16款开源Embedding模型大比拼(非常详细),RAG最佳实践从入门到精通,收藏这一篇就够了!
大多数嵌入模型基准测试仅衡量语义相似度,而我们测试的是事实准确性。我们在 49 万条亚马逊商品评论上,对参数量从 2300 万到 80 亿的 16 款开源模型进行了测评。评分依据是模型能否通过精确 ASIN 匹配检索到正确的商品评论,而非仅返回主题相似的文档。
开源嵌入模型基准测试概览
我们基于 100 条人工筛选的查询,评估了模型的检索准确率与速度,涵盖面向速度优化的轻量模型,以及为最大化语义理解设计的大规模大语言模型嵌入。
准确率:Top-K 检索性能
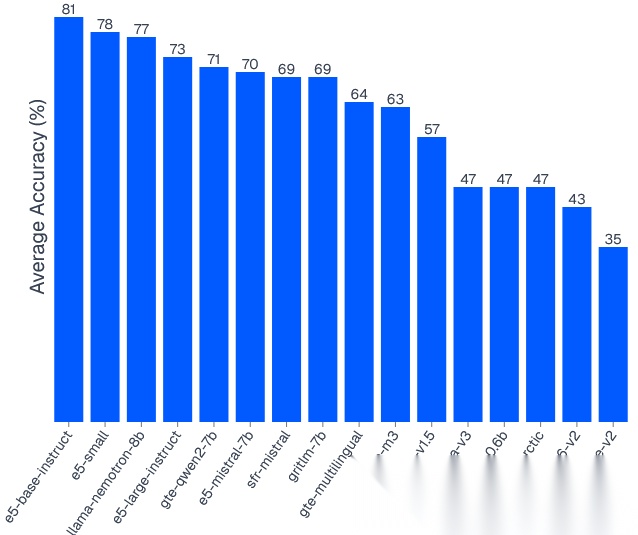
模型及平均准确率(%):
e5-base-instruct:81
e5-small:78
llama-nemotron-8b:77
e5-large-instruct:73
gte-qwen2-7b:71
e5-mistral-7b:70
sfr-mistral:69
gritlm-7b:69
gte-multilingual:64
bge-m3:63
nomic-embed-v1.5:57
jina-v3:47
qwen3-0.6b:47
snowflake-arctic:47
all-MiniLM-L6-v2:43
mpnet-base-v2:35
什么是 Top-K 准确率?
Top-K 准确率衡量正确文档出现在前 K 个检索结果中的概率:
-
Top-1
:正确答案排在第一位(精度最高)
-
Top-3
:正确答案出现在前 3 位结果中
-
Top-5
:正确答案出现在前 5 位结果中(RAG 最常用,通常使用 3–5 个上下文文档)
-
Average
:Top-1、Top-3、Top-5 准确率的平均值
准确率越高,模型越能稳定找到正确的商品评论。
准确率结果核心结论
-
Top-5 满分模型
:3 款 e5 系列模型(e5-small、e5-base-instruct、e5-large-instruct)实现100% Top-5 准确率,允许 5 次检索时从未遗漏正确答案。
-
Top-1 最佳模型
:llama-embed-nemotron-8b 以62% Top-1 准确率登顶,远超参数量仅为其 1/70 的模型。
-
大模型 Top-5 表现不佳
:尽管参数量 70–80 亿、向量维度 4096,超大模型(e5-mistral-7b、gte-qwen2-7b、sfr-mistral、gritlm-7b、llama-embed-nemotron-8b)Top-5 准确率仅 82–90%;而1.18 亿参数的 e5-small 达到 100%,全面超越。
-
效率悖论
:e5-small 推理速度比 llama-embed-nemotron-8b 快14 倍(16ms vs 195ms),且 Top-5 准确率更高(100% vs 88%)。
-
最佳大模型
:gritlm-7b 在 7B + 模型中 Top-5 准确率最高(90%),但存在排序异常:Top-1 准确率仅 38%,为同级最低,说明模型能找到正确文档,但难以将其排至首位。
-
56% 集群
:5 款模型(jina-v3、qwen3-0.6b、snowflake-arctic、all-MiniLM-L6-v2 等)Top-5 准确率停滞在 56%,与头部模型差距明显。
-
参数量≠准确率
:最小模型 e5-small(1.18 亿参数)在商品搜索 Top-5 检索中,超越了参数量为其 70 倍的模型。
-
经典模型过时
:HuggingFace 下载量超 2 亿的 all-MiniLM-L6-v2,Top-5 准确率仅 56%、Top-1 仅 28%,2019 年架构已无法匹敌现代检索优化模型。
延迟(Latency)
模型及延迟(毫秒 ms):e5-small:16all-MiniLM-L6-v2:22mpnet-base-v2:25e5-base-instruct:28bge-m3:37nomic-embed-v1.5:38gte-multilingual:39e5-large-instruct:40snowflake-arctic:41jina-v3:64qwen3-0.6b:110gte-qwen2-7b:187llama-nemotron-8b:195gritlm-7b:209e5-mistral-7b:220sfr-mistral:221
什么是延迟?
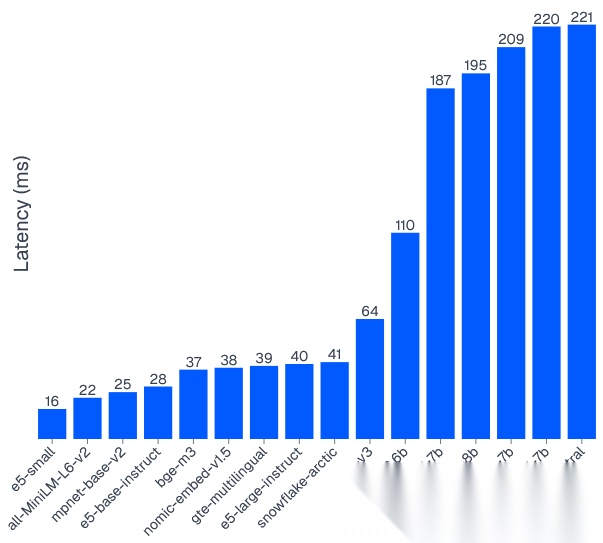
-
延迟(ms)
:仅指生成嵌入(文本转向量)的时间,越低越好。本测试不含向量检索时间。该指标反映模型在生产环境中为用户提供服务的速度。
性能结果核心结论
-
速度冠军
:e5-small 嵌入延迟仅16ms,为测试最快,比大模型集群(187–221ms)快14 倍。
-
延迟壁垒
:所有 7B + 参数模型延迟均在 187–221ms,比 1B 以下模型慢约 10 倍,无 GPU 加速时不适合实时面向用户搜索。
-
14 倍性能差
:llama-embed-nemotron-8b 处理 1 条查询的时间,e5-small 可处理 14 条,且 Top-5 准确率高 12%。
-
30ms 以内集群
:5 款模型(e5-small、all-MiniLM-L6-v2、mpnet-base-v2、e5-base-instruct、bge-m3)延迟低于 30ms,适合实时应用。
-
生产最佳平衡点
:e5-small 与 e5-base-instruct 兼具超高准确率(100% Top-5)与低延迟(30ms 内),是生产级 RAG 系统理想选择。
-
大模型取舍
:若需最高 Top-1 精度且可接受约 200ms 延迟,llama-embed-nemotron-8b 为最优(62% Top-1)。
注:以上为纯模型推理时间,不含向量库操作。所有模型均在 NVIDIA H100 GPU、BF16 精度下测试。
开源嵌入模型技术参数
表格
| 排名 | 模型 | 参数 | 维度 | 最大长度 |
|---|---|---|---|---|
| 🥇 | e5-base-instruct | 2.79 亿 | 768 | 512 |
| 🥈 | e5-small | 1.18 亿 | 384 | 512 |
| 🥉 | e5-large-instruct | 5.6 亿 | 1024 | 512 |
| 4 | llama-embed-nemotron-8b | 80 亿 | 4096 | 32768 |
| 5 | gte-qwen2-7b | 70 亿 | 3584 | 32768 |
| 6 | gritlm-7b | 70 亿 | 4096 | 8192 |
| 7 | e5-mistral-7b | 70 亿 | 4096 | 4096 |
| 8 | sfr-mistral | 70 亿 | 4096 | 4096 |
| 9 | gte-multilingual | 3.05 亿 | 768 | 8192 |
| 10 | bge-m3 | 5.68 亿 | 1024 | 8192 |
技术规格说明
-
参数
:模型可训练权重规模,更大模型(5 亿 +)学习能力更强,但内存与算力需求更高。
-
维度
:文本转换后的向量长度(如 384 即文档转为 384 维向量),更高维度(1024)语义表达更细,但存储与相似度计算更慢。
-
最大长度
:单次输入可处理的最大 token 数(近似单词数),8192 可直接处理超长文档无需分块,512 则需拆分。
核心结论:规格更大不代表性能更好。e5-small(1.18 亿参数、384 维、512token)虽参数最小,却取得顶级效果。
基准测试方法
语料库与查询
-
数据集
:49 万条亚马逊客户评论(健康与个护品类)
- 每条评论 = 单个文档向量
- 基于 Qdrant 构建索引,使用余弦相似度
-
测试集
:100 条人工筛选查询
- 真实用户问题(如 “这款益生菌对消化好吗?”)
- 每条通过 ASIN 匹配唯一正确商品
标准答案匹配
评估采用商品ASIN(亚马逊标准识别码)精确匹配:
- 查询指定目标商品 ASIN
- 模型返回 Top-5 文档(按余弦相似度排序)
- 系统检查返回文档是否匹配标准答案 ASIN
- 二元结果:匹配 = 命中,不匹配 = 未命中
示例:查询:“Aloha Hawaii 夏威夷坚果油值得买吗?”正确 ASIN:B00ABC123返回 Top-5 中第 3 位为该 ASIN,即 Top-3 命中、Top-5 命中。
该方式保证商品级事实准确性,而非仅语义相似。
余弦相似度的作用
-
使用场景
:Qdrant 内部对 49 万文档按查询相似度排序,返回前 5。
-
不使用场景
:标准答案验证为ASIN 精确字符串匹配,相似度高≠答案正确。
关键意义:模型可能返回语义相似但事实错误的文档,因此事实准确性比语义相关对 RAG 更重要。
评估环境
- 硬件:NVIDIA H100 80GB GPU(RunPod),BF16 精度
- 向量库:Qdrant(本地实例)
- 模式:零样本(无微调)
- 公平性保证:所有模型使用相同语料、查询、硬件、预处理、独立集合、原生维度与 BF16 精度。
评估指标
-
Top-K 准确率
:Top-K 中包含正确 ASIN 的查询数 / 100,测试 K=1、3、5。
-
性能
:平均延迟(仅嵌入生成时间)。
局限性
-
领域特定
:结果基于健康个护商品检索,法律、金融、代码搜索可能不同。
-
硬件依赖
:H100 测试,消费级 GPU 慢 2–3 倍,CPU 慢 10–50 倍。
-
显存需求
:7B + 模型 BF16 下需 16–20GB 显存,小显存显卡需 INT8 量化,准确率可能降 5–10%。
-
ASIN 匹配
:仅适用于带唯一标识的数据集,无标识数据集需其他验证方式。
-
仅零样本
:未做领域微调,微调后排名可能变化。
开源嵌入模型介绍
llama-embed-nemotron-8b
NVIDIA 旗舰嵌入模型,基于 Llama-3.1-8B 与双向注意力,面向企业级 RAG。
- 所有模型中Top-1 准确率最高(62%)
- Top-5 准确率 88%,低于 e5 系列满分
- 适合:重视首条精度且有 GPU 基础设施的企业部署。
e5-small
轻量多语言检索编码器,优化高吞吐语义搜索,常用于实时 RAG、推荐、商品检索。
- 100% Top-5 准确率
- 延迟最低
- 综合平衡最佳。
e5-base-instruct
指令微调,对齐查询–文档,适合任务感知搜索、AI 助手、引导检索流程。
e5-large-instruct
高容量版本,面向企业知识搜索、法务检索、复杂查询,准确率优先,但推理成本更高。
gte-multilingual
支持 70 + 语言,用于跨语言搜索、全球内容检索,准确率可靠但延迟更高。
bge-m3
多表示编码器,支持稠密 / 稀疏 / 混合向量检索,适配长文档,但准确率与延迟弱于小型优化模型。
nomic-embed-v1.5
混合专家模型 + 嵌套降维,面向成本敏感向量搜索,速度与准确率未超越小型稠密模型。
jina-v3
多语言检索模型,面向跨域文档搜索与企业知识检索,实体级精确匹配未达顶级。
qwen3-0.6b
多语言检索模型,优化指令驱动搜索,准确率尚可但延迟偏高。
snowflake-arctic
面向企业级语义搜索,稳定性好,但准确率与延迟弱于小型检索优化模型。
all-MiniLM-L6-v2
轻量 CPU 友好编码器,广泛用于本地搜索、原型、边缘部署,但实体精确匹配准确率低。
mpnet-base-v2
面向语义相似度与聚类,精确商品检索弱于检索专用紧凑型模型。
部署嵌入模型关键考量
- 性能与准确率选择匹配领域检索需求的模型,参考权威基准测试;大模型语义理解更强,但需权衡部署限制。
- 延迟与扩容实时应用需低延迟,优先小型高效模型;RAG 检索延迟直接影响用户体验。
- 与复杂 AI 系统集成选择支持多模型部署、分布式编排、可观测性的平台。
- 许可与商用16 款模型均公开权重,其中 3 款限制商用:
- MIT/Apache 2.0:可自由商用
- CC-BY-NC-4.0:禁止商用
- NVIDIA Nemotron:仅限非商用 / 研究
- Jina V3:商用需咨询
大模型 Top-5 表现不佳原因(推测)
-
中心性效应
:高维向量空间易出现中心向量,导致大模型高维向量 Top-5 召回率低。
-
训练目标不同
:小模型更优化召回,大模型更侧重精度,排序校准存在差异。
-
领域适配
:部分模型训练数据更适合商品搜索场景。
什么是开源嵌入模型?
公开可用的 AI 模型,将文本转为数值向量,支持语义比较、聚类、搜索。与闭源 API 相比优势:
- 数据完全自有,不泄露查询
- 规模化成本更低
- 可领域微调
- 支持离线 / 私有化部署
- 可自由平衡延迟、体积、准确率
嵌入模型应用场景
-
语义搜索
:基于概念而非关键词,提升搜索准确率。
-
信息检索(IR)
:RAG 核心组件,提升大模型内容准确性与时效性。
-
聚类与分类
:按语义分组文本,如客服工单分类。
-
推荐系统
:理解用户偏好,提供个性化推荐。
结论
本次测试揭示:商品检索中,模型越大未必越好。
- 最高 Top-5 召回:e5-small /e5-base-instruct /e5-large-instruct(100%)
- 最高 Top-1 精度:llama-embed-nemotron-8b(62%)
- 最佳大模型:gritlm-7b(90% Top-5)
- 多语言:gte-multilingual-base /gte-qwen2-7b
- 实时应用:e5-small(16ms + 100% Top-5)
- 不推荐:all-MiniLM-L6-v2、qwen3-0.6b
生产建议:多数 RAG 应用检索 3–5 个文档时,e5-small 或 e5-base-instruct 性价比最高,16–28ms 延迟即可实现满分召回。仅当 Top-1 精度至关重要时,大模型才具备优势,但其速度仍比轻量模型慢 12 倍以上。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献146条内容
已为社区贡献146条内容

所有评论(0)