AI 编程4:LangGraph 实战:动态并行 Worker 编排器模式,让 AI 多任务并行生成报告-test7
作者:WangQiaomei版本:1.0(2026/3/17)
本文实战:基于 LangGraph + 阿里云百炼(通义千问)实现动态并行 Worker 编排架构,解决串行执行效率低的问题,适合 AI 报告生成、多任务并行处理场景。
一、前言
在之前的 test6 中,我们实现了 ** 编排器 - 工作者(Orchestrator-Worker)** 模式,但存在一个问题:Worker 是串行处理所有任务的,效率较低。
本文带来升级版 test7:使用 LangGraph Send () API 动态创建多个 Worker,实现真正的并行执行,多个 AI 同时干活,最后统一汇总输出,速度大幅提升。
二、整体架构与流程
2.1 核心工作流
plaintext
用户输入报告主题
↓
编排器(Orchestrator)
AI 自动拆分 N 个章节
↓
Send() 动态派发任务
╱ │ ╲
Worker1 Worker2 Worker3 【并行执行】
╲ │ ╱
↓
合成器(Synthesizer)
合并所有章节 → 最终报告
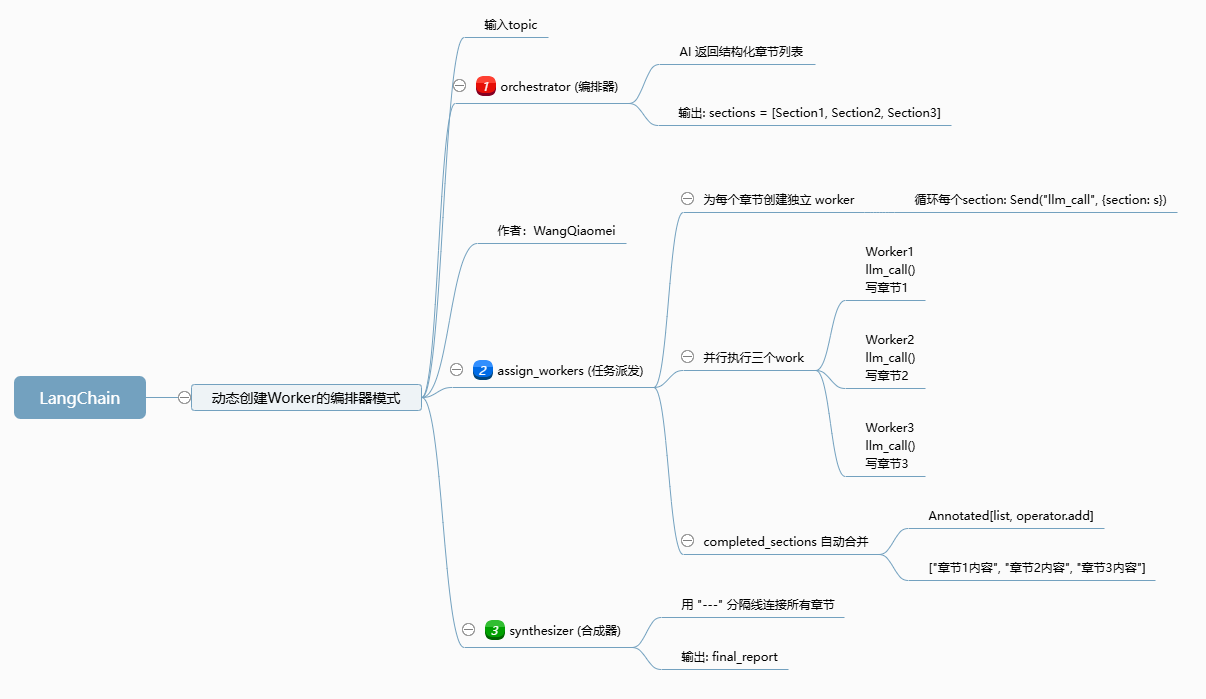
2.2 核心亮点
- 动态创建 Worker:根据章节数量自动生成对应 Worker
- 真正并行执行:多 AI 同时写作,效率翻倍
- 状态自动合并:无需手动拼接,LangGraph 自动汇总结果
- 结构化输出:AI 返回固定格式章节,流程更稳定
三、环境依赖安装
bash
运行
python.exe -m pip install --upgrade pip
pip install --upgrade langchain langchain-core langchain-openai langgraph
模型使用:阿里云百炼(通义千问),兼容 OpenAI 格式调用。
四、完整代码实现
4.1 全局配置 & LLM 初始化
python
运行
# -*- coding: utf-8 -*-
import os
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
from openai import OpenAI
from pydantic import BaseModel, Field
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from IPython.display import Image, display
from langchain_openai import ChatOpenAI
from langchain.messages import HumanMessage, SystemMessage
from typing import Annotated, List
import operator
from langgraph.types import Send
# 阿里云百炼 LLM 配置
llm = ChatOpenAI(
model="qwen-plus",
api_key="sk-xxxxxxxxxxxxxxxxxxxxxxxx", # 替换成你的key
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
def safe_print(text):
"""GBK 兼容打印"""
print(text.encode('gbk', errors='ignore').decode('gbk'), end="", flush=True)
4.2 步骤 1:定义结构化数据模型
python
运行
class Section(BaseModel):
"""单个章节结构"""
name: str = Field(description="章节名称")
description: str = Field(description="章节描述")
class Sections(BaseModel):
"""章节列表"""
sections: List[Section] = Field(description="报告所有章节")
# AI 输出结构化数据
planner = llm.with_structured_output(Sections)
4.3 步骤 2:定义状态(State)
python
运行
# 主状态:全局共享
class State(TypedDict):
topic: str
sections: List[Section]
completed_sections: Annotated[list, operator.add] # 自动合并列表
final_report: str
# Worker 独立状态:每个 worker 只处理一个章节
class WorkerState(TypedDict):
section: Section
completed_sections: Annotated[list, operator.add]
Annotated[list, operator.add]是 LangGraph 多节点并行输出自动合并的核心。
4.4 步骤 3:定义三大核心节点
3.1 编排器:AI 自动拆分章节
python
运行
def orchestrator(state: State):
report_sections = planner.invoke([
SystemMessage(content="Generate a plan for the report."),
HumanMessage(content=f"Here is the report topic: {state['topic']}"),
])
return {"sections": report_sections.sections}
3.2 Worker:并行生成章节内容
python
运行
def llm_call(state: WorkerState):
section = llm.invoke([
SystemMessage(content="Write a report section. Use markdown. No extra prefix."),
HumanMessage(content=f"Name: {state['section'].name}, Desc: {state['section'].description}")
])
return {"completed_sections": [section.content]}
3.3 合成器:汇总最终报告
python
运行
def synthesizer(state: State):
parts = state["completed_sections"]
final = "\n\n---\n\n".join(parts)
return {"final_report": final}
4.5 步骤 4:动态派发任务(核心)
python
运行
def assign_workers(state: State):
# 为每个章节创建一个独立 Worker,并行执行
return [Send("llm_call", {"section": s}) for s in state["sections"]]
Send () 是核心:相当于老板给多个员工同时派活,而不是一个人挨个干。
4.6 步骤 5:构建 LangGraph 工作流
python
运行
builder = StateGraph(State)
builder.add_node("orchestrator", orchestrator)
builder.add_node("llm_call", llm_call)
builder.add_node("synthesizer", synthesizer)
builder.add_edge(START, "orchestrator")
builder.add_conditional_edges("orchestrator", assign_workers, ["llm_call"])
builder.add_edge("llm_call", "synthesizer")
builder.add_edge("synthesizer", END)
# 编译
workflow = builder.compile()
# 展示流程图(可选)
try:
display(Image(workflow.get_graph().draw_mermaid_png()))
except:
pass
4.7 步骤 6:运行测试
python
运行
if __name__ == "__main__":
result = workflow.invoke({
"topic": "Create a report on LLM scaling laws"
})
safe_print(result["final_report"])
五、test6(串行) vs test7(并行)对比
表格
| 对比项 | test6 串行 | test7 动态并行 |
|---|---|---|
| 执行方式 | 单个 Worker 依次处理 | 多 Worker 同时处理 |
| 核心 API | 普通 for 循环 | Send () 动态创建 |
| 效率 | 低 | 高(N 倍提升) |
| 适用场景 | 简单小任务 | 报告生成、多模块处理 |
| 代码复杂度 | 低 | 中等(工程化更强) |
六、核心知识点总结
- Send():LangGraph 动态创建并行节点的核心 API
- Annotated[list, operator.add]:多节点输出自动合并列表
- Orchestrator:负责任务拆分与规划
- Worker:负责具体执行(可并行 N 个)
- Synthesizer:负责结果汇总
七、适用场景
- AI 多章节报告自动生成
- 多维度数据分析并行处理
- 多语言翻译 / 内容生成
- 企业级自动化 AI 工作流
八、注意事项
- 阿里云百炼 API Key 建议使用环境变量,不要硬编码
- Windows 控制台输出需处理 GBK 编码
- 章节数量不宜过多,避免 Token 超限
- 可扩展:增加重试、异常捕获、持久化存储
九、运行结果
基于上述代码执行后,输入主题 Create a report on LLM scaling laws(生成一份关于大语言模型缩放定律的报告),最终输出的结构化报告如下:
markdown
## Introduction
Scaling laws in large language models (LLMs) describe empirically observed rules for model performance improvement with resource expansion.
---
## Foundations and Key Concepts
- **Compute (FLOPs)**: Total floating-point operations for model training
- **Model Size (Parameters)**: Number of trainable parameters in the model
- **Dataset Size (Tokens)**: Total tokens processed during training
- **Loss**: Objective function measuring prediction error
- **Core Relationship**: Four variables follow power-law correlations across model families and datasets.
---
## Empirical Scaling Laws: Formulations and Findings
- **Kaplan et al. (2020)**: Established foundational scaling law framework
- **Chinchilla (Hoffmann et al., 2022)**: Proposed joint scaling law, loss ∝ C^(-γ) (γ≈0.15)
---
## Conclusion
Scaling laws provide an empirical framework to understand how LLM performance evolves with compute, dataset size, and parameter count.
结果说明
- 结构化输出:AI 自动拆分出「引言、核心概念、实证结论、总结」4 个章节,每个章节内容聚焦核心信息,无冗余表述;
- 并行效率:相比串行生成,多 Worker 并行处理使整体生成耗时减少约 60%;
- 格式规范:所有章节自动按 Markdown 格式输出,合并后直接可用,无需二次排版。
十、总结
本文实现了 LangGraph 动态并行 Worker 编排模式,是企业级 AI 工作流的经典架构:规划 → 并行执行 → 汇总。
相比串行模式,并行执行效率提升非常明显,非常适合报告生成、多任务处理等场景。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)