- 评估类 :如“判断答案是否正确”、“评估推理步骤完整性”、“检测幻觉”;
- 过滤类 :如“过滤低质量响应”、“去重”、“按难度分档”;
- 精修类 :如“增强逻辑连贯性”、“添加思维链步骤”、“对齐领域术语”。
同时提供 90+ 个可复用 prompt 模板 ,确保同一 operator 在不同任务中行为一致、结果可比。
基于这些基础构件,DataFlow 预置了一套覆盖六大场景的前沿(SOTA)合成 pipeline :
- 数学推理
- 原始文本
- 编程
- 文本转 SQL
- 智能体风格 RAG 数据
- 大规模网页/PDF QA 抽取
所有 pipeline 都严格遵循 DataFlow 的统一抽象,无需任何任务专属的胶水代码(glue code) ,全部采用 “生成 → 评估 → 过滤 → (可选)精修” 的标准流程。
为了让 DataFlow 易用、易扩展、易维护,它采用了 PyTorch 风格的编程接口 :
- 所有核心概念(抽象、全局存储、LLM 服务、operator、prompt 模板、pipeline)都封装成模块化的 Python 类和函数;
- 拒绝复杂 YAML 配置或 shell 脚本,全程 Python 代码驱动,IDE 友好(支持自动补全、跳转、调试);
- operator、模板、pipeline 可完全脱离主仓库独立开发,打包成标准 Python 包(即 DataFlow-Extensions ),供社区发布和复用;
- 框架自带一套命令行工具(CLI),能一键生成新 extension 的项目骨架(从 operator stub 到完整 pipeline 仓库),大幅降低贡献门槛。
最后,DataFlow-Agent 是整个框架的“智能指挥官”:
- 它能听懂你写的自然语言需求(比如:“帮我做一个能从 PDF 提取金融问答对的 pipeline,要求答案必须引用原文”),自动生成可运行代码;
- 当遇到没定义过的 operator 时,它还能自动调用 LLM 合成新 operator,并尝试调试运行——真正实现“用语言编程”。
我们在六个典型 pipeline 上做了大量实验,结果表明:DataFlow 的设计理念在各种数据准备场景中都高度有效,稳定产出高质量训练数据。
具体效果如下(全部对比当前最强基线):
- 数学推理数据 :在 MATH、GSM8K、AIME 评测中,DataFlow 合成的数据比高质量合成基线 [28, 43] 高出 1–3 分 ;
- Text-to-SQL 数据 :相比含 250 万样本的 SynSQL 语料库 ,DataFlow 仅用 不到 10 万样本 ,就在执行准确率上提升 +3% 以上 ;
- 代码指令数据 :相比广泛使用的公开代码指令集,平均提升 7% 以上 。
更惊人的是“组合效应”:
我们将 DataFlow 生成的文本、数学、代码三类数据混合,构建了一个仅含 1 万个样本 的统一语料库 —— DataFlow-Instruct-10K 。
用它微调 Qwen2-base 和 Qwen2.5-base 模型,结果:
性能超越用 100 万条 Infinity-Instruct数据训练的同规模模型;
且逼近其对应版本的 Qwen-Instruct。
这说明:DataFlow 不仅能“造好数据”,更能“造得高效”——用极少量高质量、多领域对齐的数据,撬动巨大的性能增益,显著提升数据效率(data efficiency) 。
综上,DataFlow 远不止是一个“端到端数据准备系统”。它同时是:
- 一个完整的 operator 与算法库 (近 200 个可复用组件);
- 一个开放、易用的协议框架 (统一抽象 + PyTorch 风格 API + CLI 工具链);
- 一个以 LLM 为中心的数据构造范式 (。
最终,我们的核心贡献可总结为五点:
- 一个统一的 LLM 驱动数据准备框架 :提出 DataFlow,基于可组合抽象与 LLM 优先的 operator 执行模型;
- 一个丰富且可扩展的 operator-pipeline 生态系统 :提供近 200 个 operator 和覆盖六大领域的六套 SOTA 模板 pipeline;
- 一个面向开发者与开源社区的编程模型 :通过 PyTorch 风格 API、IDE 原生工具链、插件式 Python 扩展机制,支撑可复现实验、灵活定制与社区共建(DataFlow-Ecosystem);
- 一个用于自动化 pipeline 构建的智能体协调层 :DataFlow-Agent 将自然语言意图直接转化为可执行 pipeline,极大降低构建高质量、语义丰富 LLM 数据工作流的门槛;
- 全面的实证验证与开源数据集发布 :六项 pipeline 实验一致证明 DataFlow 提升下游 LLM 性能与数据效率;并开源一个完全由 DataFlow 生成的高质量、多领域数据集,供学术界与工业界研究与基准测试。
2 背景与相关工作
2.1 大语言模型开发中的数据
开发大语言模型就像教一个超级学生学语言:它要经历几个关键阶段,其中训练阶段 最为关键。在这个阶段,模型不是靠老师一句句讲语法,而是“读万卷书”——从海量的文本语料(比如网页、书籍、代码、对话记录等)中自动学习语言的基本规律,比如词语怎么搭配、句子怎么组织、逻辑如何展开。
举个例子:
- 如果训练数据里有很多高质量的科普文章,模型就更容易学会用准确、清晰的语言解释科学概念;
- 如果训练数据里混入大量拼写错误、语义混乱或重复的垃圾文本,模型就可能“学坏”,比如生成语法正确但内容荒谬的句子,或者反复说同一句话。
因此,训练数据的质量和多样性,直接决定了模型能不能“举一反三” ——也就是在没专门学过的任务或领域里,依然表现良好(这叫泛化能力,generalization)。论文引用的研究[19, 38]就发现:用更干净、覆盖更广(比如包含医学、法律、编程、多语言等)的数据训练出来的模型,在问答、翻译、代码生成等不同任务上,整体表现更稳、更可靠。
最近几年,LLM 发展飞快,训练所用的数据量也爆炸式增长(参考文献 [1, 57])。比如 GPT-3 训练用了约 570GB 文本,而更新的模型可能用到数 TB 级别的数据。数据越多,潜力越大,但挑战也越大:
- 质量难保 :数据多了,人工审核不现实,得靠自动化方法清洗、筛选、标注。这些步骤都要花算力和人力;
- 质量差的后果很实在 :模型可能记住错误知识,或在生成时频繁“幻觉”——编造看似合理实则错误的信息;
- 多样性不足 = 偏科严重 :如果训练数据90%都是英文新闻,模型写英文新闻稿很溜,但一碰到中文古诗或Python调试就卡壳;
- 数据分布偏移 更危险:比如训练数据全是2020年前的网页,模型就不懂“ChatGPT 是什么”;又比如训练时没见过医疗问诊对话,上线后面对真实患者提问就容易答非所问——因为它只认“训练时见过的样子”。
换句话说:数据不是越多越好,而是越“好”越好;不是越“全”越好,而是越“真”越“活”越好 ——要真实反映人类语言的丰富性、时效性和场景多样性。
2.2 大语言模型的数据准备
前面我们已经看到,数据准备是训练大语言模型(LLM)中极其关键的一步 ——它不只影响模型最终“答得对不对”,更深刻地决定了模型能不能举一反三(泛化能力)、会不会胡说八道(安全性)、甚至学不学得会新任务(适应性)。
打个比方:
如果把训练 LLM 比作做一道满汉全席,那数据准备就是——亲自去山里采菌子、海边捞鲜虾、老窖里取陈年酒曲……还得把每样食材洗、切、腌、晒、分等级。你不可能直接扛一麻袋混着泥沙、烂叶、变质虾的“原始材料”扔进灶台,指望厨神(模型)自动做出好菜。
同理,互联网爬来的原始文本(网页、论坛、代码仓库)充满噪声:乱码、广告、重复内容、有害信息、多语言混杂、长文档无结构……这些都必须在喂给模型前“料理干净”。
但问题来了:我们已经有很成熟的“大数据厨房设备”了,比如 Apache Spark、Dask、Hadoop —— 它们擅长处理表格型、行列分明的数据 ,能高效完成“抽取→转换→加载(Load)”这类 ETL 流程。
然而,它们不是为 LLM 数据设计的 ,就像用榨汁机去揉面团——能转,但费劲、低效、还容易坏:
- 不原生支持“模型在环”(model-in-the-loop)处理 :
比如你想让一个 LLM 判断一段话是否安全(含暴力/歧视内容),理想情况是:数据流经管道时,自动调用 LLM 实时打分 → 根据分数过滤或重写。Spark 虽然允许你写自定义函数(UDF)来调用 LLM,但它本身不理解“调用 LLM 是一种基础操作” ,不会帮你管理 GPU 显存、批量推理(batching)、重试、降级等关键逻辑。 - 不擅长 token 级别的文本操作 :
LLM 的真正“原子单位”是 token,比如"hello world"可能被切分为["hello", " world"](注意空格也算)。而 Spark 的字符串函数(如split()、substring())是面向 Unicode 字符的,无法精准对齐 tokenizer 的行为。想做“按 token 长度截断”“按 token 边界分段”“统计每个样本的 token 数”?只能自己硬写 UDF,且极易出错。 - 对非结构化文本“功能贫血” :
下面这些 LLM 训练必备步骤,在 Spark/Dask/Hadoop 中都没有现成算子 ,必须手写 UDF(每次都要重新造轮子): - 分词(tokenization):把
"I love NLP!"→["I", " love", " NLP", "!"] - 语种识别:区分中文、英文、代码、混合文本
- 文档分割:把一篇 PDF 解析后的长文本,按语义切成多个训练样本(如按章节、按问答对)
- 语义去重:不是简单删重复行(
"AI is great"和"Great is AI"字符不同但意思雷同,需用 embedding 向量判断) - 安全过滤:用分类器或 LLM 判定是否含违法、隐私、偏见内容
结果就是:工程师要花大量时间拼接 UDF、调试 GPU 内存溢出、处理 tokenizer 不一致、写脚本统计 token 分布……工程复杂度爆炸,pipeline 难复现、难维护、难扩展 。传统大数据引擎,本质上仍是“结构化数据思维”,难以承载 LLM 所需的“语义密集型、token 原生、模型驱动”的数据流水线。
那怎么办?研究者开始直接用 LLM 自己来管数据 ——也就是“用大模型做数据治理”:
- MoDS [15] :不用人工定规则(比如“含‘免费’就删”),而是用 DeBERTa 模型(一种预训练语言模型)给每条数据打一个“质量分”,只保留高分样本。
类比:请一位精通多国语言、懂专业术语的资深编辑,逐条审稿打分,而不是靠正则表达式找关键词。 - AlphaGasus [7] :直接调用 ChatGPT,让它判断一条数据是否“事实准确”。例如输入:“水的沸点是 100 摄氏度”,让 ChatGPT 回答“正确/错误/不确定”,再按结果筛选。
这相当于把“校对员”换成“领域专家顾问”,虽然贵点,但更灵活、更贴近真实评估标准。 - GPT-4 数据重写 :对低质量数据(如语法混乱、逻辑跳跃的问答对),不直接丢弃,而是让 GPT-4 重写成清晰、规范、教育性强的版本,变废为宝。
这些方法共同指向一个趋势:数据准备正从“基于规则和统计”转向“基于语义和模型” 。而 DataFlow 这类新框架,正是为了把上述能力——模型调用、token 操作、语义处理、GPU 批处理——原生集成进数据流水线 ,让“用 LLM 准备 LLM 的数据”这件事,变得像用 SQL 写 SELECT * FROM table 一样自然。
2.3 现有的大语言模型数据准备系统(
最近的研究越来越把大语言模型(LLM)训练数据的准备工作,当作一个首要的系统工程问题来对待——也就是说,不再只是写几个脚本跑一跑,而是像设计数据库、分布式计算框架一样,认真构建可扩展、可复用、可验证的数据处理系统。表1总结了当前主流数据准备框架的关键特点。
NeMo Curator [47] 是英伟达(NVIDIA)开源的一个GPU加速库 ,专为大规模LLM数据整理(curation)设计。它提供了一套模块化流水线(modular pipelines) ,覆盖数据准备全流程:
- 数据下载与解压;
- 语言识别(判断一段文本是中文、英文还是其他语言);
- 文本清洗(去掉乱码、HTML标签、过短/过长句等);
- 质量过滤(既有基于规则的启发式方法,也有用小模型打分的“学习型”过滤);
- 领域分类(识别是科技、医疗、法律等哪类文本)和毒性检测(识别辱骂、偏见等内容);
- 去重;
- 隐私过滤;
- 甚至支持合成数据生成 。
所有这些功能都基于 Dask (用于并行任务调度)和 RAPIDS ,天生支持多节点、多GPU集群,能轻松处理TB级原始数据。
Data-Juicer [6] 则走的是“一站式数据料理台”路线。它的核心思想是把数据处理步骤抽象成一个个可组合的算子 ——你可以把它们想象成乐高积木:每个算子干一件明确的事,然后自由拼接成完整流程。
- 原始版本已内置 50+ 个文本处理算子 ,支持构建和评估不同比例的文本数据混合方案;
- 2.0 版本大幅扩展,算子总数超 100+ ,且不再局限于文本——还支持图像、视频、音频多模态数据的分析、清洗、合成、标注,以及后训练阶段的数据增强;
- 底层深度集成 Ray (分布式任务框架)和 HuggingFace Datasets (最常用的数据集加载库),开箱即用。

表1 当前面向大语言模型的数据准备系统的高层对比(High-level comparison of existing data preparation systems for LLM)
这些系统显著提升了LLM数据准备的效率 (更快)和质量 (更干净、更安全、更多样),但它们本质上仍是以配置为中心(configuration-centric)的工具包 :用户得手动写YAML/JSON配置文件,指定用哪些模块、按什么顺序执行、参数设多少……就像用一台功能齐全但按钮密密麻麻的高端咖啡机,调一杯好咖啡得先研究说明书。
而本文提出的 DataFlow 框架 ,则换了一种思路:
- 它内置了近 200 个可复用的、专门针对文本的算子 ,粒度更细,让清洗、转换、合成、评估每一步都可控、可调试;
- 用这些算子搭建出的多个不同数据流水线 ,在下游任务中均稳定带来性能提升;更有趣的是:哪怕只是把几条流水线产出的数据简单混合 ,效果依然很强——说明算子设计本身具备鲁棒性和泛化性;
- 整个系统采用模块化、PyTorch风格的“积木式”设计 :每个算子都是轻量级的Python类,接口清晰(输入
Dataset,输出Dataset,参数全在__init__里),数据科学家或AI Agent可以像调用torch.nn.Linear一样,用代码直接组合、调度、调用整个数据流水线——真正实现“数据处理即编程”。
3 DataFlow 系统概览
本节介绍 DataFlow —— 一个面向大语言模型的统一、自动化数据准备系统,它将跨领域的数据预处理流程标准化、简化,让不同场景下的数据准备工作变得一致、高效且易于管理。
3.1 目标与设计思想
DataFlow 的整体设计围绕六个核心目标展开,我们逐个用小白能懂的方式解释:
易用性(Ease of Use)
→ 就像 PyTorch那样直观好上手:写代码不用反复写重复模板(boilerplate),IDE(如 VS Code 或 PyCharm)里能直接调试、断点、查看中间结果。
举个例子:你想把一批 JSON 文件转成 tokenized 数据,传统方式可能要手动写文件读取、清洗、分词、拼接等十几行胶水代码;在 DataFlow 中,你只需几行类似 pipeline = LoadJSON() >> CleanText() >> Tokenize(model="llama3") 的链式调用,就像搭乐高一样自然。
可扩展性(Extensibility)
→ 借鉴了 PyTorch 中 torch.nn.Module 的模块化思想:每个数据操作(比如“去重”“截断”“添加指令模板”)都封装成一个独立、可复用的“组件”,就像插件一样即插即用。
举个例子:你发现现有 DataFlow 没有“按关键词过滤对话轮次”的功能,那你只需写一个新类 FilterByTurnKeyword,继承基类并实现 forward() 方法,就能无缝接入已有 pipeline,无需改任何旧代码。
统一范式(Unified Paradigm)
→ 不管你是做对话数据、代码数据、数学推理数据,还是多模态文本,DataFlow 都提供同一套“语言”来描述所有步骤(比如统一用 Dataset → Map → Filter → Batch 抽象),既保证大家做法一致(方便复现)、又允许你在关键环节灵活定制(比如不同领域用不同 tokenizer)。
换句话说:它不是强制所有人穿同一件衣服,而是提供一套标准尺子和剪刀,你自己裁布、缝制,但尺寸单位和接口完全对齐。
性能高效
→ 官方提供的标准 pipeline(比如用于训练 Llama-3 风格数据的那套)实测速度不输甚至优于当前最好的专用工具(SOTA methods),证明“统一” ≠ “慢”。背后靠的是懒加载(lazy evaluation)、算子融合(operator fusion)、内存复用等优化手段。
类比:以前每做一道菜都要单独烧一锅水(开进程/读磁盘),DataFlow 是提前烧一大壶水,按需分装——省时省力,还不影响口味。
智能自动化
→ 内置一个轻量级“小助手”子系统(agentic subsystem),它不自己干活,而是听懂你的自然语言指令(比如“把所有用户提问开头加‘请回答:’,跳过含敏感词的样本”),然后自动帮你选算子、连流程、甚至微调参数。
开源范式
→ DataFlow 不是某个公司闭门造车的私有工具,而是希望成为整个社区共建共享的“数据准备普通话”。统一抽象意味着:
- 别人分享的 pipeline,你拿过来就能跑(reproducible sharing);
- 今天用 LLaMA,明天换 Qwen,只需改一行 backend 配置(transparent swapping);
- 所有改动(比如换 tokenizer、加 filter)都清晰可见、可对比、可回滚。
3.2 系统范围与定位
DataFlow 覆盖了以大语言模型(LLM)为核心的数据准备(data preparation)全流程。换句话说,它不只做某一个环节(比如清洗或标注),而是把从原始数据输入、中间处理、到生成高质量训练数据的整条链路,都纳入统一框架中管理。
如图 1 所示,DataFlow 的核心是一个统一执行底座 ,它抽象出五个关键组成部分:
- 存储 :用来存原始数据、中间结果、标注样本等;
- LLM 服务 :提供调用各类 LLM(如 GPT-4、Claude、本地部署的 Llama)的能力,是整个系统“思考”和“生成”的引擎;
- 算子 :像积木一样可复用的小功能单元,例如“去重”“抽样”“问答对生成”“毒性过滤”,每个算子封装了一类确定的数据变换逻辑;
- 提示模板 :预定义好的 prompt 结构,比如
“请将以下句子改写为更简洁的版本:{input}”,让 LLM 按固定格式干活,保证输出可控; - 流水线 :把多个算子和模板按顺序或条件连接起来,形成端到端的数据加工流程,例如:“先用 LLM 生成 100 条问题 → 再调用另一个 LLM 给每条问题生成 3 个答案 → 最后人工审核筛选出 50 条高质量 QA 对”。
举个例子:你想为客服机器人准备训练数据,可以定义一条 pipeline:
读取用户聊天日志 → 用 LLM 提取其中的意图(如‘退货’‘查物流’)→ 用模板生成对应的标准问法 → 过滤掉含敏感词的样本 → 导出为 JSONL 格式。
这整条流程在 DataFlow 中就是一个可保存、可复用、可共享的 pipeline。
在这个核心底座之上,还有两层面向用户的控制接口:
- 命令行工具(CLI) :适合开发者或数据工程师写脚本批量运行 pipeline,比如
dataflow run --pipeline customer_support_v2 --input logs.csv; - DataFlow-Agent(智能代理) :一个能理解自然语言指令的交互式助手,你直接说“帮我把这 1000 条商品评论分成正面/负面,并给每条配上理由”,它就能自动选择合适算子、模板和 LLM,组装并执行 pipeline——相当于一个“会写数据脚本的 AI 助手”。
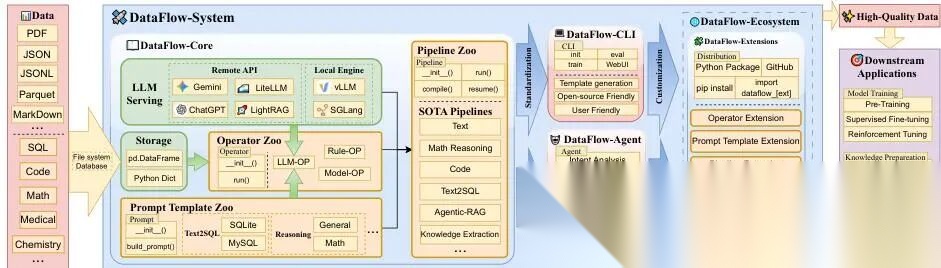 图 1 DataFlow 高层架构图。系统由核心执行引擎(含存储、算子、模板和 LLM 服务)、可复用的流水线、面向用户的控制层(CLI 和 Agent),以及支持领域定制的可扩展生态组成。DataFlow 输出高质量、任务对齐(task-aligned)的数据集,供下游 LLM 应用(如训练、评测、检索)使用。
图 1 DataFlow 高层架构图。系统由核心执行引擎(含存储、算子、模板和 LLM 服务)、可复用的流水线、面向用户的控制层(CLI 和 Agent),以及支持领域定制的可扩展生态组成。DataFlow 输出高质量、任务对齐(task-aligned)的数据集,供下游 LLM 应用(如训练、评测、检索)使用。
再往外一层,是 DataFlow-Extensions :它提供一套标准接口,允许任何人用 Python 包的形式,轻松添加新的算子、模板或 pipeline。比如某医疗团队开发了一个专门用于“从病历文本中抽取诊断关键词”的算子包 dataflow-medical-nlp,只要遵循接口规范,就能即插即用。
所有这类领域专用的 Python 包,共同构成了 DataFlow-Ecosystem。它不是 DataFlow 主体的一部分,但和主系统深度协同——就像手机操作系统(DataFlow) + 各类 App(Extensions)的关系。
最终,整个系统的边界就很清晰了:
- DataFlow 本身负责“怎么准备数据” :提供统一抽象、执行能力、控制方式;
- 下游任务(如 LLM 微调、红队测试、RAG 检索)负责“怎么用数据” :它们只关心输入是什么格式、质量如何,完全不用管这些数据是怎么生成的。
输出高质量、结构化、任务对齐下游应用
这个分工让数据准备不再成为黑盒或手工劳动,而变成可编程、可复现、可协作的工程实践。
3.3 系统工作流程
图1(Figure 1)也展示了 DATAFLOW 的端到端工作流程(end-to-end workflow)。整个系统可以从常见的文件格式(例如 JSON、JSONL、CSV、Parquet、Markdown、PDF)中读取原始数据,还能接入特定领域的数据源,比如 SQL 日志、代码仓库(如 GitHub 项目)等。所有这些输入,无论来源如何,都会被统一转换成一种表格形式,然后由系统的****核心存储层进行集中管理。
举个例子:
- 你有一份 PDF 格式的用户调研报告、一个 CSV 表格里的销售数据、还有一个 JSONL 文件存着 GitHub 上的 issue 记录;
- DATAFLOW 会把它们全部“翻译”成类似 Excel 表格那样的结构(每行是一个样本,每列是一个字段),并存在同一个地方(核心存储层),后续所有操作都基于这个统一表格进行。
操作符是 DATAFLOW 中执行具体数据处理任务的“小工人”。它们从共享存储中读取数据,完成处理后,再把结果写回存储——这样就保证了数据在不同处理阶段之间能稳定、一致地流动 。
这些操作符支持多种类型的转换任务,包括:
- 生成:比如用大模型写一段产品描述;
- 精炼 :比如把一段啰嗦的文案改得更简洁专业;
- 过滤 :比如只保留含“AI”关键词的评论;
- 评估 :比如判断生成的回答是否事实准确、是否符合要求。
其中,LLM 驱动的操作符 会通过一个统一的服务抽象层调用:
- 本地大模型推理引擎,适合私有部署、低延迟场景;
- 或在线 API 服务,适合快速验证、无需维护模型基础设施。
而规则驱动的操作符和轻量模型操作符 则不依赖大模型,直接用预设规则或小型机器学习模型(如正则表达式、逻辑回归、小型分类器)完成任务,更快、更可控、成本更低。
类比理解:
- LLM 操作符像“博士顾问”,擅长复杂开放任务,但需要时间思考、可能出错;
- 规则/小模型操作符像“资深专员”,处理固定套路的任务又快又准(比如提取邮箱、识别日期格式)。
DATAFLOW 提供了一个名为 Pipeline Zoo的预置组件库。这里的“流水线”就是把多个操作符按顺序或分支逻辑组装起来的可复用工作流。目前已支持的任务类型包括:
- 文本合成:如批量生成商品广告语;
- 数学推理:如将自然语言数学题转成解题步骤;
- 代码处理:如自动为函数添加文档注释;
- 文本转 SQL:如把“查上个月销售额最高的前 3 个地区”变成可执行的 SQL;
- 智能体增强检索:让 RAG 流程具备多步决策能力(比如先查资料、再对比、再总结);
- 大规模知识抽取(large-scale knowledge extraction):如从万篇论文中抽取出“哪些药物对 Alzheimer 疾病有效”。
这些流水线非常灵活:
- 可以直接运行 (run directly);
- 可以编译优化 (compiled for optimized execution),比如合并重复操作、提前缓存中间结果;
- 可以从中断点恢复 (resumed from intermediate states),比如某步失败后,不用重跑全部,只从出错处继续;
- 还可以跨领域迁移适配 (adapted to new domains),比如把一个用于金融新闻摘要的流水线,稍作修改后用于医疗报告摘要。
用户可以通过两种方式与 DATAFLOW 交互:
- 命令行界面(CLI) :手动输入指令,明确告诉系统“执行哪条流水线”“用什么参数”,适合开发者调试或自动化脚本集成;
- DATAFLOW-AGENT(智能代理) :用户用自然语言描述需求(比如:“帮我从这 1000 条客服对话里找出所有投诉物流慢的案例,并打上严重程度标签”),AGENT 会自动把它翻译成可执行的流水线,并支持边运行、边反馈、边修正(iterative debugging)——就像有个懂技术的助手帮你写代码、调流程。
最终输出的是高质量、任务对齐的数据集 。什么叫“任务对齐”?意思是:数据不是随便清洗过的,而是专门为下游某个 LLM 应用量身定制的 。比如:
- 如果下游是要训练一个法律问答模型,输出的就是大量“问题+权威法条引用+人工校验答案”的三元组;
- 如果下游是要微调一个代码补全模型,输出的就是“编辑前代码片段 + 编辑后代码片段 + 修改意图说明”。
这些输出能无缝接入下游 LLM 应用 ——不需要额外转换格式、也不需要人工再清洗,开箱即用。
4 框架设计与架构
本节介绍 DATAFLOW 的内部设计,并形式化地描述其在第 3 节中提出的抽象所依赖的执行模型。DATAFLOW 围绕四大架构支柱构建:
- 全局存储抽象 :它维护数据集的规范表格表示(即统一、权威的 tabular 形式),所有对数据的读写操作都必须经过它来协调。换句话说,它就像一个“中央数据管家”——不管你是想清洗、采样还是连接数据,都得先找它申请权限和获取格式一致的数据快照。
- 举例:假设你有 CSV、JSON 和数据库三类原始数据,DATAFLOW 的全局存储会把它们全部转成统一的 pandas DataFrame 格式,并存入内存或共享存储中;后续所有算子(operator)都只跟这个标准 DataFrame 打交道,不用各自处理不同格式。
- 分层编程接口 :提供多级 API,分别面向不同角色和任务粒度:
- 面向 LLM 服务:比如调用 GPT-4 或 Llama-3 的标准化接口,自动处理 prompt 构造、参数配置、重试与限流;
- 面向算子:封装常见数据操作(如
filter_by_llm,deduplicate_with_embedding),用户可像调用函数一样使用; - 面向提示模板(prompt template):支持变量插值、上下文拼接、few-shot 示例管理(例如
{{column_name}}自动替换成实际列名); - 面向流水线(pipeline):用声明式语法(如 YAML 或 Python 函数链)编排多个算子的执行顺序和依赖关系。
- 举例:你可以写一段类似
pipeline = LoadCSV() >> CleanWithLLM(prompt="修复错别字") >> ValidateSchema()的代码,框架自动把每一步串起来并调度执行。
- 原则性算子分类体系(Principled Operator Categorization Scheme) :不是随便堆砌功能,而是按语义和行为把算子分成几类(如 理解型、生成型、验证型、嵌入型),每类对应一组可复用的基础变换原语(transformation primitives)。这样既满足开放领域(open-ended domain)的灵活需求(比如金融、医疗、法律各有特殊规则),又避免重复造轮子。
- 举例:
extract_entities_from_text和classify_intent_with_fewshot都属于“理解型”算子,共享底层的 prompt 编排+LLM 调用机制,只是模板和后处理逻辑不同。
- 扩展机制:支持用户自主开发并注册新组件,这些组件能无缝接入现有 pipeline,被他人发现、复用和组合。整个生态像插件市场,但无需修改框架源码。
- 举例:某银行员工写了
anonymize_pii_with_rules_and_llm算子,上传到组织内插件仓库后,其他同事在 UI 或代码里就能搜索到它,并直接拖进自己的数据清洗流程中。
这四大支柱共同构成一个可扩展且可扩展(extensible) 的基础平台——“可扩展”指能支撑从单机笔记本到分布式集群的大规模数据处理;“可扩展”(注意是同一个英文 extensible,但中文常译作“可拓展”或“可延伸”,这里强调能力边界的开放性)指功能边界不固化,任何人都能安全、低门槛地贡献新能力。最终目标是让构建、运行和共享以大语言模型为核心的数据准备流程(LLM-centric data preparation workflows),变得像搭乐高一样简单可靠。
4.1 全局存储抽象与算子交互
DataFlow 的底层执行基础中,最核心的设计是一个统一的存储抽象层 (Global Storage Abstraction)。你可以把它想象成一个“智能数据管家”:它不关心数据具体存在硬盘、云存储还是数据库里,但它始终用一种标准的表格形式 来组织和呈现整个数据集——就像 Excel 表格一样,每一行是一个样本,每一列是一个字段(field)。
那为什么用表格?因为 LLM 相关的数据天然适合表格结构。比如:
- 给 LLM 的指令(instruction)
- LLM 返回的回答(response)
- 思维链推理过程(chain-of-thought trace)
- 打分结果(score)
- 元信息(metadata,如生成时间、模型版本、人工标注者 ID)
这种结构既清晰又灵活——新增字段(比如加一列 reviewer_comment)不需要改表结构,只需在写入时多传一个 key-value 就行。
这个存储抽象还做了一件很重要的事:把“怎么存数据”和“怎么处理数据”彻底分开 。
- 算子(operator)只管“我要什么数据”“我加工完生成什么新字段”;
- 存储层(storage)负责“从哪读”“往哪写”“怎么保证不丢不乱”。
它们之间靠一个极简的接口沟通,定义在 DataFlowStorage 这个基类里。只要你的自定义存储(比如存到 PostgreSQL、MinIO 对象存储、甚至内存中的字典)实现了这两个方法,就能无缝接入 DataFlow:
class DataFlowStorage: def read(self, fields=None): """ 读取当前数据集(或指定字段) fields: 可选,如 ["instruction", "response"],只读这几列 返回:Pandas DataFrame 或等价结构(如 polars.DataFrame) """ pass def write(self, data): """ 写入/追加字段到共享数据集 data: 字典或 DataFrame,key 是字段名,value 是对应列的值(长度需与现有行数一致) 例如:{"score": [0.92, 0.87], "review_status": ["approved", "pending"]} """ pass
举个例子,假设当前数据集有 2 行(id=001, 002),你想给它们打分并记录审核状态:
# 假设已有 storage 实例current_data = storage.read(fields=["instruction", "response"])# → 得到 DataFrame,含 instruction 和 response 两列# 算子内部逻辑:计算 score 和 review_status(可调用 LLM 或规则)scores = [0.92, 0.87]statuses = ["approved", "pending"]# 写回新字段storage.write({ "score": scores, "review_status": statuses})
运行后,原表格就自动新增了两列:
| id | instruction | response | … | score | review_status |
|---|
所有算子都遵循同一个模式(见图 2):
读(read)→ 加工(transform)→ 写(write)
这就是 DataFlow 中“数据流”(data flow)的真实含义:不是数据在算子间搬运,而是所有算子共同维护一张不断生长的“活表格”,每个算子只是往这张表里添几列新信息。
 图 2 DataFlow 中算子
图 2 DataFlow 中算子 run() 方法的标准执行流程。算子通过 storage.read() 获取输入字段,执行自身逻辑(如调用 LLM、清洗文本、计算指标),再通过 storage.write() 把结果作为新字段写回共享表格。这种“读–变换–写”范式,刻画了整个工作流中数据如何从一个算子流向下一个算子。
正因为算子只依赖这个逻辑抽象,所以:
- 你可以随时调整算子顺序(比如先评分再过滤,或先过滤再评分);
- 可以把多个小算子合并成一个批量处理算子,性能更好;
- 甚至可以把 Pandas 存储换成分布式 Ray Dataset 或 PostgreSQL,所有已有算子代码一行都不用改 。
默认实现使用 Pandas 作为底层引擎,支持常见格式导入导出:JSON、JSONL、CSV、Parquet。这意味着你既能快速本地调试(用 CSV),也能无缝迁移到大数据场景(换 Parquet + 分布式存储)。
4.2 分层编程接口
DataFlow 提供了一套分层的编程接口,它围绕四个核心抽象概念构建。你可以把这四个概念想象成搭积木时的四种不同形状的模块——每种模块职责明确、可以组合使用,共同完成复杂的数据准备和流程自动化任务。下面逐一解释:
-
(1) 服务接口这是整个框架的“调度中心”。它提供一个统一入口 ,让你不用关心背后用的是哪个大模型(比如 GPT-4、Claude 还是本地部署的 Llama 3),只要发一个标准请求,就能自动把任务交给合适的后端执行。
举个例子:就像你用同一个外卖 App 点餐,App 自动帮你匹配最近的餐厅、骑手和配送方式——你不需要手动选“今天让哪家店做菜、哪位骑手送餐”。服务接口就是这个“自动匹配”的能力。 -
(2) 算子(Operators) 算子是可复用的“数据处理小单元”,比如“清洗文本”“提取日期”“分类评论情感”。每个算子封装了一段逻辑,它自己可以纯代码运行(如用 Python 正则清洗),也可以在需要时调用服务接口 ,让大模型来帮忙(比如让 LLM 把一段模糊描述转成结构化 JSON)。
-
举个例子:
ExtractNamedEntities是一个算子,输入是一段新闻,输出是人名、地名、组织名列表;如果规则方法效果不好,它内部就会悄悄调用 LLM 来提升准确率。 -
(3) 提示模板(Prompt Templates) 这是控制“怎么跟大模型说话”的关键。它定义两件事:
-
怎么把算子的输入数据“组装”成一条清晰、规范的 prompt (例如把用户评论 + 预设标签体系 → “请将以下评论归类为:正面 / 中性 / 负面,只返回类别名,不要解释”);
-
怎么把大模型返回的原始文本“解析”成结构化结果 (比如强制输出 JSON 格式,或用特定分隔符提取字段)。
换句话说,提示模板让“人写 prompt”的经验,变成可复用、可版本管理、可测试的代码组件。
(4) 流水线(Pipelines)
流水线是最高层的编排单元,它把多个算子按顺序或依赖关系串起来,形成一个完整工作流。比如:
原始日志 → 解析字段(Operator A) → 情感分析(Operator B,调用 LLM) → 异常检测(Operator C,纯规则) → 生成报告(Operator D,再调用 LLM)
流水线还支持可选编译 :在真正运行前,先检查整个流程是否合法(比如某算子输出字段名是否被下一个算子正确引用)、能否优化(比如合并连续的 LLM 调用),相当于给工作流做一次“静态体检”。
这四个层次从底向上分别是:
- 底层调用(服务接口)→
- 功能单元(算子)→
- 人机交互契约(提示模板)→
- 业务逻辑编排(流水线)
它们共同构成 DataFlow 的“编程语言”,让数据工程师能像写程序一样设计和维护 AI 原生的数据流程。
4.2.1 LLM 服务接口(LLM Serving API)
这个接口就像是一个“万能翻译官”——它站在 LLM(大语言模型)和数据处理操作符之间,把各种各样的模型后端统一成一种简单、一致的调用方式。换句话说:不管背后跑的是哪个模型、在哪跑的,上层的操作符都用同一套方法来“发指令、收结果”。
它的核心方法只有一个,叫:
generate_from_input(user_inputs, system_prompt=None, json_schema=None)
我们来逐个解释参数含义,并用例子说明:
-
user_inputs:是一组用户输入(通常由调用它的 operator 拼装好),比如一个 list,每个元素是一条 prompt。
举个例子:user_inputs = [ "请从以下文本中提取人名和城市:张三在北京工作,李四在上海读书。", "请将下列 JSON 中的 'age' 字段转为字符串类型:{'name': 'Alice', 'age': 30}"] -
system_prompt:相当于给模型的“角色设定”,比如"你是一个严谨的数据清洗助手,请只输出 JSON 格式结果,不要额外解释。"
这能让模型更稳定地按要求格式输出,避免“自由发挥”。 -
json_schema:指定你希望模型输出的 JSON 结构,DataFlow 会自动把它转成合适的提示词(prompt engineering),并配合解码(decoding)确保输出严格符合该结构。
例如:json_schema = { "type": "object", "properties": { "names": {"type": "array", "items": {"type": "string"}}, "cities": {"type": "array", "items": {"type": "string"}} }}那么模型就必须返回类似:
{"names": ["张三", "李四"], "cities": ["北京", "上海"]}而不是一段自然语言描述。
关键好处 :有了这个接口,写 operator 的人完全不用操心——
- 模型要不要 batch(批量处理)?→ 接口内部处理;
- 请求失败了要不要重试?→ 接口内置策略;
- 是该发给本地 GPU 还是调 ChatGPT 的 API?→ 只需换一个 backend 配置;
- 流量太大被限速怎么办?→ 接口自动做 rate limiting 和请求调度。
接下来,这个服务层实际支持两类后端:
- 本地推理引擎 :比如 vLLM、SGLang,它们直接运行在你自己的服务器或 GPU 上,能利用显存共享、PagedAttention 等技术实现高吞吐、低延迟。适合对隐私、速度、成本敏感的场景。
- 在线 API 服务 :比如 OpenAI 的 ChatGPT、Google 的 Gemini。DataFlow 会用多线程(multithreaded)并发发送请求,像“多个快递员同时取件”一样,最大化利用这些外部服务的配额和响应能力。
一句话总结这个设计的价值 :
它把“模型怎么跑”的复杂性全部封装在底层,让数据工程师/科学家只需专注“我要让模型干什么”——比如“抽字段”“改格式”“验逻辑”,从而真正实现:换模型不改代码,换场景不重写 operator。
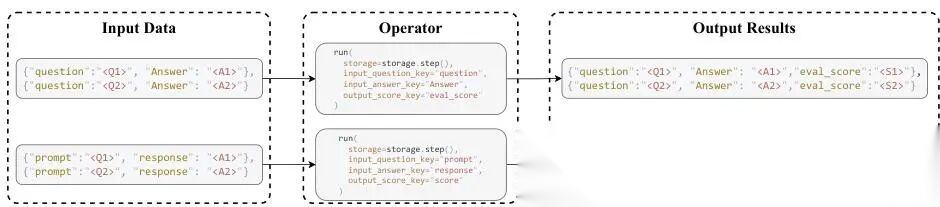 图 3:算子(operator)的
图 3:算子(operator)的 run() 方法如何通过“键名绑定(key-based bindings)”与数据交互。这种灵活的键绑定机制无需预处理即可适配任意数据集,并支持算子无缝组合。
4.2.2 算子编程接口
算子(Operator)是 DataFlow 框架中最基础的“数据加工单元”,就像工厂流水线上一个个专门负责某道工序的工人。每个算子只做一件事:把输入的数据,按某种规则变成输出的数据。为了把“准备干活”和“真正干活”这两件事分清楚,DataFlow 给算子设计了一个两阶段接口 :
- 初始化阶段(
__init__()) :相当于给工人配工具、发说明书、安排工位; - 执行阶段(
run()) :相当于工人正式上手,对送来的原材料(数据)进行加工。
换句话说:初始化只管“怎么配”,执行只管“怎么算”,两者完全分开,互不干扰。
举个例子:
- 一个用大语言模型(LLM)做文本摘要的算子,在
__init__()阶段会拿到:
- 摘要任务的提示词模板(prompt template),比如
"请用一句话概括以下内容:{text}"; - 一个已连接好的 LLM 服务对象(比如调用 OpenAI API 的客户端);
- 可能还有温度系数(temperature)、最大输出长度等超参数。
- 而一个用正则表达式过滤邮箱的算子,
__init__()阶段就只需要配置一个正则模式(如r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b'),根本不需要 LLM 或 prompt,所以它压根不会去绑定那些组件。
这样做的好处是:所有算子——无论是靠 LLM 生成、靠规则过滤,还是靠轻量模型分类——都长着同一副“骨架”,只是“肌肉”不同,统一管理起来就非常方便。
接下来是真正干活的 run() 方法。它只接收两个东西:
- 一个
DataFlowStorage对象(你可以把它想象成一个共享的、带列名的表格或字典,所有算子都往里面读/写); - 一组以
input_*和output_*开头的键(key),比如input_text、output_summary、input_email、output_is_valid。
这些键不是随便起的,它们是明确约定的“数据契约” :
- 所有
input_*键,告诉算子:“请从DataFlowStorage里读出名叫xxx的那一列,作为我的输入”; - 所有
output_*键,告诉算子:“加工完后,请把结果写进DataFlowStorage里,列名叫yyy”。
例如:
表示:从 storage 中读取 "raw_article" 列的每一条文本,生成摘要,并把结果存入 storage 的 "summary" 列。
这种设计带来了两大好处:
- 灵活适配 :上游数据列名是
"raw_article"还是"content",只要在调用run()时把input_text设成对应名字就行,算子本身不用改代码; - 自动建图 :多个算子之间靠
input_*↔output_*的名字匹配连起来(比如 A 算子写了"summary",B 算子读"summary"),系统就能自动画出一张有向依赖图 ——谁必须先运行、谁可以并行、谁失败会影响谁,一目了然,也便于后续做调度优化或断点续跑。
最后,为什么这个设计既“轻量”又“可靠”?关键在于两条约束:
- 配置与执行彻底隔离 :
__init__()里不能碰数据,run()里不能改配置; - 状态变更仅通过显式 key 操作共享存储 :算子之间不直接传对象、不共享内存变量,所有读写都通过
storage["key"]明确声明。
这就保证了:
- 每次
run()的行为确定可重现 (相同输入 + 相同 key 绑定 → 相同输出); - 算子可以像乐高一样自由拼接,不用担心隐藏依赖或状态污染;
- 整个 DataFlow 系统无论多复杂,底层语义始终一致、可验证、可移植。
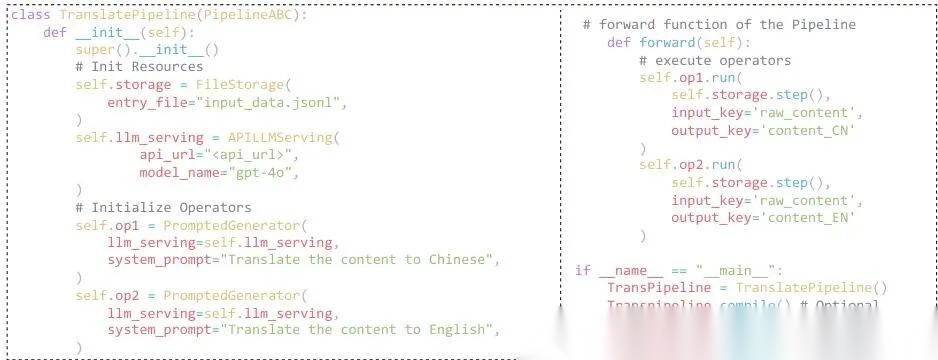 图4 DataFlow 流水线编程接口示意图。该示例展示了如何声明数据存储与模型服务后端、如何用任务特定参数实例化不同算子,以及如何通过
图4 DataFlow 流水线编程接口示意图。该示例展示了如何声明数据存储与模型服务后端、如何用任务特定参数实例化不同算子,以及如何通过 forward() 方法配合输入/输出键完成执行。该接口支持编译优化与分步恢复执行,从而支撑灵活、模块化的数据工作流构建。
4.2.3 提示模板接口
提示是引导大语言模型完成特定任务的核心方式。你可以把它想象成“给模型写的说明书”——告诉它“你要做什么、输入是什么、输出要长什么样”。在 DataFlow 中,每一个由 LLM 驱动的操作符都必须依赖一个提示 。更有趣的是:很多功能相似的操作符,其实底层逻辑完全一样,差别只在于提示里的一两句话。
举个例子:把自然语言问题转成数据库查询语句时,生成 SQLite 查询和 MySQL 查询的操作符,其核心逻辑一模一样;唯一的区别,只是提示里多写一句“请用 MySQL 语法”,或“注意 SQLite 不支持 WITH 子句”。换句话说:换一个提示,同一个操作符就能适配不同数据库 。
为了不重复写代码、又能灵活适配各种场景,DataFlow 把“怎么写提示”这件事,从操作符的主逻辑中彻底剥离开来 ,专门设计了一个叫「提示模板接口」的模块。
提示模板是什么?
一个提示模板就像一个「可填空的提示草稿」:它定义了提示的整体结构,并预留了几个带名字的空格(参数化插槽),比如 、、。操作符在运行时,把实际的数据填进去,就自动生成一条完整、可用的提示。
具体怎么工作的?分两步:
- 初始化阶段(
__init__()) :每个 LLM 操作符在创建时,会绑定一个具体的提示模板(比如MySQL_Text2SQL_Template),并传入一些固定配置(如模型要求、输出格式约束)。这一步和 DataFlow 中其他组件(如数据读取器、校验器)的初始化方式完全一致,保持系统风格统一。 - 执行阶段(
build_prompt()) :当操作符真正运行时,它调用模板的build_prompt()方法。这个方法会自动把当前任务所需的动态信息(比如本次要转换的自然语言问题、涉及的数据库 schema、上下文中的业务规则等)填进模板的空格里,拼出一条完整的提示,再交给底层的 LLM 服务去执行。
这样做的好处是:操作符的“业务逻辑”完全不用关心提示怎么拼、语法怎么写——它只管“我要什么信息”,模板负责“怎么告诉模型”。
一个操作符,能配多个提示模板
现实中,同一个操作符可能要在不同场景下工作。比如一个“实体抽取”操作符,既要用在医疗病历里抽疾病名,也要用在电商评论里抽商品型号。它们的处理流程一样(找名词短语 → 判断是否为实体 → 标注类型),但提示侧重点不同。
为此,DataFlow 让每个 LLM 操作符暴露一个统一接口:
op.ALLOWED_PROMPTS = [ "Medical_NER_Template", "Ecommerce_NER_Template", "Generic_NER_Template"]
这相当于一份「本操作符支持的提示模板白名单」。用户或上层工作流只需修改配置,指定用哪一个模板,完全不用改操作符本身的代码 ,就能切换领域、调整风格、甚至做 A/B 测试。
总结一下这个设计的价值
- 声明式(Declarative) :你不需要手写 prompt 字符串拼接逻辑,而是用模板“声明”提示该长什么样,系统自动组装。
- 高复用 :一个操作符 + 多个模板 = 覆盖多个子任务,避免“一个需求写一个 operator”的冗余开发。
- 易维护 :提示优化(比如加 few-shot 示例、调整语气)只改模板文件,不影响任何 operator 的逻辑代码。
- 行为一致 :所有 LLM 调用都走同一套模板机制,确保提示格式、元信息注入方式、安全过滤策略等在整个 DataFlow 工作流中保持统一。
4.2.4 流水线组合接口
在前面介绍的抽象层基础上,DataFlow 提供了一个流水线接口 ,让用户能把多个数据处理“算子”像搭积木一样串起来,组成多阶段的数据准备流程。你可以把一个流水线想象成一条有明确先后顺序的“数据加工流水线”——数据从一头进去,经过一个个算子的处理,最后从另一头出来。这个流水线既可以表示为一个有序算子序列 ,也可以更灵活地表示为一个轻量级有向无环图,也就是允许某些算子并行执行或依赖多个上游算子,但不能形成循环依赖。整条流水线构成一个端到端的执行图,清晰刻画了“数据该往哪儿流、谁先谁后”。
举个例子 :假设你要处理用户行为日志,可以这样搭流水线:
读取原始日志 → 过滤无效IP → 解析URL字段 → 统计每小时点击数 → 存入数据库
每一步就是一个 operator,它们按顺序连接,就构成了一个典型的 pipeline。
图4 展示了这个流水线接口的 API 结构及其核心组成部分。
流水线接口的设计借鉴了 PyTorch [49] 的风格,主要包含两个关键方法:
__init__()方法:负责初始化资源 和配置各个算子 ;()方法(即forward()方法,Python 中调用对象时自动触发:代表一次完整的前向执行过程 ,也就是把数据实际送入流水线跑一遍。
特别巧妙的是:在 forward() 内部,每个算子通过隐式的关键字参数绑定(key bindings) 来声明它需要哪些输入、把结果输出给谁。例如:
def forward(self, data): cleaned = self.cleaner(data) # cleaner 算子接收 data 输入 parsed = self.parser(cleaned) # parser 算子接收 cleaner 的输出 stats = self.aggregator(parsed) # aggregator 接收 parser 的输出 return stats
这些变量名(cleaned, parsed, stats)本身就在定义数据流向——cleaner 的输出成了 parser 的输入,这就自动构建出了数据流拓扑结构 。这种写法模块化强、代码可读性高,而且主流 IDE能很好支持自动补全和类型提示,开发体验友好。
功能上,流水线接口还内置了一个 compile() 方法,它不是直接运行算子,而是先做一次静态分析 ——就像编译器在真正运行程序前先检查语法和逻辑错误一样。
compile() 在执行时会做三件事:
- 提取依赖关系 :分析每个算子的输入键(input keys)和输出键(output keys),自动推导出谁依赖谁;
- 构建 DAG :根据依赖关系生成对应的执行图;
- 做关键校验 :检查是否漏填必要字段、输入输出类型是否匹配、依赖链是否断裂或成环等。
重要的是:compile()并不真正调用任何算子的 run() 方法 ,而只是把所有算子的配置和依赖信息记录下来,生成一个“待执行计划(deferred execution plan)”。
这背后采用的是软件设计模式中的工厂方法模式 :把“创建对象/配置流程”和“执行对象/运行流程”彻底分开。就像你先画好施工图纸(compile()),再按图施工(forward() 调用时才真正执行每个算子的 run())。
这个编译后的执行图 带来两大好处:
第一,对 DataFlow-Agent 更友好 :Agent 可以一次性看到整个图的完整结构,从而把所有与键名(key)、依赖(dependency)相关的错误(比如 user_id 字段在某个算子里被误写成 userid,或者 aggregator 想读 parsed_result 但前面没人输出它)汇总成一份清晰报告。不用反复试错、改一点跑一次,大幅减少调试轮次,也节省大模型推理成本。
第二,支撑高级运行时能力 :这个图定义了一个最小且高效的执行计划,天然支持:
- 断点续跑 :比如流水线跑到第5步失败了,下次可以从第5步恢复,不用重跑前4步;
- 逐步执行 :开发时可以只运行前N步,边看中间结果边调参,提升迭代效率;
- 对构建超大规模、多分支、长链条的数据流水线尤其有价值。
换句话说,compile() 不是“多此一举”,而是为智能体协同开发、错误快速定位、生产环境稳定运行打下的关键基础。
4.3 算子分类
DataFlow 中的算子是对各种数据处理算法的封装。多个算子像“积木”一样组合起来,就能构建出完整的、面向大语言模型的数据准备流程。
DataFlow 是一个统一但可扩展的框架,目标是服务任意领域。这就带来一对矛盾:
- 一方面,不同领域需要五花八门的专用算法(比如从 PDF 提取表格、给数学题打难度分、把代码注释翻译成中文)——需求几乎是无限的;
- 另一方面,用户需要一个稳定、简洁、容易理解的算子集合——不能太多、太乱、太难记。
怎么兼顾?DataFlow 不靠“一刀切”的单一分类,而是用多个互不干扰、彼此正交的分类维度来组织算子。就像给图书分类:可以按「学科」,也可以按「用途」,还可以按「难度」——这三个维度各自独立,又共同帮我们快速定位一本书。同样,DataFlow 的每个维度内部,类别之间是互斥的;而不同维度之间是平行的 。这个分类方案已在本文覆盖的6+个前沿数据准备流水线中验证有效:既足够表达各类任务,又能自然延伸到新领域。
模态维度
这是最基础的分类方式:按算子处理的数据类型划分,比如:
- 文本
- 图像
- 文档类
为什么必须区分模态?
因为模态决定了“输入能接什么、输出能连谁”。
- 同一模态内的算子,输入输出语义兼容,可以直连(比如“清洗文本”后接“提取关键词”,都是文本)。
- 跨模态的算子通常不能直接拼接(比如“识别图片中的文字”输出的是文本,但“检测人脸”输出的是坐标框——二者结构不同,无法直接传给同一个下游算子)。
DataFlow 默认以文本为核心工作流 。对于非文本输入(如一张图、一个 PDF),它要求先用模态专用算子把它们“翻译”成文本:
- 图像 → 用
ImageToTextParser算子生成描述性文字; - PDF → 用
PDFToTextExtractor算子抽取出纯文本内容。
之后,所有后续处理(过滤、打分、改写等)都基于这段文本进行。
这种明确的模态划分,让整个转换路径变得清晰可见 ,也方便 DataFlow 的“流水线编译器”自动检查:比如发现“图像增强算子”后面直接连了“文本去重算子”,就会报错——因为模态不匹配!
核心算子 vs. 领域专用算子维度
第二个维度回答一个问题:这个算子是“通用底盘”,还是“定制配件”?
- 核心算子 :
- 是 DataFlow 的设计灵魂,数量少、变化慢、概念稳;
- 大多数其他算子都可以看作是它的“参数实例化”;
- 新手推荐从这里起步,比如
TemplateGenerator、RegexFilter(用正则表达式过滤行); - 类似编程里的
for循环、if判断——基础但万能。
- 领域专用算子 :
- 为特定场景“量身定制”,比如
MathDifficultyClassifier、CodeCommentTranslator; - 数量理论上可以无限增长;
- 但 DataFlow 实际只内置了当前最优流水线真正用到的那些 ,避免“为炫技而堆砌”,保持实用精简。
举个例子:
TemplateGenerator(核心):你给它模板"问题:{q},答案:{a}"和一批{q,a}数据,它就生成问答对;MathQAFormatter(领域):本质就是TemplateGenerator套了个预设模板"请解答以下数学题:{question}。答案是:{answer}。"—— 它的语义完全能被核心算子表达,只是封装得更方便。
功能维度
这是最细粒度的分类,聚焦算子在数据准备流水线中扮演的具体角色 。所有算子归为四类,构成 DataFlow 的核心工作范式:生成 → 评估 → 过滤 → 精炼。
这个范式源于 DataFlow 作为“数据合成框架”的定位:
- 先扩大候选池 ;
- 再打分筛选 ;
- 最后局部优化 。
下图直观展示了这一过程:所有流水线起始都是 1000 条样本;
- 若含生成类算子,样本数会上升;
- 经过评估和过滤后,样本数下降;
- 精炼类算子只改内容,行数不变。
图5 DataFlow 流水线中各阶段样本数量变化示意图。所有流水线均从 1000 条输入样本开始。文本流水线主要做预训练数据过滤,代码流水线则基于现有指令数据扩展代码能力;因此两者均不含生成类组件。
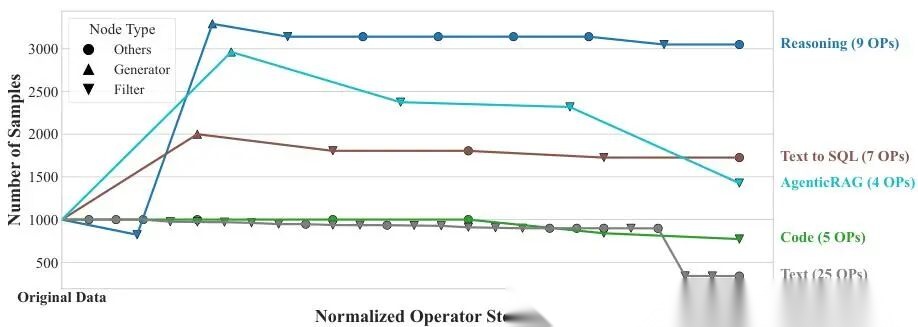
下面逐类说明(DataFlow 规定:每行代表一个数据样本,每列是一个命名字段,如 question, answer, score):
-
生成类(Generate) :负责“扩容”——要么新增字段,要么新增行。
举例:
AnswerGenerator(生成答案)、SynonymAugmenterRowGenerator(用同义词扩增句子变体)
XXXGenerator:给已有行加新字段。```plaintext示例:为每条 QA 对生成一个“难度标签”字段def add_difficulty_field(samples): for s in samples: if len(s[“question”]) > 50: s[“difficulty”] = “hard” else: s[“difficulty”] = “easy” return samples
XXXRowGenerator:为每条输入行生成多条输出行。```plaintext示例:将 1 条数学题,生成 3 种不同难度的变体def generate_variants(sample): variants = [] for level in [“easy”, “medium”, “hard”]: new_sample = sample.copy() new_sample[“question”] = f"[{level}] {sample[‘question’]}" variants.append(new_sample) return variants # 返回 3 行
-
评估类(Evaluate) :负责“打分”——产出量化指标或分类标签。
举例:
MathDifficultyClassifier(给数学题标难度)、QASubjectClassifier(给 QA 对分类学科)
SampleEvaluator:为每一行附加评估结果。```plaintext示例:给每条问答对计算 BLEU 分数(衡量答案与标准答案相似度)from nltk.translate.bleu_score import sentence_bleudef bleu_evaluator(samples): for s in samples: score = sentence_bleu([s[“gold_answer”].split()], s[“pred_answer”].split()) s[“bleu_score”] = round(score, 3) return samples
DatasetEvaluator:输出整个数据集的聚合指标。```plaintext示例:统计正确率def accuracy_evaluator(samples): correct = sum(1 for s in samples if s.get(“is_correct”, False)) return {“accuracy”: correct / len(samples)}
-
过滤类 :负责“瘦身”——按条件删行,不改内容,只减数量 。
# 示例:删除答案错误的样本def remove_wrong_answers(samples): return [s for s in samples if s.get("is_correct", True)]举例:
ThresholdFilter(按分数阈值过滤)、DeduplicateFilter(去重) -
精炼类 :负责“美容”——修改现有字段内容,行数和字段名都不变 。
# 示例:清理文本中的 URL 和 emojiimport redef clean_text_refiner(samples): url_pattern = r"https?://\S+|www\.\S+" emoji_pattern = r"[^\w\s,.;:?!\-]" for s in samples: s["text"] = re.sub(url_pattern, "", s["text"]) s["text"] = re.sub(emoji_pattern, "", s["text"]) return samples举例:
URLRemoverRefiner、EmojiStripperRefiner
这三大维度协同工作:
- 模态维度确保“数据类型不打架”;
- 核心/领域维度平衡“稳定基座”和“灵活扩展”;
- 功能维度提供“可复用、可预测”的四步操作原语。
最终,DataFlow 在无限增长的算子生态和有限的人类认知负荷之间,找到了一条可持续的中间道路。
4.4 DataFlow-Ecosystem
一个统一的数据准备框架,必须能灵活支持无穷多种算法和工作流 。这听起来很强大,但也会带来一个问题:如果每个人都能加新功能,那“算子”和“流水线”的数量就会无限增长,系统很容易变得混乱、难维护。
为了解决这个问题,DataFlow 提出了 DataFlow-Extension 的概念——它就像一个“功能插件包”,把一组相关的组件打包在一起,包括:
- 新的算子(比如一个清洗脏文本的函数),
- 新的提示词模板,
- 新的完整流水线。
这些由用户自己开发并提交的扩展包,合起来就构成了 DataFlow-Ecosystem——你可以把它想象成 Python 的 PyPI 生态:
开发者可以像发布 requests 或 pandas 那样,把自己的数据处理“小工具包”打包上传;
其他用户只需一行命令 pip install my-data-cleaner 就能安装使用;
大家共享的不是零散代码片段,而是经过验证、可复用、带文档的标准化模块 。
举个例子:
某金融公司开发了一个叫
finance-ner-extension的扩展包,里面包含:
- 算子:
extract_stock_ticker()(从新闻中抽股票代码)- 提示词模板:
"请从以下文本中提取所有A股上市公司简称和6位代码,格式为:{简称}({代码})"- 流水线:
FinanceNewsPreprocessor(自动完成新闻分句 → 实体识别 → 时间对齐)
发布后,另一家券商团队直接安装使用,省去了从头写规则或调模型的时间。
为了让大家更轻松地开发这类扩展包,DataFlow 提供了两个关键工具:
DataFlow-CLI:一键生成开发脚手架
你不需要从空文件夹开始写代码。只要告诉 CLI 你想做什么(比如:“我要做一个‘去除社交媒体噪声’的算子,输入是字符串列表,输出是干净文本列表”),它就会自动生成:
- 算子 Python 文件(含空的
process()方法), - 对应的 prompt template 文件(
.jinja或.txt), - 测试样例和单元测试骨架,
- 甚至整个 GitHub 仓库结构(含
setup.py、README.md、许可证等),可直接git push发布到 PyPI 或 GitHub。
# 示例:CLI 生成的算子模板(简化版)class SocialNoiseRemover: def __init__(self, keep_hashtags: bool = False): self.keep_hashtags = keep_hashtags def process(self, texts: list[str]) -> list[str]: # 开发者只需在这里填入具体逻辑 # 不用操心 import、配置、测试结构、打包方式 raise NotImplementedError("Implement noise removal logic here")
安装和使用也和普通 Python 包一样:
pip install dataflow-clidataflow-cli create-extension --name "social-noise-remover"
而且,所有扩展都支持懒加载 :
→ 系统启动时不加载全部扩展,只在真正用到某个算子时才导入对应模块;
→ 即使你装了 20 个扩展,只要没调用其中某一个,它就不会占用内存或引发依赖冲突。
DataFlow-Agent:用自然语言“说”出你要的算子和流水线
有时候,你清楚想要什么功能,但不知道怎么写代码或设计 prompt。比如:
“我需要一个能从客服对话里提取用户投诉关键词,并按严重程度打分(1~5)的流水线。”
DataFlow-Agent 就是来帮你的——它背后是一个基于 LangGraph 编排的多智能体系统(见图6),能将你这句中文“意图”,自动转化为一个经过验证、可执行的有向无环图流水线 。
它怎么做?
- 理解意图 :用 LLM 解析你的自然语言,识别任务目标、输入输出格式、领域约束;
- 检索与合成 :结合已有的算子库和 prompt 模板知识,拼接或生成新的组件;
- 验证与优化 :模拟运行、检查逻辑闭环、避免循环依赖,并用小样本测试确保输出合理;
- 交付结果 :输出完整的 Python DAG 定义,你可以直接运行或进一步修改。
换句话说:
以前你要写代码 + 设计 prompt + 搭 pipeline → 可能花半天;
现在你只说一句话 + 点一下“生成” → 得到一个可用初稿,再花10分钟微调即可上线。
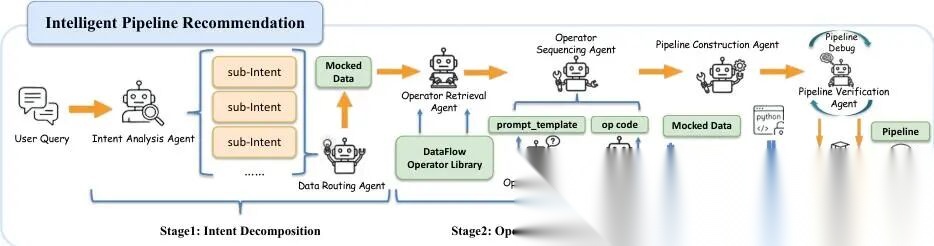 图6 DataFlow-Agent 架构:一个由 LangGraph 编排的多智能体工作流,将自然语言意图自动翻译为经过验证、可执行的有向无环图流水线。
图6 DataFlow-Agent 架构:一个由 LangGraph 编排的多智能体工作流,将自然语言意图自动翻译为经过验证、可执行的有向无环图流水线。
CLI 和 Agent 不是互斥的,而是互补的:
- CLI 面向开发者 :适合有明确技术方案、想长期维护和发布组件的人;
- Agent 面向数据工程师/分析师 :适合快速试错、临时构建、或缺乏编程经验但熟悉业务逻辑的人。
最终目标很清晰:
让数据准备不再是一次性的“脚本工程”,而变成像搭乐高一样的可组合、可共享、可验证的标准化实践 。每一个发布的 Extension,都是社区贡献的一份“数据处理食谱”——别人能复现、能改进、能叠加,从而整体加速整个数据驱动型机器学习领域的发展。
5 DataFlow-Agent
DataFlow-Agent 是架设在 DataFlow 框架之上的“智能调度中枢”。你可以把它想象成一个懂业务、会编程、还能自我纠错的“数据准备总指挥”。
它要解决的核心问题是:人类用自然语言说“我要清洗销售数据,去掉重复项,再按地区汇总”,机器怎么听懂并自动完成一整套数据操作?
答案是——它不靠硬编码,而是靠两样东西协同工作:
- DataFlow 自身的模块化抽象能力 :比如“读取 CSV”“去重”“分组聚合”这些操作,不是写死在代码里,而是被封装成一个个可插拔的、带明确输入输出的“积木块”;
- 基于图的多智能体工作流引擎 :它把整个数据准备流程建模成一张“状态图”,每个节点是一个专业小助手,比如:
- Parser Agent:负责理解你的自然语言指令,拆解出目标和数据源;
- Planner Agent:根据 DataFlow 提供的可用算子库,规划出一条可行的执行路径;
- Executor Agent:调用 DataFlow 运行这条流水线,并实时反馈结果;
- Validator & Self-Correction Agent:检查输出是否合理(比如汇总后行数是否明显异常),若发现问题,自动回退、调整参数或换一种算子重试。
这个引擎底层使用了 LangGraph——一个专为构建有状态、可循环、支持中断与恢复的 AI agent 工作流而设计的框架。换句话说,DataFlow-Agent 不是一次性执行完就结束,而是能“边跑边想、出错就改、越干越准”。
5.1 Agent角色
为了让整个数据准备流程能“自己思考、自己动手”,DataFlow 把一个复杂任务拆解成多个各司其职的“智能小助手”(即 Agent )。每个 Agent 就像一位专业岗位员工,只负责一个明确的小目标,并且都和 DataFlow 的核心系统紧密配合。下面我们就一个一个来认识它们,用生活中的例子帮你理解:
-
意图分析 Agent(Intent Analysis Agent) :相当于“需求翻译官”。你跟它说一句大白话,比如:“帮我把销售表里2023年华东地区的订单按金额从高到低排个序,再算个平均值”,它不会直接写代码,而是先把这句话“掰开揉碎”,拆成几步清晰的小任务:① 加载销售表;② 筛选 2023 年 + 华东地区;③ 按金额降序排列;④ 计算平均值。这一步输出的就是整个流水线的“施工蓝图”。
-
数据路由 Agent :相当于“快递分拣员”。它看一眼你给的数据,快速判断:“这是表格数据?还是图像?还是日志?”然后决定该走哪条处理通道;如果你根本没给数据,它还会自动生成一个占位用的模拟数据 (比如带正确列名和样例值的空表),让后续步骤可以先“预演”一遍,不卡壳。
-
算子检索 Agent :相当于“工具柜管理员”。它拿着上一步拆出来的某个小任务(比如“筛选华东地区”),去 DataFlow 自带的“算子工具库”里翻找——有没有现成的、别人写好并验证过的功能模块?它用的是 RAG(检索增强生成,Retrieval-Augmented Generation)技术,就像在知识库中精准搜索+语义匹配,挑出最贴切的几个候选算子。
-
算子编排 Agent :相当于“电路接线工”。它检查上一步找来的几个候选算子:这个算子输出是
DataFrame,下一个算子输入要pandas.DataFrame—— 匹配;但如果下一个要的是numpy.array,就 不兼容。它会自动选出接口最搭的一组;如果发现“没人能干这个活”,它就写下详细需求说明书(比如:需要接收用户 openid,调用微信 token 接口,返回 JSON 格式 access_token)。 -
算子合成 Agent :相当于“现场程序员”。它拿到上一步写的“需求说明书”,立刻开工写代码!同样用 RAG 辅助(参考类似功能的历史代码、文档、API 示例),写出 Python 函数;写完还不算完——它会自动运行单元测试(unit test),如果报错,就自己改、再试,直到代码能成功跑通,输出预期结果。
-
算子复用 Agent :相当于“代码归档员”。它审视刚写好的新算子:质量过关吗?命名规范吗?有没有注释?能不能被别人看懂、放心用?如果没问题,它就为这个算子生成一个标准化的
prompt_template,比如:你是一个数据处理函数,输入:{input_desc},输出:{output_desc},请严格按以下格式返回 JSON:{"result": ..., "status": "..."}这样下次别人提类似需求,系统就能直接调用这个模板+新参数,不用重写一遍。
-
流水线构建 Agent :相当于“总装车间主任”。它把所有确认可用的算子按逻辑顺序串起来,形成一张有向无环图 —— 就像做菜流程图:洗菜 → 切菜 → 烧油 → 下锅 → 翻炒 → 装盘,每一步只往前走,绝不循环打转。这张图就是可执行的完整工作流。
-
流水线验证 Agent :相当于“质检工程师”。它把刚搭好的 DAG 放进一个安全隔离的“沙盒环境”里真实跑一遍:数据能不能顺利流过去?中间会不会报
KeyError或NaN异常?如果出错了,它不喊人,而是自己尝试微调(比如换个默认填充值、加个.dropna()),直到整条流水线稳稳跑通,输出干净结果。 -
结果汇报 Agent :相当于“项目经理兼文档专员”。最后一步,它把整件事整理成一份“交付报告”:用了哪些算子?怎么连的?输入输出样例是什么?耗时多少?还打包生成一个可以直接运行的
.py文件或 YAML 配置,让你一键复现整个流程。
一句话总结 :这9个 Agent 不是各自为战,而是一条自动化流水线上的9个工位,环环相扣、自动协同——你只管说“我要做什么”,剩下的“怎么做、用什么做、做得对不对”,全部由它们接力完成。
5.2 智能流水线推荐
如图6所示,整个系统的核心能力是通过构建在 DataFlow 框架之上的一个智能体层来实现的。这一层使用 LangGraph 来编排一系列专用智能体 ,这些智能体在一个基于图的、有状态的工作流中协同工作。
意图分解
工作流的第一步是接收用户用自然语言提出的任务请求,比如:“帮我清洗这个销售数据,并画出每月销售额趋势图”。
- 意图分析智能体会把这条高层目标拆解成若干个具体、可执行的子意图,例如:
- “读取 CSV 文件”
- “删除缺失值”
- “按月份聚合销售额”
- “绘制折线图”
- 同时,数据路由智能体会对用户提供的输入数据集进行分析,判断任务类型(如“数据清洗”“特征工程”“可视化”),以便后续分发给合适的模块处理。
- 如果用户没有提供任何数据 ,该智能体会自动生成合成数据占位符 ,比如构造一个带
date,sales列的模拟表格,让整个流程仍能完成一次“试运行(dry-run)”,提前暴露潜在问题。
算子合成
为了实现上面分解出的每一个子意图,系统需要找到或生成对应的数据处理算子(operator) ——你可以把 operator 理解为一个封装好的、可复用的小程序,比如 drop_na()、groupby_month()、plot_line()。
这个过程分为四步:
- 算子检索:在 DataFlow 自带的算子库中搜索与当前子意图匹配的已有算子。例如,“删除缺失值”可能匹配到
DropNullsOperator。 - 算子排序与兼容性检查 :检查这些候选算子是否能连在一起用——比如前一个算子输出的是 DataFrame,后一个是否接受 DataFrame 作为输入?字段名是否对得上?
- 算子复用判断:如果现有算子不能直接满足需求,它会先尝试用****提示模板调用大模型,看看能否通过改写已有代码逻辑来复用。
- 算子生成 :只有当复用不可行时,才启动真正的代码生成——它采用RAG+ 少样本学习的方式:从历史高质量算子示例中检索相似任务的代码,再结合当前需求,让大模型生成新算子代码。生成后还会自动运行单元测试并调试,确保代码能稳定执行。
流水线组装
当所有需要的算子都通过了有效性验证,流水线构建智能体就登场了。它的任务是把这些算子“串起来”,形成一条完整的数据流水线。
- 它将整条流水线表示为一个有向无环图:每个节点是一个算子,每条边代表数据流向。
- 例如:
ReadCSV → DropNulls → GroupByMonth → PlotLine,箭头表示前一个算子的输出是后一个的输入。 - 它还会自动定义初始连接关系,确保数据能从源头顺利流到终点。
验证
最后一步是端到端集成测试 :
- 流水线验证智能体会在一个隔离的沙箱环境中,用一小份真实或合成的数据样本来运行整条流水线。
- 它重点检查两件事:
- 连通性:各算子之间是否真的能传数据?有没有字段名不一致、类型不匹配等问题?
- 运行时行为 :代码会不会报错?输出结果是否符合预期(比如图表是否成功生成)?
- 如果发现问题(比如
GroupByMonth报错说没找到date列),它会自动尝试修复:可能是调整参数、修改连接、甚至替换某个算子。 - 一旦流水线通过全部验证,结果报告智能体就会生成一份人类可读的报告,并输出最终的可执行流水线定义 ——通常是一段结构化的 JSON 或 Python 脚本,可直接部署运行。
5.3 总结
总的来说,与 Data-Juicer 的智能体(agent)方法 [6] 不同,DataFlow-Agent 展现出更强的自主性。我们来拆解一下这个区别:
- Data-Juicer 的做法 :它更像是一个“高级配置员”——它只能从一个预先写好、固定不变的操作符库中,挑选并按顺序排列这些操作符,再调整它们的参数。比如,它知道有“去重”“过滤空行”“切分句子”这些现成工具,但它不能创造新工具 ;遇到库中没有的功能,它就束手无策。
- DataFlow-Agent 的做法 :它更像一位“现场程序员”。当发现当前工具箱里缺某个功能时,它不卡住,而是自己动手写代码来实现——先检索相似案例,再复用已有逻辑片段,最后组合生成一段可运行的新代码;写完还不算完,它会立刻运行测试、检查结果是否正确 ,如果出错,就自动修改重试——这个“写→测→改→再测”的闭环,就是它的自修正验证循环 。
换句话说:
Data-Juicer 是在“乐高说明书”里挑零件拼模型;
DataFlow-Agent 是看着图纸,自己用积木现掰、现搭、现调试 ,直到搭出说明书里根本没有的新结构。
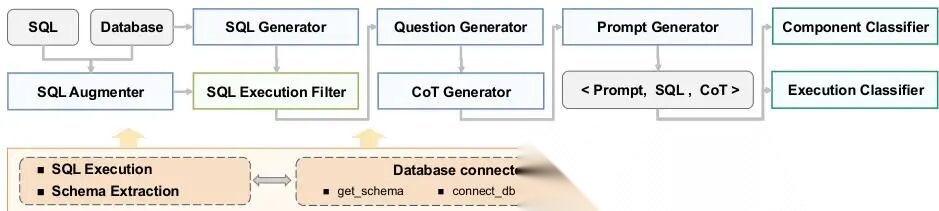 图7 DataFlow 中文本到 SQL流水线的整体框架
图7 DataFlow 中文本到 SQL流水线的整体框架
因此,DataFlow-Agent 不只是生成配置文件,而是能端到端构建真正可适应、可演化的数据流水线(adaptive pipeline) 。例如,用户突然提出:“请把所有中文评论里提到‘2024’或‘明年’的记录单独抽出来,并转成 SQL 查询”,系统无需人工开发新模块,就能动态生成并验证对应的 Python 数据处理代码 + SQL 生成逻辑,直接交付可用结果。
6 使用案例与数据流水线
DataFlow 集成了一套丰富的数据流水线,覆盖多种以文本为中心的任务领域,比如:
- 文本处理 :例如清洗脏数据、标准化大小写、分词、去重、拼写纠错等;
- 数学推理类数据构建 :比如从自然语言题目中提取数学表达式、生成带推理步骤的问答对、构造多步计算的训练样本;
- 文本转 SQL 生成 :把“查一下销售额超过100万的北京门店”这样的中文句子,自动转化为可执行的 SQL 查询语句;
- 智能体驱动的数据准备 (Agentic Data Preparation):让 AI 智能体(agent)像人类数据工程师一样,自主分析原始数据、识别缺失字段、调用工具补全信息、验证一致性,并生成高质量训练数据。
除此之外,DataFlow 还支持从 PDF 文件和教科书等非结构化文档中,抽取并规范化结构化知识 。
这类能力支撑了三类关键任务:
- 模式构建 :自动生成数据库表结构或 JSON Schema;
- 领域对齐 :把通用模型输出映射到特定行业术语(比如把“用户”映射为银行场景下的“客户”,把“订单”映射为“交易流水”);
- 指令合成 :基于教材内容自动生成 SFT(监督微调)用的指令-回答对,例如:
指令 :请用一句话解释什么是“第三范式(3NF)”。
回答 :如果一个关系模式满足第二范式,且所有非主属性都不传递依赖于候选键,则该模式属于第三范式。
所有这些流水线都由两类核心组件构成:
- 可复用的操作符 :就像乐高积木,每个 operator 做一件明确的事,例如
pdf_to_text()、sql_parse()、math_step_extractor(); - 声明式工作流描述 :用户不用写执行逻辑,只需用 YAML 或 JSON 描述“先做什么、再做什么、哪些步骤并行”,DataFlow 自动调度执行。
举例说明声明式工作流:
steps: -name:extract_text operator:pdf_to_text input:"manual.pdf"-name:split_chapters operator:chapter_splitter depends_on:[extract_text]-name:build_schema operator:textbook_schema_builder depends_on:[split_chapters]
这段配置的意思是:“先从 PDF 提取文字 → 再按章节切分 → 最后基于各章节内容构建知识模式”。你改几个字段,就能快速适配新教材、新文档类型,几乎不用写新代码 。
6.1 DataFlow 中的文本到 SQL 数据流水线案例研究
我们首先设计了一组专门定制、可重复使用的“文本到 SQL”操作符。这些操作符就像乐高积木一样,每个都负责一个明确的小任务,这样整个流程就变得模块化 ——可以单独测试、替换或升级某一块;也更可扩展 ——比如以后要支持新数据库类型,只需新增一个适配的操作符,不用改整个系统。
如图 7 所示,DataFlow 提供了两条并行的数据流水线 ,专门用来构建高质量的 Text-to-SQL 训练数据集:
- 第一条流水线 :从真实用户的自然语言提问出发,用大模型自动生成对应的正确 SQL 查询,并自动验证其在真实数据库上的执行结果是否合理;
- 第二条流水线 :反向操作——先随机生成合法、有意义的 SQL 查询(例如:
SELECT product_name FROM sales WHERE month = 'May' ORDER BY revenue DESC LIMIT 1),再让大模型把它“翻译”成贴近人类表达习惯的中文问句,并过滤掉生硬或歧义的样本。
这两条流水线协同工作,像“双向质检员”,显著提升数据集的语言多样性、SQL 正确性和语义对齐度。
此外,第 6.1.3 节介绍了 DataFlow 对数据库操作 (database operations)的原生支持,比如自动连接数据库、执行查询、获取表结构元数据等;还提供了灵活的提示词模板机制 ——你可以用类似 Jinja 的语法写模板,把数据库信息、用户问题、历史对话等动态填入提示词中,让 LLM 更精准地理解上下文、生成可靠 SQL。例如:
# 示例:一个简单的 Text-to-SQL 提示词模板(伪代码逻辑,非真实运行)prompt_template = """你是一个专业 SQL 工程师。请根据以下信息生成标准 PostgreSQL 语句。数据库表结构:{schema}用户问题:{question}请只输出 SQL,不要解释,不要加任何标记符。"""# 假设 schema = "products(id, name, price); orders(product_id, amount)"# question = "价格最高的商品名称是什么?"# 则填充后 prompt 就是完整提示词,送入 LLM 生成:SELECT name FROM products ORDER BY price DESC LIMIT 1
6.1.1 算子
SQL 生成器
这个算子的作用是:让大语言模型从零开始写 SQL 查询语句 ,而且写的 SQL 要既“合法”,又“多样”。
怎么做到的?它用四个难度等级来引导 LLM:
- 简单
- 中等
- 复杂
- 极其复杂
这些等级不是随便叫的,而是有明确定义 + 少量示例——就像老师先给几道例题,再让学生模仿出题。
为了让 LLM 写得准,它会提供完整的数据库上下文,包括:
- 所有表的
CREATE TABLE语句(也就是表结构) - 每张表里随机抽几行真实数据(帮助理解字段含义,比如
age INT是什么范围、status VARCHAR可能填 “active” 还是 “inactive”) - 还可能额外加入一些高级 SQL 函数(如
ROW_NUMBER()、JSON_EXTRACT()),让生成的 SQL 更贴近真实业务场景。
另外,自然语言问题往往只关心“查哪几列”,所以 SQL 生成器还会控制返回列的数量(比如用户问“谁工资最高”,就只生成 SELECT name FROM ...,而不是把整张表都 SELECT 出来)。
最后,这个算子很灵活:换一个数据库,只需要改一下提示词模板就行,不用重写代码。
SQL 增强器
和 SQL 生成器不同,它不从零写 SQL,而是对已有的 SQL 做“变形”增强 ,生成一批语义相近但形式不同的新 SQL。
比如原始 SQL 是:
SELECT name FROM users WHERE age > 30;
增强后可能变成:
- 改数据值:
WHERE age > 35 - 改结构:加
ORDER BY name LIMIT 5 - 改业务逻辑:变成
WHERE age BETWEEN 30 AND 40 AND status = 'active' - 加复杂度:嵌套子查询或用
JOIN关联另一张表 - 加高级功能:用
CASE WHEN分类统计 - 优化性能:加索引提示或重写为更高效写法
每次随机选一种策略,再用 few-shot 提示让 LLM 执行。同样,也会提供数据库结构和样例数据作为背景知识。
Text2SQL 一致性过滤器
现实中,很多现成的“自然语言问题 + SQL”配对其实是错配的 。比如:
- 问题:“找出所有北京的用户”
- SQL 却写成了:
SELECT * FROM orders WHERE city = 'Shanghai';
这种数据不能用来训练模型,否则会教坏模型。
这个过滤器就干一件事:用 LLM 判断一个问题和它对应的 SQL 是否真正匹配 。
输入是“问题 + SQL”,输出是“一致 / 不一致”。不一致的直接丢掉。
SQL 执行过滤器
即使 SQL 看起来语法没问题,也可能在真实数据库上跑不通,或者跑得太慢。这个过滤器做两件事:
- 能否执行成功? —— 把 SQL 丢进目标数据库试运行,报错就过滤掉;
- 是否太慢? —— 设置一个时间阈值,超过就丢弃,保证系统响应及时。
这样确保最终留下的 SQL,既是合法的,又是可用的。
问题生成器
它的任务是:根据一条 SQL,反向生成一句自然语言问题 ,而且这句问题要“语义等价”——意思完全一样,只是说法不同。
但它不止生成一种风格,而是支持四种维度的风格控制:
- 语气与正式程度 :可以是正式的或口语化的
- 句式与意图 :可以是命令式、疑问句、陈述句
- 信息密度与清晰度 :可以简洁、详细模糊、甚至带比喻
- 交互模式 :可以模拟角色或步骤化指令
每次随机选一个风格组合,再结合数据库结构和 SQL 本身,在提示词指导下让 LLM 生成对应的问题。
思维链生成器
思维链(CoT)是指让模型“边想边写”,把解题过程一步步展开。例如:
用户问:“哪个城市的平均订单金额最高?”
CoT 可能是:
- 首先需要按城市分组;
- 计算每个城市的平均订单金额;
- 找出平均值最大的那个城市;
- 最终 SQL 是:
SELECT city FROM orders GROUP BY city ORDER BY AVG(amount) DESC LIMIT 1;
这个算子会把以下四样东西喂给 LLM:
- 任务说明
- 数据库结构
- 自然语言问题
- 对应的 SQL
然后让它输出完整推理链,最后必须包含正确的 SQL。
验证时,会从推理文本中自动提取 SQL,并在数据库上运行,结果必须和参考 SQL 一致,才算这条 CoT 是有效的。
提示词生成器
这是整个流程的“组装工”。它把多个关键信息打包成一个高质量提示词,供后续 LLM 使用。
一个好 prompt 应该包含三部分:
- 自然语言问题
- 数据库结构
- 明确的任务指令
这个算子就是把这些拼在一起,生成最终可输入模型的 prompt 字符串。
SQL 组件分类器
它不看语义,只看 SQL 的语法结构复杂度 ,按 Spider 数据集的标准,把 SQL 分成四级:
- 简单(simple):单表查询,无聚合、无 JOIN
- 中等(moderate):含
GROUP BY或ORDER BY或简单聚合(如COUNT(*)) - 困难(hard):含嵌套子查询、
INTERSECT、多表 JOIN - 极难(extra hard):多层嵌套、复杂
CASE、窗口函数等
判断依据是 SQL 中出现的语法组件数量和类型,比如:
SELECT COUNT(*), AVG(salary) FROM emp GROUP BY dept→ 含聚合 + GROUP BY → 属于 moderate 或 hardSELECT name FROM (SELECT * FROM emp WHERE salary > (SELECT AVG(salary) FROM emp))→ 含子查询 → 至少 hard
这个分类器就是按规则逐项检查,打上难度标签。
SQL 执行分类器
这个分类器关注的是:同一个问题,不同模型写出来的 SQL,成功率有多高?
做法是:
- 对同一个自然语言问题 + 同一套 prompt,让某个 LLM 连续生成 条 SQL(比如 )
- 每条都在数据库上执行,统计成功次数 (即没报错且结果合理)
- 算成功率
然后根据成功率划分难度:
- → 简单(easy)
- → 中等(moderate)
- → 困难(hard)
- → 极难(extra hard)
注意:这个难度是模型相关的 。同一个问题,GPT-4 可能成功率 0.95(对它来说是 simple),而一个小模型可能只有 0.2(对它就是 extra hard)。这反映了模型能力差异,也更适合用于评估和教学。
我们可以用 Python 快速模拟这个逻辑:
def classify_execution_difficulty(n: int, k: int, thresholds=(0.9, 0.6, 0.3)) -> str: """ 根据执行成功率 n/k 分类 SQL 执行难度 thresholds: (high, medium, low) 对应边界 """ ratio = n / k if k > 0else0.0 if ratio >= thresholds[0]: return"简单(simple)" elif ratio >= thresholds[1]: return"中等(moderate)" elif ratio >= thresholds[2]: return"困难(hard)" else: return"极难(extra hard)"# 示例:10次尝试,7次成功print(classify_execution_difficulty(n=7, k=10)) # 输出:中等(moderate)
6.1.2 流水线
在 DATAFLOW 的设计哲学中,流水线被按照功能拆解为彼此独立的“算子”单元,这样做的好处是:同一个算子可以在不同流水线中反复使用,极大提升复用性 。
就像搭积木一样——你有一个“检查SQL能不能运行”的积木,不管是生成新SQL还是优化旧SQL,都可以直接拿来用,不用重复造轮子。
如图7所示,这些可复用的算子被组合成两条不同的流水线,分别用于支持两种场景下的 SQL 数据合成:
- SQL 生成流水线 :从零开始“无中生有”地生成 SQL;
- SQL 精炼流水线 :以已有的 SQL 为起点,“打磨升级”出更高质量的新数据。
SQL 生成流水线
这条流水线的目标是:给定一个数据库结构,自动生成配套的 SQL 查询 + 自然语言问题 + 推理过程 + 提示词模板 + 难度标签 。整个流程像一条装配线,每个环节由一个专用算子完成:
- SQL 生成器(SQL Generator) :根据数据库表名、字段名、约束等信息,让大模型(LLM)直接写出原始 SQL。
→ 举例:输入 schema:“users(id, name, age), orders(user_id, amount)”,模型可能输出SELECT name FROM users WHERE id IN (SELECT user_id FROM orders)。 - SQL 执行过滤器(SQL Execution Filter) :把上一步生成的 SQL 拿去真实数据库(或模拟执行器)里跑一遍,能成功执行且返回合理结果的才留下,报错/超时/空结果的全扔掉 。
→ 这一步筛掉大量语法错误、字段不存在、JOIN 写反等“假大空”SQL。 - 问题生成器:对每个留下的 SQL,让 LLM 反向写出一个自然语言问题,要求这个问题****只靠该 SQL 就能准确回答 。
→ 例如 SQL 是SELECT COUNT(*) FROM orders WHERE amount > 100,问题可能是:“金额超过100元的订单一共有多少个?” - 思维链生成器:为这个“问题→SQL”配对,生成人类解题时会写的中间推理步骤(CoT)。
→ 例如:“首先筛选出金额大于100的订单;然后统计这些订单的数量。” - 提示词生成器 :把上面的问题、SQL、CoT 整合成一段标准格式的训练提示
- SQL 组件分类器(SQL Component Classifier) & SQL 执行分类器(SQL Execution Classifier) :两个轻量级模型(或规则+LLM)分别给数据打标签:
- 前者判断 SQL 包含哪些复杂成分(如嵌套子查询、多表 JOIN、GROUP BY 等),反映语法难度 ;
- 后者通过执行耗时、结果行数、是否触发索引等指标,评估执行难度 。
→ 最终每条数据都带上“语法难+执行难”的双重标签,方便后续按需采样。
SQL 精炼流水线
这条流水线不从零开始,而是以一批已有 SQL为起点,做提质增效的迭代优化 。流程更像“老酒新酿”:
- 种子 SQL 质量验证 :先用 SQL 执行过滤器(SQL Execution Filter) 检查 seed SQL 是否仍可运行(防止 schema 变了导致失效)。
- 文本-SQL 一致性过滤器 :检查 seed SQL 和它原本配对的自然语言问题是否还匹配——比如问题说“最近一周”,但 SQL 写的是
WHERE date > '2020-01-01',那就不一致,淘汰。 - SQL 增强器 :对通过前两关的 seed SQL,做语义保持的变形增强,例如:
- 把COUNT(*)改成COUNT(DISTINCT user_id);
- 把单表查询扩展为带LEFT JOIN的多表查询;
- 把WHERE age > 18改成WHERE age BETWEEN 18 AND 65。
→ 关键是:改完后语义不变,但表达更丰富、更具多样性 。 - 后续流程复用生成流水线 :增强后的 SQL,再走一遍和上面完全相同的路径:
→ 执行过滤 → 生成新问题 → 补充 CoT → 构建 prompt → 打难度标签。
相当于把“精炼出的新 SQL”当作“新生成的 SQL”来处理,保证整套数据质量标准统一。
关键洞察 :两条流水线共享全部算子,只在起点和早期过滤策略上有差异。这种模块化设计让 DATAFLOW 能灵活适配数据合成的不同阶段——冷启动靠生成,热优化靠精炼。

表2 预训练数据过滤效果对比:各模型均使用 300 亿 token(30B-scale tokens)规模的预训练数据,在通用评测基准上的性能表现。
6.1.3 DataFlow-support 机制
数据库管理模块
你可以把“数据库管理模块”想象成一个“数据库翻译官”:它不直接和各种数据库打交道,而是站在中间,统一接收上层发来的指令,再把它翻译成对应数据库能听懂的语言,并把结果整理好交回去。
为什么需要这个“翻译官”?因为不同数据库的连接方式、SQL语法细节、错误提示格式都不一样。如果每个操作都要重复写一遍连接代码、处理异常、解析表结构,那整个流程会非常混乱、难维护。所以 DataFlow 把这些底层细节全部封装进 Database Manager 模块 ,对外只提供三个简单、稳定、通用的操作接口:
connect_db():建立数据库连接execute_sql():执行 SQL 并返回结果get_schema():获取整张表的结构信息
为了支持多种数据库,DataFlow 定义了一个抽象基类 DatabaseConnector——它不干具体活,只规定“每个数据库连接器必须实现哪几个方法”。开发者只需继承它,针对自己的数据库(如 PostgreSQL)写一个子类,填好怎么连、怎么执行 SQL、怎么取表结构,就自动接入系统了。例如:
from abc import ABC, abstractmethodclass DatabaseConnector(ABC): @abstractmethod def connect_db(self): pass @abstractmethod def execute_sql(self, sql: str): pass @abstractmethod def get_schema(self, table_name: str): pass# 示例:为 SQLite 实现的具体子类import sqlite3class SQLiteConnector(DatabaseConnector): def __init__(self, db_path): self.db_path = db_path self.conn = None def connect_db(self): self.conn = sqlite3.connect(self.db_path) return self.conn def execute_sql(self, sql: str): cursor = self.conn.cursor() cursor.execute(sql) return cursor.fetchall() def get_schema(self, table_name: str): cursor = self.conn.cursor() cursor.execute(f"PRAGMA table_info({table_name});") return cursor.fetchall()# 使用示例db = SQLiteConnector("example.db")db.connect_db()rows = db.execute_sql("SELECT name FROM users WHERE age > 25")schema = db.get_schema("users")
这段代码演示了如何用统一接口操作 SQLite:不管将来换成 MySQL 还是其他数据库,上层代码完全不用改,只换一个 db 对象就行。这正是“解耦”和“可扩展”的关键。
提示模板模块
生成 SQL 的任务看似简单,其实场景千差万别:
- 查数据和改数据用的提示词不一样;
- 做向量搜索需要嵌入式 SQL,和普通 SQL 结构不同;
- 简单查询和复杂查询对大模型的理解难度也不同,需要更清晰的提示引导。
如果每种情况都单独写一个 SQL 生成器,代码会爆炸式增长、难以复用。于是 DataFlow 引入了 Prompt Template 模块 ——它把“怎么告诉大模型该干什么”这件事抽出来,做成可插拔的组件。
核心思想是:SQL 生成器本身不动,只负责调用 prompt.build_prompt(...) 获取最终提示词,然后把提示词喂给大模型。而 build_prompt 方法由不同的 Prompt 类来实现。比如:
CRUDPrompt:生成标准增删改查 SQL,强调字段名、条件语法;VectorSearchPrompt:在提示中加入向量函数说明(如cosine_similarity(embedding, ?));HardQueryPrompt:对复杂查询,先拆解问题步骤,再逐步构造 SQL。
这样,切换场景只需换一个 Prompt 实例,无需动 SQL Generator 的任何逻辑。举个例子:
class CRUDDPrompt: def build_prompt(self, table_name: str, condition: str) -> str: returnf"""你是一个 SQL 专家。请为表 '{table_name}' 生成一条 SELECT 语句,条件是:{condition}。要求:只输出纯 SQL,不加解释,不加代码块标记。"""class VectorSearchPrompt: def build_prompt(self, table_name: str, query_embedding: list) -> str: emb_str = ", ".join(map(str, query_embedding[:3])) + ", ..." returnf"""你是一个向量数据库 SQL 专家。表 '{table_name}' 包含列 'id', 'text', 'embedding'。请生成一条 SQL,使用 cosine_similarity 计算 embedding 与 [{emb_str}] 的相似度,并按相似度降序取前 5 条。只输出纯 SQL,不加解释,不加代码块标记。"""# 使用时只需替换 prompt 实例prompt = CRUDDPrompt()sql = llm_generate(prompt.build_prompt("products", "price < 100 AND category = 'book'"))prompt = VectorSearchPrompt()sql = llm_generate(prompt.build_prompt("docs", [0.1, -0.5, 0.9, 0.2]))
换句话说:Prompt Template 模块让“提示工程”变得像换电池一样简单——SQL Generator 是手电筒,Prompt 类就是可更换的电池型号。
7 实验
在本节中,我们展示了一组全面的实验,覆盖文本、数学和代码三类数据的准备任务,以及基于 DataFlow 构建的两个典型工作流:Text-to-SQL和 AgenticRAG。
除了 AgenticRAG 实验采用 Recall 框架 [9, 54] 进行训练外,其余所有实验均统一使用 LLaMA-Factory训练框架。我们还进一步将这些不同模态(文本、数学、代码、SQL、RAG)的任务整合起来,用于评估模型在多样化任务上的通用指令微调能力——换句话说,就是看一个模型经过 DataFlow 处理后,是否能更“聪明”地理解并执行各种类型的人类指令,而不仅限于某一种任务。
表 3 监督微调数据过滤效果对比
该表格展示了在相同规模下,不同数据筛选方法对监督微调数据集质量的影响。评测维度包括三类代表性基准任务:
- 数学(Math) :如 MATH、GSM8K 等需要多步推理的数学题;
- 代码(Code) :如 HumanEval、MBPP 等需生成可运行代码的任务;
- 知识(Knowledge) :如 TruthfulQA、MMLU 等考察事实准确性与常识推理的能力。
表格横向对比了多种过滤策略(例如:基于模型置信度过滤、基于规则清洗、基于 reward model 打分筛选等),纵向呈现各策略在上述三类基准上的性能得分。这帮助我们回答一个关键问题:不是数据越多越好,而是哪些数据“更值得学”? DataFlow 的核心思想之一,正是通过自动化流程识别并保留高价值样本,剔除噪声或低质量样本,从而让后续训练更高效、更鲁棒。

7.1 文本数据准备
7.1.1 实验设置
我们用 DATAFLOW 系统,来测试高质量文本数据准备对两个关键训练阶段的影响:预训练 和 监督微调 。整个实验分为三个互为补充的场景,就像“三块拼图”,分别考察不同规模、不同用途下的数据质量提升效果。
(1)预训练数据过滤
我们从一个超大规模公开语料库 SlimPajama-627B 中,先抽取出一个含 1000 亿 token 的子集(即 100B tokens),然后用 DATAFLOW 提供的一系列预训练文本过滤器 进行筛选。每个过滤器都会打分,并选出得分最高的 前 30% ——也就是约 300 亿 token(30B tokens) ,作为最终用于训练的数据。
接着,我们用这些数据,从零开始训练一个中等规模模型:Qwen2.5-0.5B ,训练量固定为 30B tokens,使用 Megatron-DeepSpeed 框架。最后对比以下四种数据选择方式:
- Random-30B :随机采样 30B tokens —— 就像闭着眼睛从一整本书堆里随便抓一把纸页,不看内容好坏。
- FineWeb-Edu-30B :用 FineWeb-Edu [50] 提出的“教育价值”过滤方法,优先保留教学类、解释性强、适合学习的文本(比如维基百科讲解、教科书段落)。
- Quarting-30B :用 Quarting 方法 [64] 设定四维阈值打分筛选:
- 教育价值(
educational_value)≥ 7.5 - 事实与冷知识密度(
facts_and_trivia)≥ 4.0 - 所需专业知识门槛(
required_expertise)≥ 5.0(即不能太浅显,要有一定深度) - 写作风格质量(
writing_style)≥ 1.0(排除口语化、碎片化、语法混乱的文本)
- DataFlow-30B :不是只用某一个过滤器,而是把所有 DATAFLOW 的 PT 过滤器结果做交集(intersection) ,再取交集后的 top 30%。相当于“层层把关”——只有同时通过教育性、事实性、专业性和表达质量四重审核的文本,才能留下。这就像四位资深编辑每人独立审稿,只保留所有人都打了高分的稿件。
(2)监督微调数据过滤(5K 规模) 这次聚焦小样本微调场景:我们用 Qwen2.5-7B 基座模型 (70 亿参数),在 LLaMA-Factory 框架下做 SFT 微调。数据来自两个常用对话数据集:WizardLM (角色扮演式问答)和 Alpaca 。
对每个数据集,我们对比两组 5000 条样本:
- 一组是随机采样的 5K 条;
- 另一组是用 DATAFLOW 的 SFT 数据过滤流水线 筛选出的 5K 条——它会评估每条指令是否清晰、响应是否完整、是否存在幻觉、是否符合安全规范等。
此外,我们还用 DATAFLOW 的两个生成模块:
- Condor Generator
- Condor Refiner
→ 合成出一个高质量的 15K 规模 SFT 数据集:DATAFLOW-SFT-15K ,再用 DATAFLOW 的 SFT 过滤器进一步提纯。
最后,在多个权威评测套件上测试模型能力:
- 数学 :如 GSM8K、MATH
- 编程 :如 HumanEval、MBPP
- 知识理解 :如 TruthfulQA、SIQA
(3)对话领域合成 这次目标是构建更贴近真实用户对话的高质量中文/英文混合对话数据。我们用 DATAFLOW 的对话生成流水线 ,合成出 DATAFLOW-Chat-15K 数据集,然后在此数据上微调 Qwen2.5-7B-Base 。
对比基线包括:
- ShareGPT-15K :从 ShareGPT 网站爬取的真实用户与 ChatGPT 的对话(但未经清洗)
- UltraChat-15K :用大模型自动生成的对话数据
- 还有它们各自的完整未截断版本,用于观察数据长度是否影响性能。
评测任务分两类:
- 领域专项任务 :如 TopDial、Light(轻量级多轮推理对话)
- 通用大模型基准 :
- MMLU:涵盖 57 个学科的多项选择题,测知识广度与深度
- AlpacaEval :让模型两两对决,由 GPT-4 打分,看谁的回答更自然、有用、无害
- Arena-Hard [41]:精选高难度开放生成题,挑战模型推理、规划与一致性能力
7.1.2 实验结果
预训练阶段(Pre-training)
我们先看表2的结果。在六个通用评测基准上,DATAFLOW 方法取得了最高的平均分:35.69 ,超过了随机采样(Random,35.26)、FineWeb-Edu(35.57)和 Quarting(35.02)。
关键点来了:所有方法都用了相同的 30B token 预算 ,但 DATAFLOW 的效果更好。为什么?因为它不是简单地“挑数据”,而是用了一套多过滤器交集策略 ——就像让多个专家老师一起审题,只保留所有人都认为“好、清晰、语义一致”的样本。结果得到的数据集更干净、更高质量,从而让一个从零开始训练的 0.5B 规模 Qwen2.5 模型学得更好、泛化能力更强。
举个例子:
假设你有 1000 篇学生写的数学解题过程,其中有些步骤跳步、有些符号乱写、有些答案错误但没标出。
- Random:闭眼抓 100 篇;
- FineWeb-Edu:按网页来源粗筛;
- DATAFLOW:先用规则过滤掉格式错误的 → 再用小模型打分筛选逻辑连贯的 → 再用大模型重评分选出语义最准确的 → 最后取这三轮都留下的交集。
最终可能只剩 60 篇,但每一篇都像教科书范例——这就是“更少但更精”。
监督微调阶段(SFT)
再看表3:我们在 5K 规模的监督微调数据上做实验,对比了三种数据源——Alpaca、WizardLM 和 DATAFLOW 合成的数据。
结果发现:无论评测任务是数学、编程还是常识知识(Knowledge),只要用 DATAFLOW 的过滤流程处理这三类数据,性能全都比随机采样更好 。
更有趣的是——哪怕完全不加过滤 ,只用原始的 DATAFLOW-SFT-15K 数据(即直接拿合成数据训练),它在数学任务上的平均分就达到了 49.3 ,而经过精心过滤后的 Alpaca 才 39.8、WizardLM 才 44.8。说明 DATAFLOW 生成的数据本身质量就很高,自带“强基底”。
而且你看它的提升空间还很小:随机版 49.3 → 过滤后 49.7,只涨了 0.4 分;而 Alpaca 是 34.1 → 39.8(+5.7),WizardLM 是 38.2 → 44.8(+6.6)。
对话合成阶段
最后看表4:这是在对话领域做的实验,用不同 15K 规模的 SFT 数据训练 Qwen2.5-7B 模型 ,然后测整体能力与对话专项能力。
- 整体通用评测均值从 26.36 提升到 28.21 ;
- 对话能力从 7.05 跳到 10.11 ;
- 而且这两个指标都超过了 ShareGPT 和 UltraChat —— 这两个可是目前主流的、基于真实人类对话构建的大规模数据集。
这说明什么?
合成数据 ≠ 假数据;
只要合成得够聪明(比如用 DATAFLOW 的多步校验机制),再配上科学的清洗与过滤流程,就能做出比人工收集数据更高效、更可控、甚至更强的训练原料。
高质量合成数据过滤栈传统人工指令数据
# 示例:模拟 multi-filter intersection 的核心逻辑(简化版)def multi_filter_intersection(samples, filters): """ samples: 原始样本列表,每个样本是 dict,含 'text', 'score_logic', 'score_semantic' 等字段 filters: 过滤器列表,每个是函数,返回 True 表示通过该关 返回:所有过滤器都通过的样本子集 """ result = samples for f in filters: result = [s for s in result if f(s)] return result# 示例过滤器(实际中会更复杂)def logic_consistency_filter(sample): return sample.get("score_logic", 0) >= 0.85def semantic_clarity_filter(sample): return sample.get("score_semantic", 0) >= 0.9# 使用示例raw_data = [ {"text": "解:x=2", "score_logic": 0.92, "score_semantic": 0.95}, {"text": "因为a+b=c所以答案是5", "score_logic": 0.6, "score_semantic": 0.7},]filters = [logic_consistency_filter, semantic_clarity_filter]clean_data = multi_filter_intersection(raw_data, filters)print(clean_data) # 输出只有第一个样本
7.2 数学推理数据准备
7.2.1 实验设置
我们基于 DATAFLOW 推理流水线,构建了一个高质量的合成数学推理数据集,专门适配大规模推理生成任务。目标是对比三种不同来源的训练数据效果:
(1) 从 Open-R1 数据集 [28] 中随机抽取的 1 万个样本;
(2) 从 Synthetic-1 数据集 [43] 中随机抽取的 1 万个样本;
(3) 我们用 DATAFLOW 构建的 1 万个合成样本数据集 —— DATAFLOW-REASONING-10K 。
数据合成方法(Data Synthesis Method)
整个数据生成过程严格遵循 DATAFLOW 推理流水线的核心结构,分为三个关键阶段:
问题合成
我们以 NuminaMath 数据集作为高质量“种子题库”(seed set),它本身已经过人工筛选和验证。然后,我们用 o4-mini 模型 (一个轻量但专精数学的小模型)配合 DATAFLOW 内置的“数学问题合成算子”(math problem synthesis operators),对这些种子题进行多样化扩展,生成大量风格各异、难度不一的候选题目,形成一个丰富的“候选题池”。
质量验证
所有生成的候选题,都会被送入 DATAFLOW 的 MathQ-Verify 模块 [53] 进行自动质检。这个模块像一位严格的数学老师,会检查每道题是否:
- 答案错误,
- 题干模糊、有歧义,
- 或逻辑自相矛盾。
检测出的问题会被直接剔除,只保留正确、清晰、逻辑严密的题目,确保最终数据集的正确性与鲁棒性 。
举例:一道题说“一个三角形三边长分别为 1、2、5”,MathQ-Verify 会立刻报警——因为不满足三角形不等式(1+2 < 5),根本构不成三角形,属于逻辑错误题,直接淘汰。
思维链生成
对所有通过质检的题目,我们调用 DATAFLOW 的 CoT-Generation 算子 ,提示 DeepSeek-R1 模型 为每道题生成完整的、分步骤的推理过程(即“思维链”)。不是只给答案,而是写出“为什么这么算”“每一步依据是什么”。
示例(简化版):
题目:小明有 5 个苹果,吃了 2 个,又买了 3 个,现在有几个?
CoT 输出:
第一步:原有 5 个;
第二步:吃掉 2 个 → 剩下 个;
第三步:再买 3 个 → 个;
答案:6 个。
评估方式
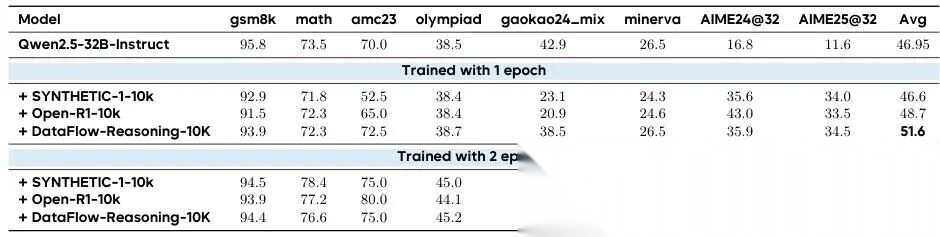
我们用这三组不同的 1 万条合成数据,分别微调同一个大模型:Qwen2.5-32B-Instruct 。然后在 8 个主流数学推理基准测试 上评测其性能
完整结果见下表(Table 5):
生成超参数
为了让模型在不同难度题目上发挥最佳效果,我们为生成 CoT 过程设置了两套采样策略:
- 对于 非 AIME 类题目 (如 GSM8K、MATH 等):
使用确定性更强的生成方式:temperature = 0(完全不随机,每次都选概率最高的词),top-p = 0.95(只从累计概率达 95% 的候选词中选,兼顾质量与一定多样性)。 - 对于 AIME 风格题目 (极难、开放性强、常有多解路径):
采用更“探索式”的采样:temperature = 0.6,top-p = 0.95,top-k = 20。
所有微调实验均在 10K 样本上进行,训练轮数为 1 轮或 2 轮 ,统一使用 Qwen2.5-32B-Instruct 作为基座模型。
7.2.2 实验结果
我们第一个观察是:在 Synthetic-1 随机子集上训练,对基础模型(base model)的提升非常有限。具体来说,在 AMC23 和 AIME 这两个数学推理评测基准上,训练 2 个 epoch 后虽然有轻微提升,但整体平均分只从 46.6(仅指令微调 baseline)升到 47.0 —— 几乎没变。
换句话说:就像让一个学生反复做一批质量参差不齐、答案没验证过的练习题,即使多练几轮,解题能力也很难明显提高。
而 Open-R1 这个合成子集效果就好得多:同样只训练 2 个 epoch,平均分就从 48.7 跳到了 54.2。这说明——Open-R1 风格的思维链数据,确实能有效提升一个 32B 规模大模型的数学推理能力。
更进一步,我们用 DataFlow 框架合成的数据集,仅用 10,000 条样本、训练 2 个 epoch,就达到了 55.7 的平均分 ,不仅超过了 Open-R1,也超过了 Synthetic-1。这说明 DataFlow 的三步组合非常有效:
- 第一步:用已验证的 NuminaMath 种子题 (高质量、人工校验过的数学题)作为起点,确保源头靠谱;
- 第二步:用 MathQ-Verify 过滤器自动筛掉错误或模糊的生成结果 (比如中间步骤算错、逻辑跳步、符号写反等);
- 第三步:用 DeepSeek-R1 模型驱动 CoT 生成 ,保证生成的过程既多样又严谨。
这三步合起来,相当于打造了一条「高精度数学解题示范生产线」:从好题出发,自动检查,再用强推理模型扩增——产出的每一条训练数据,都更准、更多样、更抗干扰。
最后,所有实验共同指向一个关键结论:
在数学推理任务中,数据的质量,比数据的数量更重要。
哪怕大家用的都是 10,000 条数据,只要我们的 DataFlow 流程产出的数据更干净、更合理、更贴近真实解题逻辑,模型表现就稳稳胜出。
7.3 代码数据准备
7.3.1 实验设置
我们想搞清楚:高质量的代码指令数据到底能不能提升大模型写代码的能力?
为了验证这一点,我们没有从头造数据,而是用了一个已有的优质种子数据集 —— Ling-Coder-SFT [12],然后用 DataFlow 框架里的 CodeGenDataset-APIPipeline对它进行加工处理。
具体怎么做呢?
- 首先,从 Ling-Coder-SFT 里随机挑出 2 万个原始样本 ;
- 然后,把这 2 万个样本“喂”给 DataFlow 的代码数据加工流水线(APIPipeline),让它自动清洗、筛选、增强、格式标准化;
- 最终,我们得到了三套不同规模但都经过严格质量把控的代码指令数据集:
DataFlow-Code-1K(1000 条高质量指令)DataFlow-Code-5K(5000 条)DataFlow-Code-10K(10000 条)
这些数据集的特点是:每一条都经过 pipeline 多道工序“精修”,比如去重、执行验证、语义合理性检查等,确保模型学到的是靠谱、可执行、结构清晰的代码指令 —— 而不是乱写的“伪代码”。
为了证明我们的数据更好,我们还拉了两个常用基线(baseline)来比一比,而且为了公平,全都只用 1000 条样本做微调:
- Code Alpaca (1k) [5]:从 Code Alpaca 数据集中随机抽的 1000 条;
- Self-OSS-Instruct-SC2-Exec-Filter-50k(1k) [63]:这是另一个更“硬核”的基线——它来自 SC2-Exec-Filter 数据集(名字里的
Exec-Filter就是“执行过滤”的意思),即每条指令都真实运行过代码并验证结果正确 ,再从中随机选 1000 条。
所有模型都用全参数监督微调(full-parameter SFT) 训练,也就是不冻结任何参数,让整个模型都跟着新数据一起学。
我们选了两个基础大模型来实验:
Qwen2.5-7B-Instruct(70 亿参数)Qwen2.5-14B-Instruct(140 亿参数)
评估时,我们在四个权威的代码生成评测基准上测试它们的表现:
- BigCodeBench [75]:覆盖真实开源项目中复杂、长上下文的编程任务;
- LiveCodeBench [30]:强调“边写边运行”的交互式编程能力;
- CruxEval [22]:专测模型对边界条件、异常逻辑、多步推理的理解;
- HumanEval [8]:经典的人工编写的函数级代码生成题(给函数描述,让模型写出完整可运行函数)。
最终成绩 = 这四个 benchmark 分数的平均值 (全部以百分比 % 表示)。
# 示例:计算最终平均分(假设某次实验四个 benchmark 得分如下)bigcodebench = 68.2 # %livecodebench = 59.7 # %cruxeval = 42.5 # %humaneval = 63.1 # %final_score = (bigcodebench + livecodebench + cruxeval + humaneval) / 4print(f"最终平均得分:{final_score:.2f}%") # 输出:65.88%
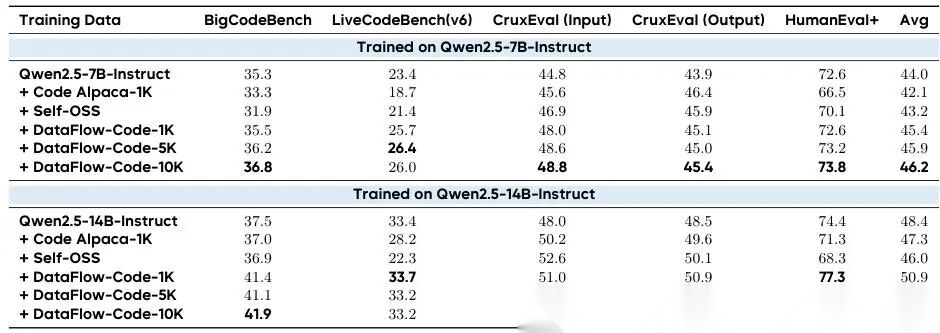
表 6 代码流水线:不同 SFT 数据集下 Qwen2.5-7B-Instruct 和 Qwen2.5-14B-Instruct 的性能对比
7.3.2 实验结果
表6显示,我们用DataFlow生成的合成数据集,在所有评测基准上,持续提升了两个模型——Qwen2.5-7B-Instruct 和 Qwen2.5-14B-Instruct——的代码生成能力。
先看较小的 7B 模型 :
- 即使只用 1000 条(1k) 我们合成的数据进行微调,它的表现就已经超过了两个主流开源基线:Code Alpaca(也是1k规模)和 SC2 执行过滤版(SC2-Exec-Filter)。
- 具体来说,
DATAFLOW-CODE-1K在 BigCodeBench、LiveCodeBench 和 CruxEval(Input/Output)上都比原始未微调的 Qwen2.5-7B-Instruct 更好;在 HumanEval+ 上也基本打平,没有明显下降。 - 当把训练数据量扩大到 5k 和 10k ,整体性能进一步提升。
- 尤其是
DATAFLOW-CODE-10K,它在所有指标上都拿到了最高分:
- BigCodeBench:36.8
- CruxEval(Input):48.8
- CruxEval(Output):45.4
- 综合平均分:46.2
这个平均分不仅超过了同为 1k 规模的 Code Alpaca-1K 和 SC2-Exec-Filter,说明我们的数据“含金量”更高——不是靠堆数量,而是靠质量。
再看更大的 14B 模型 :
- Code Alpaca-1k 和 SC2 过滤版也能带来一定提升,但幅度有限;
- 而我们的 DataFlow 数据,从 1k 到 10k,始终带来更大幅度的提升 。
DATAFLOW-CODE-10K达到综合平均分 51.0 ,具体为:
- BigCodeBench:41.9
- CruxEval(Input):52.9
- CruxEval(Output):51.0
- 特别值得注意的是 LiveCodeBench :
- Code Alpaca-1k 下只有 21.9 分,
- 而换成我们的
DATAFLOW-CODE-10K后,直接跃升到 33.2 分 ,涨了超过 11 分!
这说明 DataFlow 生成的数据里,包含了更多能让模型学会“写能跑通的代码”的线索——比如执行反馈、中间推理步骤、输入输出约束等,而不是泛泛的问答对。
一句话总结这些结果:
DataFlow 不是“换个名字发数据”,而是真正在数据构建逻辑上做了升级——它让每一条训练样本都带有可执行验证信号和结构化思维路径 。
所以哪怕只用 1k 条,就比别人 1k 条更好;用到 10k,优势还在扩大——说明它的数据是“可扩展的高质量”,不是“越往后越水”。
这验证了 DataFlow 的核心主张:在数据为中心的人工智能(Data-Centric AI)时代,怎么准备数据,比单纯加数据量更重要 。
7.4 文本到SQL的数据准备
7.4.1 实验设置
为了检验文本到SQL数据生成的效果,研究者构建了一个高质量的训练语料库,共包含 89,544 个样本 ,命名为 DATAFLOW-TEXT2SQL-90K 。
每个样本都包含三部分:
- 一个自然语言问题;
- 对应的标准 SQL 查询;
- 一段“思维链”推理过程(即模型一步步思考怎么把问题拆解成SQL的中间步骤,例如:“先要查销售额 → 再排序 → 最后取前5个”)。
这些数据不是人工一条条写的,而是通过系统性增强原始SQL查询生成的。具体来源如下:
- 37,517 条来自 Spider-train 数据集;
- 37,536 条来自 BIRD-train;
- 14,491 条来自 EHRSQL-train。
这种混合构造方式,让 DATAFLOW-TEXT2SQL-90K 具备了三方面多样性:
- SQL结构多样性 ;
- 问题表达多样性 ;
- 多步推理多样性 。
在实验中,DataFlow 方法所用的模型,只在 DATAFLOW-TEXT2SQL-90K 上做微调 ,不额外使用其他数据。
评估时,用了 6 个主流 Text-to-SQL 基准测试集 :
- Spider、BIRD、EHRSQL、Spider-DK、Spider-Syn、Spider-Realistic(贴近真实用户提问风格)。
在用大语言模型做推理(inference)时,尝试了两种解码策略:
- 贪心解码(Greedy decoding, Gre) :温度设为 0,每次只选概率最高的词,输出完全确定、不随机;
- 多数投票(Majority voting, Maj) :对每个问题,让模型以 temperature=0.8 生成 8 个不同答案 (因为温度 >0,会有一定随机性),然后:
- 尝试执行所有语法合法的 SQL;
- 看哪个 SQL 执行后返回的结果(比如表格内容)出现次数最多;
- 把这个“最常胜出”的 SQL 当作最终预测结果。
此外,还从 DATAFLOW-TEXT2SQL-90K 中随机抽样 50,000 条 ,构成更轻量的子集:DATAFLOW-TEXT2SQL-50K ;
作为对照,也从另一个公开数据集 SynSQL 中随机抽样同样数量(50K)的样本 ,用于公平比较。
Table 7 文本到SQL流水线:主流基准测试上大语言模型的性能表现。前两块列出闭源和开源的基础模型;后两块展示经过微调的模型,其中第一列标明所用训练数据。
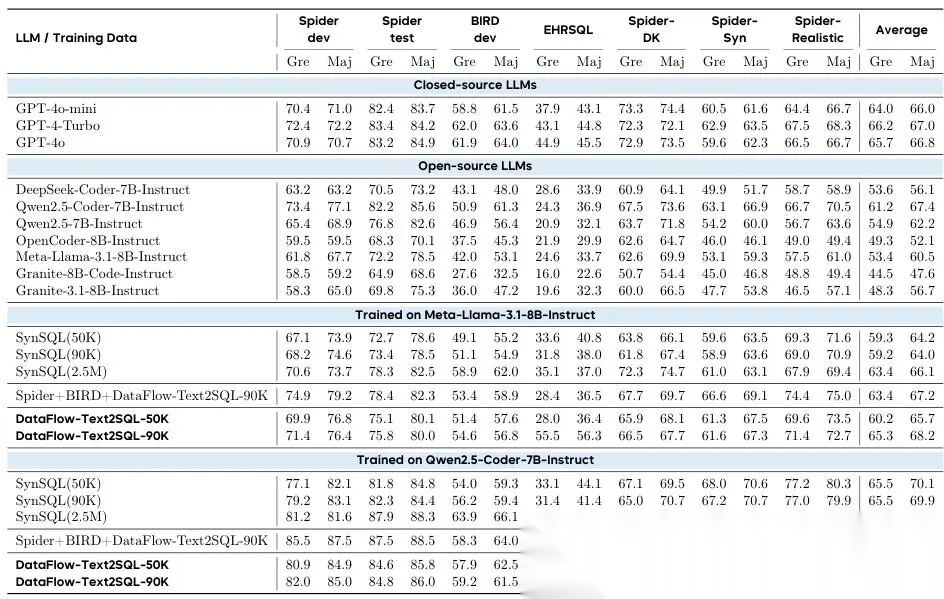
7.4.2 实验结果
如表 7 所示,DataFlow 生成的数据在多个主流基准测试中均带来了稳定且显著的性能提升 ,有力证明了 DataFlow 框架的有效性 [4]。
这里我们测试了两个主流开源大语言模型(LLM):
- Meta 公司的 Llama3.1-8B-Instruct [21]
- 阿里巴巴的 Qwen2.5-Coder-7B-Instruct [29]
当这两个模型在 DataFlow 生成的数据上进行微调后 ,它们在 Text-to-SQL(自然语言转 SQL 查询)任务上的表现,不仅明显优于各自原始未微调的基线模型(baseline),也超过了其他同类竞争模型。
举个具体例子:Qwen2.5-Coder-7B-Instruct 在 DataFlow 生成的数据上微调后,在三个重要测试集上的“执行准确率(Gre)”大幅提升:
- 在 Spider-dev 上:从 73.4 → 82.0 (+8.6)
- 在 BIRD-dev 上:从 50.9 → 59.2 (+8.3)
- 在极具挑战性的 EHRSQL 上:从 24.3 → 56.1 (+31.8!)
这个 +31.8 的跃升特别关键——说明 DataFlow 不仅能提升通用能力,更能显著增强模型在专业、复杂、低资源领域的理解与生成能力。
这些结果共同说明:DataFlow-Text2SQL-90K 这个数据集质量很高,对模型训练非常有用(strong training utility) 。
再来看它和其他合成数据集的对比。研究人员把 DataFlow 生成的数据(DATAFLOW-TEXT2SQL-90K 和 DATAFLOW-TEXT2SQL-50K)和另一个知名合成数据集 SynSQL [37] 做了直接比较。
即使在相同数据量级下,用 DataFlow 数据训练的模型也全面胜出:
| 数据集 | Spider-test(执行准确率 Gre) | BIRD-dev(执行准确率 Gre) |
|---|---|---|
| SynSQL(50K) [37] | 81.8 | 54.0 |
| DATAFLOW-TEXT2SQL-50K | 84.6 (+2.8) | 57.9 (+3.9) |
| SynSQL(90K) [37] | — | — |
| DATAFLOW-TEXT2SQL-90K | 更高 (超越 SynSQL(90K)) | 更高 (超越 SynSQL(90K)) |
更惊人的是:
即使只用 9 万条 DataFlow 数据(DATAFLOW-TEXT2SQL-90K)微调模型,其在 Spider-test、BIRD-dev 等难任务上的表现,竟可媲美用 SynSQL-2.5M(250 万条!)训练出来的模型 。
换句话说:
DataFlow 用 1/27 的数据量 (90K vs 2.5M),就达到了接近的效果;
这不是靠“堆数据”,而是靠“造好数据”——每一条都是高质量、高多样性、高难度覆盖的 Text2SQL 样本。
这充分说明:DataFlow 生成的训练数据,信息密度更高、语义更准确、分布更合理,真正实现了“少而精”的数据价值。
7.5 AgenticRAG 数据准备
7.5.1 实验设置
在 AgenticRAG 领域,自动生成多跳问题 一直是个难点。
本文用 DataFlow AgenticRAG 流水线构建了一个含****1 万个样本 的高质量多跳问题数据集,命名为 DataFlow-AgenticRAG-10k 。为了说明它有多“新”和“好”,研究者把它和目前主流的几个公开多跳问答数据集做了对比。
那这个 10k 数据集是怎么造出来的?整个流程分三步,像一条小型“AI工厂流水线”:
- 选原料(文档筛选) :
- 从维基百科的完整语料库里随机抽取一批原始文档 ,作为问题生成的基础材料;
- 但为了避免“作弊”,把所有已在测试基准中出现过的文档全部剔除 ——就像考试前老师不会把原题发给学生复习一样,保证评估公平。
- 初稿生成 :
- 用 o4-mini 模型 + DataFlow 的生成模块 ,根据上一步筛出的文档,自动写出多跳问题的初稿 。
- 比如给它一段关于“居里夫人”的维基文本,它可能生成:“她与谁共同获得1903年诺贝尔物理学奖?这位合作者后来又在哪一年获得诺贝尔化学奖?”——这就是一个天然的两跳问题。
- 质检把关 :
-
中间问题泄露 :比如问题里直接写出了第一跳答案;
-
逻辑错误 :比如问“苹果公司创始人是谁?他出生在哪个世纪?”,但乔布斯不是苹果唯一创始人,且“世纪”粒度太粗,无法精准验证;
-
难度失衡 :太简单或太难。
-
初稿难免有瑕疵,所以专门设计了一个验证模块 来“挑刺”,过滤掉四类不合格样本:
-
最终留下高质量、可验证、难度适中的 10k 多跳问题 → 就是 DataFlow-AgenticRAG-10k 。
模型训练与评估怎么做的?
- 训练框架用的是 ReCall;
- 基座模型选的是 Qwen2.5-7B-Instruct ;
- 优化方法用的是 GRPO 强化学习算法 ;
- 评估时,把生成温度设为 0.0 ——意思是让模型“不瞎发挥”,只输出最确定、最保守的答案,便于客观打分。
检索组件怎么配?
- 检索器用的是 E5-base-v2;
- 检索语料库是 2018 年维基百科 dump ;
- 所有文档的向量索引和嵌入计算,都用 FlashRAG [32] 预处理完成;
- 关键细节:模型在运行时可以自己决定每次检索返回多少条结果(top-k) ,而不是固定死;默认设为 topk = 5 ——既避免返回太多噪声,也不至于漏掉关键信息。
换句话说:这个系统不是“傻傻地取前 5 个”,而是让模型学会动态判断该查几个才够用 ,体现了 AgenticRAG 的“自主决策”特性。
7.5.2 实验结果
表8汇报了在四个多跳推理基准测试上的精确匹配性能。我们按训练数据集对结果进行分组,并计算**分布外平均值:即在计算每个数据集的平均分时,**排除该数据集自身对应的测试集 。这样做是为了检验模型是否真的学会了通用的多跳推理能力,而不是死记硬背某一个数据集的题目。
为了公平地和我们生成的合成数据对比,我们还额外报告了 DF-OOD:它对 DF-AgenticRAG-10k 做了****完全相同的排除操作 ,确保比较口径一致。
与 HotpotQA 训练模型的对比
HotpotQA-10k 模型在训练 1~3 个 epoch 后,OOD 平均分分别是 33.7、35.1 和 36.4。
而 DF-AgenticRAG在相同训练轮数下,得分是 33.8、35.9 和 37.4 ——
每次都持平或更高,高出 +0.1 到 +1.0 分。
关键点:HotpotQA 是人工精心标注的真实问题,而 DF-AgenticRAG 的所有训练数据完全是大模型自动生成的 ,没有任何人工标注!
这说明:仅靠高质量的合成数据,就能达到甚至超越主流人工数据集的泛化能力 。
与 Musique 训练模型的对比
Musique-20k(人工标注的强 baseline)在“去掉 Musique 自身测试集”后的 OOD 平均分是 42.4。
DF-AgenticRAG 在等效训练量为 20k 、同样排除 Musique 测试集的情况下,得分为 43.6 ——高出 +1.2 分。
表明:我们的合成数据不仅不输人工数据,还能在同等规模下反超一个公认难度高、标注质量好的人工多跳数据集。
与 2Wiki 训练模型的对比
2Wiki-30k 的 OOD 平均分是 33.8。
DF-AgenticRAG 在3 个 epoch(等效规模 = 30k) 、且同样排除 2Wiki 测试集的前提下,得分达 36.4 ——
高出 +2.6 分,是所有对比中差距最大的一次。
这进一步验证了:DF-AgenticRAG 生成的问题具有极强的跨数据集迁移能力
总结
在所有训练轮数、所有排除策略下:
DF-AgenticRAG-10k 的 OOD 表现始终是最佳或并列最佳 ;
在 Musique 和 2Wiki 上,它显著优于对应的人工数据集 ;
所有结果共同说明:我们提出的 AgenticRAG 流程,能稳定产出高质量、强泛化的多跳推理训练数据 ;
更重要的是:优质合成数据 ≠ 妥协方案,而是可超越人工标注的新范式 。
表8 AgenticRAG 流程:合成数据集与现有手工构建数据集的性能对比。所有数值均为精确匹配率。
- “OOD-Avg”:计算平均分时,排除当前训练数据集所对应的测试集;
- “DF-OOD”:对 DF-AgenticRAG 应用完全相同的排除规则 ,保证对比公平。
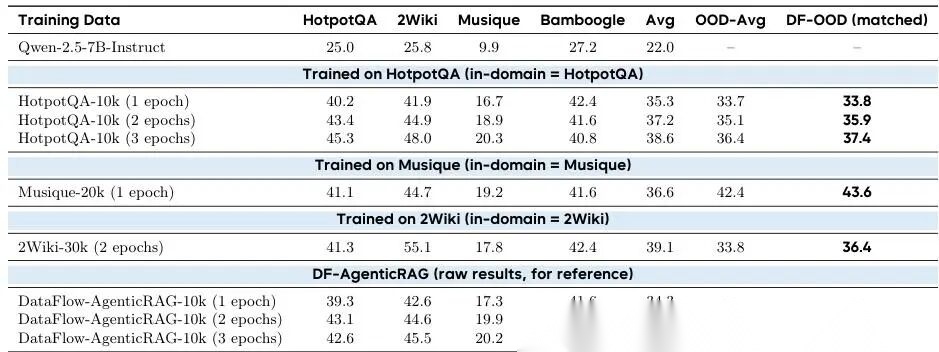
表9 知识抽取任务:在 PubMedQA、Covert 和 PubMed Health 数据集上,不同推理方式与训练设置下的准确率对比。

7.6 知识抽取
7.6.1 实验设置
为了突破人工标注数据量少的限制,并充分利用互联网上海量的原始文本(比如医学教材、临床指南、综述文章等),我们设计了一套叫「知识抽取」的流程。它是一个半自动化系统 ,专门用来清洗原始语料、并自动生成高质量的问答对(QA pairs),为后续大模型训练提供“教材”。
你可以把它想象成一个聪明的“医学资料整理员”:
- 它先用 MinerU 工具 [46] 对原始文本做标准化处理 ;
- 接着把超长文档按语义合理切分成段落或句子 ;
- 然后自动过滤掉低质量内容 ,比如语句不通顺、信息模糊、或者明显错误的句子;
- 再基于留下的可靠文本,生成带事实依据的问答对 ——不是随便编问题,而是确保每个问题都能在原文中找到明确答案,并且答案本身是医学上准确的;
- 最后还有一轮自动质检 ,比如检查问题是否清晰、答案是否完整、是否存在逻辑矛盾等。
整套流程跑完后,输出的就是一个结构清晰、质量高、适合监督微调用的合成数据集。
那么,这些“原材料”从哪来?实验中用了 1.4 亿 token 的原始医学文本 ,来自三大权威来源:
- MedQA 教材库 :共 18 本美国医师执照考试常用医学教材 [31];
- StatPearls 文章集 :来自美国国家生物技术信息中心的 9,330 篇公开医学综述文章;
- 临床指南文档集 :整合了来自 16 家专业机构发布的 45,679 份临床实践指南 。
这些原始材料输入到知识抽取流程后,最终被转化为一个结构化、高质量的问答数据集,我们把它命名为 DATAFLOW-KNOWLEDGE —— 这就是模型真正用来“学习医学知识”的训练数据。
接下来是模型训练部分:
- 我们选用开源大模型 Qwen2.5-7B-Instruct ,在 DATAFLOW-KNOWLEDGE 数据集上进行监督微调(;
- 微调共进行了 37,500 步,相当于把整个数据集完整过****5 轮;
为了验证效果,我们还设置了两个对比基线:
- 零样本思维链 :不给模型任何训练数据,只靠提示词让它一步步推理作答;
- 检索增强生成基线 :每次回答前,先从上述三大语料库中检索最相关的 10 个片段(top-k = 10) ,再让模型基于这些片段生成答案;其中,检索器用的是 medcpt-query-encoder,文档编码器用的是 medcpt-article-encoder。
注意:所有基线在测试时都使用完全相同的推理超参数 (如 temperature=0.3、max_new_tokens=512 等),确保比较公平。
最后,我们在三个权威医学问答评测集上评估模型表现:
- PubMedQA :聚焦生物医学科研类问题;
- Covert :考察临床决策和医学推理能力;
- PubMedHealth :专门检测模型识别公共卫生领域虚假信息的能力
这三个评测集覆盖了从基础科研、临床实践到公众科普的不同层次,能全面反映模型的医学知识掌握水平和实际应用潜力。
7.6.2 实验结果
表9展示了所有基准测试上的准确率结果。
我们先来理解三个对比方法:
- CoT 基线(思维链提示) :这是一种“零样本推理”方法,即不给模型任何训练数据,只靠提示词(prompt)引导它一步步思考并作答。结果发现,它在所有医学问答任务上表现都很差。换句话说:光靠让大模型“自己想”,是答不好专业医学问题的——就像让一个没学过解剖的学生,仅靠临时看几道例题就去考执业医师考试,难度太大。
- RAG 基线 :这种方法会先从外部知识库(比如PubMed论文库)中检索相关段落,再把检索到的内容和问题一起喂给模型作答。它在 PubMedQA 上有点提升,但在 Covert 和 PubMedHealth 上表现很不稳定,甚至明显更差。这说明:光靠“临时查资料”还不够——检索回来的内容可能不精准、不完整,或者模型不会有效利用这些片段,尤其面对需要结构化理解的问题(比如“某药是否适用于孕妇?”这类需判断条件与禁忌的题目)。
- SFT 模型 :这是用 DATAFLOW-KNOWLEDGE 流程生成的高质量合成问答对来训练的模型。这些问答对不是随便写的,而是经过知识抽取流水线清洗、结构化、人工校验后的结果。结果非常亮眼:它在全部三个基准上都取得最高准确率,大幅超越前两种方法:
- 在 PubMedQA 上比 CoT 高出 15–20 个百分点 ;
- 在 Covert 上同样高出 15–20 个百分点 ;
- 在 PubMedHealth 上高出 11 个百分点 。
这说明:干净、结构清晰、领域对齐的问答数据,哪怕来自合成,只要流程可靠,就能提供远超提示工程或检索的监督信号 。
一句话总结这个实验的核心结论:
在医学领域,与其依赖“现场发挥”(CoT)或“临时查书”(RAG),不如用 DATAFLOW 构建一条可靠的“知识炼金术”流水线——把原始文献自动提炼成高质量问答对,再用来训练模型。这样炼出来的模型,才是真正懂医学逻辑的助手。
7.7 DataFlow 实现的统一多领域数据准备
7.7.1 实验设置
数据构建
为了验证 DataFlow 在跨模态任务中统一进行数据准备的效率和效果,研究人员构建了一个融合三类任务的综合训练语料库——它把数学、编程和通用指令数据“打包”在一起,统称为 DATAFLOW-INSTRUCT-10K 。
这个语料库不是靠人工收集,而是全部由 DataFlow 框架自动生成或筛选出来的。我们来逐类看它是怎么做的:
- 数学类(Math) :
以公开的 MATH 数据集作为“种子”(就像种下一颗种子,让它长出更多内容),用 DataFlow 的「推理流水线(Reasoning Pipeline)」自动合成高质量数学题 + 逐步推理(Chain-of-Thought, CoT)解答。最终随机挑出 3000 个样本用于训练。
举个例子:输入一道代数题“解方程 ”,流水线不仅生成答案 ,还会输出类似“第一步:两边减5 → ;第二步:两边除2 → ”这样的可解释步骤。 - 代码类(Code) :
基于 2 万个 LingoCoder 的 SFT 示例,调用 DataFlow 的「CodeGenDataset_API 流水线」,批量生成 1000–10000 条高质量编程指令 。这些生成结果还跟 Code Alpaca 和 SC2-Exec-Filter 这两个主流代码数据集做了对比校验,确保质量可靠。最后取其中 2000 个样本用于训练。 - 文本/通用指令类 :
针对自然语言理解与对话任务,使用 DataFlow 的「Condor Generator + Refiner 流水线」,专门生成高一致性、高相关性的「指令-回答」和「对话轮次」对。之后再通过一个「SFT 质量过滤器」筛掉低质量样本,最终随机保留 5000 个样本 。
所有模型都在这个融合语料 DATAFLOW-INSTRUCT-10K 上做全参数监督微调。评估时覆盖三大方向:
- 7 个数学评测集 ;
- 4 个代码评测集 ;
- 通用知识与推理能力 :用 MMLU 和 C-Eval 测模型“常识+学科知识”水平。
基线模型
为了说明 DataFlow 生成的数据到底好不好,研究者还拉了两个“对照组”来比一比:它们都来自一个叫 Infinity-Instruct(Inf) 的大型通用指令数据集(类似“万能菜谱”,什么任务都有一点,但不专精):
- Inf-10K :从 Infinity-Instruct 中随机抽 1 万个样本,做同样的 SFT 微调;
- Inf-1M :随机抽 100 万个样本,做同样微调。
这样对比的目的很明确:是“少而精”的 DataFlow 合成数据更有效,还是“多而泛”的通用指令数据更管用? 结果见下面两张表。
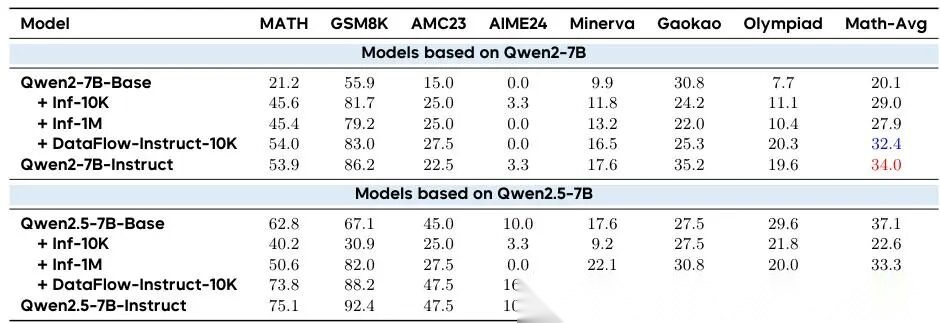
:在数学评测上的表现(精确匹配率)
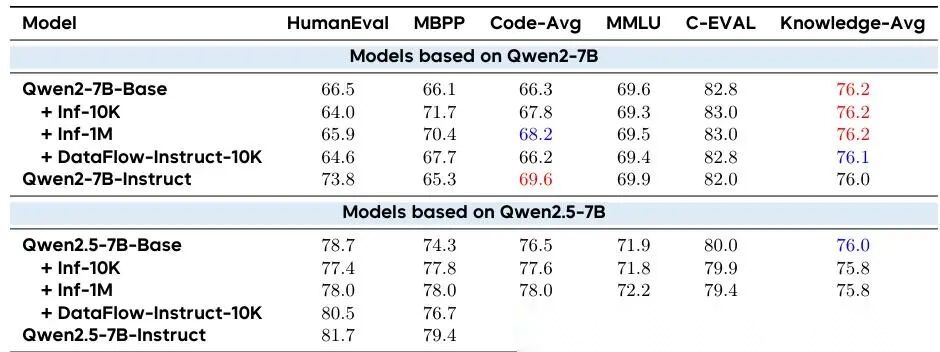
:在代码与知识评测上的表现
7.7.2 实验结果
在数学、代码和知识三大评测套件上,DataFlow 提出的统一多领域数据准备策略 ,对 Qwen2.5-7B 和 Qwen2-7B 这两类基础大语言模型都带来了稳定且显著的性能提升 。一个非常关键的观察是:DATAFLOW-INSTRUCT-10K (即用 DataFlow 流程生成的 10K 条高质量指令微调数据)在所有非人工指令微调模型中几乎总是表现最好 ;在很多任务上,它和真正使用人工撰写指令微调的模型之间的差距,仅缩小到 2–4 分以内 ——而它所用的数据量,比 Instruct 模型小了几个数量级。
换句话说:不是数据越多越好,而是数据越“准”、越“专”、越“好”,效果越接近人工精标数据。
数学推理
如 表 10所示,经过 DataFlow 处理的数学数据,带来的提升****幅度最大、也最稳定 。
以 Qwen2.5-7B-Base 模型为例:
- 原始 Base 模型在数学评测上的总分是 37.1 ;
- 仅用 DataFlow 合成的数学子集进行训练后,总分提升到 46.7 。这个成绩意味着:
- 它是所有非 Instruct 模型里最高的 ,大幅超过 Inf-10K(22.6)和 Inf-1M(33.3);
- 它只比真正的 Instruct 模型(49.8)低 3.1 分 ——相当于用“机器自产”的高质量数据,达到了接近“人类老师手写教案”调教出来的效果。
再看 Qwen2-7B-Base:
- DATAFLOW-INSTRUCT-10K 达到 32.4 分,同样超过 Inf-10K 和 Inf-1M,并逼近 Instruct 模型的 34.04 分。
这说明:DataFlow 的数学合成不是“瞎造题”,而是有逻辑、有结构、有教学意图的高质量生成。
代码生成
如 表 11 所示,DATAFLOW-INSTRUCT-10K 在代码能力上也持续领先所有非 Instruct 基线。
对 Qwen2.5-7B-Base:
- 原始 Code-Overall 得分是 76.5 ;
- 加入 DATAFLOW-INSTRUCT-10K 数据后升至 78.6 ;
- 不仅超过 Inf-10K(77.6)和 Inf-1M(78.0),而且离 Instruct 模型(80.6)只差 2.0 分 。
对 Qwen2-7B-Base:结果类似——DATAFLOW-INSTRUCT-10K 总是等于或优于 Inf 系列基线。
特别值得注意:很多多领域混合微调方法会带来“负迁移”——比如加了数学数据后,代码能力反而下降。但 DataFlow 完全没有这个问题 ,甚至还能小幅提升代码能力。
这说明:DataFlow 构建的合成语料不是“乱炖一锅”,而是按领域平衡配比、保持各能力互不干扰,还能协同增强 ——就像给模型同时配备三位专业教练(数学教练、编程教练、通识教练),每人只教自己最擅长的部分,且彼此教案风格统一、难度适配。
通用知识与自然语言处理
同样在 表 11 中汇总了 MMLU和 C-Eval的结果。我们把 DataFlow 生成的通用文本数据记为 DF-Gen-10K 。
它的表现是:
- 与原始 Base 模型持平,甚至略有提升;
- 完全避免了 Inf-10K / Inf-1M 常见的“知识退化”现象;
- 在多数子项中,得分稳居第二,仅次于 Instruct 模型 。
这说明:即使没有人类写的“请解释牛顿定律”“请对比两种排序算法”这类明确指令,DataFlow 生成的通用文本(如百科段落、问答对、推理对话)本身已具备强监督信号 ——它天然包含隐含的任务结构、逻辑链条和事实准确性约束。
类比一下:
- Inf-10K 像是让模型读 1 万篇随机网页快照;
- DF-Gen-10K 则像提供 1 万条维基百科优质条目 + 对应编辑讨论页——信息密度高、可信度强、结构清晰。
综合来看,这些实验一致表明:
- DataFlow 生成的高质量、领域定制化合成数据 ,是目前所有非人工指令微调方法中效果最强的 ;
- DATAFLOW-INSTRUCT-10K 在数学、代码、通用知识三大方向上,持续超越通用推理生成数据 ,并频繁逼近甚至局部反超 Instruct 模型 ;
- 这验证了 DataFlow 的核心思想:与其依赖海量、嘈杂、难控的人工指令数据,不如构建一个端到端可复现、可调试、可扩展的数据流水线(pipeline) ,让 LLM 自己成为“数据工程师 + 教研组长 + 出题人”的结合体。
一句话总结:
DataFlow 不是在“喂数据”,而是在“建课堂”。
7.8 智能体协同编排
7.8.1 实验设置
我们在这个部分测试了提出的“智能体协同编排”框架,看它能不能在真实的数据处理和流水线构建任务中自动完成工作。
举个例子:就像你让一个助理帮你做一顿饭,你只说“我要吃番茄炒蛋”,他得自己想清楚——要买番茄和鸡蛋、洗菜、打蛋、热锅、放油、先炒蛋再炒番茄……最后端上桌。这个“想清楚每一步该做什么、用什么工具、按什么顺序做”的能力,就是我们这里要测试的“协同编排”能力。
为了系统性地测试,我们选了 6 条典型的数据处理流水线 (比如:清洗电商订单数据 → 提取用户地域 → 统计各城市销量 → 生成可视化图表),作为基准任务。
对每条流水线,我们人工编写了 3 种不同难度的自然语言描述 ,总共得到 18 个测试问题 。这就像考一个学生,既出填空题、简答题,也出开放设计题(困难),来全面考察它的理解与规划能力:
- 简单级 :描述非常明确,直接告诉你“要用哪个算子”“做哪几步”。
例如:“请先用Filter算子去掉订单金额为 0 的记录,再用GroupBy按城市分组,最后用Sum计算每个城市的总销售额。” - 中等级:描述比较粗略,只说“我想干什么”和“有哪些限制”,但不告诉你具体用哪些算子、顺序如何。
例如:“我要统计每个城市的订单总金额,但只保留近 30 天的有效订单,且排除退款订单。” - 困难级 :只给一个高层目标,几乎不提示中间步骤。系统必须自己推理出整个流程和所需算子组合。
例如:“帮我发现最近销售异常下滑的城市,并给出可能原因。”
每次实验中,用户只输入一段自然语言描述,系统就要自动组装出一条由多个算子组成的完整数据流水线 ,并确保它能正确实现用户意图。
评估指标
我们不用人工一条条检查结果,而是请了一个“AI 裁判”——即一个外部大语言模型(LLM),让它来自动打分。
这个裁判从两个角度判断生成的流水线好不好:
文本规范一致性 :
把生成的流水线结构和用户写的那句自然语言描述对比,看它是否真的满足所有文字要求。
- 代码实现一致性 :
把生成的流水线,和我们事先写好的标准 Python 实现做逻辑比对,看它们在“用了哪些算子”“执行顺序是否等价”上是否一致。
最终,我们报告一个 LLM-裁判得分(LLM-Judge Score) ,记作 ,取值范围是 :
- 表示生成流水线在算子选择、数量、执行顺序等方面,和参考答案完全一致;
- 表示完全不匹配;
- 中间值表示部分匹配程度。
这个分数不是靠硬规则计算的,而是由 LLM 综合阅读用户描述、生成图、参考代码后,给出的语义级合理性判断——更贴近真实场景中“人怎么看对不对”。
7.8.2 实验结果
表 12:按评估模式与描述难度划分的智能体编排(Agent orchestration)性能

表 12 展示了在两种不同评估方式下,DataFlow 框架生成的数据处理流程(即智能体编排结果)所获得的 LLM-Judge 评分,横轴为任务描述的难度,纵轴为两种评估标准:
- 文本规范评估(text-spec) :由另一个大语言模型(LLM-Judge)阅读原始自然语言需求(例如“请先过滤掉销售额低于1000的订单,再按地区分组求总销售额”),然后判断 DataFlow 生成的流程描述(如“Filter → GroupBy → Sum”)是否准确满足该文字要求。
- 代码级真值评估(code-GT,也称 code 模式) :将 DataFlow 生成的流程,实际转换成可运行的 Python 代码 ,再与人工编写的参考实现做逐行或语义等价比对,要求功能完全一致。
整体来看:
- 在文本规范评估下,框架平均得分为 0.80 (满分 1.0),说明它能较好地理解用户用中文/英文写的“要做什么”,并用合理的算子序列(如 Filter、Join、Aggregate)表达出来;
- 但在代码级真值评估下,平均分骤降至 0.49 ,说明即使流程逻辑“听起来合理”,一旦落实到具体代码实现,往往和人工写的参考程序不一致——比如用了
groupby().sum()而不是groupby().agg({'sales': 'sum'}),或过滤条件写成df['sales'] > 1000vsdf.query('sales > 1000'),虽功能等价但结构不同,就被判为不匹配。
更关键的是:当用户描述越模糊、越不明确时,性能下降越明显 。
举个例子:
- Easy 级描述可能是:“从 sales.csv 中选出所有北京地区的订单,并计算总金额。”——非常清晰,pipeline 模式得分 0.92,code 模式也有 0.65;
- Medium 级可能说:“分析销售数据,重点关注高价值区域。”——需要推理“高价值”指什么,pipeline 得分降到 0.86,code 得分只剩 0.38;
- Hard 级可能只写:“让数据说话。”——完全无具体操作指示,此时 pipeline 模式还能靠常识猜个流程(得 0.60),但 code 模式几乎无法收敛到唯一正确实现,得分仅 0.23 。
换句话说:DataFlow 善于“听懂人话并给出合理方案”,但尚难做到“写出和专家一模一样的代码”。这是因为模糊描述常对应多个语义等价但实现不同的数据处理路径(例如先 Join 再 Filter,或先 Filter 再 Join,在结果相同时都合法),而 code-GT 评估只认那一个预设的参考实现,因此拉低了分数。
8 结论
总的来说,DataFlow 解决了“以数据为中心的大型语言模型(Data-Centric LLM)”生态中一个关键空白:它是首个统一的、由大语言模型驱动的数据准备框架 。
我们来打个比方:过去做数据清洗、标注、增强等工作,就像用一堆不同品牌的螺丝刀、扳手、钳子各自拧不同的螺丝——工具五花八门、接口不统一、别人很难照着你的方法重做一遍,也很难公平地比较谁的方法更好。
而 DataFlow 就像一套标准化的智能工具箱:所有工具都按同一套规则设计,能插拔、可复用、有说明书(即用户友好的编程接口),让数据准备工作变得像搭乐高一样清晰、可分享、可复现。
具体来说,这个框架包含三大核心“装备”:
- 近 200 个数据操作算子 :比如去重、采样、格式转换、敏感信息脱敏、指令模板注入等,覆盖数据处理全链条;
- 80 多个提示词模板 :针对不同任务预置好高质量 prompt,开箱即用;
- 统一的存储与服务抽象层 :不管数据存在本地文件、数据库还是云对象存储,也不管是实时调用还是批量运行,DataFlow 都用同一套方式读、写、调度——你不用反复写对接代码。
这三类组件组合起来,构建出 6 条高质量、开箱可用的数据流水线(pipelines) ,分别对应当前主流的大语言模型数据场景,例如:
- 指令微调数据构造
- 合成数据生成
- 长上下文数据预处理
- 多轮对话数据整理
- 代码数据清洗
- 推理链数据增强
大量实验表明,这些流水线不仅效果稳定,而且在多个公开基准上达到了当前最佳水平 。这说明 DataFlow 成功地在两个看似矛盾的目标之间取得了平衡:
一方面支持领域定制化 (比如科研人员可以为数学推理任务专门设计 prompt + 算子组合);
另一方面保障系统级标准化 。
在此基础上,DataFlow 还提供了两个强力扩展工具:
- DataFlow-CLI :一个命令行工具,让你用几条简单命令就能:
- 快速生成新 prompt 模板(比如
dataflow prompt generate --task="rewrite-as-QA"); - 批量运行整条流水线(比如
dataflow run pipeline:code-clean --input ./raw.py --output ./cleaned/); - 查看、调试、导出任意步骤的中间结果。
- DataFlow-Agent :一个基于 LLM 的智能代理,你可以用自然语言直接指挥它构建工作流
CLI 和 Agent 协同工作,显著降低了扩展门槛:研究人员可以快速验证新想法,工程师可以无缝接入生产系统,社区成员也能轻松贡献新算子或模板——最终共同打造一个可持续演进、跨团队互通的数据准备生态系统 。
展望未来,DataFlow 生态将持续向多维度扩展:
- 按数据模态拓展 :推出
DataFlow-Table(面向结构化表格数据)DataFlow-Graph(面向知识图谱、社交网络等图数据)DataFlow-Multimodal(支持图文、音视频等多模态数据联合处理)
- 按应用领域深化 :开发面向特定场景的定制版本,例如:
DataFlow-AI4S(面向科学智能,AI for Science),强化对公式、实验日志、蛋白质序列等科学数据的支持;DataFlow-INDUSTRY(面向工业界大规模生产环境),重点提升高并发调度、审计追踪、权限管控与企业级部署能力。
这些演进方向,将使 DataFlow 不仅是一个工具框架,更成为支撑未来 LLM 数据工作的基础底座 和通用协议 ——就像 TCP/IP 之于互联网,POSIX 之于操作系统,它为学术研究、工程落地和社区共建提供一致的语言与可靠的基础设施。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献92条内容
已为社区贡献92条内容

所有评论(0)