Kimi、Qwen、GLM架构大比拼(非常详细),最新开源大模型底层原理从入门到精通,收藏这一篇就够了!
背景知识
构建多模态线性线性模型主要有两种方法:
- 方法 A:统一Embedding解码器架构方法
- 方法 B:跨模态注意力架构方法
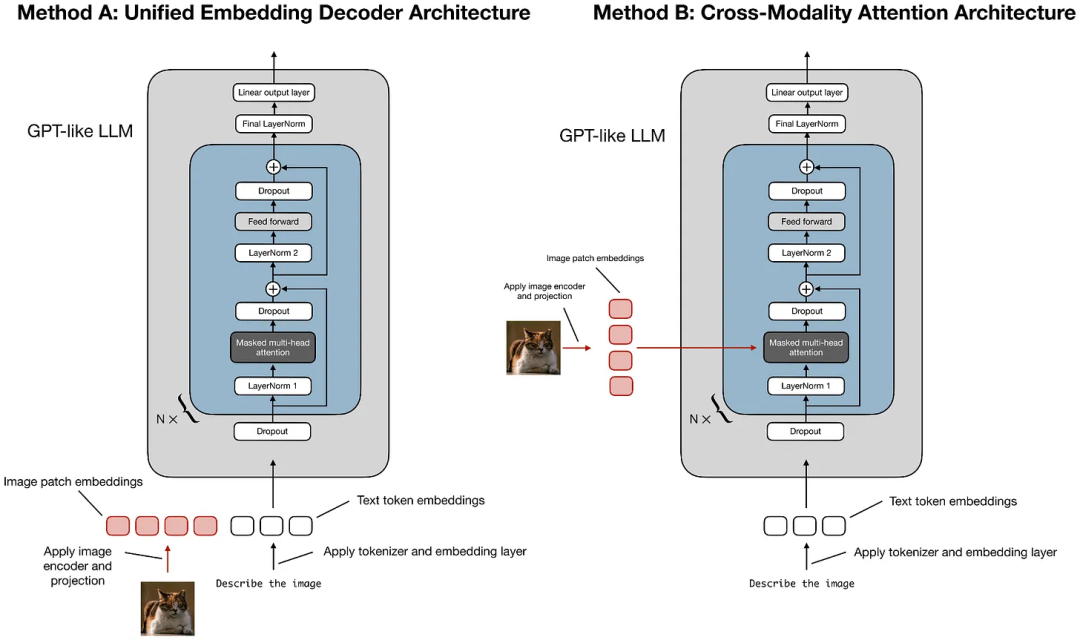
多模态预训练架构
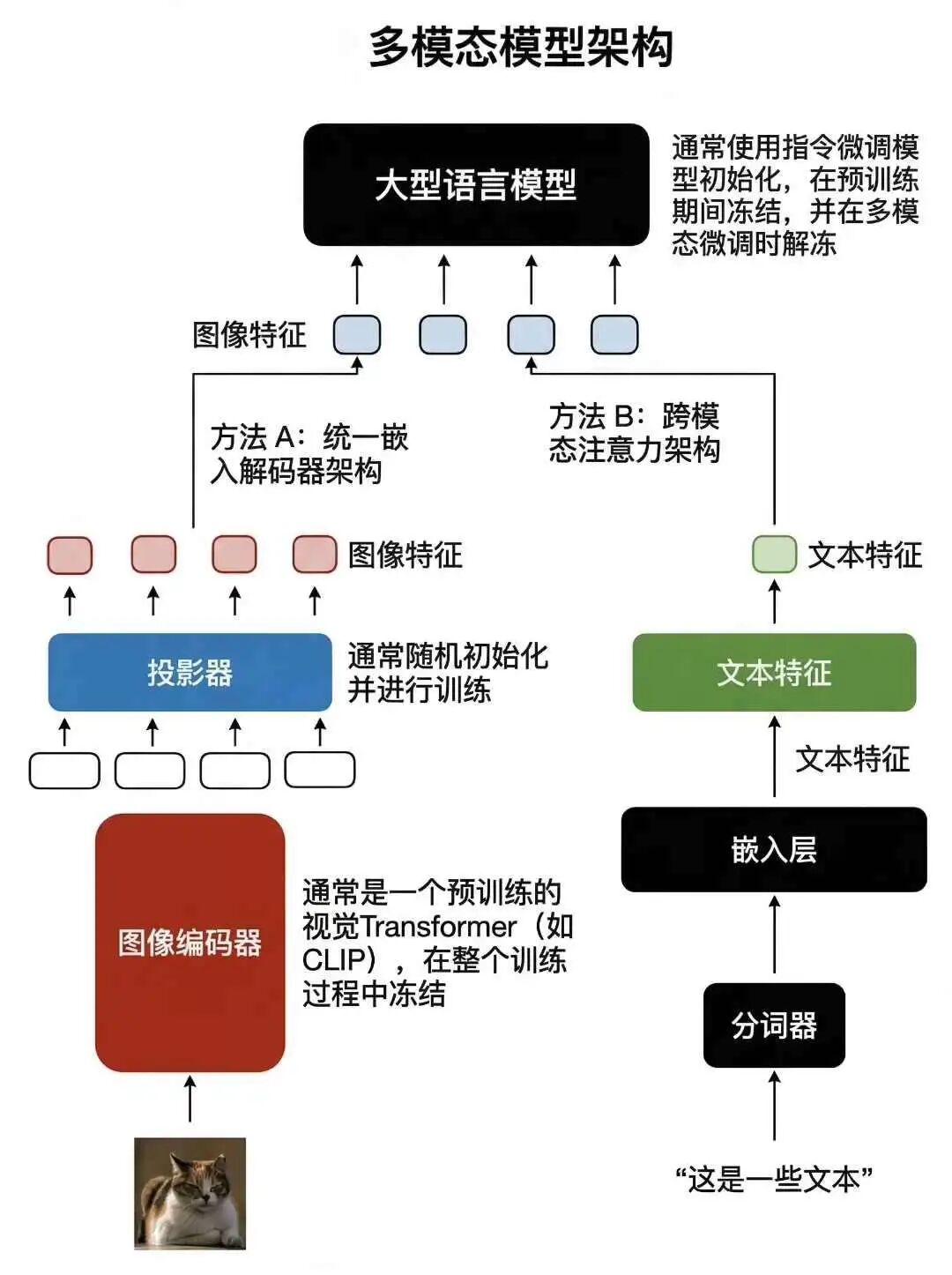
tokenizer
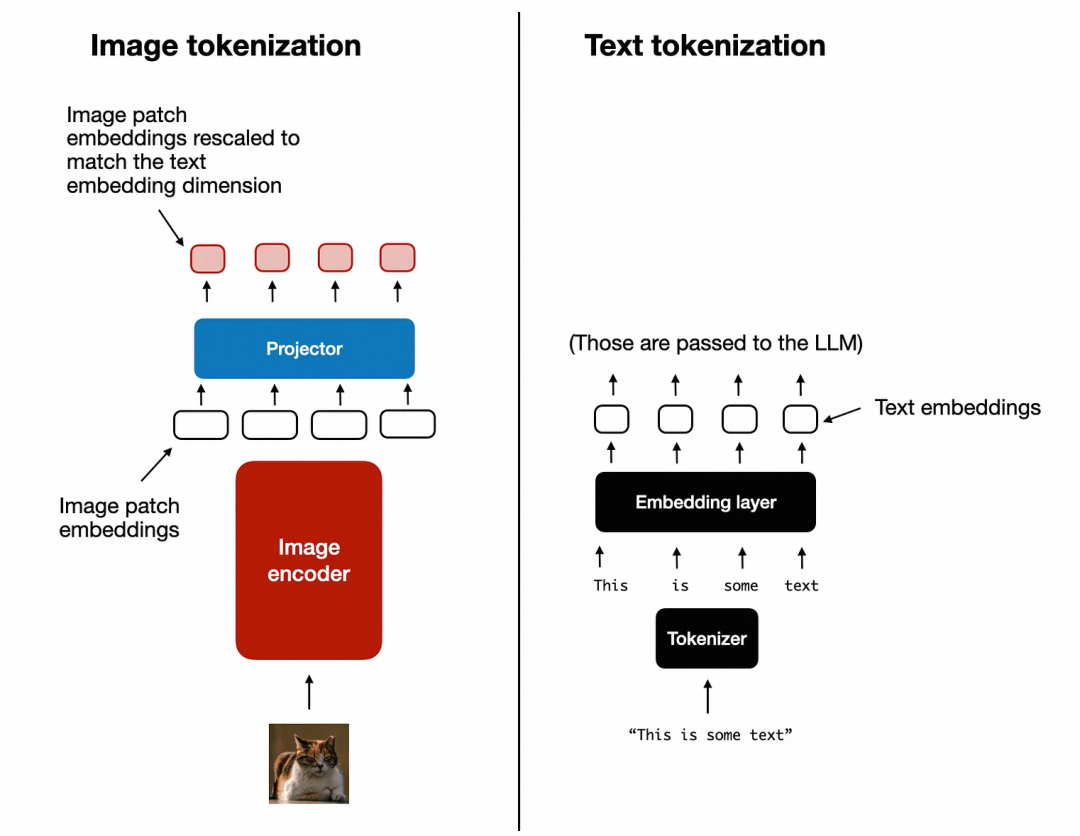
Image vs text tokenization
在图像编码器之后添加了一个投影模块。这个投影模块通常只是一个与前面解释的类似的线性投影层。其目的是将图像编码器的输出投影到与嵌入文本标记尺寸相匹配的维度上
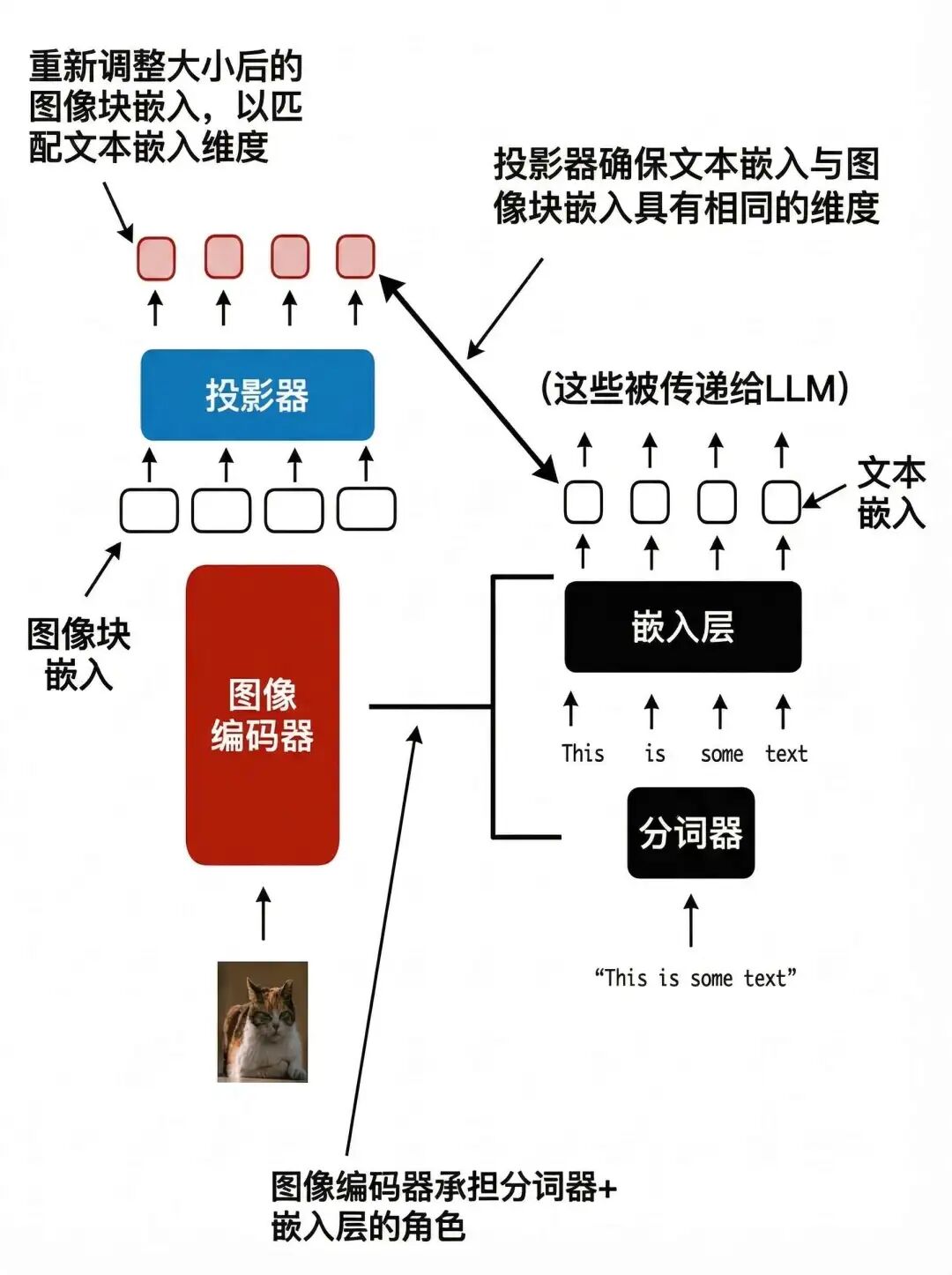
图像patch embedding与文本token embedding具有相同的embedding维度,将它们连接起来作为 LLM 的输入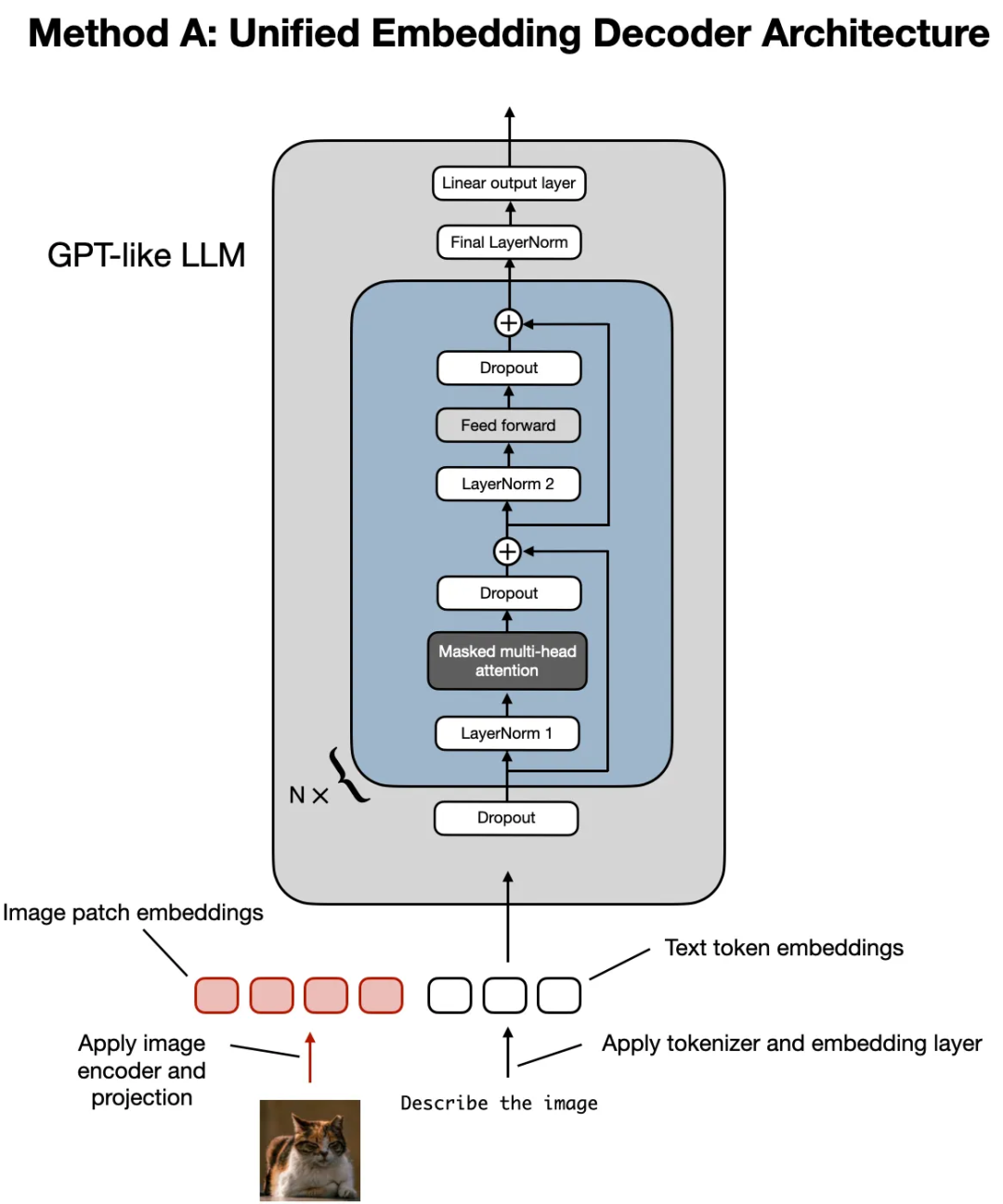
cross attention
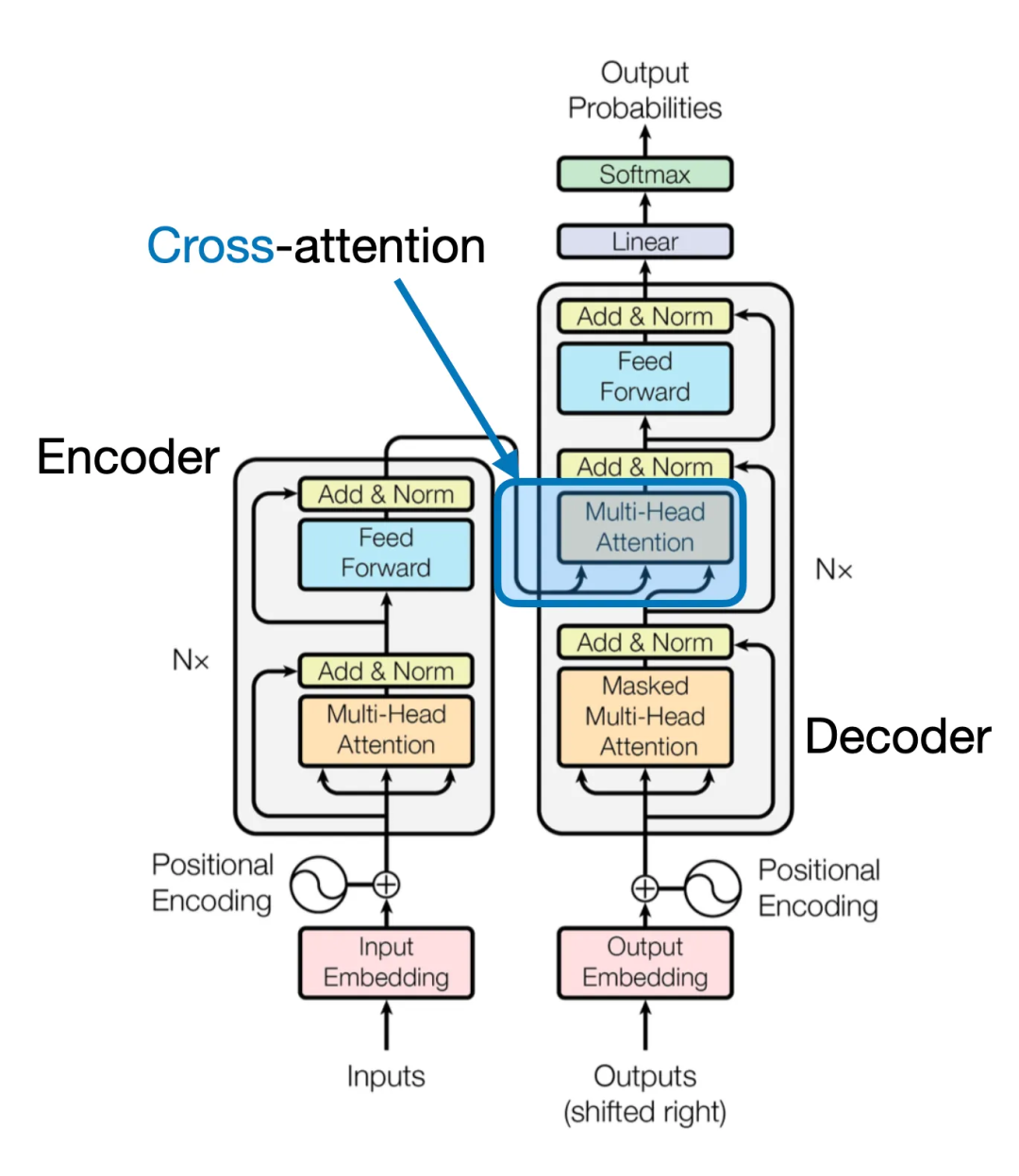
Transformer 架构中使用的交叉注意力机制
将图像patch token投影到与文本标记嵌入相同的维度后,将它们连接起来作为标准 LLM 的输入。跨模态注意力架构方法中,不再将图像块编码为 LLM 的输入,而是通过交叉注意力机制将多头注意力层的输入图像块连接起来
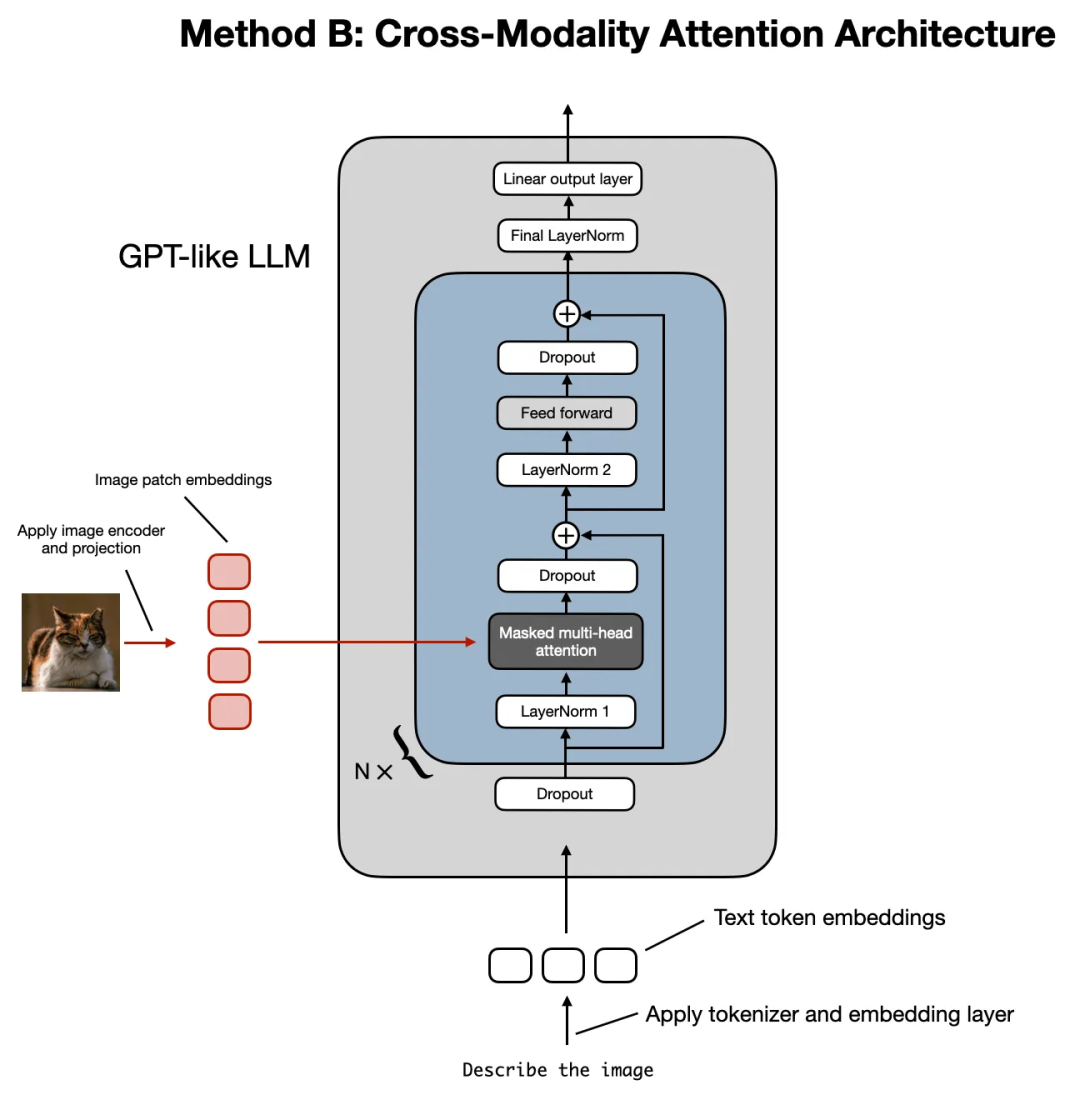
Kimi K2.5
Kimi K2.5 基于Kimi K2 MoE 大模型文本底座,是一个原生多模态模型融合MoonViT-3D 原生分辨率视觉编码器, “视觉编码器 - MLP 投影层 - 文本 MoE 模型” 的统一多模态架构,同时设计了分阶段的训练流水线和高效的训练基础设施。
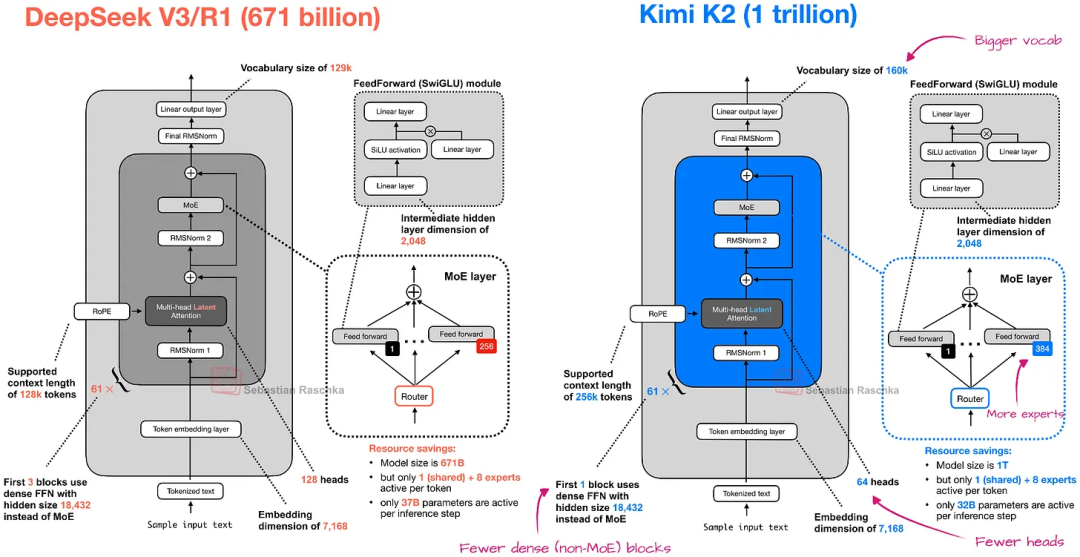
kimi k2是deepseek v3的放大版
- 文本基座模型:Kimi K2 MoE 模型激活参数 320 亿,384 个专家,每个token激活 8 个专家(稀疏度 48)预训练采用了15 万亿高质量文本token。支持 256k 超长上下文,为长文本 / 长视频理解奠定基础。
模型架构
| 属性 | 值 |
|---|---|
| 架构 | Mixture-of-Experts (MoE) |
| 总参数量 | 1T |
| 激活参数量 | 32B |
| 总层数(含稠密层) | 61 |
| 稠密层数量 | 1 |
| 注意力隐藏维度 | 7168 |
| MoE 隐藏维度(每专家) | 2048 |
| 注意力头数 | 64 |
| 专家总数 | 384 |
| 每 Token 选中专家数 | 8 |
| 共享专家数 | 1 |
| 词表大小 | 160K |
| 上下文长度 | 256K |
| 注意力机制 | MLA |
| 激活函数 | SwiGLU |
| 视觉编码器 | MoonViT |
| 视觉编码器参数量 | 400M |
采用token-efficient的MuonClip优化器替换掉AdamW优化器,后者容易在出现注意力logit爆炸,从而导致loss spike。
在训练过程中,将视觉token与文本标记token一起传递,消融研究实验发现,表明模型可以从预训练早期看到视觉标记中受益
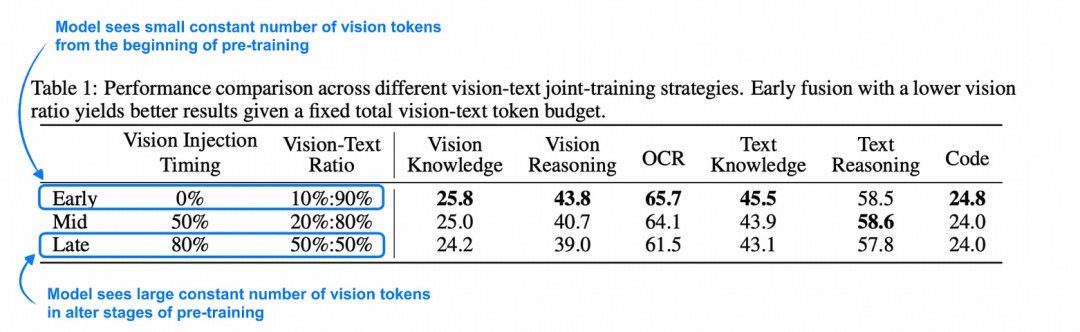
在训练过程中视觉token数量固定的情况下,如果在预训练初期向模型展示较少数量的视觉token(而不是在后期添加更多视觉token),则模型性能会得到提升
Setp 3.5 Flash
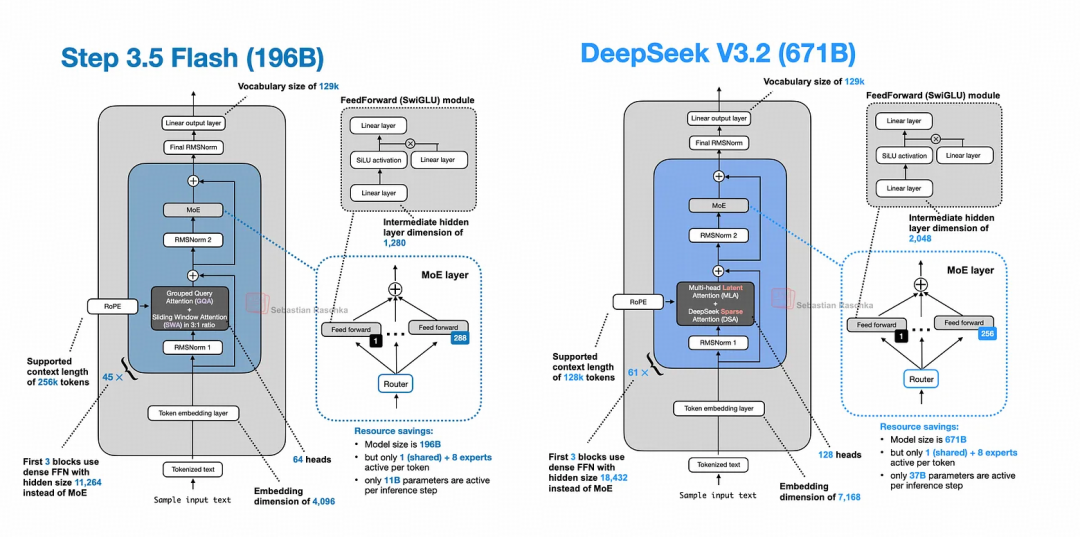
Step 3.5 Flash 在 128k 上下文长度下吞吐量为 100 个token/秒,采用了Deepseek同款Multi-token Prediction,Step 3.5 Flash 在训练和推理过程中使用带有3个附加token的 MTP(MTP-3)
Multi-token Prediction原理
多token预测(Multi-token Prediction):让模型在训练时,一次性预测多个未来token,而不是仅仅预测下一个token
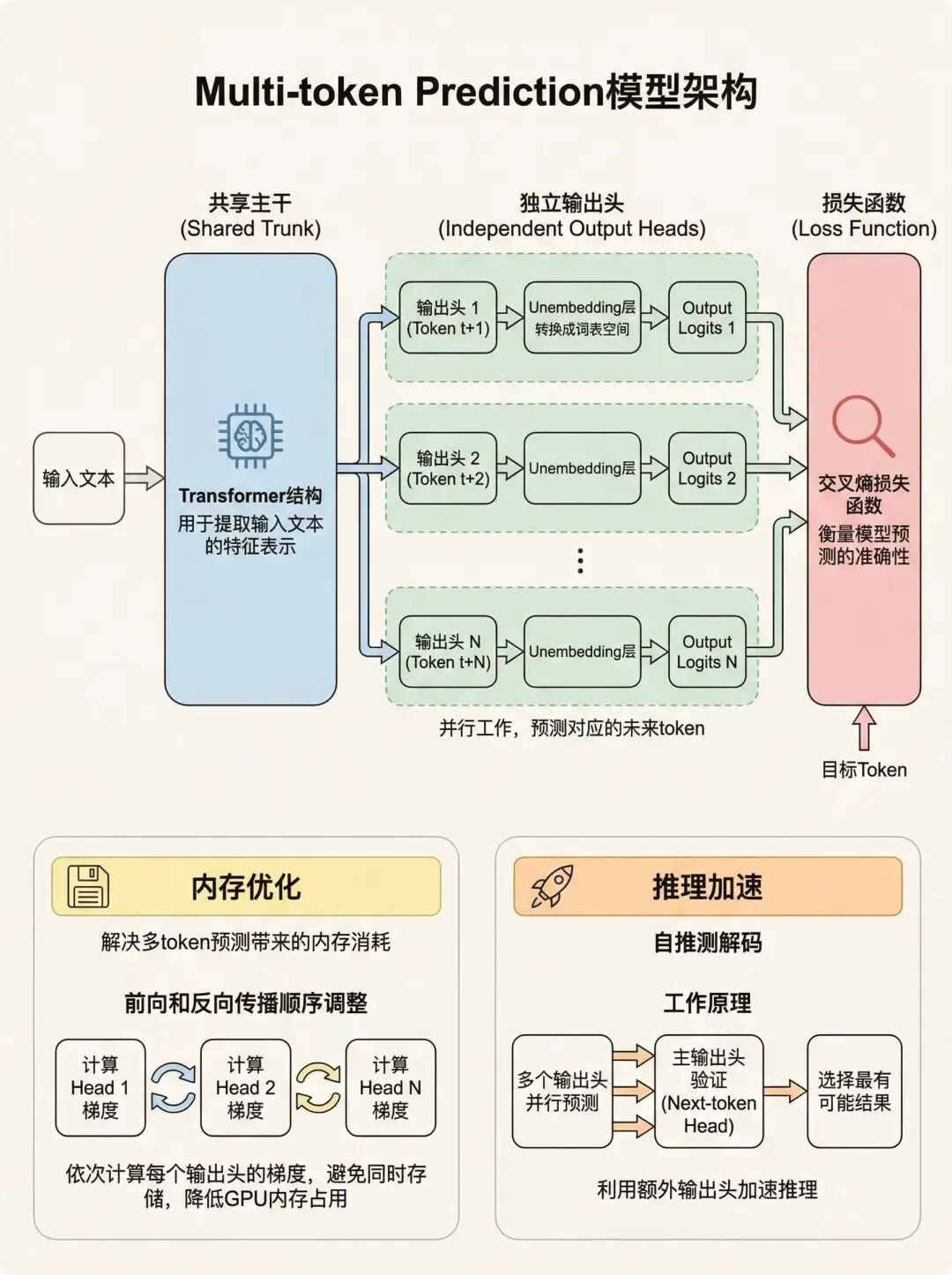
Multi-token Prediction模型架构
- 共享主干(Shared Trunk):模型的主体部分是一个Transformer结构,用于提取输入文本的特征表示。
- 独立输出头(Independent Output Heads):在共享主干的基础上,为每个待预测的token都设置一个独立的输出头。这些输出头并行工作,预测对应的未来token。
- Unembedding层 每个输出头后面跟着一个Unembedding层,将Transformer的输出转换成词表空间(vocabulary space)。
- 损失函数:使用交叉熵损失函数来衡量模型预测的准确性。
- 内存优化:
为了解决多token预测带来的内存消耗问题,提出了一种内存高效的实现方法。 - 前向和反向传播顺序调整**:在计算梯度时,模型会依次计算每个输出头的梯度,而不是一次性计算所有头的梯度,从而避免了同时存储所有输出头的梯度信息,降低GPU内存占用**。推理加速:
- 自推测解码(Self-Speculative Decoding):利用多token预测的额外输出头进行自推测解码,从而加速推理过程。
工作原理:先用多个输出头并行预测多个token,然后用主输出头(next-token prediction head)验证预测结果,并选择最有可能的预测结果
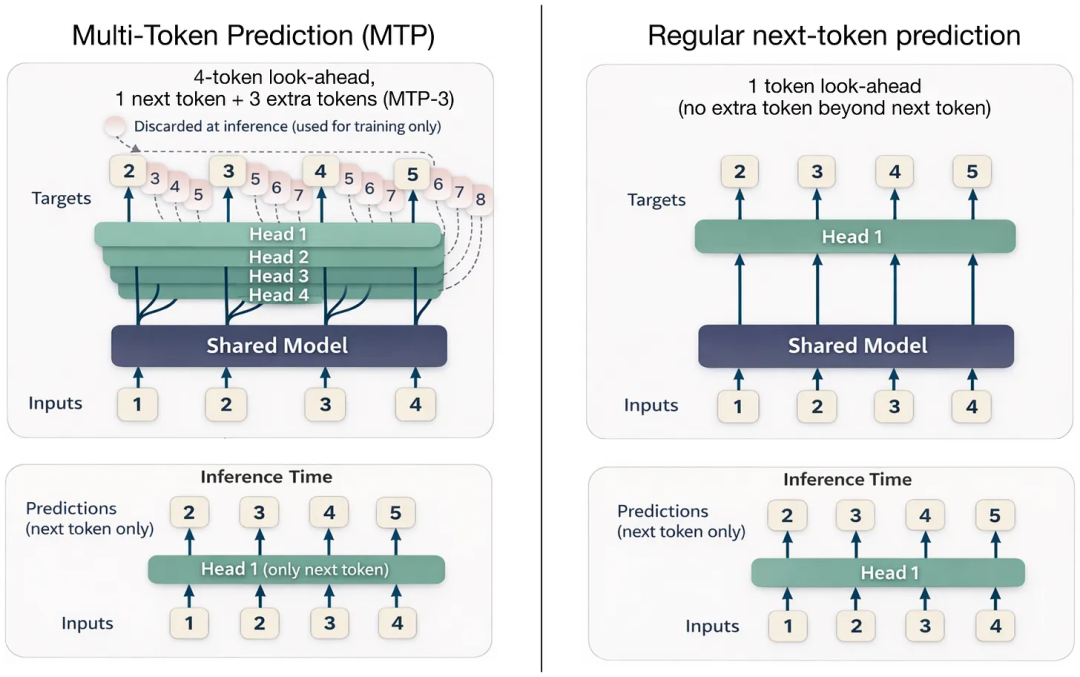
多token预测与常规下一token预测的比较。最初,MTP 仅用于训练阶段,而不用于推理阶段;因此,推理时间步(底部)仅显示一次下一词元预测。
GLM-5
GLM-5采用了78层Transformer解码器,前三层为Dense结构,第四层及以后采用Mo架构,expert数量从 160 个(GLM-4.7)增加到 256 个(GLM-5),处理单个token激活其中8个expert,1个共享专家保证基础能力稳定,但是GLM-5 中 Transformer 层数从 GLM-4.7 的 92 层减少到了 78 层,可能是为了推理效率的考虑
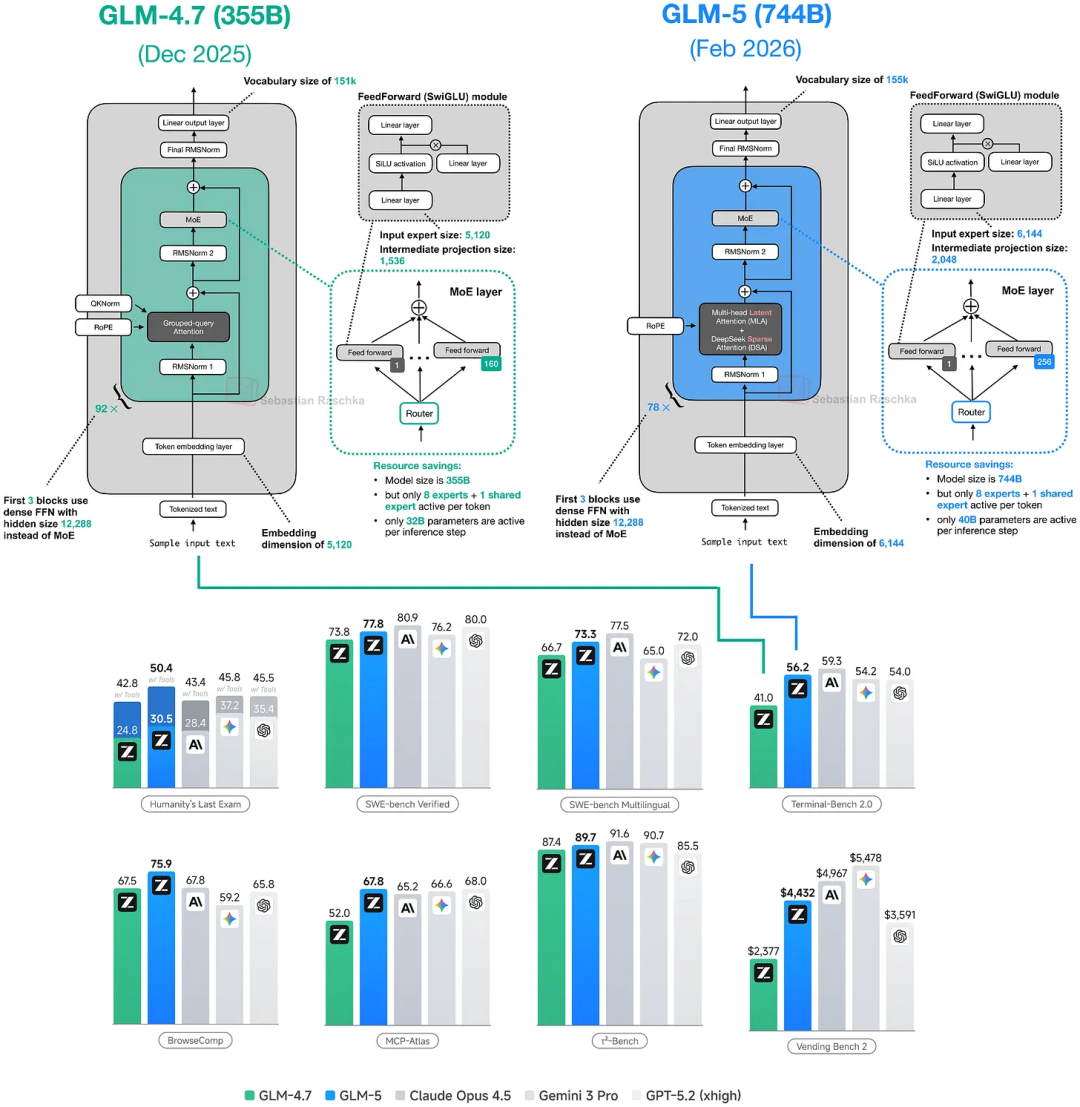
GLM-4.7 和GLM-5模型架构对比
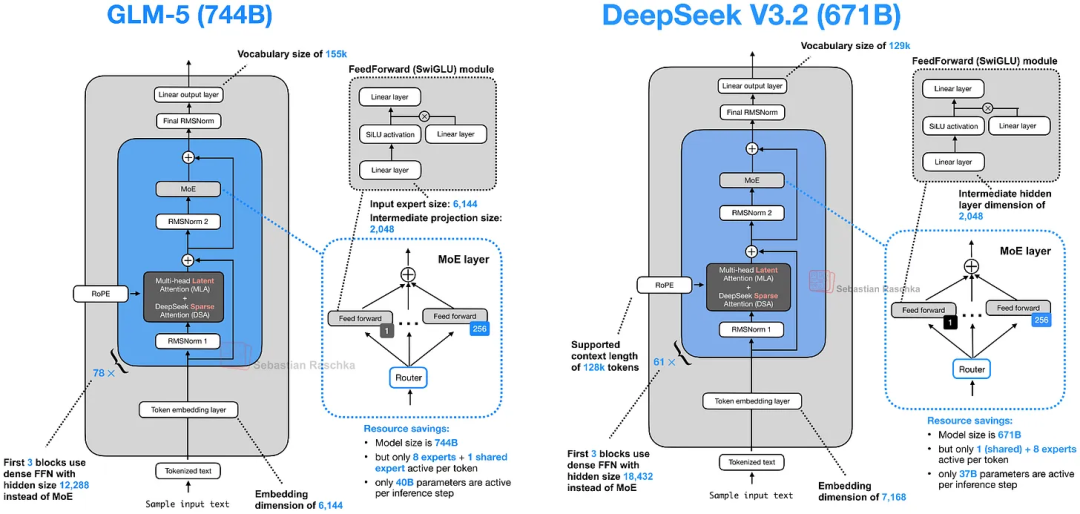
GLM-5 和 DeepSeek V3.2 模型架构对比
Minimax M2.5
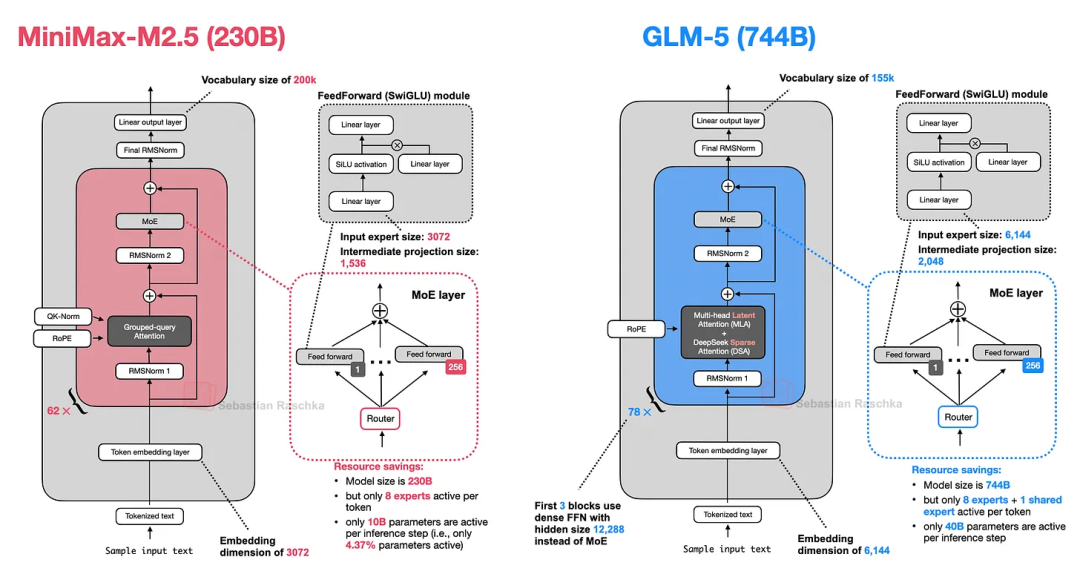
从架构上看,MiniMax M2.5 是一款 230B 型号,采用相当经典的设计:只有简单的分组查询注意力机制,没有滑动窗口注意力机制或其他效率改进
Qwen3.5
Qwen3.5 从代码结构上看是Qwen 家族第一个原生多模态模型,采用Gate Attention+Gate DeltaNet混合注意力机制。
Gate Attention
在大语言模型持续向更大规模、更长上下文演进的过程中,训练稳定性与注意力行为的可控性日益成为关键瓶颈,Qwen团队提出了Gate Attention,率先用在了Qwen3 Next模型上面。
详细解读可参考 https://mp.weixin.qq.com/s/EV_fwU9muCocQiMCAsbYhA
欠阿贝尔两块钱,公众号:AIGC面面观NIPS2025最佳论文 Qwen团队Gated Attentio精读,LLM注意力机制再度突破
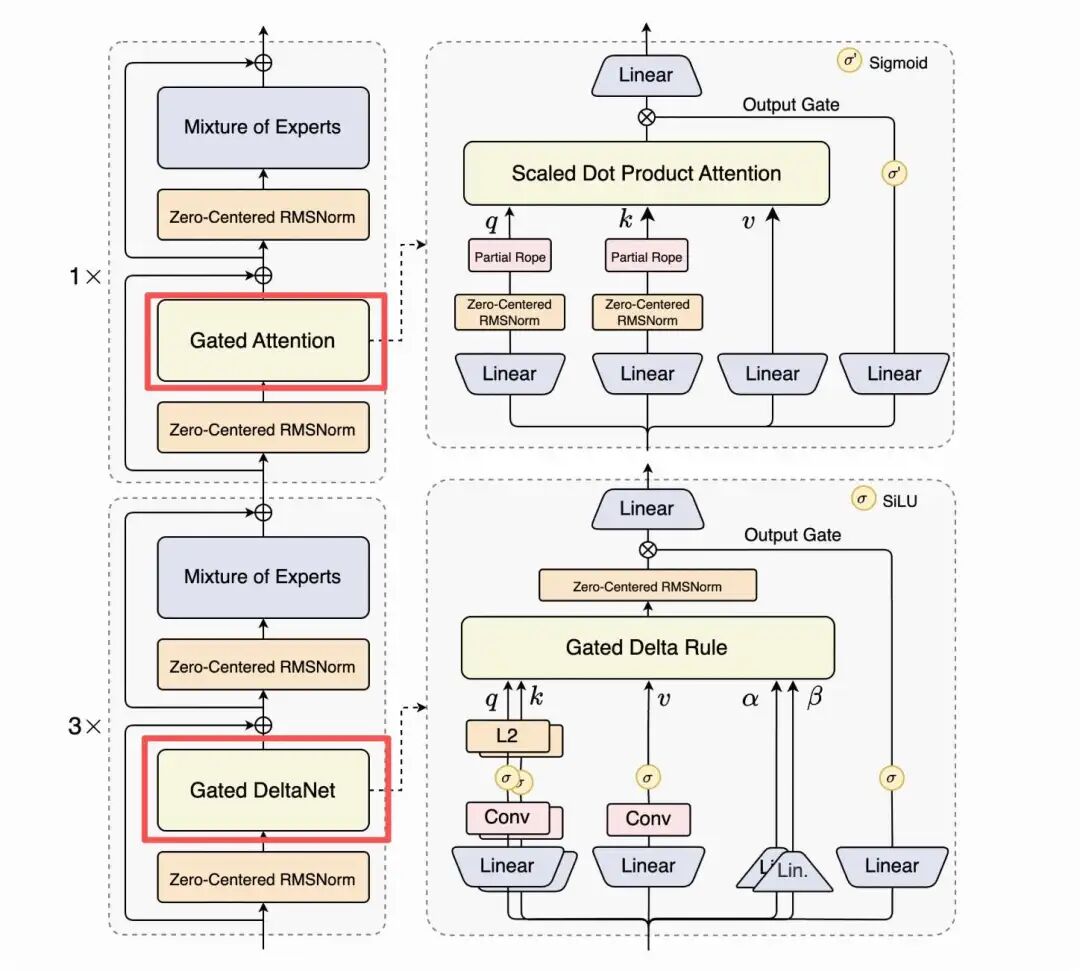
qwen3 next模型架构
Gate Attention视为 GQA 中使用的标准缩放点积注意力(Scaled Dot-Product Attention)机制,并在此基础上进行了一些调整。门控注意力模块与普通 GQA 模块的主要区别在于:
- 一个输出门(sigmoid 控制,通常按通道),用于在将注意力结果加回残差之前对其进行缩放
- QKNorm 的 RMSNorm 是以零为中心的 RMSNorm,而不是标准的 RMSNorm
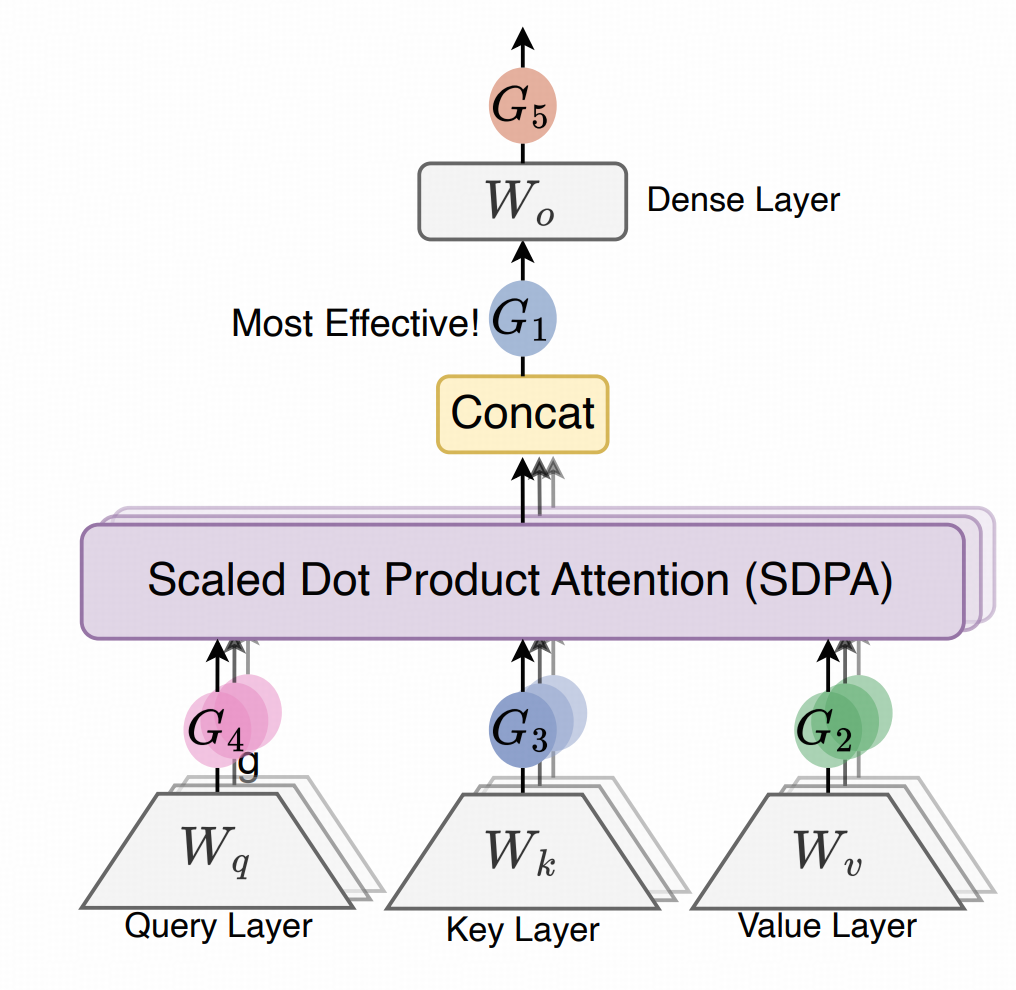
gate attention关键门控位置
Gate Attention关键门控位置选择的关键原因在于:
- 此时添加门控,
可直接对SDPA的加权结果(如SDPA前、Value层、SDPA输出后)进行动态筛选,避免无关信息进入后续计算; - 若在SDPA前或Value层添加门控,
仅能对原始输入或单一Value向量处理,无法基于完整的注意力权重整合结果做决策,效果大打折扣。
本质上只是对 GQA 的稳定性进行更改。
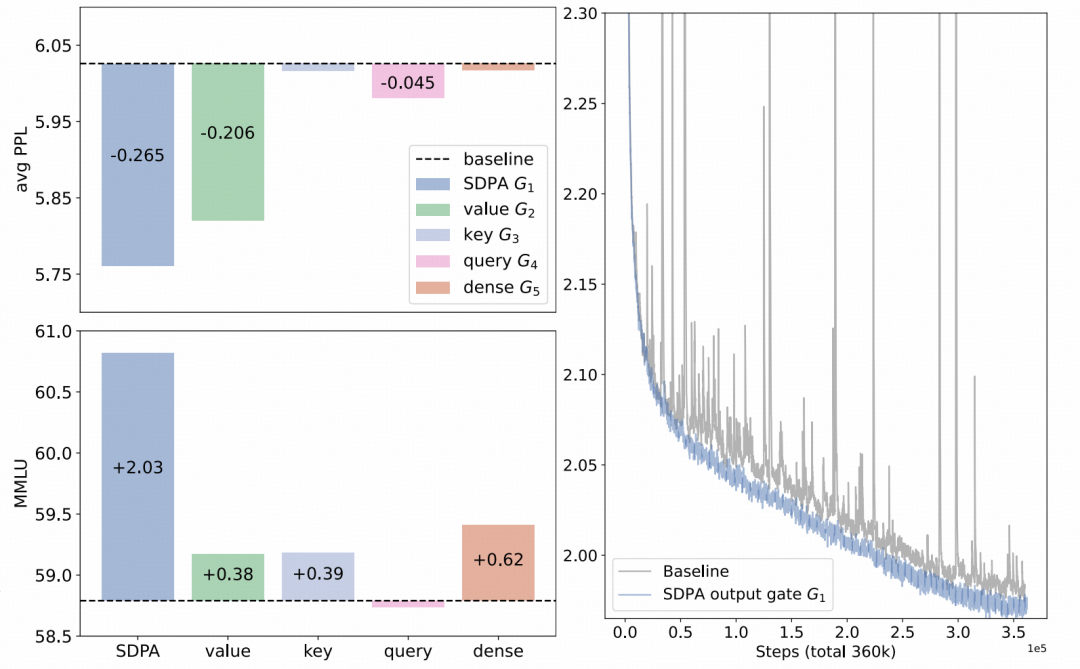
对 150 亿 MoE 模型在不同位置应用门控后的性能比较(测试 PPL 和 MMLU)。在 SDPA 层之后应用门控(G1)可获得最佳的整体结果。在 Value 层之后应用门控(G2)也展现出显著的改进,尤其是在 PPL 指标上在相同的超参数下,对基线模型和应用 SDPA 门控的 17 亿密集模型在 3.5T 个 token 上的训练损失进行比较(平滑处理,系数为 0.9)
Gate DeltaNet
Gate DeltaNet 是一项更为显著的改进。在 DeltaNet 模块中,、、 以及两个门(α、β)由线性轻量级卷积层生成并进行归一化处理,而该层则用快速权重增量规则更新取代了注意力机制
Gate DeltaNet 的Gate Attention与之前讨论的门控注意力机制类似,不同之处在于它使用 SiLU 激活函数代替逻辑 sigmoid 激活函数
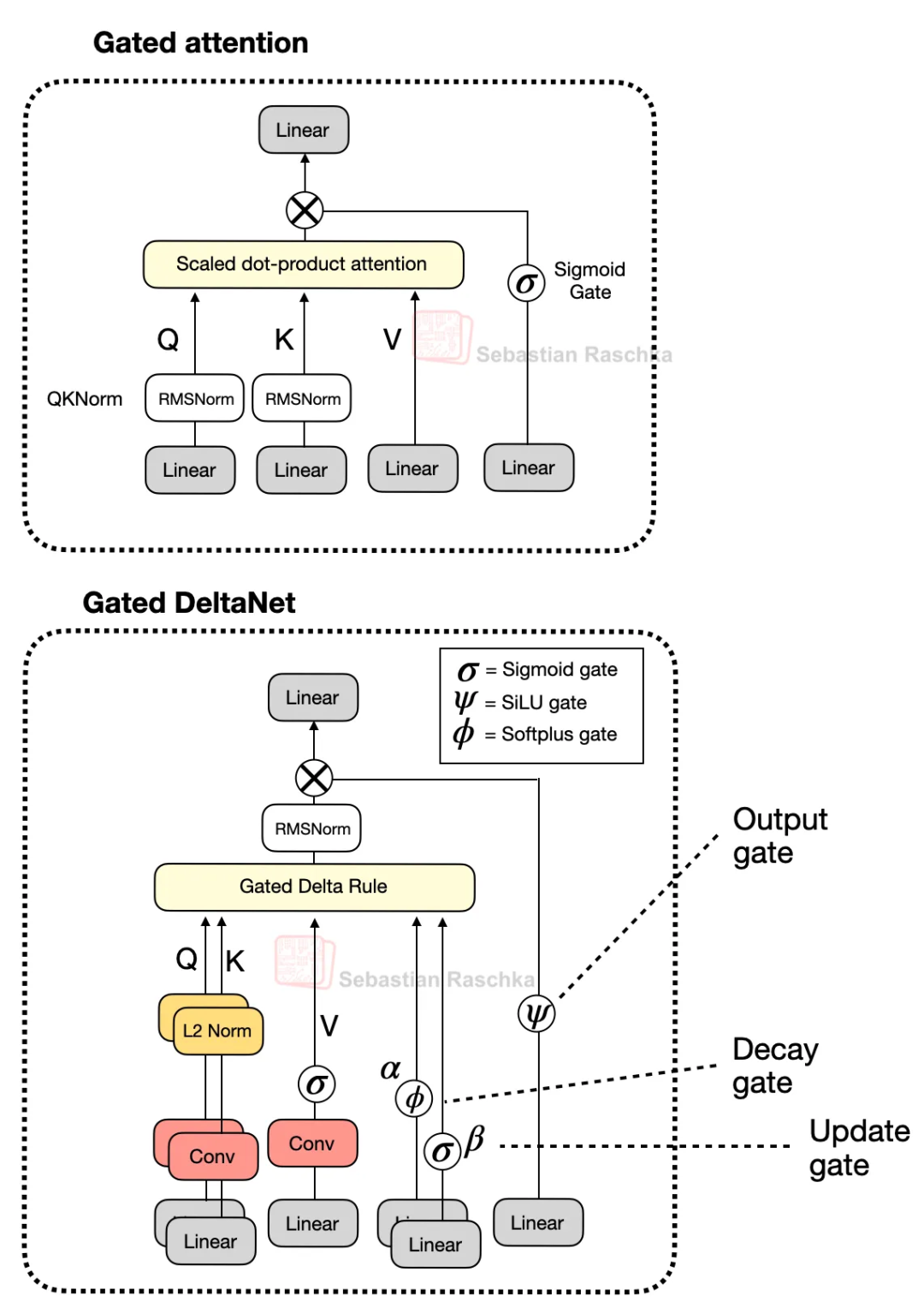
Gate Attention与Gate DeltaNet的比较
除了输出门之外,Gate DeltaNet中的“Gate”还指代几个额外的门:
- α(衰减门)控制着记忆随时间衰减或重置的速度。
- β(更新门)控制新输入对状态的修改强度。
Qwen3.5 采用了与 Qwen3-Next 和 Qwen3-Coder-Next相同的混合注意力模型(包含 Gated DeltaNet)
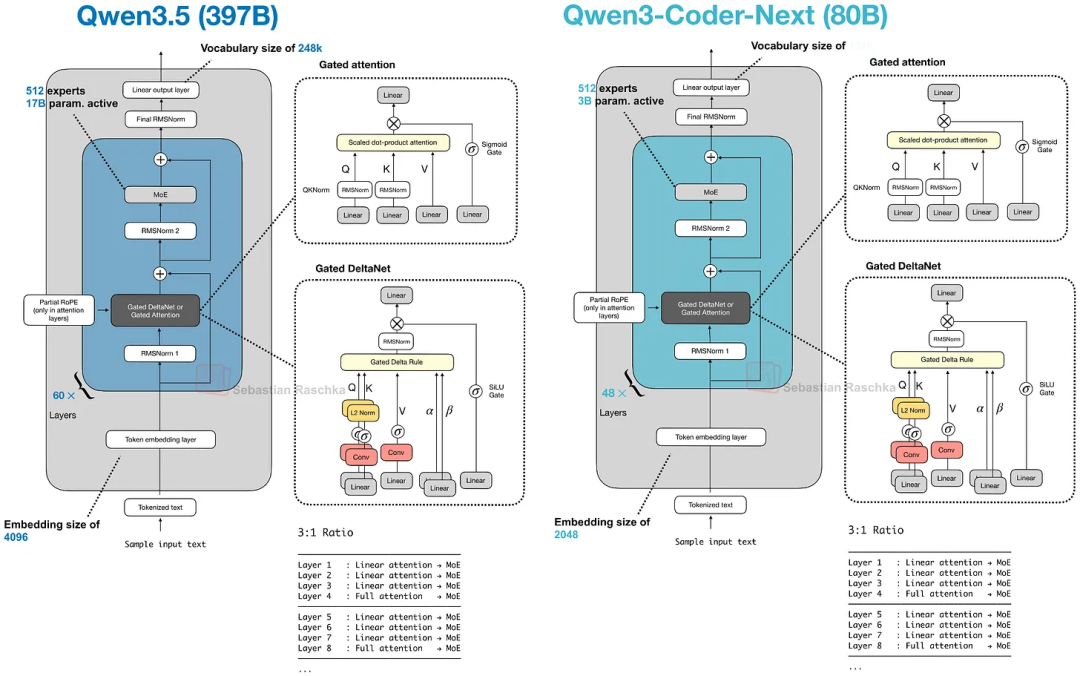
Qwen3.5 与 Qwen3(-Coder)-Next 架构的比较
Ling 2.5
没有使用Gate DeltaNet,而是采用了一种名为Lightning Attention)的略微简单的循环线性注意力机制变体。此外,Ling 2.5 还采用了来自 DeepSeek 的Multi-Head Latent Attention机制。
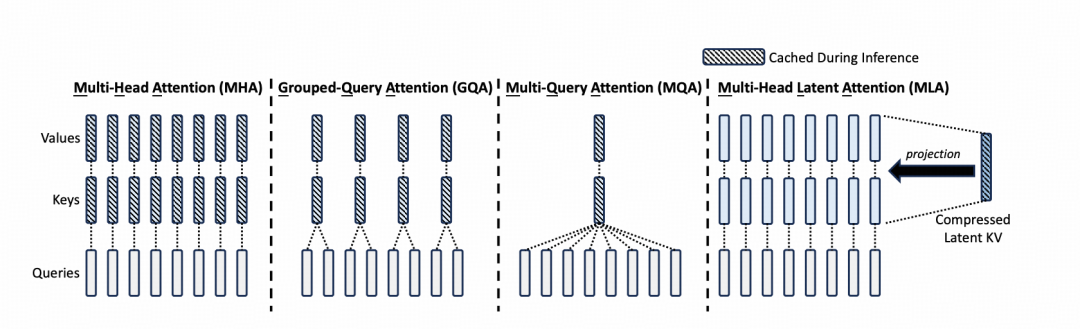
Multi-Head Attention (MHA), Grouped-Query Attention (GQA), Multi-Query Attention (MQA), and Multi-head Latent Attention (MLA)对比
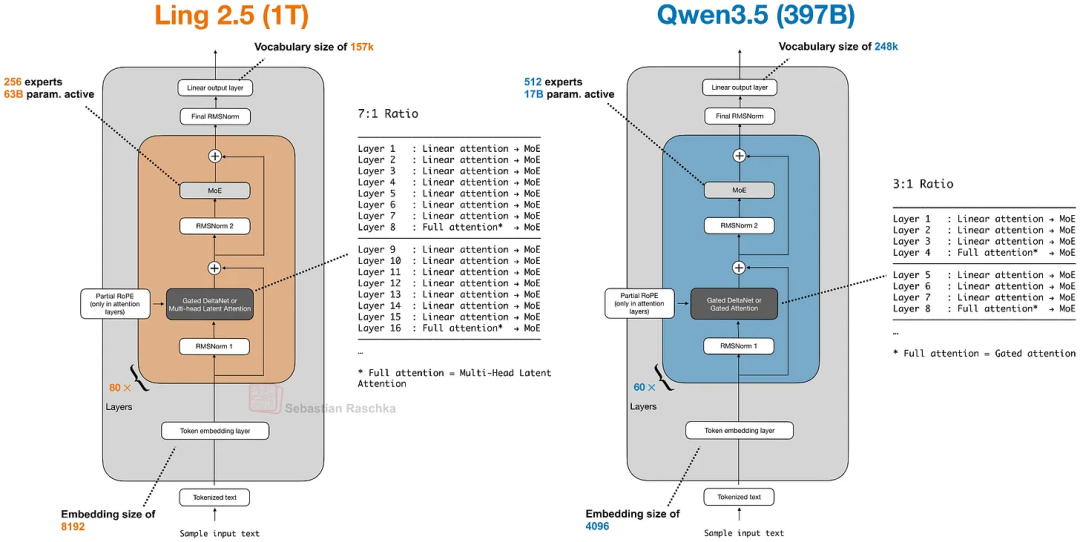
Ling 2.5 与 Qwen 3.5 的比较;两种架构都是线性注意力混合架构
优势在于处理长上下文时效率极高,与 Kimi K2(参数量为 1T,与 Ling 2.5 相同)相比,Ling 2.5 在 32k token 的序列长度下吞吐量提高了 3.5 倍。
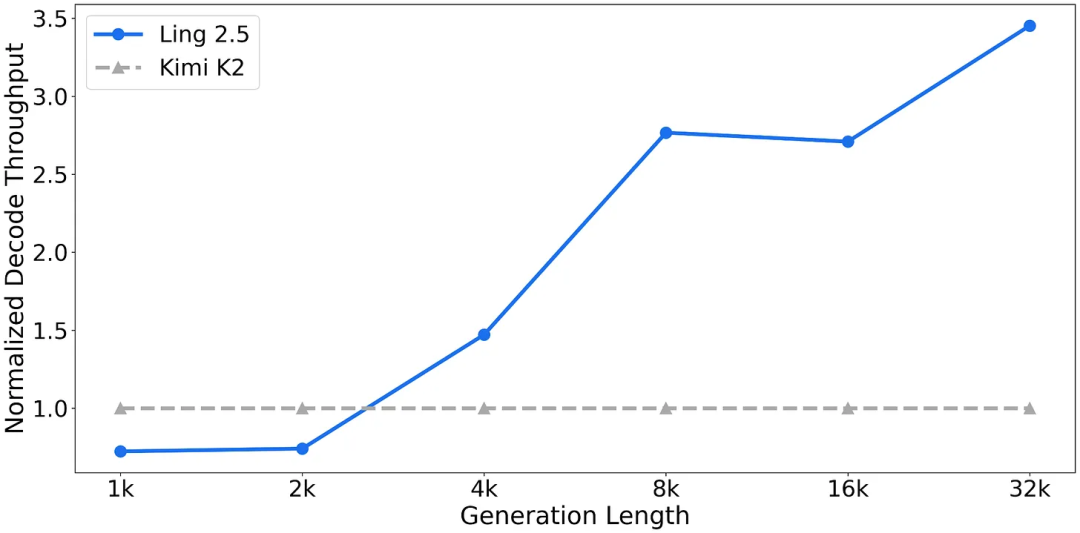
Ling 2.5 与 Kimi K2 的相对吞吐量对比(参数规模均为 1 万亿);请注意,吞吐量已进行归一化处理,Kimi K2 的吞吐量显示为 1 倍(尽管图中看起来呈线性,但 Kimi 的吞吐量并非线性关系)
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献149条内容
已为社区贡献149条内容

所有评论(0)