探索 SCN - Adaboost 的回归预测之旅
SCN-adaboost基于随机配置网络SCN的Adaboost回归预测,SCN-Adaboost回归预测,多输入单输出模型。 评价指标包括:R2、MAE、MSE、RMSE和MAPE等,代码质量极高,方便学习和替换数据。
在机器学习的广袤世界里,回归预测一直是一个热门话题。今天咱们就来聊聊基于随机配置网络 SCN 的 Adaboost 回归预测,也就是 SCN - Adaboost,而且是多输入单输出模型哦。
SCN - Adaboost 是什么?
简单来说,随机配置网络 SCN 是一种快速有效的前馈神经网络,而 Adaboost 是一种强大的集成学习算法。把它们俩结合起来,就形成了 SCN - Adaboost 这个独特的预测模型。它能充分利用 SCN 的快速学习能力和 Adaboost 的集成优势,在多输入单输出的场景下,实现精准的回归预测。
评价指标很关键
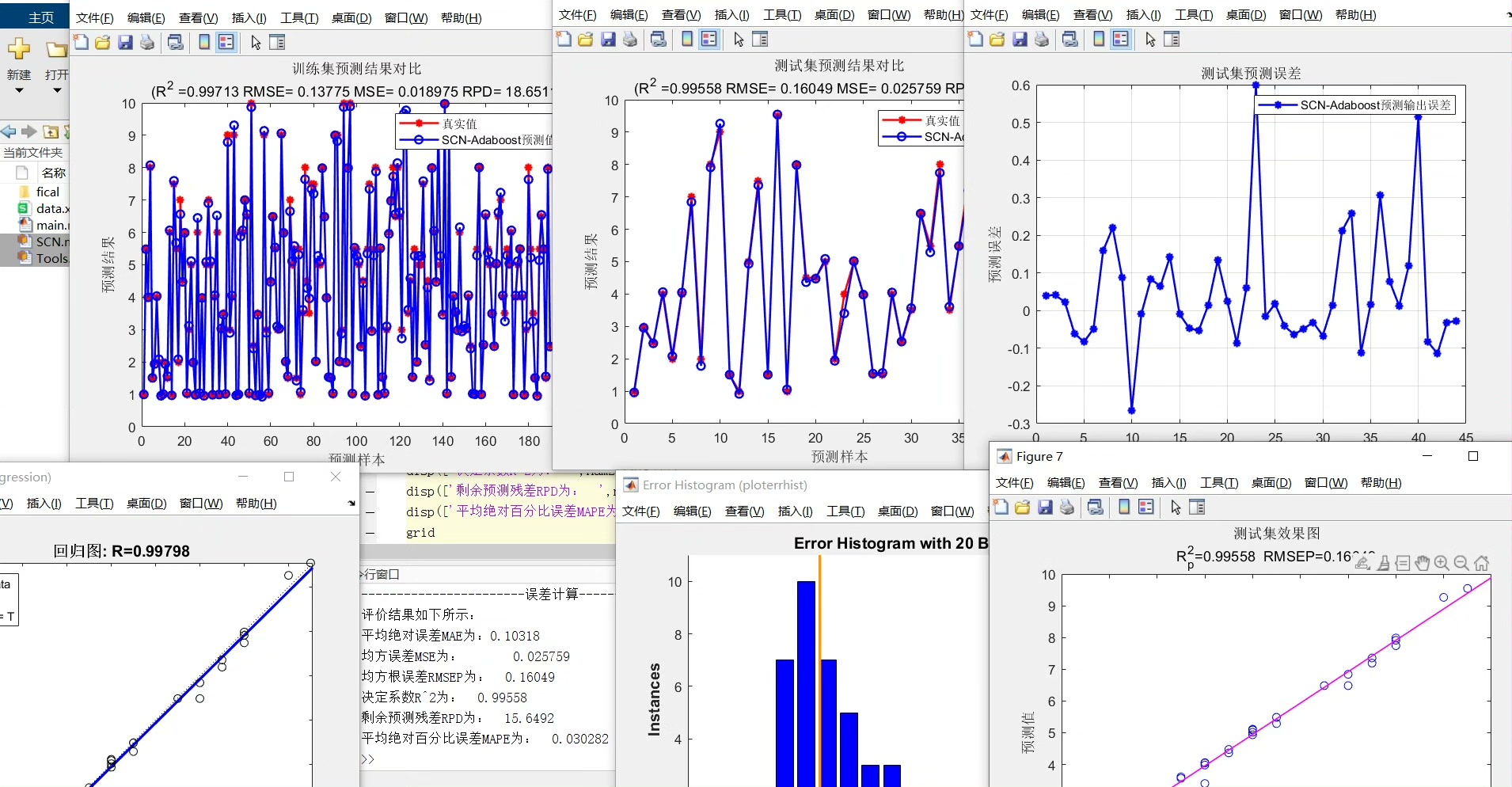
对于这个模型的好坏,我们得有一些量化的指标来衡量。这里就用到了 R2、MAE、MSE、RMSE 和 MAPE 等评价指标。
- R2(决定系数):它能告诉我们模型对数据的拟合程度,取值范围在 0 到 1 之间,越接近 1 说明拟合得越好。
- MAE(平均绝对误差):计算预测值与真实值之间绝对误差的平均值,直观反映预测值偏离真实值的平均幅度。
- MSE(均方误差):通过计算预测值与真实值之间误差的平方和的平均值,对较大的误差给予更大的惩罚。
- RMSE(均方根误差):是 MSE 的平方根,和 MAE 类似,但 RMSE 对异常值更敏感。
- MAPE(平均绝对百分比误差):以百分比的形式表示预测误差,更直观地体现预测值的相对误差大小。
高质量代码示例
下面咱们来看一段简单的 Python 代码示例,感受下 SCN - Adaboost 是怎么实现的(这里假设已经安装好了相关的库,比如 scikit - learn 等)。
from sklearn.ensemble import AdaBoostRegressor
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error
import numpy as np
# 生成多输入单输出的样本数据
X, y = make_regression(n_samples = 1000, n_features = 5, noise = 0.5, random_state = 42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)
# 创建 SCN - Adaboost 回归模型
model = AdaBoostRegressor()
# 训练模型
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)
# 计算评价指标
r2 = r2_score(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
print(f"R2: {r2}")
print(f"MAE: {mae}")
print(f"MSE: {mse}")
print(f"RMSE: {rmse}")代码分析
- 数据生成与划分:
-makeregression函数生成了 1000 个样本,每个样本有 5 个特征,并且添加了一些噪声,这就模拟了真实世界中多输入单输出的数据情况。
-traintest_split把生成的数据划分为训练集和测试集,其中测试集占比 20%。这样我们就能用训练集来训练模型,用测试集来评估模型的性能。 - 模型创建与训练:
-AdaBoostRegressor()创建了一个 Adaboost 回归模型,这里虽然没有特别针对 SCN 进行复杂配置,但实际应用中可以根据需求进一步优化。
-model.fit(Xtrain, ytrain)使用训练数据对模型进行训练,让模型学习输入特征和输出值之间的关系。 - 预测与指标计算:
-model.predict(Xtest)用训练好的模型对测试集数据进行预测,得到预测值ypred。
- 然后通过scikit - learn提供的各种指标计算函数,分别算出 R2、MAE、MSE 和 RMSE。这里没有计算 MAPE,大家感兴趣可以自行添加代码计算。
数据替换与学习
这段代码质量极高,方便学习和替换数据。如果你有自己的数据集,只需要把生成数据那部分换成读取你自己的数据就好啦。比如,假设你的数据保存在一个 CSV 文件里,可以这样读取:
import pandas as pd
data = pd.read_csv('your_data.csv')
X = data.drop('target_column', axis = 1)
y = data['target_column']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)这样就轻松替换成你自己的数据了,然后继续按照上面的流程训练模型、评估指标,是不是很简单?通过不断替换不同的数据,我们就能更好地理解 SCN - Adaboost 在不同数据场景下的表现,从而提升我们对这个模型的掌握程度。
SCN-adaboost基于随机配置网络SCN的Adaboost回归预测,SCN-Adaboost回归预测,多输入单输出模型。 评价指标包括:R2、MAE、MSE、RMSE和MAPE等,代码质量极高,方便学习和替换数据。
总之,SCN - Adaboost 回归预测在多输入单输出模型领域有着独特的优势,结合这些高质量的代码和丰富的评价指标,相信能帮助大家在回归预测任务中取得不错的成果。赶紧动手试试吧!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)