2026年9大热门大模型深度解析:从GPT-5.4到DeepSeek,小白必看
本文深度盘点截至2026年初的9大热门大模型,涵盖OpenAI GPT-5.4、DeepSeek、Qwen、Claude等。文章详细解析了各模型在长上下文、开源生态及企业级应用上的独特优势,助你快速把握大模型行业前沿动态。
大模型的技术迭代一天一个样,在本文我们重点介绍了我们截止2026年初,目前在行业内引起关注的 9 个 LLM,每个模型都具有独特的功能和专业优势,在自然语言处理、代码合成、少样本学习或可扩展性等领域表现出色。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
- OpenAI
=========
 Community - OpenAI Developer Community](https://mmbiz.qpic.cn/mmbiz_jpg/Wz32s0BYYH4icib5HX7k7tQ4V0CFTK7kyheMEHsuZYsjmGcgN4Dic8omibNVnv1pfrGwDia2mesUvDpoDiaFe0zDKicNQ/640?wx_fmt=jpeg&from=appmsg)
Community - OpenAI Developer Community](https://mmbiz.qpic.cn/mmbiz_jpg/Wz32s0BYYH4icib5HX7k7tQ4V0CFTK7kyheMEHsuZYsjmGcgN4Dic8omibNVnv1pfrGwDia2mesUvDpoDiaFe0zDKicNQ/640?wx_fmt=jpeg&from=appmsg)
我们的列表以 OpenAI 的生成式预训练转换器(GPT)模型开篇,这些模型在每次新发布中都持续超越其先前能力。
最新型号:GPT-5.4(旗舰模型)、GPT-4o(商用主力模型)、GPT-oss-120b/20b(开源系列)
介绍信息:GPT-5.4于2026年3月5日正式发布,推出标准版、Thinking(推理版)、Pro(高性能版)三个版本,核心升级为上下文窗口提升至100万token,是首个具备原生计算机使用能力的通用模型,可通过截图识别和键盘鼠标指令完成跨应用复杂工作流程处理。GPT-oss-120b/20b采用Apache 2.0许可,适配消费级硬件且支持代理工作流;GPT-4o仍作为商用主力模型稳定服务。
优点:长上下文处理能力突出,100万token窗口可高效完成长周期任务;事实性准确率高,单个陈述错误率较前代降低33%;专业任务表现接近人类专家,44个职业领域GDPval基准测试中83.0%的项目达到行业专业水平;编码能力优异,延迟低且适配各类工具,网络搜索能力较前代提升17个百分点;开源系列降低使用门槛,商用模型覆盖不同需求场景。尽管其具有先进的对话和推理能力,GPT 仍然是一个专有模型。OpenAI 对训练数据和参数保密,完全访问通常需要商业许可证或订阅。我们建议此模型给寻求在多步推理、对话式对话和实时交互方面表现出色的企业,特别是预算灵活的企业。
- DeepSeek
===========
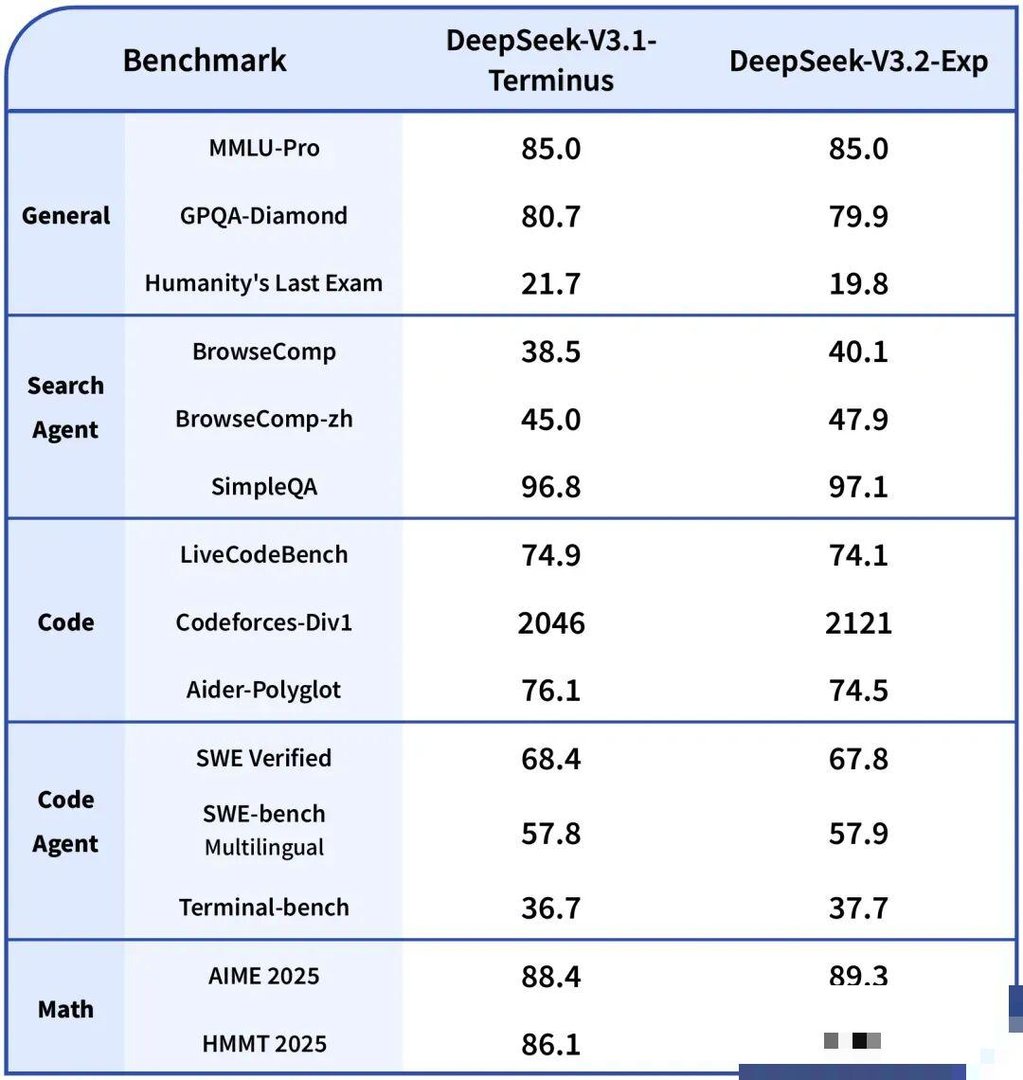
DeepSeek 积极发布和更新其模型,包括深 Seek-V3.2-Exp 和深 Seek-R1 系列。有传闻说近期会发布最新模型,但一直没有等到。。
该模型引入了“细粒度稀疏注意力”架构,这是一种前所未有的架构,通过提高计算效率 50%来提升性能。对于关注投资回报率的企业,DeepSeek 提供极具竞争力的定价结构,输入成本低至每百万个 token 0.07 美元(缓存命中时)。它也是第一个将“思考”直接集成到工具使用能力中的模型,弥合了推理与行动之间的差距。
对于高级推理,推出了 DeepSeek-R1 系列,其中包括 R1-Zero 和 R1 等模型。R1 系列专门设计用于解决金融分析、复杂数学和自动定理证明等领域的高级问题。据说春节前后这段时间会发布新模型!
DeepSeek 还发布了 DeepSeek-Prover-V2,这是一个为 Lean 4 中的形式化定理证明量身定制的开源模型。为了使这些强大的功能更加易于使用,DeepSeek 还开发了 DeepSeek-R1-Distill 系列,这些是更小、更高效的模型,它们是从更大的 R1 模型中“蒸馏”出来的。这些蒸馏模型基于 Qwen 和 Llama 等架构,非常适合计算效率优先的生产环境。
- Qwen
=======
 r/LocalLLaMA](https://mmbiz.qpic.cn/mmbiz_jpg/Wz32s0BYYH4icib5HX7k7tQ4V0CFTK7kyhOUzRgN93LVjML3QSP6ta56ZsLica9yaFGdNibUA9ArMR9laibRXuQiamJQ/640?wx_fmt=jpeg&from=appmsg)
r/LocalLLaMA](https://mmbiz.qpic.cn/mmbiz_jpg/Wz32s0BYYH4icib5HX7k7tQ4V0CFTK7kyhOUzRgN93LVjML3QSP6ta56ZsLica9yaFGdNibUA9ArMR9laibRXuQiamJQ/640?wx_fmt=jpeg&from=appmsg)
阿里巴巴一直在积极推进其语言模型系列,最新的主要发布以 Qwen3.5 系列为中心。这些混合专家混合(MoE)模型据报道在大多数公共基准上达到或超过 GPT-4o 和 DeepSeek-V3,同时使用的计算量要少得多。
Qwen3.5-Plus(核心型号)于2026年2月正式发布,总参数达3970亿,仅激活170亿参数,实现从纯文本模型到原生多模态模型的代际跃迁,基于视觉和文本混合token预训练,原生支持262144 token上下文,全系采用Apache 2.0开源许可,支持201种语言,API价格极具优势。性能强悍,MMLU-Pro基准测试得分87.8分超越GPT-5.2,GPQA博士级难题测评得分88.4分高于Claude 4.5;推理效率极高,吞吐量最大提升至19倍,显存占用降低60%;多模态能力突出,视觉理解、视频分析、视觉编程表现优异;开源生态完善,全球下载量领先,开发者友好,部署成本低。
对于企业和开发者而言,Qwen 系列获得了显著的关注,已有超过 90,000 家企业采用,涵盖消费电子、游戏和其他领域。
- Grok
=======
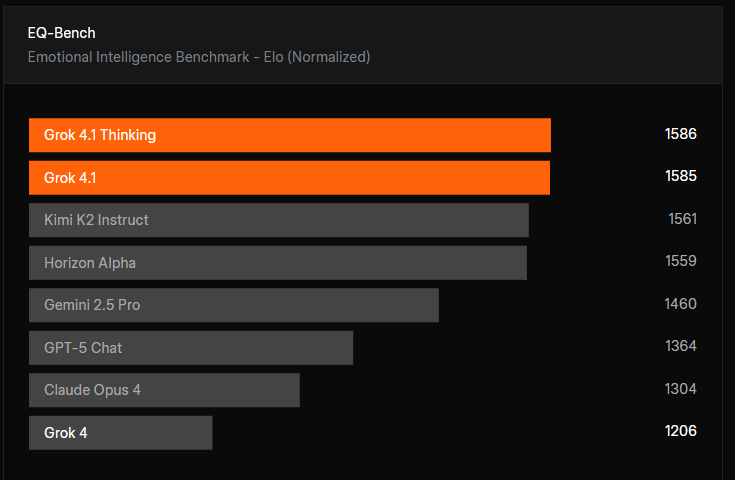
Grok 是 xAI 开发的生成式 AI 聊天机器人,与社交媒体平台 X 整合,提供实时信息以及机智的对话体验。Grok 系列模型被设计为分层的阵容,每个模型都针对不同的用途进行了优化。
最新型号为 Grok 4.2(2026 年 2 月发布),EQ-Bench3 得分 1586,新增全模态及多智能体协作功能。目前,它在 LMArena Elo 排名和 EQ-Bench 上位列第一(1483 Elo)。对于商业用途来说,最值得注意的是,幻觉率从 Grok 4 的约 12%下降到 Grok 4.2的超过 4%——降低了 65%。在盲法 A/B 测试中,用户在近 65%的时间内更倾向于选择 4.1 模型,而不是之前的生成模型。
对于开发者来说,Grok Code Fast 1 是一个专门设计、高性价比的模型,用于“代理式编码”,在自动化软件开发流程、调试和代码生成方面表现出色。
这些近期模型建立在它们的前辈所奠定的基础上。Grok 3 引入了先进的推理能力,具有“思考”模式进行逐步问题解决和“深度搜索”功能进行深入实时研究。Grok 2 首次引入了多模态,包括图像理解和文本到图像生成。
鉴于这一多样化的阵容,推荐使用 Grok 应用于多种场景。Grok 4 非常适合进行深入研究、数据分析以及专家级问题解决。Grok Code Fast 1 是软件开发的首选,其中速度和成本是优先考虑因素。对于速度和质量的平衡,Grok 3 模型非常适合高级问题解决、教育和实时分析时事。
- Llama
========
 you need to know… | by Erich R. Bühler | Enterprise Agility Magazine](https://mmbiz.qpic.cn/mmbiz_png/Wz32s0BYYH4icib5HX7k7tQ4V0CFTK7kyhlWmf4cxBkbFIUnJQOujYl1Z7SeoUA2w8CIicb6f2pW3F2wvgCOLPkMw/640?wx_fmt=png&from=appmsg)
you need to know… | by Erich R. Bühler | Enterprise Agility Magazine](https://mmbiz.qpic.cn/mmbiz_png/Wz32s0BYYH4icib5HX7k7tQ4V0CFTK7kyhlWmf4cxBkbFIUnJQOujYl1Z7SeoUA2w8CIicb6f2pW3F2wvgCOLPkMw/640?wx_fmt=png&from=appmsg)
Meta 继续在 LLM 领域保持领先地位,凭借其最先进的 Llama 模型,优先采用开源方法。最新的大规模发布是 Llama 4,其中包括原生多模态模型,如 Llama 4 Scout 和 Llama 4 Maverick。这些模型可以处理文本、图像和短视频,并基于专家混合(MoE)架构以提高效率。
Llama 4 Scout 以其高达 1000 万 token 的行业领先级上下文窗口而著称,非常适合需要大量文档分析的任务。Llama 3 系列(包括 Llama 3.1 和 3.3)是强大的基于文本的模型,针对客户服务、数据分析和内容创作等应用进行了优化。
在最近的基准测试中,Llama 4 Maverick 在标准基准测试中获得了 68.47% 的分数,领先于 Llama 3.1 405B。在代码编译任务中,它成功编译了 1007 个实例,超越了之前的版本。Llama 4 Scout 的 1000 万 token 上下文窗口(约 80 部小说)仍然是大规模文档分析的行业领导者。
与 OpenAI 和 Google 等闭源模型不同,Llama 的开源特性为开发者提供了更大的灵活性和控制权。这使得模型可以根据特定需求进行微调,并在私有基础设施上部署,吸引了寻求可扩展性和更高安全性的企业。在性能方面,据报道 Llama 4 Maverick 和 Scout 在各种基准测试中优于 GPT-4o 和 Gemini 2.0 Flash 等竞争对手,尤其是在编程、推理和多语言能力方面。这些模型的开放可用性和竞争性性能促进了大量研究人员和开发者的社区。
- Claude
=========
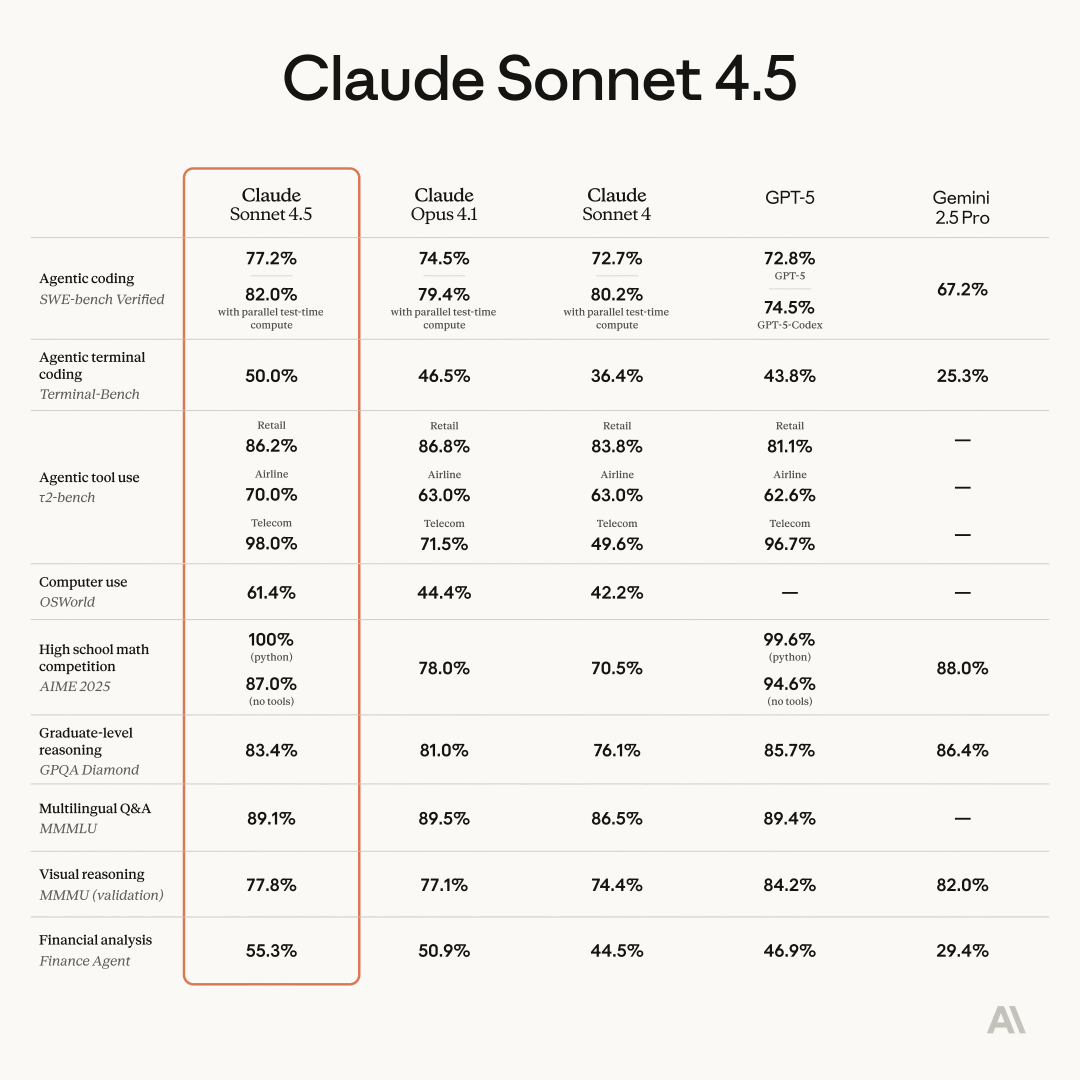
Anthropic 最新旗舰模型,Claude 4 系列(Opus 4 和 Sonnet 4.6),在 Claude 3 系列的基础上,通过整合多种推理方法进行构建。其突出特点是“扩展思考模式”,该模式利用了刻意推理或自我反思循环的技术。这使得模型能够迭代优化其思考过程,评估各种推理路径,并在最终确定输出前进行优化,使其适用于复杂的、多步骤问题解决。
Claude 模型系列被设计为多功能家族,每个模型都在智能、速度和成本之间取得平衡。
Claude Opus 4.6于2026年2月发布,新增100万token上下文(Beta版),论文评审准确率达85%,延续前代模型的核心优势,具备30小时持续任务处理能力,在OSWorld基准测试中得分61.4%、SWE-bench基准测试中得分77.2%,专注于专业场景服务。尽管较旧的 Claude 3 模型具有 200K-token 的上下文窗口,Claude 4 模型同样提供了令人印象深刻的 200K token 窗口(在 Sonnet 4 上提供 beta 1 百万 token 的上下文窗口),使其能够处理长文档。这些模型是多模态的,能够处理文本和图像,并引入了新功能,如“计算机使用”,这允许它们以更高的熟练度导航计算机屏幕。
总体而言,Claude 系列是像 Google 的 Gemini 和 OpenAI 的 GPT-4 等模型的有力竞争者,在编码和推理的基准测试中始终表现良好。
- Mistral
==========
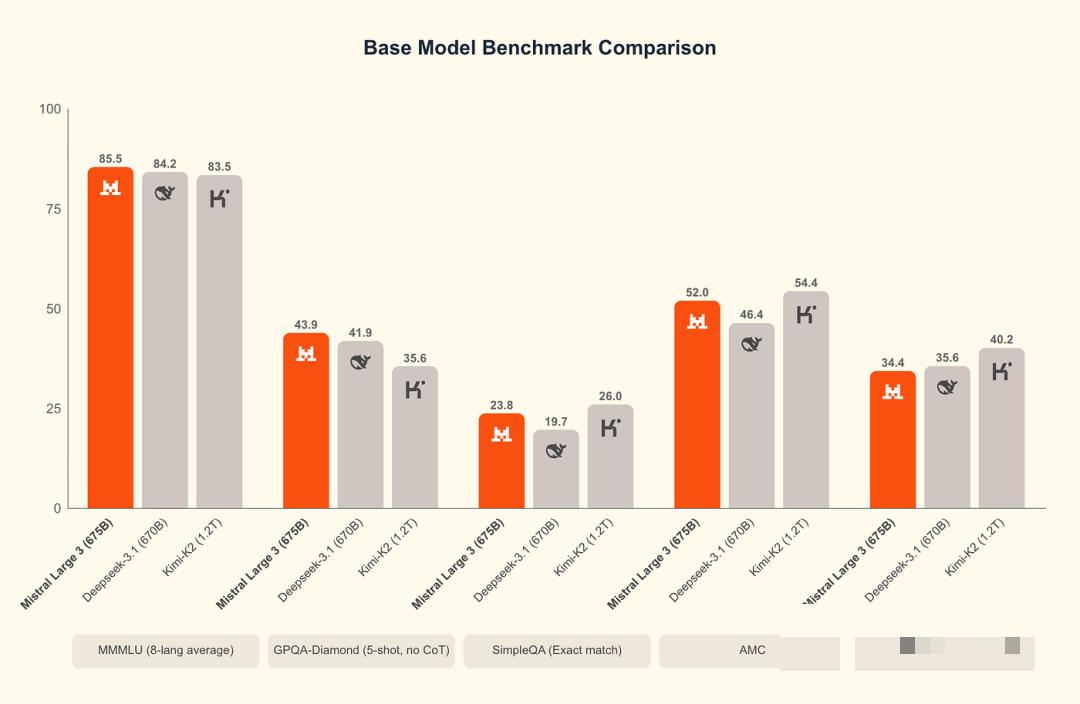
Mistral AI 是 LLM 领域的重要参与者,为开源社区和企业客户提供多样化的模型组合。其关键差异化优势在于其专业且灵活的模型方法,为特定用例提供定制选项。
mistral 发布了Mistral 3 系列,包括 Large 3(675B 总参数量,MoE)。它提供了GPT-5.2 性能的 92%,但价格仅为其 15% 左右,为注重成本效益的扩展提供了巨大的价值。Mistral 还通过Ministral 3更新了其边缘能力,能够在单个 GPU 上运行,适用于无人机和机器人。他们的 OCR 3 模型在复杂文档解析方面现在取得了 74% 的胜率,这对行政自动化至关重要。
对于开发者来说,有 Devstral Medium,这是一个“代理编码”模型,以及 Codestral 2508,针对 80 多种语言中的低延迟编码任务进行了优化。Mistral 还提供了较小的“边缘”模型,如 Ministral 3B & 8B,适用于资源受限的设备,以及 Voxtral,这是一系列用于语音转文本的音频模型。
在开源方面,Mistral 的模型采用 Apache 2.0 许可证发布。Mixtral 8x22B 是一个强大的开源模型,采用专家混合(MoE)架构,以其性能和计算效率而闻名。其他开源模型包括用于编码的 Devstral Small 1.1、用于多模态任务的 Pixtral 12B,以及用于解决数学问题的 Mathstral 7B。
- Gemini
=========
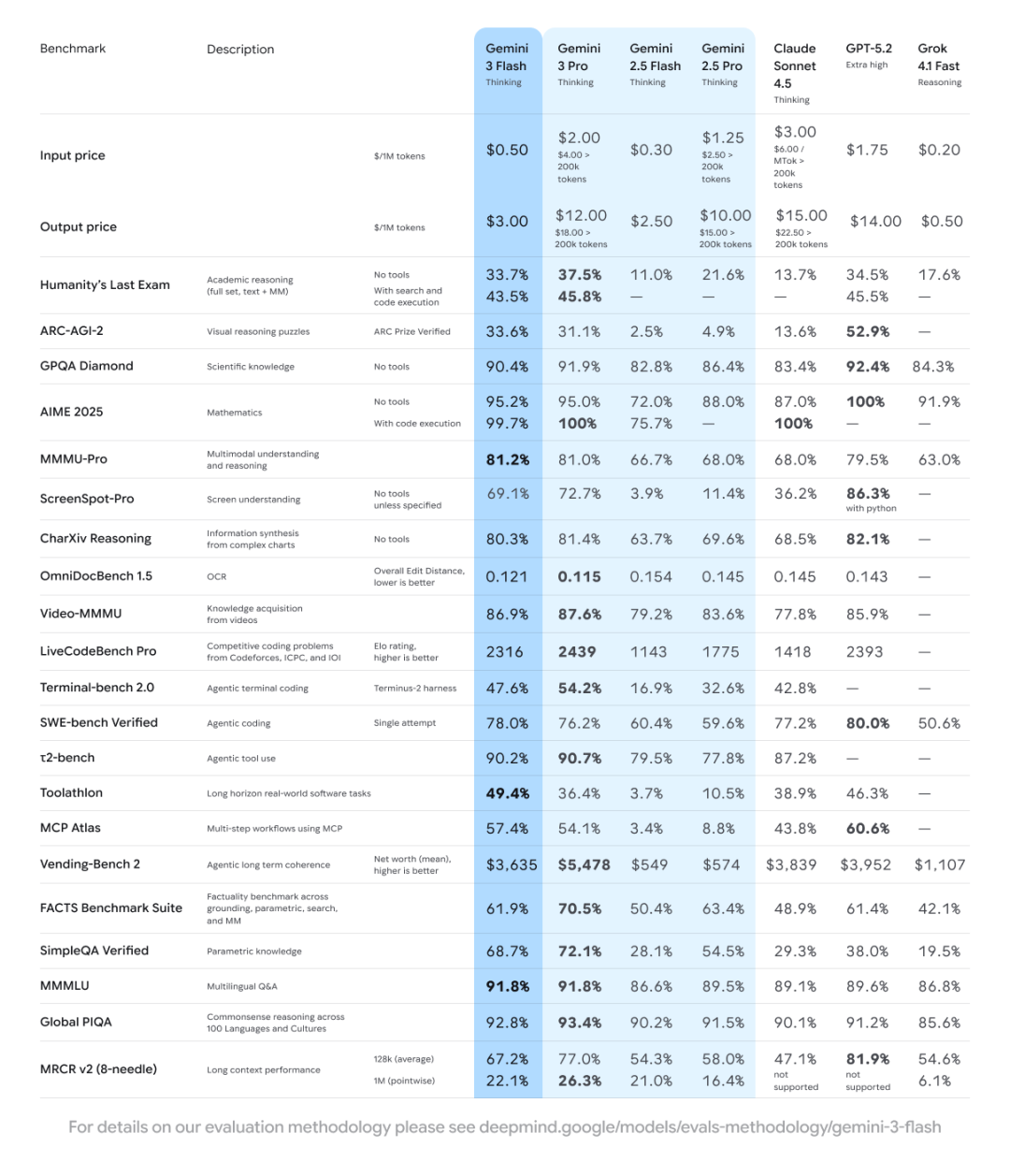
最新型号:Gemini 3.1(含Pro、Flash-Lite两个版本)
介绍信息:于2026年3月发布,Flash-Lite版本输入成本低至0.25美元/百万tokens,响应速度较上一代提升2.5倍,最高支持200万token上下文,在SWE-bench Verified基准测试中得分78%,深度思考能力推理得分较上一代提升2.5倍,聚焦高效、低成本服务。
优点:成本极低,Flash-Lite版本性价比突出;响应速度快,推理效率大幅提升;深度思考能力强,基准测试表现优异;上下文窗口可达200万token,长文本处理能力出色,适配不同性能需求场景。
虽然 Gemini 是专有、闭源的模型,但 Google 也提供了基于相同研究的 Gemma 系列开源模型。 Gemma 3 支持 128,000 个 token 的上下文窗口,并提供多种参数尺寸,使其成为需要本地微调和部署模型、并希望获得更大控制权的开发者、学者和初创企业的理想、灵活的替代方案。
鉴于 Gemini 是专有模型,处理敏感或机密数据的公司必须确保供应商符合 GDPR 和 HIPAA 等数据隐私和安全标准。这种尽职调查对于减轻将数据发送到外部服务器相关的安全风险至关重要。
- Cohere
=========
Cohere 的 Command 系列模型面向企业应用场景。旗舰模型 Command A 具有 256,000 个 token 的上下文窗口,私有部署仅需两块 GPU,比 GPT-4o 等竞争对手更高效。人类评估显示,Command A 在商业、STEM 和编程任务上与更大模型相当或表现更优。Cohere 还发布了专用模型:Command A Vision 用于图像和文档分析,Command A Reasoning 用于复杂问题解决,以及 Command A Translate,支持 23 种语言并优于竞争对手的翻译服务。
这些模型是为检索增强生成(RAG)而构建的,能够访问并引用公司内部文档以提供准确回答。Cohere 对多语言(尤其是常被忽视的语言)的关注是其关键差异化优势。公司解决方案还提供安全、本地部署,这对处理敏感数据的金融和医疗行业至关重要。Cohere 的策略专注于为业务流程提供特定、高效的工具,而非追求通用基准的顶尖表现。
最近的更新强调了硬件效率;现在仅需2 个 GPU(H100/A100)即可高效运行,而类似的模型通常需要高达 32 个。它还以156 个 token/秒的速度生成 token——比 GPT-4o 快约 1.75 倍,使其成为低延迟、安全的企业部署的理想选择。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
ibute.pc_search_result.none-task-blog-2allsobaiduweb~default-0-137261875.142%5Ev100%5Epc_search_result_base4&spm=1018.2226.3001.4187)👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)