第 1 篇|YOLO 核心思想:为什么它是一阶段巅峰?
大家好,这里是 YOLO 理论与改进实战系列 第1篇。
本系列默认你已经具备 YOLO 基础能力:能够熟练搭建环境、运行推理代码、用自定义数据集训练模型并完成本地部署,因此不再重复讲解基础安装、跑通步骤,全程专注于 原理吃透 + 算法改进,帮大家从“会用工具”进阶到“掌握算法”,为后续魔改模型、做毕设/竞赛/科研打下坚实基础。
话不多说,这一篇我们从 YOLO 最本质的核心思想入手,把“YOLO 到底是什么、为什么能做到实时检测、每个预测结果背后的逻辑”彻底讲透,不堆砌冗余公式,只讲实用、能落地的原理,看完就能对应上你平时训练、推理时的各种场景。
0. 前言:为什么要吃透 YOLO 核心思想?
很多同学都有这样的经历:拿着别人的代码,改改数据集路径、调调epochs和学习率,就能训出一个mAP不错的模型,也能顺利部署到本地跑通检测。但只要被问到以下几个问题,就会瞬间卡壳:
-
YOLO 输出的预测结果里,x、y、w、h 到底代表什么?为什么有时候预测框会偏移、不准?
-
同样是目标检测,为什么 YOLO 比 Faster R-CNN 快那么多?“一阶段”和“两阶段”的核心区别到底在哪里?
-
训练时,模型是怎么判断“这个格子里有物体、那个格子里没有物体”的?置信度和类别概率之间是什么关系?
-
后续做模型改进(比如加注意力、改损失函数),到底改的是 YOLO 核心流程的哪一步?为什么这么改能涨点?
这些问题,都需要从 YOLO 的核心思想里找答案。只有吃透了核心,后续的改进、调参、排错才能有的放矢,而不是盲目试错。这也是我们这个系列的核心目的——不做“调参侠”,只做“懂原理、能创新”的学习者。
1. 目标检测两大流派:一阶段 vs 两阶段(彻底分清)
在讲 YOLO 之前,我们必须先明确目标检测的两大核心流派,因为 YOLO 的诞生,本质上是对“一阶段检测”的极致优化,理解了两大流派的区别,才能真正明白 YOLO 的优势所在。
1.1 两阶段检测器(代表:Faster R-CNN 系列)
两阶段检测器的核心逻辑是“分两步走”,先“找可能有物体的区域”,再“判断这个区域是什么、在哪里”,具体流程如下:
-
第一步:生成候选框(Region Proposal)
-
先通过主干网络(如 VGG、ResNet)提取图像特征,再通过 RPN(区域提议网络)生成大量“可能包含物体”的候选框(大概几千个)。
-
这些候选框是随机生成的不同尺寸、不同位置的矩形框,目的是“覆盖”图像中所有可能存在物体的区域,避免遗漏。
-
-
第二步:候选框分类与回归
-
对第一步生成的几千个候选框,逐一进行“分类”(判断这个框里是哪一类物体,如人、车、猫)和“回归”(修正候选框的坐标,让框更贴合物体实际位置)。
-
最后通过 NMS(非极大值抑制)去掉重复的候选框,得到最终的检测结果。
-
优点:检测精度高,尤其是对小目标、遮挡目标的识别效果较好,因为候选框的筛选的过程,相当于提前“聚焦”了可能有物体的区域,减少了误判。
缺点:速度慢、流程复杂。因为要生成几千个候选框,还要逐一处理每个候选框,计算量极大,难以满足实时检测需求(比如摄像头实时推理、自动驾驶场景),工程部署难度也更高。
1.2 一阶段检测器(代表:YOLO / SSD / RetinaNet)
一阶段检测器的核心创新的是:跳过候选框生成步骤,把目标检测直接当成一个“回归问题”来解决。
简单来说,就是“一张图片进去,一次前向传播,直接输出所有检测结果”,不需要分两步,具体流程如下:
-
图像输入后,经过主干网络提取特征、 Neck 层进行多尺度特征融合;
-
检测头(Head)直接输出所有物体的“框坐标、置信度、类别概率”;
-
通过 NMS 去重,得到最终检测结果。
其中,YOLO 是一阶段检测器的“巅峰之作”,它的名字 “You Only Look Once” 就精准概括了其核心逻辑——对输入图像只进行一次前向传播,就完成所有目标的检测,不需要任何额外的候选框生成步骤。
优点:速度极快,能够满足实时检测需求(比如 YOLOv8n 可以轻松达到每秒几十帧甚至上百帧),流程简单、工程部署友好,适合嵌入式、端侧等资源有限的场景。
缺点:早期版本(v1、v2)对小目标、密集目标的检测精度略低于两阶段检测器,因为没有候选框的“聚焦”过程,容易出现漏检、误检;但从 v3 开始,通过多尺度检测、Anchor 优化等改进,精度已经逐步追上甚至超过部分两阶段检测器,实现了“速度与精度的平衡”。
1.3 核心区别总结
用一句话就能分清两者的核心差异:两阶段是“先找候选区,再判断”,一阶段是“直接判断,不找候选区”。
而 YOLO 之所以能成为一阶段的巅峰,就是因为它把“回归问题(修正)”做到了极致——用最简单的逻辑(网格化),实现了最快的检测速度,同时通过不断迭代,补齐了精度短板。
2. YOLO 最核心思想:网格化预测(灵魂所在)
YOLO 的所有逻辑,都围绕“网格化预测”展开。这是一个极其简单,但又极其聪明的设计,也是 YOLO 区别于其他一阶段检测器(如 SSD)的核心特征。
我们一步步拆解,结合你平时训练、推理的场景,让你瞬间理解。
2.1 第一步:图像网格化划分
YOLO 会先将输入图像(比如我们常用的 640×640 尺寸),通过主干网络下采样后,得到不同尺度的特征图(比如 YOLOv8 的 80×80、40×40、20×20 三个尺度),每个特征图都会被划分成 S × S 的网格。
这里要注意两个关键细节(很多人容易混淆):
-
网格是划分在“特征图”上,而不是原始输入图像上,但特征图和原始图像是“一一对应”的(通过下采样比例关联)。比如 640×640 原始图像,下采样 8 倍得到 80×80 特征图,那么特征图上的 1 个网格,对应原始图像上的 8×8=64 个像素。
-
多尺度特征图的网格划分,是为了适配不同尺寸的物体:80×80 小网格(对应原始图像小区域)负责检测小目标,20×20 大网格(对应原始图像大区域)负责检测大目标——这也是 YOLO 解决小目标检测的核心手段之一(后续会专门讲)。
举个通俗的例子:假设我们用 YOLOv8 检测一张 640×640 的图片,其中 80×80 特征图被划分成 80×80=6400 个小网格,每个小网格对应原始图像上 8×8 的像素区域;20×20 特征图被划分成 400 个大网格,每个大网格对应原始图像上 32×32 的像素区域。
2.2 第二步:网格的“责任划分”
网格化划分后,YOLO 会给每个网格分配一个“责任”:每个网格,只负责预测“物体中心点落在该网格内”的物体。
这句话非常关键,我们拆解一下:
-
对于图像中的任意一个物体,我们先找到它的“中心点坐标”(比如一个人的中心点在 (x0, y0));
-
判断这个中心点 (x0, y0) 落在哪个网格内(比如落在 80×80 特征图的第 30 行、第 40 列网格);
-
那么,就由这个网格(30,40)来负责预测这个物体的框坐标、置信度和类别——其他网格不会预测这个物体,避免了重复预测。
这里有一个补充点:早期 YOLO 版本(v1~v7)中,每个网格会预测多个边界框(比如 v3 每个网格预测 3 个框),目的是适配不同形状的物体;而 YOLOv8 采用 Anchor-Free 机制,每个网格只预测 1 个框,但通过标签分配策略,依然能精准适配不同形状的物体(后续第4篇会详细讲标签分配)。
2.3 第三步:每个网格到底输出什么?(必懂,对应代码输出)
这是最核心、最实用的部分,直接对应你平时训练时看到的模型输出、推理时得到的结果。每个网格的输出,本质上是一组“预测向量”,包含 4 类关键信息,我们逐一拆解,结合代码场景讲解。
(1)边界框坐标 (x, y, w, h)
这四个值是模型预测的“物体位置”,但要注意:它们的取值范围和含义,和我们平时标注数据集时的坐标完全不同——这也是很多人训练时“框不准”的核心原因之一。
-
x、y:框中心相对于当前网格的偏移量
-
取值范围是 [0, 1],表示框中心在当前网格内的相对位置。比如 x=0.5、y=0.5,说明框中心正好在网格的正中间;x=0.1、y=0.2,说明框中心在网格的左上角区域。
-
为什么要做“相对偏移”?因为这样可以让模型更容易学习——不管物体在图像的哪个位置,模型只需要学习“框中心在网格内的相对位置”,而不需要学习绝对坐标,减少了模型的学习难度。
-
-
w、h:边界框的宽度和高度(相对于整张图像的比例)
-
取值范围也是 [0, 1],表示框的宽和高占整个输入图像宽高的比例。比如输入图像是 640×640,w=0.2、h=0.3,那么框的实际宽度是 640×0.2=128 像素,实际高度是 640×0.3=192 像素。
-
补充:训练时,我们标注的坐标是“绝对坐标”(比如框的左上角 (x1,y1)、右下角 (x2,y2)),而模型输出的是“相对坐标”,因此需要在数据加载时做“坐标转换”——这就是你在 ultralytics 源码中,看到的 dataloaders 里的坐标归一化、偏移计算的原因。
-
(2)置信度 Confidence
置信度是一个 [0, 1] 之间的值,很多人只知道“置信度越高,预测越准”,但不知道它的具体含义——它其实包含两个层面的信息,公式如下(不用死记,理解即可):
![]()
-
P(Object):该网格内存在物体的概率
-
如果网格内没有物体,P(Object) = 0,置信度也为 0;如果有物体,P(Object) 接近 1,置信度也会随之升高。
-
-
IoU(pred,truth):预测框与真实框的交并比
-
IoU 是衡量“预测框和真实框重合程度”的指标,取值范围 [0, 1],IoU 越接近 1,说明预测框越贴合真实框。
-
通俗来说:置信度 = “这个网格里有物体”的概率 × “预测框有多准”的概率。因此,置信度高,说明两个条件都满足——既有物体,框又准;置信度低,要么没物体,要么框不准。
补充:训练时,置信度损失(Confidence Loss)就是用来优化这个指标的,让模型学会“判断网格里有没有物体”和“预测框准不准”(后续第5篇会详细讲损失函数)。
(3)类别概率 Class Probabilities
类别概率是一个向量,长度等于你数据集的类别数(nc),每个元素的取值范围是 [0, 1],代表“该网格预测的物体属于某一类”的概率。
比如你的数据集有 2 类(人脸、口罩),那么类别概率向量就是 [p1, p2],p1 是“该物体是人脸上”的概率,p2 是“该物体是口罩”的概率,且 p1 + p2 = 1(通过 Softmax 激活函数实现)。
这里要注意一个关键:类别概率,是“在该网格存在物体的前提下”,物体属于某一类的概率——也就是说,它和置信度是“相乘”的关系,最终得到“某一类物体的置信度”(比如:人脸的置信度 = 置信度 × 人脸类别概率)。
(4)最终预测信息总结
结合上面三点,每个网格的最终输出可以概括为:
1 个网格 → 多个边界框(v8 为 1 个) × (4个框坐标 + 1个置信度 + nc个类别概率)
比如:你的数据集有 2 类,YOLOv8 每个网格输出 1 个框,那么每个网格的输出向量长度就是 4(坐标)+1(置信度)+2(类别)=7;如果是 80×80 特征图,那么这一层的输出就是 80×80×7。
而我们平时推理时看到的“检测框 + 类别 + 置信度”,就是模型对所有网格的输出进行筛选、去重(NMS)后得到的最终结果。
3. 为什么 YOLO 快到爆炸?(核心优势拆解)
很多同学都知道 YOLO 快,但不知道快在哪里——其实核心就是“去掉冗余步骤,最大化简化计算”,结合前面的核心思想,我们拆解 3 个关键原因,对应源码逻辑,让你一看就懂。
3.1 没有候选框生成阶段(最核心原因)
两阶段检测器的大部分计算量,都花在“生成候选框”和“处理候选框”上(比如 Faster R-CNN 要处理几千个候选框),而 YOLO 直接跳过了这一步,通过“网格化预测”,让每个网格只负责自己范围内的物体,不需要额外生成候选框,计算量直接减少一个量级。
补充:早期一阶段检测器(如 SSD)虽然也没有候选框,但它采用“先验框”(和 Anchor 类似),每个网格需要预测多个先验框,计算量依然比 YOLO 大;而 YOLOv8 采用 Anchor-Free,进一步减少了计算量,速度更快。
3.2 一次卷积搞定所有任务,共享特征
YOLO 的主干网络(Backbone)、Neck 层、检测头(Head)是“端到端”的结构,所有任务(分类、回归、置信度预测)都共享同一个特征图,不需要像两阶段那样,对候选框单独提取特征、单独计算。
简单来说:一张图片输入后,经过一次卷积运算,就能同时输出所有物体的坐标、置信度、类别,不需要分步骤计算,极大提升了速度。
3.3 全卷积架构,无冗余计算
YOLO 整个网络都是“全卷积架构”,没有全连接层(除了早期 v1 有少量全连接层,后续版本都去掉了)。全连接层会产生大量的参数和冗余计算,而卷积层能够高效提取特征,且参数更少、计算更快,尤其适合大尺寸图像的实时推理。
举个直观的对比:Faster R-CNN 包含全连接层,在 CPU 上推理一张图片可能需要几秒;而 YOLOv8n 在 CPU 上推理一张图片只需几十毫秒,在 GPU 上更是能达到每秒上百帧,完全满足实时检测需求。
总结一句话:别人分两步走,还要处理大量冗余信息;YOLO 一步到位,只计算核心有用的信息,这就是它快的本质。
4. YOLO 的关键流程(极简版,对应源码执行逻辑)
结合你平时运行 YOLO 代码的场景,我们梳理一下 YOLO 从“输入图片”到“输出检测结果”的完整流程,每一步都对应 ultralytics 源码的核心逻辑,帮你把原理和代码对应起来,后续看源码时更轻松。
-
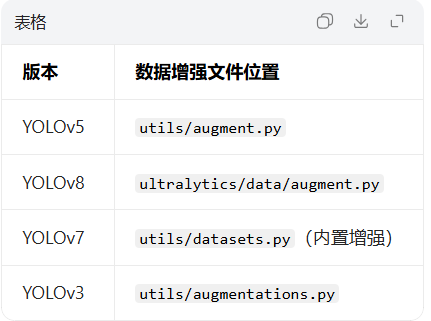
图像预处理(对应源码:dataloaders/augment.py)
-
将输入图片 resize 到统一尺寸(比如 640×640),避免因图片尺寸不一致导致模型无法计算;
-
进行归一化(将像素值从 0~255 转换为 0~1),让模型更容易收敛;
-
(训练时)进行数据增强(马赛克、翻转、缩放等),提升模型泛化能力;(推理时)不做数据增强,只做 resize 和归一化。
-
-
特征提取(对应源码:models/yolo/model.py → Backbone)
-
通过主干网络(如 YOLOv8 的 C2f 网络)提取图像特征,得到不同尺度的特征图(80×80、40×40、20×20);
-
核心作用:将原始图像的像素信息,转换为“能代表物体特征”的特征向量,供后续预测使用。
-
-
多尺度特征融合(对应源码:models/yolo.py → Neck)
-
通过 PAN 层(路径聚合网络),将不同尺度的特征图进行融合——把浅层特征(高分辨率,适合小目标)和深层特征(低分辨率,适合大目标)结合起来;
-
核心作用:解决“小目标检测不准”的问题,让模型既能检测到大目标,也能检测到小目标。
-
-
检测头预测(对应源码:models/yolo.py → Head)
-
检测头对融合后的特征图进行卷积运算,输出每个网格的预测结果:框坐标 (x,y,w,h)、置信度、类别概率;
-
YOLOv8 采用“解耦头”(分类头和回归头分开),进一步提升预测精度和速度(后续第3篇会详细讲)。
-
-
后处理(对应源码:utils/ops.py → non_max_suppression)
-
首先对预测结果进行“置信度筛选”:过滤掉置信度低于阈值(比如 0.25)的预测框,减少误检;
-
然后进行 NMS(非极大值抑制):去掉重复的预测框(比如同一个物体被多个网格预测,只保留置信度最高、最准确的一个框);
-
最后将“相对坐标”转换为“绝对坐标”,方便显示和后续处理。
-
-
输出结果
-
将处理后的检测框、类别、置信度,绘制在原始图片上(推理时),或用于计算损失(训练时)。
-
简单记:预处理 → Backbone(特征提取) → Neck(特征融合) → Head(预测) → 后处理(NMS) → 输出结果,这就是 YOLO 从输入到输出的完整逻辑,后续所有改进,都是在这个流程的某一步做优化。
5. 本篇总结
这一篇是整个系列的“地基”,后续所有的原理讲解、算法改进,都基于今天讲的核心思想,建议大家背下来,或反复看几遍,确保吃透:
-
YOLO 是一阶段目标检测的代表,核心创新是“把目标检测直接当成回归问题”,跳过候选框生成步骤,实现“Only Look Once”。
-
YOLO 的灵魂是S×S 网格化预测:将特征图划分成网格,每个网格负责预测“中心点落在该网格内”的物体,避免重复预测。
-
每个网格的输出包含 3 类核心信息:框坐标 (x,y,w,h)、置信度、类别概率,其中 x、y 是网格内相对偏移,w、h 是图像比例,置信度是“有物体概率 × 框准确率”。
-
YOLO 快的原因:无候选框、一次卷积完成所有任务、全卷积架构,最大化减少冗余计算。
-
YOLO 完整流程:预处理 → 特征提取 → 特征融合 → 预测 → 后处理(NMS) → 输出,后续改进都围绕这个流程展开。
补充:本篇我们讲的是 YOLO 所有版本的“通用核心思想”,不管是 v1 还是 v8,核心逻辑都是“网格化 + 回归”,只是后续版本在网络结构、标签分配、损失函数等方面做了优化,让精度和速度更优。
下一篇,我们会讲 YOLO 的演进史:从 v1 到 v8,每个版本到底做了哪些关键改进?为什么 v8 能成为当前工业界主流?帮大家理清 YOLO 的迭代逻辑,为后续拆解 YOLOv8 结构、做改进打下基础。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)