YOLOv8(5)训练结果解释
文章目录
训练结果存储位置
训练结果通常存放在工作目录的 runs\detect子目录中。 例如下图,其中train_n为第n次训练的结果。
针对目录中每一个文件 / 文件夹的详细含义解读,按功能分类整理:
- 核心配置与权重文件 (Weights & Config)
这些是模型训练的产物,用于后续的推理(预测)或迁移学习。
weights:存放训练过程中生成的模型权重文件。
通常包含 best.pt(验证集性能最好的权重)和 last.pt(训练最后一轮的权重)。
args.yaml:训练时的超参数配置文件。记录了本次训练的所有设置,比如数据集路径、批次大小(batch size)、学习率、训练轮数(epochs)、网络深度等。用于复现实验结果。
- 模型性能可视化图表 (Metrics & Curves)
这些是最直观的指标图片,用于分析模型训练的好坏及是否存在过拟合 / 欠拟合。
BoxF1_curve.png:目标框(Box)的 F1 分数曲线。F1 分数是精确率(Precision)和召回率(Recall)的调和平均,曲线越高代表模型对目标框的回归越准确。
BoxP_curve.png:目标框的精确率(Precision)曲线。代表预测出来的框里有多少是准确的。
BoxPR_curve.png:P-R 曲线(Precision-Recall Curve)。这是评估目标检测模型最核心的曲线之一,图下的面积(AP)衡量了模型在不同召回率下的精确表现。
BoxR_curve.png:目标框的召回率(Recall)曲线。代表所有真实目标被模型找出来的比例。
results.png:综合指标汇总图。将所有指标(损失值、mAP、P/R、F1 等)整合在一张图中,方便快速查看训练趋势。
- 混淆矩阵 (Confusion Matrix)
用于分析模型具体在哪些类别上容易认错。
confusion_matrix.png:原始混淆矩阵。横轴是预测类别,纵轴是真实类别。
confusion_matrix_normalized.png:归一化后的混淆矩阵。将数值按比例缩放,更适合看多类别之间的误分类比例,而非绝对数量。
labels.jpg:标签可视化示例图。展示数据集中标注的标签长什么样,通常包含了框和类别名,用于检查标注是否正常。
- 训练结果数据 (Logs & Data)
results.csv:训练过程中的日志数据。记录了每一代(epoch)训练和验证的详细指标数据(如 loss、accuracy、mAP50 等)。
用途:方便你后续用 Excel 或 Python 自己绘制更精细的曲线。
基本概念
1 置信度 = 对一个判断 / 结果的「靠谱程度、把握度、确定性」(越高越确定)
2 精确率 = 我挑出来的里面,对的有多少?(百分比)
3 召回率 = 本该找到的里面,找到多少?(百分比)
4 精确率 §、召回率 ® 的调和平均 = 2 × (精确率 × 召回率) ÷ (精确率 + 召回率) , 该数值反应找的准与全的综合能力。之所以使用调和平均而不用算术平均是因为:算术平均的计算过程导致一个高、一个低,平均分也会很高,会掩盖模型的致命缺陷。而调和平均只要有一项接近 0,整体分数直接接近 0。
5 IoU = 交并比 = 预测框 和 真实框 的重叠程度
6 @0.5 = 只有预测框和真实框重叠 (loU)≥ 50%,才算检测正确 (综合反应找的准与找的全)
7 AP = Average Precision = 平均精确率。 它不是一个点的精确率,而是把所有置信度档位下的「精确率 + 召回率」综合起来,即算P-R 曲线下的面积。
8 mAP = mean AP = 所有类别的 AP 求平均, 比如模型要检测:人、车、猫、狗。
先算「人的 AP」「车的 AP」「猫的 AP」「狗的 AP」再相加除以 4 → mAP
9 mAP@0.5 :在「预测框与真实框重叠至少 50% 才算正确」的规则下,模型对所有待检测类别,综合【精确率(找的准)+ 召回率(找的全)】的平均得分。
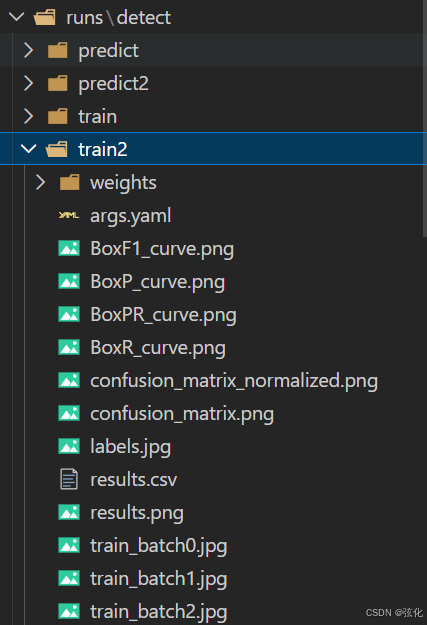
BoxF1_curve.png
- 图表核心含义
横轴(Confidence):模型预测的置信度阈值(0~1)。阈值越高,代表模型对预测结果的 “把握” 越严格。
纵轴(F1):F1 分数,是 ** 精确率(Precision)和召回率(Recall)** 的调和平均,越接近 1 代表模型性能越好。
曲线颜色:
🔵 青色(fire):“火” 类别的 F1 置信度曲线。
🟠 橙色(smoke):“烟” 类别的 F1 置信度曲线。
🔵 深蓝色(all classes):两类别的综合 F1 曲线。 - 关键数据解读
图中标注的关键信息:all classes 0.99 at 0.672
最佳平衡点:在置信度阈值 = 0.672 时,所有类别的综合 F1 分数达到 0.99。
这是一个非常优秀的数值,意味着在该阈值下,模型兼顾了高精确率(预测的少但准)和高召回率(漏检的少),是模型性能的最佳平衡点。 - 曲线趋势分析
高置信度区(0.2 ~ 0.8):曲线平稳且接近 1.0,说明:
模型在中等偏高的置信度下,对 fire 和 smoke 的识别都非常稳定,几乎没有误判和漏判。
置信度骤降区(> 0.8):曲线在置信度接近 1.0 时快速断崖式下跌:
原因:置信度阈值设得太高(比如只相信 90% 以上的预测),模型会过滤掉大量边缘样本,导致参与计算的样本数骤减,F1 分数因此急剧下降。这是正常现象,不代表模型变差。 - 两类对比(fire vs smoke)
fire(青色) 与 smoke(橙色) 的曲线几乎完全重合,且都维持在高位。
结论:模型对 fire 和 smoke 两个类别的学习能力非常均衡,没有出现某一类(例如 smoke)效果明显变差的情况,数据集的标注和训练质量很高。
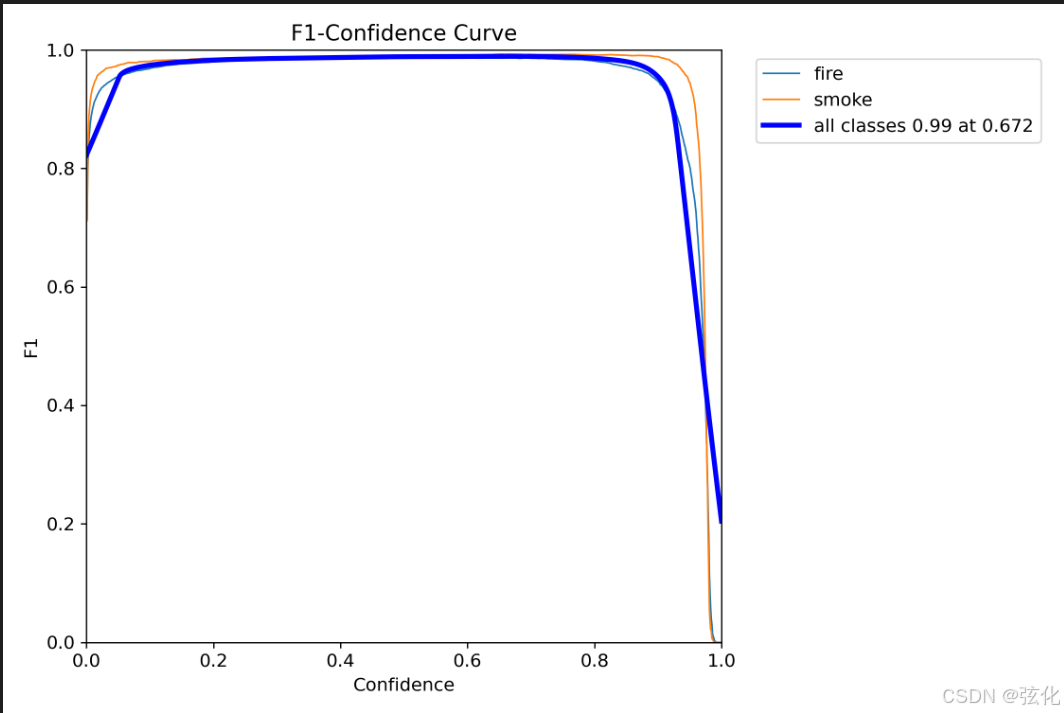
BoxP_curve.png
这是目标检测模型的精确率 - 置信度曲线,用于评估模型在不同置信度阈值下的预测准确性,代表预测出来的框里有多少是准确的。
- 核心概念
横轴(Confidence):模型预测的置信度阈值(0~1),阈值越高,模型对预测结果的 “把握” 越严格。
纵轴(Precision):精确率,代表预测为正的样本中,真实为正的比例,越接近 1 说明误报越少。
曲线含义:
🔵 青色(fire):火类别的精确率曲线
🟠 橙色(smoke):烟类别的精确率曲线
🔵 深蓝色(all classes):两类综合精确率曲线(将 fire 和 smoke 两个类别合并后,计算得到的整体精确率 - 置信度关系,代表模型在所有检测目标上的平均精确率表现。它不是简单取 fire 和 smoke 两条曲线的平均值,而是把所有样本(火 + 烟)混在一起,重新计算:all classes = 所有类别中预测正确的正样本数 / 所有类别中预测为正的样本总数 )
-
关键数据与趋势
标注信息:all classes 1.00 at 1.000
当置信度阈值设为 1.0 时,模型的综合精确率达到 100%,意味着模型只在完全确定时才会输出预测,此时没有任何误报。
曲线走势:
置信度 > 0.2 后,三条曲线均快速攀升并稳定在 接近 1.0 的高位,说明在常规置信度区间(0.2~1.0)内,模型预测的结果几乎都是准确的,误报率极低。
置信度接近 0 时,精确率略有下降,这是因为低阈值会让模型输出大量低置信度的预测,其中包含更多误报,属于正常现象。 -
类别对比
fire 和 smoke 两条曲线高度重合,均维持在高位,说明模型对两个类别的识别精度非常均衡,没有出现某一类更容易误判的情况。
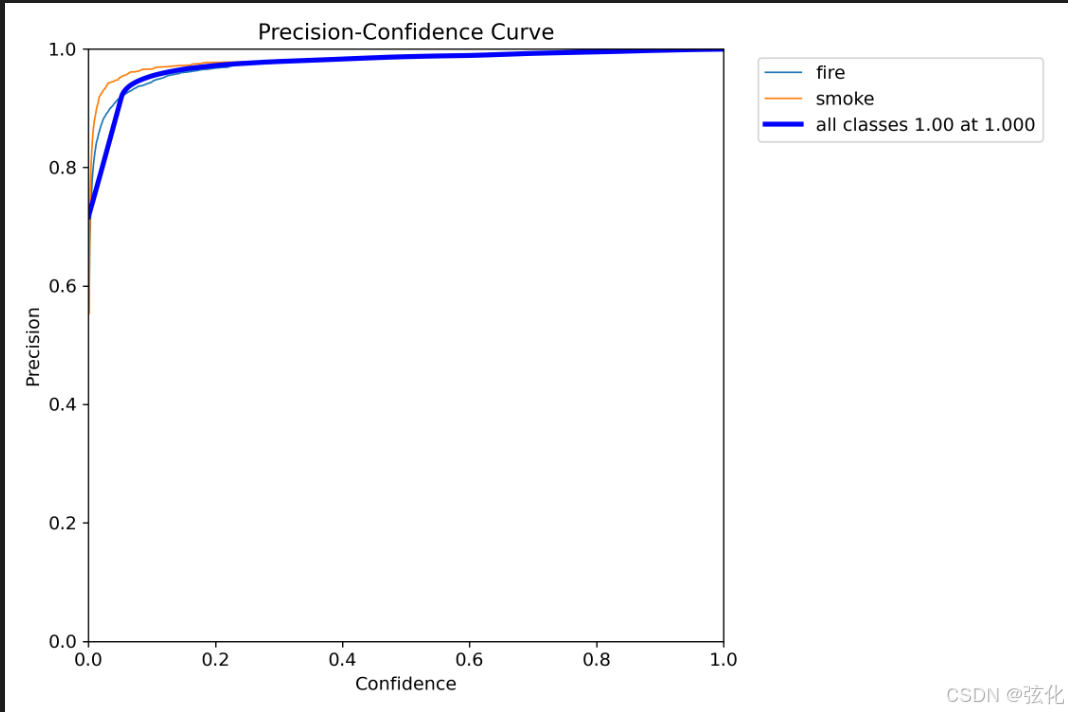
BoxPR_curve.png
Precision-Recall Curve(P-R 曲线)
- 核心概念
横轴(Recall):召回率,代表所有真实目标中被模型正确检测出来的比例,越接近 1 说明漏检越少。
纵轴(Precision):精确率,代表所有被模型检测出的目标中真实为正的比例,越接近 1 说明误报越少。
曲线含义:
🔵 青色(fire):火类别的 P-R 曲线,mAP@0.5 = 0.993
🟠 橙色(smoke):烟类别的 P-R 曲线,mAP@0.5 = 0.995
🔵 深蓝色(all classes):两类综合 P-R 曲线,mAP@0.5 = 0.994 - 关键指标:mAP@0.5
mAP@0.5:在 IoU 阈值为 0.5 时的平均精度均值,是 P-R 曲线下的面积,数值越接近 1 代表模型性能越好。
你的模型结果:
fire:0.993
smoke:0.995
all classes:0.994
这是极其优异的表现,说明模型在火灾和烟雾检测任务中,几乎能做到既不漏检、又不误报。 - 曲线形态解读
曲线在 Recall 从 0 到接近 1 的区间内,Precision 始终维持在 1.0 附近,仅在 Recall 接近 1 时才轻微下降。
这意味着:
模型在召回率极高(几乎不漏检)的情况下,依然能保持近乎 100% 的精确率。
不存在 “为了提高召回率而牺牲精确率” 的问题,模型在两者之间取得了完美平衡。 - 类别对比
fire 和 smoke 的 mAP@0.5 数值非常接近,曲线形态几乎完全重合,说明模型对两个类别的学习效果高度均衡,没有出现某一类性能明显偏弱的情况。
mAP@0.5 高达 0.994,代表模型在实际场景中能精准识别几乎所有火 / 烟目标,同时几乎不会产生误报。
单类别表现均衡,适合直接部署到安防、预警等对可靠性要求极高的场景。
BoxR_curve.png
召回率 - 置信度曲线(Recall-Confidence Curve)
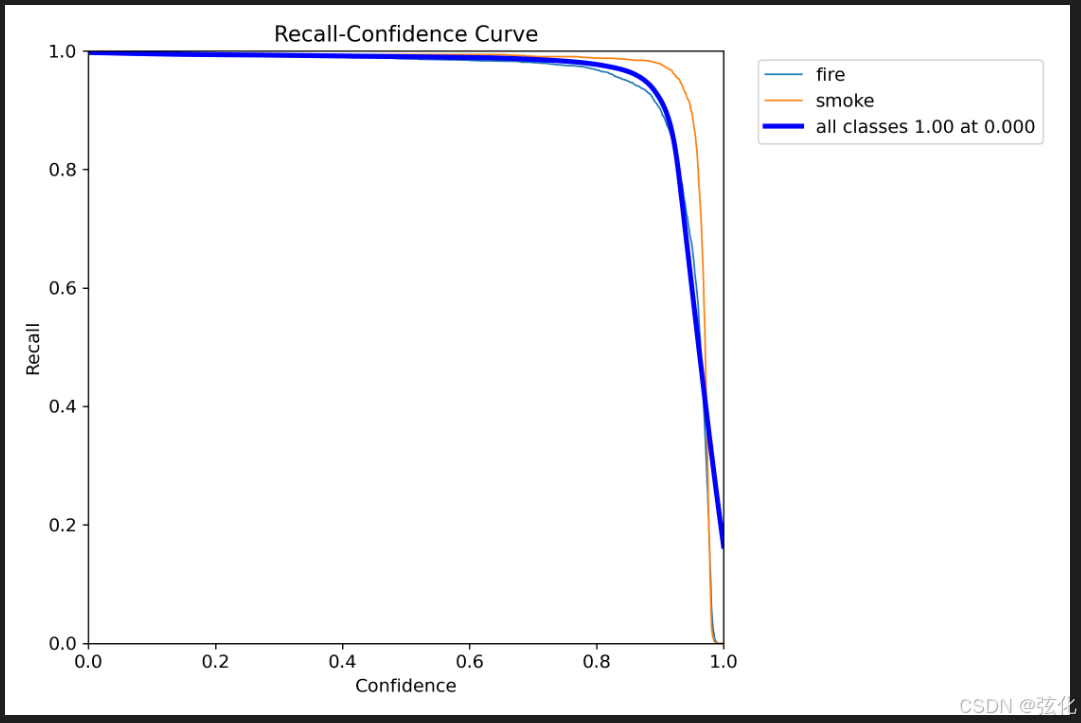
- 核心含义
曲线走势:在置信度较低时,模型几乎保留所有预测结果,因此召回率接近 1.0;随着置信度阈值提高,模型只保留更确定的预测,召回率逐步下降。
类别区分:
蓝色线(fire):火焰类别的召回率 - 置信度曲线
橙色线(smoke):烟雾类别的召回率 - 置信度曲线
深蓝色线(all classes):所有类别的平均召回率曲线
2. 关键观察
低置信度区间(0~0.8):三类曲线均保持在接近 1.0 的水平,说明在宽松置信度阈值下,模型能几乎召回所有目标,漏检极少。
高置信度区间(0.8~1.0):召回率快速下降,说明模型在只保留高置信度预测时,会舍弃大量低置信度的正确目标,导致召回率骤降。
类别差异:smoke(橙色)曲线在高置信度区间的召回率略高于 fire(蓝色),说明烟雾类目标在高置信度下的召回表现更稳定。
若业务场景要求极低漏检率(如火灾预警),可选择较低置信度阈值(如 0.5),保证召回率接近 1.0。
若业务场景要求高预测可信度,可选择较高置信度阈值(如 0.8),但需接受召回率下降的代价。
曲线的 “陡峭程度” 反映了模型置信度区分能力:越平缓说明模型对置信度阈值越不敏感,性能更稳定。
confusion_matrix_normalized.png
下面是归一化混淆矩阵(Confusion Matrix Normalized),用于直观展示模型在各类别上的分类错误比例,核心是看 “真实类别被模型错判成了什么”。
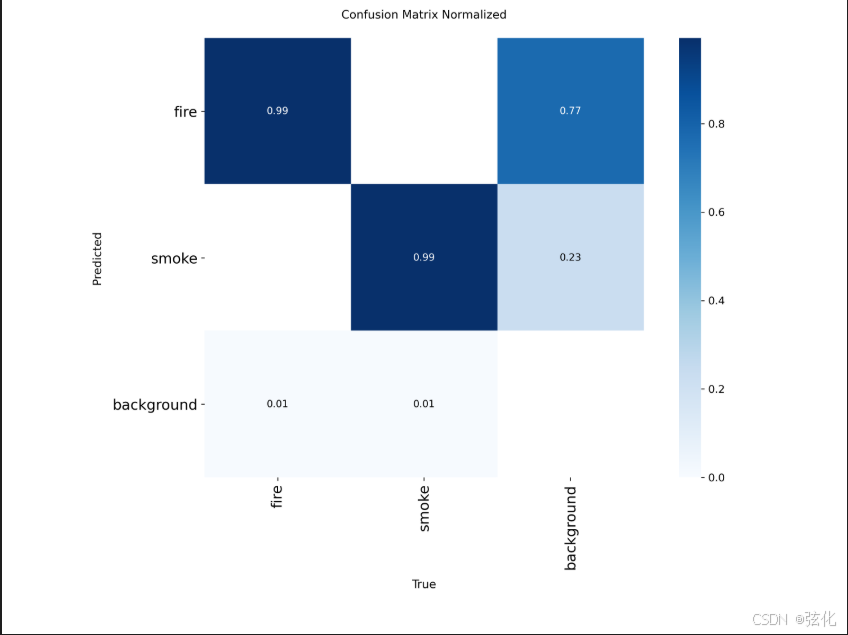
- 基本概念
横轴(True):真实标签(fire /smoke/background)
纵轴(Predicted):模型预测标签
对角线上的数值:该类别被正确分类的比例(数值越接近 1,分类越准确)
非对角线上的数值:该类别被错判为其他类别的比例
例如 X = fire , Y = fire ,根据图得值为0.99,代表实际是fire,最终被判定为fire的比例为0.99。
例如 X = fire , Y = background, 查图得值为0.01,代表实际是fire,最终被判断为backgroud的比例是0.01。
关键发现:极高的分类准确率
fire 和 smoke 的对角值均为 0.99,说明模型对这两个目标类别的识别极其精准,几乎不会互相混淆(没有出现将火判为烟、或将烟判为火的情况)。
主要错误来源:
唯一的错误是:少量 fire(23%)和 smoke(77%)样本被错判为 background,这属于目标漏检,而非误报。
反过来,背景几乎不会被误判为火 / 烟(仅 1%),说明模型误报率极低,非常适合火灾预警这类对 “零误报” 要求高的场景。
类别间无混淆
fire 和 smoke 之间的交叉值为 0,说明模型完全能区分这两类目标,不存在视觉特征混淆的问题。
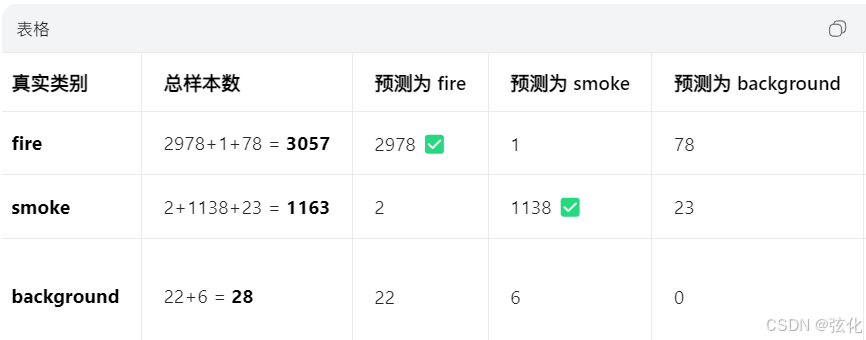
confusion_matrix.png
原始混淆矩阵(Confusion Matrix),展示了模型在验证集上具体样本数量的分类结果,能直观看到每类样本的正确 / 错误预测数量。
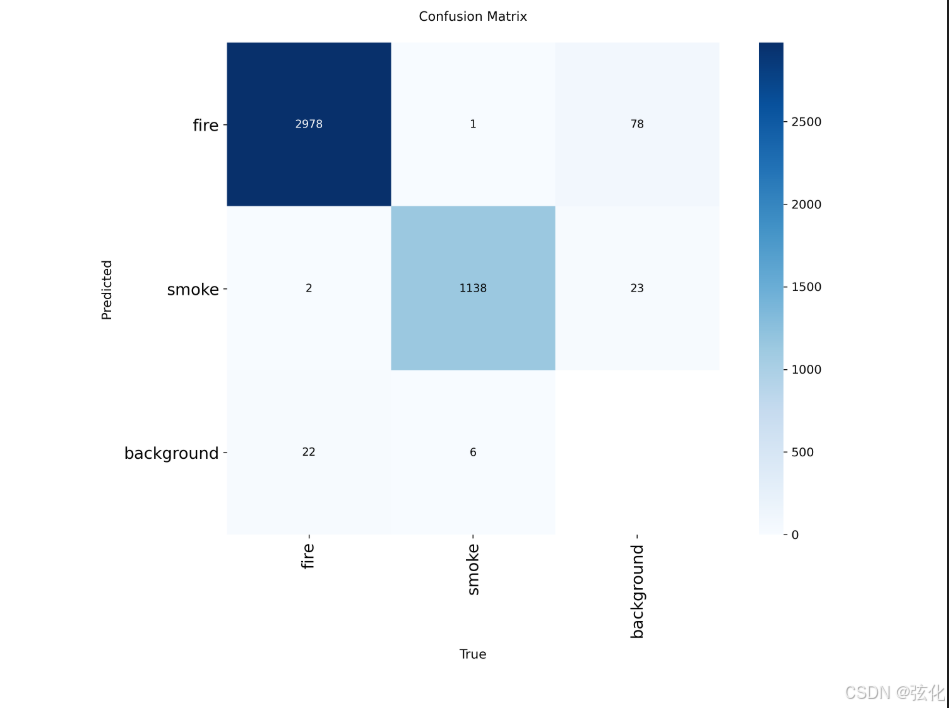
- 基本概念
横轴(True):真实标签(fire /smoke/background)
纵轴(Predicted):模型预测标签
对角线上的数值:该类别被正确分类的样本数
非对角线上的数值:该类别被错判为其他类别的样本数
-
关键发现
极高的正确识别率
fire 正确识别 2978 个样本,smoke 正确识别 1138 个样本,两类准确率均接近 98%,说明模型对目标的识别能力极强。
极低的类别混淆
fire 与 smoke 之间的错判仅为 1+2=3 个样本,几乎可以忽略,模型完全能区分两类目标。
主要错误来源:漏检
fire 有 78 个样本被错判为 background(漏检),smoke 有 23 个样本被错判为 background(漏检),这是最主要的错误类型。
误报(background→fire/smoke)仅 22+6=28 个样本,占比极低,符合火灾预警对 “低误报” 的要求。 -
与归一化矩阵的对比
原始矩阵:看绝对数量,适合了解数据集规模和错误样本的绝对量级。
归一化矩阵:看比例,适合对比不同类别(尤其是样本数差异大的类别)的错误率。
两者结论一致:模型性能优异,主要问题是少量漏检,无明显类别混淆。
漏检分析:测试集标注错误,下图标注的smoke后经考查,实际为水幕,此类照片数量级约为400,可能造成了一定程度的误判。
综合结论
火灾 / 烟雾检测模型在实际样本数量上表现极其稳健:
对 fire 和 smoke 的识别准确率接近 98%,类别间几乎无混淆。
误报样本仅 28 个,远低于漏检样本,非常适合实际预警场景。
可通过优化置信度阈值或补充小目标 / 模糊场景的样本,进一步降低漏检率。
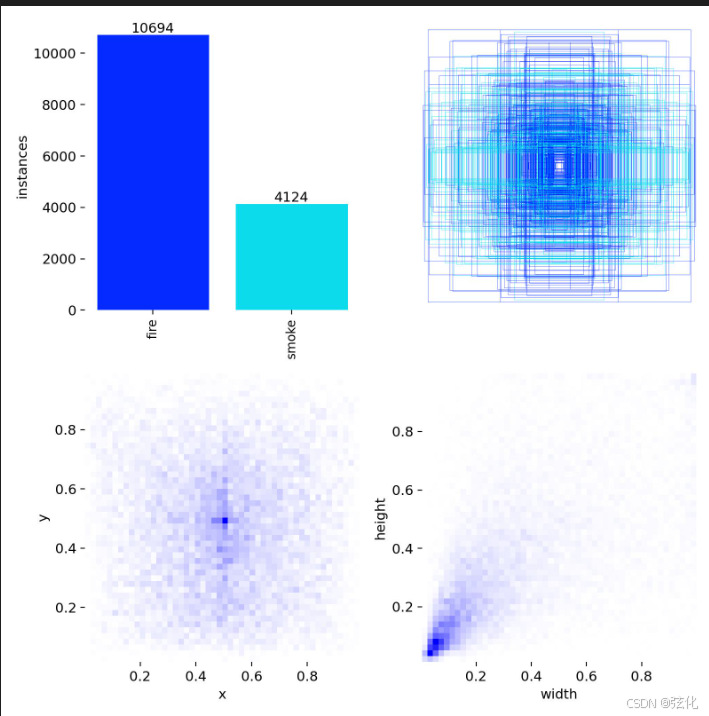
labels.jpg
数据集标签可视化报告:
-
类别数量统计(左上柱状图)
fire(火):10694 个实例
smoke(烟):4124 个实例
总样本数:14818 个
分布特点:
火样本数量约为烟样本的 2.6 倍,存在一定的类别不平衡,但差距在可接受范围内,结合之前的模型表现看,并未对训练效果造成明显负面影响。 -
边界框分布(右上热图)
这是所有标注框的宽高与位置叠加图,颜色深浅代表框的密集程度。
可以看到:
目标框集中在图像中心区域,符合真实场景中火灾 / 烟雾多发生在画面中部的特点。
框的大小差异较大,说明数据集中包含小、中、大不同尺度的目标,模型能学到多尺度特征。 -
目标位置分布(左下热力图)
横轴 x、纵轴 y 代表图像归一化坐标(0~1),颜色越深表示目标出现越频繁。
特点:
目标主要集中在 x: 0.2~0.8、y: 0.2~0.8 的中间区域,边缘区域目标较少。
这说明数据集的目标分布较为集中,模型更容易学习到核心区域的特征。 -
目标尺寸分布(右下热力图)
横轴 width(宽)、纵轴 height(高),代表边界框的归一化尺寸。
特点:
目标以小尺寸和中等尺寸为主(宽高多集中在 0~0.4 区间),大尺寸目标较少。
宽高比呈现一定的多样性,说明数据集中包含不同形态的火 / 烟目标。
综合结论
类别数量:虽有轻微不平衡,但未影响模型性能(两类 mAP 均接近 0.99)。
空间分布:目标集中在画面中部,符合真实场景,便于模型学习。
尺度多样性:包含多尺度目标,能让模型适应不同距离的检测场景。
数据规模:总样本数超 1.4 万,足够训练出高性能模型
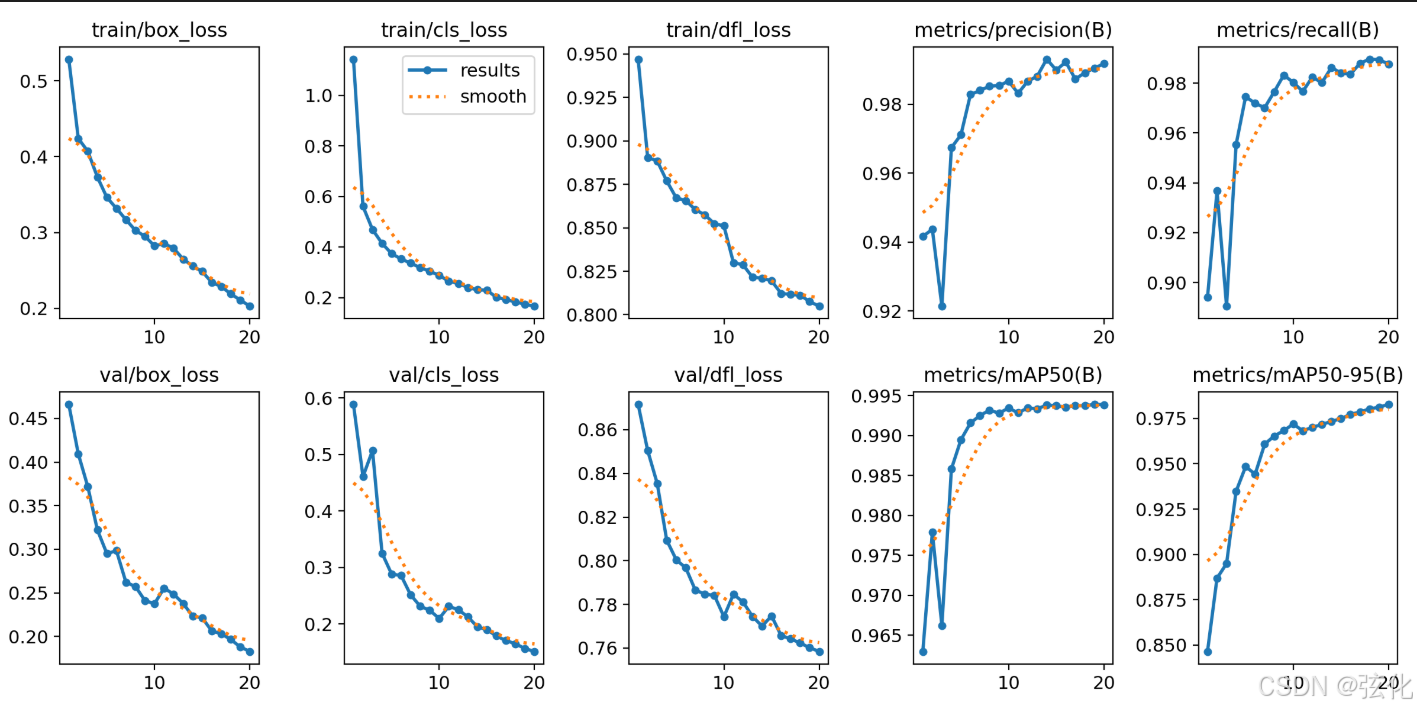
results.png
-
损失曲线(Loss Curves)
train/box_loss / val/box_loss:边界框回归损失
训练和验证损失均从高位快速下降,最终稳定在 ~0.2 左右,曲线平滑无剧烈抖动,说明框回归任务收敛良好。
train/cls_loss / val/cls_loss:分类损失
训练损失从 1.1 降至~0.18,验证损失从 0.58 降至~0.17,两者走势高度一致,无明显过拟合。
train/dfl_loss / val/dfl_loss:分布焦点损失(YOLOv8 特有)
训练损失从 0.95 降至~0.80,验证损失从 0.87 降至~0.76,同样平稳下降,说明分布学习充分。
✅ 结论:所有损失曲线均平稳下降且训练 / 验证趋势一致,无过拟合 / 欠拟合,训练过程非常健康。 -
指标曲线(Metrics Curves)
metrics/precision(B):精确率
从初始 0.94 快速攀升并稳定在 ~0.99,说明模型预测结果几乎无错误。
metrics/recall(B):召回率
从初始 0.90 逐步提升至 ~0.99,说明模型能识别绝大多数目标,漏检极少。
metrics/mAP50(B):IoU=0.5 时的平均精度
从 0.965 快速上升并稳定在 ~0.994,是极其优异的表现。
metrics/mAP50-95(B):多 IoU 阈值下的平均精度
从 0.85 稳步提升至 ~0.98,说明模型在不同 IoU 要求下都保持高精度,泛化能力强。
✅ 结论:所有指标均在训练初期快速达到高位并持续优化,最终收敛到接近完美的水平。 -
训练健康度总结
收敛速度:前 10 个 epoch 就完成了大部分优化,后 10 个 epoch 仅做小幅提升,说明学习率和训练轮数设置合理。
过拟合检查:训练 / 验证损失差值极小,指标曲线无 “训练上升、验证下降” 的情况,无过拟合风险。
最终性能:mAP50 达 0.994,mAP50-95 达 0.98,精确率和召回率均接近 0.99,模型性能达到工业级可用水平。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)