基于OPENMV H7 PLUS的深度模型部署方法
自从学习嵌入式以来,我也陆陆续续接触过不少项目了。从stc51单片机到stm32f103c8t6,再到如今的stm32h743和gd32系列,从普通二层板到如今的高速信号板,从标准库到hal库,从下位机到上位机,从大一的懵懂无知,到现在大三的懵懂无知(笑),恍惚间似乎学到很多东西了,于是我决定写一些博客来记录、分享我的经验。
本期主题是:“基于OPENMV H7 PLUS的深度模型部署方法”。主要是最近的课设在做机器人视觉的项目,所以目前对此最为熟悉,于是就简单分享一下以帮助小白快速入门。
以下是正文
Part 0、
这是一款基于 Edge Impulse 平台训练、专为 OpenMV 嵌入式视觉设备优化的TensorFlow Lite Micro 轻量化卷积神经网络(CNN)图像分类模型,属于面向单片机端的微型端侧 AI 模型,采用嵌入式专用的轻量化网络结构,具备体积小巧、资源占用极低、低功耗、离线实时推理的核心特性,无需联网即可独立完成图像识别任务,主要用于实现精准分类识别,是嵌入式视觉场景中典型的轻量化图像分类 AI 模型。
Part 1、
登录网站:Edge Impulse - The Leading Edge AI Platform
点击get started(可能要注册,正常注册就行。如果qq邮箱或者foxmail不行的话试试教育邮箱),进入主页后,点击created new project。会弹出这个界面
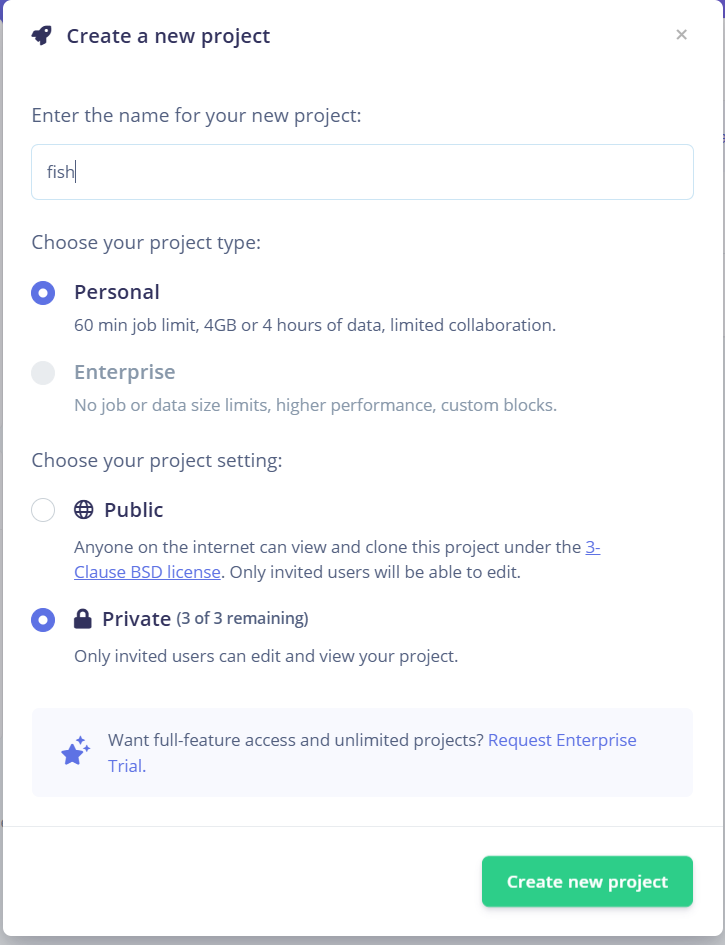
我们来尝试做一个最简单的鱼类识别模型,文件名称就叫做“fish”。我们做普通的项目选择个人即可。下方则可以选择私有项目。如果不建议公开的话选择public也行。私有项目最多是三个。
进来以后主页是这样的
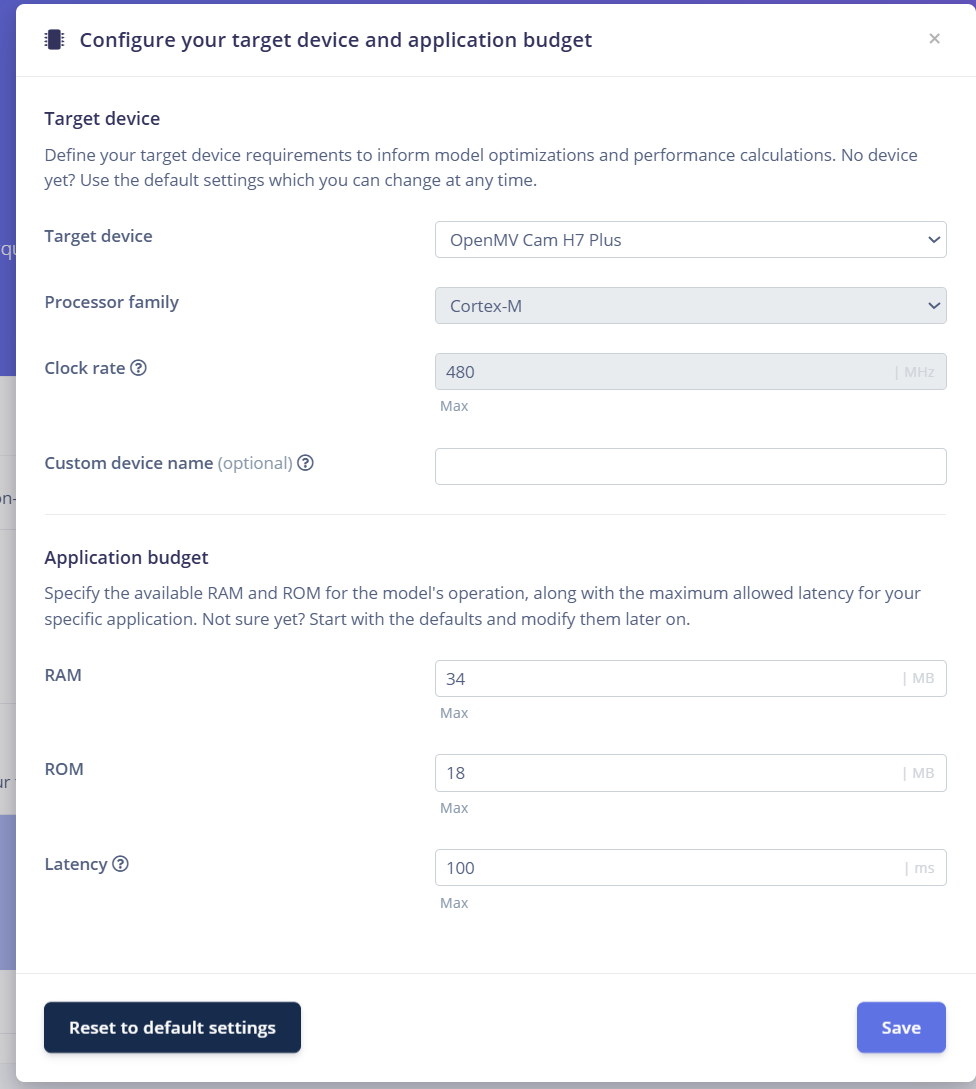
可以在右上角选择设备,如图,选择openmv h7 plus即可(openmv h7似乎不行?不过可以试一下)。
Part 2、
数据集添加。很多小伙伴不知道从哪里找数据集,可以问问ai要个链接,或者去淘宝上花几十块钱买一些数据集即可。我的数据集来自开源数据集,文章末尾给出了。
点击左边导航栏的“Data acquisition”,设置成这样即可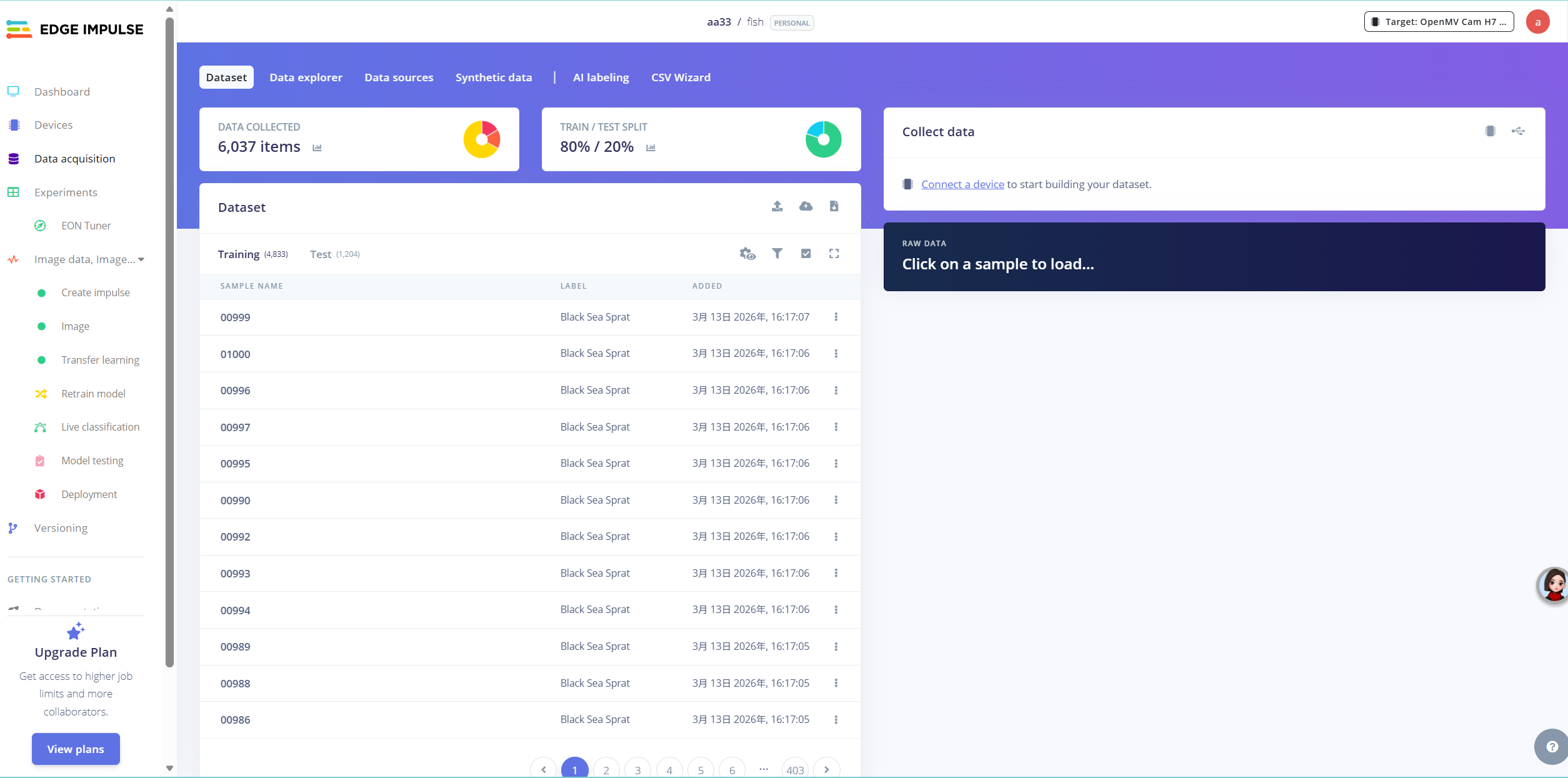
然后上传数据
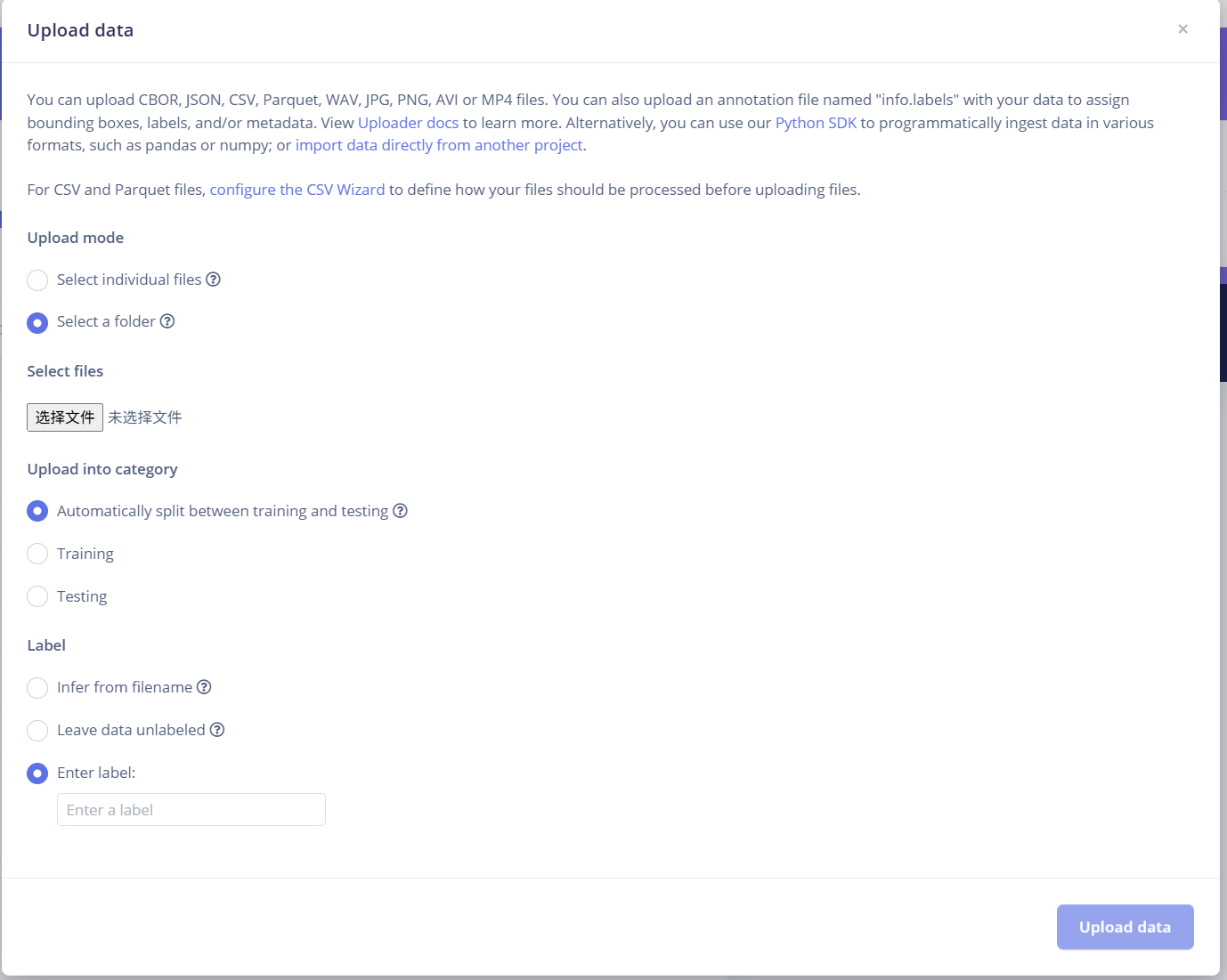
第一个选项是选择整个文件夹上传,第二个选择是自动分为训练集和测试集,这里不区分验证集。
最后一个选项是添加你上传的这一数据集的数据类型。比如你上传的全是鲫鱼,你输入鲫鱼即可(建议英语)。
Part 4、
有了数据集以后点击“creat impulse“,如图设置即可
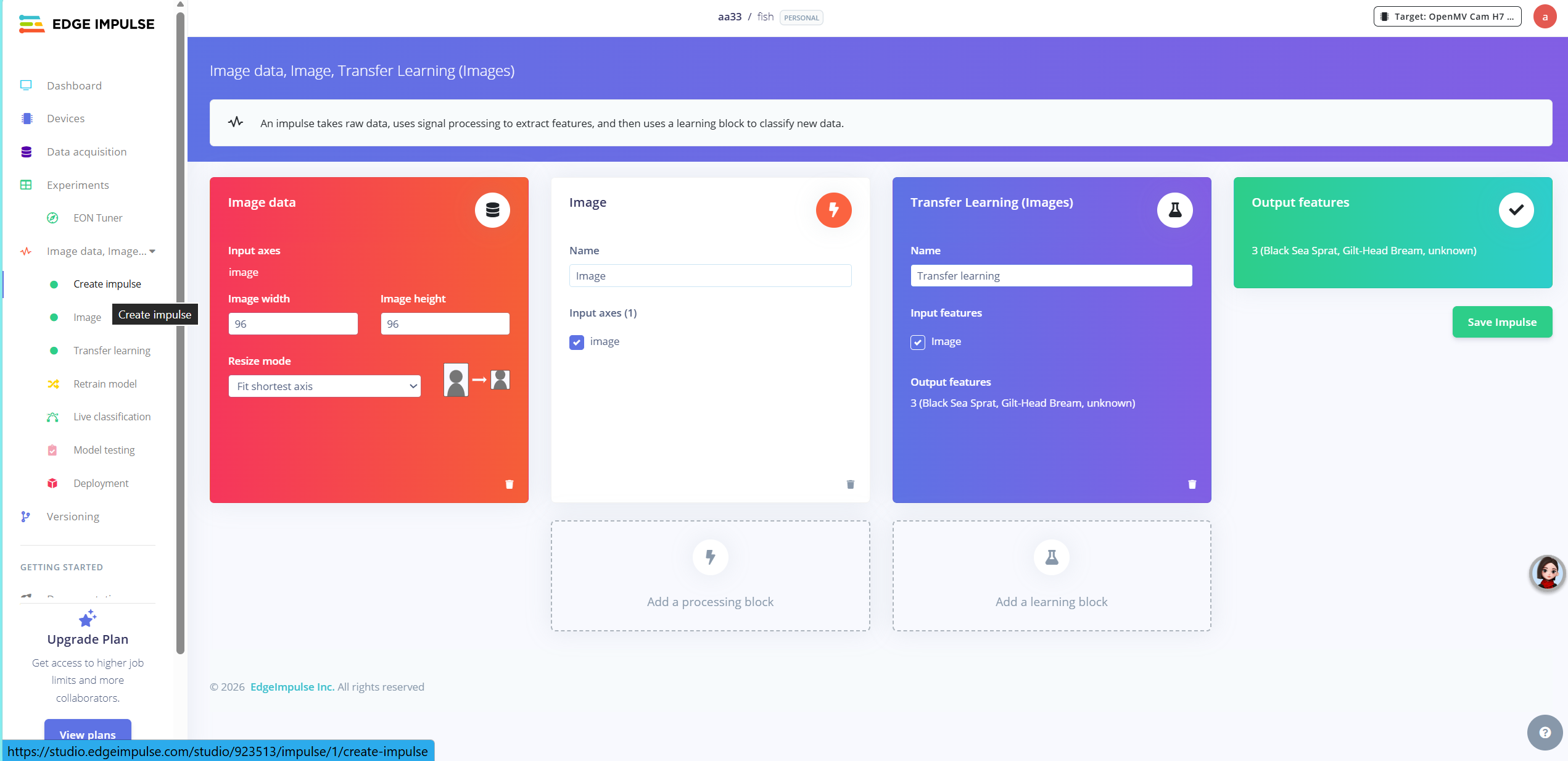 这里简单说一下紫色部分的选项。我个人是建议选择Transfer learning更好,因为准确度更高,更快速。openmv支持的还有object detection。但从我实测来看,object detection准确率极低。
这里简单说一下紫色部分的选项。我个人是建议选择Transfer learning更好,因为准确度更高,更快速。openmv支持的还有object detection。但从我实测来看,object detection准确率极低。
Transfer learning是借助别人都模型帮你训练,快速而且准确率高,但是仅仅能识别出这个东西,不能知道这个东西在哪。
object detection需要自己标注模型(类似于传统的数据标注?我不是深度学习方向的,对此懂得不多),数据集一多很麻烦(但现在似乎也支持人工智能标注了?)。但是相对的该模型不仅能识别出这个东西,还知道这个东西在哪。
Part 5、
点击左边的“image”,再点击generate features,再点击图像中间的generate feature即可生成特征图像。
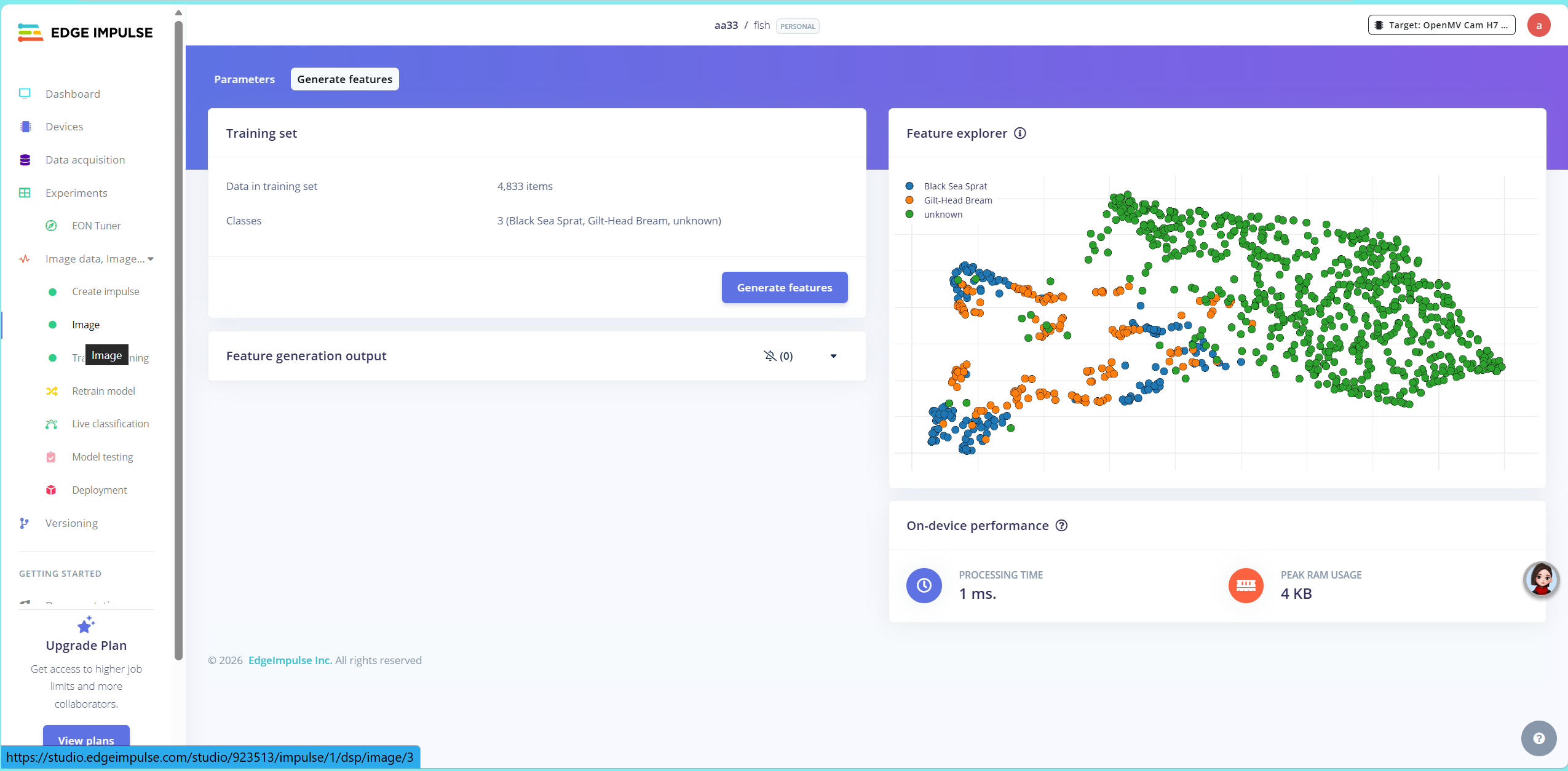
我这里一共是三个数据集,分别是黑海鱼(蓝色点),金鱼(金色点),和作为背景的unknown(绿色点,相当建议投入一定数量的unknown,否则你的openmv只会显示两种结果,比如非金鱼就黑海鱼,即该模型输出的置信度和是100%,如果你没有unknown,你把镜头对准空白处也会识别出黑海鱼或者金鱼)。
绿色点和其它两色点在区域分布上有明显区别,说明绿色点和两种鱼类区别明显。
蓝色点和金色点相互混杂,说明这两种鱼类特征有部分重合。
Part 6、
点击transfer learning,再点击save & train。
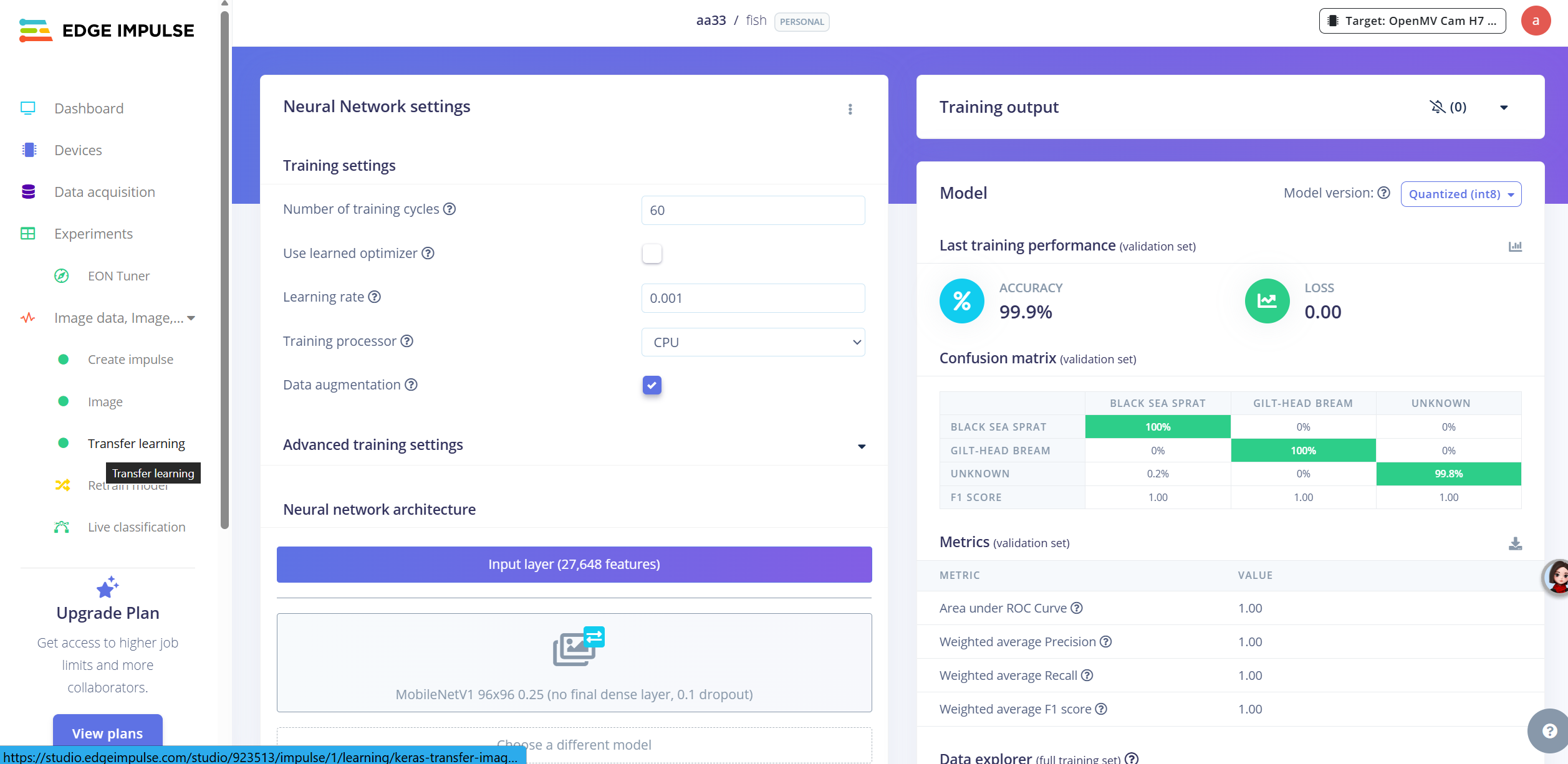
数据集小的话可以选择Number of training cycles=60(这个大概意思就是训练多少轮,一般来说,轮次高的效果低于轮次低的),数据集大的话建议减少相应轮数,因为个人免费时间只有1h。
从图像右侧来看,我的模型识别准确率相当高(和我数据集比较优质,识别种类少有关系),但是我选择object detection时,准确率只有30%左右。
Part 7、
最后也是来到部署部分。点击“development”到如图界面

再选择openmv library。最后点击build即可生成本地文件。
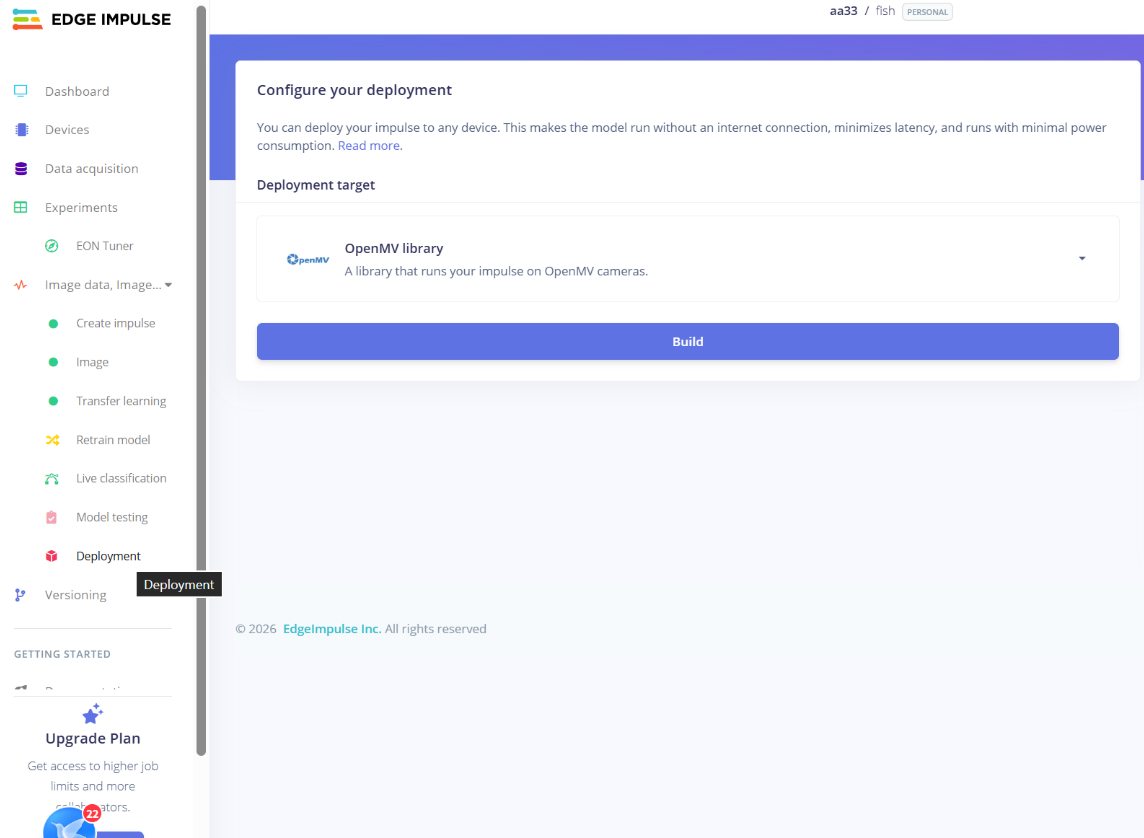
生成的三个本地文件全部放入openmv中即可,如果不可以的话将生成的python文件烧录进openmv'即可。
Part 8、
个性化修改。只有模型还是不够的,我们需要将模型结果输出。
以下是基于openmv ide4.4.4,openmv h7 plus固件版本为4.5.9开发的代码。
# Edge Impulse - OpenMV 图像分类示例程序
# 适配OpenMV 4.5.9固件 + 官方LCD扩展板
# 功能:基于TFLite轻量化模型实现两种鱼类识别,LCD实时显示,串口定时发送结果
# 授权:MIT开源协议
# 导入依赖库
# sensor:摄像头驱动 time:时间控制 ml:机器学习模型推理
# gc:内存回收 pyb:硬件控制 display:LCD屏幕驱动
import sensor, time, ml, uos, gc, pyb
import display
# ====================== 1. 摄像头模块初始化 ======================
sensor.reset() # 重置摄像头硬件
sensor.set_pixformat(sensor.RGB565) # 设置图像格式为RGB565彩色
sensor.set_framesize(sensor.QQVGA2) # 设置图像分辨率(适配模型输入尺寸)
sensor.skip_frames(time=2000) # 跳过初始帧,让摄像头稳定
# ====================== 2. LCD显示屏初始化 ======================
try:
lcd = display.SPIDisplay() # 初始化SPI接口的LCD屏幕
print("LCD初始化成功")
except Exception as e: # 捕获初始化失败异常
print(f"LCD初始化失败: {e}")
lcd = None # 初始化失败则置空,避免后续报错
# ====================== 3. 串口通信初始化 ======================
# 初始化串口3,波特率115200,8位数据位,无校验,1位停止位
uart = pyb.UART(3, 115200, bits=8, parity=None, stop=1)
# 定义全局变量:存储模型和标签
net = None
labels = None
# ====================== 4. 加载AI模型和标签文件 ======================
try:
# 加载Edge Impulse训练导出的TFLite轻量化模型
net = ml.Model("trained.tflite")
except Exception as e:
print(e)
# 模型缺失则抛出异常,提示用户拷贝文件
raise Exception('请确保 trained.tflite 和 labels.txt 已复制到文件系统')
try:
# 读取标签文件,存储分类名称
labels = [line.rstrip('\n') for line in open("labels.txt")]
except Exception as e:
# 标签文件缺失则抛出异常
raise Exception('缺少 labels.txt')
# ====================== 5. 全局参数定义 ======================
clock = time.clock() # 帧率计时器
last_send_time = time.ticks_ms() # 记录上一次串口发送的时间
send_interval = 5000 # 串口发送间隔:5000毫秒(5秒)
last_sent_result = "unknown" # 保存上一次串口发送的识别结果
# ====================== 6. 主循环:实时识别 ======================
while(True):
clock.tick() # 开始计时,计算帧率
img = sensor.snapshot() # 摄像头拍摄一帧图像
# 模型推理:对当前图像进行分类,输出所有标签的置信度
predictions = net.predict([img])[0].flatten().tolist()
# 将标签与对应置信度配对
predictions_list = list(zip(labels, predictions))
# 初始化两种目标鱼类的置信度
sprat_score = 0.0 # 黑海黍鲱置信度
bream_score = 0.0 # 金头鲷置信度
# 遍历推理结果,提取目标鱼类的置信度
for label, score in predictions_list:
if label == "Black Sea Sprat":
sprat_score = score
elif label == "Gilt-Head Bream":
bream_score = score
# 在图像上绘制实时置信度(白色文字)
img.draw_string(5, 5, f"Sprat:{sprat_score:.2f}", color=(255,255,255), scale=1)
img.draw_string(5, 20, f"Bream:{bream_score:.2f}", color=(255,255,255), scale=1)
# ====================== 串口定时发送逻辑 ======================
current_time = time.ticks_ms() # 获取当前时间
# 判断是否达到发送间隔(5秒)
if time.ticks_diff(current_time, last_send_time) >= send_interval:
# 默认结果为未知
temp_send = "unknown"
# 置信度大于0.9判定为对应鱼类
if sprat_score > 0.9:
temp_send = "Black Sea Sprat"
elif bream_score > 0.9:
temp_send = "Gilt-Head Bream"
# 串口发送识别结果(换行符用于接收端解析)
uart.write(temp_send + "\n")
print(f"已发送: {temp_send}")
# 更新上一次发送的结果(用于屏幕显示)
last_sent_result = temp_send
# 更新最后发送时间
last_send_time = current_time
# 在图像上绘制上一次的发送结果(绿色文字,固定显示直到下次发送)
img.draw_string(5, 35, f"Send:{last_sent_result}", color=(0,255,0), scale=1)
# ====================== 屏幕显示 ======================
# 如果LCD初始化成功,将图像显示在屏幕上
if lcd is not None:
lcd.write(img)
# 打印当前帧率
print(clock.fps(), "fps")
# 内存垃圾回收,防止内存溢出(嵌入式设备必备)
gc.collect()这个代码的功能是通过串口发送识别结果,并且在屏幕上打印出识别结果。
Part 9、
实测部分。这里我一共生成了两个模型,可以分别看下效果
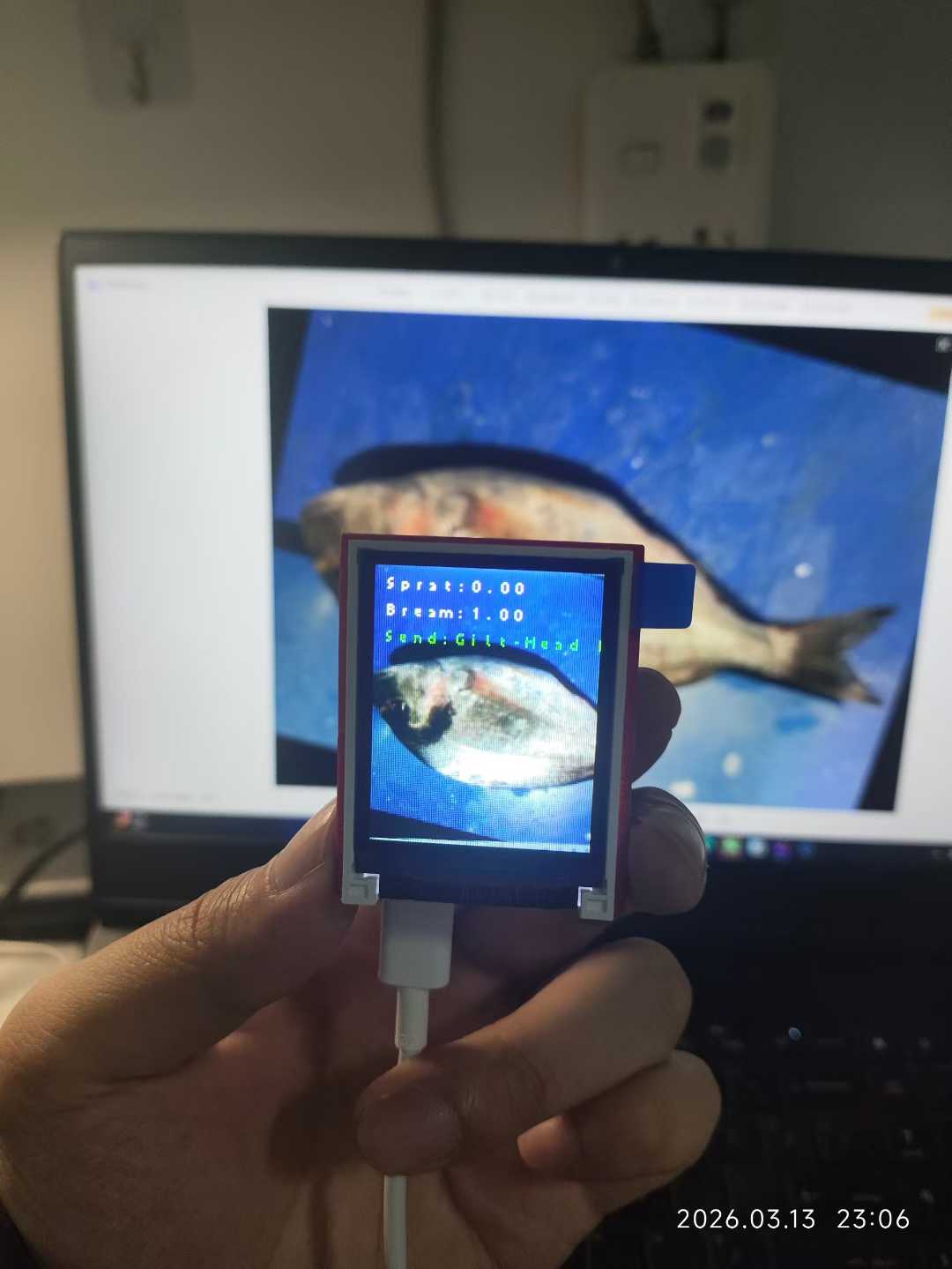

最后给出我的模型供大家测试:通过网盘分享的文件:fish.zip
链接: https://pan.baidu.com/s/1dhTiWjbMvq_guZ3dEmCz9A?pwd=cde9 提取码: cde9。
鱼类数据集来自A Large Scale Fish Dataset 大规模鱼类数据集_数据集-阿里云天池的A Large Scale Fish Dataset_Gilt-Head Bream_datasets.zip和A Large Scale Fish Dataset_Black Sea Sprat_datasets.zip。大家可以自行下载测试。
如有谬误,敬请指出。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)