机器学习Class3 ——批次标准化(Batch Normalization)简介
一、batch normalization——training
当error surface(误差曲面)比较崎岖的时候很难train,那我们可以通过什么方式来将其“铲平”呢?Batch Normalization就是一种很好的方式。
当我们遇到两个未知参数的斜率相差很大的时候,就应该思考,这是由什么导致的?
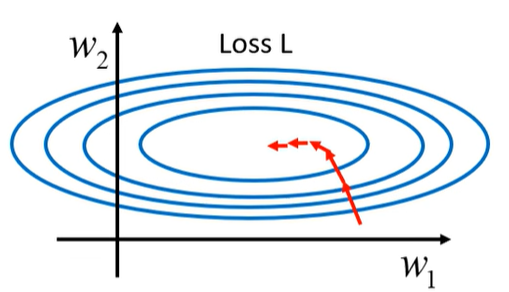
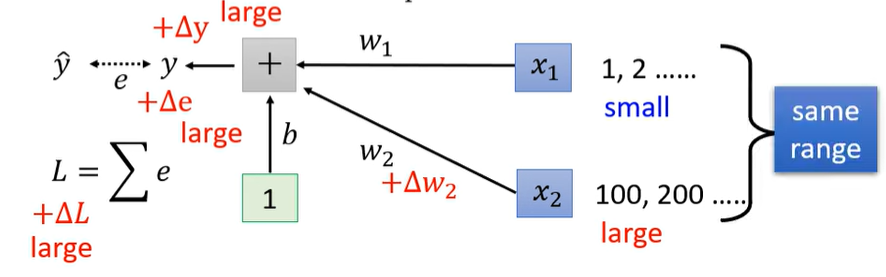
已知当权重 W_1 发生一个很小的变化时,模型输出 y会随之发生改变,进而导致误差 e 的变化,并最终影响损失函数 L 的值。如果输入特征 X_1 的数值较小,那么由于 W_1 与 X_1 是直接相乘的关系,即使 W_1 发生一定的变化,对输出 y 的影响也会较小,因此损失函数 L 的变化量也相对较小。相反,如果输入特征 X_2的数值较大,即使权重 W_2的变化幅度很小,也可能对输出 y 产生较大的影响,从而导致损失函数 L 出现较大的变化。这就解释上图两个未知参数坡度非常不同的error surface产生的原因。如果可以给不同的dimension相同的数值范围的话,我们就可以制造比较好的error surface了,让training变得更为容易。
想要实现这一目的,有很多不同的方法,他们统称为feature normalization(特征归一化)。现在我们来了解feature normalization的一种可能性:
假设x^1到x^R是所有训练资料的feature vector(特征向量),我们把不同特征向量中同一个dimension(特征的维度)里面的数值取出来,去计算某一个dimension的mean(平均值)以及其standard deviation(标准差)。那么现在就可以来做一种normalization(标准化)
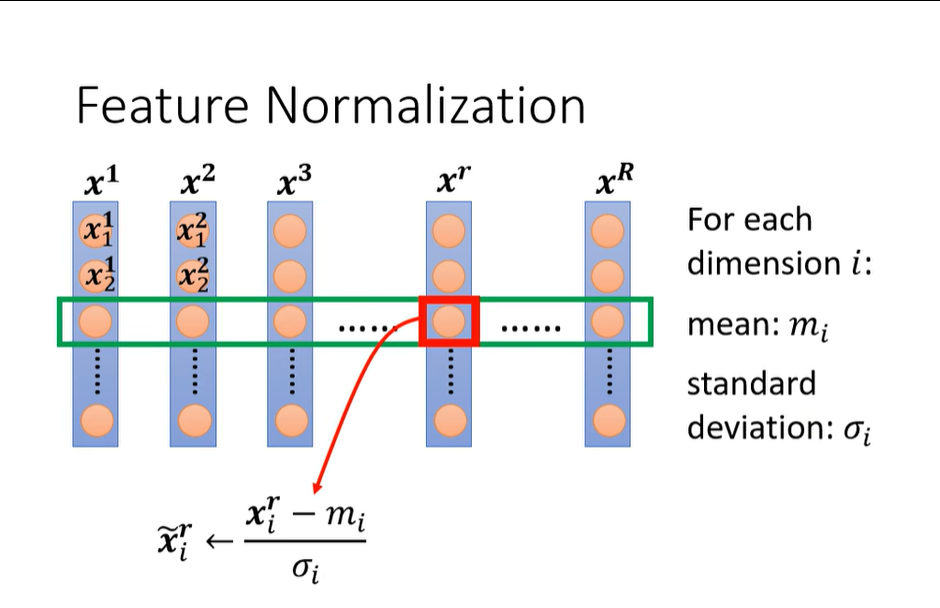
这么做的好处是,这个dimension上数值的平均值会由此变为0,其 variance(方差)将会变成1(但工程上这两者会因为浮点计算误差等多种原因,导致最后只有接近0或1的效果)。我们对每一个dimension都做同样的操作,那么我们可以得到一个比较好的error surface。所以像这样的feature normalization的方式,往往对我们的training更有帮助,可以使我们在做gradient descent 的时候,loss更快的收敛。
于是我们可以将做过feature normalization的丢到network里面,做接下来的运算。把标准化后的输入特征
输入到神经网络的第一层,经过线性计算后得到输出z_1,
,再通过activate function(激活函数),无论是sigmoid或是relu都可以,然后再得到a_1,再通过下一层,对每一个x都做相同操作(有几层network就做多少层运算)……
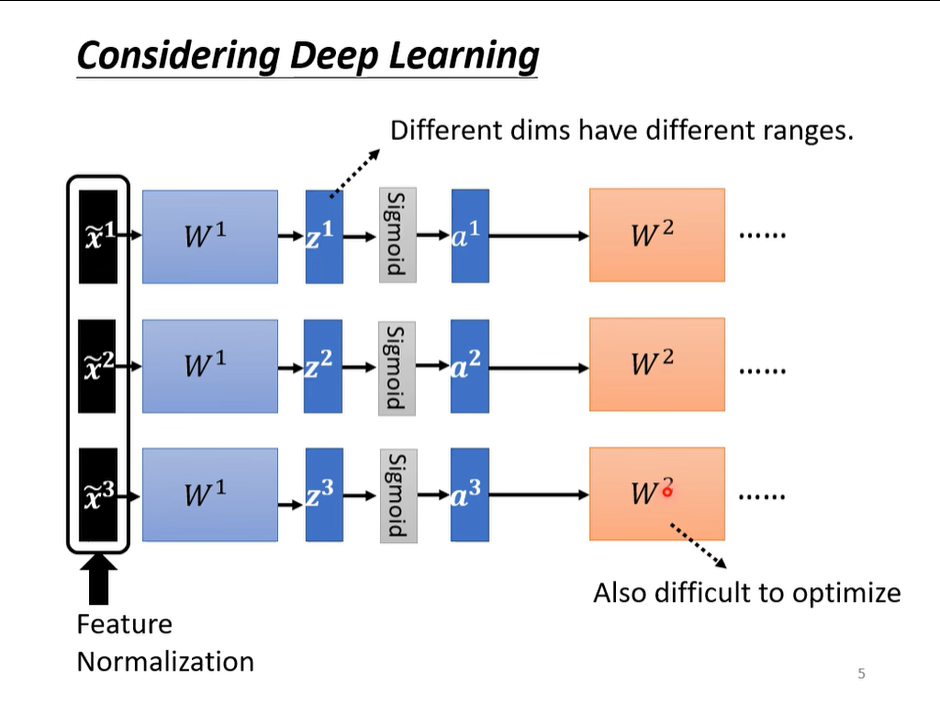
但是我们仔细来想,对于w^2而言,a^2和z^2也可以看作是input。即使是normalization过的,但是在经过一系列操作后得到的z^2和a^2是没有标准化过的。如果得到的z之间的差距是很大的,用其来训练第二层的w,可能又会遇到困难。所以,对z和a,也要进行feature normalization。
这个时候又有问题了,我们到底应该在activate function之前还是之后进行标准化呢?其实际上两者的差距并不大,但是在使用sigmoid的时候更建议对z进行normalization。
我们从前可能的network都是一个iniput得到一个output,但是这里是一堆input得到一堆output,并且要把计算和
的过程也放在这个network里面,所以这可能将会是一个巨大的network。但是我们的gpu可能没有办法一次性处理这么多数据集,所以我们在实作的时候只考虑一个batch里面的example。因为我们实作的时候是对每一个batch做normalization,所以这个方法叫做batch normalization(但是我们要有够大的batch set 才可以算出这个\mu和\sigma,才举一表示整个corpus的分布)。
我们在做batch normalization的时候往往还会有这样的设计:在一个mini-batch中,每个样本经过权重W^1得到线性输出Z^1。然后对这一批的Z^i计算均值\mu和标准差\sigma,并对Z^i进行标准化:
之后再通过可学习参数\gamma和\beta进行线性变换:
从而恢复模型的表达能力,并将结构传递到下一层网络。
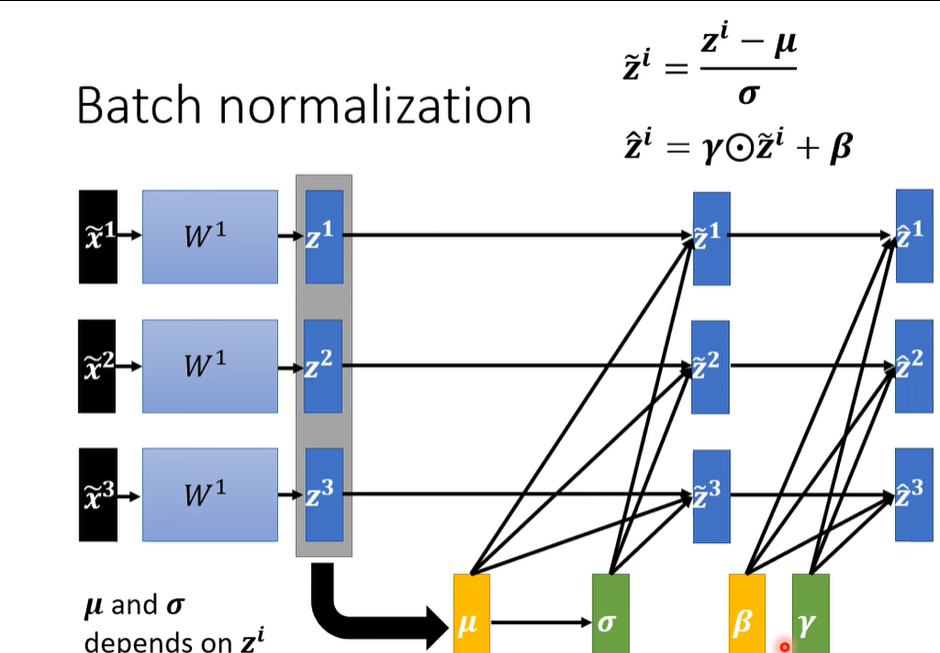
同时,\beta和\gamma在这里被看作另外一组参数,是需要另外一个模型训练出来的。beta调整数据的方差,beta调整数据的均值,让标准化后的数据变成更适合神经网络学习的形式。
这时我们就很容易想到,我们做normalization不就是为了让每一个不同的dimension的range都一样吗?那这里乘上γ又加上β,那不同dimension的分布不是又不一样了吗?这是有可能的,但是我们在实际训练的时候,γ的初始值设成1,β的初始值设为0,这样在训练开始时数据任然保持标准化后的分布,而在后续训过程中,模型可以通过学习逐渐调整β和γ,从而得到更适合当前任务的数据分布。
二、batch normalization——testing(inference)
当我们在做实际testing的时候,不可能等到每一个batch都集齐了再做testing,而是每一笔资料进来都要做一次。但是我们的\mu和\sigma又需要一个完整的batch才能计算出来,这时候应该如何来处理呢?
这个问题pytorch已经帮我们处理好了,如果我们有做batch normalization,在training的时候,每一个计算出来的\mu和\sigmma都会拿来算moving average(滑动平均)。意思就是取第一个batch的时候就会算一个,取第二个batch的时候就会算一个
,以此类推,直到取第t个batch的时候算
,然后算其moving average,具体公式如下:
其中表示当前保存的全局平均值;
表示第t次batch的均值;p是一个也需要训练的常数,在pytorch里设定好取0.1。整个公司的大致意思就是:新的品均值=某一比例过去的品均值+(1-该比例)当前batch的平均值。然后我们在testing的时候就不用再计算\mu和\sigmma了,直接用
和
来取代就好了。
三、为什么batch normalization会有作用
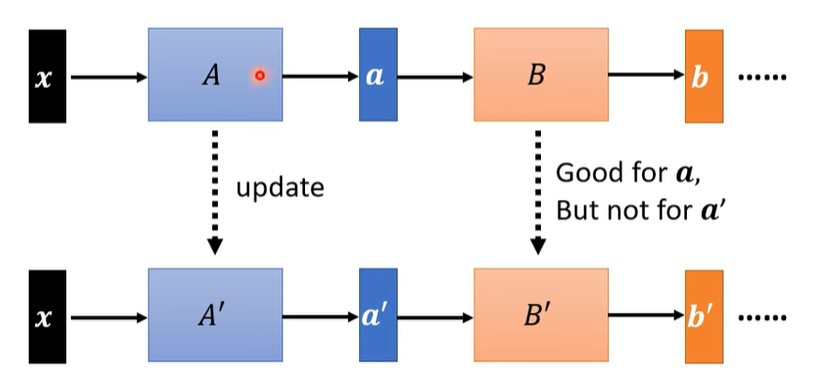
network有很多层,x通过第一层得到a,a经过第二层得到b。经过gradient之后,把A update成A’,把B update成B'。但是当第一层 A更新为 A′ 时,它的输出从 a变成了 a′,导致后面的层 B接收到的输入分布发生变化。原本 B 是针对 a 训练好的,但面对新的 a′ 就不再适应,从而影响整体模型性能。这种前一层变化影响后一层的现象会让训练变得不稳定,而 Batch Normalization 的作用就是让这些中间输出的分布保持稳定。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)