Cursor 频繁限流、模型切换困难?三分钟接入 API 中转站彻底解决(附 Claude 4.6 / Gemini-3 配置教程)
用 Cursor 写代码的开发者,多多少少都踩过这几个坑:正在跑一个大型重构任务,Claude 3.5 Sonnet 突然触发速率限制,整个 Composer 流程卡死;想试试刚发布的 Claude 4.6 Opus,发现官方订阅根本没有入口;或者直连官方 API 延迟抖动,补全响应慢得像在等外卖。这些问题的根源都指向同一个地方——Cursor 默认的模型接入方式太死。本文记录的解法是:通过修改 Cursor 的 Base URL,将请求接入兼容 OpenAI 协议的 API 中转站,从而同时解决限流、模型选择和响应稳定性三个问题。
一、问题拆解:Cursor 的三个典型痛点
在动手配置之前,先把问题说清楚,方便你判断这套方案是否对症。
痛点一:主力模型限流
Cursor 的 Pro 订阅对 Claude 系列模型有请求频率上限,重度用户(尤其是跑 Agent 模式或大文件 Composer 的场景)很容易在工作日高峰期触发限制,被迫降级到响应质量更差的备用模型。
痛点二:无法使用最新模型
官方订阅的模型列表更新有延迟,而且部分新模型(如 Claude 4.6 Opus、GPT-5.3)在官方渠道需要等待灰度开放。通过自定义 Base URL 接入中转站,可以直接调用这些模型,不受官方订阅计划的限制。
痛点三:直连延迟不稳定
在某些网络环境下,直连官方 API 的响应时间波动较大,代码补全出现明显卡顿。中转站通常在多个地区部署了节点,请求会自动路由到响应最快的节点,实际体验比直连更稳定。
二、解决方案原理:Cursor 的自定义 Base URL 机制
Cursor 内置了一个 Override OpenAI Base URL 的配置项,允许开发者将所有 API 请求指向任意兼容 OpenAI 协议的接口地址。只要中转站实现了 /v1/chat/completions 等标准端点,Cursor 就能无缝对接,感知不到任何差异。
- 零代码改动:不需要修改任何项目文件,只改 Cursor 设置
- 协议完全兼容:Claude、Gemini、DeepSeek 等非 OpenAI 模型,通过中转站统一转换为 OpenAI 协议格式,Cursor 可以直接调用
- 模型自由切换:在 Cursor 的 Models 列表中手动添加模型 ID,即可在 Composer 和 Chat 中随时切换
三、配置步骤:三分钟完成接入
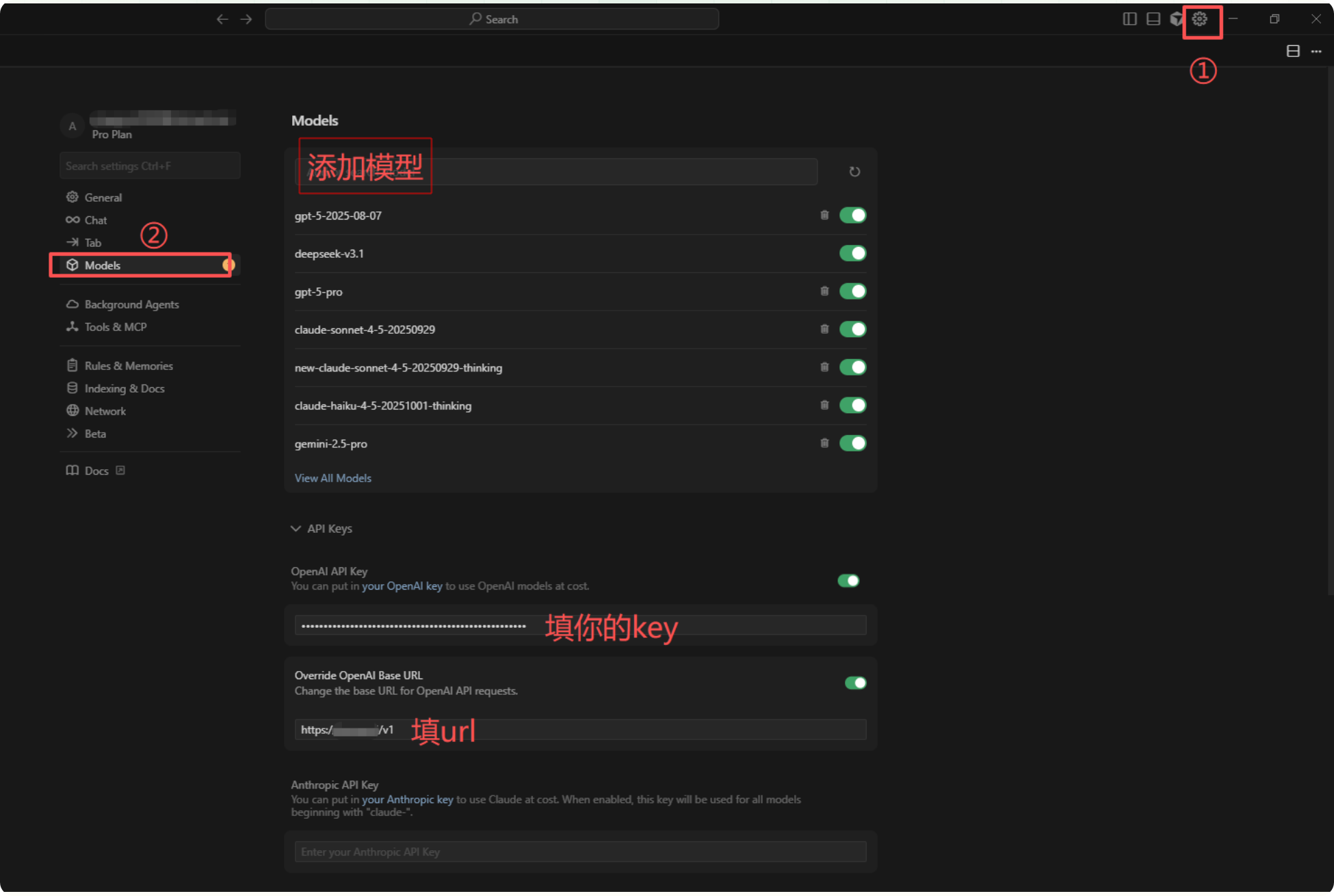
3.1 打开 Cursor 设置
点击 Cursor 右上角的齿轮图标,进入设置中心。
3.2 进入 Models 管理页
在左侧菜单选择 Models 选项卡,这里集中管理所有 AI 模型和 API 凭据。
3.3 添加目标模型
在模型输入框中,手动添加你想使用的模型名称。以下是几个常用模型 ID:
# 直接在 Cursor Models 输入框中填入以下模型 ID(每行一个)
claude-4-6-opus # Claude 4.6 Opus,适合复杂推理和大型重构
claude-sonnet-4-5 # Claude Sonnet 4.5,日常编程性价比较高
gemini-3-pro # Gemini 2.5 Pro,超长上下文场景适用
添加后,确保每个模型右侧的开关处于启用状态,否则在 Composer 中不会出现在可选列表里。
3.4 填写 API Key
在 OpenAI API Key 输入框中,填入你从中转站获取的 API Key,格式通常为 sk- 开头的字符串。
3.5 修改 Base URL(核心步骤)
勾选 Override OpenAI Base URL,将地址修改为:
<https://api.88api.shop/v1>
注意末尾必须带 /v1,这是 OpenAI 协议的标准路径前缀,缺少会导致请求 404。
3.6 验证连接
点击 Verify 按钮,如果提示验证成功,说明 API Key 和 Base URL 均配置正确。此时在 Cursor Chat 或 Composer 中选择你刚添加的模型,发送一条测试消息即可确认端到端连通。
四、进阶用法:用脚本批量测试模型响应质量
配置完成后,很多开发者会想对比不同模型在特定任务上的表现。以下是一个 Python 脚本,可以批量向多个模型发送相同的代码问题,对比响应质量和耗时:
import openai
import time
from typing import List, Dict
# 初始化客户端,指向中转站地址
client = openai.OpenAI(
api_key="sk-your-api-key-here", # 替换为你的真实 API Key
base_url="<https://api.88api.shop/v1>" # 中转站 Base URL
)
def test_model(model_id: str, prompt: str) -> Dict:
"""
向指定模型发送请求并记录响应时间
:param model_id: 模型 ID,如 "claude-4-6-opus"
:param prompt: 测试用的代码问题
:return: 包含响应内容和耗时的字典
"""
start_time = time.time()
try:
response = client.chat.completions.create(
model=model_id,
messages=[
{
"role": "system",
"content": "你是一位资深 Python 开发工程师,请给出简洁、可运行的代码答案。"
},
{
"role": "user",
"content": prompt
}
],
max_tokens=1024,
temperature=0.2 # 代码类任务建议低温度,输出更稳定
)
elapsed = round(time.time() - start_time, 2)
content = response.choices[0].message.content
return {
"model": model_id,
"status": "success",
"elapsed_seconds": elapsed,
"tokens_used": response.usage.total_tokens,
"response_preview": content[:200] # 只取前 200 字用于预览
}
except Exception as e:
# 捕获异常,记录失败原因,不中断批量测试流程
return {
"model": model_id,
"status": "failed",
"error": str(e)
}
def batch_test(models: List[str], prompt: str) -> None:
"""
批量测试多个模型,打印对比结果
:param models: 模型 ID 列表
:param prompt: 统一的测试问题
"""
print(f"测试问题:{prompt}\\\\n{'='*60}")
for model in models:
print(f"\\\\n▶ 正在测试模型:{model}")
result = test_model(model, prompt)
if result["status"] == "success":
print(f" ✅ 响应耗时:{result['elapsed_seconds']}s")
print(f" 📊 Token 消耗:{result['tokens_used']}")
print(f" 📝 响应预览:{result['response_preview']}...")
else:
print(f" ❌ 请求失败:{result['error']}")
if __name__ == "__main__":
# 待测试的模型列表,按需增减
target_models = [
"claude-4-6-opus",
"gpt-5.3",
"deepseek-v3"
]
# 测试问题:一个典型的代码重构场景
test_prompt = """
以下函数存在性能问题,请重构并说明优化点:
def find_duplicates(lst):
duplicates = []
for i in range(len(lst)):
for j in range(i + 1, len(lst)):
if lst[i] == lst[j] and lst[i] not in duplicates:
duplicates.append(lst[i])
return duplicates
"""
batch_test(target_models, test_prompt)
这个脚本的实用价值在于:你可以用自己项目中的真实代码问题作为 test_prompt,对比不同模型的响应质量和 Token 消耗,从而为 Cursor 选出最适合当前项目的主力模型。
五、常见报错与排查
验证失败(Authentication Error)
检查 API Key 是否复制完整,注意不要包含首尾空格。部分编辑器在粘贴时会自动加入换行符,建议手动确认。
模型未出现在 Composer 下拉列表
在 Cursor Models 页面,确认手动添加的模型 ID 右侧开关已打开。如果开关是灰色的,说明该模型 ID 格式有误,检查是否与中转站支持的模型名称完全一致。
请求返回 404
Base URL 末尾缺少 /v1,或者多了一个斜杠(如 https://api.88api.shop/v1/),标准格式应为 https://api.88api.shop/v1,不带末尾斜杠。
响应内容截断
说明 max_tokens 设置过低,或者该模型在中转站的单次输出上限低于你的预期。可以在 Cursor 的高级设置中调整 Max Tokens 参数。
六、不同场景下的模型选择建议
接入中转站之后,面对 Cursor 里一长串模型列表,很多开发者反而不知道该选哪个。以下是根据实际编程场景整理的参考:
| 使用场景 | 推荐模型 | 原因 |
|---|---|---|
| 大型代码库重构 / Agent 模式 | Claude 4.6 Opus | 长上下文理解能力强,多步骤任务稳定 |
| 日常代码补全 / 函数生成 | Claude Sonnet 4.5 | 响应速度快,性价比高 |
| 超长文件分析 / 文档生成 | Gemini 3 Pro | 上下文窗口大,适合大文件输入 |
| 高频重复性任务 / 注释生成 | DeepSeek V3 | Token 成本最低,适合批量处理 |
结语
Cursor 的自定义 Base URL 功能本质上是一个开放接口,给了开发者自由选择模型后端的空间。配置完成后,限流、模型选择受限、延迟抖动这三个问题可以同时得到缓解,而且整个过程不涉及任何代码改动,改回官方直连也只需要清空 Base URL 配置。对于每天重度依赖 Cursor 的开发者来说,这个十分钟的配置值得做一次。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)