Nature子刊重磅:材料学大模型LLaMat入门教程(非常详细),从400万论文到科研Copilot,收藏这一篇就够了!
1. 为什么材料科学需要“专属 LLM”,而不是直接用通用大模型?
材料科学的核心矛盾之一,是“知识增长速度”远快于人类的阅读、筛选与整合速度。论文指出:通用大模型虽然强,但在材料领域常常会在关键点“掉链子”,比如对物理规律/理论的科学解释、专业术语、晶体结构等任务上出错。 因此,要做一个真正能落地的材料科研 Copilot,必须进行领域自适应(domain adaptation),让模型在材料语料、符号体系、数据结构上“二次生长”。

2. 论文做了什么:LLaMat 的目标与核心贡献
作者提出 LLaMat(Large Language Model for Materials):一个面向材料科研全流程的领域基础模型家族。它通过三段式训练,把通用 LLaMA 模型改造成材料学“专科医生”:
- continued pretraining(继续预训练):用材料领域大语料把底座“浸透”
- instruction fine-tuning(指令微调):把它训练成能对话、能问答、能遵循任务指令的助手
- task fine-tuning(任务微调):用下游任务做最后的能力对齐
论文强调:LLaMat 在42 项任务的综合评测中,稳定超过 Claude/GPT/Gemini 等商用模型,同时保持一般语言能力。
3. 读懂全局:LLaMat 的训练管线与数据配方
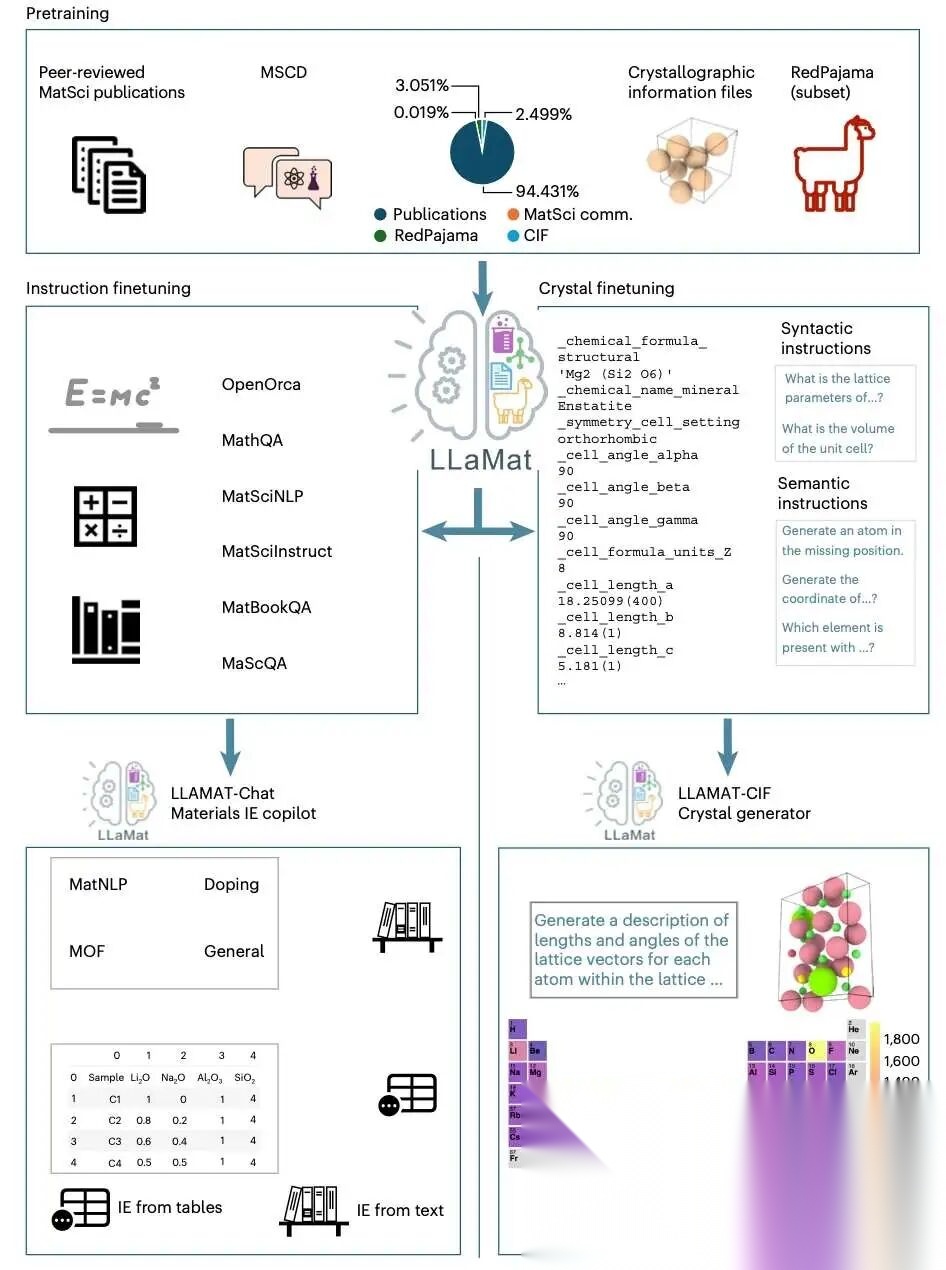
图 1(原文 Fig. 1):三阶段训练 + 两条能力分支
图 1 是整篇论文的“总路线图”:先继续预训练,再走两条微调分支——一个做材料文本与信息抽取(LLaMat-Chat),一个做晶体结构理解与生成(LLaMat-CIF)。
3.1 继续预训练语料 R2CID:30B tokens 的材料世界
作者构建了 R2CID 语料库(>30B tokens),核心由三部分组成:
- 同行评审材料论文 94.43%(约 400 万篇)
- CIF 晶体学文件约 2.5%
- RedPajama 子集约 3.051%(防止“忘英语”)
- 材料社区讨论 MSCD 0.019%
这些比例在图 1 的饼图里一眼可见。
同时,正文进一步说明:语料包含约 400 万篇同行评审论文,并明确给出 CIF 与 MSCD 的占比。
3.2 为什么要掺 RedPajama:对抗“灾难性遗忘”
作者非常明确:如果只喂材料语料,模型会牺牲通用语言能力,所以要战略性加入通用语料子集来“保底”。
3.3 CIF 数据的规模与来源:不仅“有晶体”,还“懂晶体”
在方法部分,作者给出 CIF 数据的关键细节:数据集中包含 470,000 个 CIF 文件,并用 RoboCrystallographer 生成自然语言描述;CIF 来自 Materials Project、GNoME 计算构型与 AMCSD 等来源。
4. LLaMat-Chat:让模型能“读论文、抽信息、做材料 NLP”
作者把材料科研 Copilot 的语言能力拆成两大板块评测:
- MatNLP:材料自然语言处理(理解与推理)
- MatSIE:材料结构化信息抽取(从文本/表格抽成机器可用的结构)
4.1 MatNLP:14 个任务、14,579 个测试样本
论文说明 MatNLP 基准由材料任务与一般英语任务共同构成,总计 14,579 个测试实例,用于检验模型既能“懂材料”,也不至于变成“材料土话模型”。
5. 为什么说它“打赢”了商用 LLM?
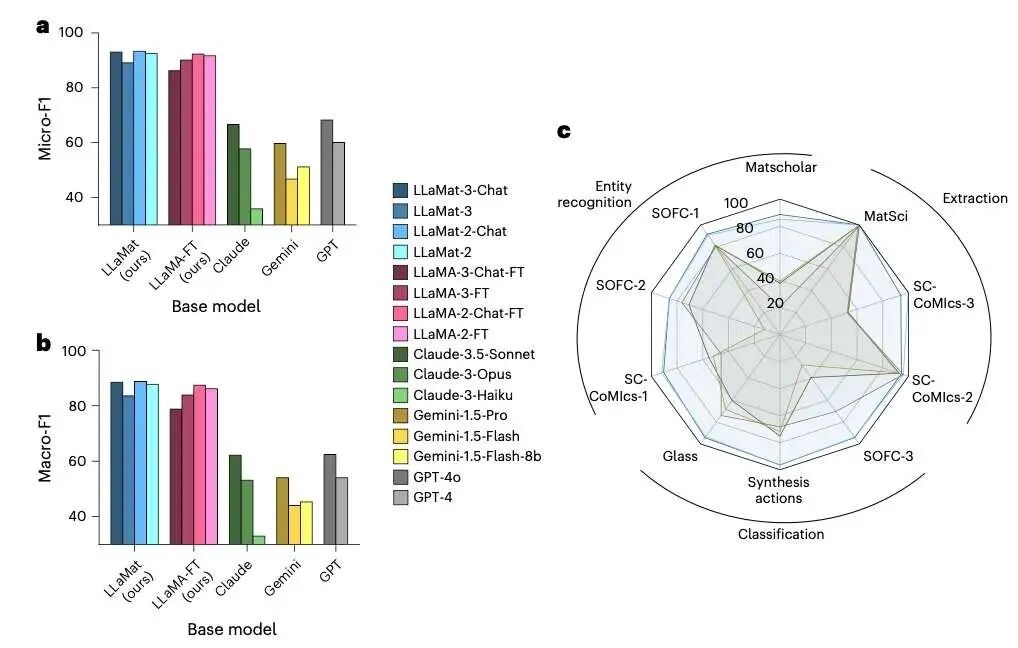
图 2:Micro-F1 / Macro-F1 与雷达图
图 2 的信息量很大,建议公众号排版时把图 2a/2b(柱状)和 2c(雷达)分两张放。
- 图 2a/2b:在 MatNLP 的 micro-F1 与 macro-F1 上,LLaMat 整体优于基座模型与商用 LLM。
- 作者特别强调:评测温度设为 0,保证输出确定性(避免“抽卡式评测”)。
- 图 2c(雷达图):细看各子任务,LLaMat-3-Chat 最强,LLaMat-2-Chat 次之;Claude-3.5-Sonnet、Gemini-1.5-Pro、GPT-4o 在材料任务上整体落后。
如何理解这张图的“科研意义”?
材料科研里,真正花时间的往往不是“模型推理”,而是“读文献→提取关键信息→结构化整理”。图 2 的胜利,本质是:LLaMat 在材料语境下的实体识别、关系抽取、分类等能力更稳定,因而更适合做“自动化读论文”的底座。
6. 从文本与表格抽取结构化知识,才是材料 Copilot 的硬骨头
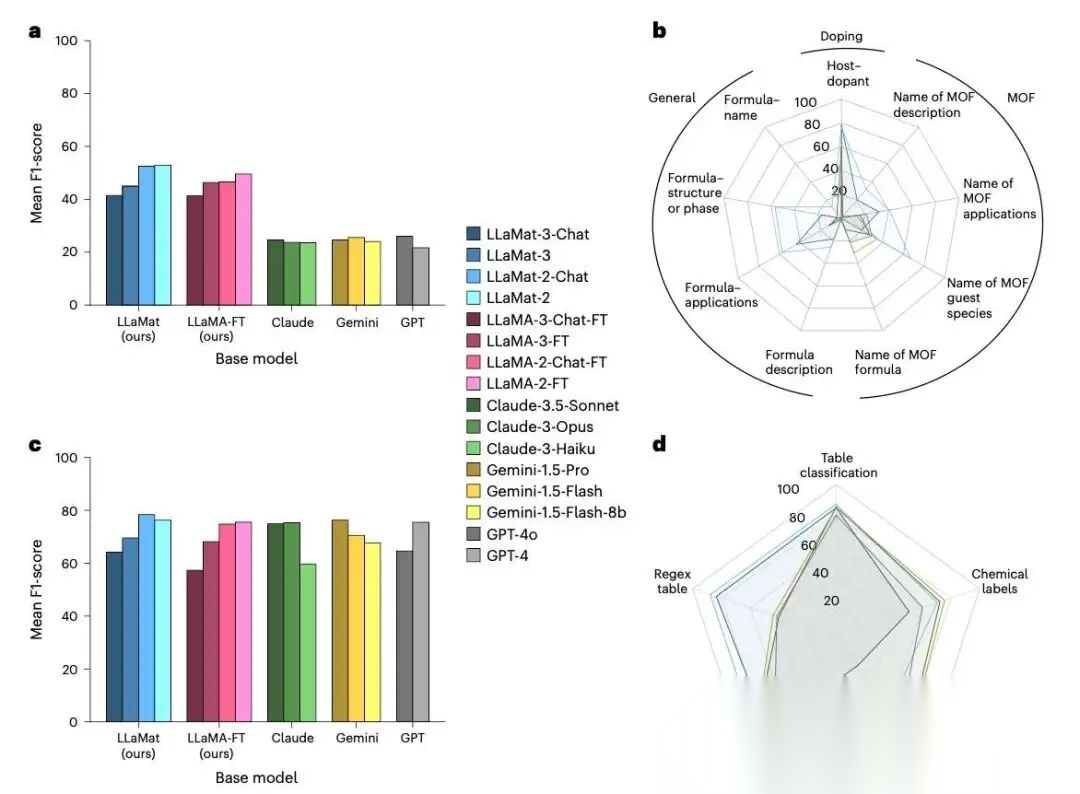
图 3:MatSIE 信息抽取(文本 + 表格)
图 3覆盖了材料信息抽取的三类典型场景:掺杂体系(doping)、MOF、通用材料域,以及对材料表格的抽取。
- 论文指出:LLaMat-Chat 在关键材料信息抽取任务上,显著优于对照模型(包括商用 LLM),尤其在 host–dopant、formula–structure、应用信息等关系抽取上表现突出。
- 作者还观察到:LLaMat-2-Chat 在需要深材料知识的任务(如 formula–application、host–dopant)上尤其强,并把它与后文的“适配刚性”现象联系起来。
6.1 表格抽取:737 张表的“地狱模式”
材料论文的表格极其多样:有的按成分,有的按处理工艺,有的混着脚注、符号、缩写、上下标。作者用 737 张同行评审论文表格做评测,考察 5 种能力:表格分类、化学组分定位、成分抽取、材料 ID 识别、regex 可抽取信息识别。
结果上,LLaMat-2-Chat 在表格任务总体略优于商用模型,但作者也很诚实地指出:优势主要来自对 regex tables(材料领域特有的“符号/记号表格”)的强适配;在一些更通用的表格结构理解上,商用 LLM 有时能持平或略强。
7. 全文最“反直觉”的发现:适配刚性(Adaptation Rigidity)
如果你只看结果,很容易得出一个“老套结论”——“多预训练、多参数、更强”。但这篇论文最重要的科学点恰恰相反:
更“过度预训练”的模型,可能更难被继续预训练/微调成领域专家。
作者把这种现象命名为 adaptation rigidity(适配刚性):即像 LLaMA-3 这种在海量通用语料上训练得非常充分的模型,形成了很强的通用语言先验,导致它对材料领域继续预训练与微调的“可塑性”下降。
表 1:同样微调,LLaMA-2 的提升幅度远大于 LLaMA-3

这张表是“适配刚性”的定量证据核心:
- MatNLP 的 Macro-F1:LLaMA-2 从 12.36 提升到 87.398(+607.10%),而 LLaMA-3 从 32.287 到 78.775(+143.98%)。
- Micro-F1 也呈现类似趋势(+522.48% vs +136.30%)。 更“扎心”的是:这种规律在材料任务上很强,但在 SQuAD、HellaSwag 等通用任务上却可能反过来——LLaMA-3 微调后仍保持通用优势。作者用这一点强化了“领域依赖的适配行为”。
机制线索:可解释性分析给出的图景
论文进一步提到:用 attribution 方法做可解释性分析,LLaMat-2 学到的是更“聚焦”的领域 token 关联,而 LLaMat-3 的关联更分散、更均匀,这与“难以被定向专门化”的假设一致。
8. LLaMat-CIF:当大模型开始“写晶体结构”
这部分是整篇论文最“未来感”的内容:不仅理解材料文本,还要生成可解析的晶体结构文件(CIF)。
8.1 CIF 指令数据:约 700 万条“语法+语义”任务
作者为晶体生成构建了 dual-task 框架:
- 语法类任务(syntactic):比如原子频次统计、坐标识别、晶胞参数计算、化学式推导等
- 语义类任务(semantic):比如与稳定性相关的生成、MASK 位置预测、为稳定性预测结构维度、元素约束生成等
这套框架共产生约 700 万 instruction–output pairs(6,941,865 训练、27,183 验证),并列出具体任务清单。
8.2 无条件生成:模型“从零写 CIF”
论文给了无条件生成的提示词:让模型输出晶格矢量长度/夹角,再给出每个原子的元素与坐标,本质上是在考验模型是否能自洽地写出一个结构。
表 2:无条件生成的结构质量差异巨大

作者对每个模型生成 10,000 个结构,并用有效性、唯一性、新颖性、能量与稳定性等指标评估。核心结论:
- LLaMat-2-CIF:有效性 76.77%,唯一性 89.93%,新颖性 58.29%;更关键的是 stable 结构 214 个、SUN(stable+unique+novel)为 128
- LLaMat-3-CIF:有效性仅 13.18%,stable 16 个、SUN 11
这些数字在正文中写得非常明确。 此外,生成效率也差很多:LLaMat-2-CIF 约 13,000 次尝试得到 10,000 个有效结构;LLaMat-3-CIF 需要约 33,000 次(约 2.5× 差距)。
注意:作者也强调这更多是 proof-of-concept,重点证明“LLM 能生成可解析 CIF”,而不把它包装成“最强晶体生成模型”。
8.3 条件生成:给定成分与空间群,做“逆向设计”
条件生成才是真正的“材料设计入口”。作者在 9,046 个测试结构上评估:给定目标成分与空间群,模型生成对应结构。
最震撼的结论:
- LLaMat-2-CIF 总体成分匹配 79.1%,可解析输出(extraction success)90.8%
- LLaMat-3-CIF 成分匹配仅 **5.5%**,可解析输出 69.2%
差距高达 73.6 个百分点。 表 3(原文 Table 3)进一步把匹配率按元素数、晶系分层,能看到 LLaMat-2-CIF 在三元体系占比最高(58.9%)的子集上依然维持 ~80% 匹配,而 LLaMat-3-CIF 仍在个位数。
9. 讨论与落地:这项工作到底改变了什么?
论文在讨论部分给了一个很实用的观点:在材料任务上,经过领域自适应的中等规模开源模型,可以在很多关键任务上超过更大、更贵的商用模型;这对“要规模化处理数百万篇论文”的现实场景尤其关键。
此外,作者强调 LLaMat-CIF 的条件生成能力是“逆向设计”的雏形:从目标成分/空间群出发生成结构,未来可以扩展到按性质约束生成。
他们还提到模型的交互与 agentic 应用潜力,例如提供交互式 dashboard,帮助研究者比较模型输出,并能在真实研究链路中扮演“材料知识代理”。
10. 个人解读
材料 Copilot 的关键,不是“会聊天”,而是“能结构化”。
图 2、图 3 的胜利点非常清晰:材料科研的瓶颈在信息抽取与结构化整理。只要能把“论文里的材料配方—工艺—结构—性质”抽成 schema,就等于把海量文献变成可计算资产(可做知识图谱、可做数据驱动建模、可做自动假设生成)。
大模型不是越大越好,至少在“继续预训练/再专门化”这件事上未必。
“适配刚性”是很可能影响整个科学大模型路线选择的发现:如果一个模型在通用语料上被训练到非常“圆滑”,它可能更难在某个窄域里长出尖锐的、可用的专业能力。这会逼着我们重新思考:
- 领域模型到底该从哪个 base 出发?
- continued pretraining 的配比、阶段、学习率策略如何设计?
- 是否需要“模块化可塑性”(例如可替换/可生长的专家模块)来对抗刚性?
把 CIF 这种“严肃格式”交给 LLM,是通往材料逆向设计工作流的一扇门。
即便作者说这是 proof-of-concept,我依然认为意义很大:一旦 LLM 能稳定地产生可解析结构,并能与能量模型、结构弛豫、DFT/MLP 验证闭环,那么“文本模型—结构空间—性质预测—实验规划”的整合将变得更自然。未来真正重要的不是“能不能生成 CIF”,而是:
- 能否在生成时内置物理约束(电中性、配位偏好、局域几何合理性)?
- 能否与检索(Materials Project/文献)联动,做“有证据的生成”?
- 能否把生成结构直接接入合成路线推断与可合成性评估?
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献166条内容
已为社区贡献166条内容

所有评论(0)