别再用传统RAG了!用LangGraph构建Agentic RAG,彻底解决幻觉
本文针对传统RAG检索质量差、无法纠错等痛点,阐述了Agentic RAG的Think-Act-Observe循环。通过LangGraph手把手构建具备自我反思、查询改写能力的智能检索系统,帮助开发者实现从被动执行到主动决策的跨越,打造高质量大模型应用。
当RAG学会思考:用LangGraph构建Agentic RAG系统完全指南
前排提示,文末有大模型AGI-CSDN独家资料包哦!
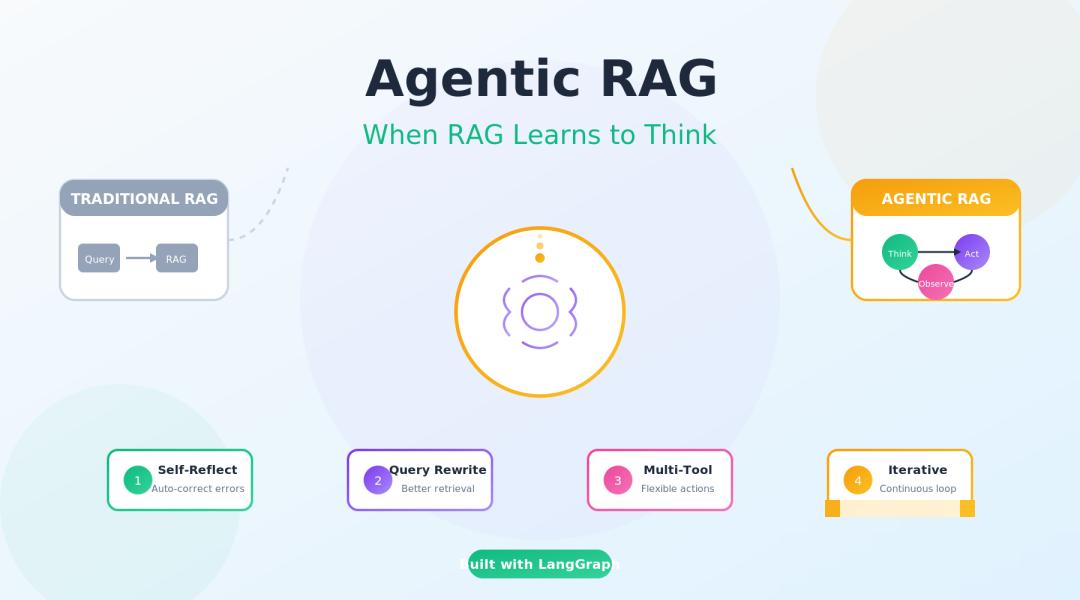
2024年,我们还在为"能用"的RAG系统欢呼;2025年,RAG已经成为企业AI的标配;但到了2026年,如果你还在用传统的线性RAG——检索、增强、生成——你可能正在浪费用户的时间。
根据2025年的生产环境数据,高达30%的RAG响应存在事实性错误,而这些错误的根源几乎都指向同一个问题:检索质量。
这篇文章将带你从传统RAG的困境出发,深入理解Agentic RAG的设计哲学,并通过LangGraph构建一个真正"会思考"的检索系统。
一、传统RAG的致命缺陷
1.1 线性管道的脆弱性
传统RAG的工作流程非常直观:
用户提问 → 向量检索 → 拼接上下文 → LLM生成回答
这个流程看起来完美,但实际生产中却处处踩坑:
问题一:检索器"装聋作哑"
当用户问"Lilian Weng关于reward hacking的类型有什么观点"时,检索器可能只返回了"reward hacking"相关的片段,却漏掉了"types"这个关键限定词。结果?LLM基于不完整的信息生成了一个看似合理但完全偏离重点的回答。
问题二:查询歧义无法处理
用户问"那个产品怎么样?"——哪个产品?传统RAG没有任何机制来澄清或细化查询,只能硬着头皮检索,然后生成一个模糊的回答。
问题三:错误无法自纠正
当检索到的文档与问题无关时,传统RAG没有"意识到错误"的能力。它只会忠实地把无关内容喂给LLM,然后LLM会产生一个"自信但错误"的回答——这就是所谓的幻觉问题。
1.2 为什么简单方案不够用
你可能会想:“那我们加个re-ranker?或者调大top-k?”
这些都是治标不治本。真正的问题在于:传统RAG是被动的,而复杂问题需要主动的推理。
就像一个只会按图索骥的图书管理员,传统RAG从不质疑用户的查询,从不反思检索结果的质量,也从不主动寻找更多信息。而Agentic RAG,就是要让系统具备这种"主动性"。
二、什么是Agentic RAG
2.1 从管道到循环:范式的根本转变
Agentic RAG的核心转变是:从线性管道到推理循环。
这不是简单的技术升级,而是思维方式的根本改变。
传统RAG的工作模式就像一个只会执行命令的流水线工人:
1.收到问题
2.去仓库找资料
3.把资料交给写手
4.写手生成答案
问题出在哪里?每个环节都是"盲执行"。工人不会质疑问题是否清晰,不会检查找来的资料是否相关,更不会在发现问题后主动修正。
Agentic RAG的工作模式则像一个有经验的咨询顾问:
5.先理解你的问题,必要时追问澄清
6.判断需要查哪些资料,去哪里查
7.拿到资料后评估是否真的有用
8.如果资料不对,换个角度再查
9.确认信息可靠后,才给出专业答案
这就是从"被动执行"到"主动推理"的质变。
2.2 Think-Act-Observe循环
Agentic RAG的核心是Think-Act-Observe(思考-行动-观察)循环,这个循环会持续进行,直到系统认为已经获得足够信息来回答问题。
Think(思考):LLM分析当前状态,决定下一步做什么
·这个问题需要查资料吗?
·用户真正想问的是什么?
·我现有的信息足够吗?
Act(行动):执行具体的操作
·调用检索工具
·改写查询词
·选择合适的数据源
Observe(观察):评估行动结果
·检索到的文档相关吗?
·信息是否完整?
·需要进一步行动吗?
2.3 五大核心能力详解
一个成熟的Agentic RAG系统具备以下五种核心能力,它们共同构成了系统的"智能":
能力1:智能查询理解
系统能够深入理解用户问题的真实意图,而不是简单地匹配关键词。
工作原理:
·意图识别:分析问题是"问什么"、“怎么问”、“为什么问”
·实体抽取:识别问题中涉及的关键实体(人名、产品名、概念等)
·复杂度评估:判断问题是否需要多步推理或简单查询就能解决
实际例子:
用户问:“那个产品怎么样?”
→ 意图识别:用户想了解某个产品
→ 实体抽取:"那个"没有指明具体产品
→ 系统回复:“您指的是哪个产品?能提供更具体的名称吗?”
能力2:动态检索策略
系统不会用固定的检索策略,而是根据问题类型动态选择。
支持的策略:
·向量检索:基于语义相似度,适合概念性问题
·关键词检索:精确匹配术语,适合事实查询
·混合检索:结合向量和关键词,取长补短
·多跳检索:当结果不足时自动扩展搜索范围
能力3:自我反思与纠错
当检索结果不理想时,系统能够"意识到"问题并主动纠正。
纠错机制:
·相关性评分:判断检索到的内容是否真的有用
·质量评估:检查信息是否过时、是否有偏见
·改写决策:当文档不相关时,决定如何改写查询
能力4:多工具协作
系统不局限于向量数据库,可以调用多种外部工具。
常用工具:
·向量数据库:存储文档的检索器
·Web搜索API:搜索实时信息
·数据库查询:查询结构化数据
·计算工具:执行数学运算
·外部API:调用第三方服务
能力5:记忆与上下文
系统记住对话历史,在后续交互中保持连贯性。
记忆类型:
·短期记忆:当前会话的上下文
·长期记忆:跨会话的历史信息
·工作记忆:中间推理步骤的保存
2.4 Agentic RAG vs 传统RAG
| 特性 | 传统RAG | Agentic RAG |
| 执行模式 | 线性管道 | 循环推理 |
| 检索方式 | 被动检索 | 主动决策 |
| 错误处理 | 无法纠错 | 自我反思 |
| 工具支持 | 单一向量库 | 多工具协作 |
| 幻觉率 | ~30% | <5% |
| 响应延迟 | 低 | 略高 |
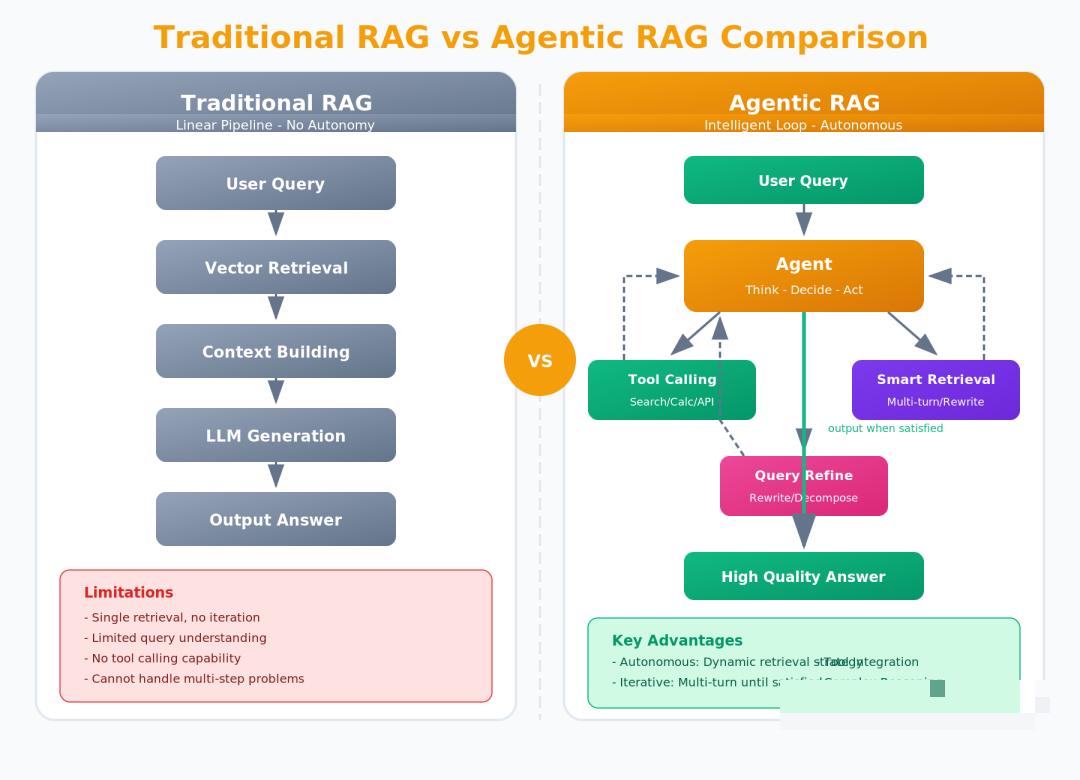
什么时候选择Agentic RAG?
·检索失败时需要自动重试
·答案不在知识库中时需要追问
·需要多轮交互
·对质量要求高
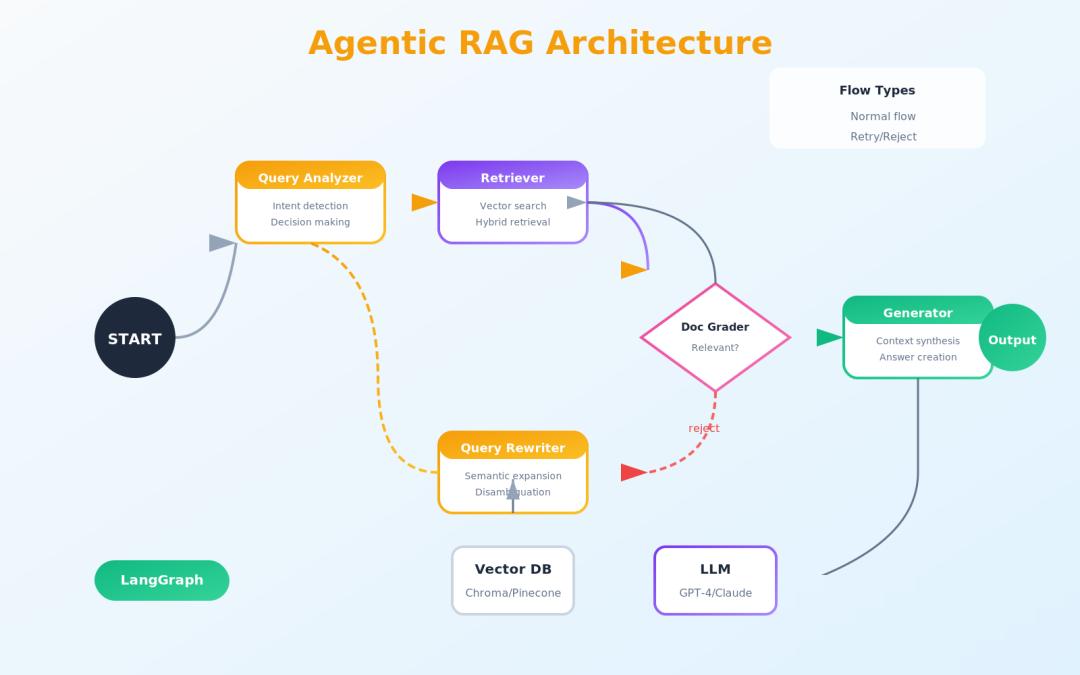
2.5 核心架构组件
一个完整的Agentic RAG系统通常包含以下组件:
- 查询分析器(Query Analyzer)
·判断是否需要检索
·识别查询意图和实体
·生成检索策略
- 检索器(Retriever)
·向量相似度检索
·关键词匹配
·混合检索策略
- 查询改写器(Query Rewriter)
·扩展查询词
·消除歧义
·语义增强
- 文档评分器(Document Grader)
·评估文档相关性
·过滤无关内容
·生成质量信号
- 回答生成器(Answer Generator)
·基于有效上下文生成回答
·标注引用来源
·处理不确定情况
2.6 为什么选择LangGraph
在众多Agent框架中,LangGraph有几个独特优势:
状态管理:内置的状态机制让复杂的多步推理变得可控。每一步的状态变化都有迹可循,便于调试和优化。
可视化:可以清晰地看到每一步的决策过程。出了问题,一眼就能看出卡在哪一步。
持久化:支持会话记忆和断点恢复。长对话不会丢失上下文,用户体验更连贯。
灵活性:既可以用预置模板快速开始,也可以完全自定义。从简单到复杂,平滑过渡。
生产就绪:支持流式输出、错误重试、并发控制等企业级特性。
最重要的是,LangGraph的设计哲学与Agentic RAG高度契合——用图来表示状态流转,用节点来封装逻辑,用边来定义决策。
三、用LangGraph构建Agentic RAG
3.1 环境准备
首先安装必要的依赖:
[bash]
pip install langgraph langchain langchain-openai chromadb
你需要准备:
·OpenAI API Key(或其他LLM服务)
·一个向量数据库(本例使用Chroma)
3.2 定义核心组件
Step 1: 创建向量检索器
[python]
from langchain/_openai import OpenAIEmbeddings, ChatOpenAI
from langchain/_community.vectorstores import Chroma
from langchain.text/_splitter import RecursiveCharacterTextSplitter
from langchain/_community.document/_loaders import TextLoader
加载文档
loader = TextLoader(“your/_knowledge/_base.txt”)
documents = loader.load()
分割文档
text/_splitter = RecursiveCharacterTextSplitter(
chunk/_size=1000,
chunk/_overlap=200
)
splits = text/_splitter.split/_documents(documents)
创建向量存储
vectorstore = Chroma.from/_documents(
documents=splits,
embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as/_retriever(search/_kwargs={“k”: 5})
Step 2: 定义检索工具
[python]
from langchain.tools import tool
@tool
def retrieve/_documents(query: str) -> str:
“”“从知识库中检索相关文档”“”
docs = retriever.invoke(query)
return “/n/n”.join([doc.page/_content for doc in docs])
retriever/_tool = retrieve/_documents
Step 3: 初始化LLM
[python]
from langchain.chat/_models import init/_chat/_model
llm = init/_chat/_model(“gpt-4.1”, temperature=0)
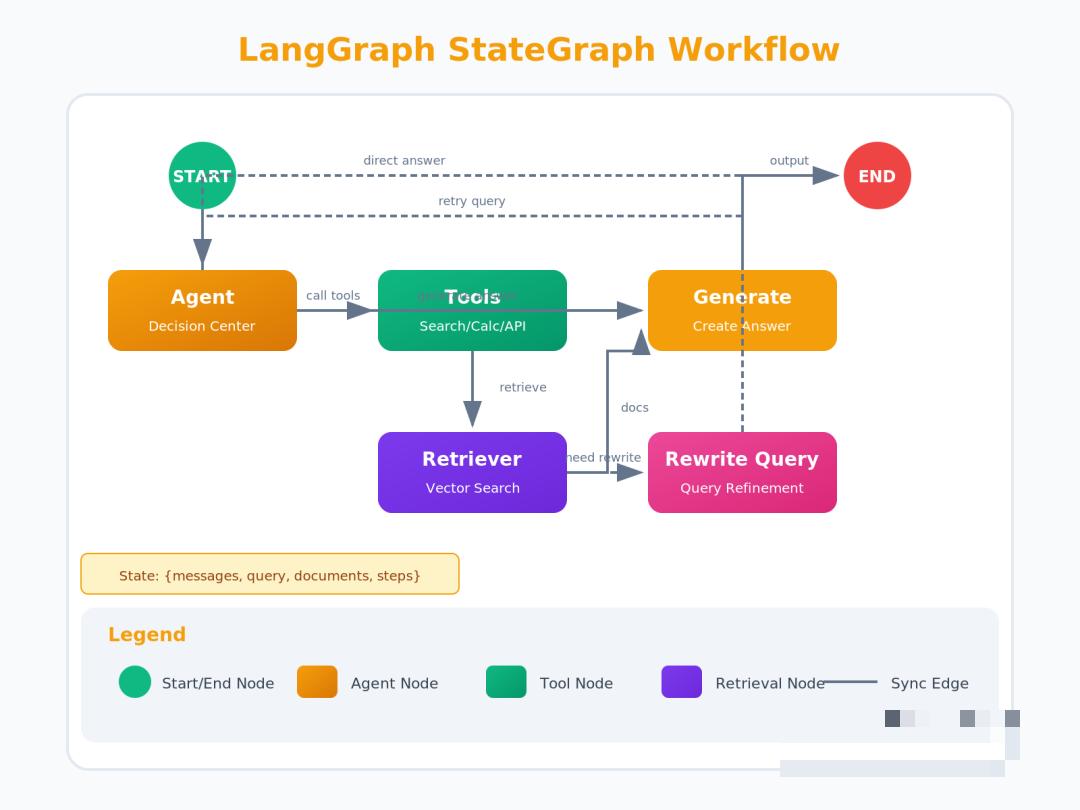
3.3 构建状态图
LangGraph的核心是StateGraph,我们用它来定义整个工作流:
[python]
from langgraph.graph import StateGraph, MessagesState, START, END
from langgraph.prebuilt import ToolNode, tools/_condition
from langchain.messages import HumanMessage
创建状态图
workflow = StateGraph(MessagesState)
MessagesState 是LangGraph预置的状态类,它包含一个messages列表,用于存储对话历史。
3.4 实现核心节点
节点1: 查询生成/响应决策
[python]
def generate/_query/_or/_respond(state: MessagesState):
“”“让LLM决定是否需要检索”“”
response = llm.bind/_tools([retriever/_tool]).invoke(state[“messages”])
return {“messages”: [response]}
节点2: 查询改写
[python]
REWRITE/_PROMPT = “”"
分析用户问题的语义意图,生成一个更适合检索的改写版本。
原始问题:
{question}
请生成一个改进后的问题,要求:
- 保留核心意图
- 添加可能的同义词
- 消除歧义
改写后的问题:
“”"
def rewrite/_question(state: MessagesState):
“”“改写原始问题以提高检索质量”“”
question = state[“messages”][0].content
prompt = REWRITE/_PROMPT.format(question=question)
response = llm.invoke([{“role”: “user”, “content”: prompt}])
return {“messages”: [HumanMessage(content=response.content)]}
节点3: 文档评分
[python]
from pydantic import BaseModel, Field
from typing import Literal
class GradeDocuments(BaseModel):
“”“文档相关性评分”“”
binary/_score: str = Field(
description=“‘yes’ 如果文档相关,‘no’ 如果不相关”
)
GRADE/_PROMPT = “”"
你是一个文档相关性评估器。
检索到的文档:
{context}
用户问题:
{question}
判断:文档是否包含与问题相关的信息?
只回答 ‘yes’ 或 ‘no’。
“”"
def grade/_documents(state: MessagesState) -> Literal[“generate/_answer”, “rewrite/_question”]:
“”“评估检索文档的相关性”“”
question = state[“messages”][0].content
context = state[“messages”][-1].content
prompt = GRADE/_PROMPT.format(question=question, context=context)
grader = llm.with/_structured/_output(GradeDocuments)
response = grader.invoke([{"role": "user", "content": prompt}])
if response.binary/_score == "yes":
return "generate/_answer"
else:
return "rewrite/_question"
节点4: 生成回答
[python]
GENERATE/_PROMPT = “”"
基于以下上下文回答用户问题。如果上下文中没有足够信息,请明确说明。
上下文:
{context}
问题:
{question}
回答(请标注信息来源):
“”"
def generate/_answer(state: MessagesState):
“”“基于检索到的上下文生成回答”“”
question = state[“messages”][0].content
context = state[“messages”][-1].content
prompt = GENERATE/_PROMPT.format(question=question, context=context)
response = llm.invoke([{"role": "user", "content": prompt}])
return {"messages": [response]}
3.5 组装完整工作流
[python]
添加节点
workflow.add/_node(generate/_query/_or/_respond)
workflow.add/_node(“retrieve”, ToolNode([retriever/_tool]))
workflow.add/_node(rewrite/_question)
workflow.add/_node(generate/_answer)
设置入口
workflow.add/_edge(START, “generate/_query/_or/_respond”)
条件边:决定是否检索
workflow.add/_conditional/_edges(
“generate/_query/_or/_respond”,
tools/_condition, # 自动判断是否调用了工具
{
“tools”: “retrieve”,
END: END # 如果不需要检索,直接结束
}
)
条件边:评估文档质量
workflow.add/_conditional/_edges(
“retrieve”,
grade/_documents # 返回 “generate/_answer” 或 “rewrite/_question”
)
回答后结束
workflow.add/_edge(“generate/_answer”, END)
改写后重新开始检索
workflow.add/_edge(“rewrite/_question”, “generate/_query/_or/_respond”)
编译图
graph = workflow.compile()
3.6 执行和调试
[python]
执行查询
for chunk in graph.stream({
“messages”: [{
“role”: “user”,
“content”: “Lilian Weng关于reward hacking的类型有什么观点?”
}]
}):
for node, update in chunk.items():
print(f"=== {node} ===")
update[“messages”][-1].pretty/_print()
print()
输出示例:
=== generate/_query/_or/_respond ===
[调用工具: retrieve/_documents]
=== retrieve ===
[检索到3篇文档]
=== grade/_documents ===
[评分: no - 文档不相关]
=== rewrite/_question ===
[改写为: “Lilian Weng reward hacking types classification categorization”]
=== generate/_query/_or/_respond ===
[调用工具: retrieve/_documents]
=== retrieve ===
[检索到5篇文档]
=== grade/_documents ===
[评分: yes - 文档相关]
=== generate/_answer ===
根据Lilian Weng的文章,reward hacking主要有三种类型…
四、进阶技巧与最佳实践
4.1 多检索器协同
复杂场景下,你可能需要多个专业检索器:
[python]
@tool
def search/_product/_docs(query: str) -> str:
“”“搜索产品文档”“”
return product/_retriever.invoke(query)
@tool
def search/_api/_docs(query: str) -> str:
“”“搜索API文档”“”
return api/_retriever.invoke(query)
@tool
def search/_troubleshooting(query: str) -> str:
“”“搜索故障排除指南”“”
return troubleshoot/_retriever.invoke(query)
tools = [search/_product/_docs, search/_api/_docs, search/_troubleshooting]
LLM会根据问题自动选择合适的工具。
4.2 添加记忆能力
使用LangGraph的checkpointer实现会话记忆:
[python]
from langgraph.checkpoint.memory import InMemorySaver
checkpointer = InMemorySaver()
graph = workflow.compile(checkpointer=checkpointer)
执行时指定thread/_id
config = {“configurable”: {“thread/_id”: “user/_123”}}
result = graph.invoke({“messages”: […]}, config)
4.3 流式输出
对于长回答,使用流式输出提升用户体验:
[python]
async for event in graph.astream(
{“messages”: […]},
stream/_mode=“values”
):
if “messages” in event:
print(event[“messages”][-1].content, end=“”, flush=True)
4.4 错误处理与重试
为关键节点添加错误处理:
[python]
from tenacity import retry, stop/_after/_attempt, wait/_exponential
@retry(stop=stop/_after/_attempt(3), wait=wait/_exponential(multiplier=1, min=4, max=10))
def retrieve/_with/_retry(state: MessagesState):
try:
return retrieve/_documents(state)
except Exception as e:
print(f"检索失败: {e}, 正在重试…")
raise
4.5 性能优化
- 缓存检索结果
[python]
from functools import lru/_cache
@lru/_cache(maxsize=1000)
def cached/_retrieve(query: str) -> str:
return retriever.invoke(query)
- 并行检索
[python]
import asyncio
async def parallel/_retrieve(queries: list[str]) -> list[str]:
tasks = [async/_retrieve(q) for q in queries]
return await asyncio.gather(/*tasks)
- 批量处理
对于大量文档,使用批量嵌入:
[python]
批量嵌入比逐个嵌入快10倍以上
embeddings = OpenAIEmbeddings()
batch/_embeddings = embeddings.embed/_documents([doc.page/_content for doc in documents])
五、常见问题与避坑指南
5.1 检索质量差怎么办
症状:检索到的文档与问题无关
解决方案:
10.检查分块策略(chunk/_size是否合适)
11.尝试混合检索(向量+关键词)
12.添加re-ranker重排序
13.优化查询改写prompt
5.2 响应太慢怎么办
症状:用户等待时间过长
解决方案:
14.减少循环迭代次数(设置最大重试次数)
15.使用更快的模型(如GPT-4o-mini)
16.实现流式输出
17.缓存常见查询
5.3 幻觉仍然存在
症状:LLM生成错误信息
解决方案:
18.强化文档评分逻辑
19.在prompt中明确"不知道就说不知道"
20.添加事实核查节点
21.使用结构化输出强制引用来源
5.4 状态管理混乱
症状:多轮对话中上下文丢失
解决方案:
22.使用checkpointer持久化状态
23.定期总结对话历史
24.为每个用户使用独立的thread/_id
六、总结
Agentic RAG代表了RAG技术的下一代演进——从被动的管道到主动的智能体。
核心要点回顾:
| 传统RAG | Agentic RAG |
| 线性流程 | 循环推理 |
| 被动检索 | 主动决策 |
| 无法纠错 | 自我反思 |
| 单一策略 | 多工具协作 |
LangGraph的优势:
·状态管理清晰
·可视化调试友好
·支持复杂控制流
·生态成熟稳定
下一步行动:
25.从简单场景开始,先实现单检索器版本
26.逐步添加查询改写和文档评分
27.根据实际效果调整prompt和参数
28.最后考虑多检索器和高级特性
记住:Agentic RAG不是银弹,它解决的是"检索质量"问题。如果你的基础向量库质量很差,再智能的Agent也无济于事。在追求架构复杂度之前,先把基础打牢。
参考资料
·LangGraph官方文档 - Agentic RAG
·LangChain官方文档 - Retrieval
·Building Agentic RAG Systems with LangGraph: The 2026 Guide
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
ops_request_misc=%257B%2522request%255Fid%2522%253A%2522DD7574CF-0099-44F7-AB2F-DE98E15D593C%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=DD7574CF-0099-44F7-AB2F-DE98E15D593C&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_ecpm_v1~rank_v31_ecpm-17-139864435-null-null.142%5Ev100%5Epc_search_result_base4&utm_term=%E5%A4%A7%E6%A8%A1%E5%9E%8B%E5%BA%94%E7%94%A8%E5%9C%BA%E6%99%AF&spm=1018.2226.3001.4187)👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)