IO模型与高性能原理
Redis IO模型与高性能原理
引言:Redis为什么这么快?
Redis 之所以能够实现极高的性能,主要基于以下三个核心设计:
- 完全基于内存操作:所有数据存储在内存中,读写速度远超磁盘
- 单线程模型:避免了多线程上下文切换的开销和竞争条件
- I/O多路复用模型:高效处理大量并发连接
本文将重点深入探讨 Redis 的 I/O 模型及其高性能的实现原理。
一、I/O模型基础概念
1.1 用户空间与内核空间
现代操作系统将内存划分为两个区域:
- 用户空间:应用程序运行的空间,权限较低,无法直接操作硬件设备
- 内核空间:操作系统内核运行的空间,拥有最高权限,可以直接操作硬件
当应用程序需要访问网络、磁盘等硬件资源时,必须通过系统调用请求内核空间的协助。这个过程中涉及数据的多次拷贝,是影响 I/O 性能的关键因素。
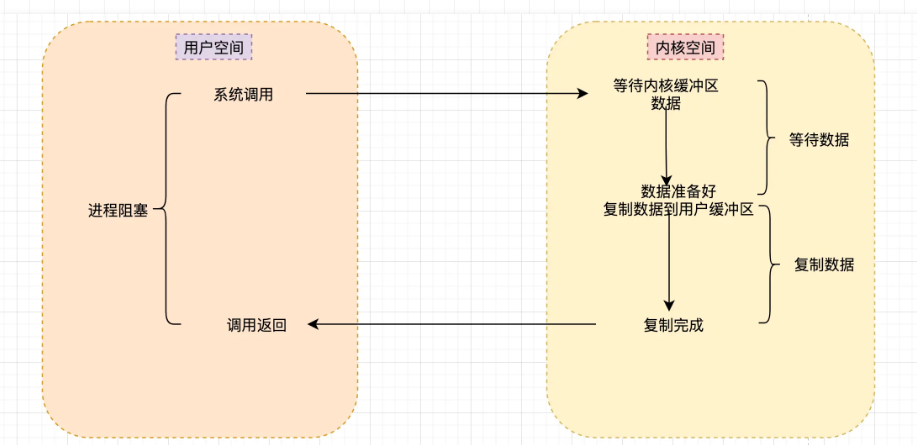
1.2 阻塞I/O模型(Blocking I/O)
在传统的阻塞 I/O 模型中,应用程序执行系统调用后会一直等待,直到数据准备完成并从内核缓冲区拷贝到用户缓冲区。
Redis视角下的阻塞问题:
当 Redis 主线程调用 read(fd) 从 Socket 读取客户端指令时:
- 如果客户端发送的指令(如
GET name)还在网络中传输,或只到达了一部分 - Redis 主线程会挂起(阻塞),无法处理其他客户端的请求
- 直到网络报文全部到达内核缓冲区,并拷贝到用户空间,主线程才能继续执行
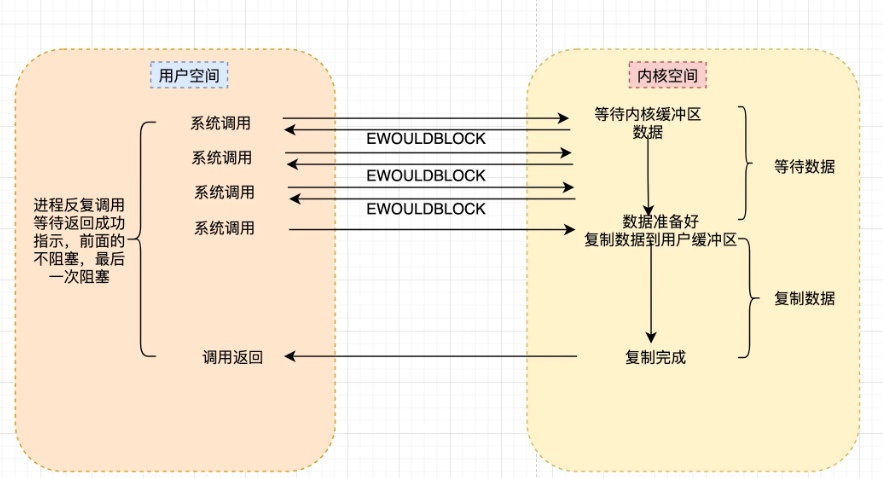
1.3 非阻塞I/O模型(Non-blocking I/O)
非阻塞 I/O 通过设置 O_NONBLOCK 标志,使系统调用在数据未准备好时立即返回错误,而不是阻塞等待。
特点:
- 第一阶段(等待数据):非阻塞,应用程序可以轮询检查
- 第二阶段(拷贝数据):仍然是阻塞的
- 缺点:轮询会消耗大量 CPU 资源
1.4 I/O多路复用模型(I/O Multiplexing)
I/O 多路复用允许单个进程同时监视多个文件描述符(Socket),当其中任何一个就绪时,内核通知应用程序进行处理。
核心思想:让内核发现进程指定的一个或多个 I/O 条件就绪后,再通知进程进行处理。
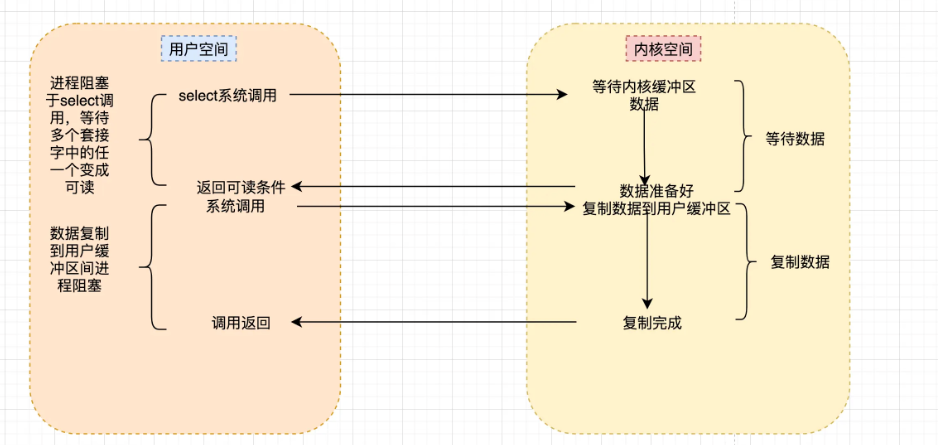
三种多路复用技术对比
| 技术 | 工作原理 | 优点 | 缺点 |
|---|---|---|---|
| select | 遍历所有监听的文件描述符 | 跨平台支持 | 有最大FD数量限制(1024),效率随FD数增加而下降 |
| poll | 链表存储FD,无数量限制 | 无FD数量限制 | 仍需要遍历所有FD,效率问题未解决 |
| epoll | 事件驱动,仅通知就绪FD | 高性能,无遍历开销 | 仅限Linux系统 |
二、Redis的I/O多路复用实现
2.1 核心架构组件
Redis 基于 I/O 多路复用开发了一套 文件事件处理器(File Event Handler),采用经典的 Reactor 模式:
- 套接字(Socket):客户端与服务端的通信窗口
- I/O多路复用程序(epoll):监听大量Socket的读/写事件
- 文件事件分派器(Dispatcher):将就绪Socket分发给对应处理器
- 事件处理器(Handlers):执行具体业务逻辑(连接应答、命令请求、命令回复)
2.2 epoll的工作机制(Linux环境)
在 Linux 环境下,Redis 使用 epoll 作为 I/O 多路复用的实现,其高效性源于两个核心数据结构:
-
红黑树(RB-Tree):保存所有需要监听的 Socket 文件描述符
- Redis 只需通过
epoll_ctl将 Socket 加入树中 - 无需像
select/poll那样每次全量拷贝 FD 列表
- Redis 只需通过
-
就绪链表(Ready List):当 Socket 有数据到达时,硬件中断触发内核回调函数,将该 FD 加入此链表
2.3 完整的事件处理生命周期
以下通过客户端发送 GET name 指令的完整路径来展示 Redis 事件处理机制:
第一阶段:注册与监听
- 建立连接:新客户端连接时,
epoll监听到 Server Socket 就绪,触发连接应答处理器 - 事件注册:Redis 将该客户端 Socket 的
AE_READABLE事件注册到epoll红黑树,关联命令请求处理器
第二阶段:事件就绪(内核感知)
- 硬件中断:数据包到达网卡,触发 CPU 硬件中断
- 数据就位:内核将数据从网卡搬运到内核缓冲区,Socket 状态变为"可读"
- 链表填充:内核回调机制将该 FD 放入
epoll的就绪链表
第三阶段:任务下发(Redis 唤醒)
epoll_wait返回:Redis 主线程从epoll_wait调用中醒来,获取就绪 FD 列表- 事件分发:分派器根据 FD 的可读事件,将其交给命令请求处理器
第四阶段:业务执行(单线程执行引擎)
- 读取指令:Redis 调用
read(fd),将GET name从内核缓冲区拷贝到用户缓冲区 - 执行命令:Redis 顺序解析指令、从内存查找数据、生成结果
- 暂存结果:结果存入客户端回复缓冲区,注册该 Socket 的
AE_WRITABLE事件
第五阶段:结果返回
- 可写触发:当 Socket 发送缓冲区有空间时,
epoll_wait再次通知 Redis - 写回客户端:调用命令回复处理器执行
write(fd),数据经网卡发往客户端
三、Redis的网络模型演进
3.1 Redis 4.0 之前:纯单线程模型
- 所有网络 I/O 和命令执行都在单个主线程中完成
- 利用 I/O 多路复用处理并发连接
- 简单高效,避免了锁竞争和上下文切换
3.2 Redis 4.0:引入异步线程
- 针对大键值对的删除操作(如
UNLINK、FLUSHDB ASYNC)使用异步线程 - 避免大键删除阻塞主线程过长时间
3.3 Redis 6.0:网络 I/O 多线程
- 背景:随着网络带宽提升,网络 I/O 成为瓶颈
- 改进:引入多线程处理网络数据的读写
- 架构:
- 多个 I/O 线程并行读取客户端请求,解析命令
- 解析后的命令仍由主线程顺序执行
- 结果写回时,再次使用多线程发送给客户端
重要原则:命令执行始终保持单线程,保证原子性和简单性,只有网络 I/O 使用多线程。
四、性能优化总结
4.1 Redis 高性能的关键因素
| 因素 | 具体实现 | 性能收益 |
|---|---|---|
| 内存存储 | 所有数据在内存中 | 微秒级读写延迟 |
| 单线程执行 | 避免上下文切换 | 减少CPU开销,无锁竞争 |
| I/O多路复用 | epoll 事件驱动 | 高并发连接处理 |
| 高效数据结构 | 自定义数据结构 | 减少内存占用,快速操作 |
| 渐进式优化 | 6.0网络多线程 | 适应高带宽场景 |
4.2 适用场景与限制
适用场景:
- 高并发读写
- 缓存、会话存储
- 消息队列、排行榜
- 实时分析
性能限制:
- 单线程 CPU 密集型操作可能成为瓶颈
- 大键操作可能阻塞主线程
- 网络延迟对性能影响显著
五、参考资料
本文合并自 [[Redis/参考文档/RedisIO多路复用.md]] 和 [[Redis/重要知识点/Redis IO模型.md]] 的内容,并进行了结构优化和内容补充。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)