【无标题】
1. 论文基本信息
标题
How to Mitigate Overfitting in Weak-to-strong Generalization?
作者
Junhao Shi, Qinyuan Cheng, Zhaoye Fei, Yining Zheng, Qipeng Guo, Xipeng Qiu。
研究问题
在 weak-to-strong generalization 里,强模型虽然能从弱监督中学到比弱教师更强的能力,但也容易过拟合弱模型给出的错误标签。而如果只做强过滤,又会把困难样本一并丢掉,导致训练问题分布退化,损伤泛化。论文试图同时解决这两个问题。
一句话总结
作者提出一个两阶段训练框架:第一阶段先按一致性过滤弱模型标签,提升监督质量;第二阶段再把先前被丢弃的难题交给阶段一后的强模型重新打标并筛选,补回高质量困难样本,从而同时改善监督质量和问题质量。
2. 摘要
将强大的 AI 模型对齐到超出人类评估能力的任务上,是 superalignment 的核心问题。为了解决这个问题,weak-to-strong generalization 试图通过弱监督者来激发强模型的能力,并确保强模型的行为与弱监督者的意图一致,而不会出现诸如欺骗之类的不安全行为。尽管 weak-to-strong generalization 展现出一定的泛化能力,但强模型在该过程中表现出显著的过拟合:由于强模型具有很强的拟合能力,来自弱监督者的错误标签可能导致强模型过拟合。此外,若只是简单地过滤掉错误标签,可能会导致问题质量退化,从而削弱强模型在困难问题上的泛化能力。为缓解 weak-to-strong generalization 中的过拟合,我们提出了一个两阶段框架,同时提升监督信号质量和输入问题质量。三组大语言模型和两个数学基准上的实验表明,该框架相较于朴素的 weak-to-strong generalization,显著提升了 PGR,甚至在某些模型上达到 100% 的 PGR。
引言
作者先把问题放到 superalignment 背景下:真正困难的地方是,很多任务已经难到人类都无法可靠评估,因此人类无法直接给出正确监督。weak-to-strong generalization 的目标,就是让较弱的监督者去训练更强的学生模型,并且让学生最终超过教师。
接着作者指出已有方法的问题:
弱模型标签本身有噪声,强模型又很擅长拟合,所以会学到错误监督;而已有 filtering 方法虽然能提高标签正确率,却会过度丢弃困难样本,造成训练集只剩容易题,进而伤害强模型在难题上的能力。作者把这件事概括为:过去方法重视了 pseudolabel correction,却损伤了 coverage expansion。
因此本文的核心立场很明确:
要减少 weak-to-strong 里的过拟合,不能只提升标签质量,还必须保住题目的难度与多样性。
3. 方法
3.1 背景:PGR 指标
论文用 Performance Gap Recovered (PGR) 衡量 strong model 的潜力被激发了多少:
PGR=weak-to-strong−weakstrong ceiling−weak \mathrm{PGR} = \frac{\mathrm{weak\text{-}to\text{-}strong} - \mathrm{weak}}{\mathrm{strong\ ceiling} - \mathrm{weak}} PGR=strong ceiling−weakweak-to-strong−weak
其中:
-
weak:弱模型性能
-
weak-to-strong:强模型用弱标签微调后的性能
-
strong ceiling:强模型用真值标签微调后的上限性能
这个式子定义的是:
强模型在“从弱监督学到东西”这件事上,追回了多少原本和上限之间的性能差距。PGR 越高,说明 weak-to-strong 越成功。
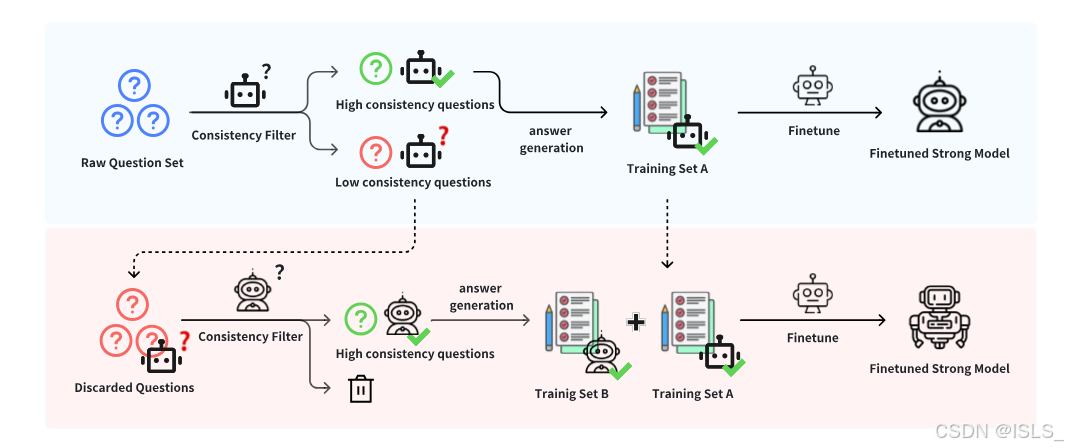
3.2 方法总览
方法分成两阶段。图 2 画得很清楚:第一阶段从原始问题集中筛高一致性样本形成 Training Set A;第二阶段把第一阶段丢掉的问题重新交给阶段一后的强模型回答,再筛出高一致性样本形成 Training Set B,最后把 A 和 B 合并做最终微调。
为什么要两阶段
作者认为 weak-to-strong 里有两个关键质量维度:
-
监督质量:标签对不对
-
问题质量:题目够不够难、分布够不够全面
第一阶段主要处理前者,第二阶段主要补救后者。
3.3 Stage I: Purifying Supervision Signals
原文核心流程
给定弱模型 MweakM_{\text{weak}}Mweak、强模型 MstrongM_{\text{strong}}Mstrong 和一组问题,传统 weak-to-strong 是让弱模型直接生成答案,再拿这些样本训练强模型。作者认为这样会把很多错误标签带入训练。于是他们引入一个基于不确定性的过滤器,保留一致性高的样本。具体做法是:对每个问题用 chain-of-thought prompting 随机生成 10 个回答,然后选一致性最高的答案作为最终答案。
公式
Confidence(Ans)=NAnsNTotal×100 \mathrm{Confidence}(\mathrm{Ans}) = \frac{N_{\mathrm{Ans}}}{N_{\mathrm{Total}}} \times 100% Confidence(Ans)=NTotalNAns×100
其中:
-
NAnsN_{\mathrm{Ans}}NAns:某个候选答案出现的次数
-
NTotalN_{\mathrm{Total}}NTotal:总采样次数,这里是 10 次
公式解释
这个公式定义的是答案置信度,本质上就是“10 次采样里,最常出现的答案占了多少比例”。
如果一个答案在 10 次里出现了 8 次,那 confidence 就是 80%。
作者把这个值当作模型自一致性的近似:
一致性越高,说明弱模型越确信;一致性越低,说明这道题更可能有标签噪声。然后根据阈值过滤,只留下高置信样本组成 Training Set A。
作者想解决什么
Stage I 的目标很直接:
降低错误伪标签进入强模型训练的概率,避免强模型对噪声监督过拟合。 图 3 也支持这一点:随着过滤阈值提高,标签正确率整体上升。
3.4 Stage II: Mitigating Question Degeneration
原文核心流程
Stage I 之后会得到两个集合:
-
DfilteredD_{\text{filtered}}Dfiltered:高确定性问题
-
DdiscardedD_{\text{discarded}}Ddiscarded:低确定性、被丢弃的问题
作者指出,被丢弃的问题往往更难、主题更少见,恰恰是测试集里也会出现、对泛化很重要的那类题。所以这些题不能直接扔掉。此时用经过 Stage I 微调后的强模型去回答这些题,因为它已经被部分激发出来,可能比弱模型更能处理困难问题。对这些回答再做一次与 Stage I 类似的不确定性过滤,保留高置信样本,得到 Training Set B,再与 Set A 合并继续训练。
这一阶段在解决什么
这一步不是单纯“再过滤一次”,而是在补回第一阶段因过滤造成的题目分布退化。
也就是:
-
Stage I 提升监督质量
-
Stage II 恢复题目难度与多样性,提升 coverage expansion
这是整篇论文最关键的设计思想。
4. 实验设计讲解
实验目标
论文想验证三件事:
-
提高监督质量是否真的能缓解 weak-to-strong 的过拟合
-
仅做 filtering 是否会伤害问题质量
-
两阶段框架能否同时兼顾两者并提升最终 PGR 与准确率
数据集与任务
作者在两个数学推理基准上做实验:
-
GSM8K:小学数学文字推理
-
MATH:更难的数学推理任务
模型系列
使用两组模型:
-
Llama 3 系列:Llama 3 8B Instruct 与 Llama 3 70B
-
Deepseek 系列:Deepseek 7B Chat 与 Deepseek 67B Base
评价指标
主要用两个指标:
-
Accuracy
-
PGR
实验对比
图 4 展示了三种训练阶段的轨迹:
-
Baseline
-
Stage I
-
Stage II
作者还做了阈值分析,考察不同 filtering threshold 对结果的影响;并在后文做了 Stage II 里“有过滤”和“无过滤”的消融。
5. 主要结果与作者结论
主结果
作者声称他们的方法在多个模型系列上都能显著缩小 strong model 与 strong ceiling 的差距。图 4 的结论是:Stage II 通常优于 Stage I,而 Stage I 又优于 baseline。
文中给出的代表性数字包括:
-
Llama 3 / GSM8K:PGR 从 7.19% 提升到 120.50%,准确率从 75.20% 提升到 81.50%。
-
Llama 3 / MATH:PGR 从 36.17% 提升到 121.28%,准确率从 18.2% 提升到 35.2%。
-
Deepseek / GSM8K:PGR 从 51.39% 提升到 90.04%,准确率从 62.39% 提升到 72.94%。
-
Deepseek / MATH:PGR 从 65.85% 提升到 126.83%,准确率从 16.8% 提升到 21.8%。
消融实验
表 1 比较了 Stage II 中“带过滤”和“不带过滤”的版本。结果显示,在 Llama 3 / GSM8K 上,带过滤通常更好,说明第二阶段也不能直接把强模型生成的样本全收回来,仍然要做质量控制。
作者结论
作者的结论不是“过滤越狠越好”,而是:
-
过滤确实能提高监督正确率
-
但过度过滤会损伤题目质量
-
最有效的办法是先净化监督,再把有价值的困难题重新纳回训练
6. 我对这篇论文的简短判断
这篇论文最有价值的点,在于它把 weak-to-strong 里的失败原因拆成了两个维度:
-
label noise / supervision quality
-
sample difficulty and diversity / question quality
这比单纯说“弱标签有噪声”更细,也更能解释为什么很多 filtering 方法虽然短期干净了,但长期泛化反而不一定最好。这个分析和它的两阶段设计是对得上的。这个判断是我基于论文内容做的归纳。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)