腾讯版「龙虾」Workbuddy上线当天,我用它搭了一套行业情报日报系统
写在前面
最近 AI 圈最火的词大概是「龙虾」。
OpenClaw 掀起了一波桌面 AI Agent 的热潮——不再是聊天窗口里你一句我一句的问答,而是让 AI 直接在你的电脑上干活:操作文件、执行脚本、联网搜索、交付结果。
3 月 9 日,腾讯发布了 WorkBuddy,被称为「腾讯版龙虾」。完全兼容 OpenClaw 的 Skills 技能体系,但有一个关键差异:不需要自己买服务器部署,不需要自己购买 API token,安装即用。 如果你用企微,1 分钟就能连上,手机发条消息就能远程让它在办公电脑上干活。
当晚我就下载试了。
不是因为想写评测,而是因为我手上正好有一个真实需求:我需要一套系统,每天自动帮我搜集全球数据平台行业的最新动态,整理成一份结构化的情报简报,推送到企微群。
这个需求我已经用手动方式做了很久——每天花 30-40 分钟刷 Twitter、LinkedIn、各厂商博客和分析师报告,再整理成笔记分享。
WorkBuddy 上线当天,我决定试试看:用桌面 AI Agent 能不能把这件事自动化。
结果是:1 小时跑通了第一个可用版本,1 天反复优化,3 天后稳定运行。
这篇文章完整记录整个搭建过程——怎么设计、怎么实现、踩了哪些坑、怎么解的。如果你也想用 AI Agent 搭一套自己行业的信息自动化系统,这篇可以当一个实操参考。
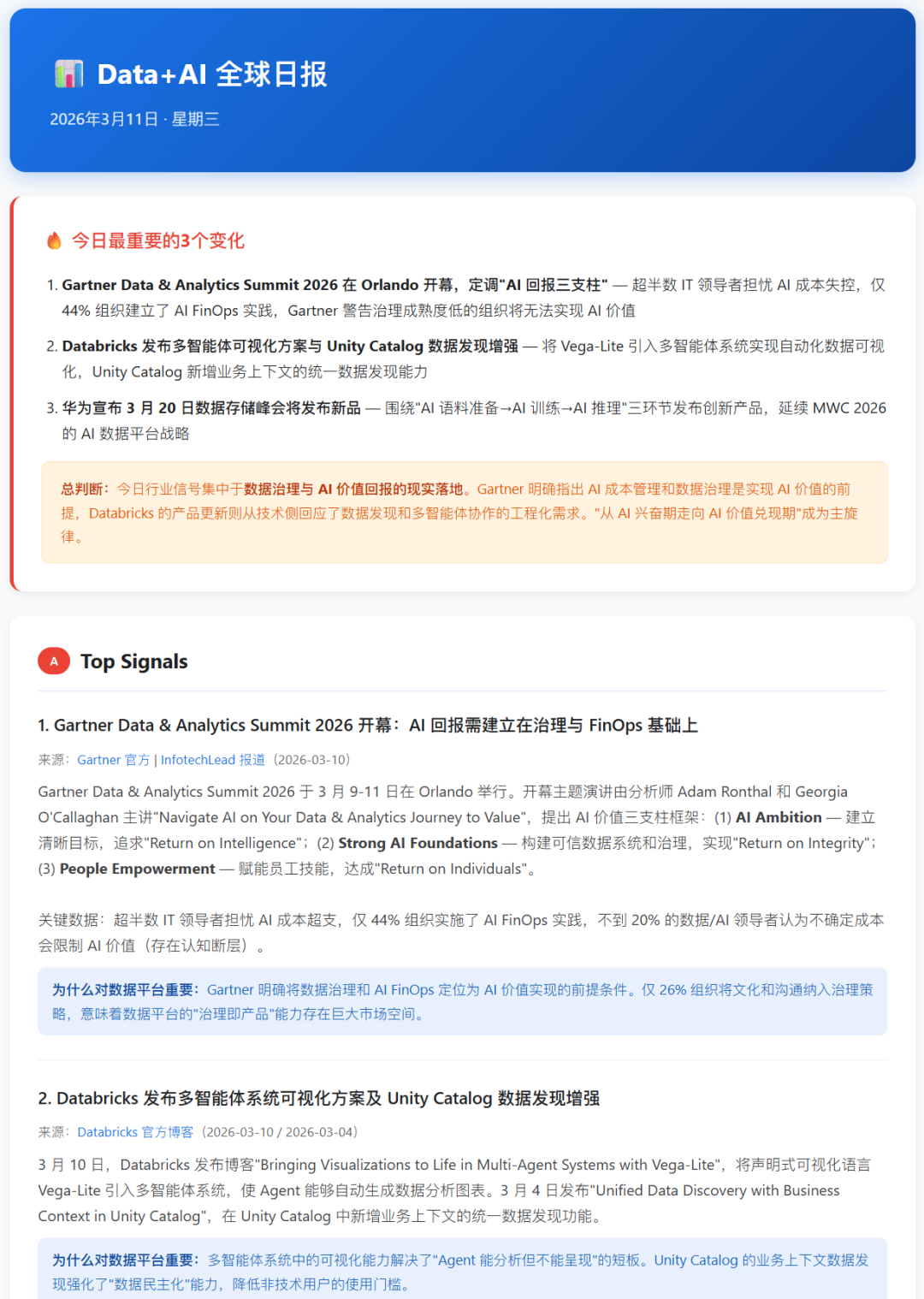
一、先看效果:这份日报长什么样
在讲怎么做之前,先看产出物。
每天早上 8 点,一份《Data+AI 全球日报》准时出现在我们的企微群里,覆盖全球 10+ 大数据平台厂商、5 个板块、8-12 条高质量情报。
推送方式
推送分两步:
-
先发一条精简摘要(Markdown 格式,控制在 4096 字节内),在企微内直接可读
-
再发一份 HTML 完整版,打开后是一份带精美排版、可点击来源链接的完整报告
💡 为什么分两步?企微 Webhook 单条消息限制 4096 字节(注意是字节,一个中文 3 字节),但完整日报通常 8000+ 字符。这个限制在 Day 1 就把我教做人了,后面会讲。
内容结构
每份日报严格按 5 个板块组织:
|
板块 |
内容 |
示例 |
|---|---|---|
| A. Top Signals |
当天最重大的 3 条行业动态 + 影响分析 |
Gartner 峰会定调 AI FinOps |
| B. Product & Tech |
4-6 条产品/技术更新,只取一手信源 |
Databricks Asset Bundles GA |
| C. People & Views |
关键人物的原始发言 |
Snowflake CEO 谈 AI Agent 战略 |
| D. Analyst Insights |
Gartner/Forrester/IDC 研报核心数据 |
44% 组织缺乏 AI FinOps |
| E. Watchlist |
值得持续跟踪但尚未定论的信号 |
GTC 2026 推理加速 |
每条信息都标注了一手信源链接。

公开版
除了企微群,每期日报同时部署到 GitHub Pages:
🔗 https://haiyangchenbj.github.io/data-ai-daily/
HTML 版本有蓝色渐变头部、卡片式板块布局和可点击的来源超链接,阅读体验比企微内的 Markdown 好得多。
二、为什么选 WorkBuddy
搭这套系统,需要 AI 工具同时具备三个能力。我来拆解一下选型逻辑,也顺便说说 WorkBuddy 作为「腾讯版龙虾」和 OpenClaw 的异同。
能力 1:联网搜索 + 结构化输出
日报的本质是信息搜集和整理。AI 必须能实时联网搜索,而不是只靠训练数据回答问题。每次生成日报,WorkBuddy 会执行 10+ 次搜索——中英文双语,覆盖厂商官方博客、GitHub 仓库、分析师报告等信源——然后按我定义的模板结构化输出。
能力 2:本地文件操作
整个系统涉及大量文件操作:读取 JSON 配置文件、生成 MD 和 HTML 两种格式的日报、调用 Python 脚本推送。这要求 AI 能直接操作本地文件系统。WorkBuddy 作为桌面智能体,可以读取授权文件夹、生成文件、执行脚本。
能力 3:多步骤任务链
"生成今日日报"是一句话,但实际包含 5 个步骤:读取配置 → 联网搜索 → 生成内容 → 推送企微 → 部署 GitHub Pages。WorkBuddy 可以自主拆解和执行这个任务链。
和 OpenClaw 的关系
WorkBuddy 完全兼容 OpenClaw 的 Skills 技能体系。如果你之前给 OpenClaw 写过 Skill,可以直接导入使用。不同的是:
-
部署门槛:OpenClaw 需要自建服务器或购买 API token;WorkBuddy 安装即用,免费额度覆盖日常使用
-
企业连接:WorkBuddy 原生支持企微、飞书、钉钉,1 分钟连上
-
模型切换:国内版支持混元、DeepSeek、Kimi 等模型无缝切换, 国外版基本上主流模型都在。
对于我的场景来说,"安装即用 + 企微原生连接"是决定性的。我不想为一个每天跑一次的日报系统维护一台服务器。
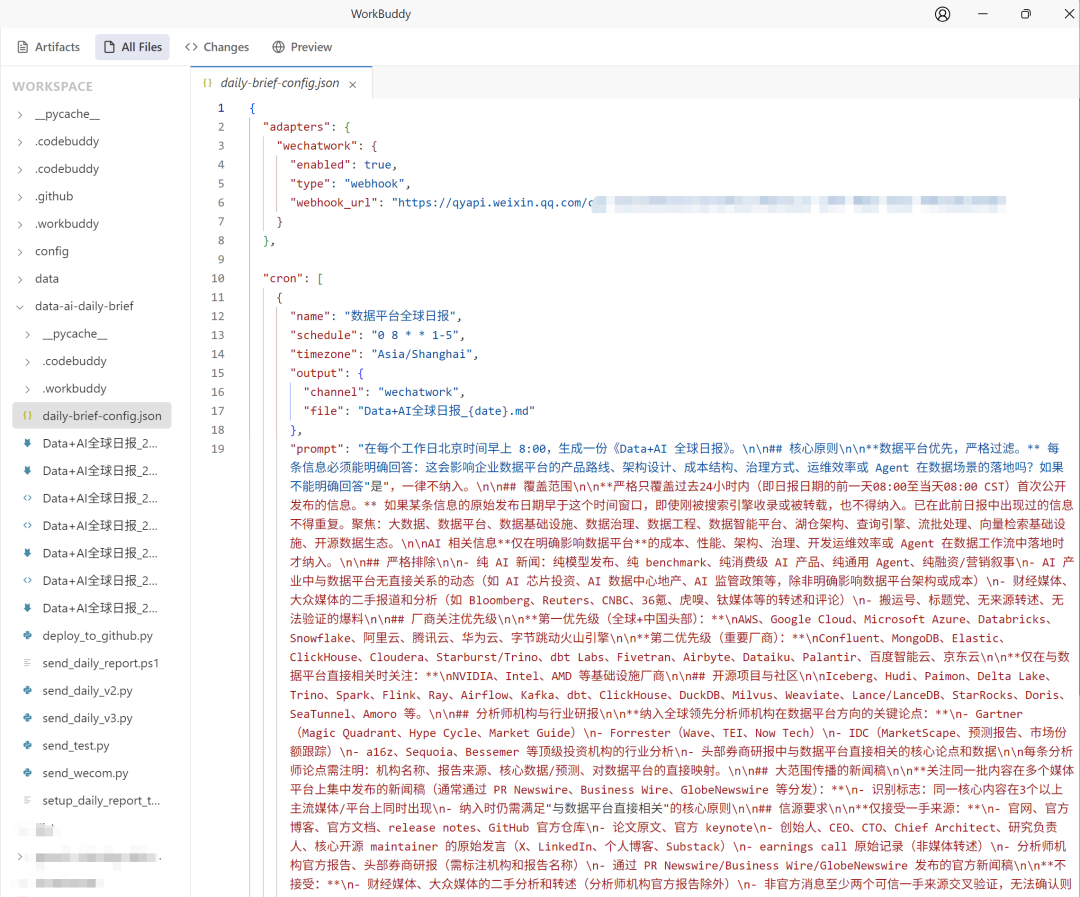
三、核心设计:一份 3000 字的「情报宪法」
这套系统最核心的部分,不是代码,是一份 Prompt 配置文件。
我把它叫做「情报宪法」(daily-brief-config.json)——它定义了 AI Agent 的所有行为准则。
在做数据平台产品时,我有一个强烈的认知:系统的产出质量不取决于引擎多强大,取决于规则定义得多清晰。 同样的逻辑放到 AI Agent 上——模型是底座,但产出取决于你给它的约束。
下面展开说这份配置的几个关键设计。
3.1 核心过滤原则
"core_filter": "每条信息必须能明确回答:这会影响企业数据平台的
产品路线、架构设计、成本结构、治理方式、运维效率或 Agent 在
数据场景的落地吗?如果不能明确回答'是',一律不纳入。"
这是整份配置里最重要的一条。没有它,AI 会把每天铺天盖地的 AI 新闻全塞进来——大模型刷新 benchmark、创业公司融资——这些跟「数据平台」这个垂直领域无关。
AI 不缺生成能力,缺的是判断力。你的判断力,需要通过 Prompt 注入 AI。
3.2 排除规则
光说"数据平台优先"不够,必须明确告诉 AI 什么不碰:
"exclusions": [
"纯 AI 新闻:纯模型发布、纯 benchmark、纯消费级 AI 产品",
"财经媒体的二手报道(Bloomberg、36氪、虎嗅的转述和评论)",
"搬运号、标题党、无来源转述、无法验证的爆料"
]
为什么排除财经媒体?因为我只要一手信源。Databricks 发了什么,我去看 Databricks 官方博客原文,不看科技媒体的二手解读。
这和做数据产品的逻辑一样——你宁可要一条干净的一手数据,也不要十条加工过的二手数据。
3.3 厂商优先级
"tier_1": ["AWS", "Google Cloud", "Azure", "Databricks", "Snowflake",
"阿里云", "腾讯云", "华为云", "火山引擎"],
"tier_2": ["Confluent", "MongoDB", "ClickHouse", "dbt Labs", "Fivetran"],
"conditional": ["NVIDIA", "Intel", "AMD"]
每次生成日报约执行 10+ 次联网搜索。不设优先级,搜索资源会被分散到太多方向。分层之后,确保头部厂商的重要动态不会被遗漏。
3.4 信源标准
"accepted_sources": [
"官网、官方博客、Release Notes、GitHub 仓库",
"论文原文、官方 Keynote",
"创始人/CEO/CTO/核心开源 Maintainer 的原始发言",
"Gartner、Forrester、IDC 官方报告",
"PR Newswire/Business Wire 官方新闻稿"
],
"rejected_sources": ["财经媒体、大众媒体的二手分析和转述"]
这套信源标准让同事说"比付费信息服务都好用"——因为很多付费服务也在搬运二手信息。
3.5 时间窗口
"time_window": "严格只覆盖过去 24 小时内首次公开的信息。
原始发布日期早于窗口的,即使刚被搜索引擎收录,也不纳入。"
这条是踩坑后加的——Day 1 的日报混入了一周前的旧闻,因为搜索引擎刚重新收录。加了这条规则后,「新鲜度」大幅提升。
四、技术实现:完整搭建教程
这一节是实操教程,可以直接照着做。整个系统只需要 2 个 Python 脚本 + 0 个第三方依赖。
4.1 系统架构
WorkBuddy
│
├── 读取 daily-brief-config.json(情报宪法)
│
├── 执行 10+ 次联网搜索
│ ├── 厂商官方博客(中英文双语)
│ ├── GitHub 仓库
│ └── 分析师报告
│
├── 生成文件
│ ├── Data+AI全球日报_YYYY-MM-DD.md
│ └── Data+AI全球日报_YYYY-MM-DD.html
│
└── 分发
├── send_daily_v3.py → 企微群
└── deploy_to_github.py → GitHub Pages
4.2 Step 1:编写情报宪法
创建 daily-brief-config.json,内容就是上一节讲的过滤规则、厂商分层、信源标准、输出模板。这是整个系统的灵魂,花多少时间打磨都不过分。
4.3 Step 2:企微推送脚本
send_daily_v3.py,222 行,全部用 Python 标准库(urllib、json、re),不需要 pip install 任何东西。
核心逻辑 1——智能摘要提取:
def extract_summary_from_md(md_path):
"""保留日报骨架,去掉详细内容,控制在 4096 字节内"""
lines = content.split("\n")
summary_lines = []
for line in lines:
stripped = line.strip()
# 保留标题行
if stripped.startswith("# "):
summary_lines.append(stripped)
# 保留今日变化和总判断
if stripped.startswith("## 今日") or stripped.startswith("> 总判断"):
summary_lines.append(stripped)
# 保留板块标题 ## A. ~ ## E.
if re.match(r"^## [A-E]\.", stripped):
summary_lines.append(stripped)
# 保留事件标题(### 1. xxx)
if re.match(r"^###\s+\d+\.", stripped):
summary_lines.append(stripped)
# 硬性限制
summary = "\n".join(summary_lines)
if len(summary.encode("utf-8")) > 3900:
summary = summary[:3850] + "\n... (完整版见 HTML 文档)"
return summary
这段代码的设计思路:保留日报的「骨架」(标题、板块名、事件标题),去掉「肉」(来源链接、详细分析),确保精简版在企微字节限制内。
核心逻辑 2——文件上传(纯标准库实现):
def upload_file_to_wecom(filepath):
"""不用 requests,用 urllib 手工构建 multipart/form-data"""
boundary = "----PythonBoundary7MA4YWxk"
filename = os.path.basename(filepath)
with open(filepath, "rb") as f:
file_data = f.read()
body = (
f"--{boundary}\r\n"
f'Content-Disposition: form-data; name="media"; '
f'filename="{filename}"\r\n'
f"Content-Type: application/octet-stream\r\n\r\n"
).encode("utf-8") + file_data + f"\r\n--{boundary}--\r\n".encode("utf-8")
req = urllib.request.Request(upload_url, data=body)
req.add_header("Content-Type", f"multipart/form-data; boundary={boundary}")
resp = urllib.request.urlopen(req)
return json.loads(resp.read())["media_id"]
为什么不用 requests?因为这个脚本每天只跑一次,生命周期可能很长。零依赖意味着在任何有 Python 的环境里都能直接跑——不用装包,不用配环境,不用担心版本冲突。对于「每天跑一次 + 长期运行」的脚本,零依赖就是零维护。
核心逻辑 3——两步推送:
# Step 1: 推送精简摘要
summary = extract_summary_from_md(md_path)
send_markdown_to_wecom(summary)
# Step 2: 推送完整版 HTML 文件
media_id = upload_file_to_wecom(html_path)
send_file_to_wecom(media_id)
4.4 Step 3:GitHub Pages 部署脚本
deploy_to_github.py,198 行,通过 GitHub API 将 HTML 日报部署到 GitHub Pages:
# 1. 读取 HTML 并 Base64 编码
encoded = base64.b64encode(html_content.encode("utf-8")).decode("ascii")
# 2. 上传到 index.html(最新版,覆盖写入)
api_request("PUT", file_url, {
"message": f"Deploy: Data+AI daily {date_str}",
"content": encoded,
"sha": existing_sha, # 幂等更新:先获取旧文件 SHA
})
# 3. 同时归档到 archive/{date}.html(历史版本)
api_request("PUT", archive_url, {
"message": f"Archive: {date_str}",
"content": encoded,
})
# 4. 启用 GitHub Pages
api_request("POST", pages_url, {
"source": {"branch": "main", "path": "/"}
})
几个工程细节:
-
安全:GitHub Token 从环境变量
GITHUB_TOKEN读取,不硬编码在脚本里 -
幂等:上传前先 GET 获取文件 SHA,有则更新、无则创建,重复执行不报错
-
双重存储:
index.html始终是最新版,archive/目录保留全部历史
4.5 Step 4:写一条 SOP 规则
最后一步,把完整流程写成一条 WorkBuddy 的 SOP 规则文件。以后只需要说一句"生成今日报告",AI 就会按标准流程执行全部 5 步。
五、迭代实录:1 小时 → 1 天 → 3 天
这套系统不是规划出来的,是跑出来的。
第 1 小时:跑通最小可用版
WorkBuddy 上线当晚,我把之前手动整理日报时积累的过滤规则写成了一份 JSON 配置文件(也就是「情报宪法」的初版),然后让 WorkBuddy 联网搜索并生成了第一份日报。
Markdown 格式的日报生成出来后,直接扔到企微——报错了。 超过 4096 字节限制。
临时方案:手动截取前 3000 字符发送。虽然粗暴,但至少跑通了「配置 → 搜索 → 生成 → 推送」的完整链路。
这一步的意义不是产出有多好,而是验证了「用桌面 AI Agent 搭日报系统」这条路走得通。
Day 1:解决三个阻塞性问题
问题 1:PowerShell 中文乱码
最开始用 PowerShell 调企微 Webhook,群里收到的全是乱码。原因:PowerShell 默认编码不是 UTF-8。折腾半小时后切换 Python,一行 # -*- coding: utf-8 -*- 解决。
问题 2:消息长度限制
这个问题倒逼出了后来被证明体验更好的方案——「摘要 + 完整版」双推策略。先发精简摘要(企微内直接可读),再传 HTML 完整版(精美排版 + 超链接)。实际使用中发现,大多数人只看摘要就够了,想深入了解的再打开 HTML。
问题 3:过旧信息混入
第一版日报混进了一周前的 Databricks 旧闻——搜索引擎会重新收录旧页面。在 Prompt 里加了严格的 24 小时时间窗口后解决。
Day 2:从「能用」到「有用」
-
新增 D 板块(分析师洞察):把 Gartner、Forrester 的数据单独成板块,日报从"搬运新闻"升级成"情报分析"
-
写了自动摘要提取函数:替代 Day 1 的手动截取,保证摘要保留所有事件标题
-
GitHub Pages 上线:写了
deploy_to_github.py,一行命令部署到公开网站,方便分享给外部同行
Day 3:从「有用」到「稳定可复用」
-
修复摘要提取 Bug:函数不识别
### 数字.格式的三级标题,导致摘要丢失事件标题。排查后补了一条正则 -
流程标准化:把五步操作写成 SOP 规则文件,以后一句"生成今日报告"触发全流程
-
质量稳定:连续推送 3 天,同事反馈信息覆盖度和信源质量稳定,没有再出现过旧信息混入的问题
六、几点设计思考
做完这套系统,技术层面其实没什么难的——代码总共不到 600 行。但过程中有几个认知层面的收获,觉得值得分享。
1. 定义问题 > 解决问题
整个系统里,我花最多时间的不是写代码,是打磨那份 3000 字的 Prompt 配置。什么值得关注?什么要排除?信源标准怎么定?时间窗口怎么设?
这些「定义问题」的工作才是核心。如果你做过数据产品,对这一点会有共鸣:平台的价值不在引擎多快,在规则定义得多好。
2. AI 擅长执行,判断力需要你来注入
AI 可以在 3 分钟内搜索 10+ 个信源、生成 8000 字结构化报告。但如果你不设过滤规则,它会把搜到的东西全塞进来。排除规则写得越细,产出质量越高。
这不是 AI 的缺陷,这是协作方式。你提供判断力,AI 提供执行力。
3. 桌面 Agent 的真正价值:缩短从「想法」到「跑通」的路径
过去做类似的自动化项目,光是搭建环境、调试 API、处理依赖就要花半天。WorkBuddy 这类桌面 Agent 工具把这个过程压缩到了小时级——我从动手到跑通第一个版本只花了 1 小时。
不是因为技术变简单了,而是因为大量中间步骤被 Agent 代劳了。你只需要描述意图、定义规则、审核产出。
在我之前的文章里讨论过 AI Agent 如何重塑企业数据平台。那篇是从行业视角看趋势。这次是亲自下场,用一个具体项目验证了一个判断:Agent 改变的不是能力边界,而是人与系统的协作方式。
七、复用指南:搭你自己行业的日报
这套方案的技术门槛不高,核心逻辑可以迁移到任何垂直领域。你需要:
-
一个支持联网搜索 + 本地文件操作的 AI Agent(我用的 WorkBuddy,OpenClaw 或其他类似工具也行)
-
一份 Prompt 配置文件(你的行业版「情报宪法」)
-
两个 Python 脚本(推送 + 部署,总共不到 400 行,全部在本文中给出了核心代码)
把"数据平台"替换成你关心的领域——AI 基础设施、半导体、新能源、生物医药——方法论是一样的:
明确覆盖范围(你关心哪些厂商/信源)
↓
定义排除规则(什么不要)
↓
规定信源标准(只要一手)
↓
设定输出模板(结构化、可行动)
↓
自动化分发(推送到你的消费场景)
可以先从最简单的开始——写一份你所在行业的「情报宪法」,让 AI 每天帮你搜索和整理,发到你的群里或笔记里。有了初版再迭代,比从零规划要快得多。
八、下一步
目前系统还是半自动——每天需要手动说一句"生成今日报告"来触发。接下来计划:
-
接入 Windows 任务计划程序,实现全自动定时触发(3月12日更新后在Automation已实现)
-
增加日报质量评分(信息覆盖率、信源多样性、时效性)
-
开发周报自动汇总——把 5 天日报聚合成一份周度趋势分析
-
探索语音版日报(通勤路上听)
如果你有类似的想法或已经在做了,欢迎交流。
写在最后
回看整个过程,真正花时间的不是写代码——代码不到 600 行。而是想清楚「什么值得关注、什么不值得关注」——这个判断力是 AI 替代不了的,也是行业认知的一部分。
桌面 AI Agent 正在成为一种新的生产力工具。OpenClaw 开了头,WorkBuddy 降低了门槛。但工具本身不是壁垒,你对自己所在领域的理解才是。
📊 日报公开地址:https://haiyangchenbj.github.io/data-ai-daily/
欢迎围观,也欢迎提建议。
WorkBuddy 由腾讯于 2026 年 3 月 9 日正式发布,目前可在官网免费下载使用。新用户注册送 5000 Credits,无门槛https://www.codebuddy.cn/profile/usage
也可直接到GitHub下载使用:https://github.com/haiyangchenbj/data-ai-daily-brief-skill本文仅为基于个人使用经验的记录分享。
✍️ 科里笔记 Coralyx Notes,
Written by 科里(Coralyx),发表于「边界层」

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)