VLN范式大洗牌|10篇力作,拆解2026年VLN四大核心突破方向

2026年了,VLN的护城河,还挖得动吗?
——且探虚实
目录
One Agent to Guide Them All:显式世界表示,赋能MLLM导航
视觉语言导航(VLN)正经历一场深刻的范式重塑。如果说过去几年,领域内主要聚焦于模型架构的优化与数据规模的扩充,那么2026年开年,我们看到的则是多条技术路径的并行爆发与交叉融合。
而在利用大型语言模型提升零样本泛化能力成为共识的背景下,VLN也面临更深层的攻坚挑战:
如何破解空间感知的模糊性?如何处理物理世界中异构机器人的“具身鸿沟”?又如何在长尾分布下实现真正的泛化?
这些问题的求解,正牵引着领域内多条技术路径的并行突破:
视频生成模型的引入,为智能体赋予“想象力”,使其能够推演长程轨迹;
多模态大模型与VLA的融合,则试图消融感知与决策的壁垒;
强化学习通过多轮交互与因果推理,从根源上缓解短视决策;
而面向垂直场景的深耕,则将技术推向真实世界复杂性的严峻考验。
我们整理了2026年初来自顶尖机构的10篇最新力作,发现它们不约而同地沿着上述技术流向,给出了各自的答案。
注:本文所选取的论文,均来自2025年底至2026年2月间的VLN相关工作。受限于篇幅,大量同样出色甚至更具影响力的工作未能悉数呈现,难免挂一漏万,这是选题取舍的结果,而非价值判断使然。欢迎在评论区留言补充,我们也会持续追踪这一领域的更多进展。
01 风向一:视频生成模型入场,用“想象力”导航未来
2026年,VLN领域最令人兴奋的突破,莫过于视频生成模型的跨界入场。
越来越多的VLN研究者将视频生成模型作为导航智能体的“想象力引擎”,让机器人能够“预见”未来的路径,从而做出更优的决策。
SparseVideoNav:稀疏视频生成,点亮超视距导航之路
来自OpenDriveLab(上海AI Lab与港大)的 SparseVideoNav 首次将视频生成模型引入真实世界的超视距导航(Beyond-the-View Navigation, BVN)任务。
传统VLN严重依赖稠密的指令,而BVN任务中,智能体只有一个模糊的目标,需要自主探索。
研究者发现,视频生成模型天生就擅长在长时序上对齐语言指令,非常适合BVN。但生成长达数十秒的完整视频,延迟太高,无法实际部署。
为此,研究提出了稀疏视频生成的巧妙思路:只生成未来20秒内的几个关键帧,就能勾勒出一条大致的轨迹。
这一“脑补”出的稀疏未来,为智能体提供了宝贵的全局规划信息,推理速度却比生成完整视频快了27倍!
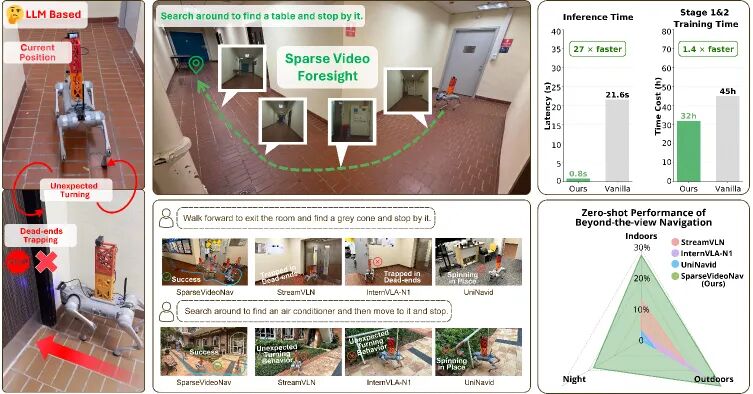
▲图1 | SparseVideoNav的核心思想:用稀疏视频"脑补"未来路径。 智能体根据当前观察和高层指令,生成未来轨迹的几个关键帧(稀疏视频),并据此规划动作。左侧为传统VLN(需要详细逐步指令),右侧为BVN任务(仅有粗略方向指导),凸显了稀疏视频生成在超视距导航中的独特价值。
NavDreamer:当视频模型成为零样本3D导航大师
无独有偶,浙江大学的 NavDreamer 也将目光投向了生成式视频模型,并将其直接作为零样本的3D导航规划器。
他们认为,导航任务的核心是高层决策和方向指导,这与视频模型的能力天然契合。
NavDreamer的流程颇具巧思:
首先,利用VLM(视觉语言模型)对视频模型生成的多个“导航梦境”(即预测视频)进行打分,选出最靠谱的“梦”;
然后,通过一个逆动力学模型(Inverse Dynamics Model),从这个最佳视频中解码出可执行的导航路点。
为了解决室外场景的尺度模糊问题,研究还引入了度量深度先验进行校准。
这项工作不仅提出了一个新颖的框架,还为3D导航领域的视频模型建立了一个全面的评估基准,为后续研究铺平了道路。

▲图2 | NavDreamer系统概览:预测、评分、执行。 左侧展示了从文本指令和初始图像生成多条"导航预测"(预测视频),再由VLM评分选出最优路径,最终通过逆动力学模型解码出可执行航点的完整流程。下侧雷达图则展示了NavDreamer在物体导航、精确导航、空间定位、场景推理和语言控制五个维度上的综合能力评估,是目前视频模型用于3D导航最全面的基准之一。
02 风向二:MLLM/VLA大一统,一个模型搞定所有导航
长期以来,VLN领域被各种任务特定的模型架构所割裂。
2026年,一股强大的“统一”浪潮正席卷而来,研究者们开始借助多模态大模型(MLLM)和视觉-语言-动作(VLA)模型的强大能力,试图打造一个能通吃所有导航任务的“大一统”模型。
ABot-N0:高德地图出品,VLA基础模型实现“大一统”
来自高德地图AI Lab的ABot-N0提出了一个统一的VLA基础模型,能够同时处理5大核心导航任务:
目标点导航、物体导航、指令跟随、兴趣点导航和行人跟随。
为了支撑如此宏大的目标,他们构建了ABot-N0数据引擎,包含了在7802个高保真3D场景中收集的1690万条专家轨迹和500万个推理样本。
其核心架构是分层的“大脑-动作”体系:一个基于LLM的“认知大脑”负责高级语义推理,一个基于流匹配(Flow Matching)的“动作专家”则负责生成精确、连续的运动轨迹。
这种设计兼顾了高级规划的智能性和底层控制的精确性,在7个主流导航基准上取得了全面的SOTA表现,远超各种“专才”模型。
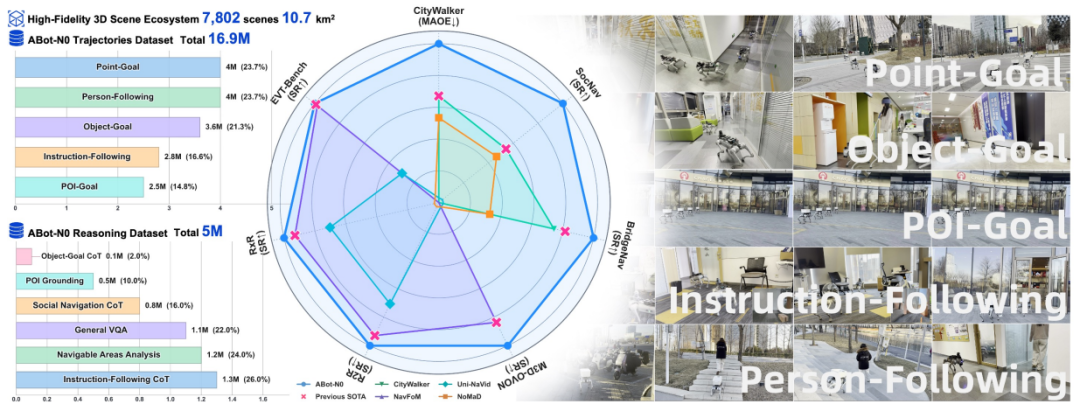
▲图3 | ABot-N0的"大一统"成果全景。 左侧柱状图展示了数据引擎的规模——1690万条专家轨迹和500万推理样本,覆盖点目标、人员跟随、物体目标、指令跟随、兴趣点导航五大任务。中间雷达图直观呈现了ABot-N0(蓝色)在多个基准上全面碾压各路专才模型的强劲表现。右侧则是模型在真实室内外场景中的实际部署效果,证明了"大一统"不只是纸面数据。
One Agent to Guide Them All:显式世界表示,赋能MLLM导航
阿德莱德大学吴琦团队的 GTA (Guide Them All) 框架则另辟蹊径,他们认为:
当前MLLM导航模型将空间感知和语义规划紧密耦合的设计存在缺陷,容易导致错误传播。
为此,研究提出了一种解耦设计。
GTA的核心是引入了一个交互式的度量世界表示(Interactive Metric World Representation)。智能体不再依赖于被动的、文本化的地图,而是可以主动与这个丰富的、持续更新的3D世界模型进行交互和推理。
在此基础上,他们还引入了反事实推理(Counterfactual Reasoning),让MLLM通过“如果……会怎样?”的模拟推演来做出决策,确保了动作的物理有效性。
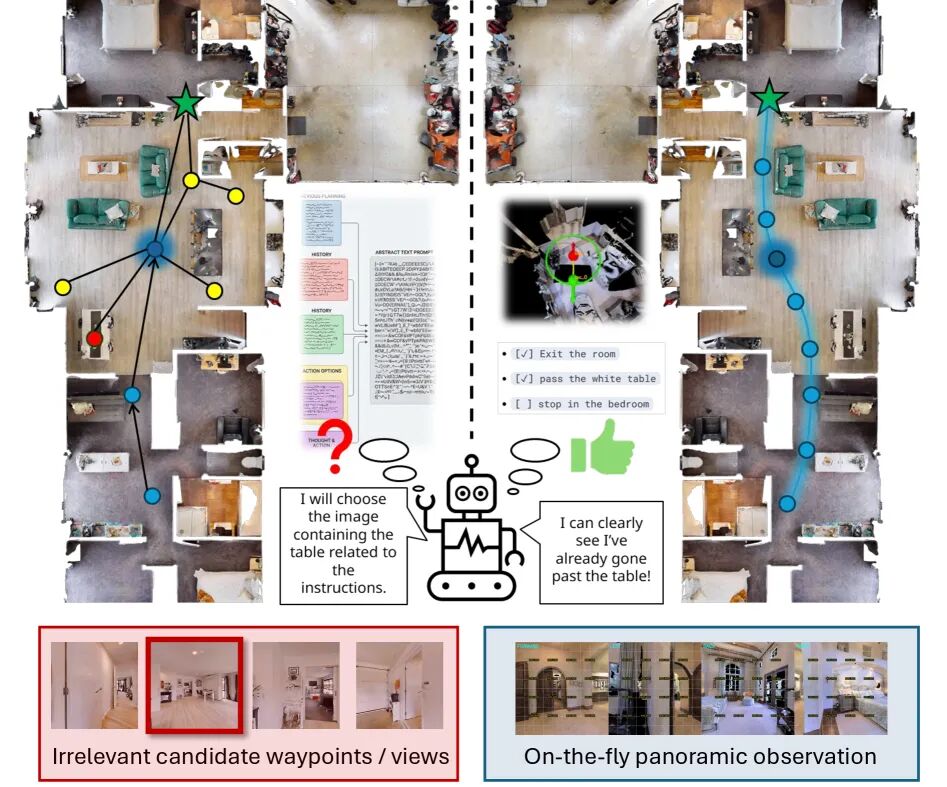
▲图4 | GTA框架的核心创新:解耦空间感知与语义推理。 左图揭示了现有方法的局限——将复杂3D环境压缩为线性文本记忆,导致空间结构信息大量流失。右图的GTA则通过交互式度量世界表示和反事实推理,将空间建模与语义决策彻底分离,使MLLM能够在保留完整空间信息的前提下做出更可靠的导航决策,并成功实现从模拟器到真实机器人的零样本迁移。
DACo:双智能体协作,全局指挥官与局部执行官
新加坡国立大学等团队提出的DACo框架同样采用了“解耦”思想,但实现方式是双智能体协作。
他们将导航任务分解为两个角色:
一个“全局指挥官”(Global Commander)负责高级别的战略规划;
一个“局部执行官”(Local Operative)负责精细的自我中心观察和执行。
这种分工明确的架构,有效缓解了单个智能体的认知过载,提升了长时序导航的稳定性。在R2R、REVERIE和R4R三个数据集上的零样本实验中,DACo相比之前的最佳基线取得了较大的绝对成功率提升,展现了强大的泛化能力。
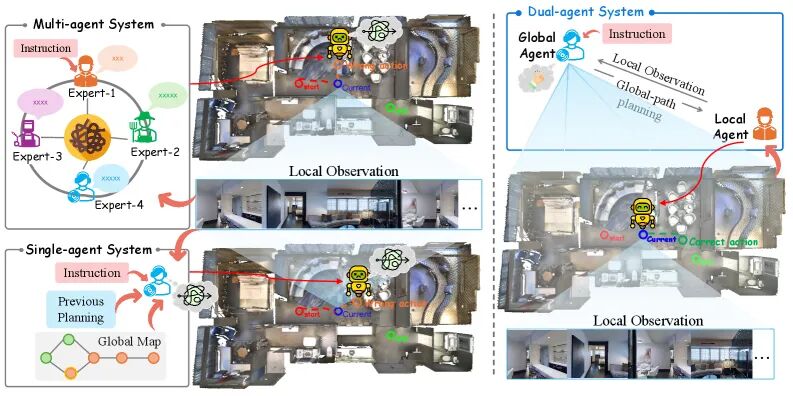
▲图5 | DACo双智能体框架与其他系统的对比。 多智能体系统(上)协调开销大;单智能体系统(下)认知负荷重,容易顾此失彼。DACo(右侧)通过明确的"全局指挥官+局部执行官"角色划分,在简化系统设计的同时,实现了更稳健的长时序导航推理,在R2R、REVERIE、R4R三个数据集上取得了4.9%到6.5%的绝对成功率提升。
03 风向三:强化学习再进化,赋予智能体“远见”
强化学习(RL)一直是VLN的重要技术路线,但传统的RL方法在长时序任务中常常受困于“短视”问题。
2026年的新工作,通过引入多轮对话机制和因果推理,让RL智能体学会了“三思而后行”。
LongNav-R1:多轮强化学习,攻克长时序导航
密歇根大学提出LongNav-R1,应将导航决策过程重新定义为智能体与环境之间的连续多轮对话。
这种多轮RL框架,使得智能体能够推理历史交互的因果关系,并从在线交互中直接学习,从而生成更多样化的轨迹,避免了模仿学习带来的行为僵化。
为了解决长时序任务中的时间信用分配难题,研究还提出了视域自适应策略优化(Horizon-Adaptive Policy Optimization, HAPO),该机制能够在优势估计中明确考虑不同的视域长度,从而实现更精确的长期回报分配。
实验证明,仅用4000条部署轨迹,LongNav-R1就将Qwen3-VL-2B模型的成功率从64.3%提升到了73.0%,展现了极高的样本效率。
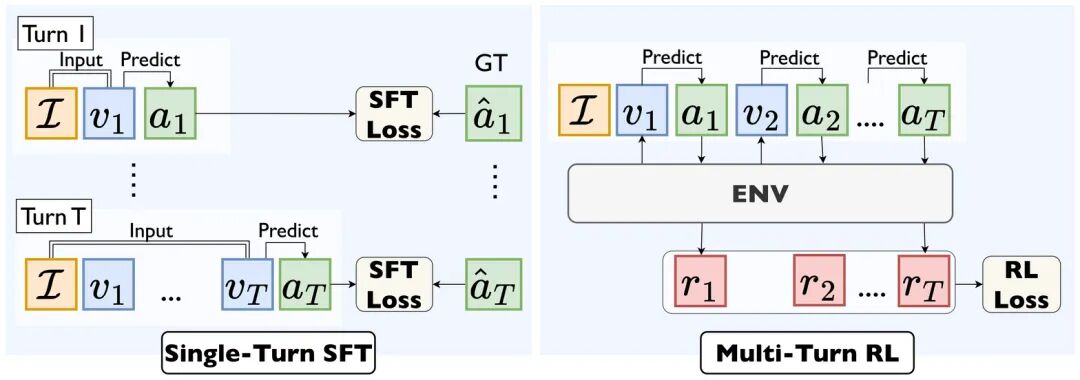
▲图6 | 单轮SFT与多轮RL的本质差异。 左侧的单轮监督微调(SFT)将导航视为孤立的问答,无法建立时序因果推理。右侧的多轮强化学习(RL)则将导航重新定义为与环境的连续对话,智能体能从每次交互中学习动作与长期回报的关联,从而实现更优的探索策略和决策质量
NaVIDA:逆动力学增强,让模型理解“动作的后果”
南方科技大学的 NaVIDA 则从另一个角度切入,他们认为现有模型缺乏对“动作-视觉”因果关系的理解。
为此,他们引入了逆动力学监督(Inverse-Dynamics Supervision, IDS)作为辅助任务,让模型学习视觉变化与相应动作之间的因果联系。
简单来说,就是让模型不仅预测“下一步该做什么”,还要理解“做了这个动作后,世界会变成什么样”。为了给IDS提供更丰富的学习信号,他们还设计了分层概率动作分块(HPAC)机制,将低级原子动作逐步聚合成更高级、更具语义的动作块。这使得模型能够进行更长远的规划。
凭借这一系列创新,NaVIDA用一个3B参数的模型,在VLN-CE基准上超越了之前8B参数的SOTA模型。
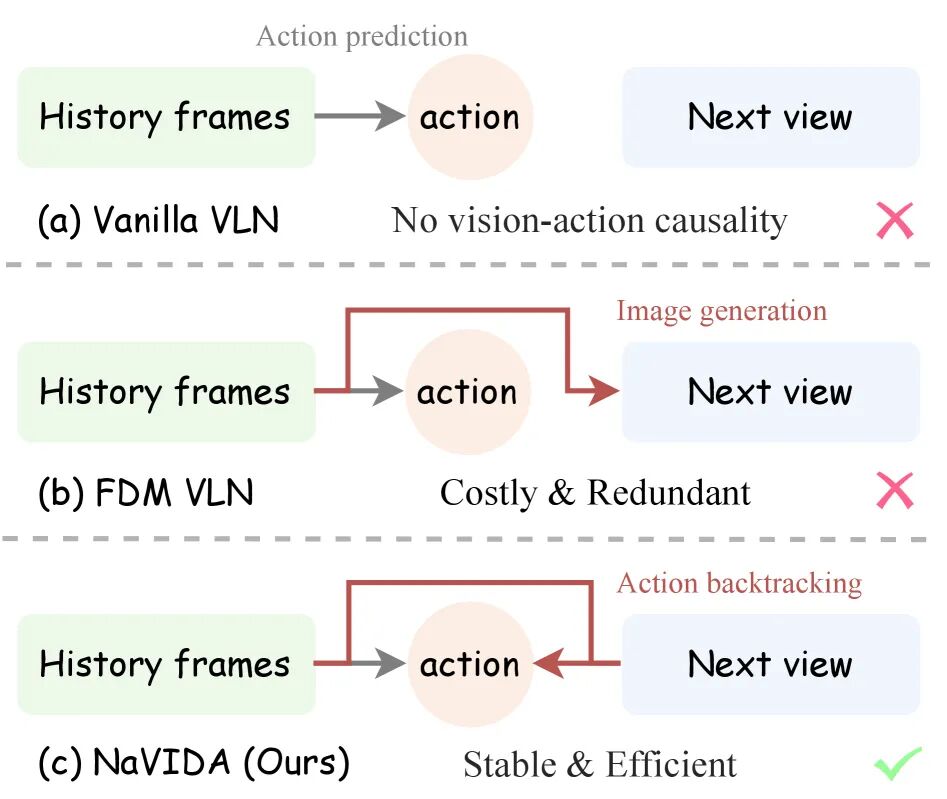
▲图7 | NaVIDA与其他VLN范式的对比。 (a)传统VLN缺乏动作与视觉变化的因果联系;(b)前向动力学模型(FDM)需要生成图像,代价高昂且不稳定;(c)NaVIDA采用逆动力学监督(IDS),直接学习"执行动作后视觉如何变化"的因果关系,既稳定又高效——用3B参数模型超越了8B参数的SOTA,充分证明了因果建模的力量。
04 风向四:垂直场景深耕,从地面到天空,从精确到可靠
随着核心技术的成熟,VLN的研究开始向更具挑战性的垂直场景拓展,从室内走向室外,从地面走向空中,对导航的可靠性和鲁棒性也提出了更高的要求。
AutoFly:为无人机装上“自主导航之眼”
东南大学等团队提出的AutoFly专为无人机在野外的自主导航而设计。他们指出,真实的户外探索往往缺乏详细的导航指令,无人机需要具备自主规划和避障的能力。
为此,AutoFly模型集成了一个伪深度编码器,从RGB图像中提取深度感知特征,以增强空间推理能力。
此外,他们还构建了一个全新的自主导航数据集,强调连续避障、自主规划和识别流程,并包含了大量的真实世界数据,有效弥补了现有数据集的不足。
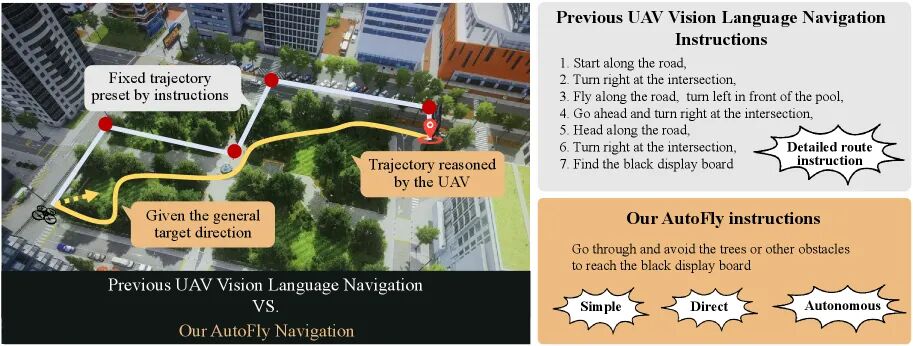
▲图8 | AutoFly与传统无人机VLN的范式对比。
左侧的传统方法依赖详细的逐步指令,无人机只是"按图索骥";
右侧的AutoFly则能在仅有粗略方向指导的情况下,凭借伪深度编码器和自主规划能力,在真实野外环境中完成连续避障和路径规划。
成功率比最先进的VLA基线高出3.9%,且在模拟与真实环境中均表现稳定。
DGNav:动态拓扑感知,打破导航图的“粒度僵化”
在连续环境中,基于拓扑地图的导航方法一直备受青睐。然而,现有方法通常使用固定的几何阈值来构建拓扑图,导致在简单区域节点过于密集(计算冗余),在复杂区域又过于稀疏(容易碰撞)。
针对这一“粒度僵化”问题,中科院提出DGNav,一种动态拓扑导航框架。
DGNav的核心是场景感知的自适应策略,它能根据预测路点的离散程度,动态调整图的构建阈值,在复杂环境中“按需加密”拓扑节点。
同时,一个动态图Transformer会融合视觉、语言和几何线索,重构图的连接性,滤除拓扑噪声。这一系列操作,使得导航在效率和安全性之间达到了更优的平衡。

▲图9 | DGNav动态拓扑导航框架概览。 针对"粒度僵化"问题,DGNav能根据场景复杂度(简单区域 vs 复杂区域)动态调整拓扑图的构建密度——在简单区域保持稀疏以节省计算,在复杂区域"按需加密"以保障安全。动态图Transformer进一步融合视觉、语言和几何线索,滤除拓扑噪声,在R2R-CE和RxR-CE两个基准上均取得了效率与安全性的最优平衡。
DV-VLN:双重验证,提升LLM导航的可靠性
浙江师范大学等团队提出的DV-VLN则聚焦于提升LLM导航的可靠性。
研究发现,LLM在做单步决策时,容易受到噪声和不完美推理的影响,导致错误累积。为此,他们提出了一个“生成-然后-验证”(Generate-then-Verify)的范式。
DV-VLN首先让LLM生成一个结构化的导航思维链,然后通过两个互补的通道进行验证:真假验证(True-False Verification)和掩码实体验证(Masked-Entity Verification)。
通过聚合多次采样的验证结果,DV-VLN能够为候选动作打出可解释的分数,并进行重排序,从而选出最可靠的下一步行动。实验证明,该方法在R2R、RxR和REVERIE等多个基准上,都显著优于直接预测的基线模型。
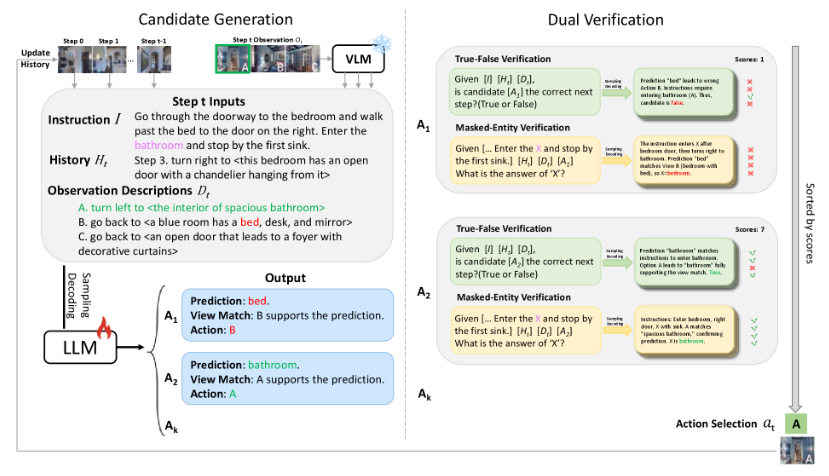
▲图10 | DV-VLN完整框架流程图。 在每个时间步,视觉-文本模块将全景观察转化为文字描述,LLM据此生成包含"预测-视角匹配-动作"三步推理链的K个候选动作;随后双重验证模块(TFV+MEV)对每个候选进行多次采样验证并打分,最终按分数排名选出最可靠的动作执行。
05 总结与延伸
综上所述,VLN领域呈现出四大清晰且令人振奋的研究风向。
-
视频生成模型的引入,为智能体赋予了前所未有的“想象力”,使其能够规划更长远的未来;
-
MLLM/VLA的“大一统”趋势,则预示着一个通用具身智能时代的到来,模型的能力边界被极大地拓宽;
-
强化学习的深化,通过引入多轮交互和因果推理,正在解决长期困扰VLN的短视和泛化难题;
-
面向垂直场景的深耕,则标志着VLN技术正从实验室走向更广阔、更复杂的真实世界应用。
这四大风向并非孤立发展,而是相互交织,共同推动着VLN技术迈向新的“奇点”。
可以预见的是,未来的VLN智能体,将是一个既能“仰望星空”(进行长远规划和想象),又能“脚踏实地”(在复杂环境中精确执行)的通用物理世界助手。
Ref
1. SparseVideoNav: Sparse Video Generation Propels Real-World Beyond-the-View Vision-Language Navigation
2. NavDreamer: Video Models as Zero-Shot 3D Navigators
3. ABot-N0: VLA Foundation Model for Versatile Embodied Navigation
4. One Agent to Guide Them All: Empowering MLLMs for VLN via Explicit World Representation
5. DACo: Global Commander and Local Operative: A Dual-Agent Framework for Scene Navigation
6. LongNav-R1: Horizon-Adaptive Multi-Turn RL for Long-Horizon VLA Navigation
7. NaVIDA: VLN with Inverse Dynamics Augmentation
8. AutoFly: VLA Model for UAV Autonomous Navigation in the Wild
9. DGNav: Breaking the Granularity Rigidity in VLN
10. DV-VLN: Dual Verification for Reliable LLM-Based VLN

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)