X00233-基于KMeans聚类的航空公司客户价值识别
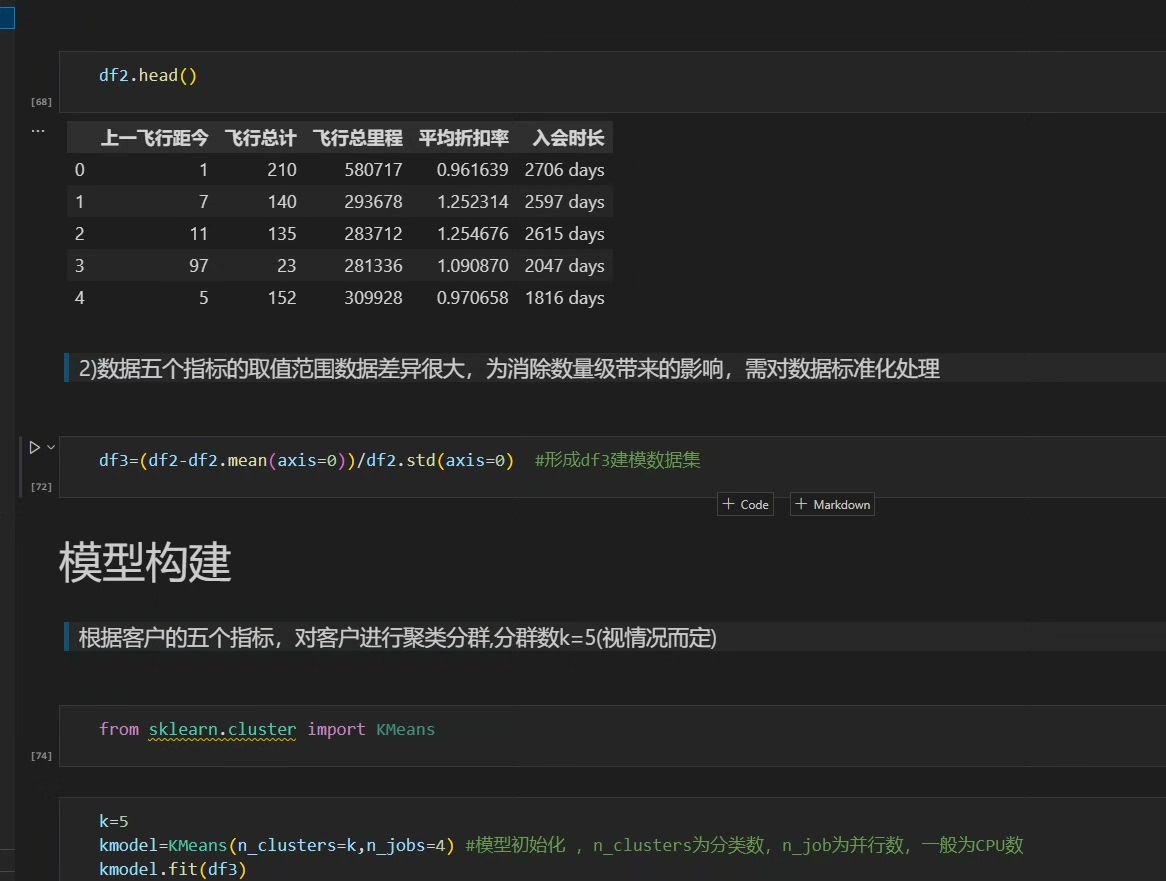
X00233-通过航空公司数据识别不同客户价值KMeans聚类 通过航空公司客户数据识别不同价值的客户。 识别客户价值应用最广泛的模型是通过3个指标(最近消费时间间隔、消费频带和消费金额)来进行客户细分,识别出高价值的客户,简称REFM 。 在RFM模型中,消费金额表示在一段时间内, 客户该企业产品金额的总和由于航空票价受到运输距离、舱位等级等多种因素影响,同样消费金额的不同旅名对航空公司的价值是不同的。 例如,一位长航线、低等级舱位票的旅各与一位短航线、高等级验位票的旅客相比,后者对于航空公司而言价值可能更高。 因此,这个指标并不适用于航空公司的客户价值分析151我们选择客户在一定时间内累积的飞行里程M和客户在一定时间内乘坐舱位所对应的折扣系数的平均值两个指标代替消费金额。 此外,考虑航空公司会员人会时间的长短在定程度上能够影响客户价值,所以在模型中增加客户关系长度L.作烟区分客户的另一指标。
老司机们都知道,客户分群这事就像给自家果园分苹果——得按酸甜程度装筐。航空公司的客户价值识别更是门技术活,传统RFM模型在这儿容易崴脚,咱们今天用Python整点硬核的,搞个定制版LRFMC模型。
X00233-通过航空公司数据识别不同客户价值KMeans聚类 通过航空公司客户数据识别不同价值的客户。 识别客户价值应用最广泛的模型是通过3个指标(最近消费时间间隔、消费频带和消费金额)来进行客户细分,识别出高价值的客户,简称REFM 。 在RFM模型中,消费金额表示在一段时间内, 客户该企业产品金额的总和由于航空票价受到运输距离、舱位等级等多种因素影响,同样消费金额的不同旅名对航空公司的价值是不同的。 例如,一位长航线、低等级舱位票的旅各与一位短航线、高等级验位票的旅客相比,后者对于航空公司而言价值可能更高。 因此,这个指标并不适用于航空公司的客户价值分析151我们选择客户在一定时间内累积的飞行里程M和客户在一定时间内乘坐舱位所对应的折扣系数的平均值两个指标代替消费金额。 此外,考虑航空公司会员人会时间的长短在定程度上能够影响客户价值,所以在模型中增加客户关系长度L.作烟区分客户的另一指标。
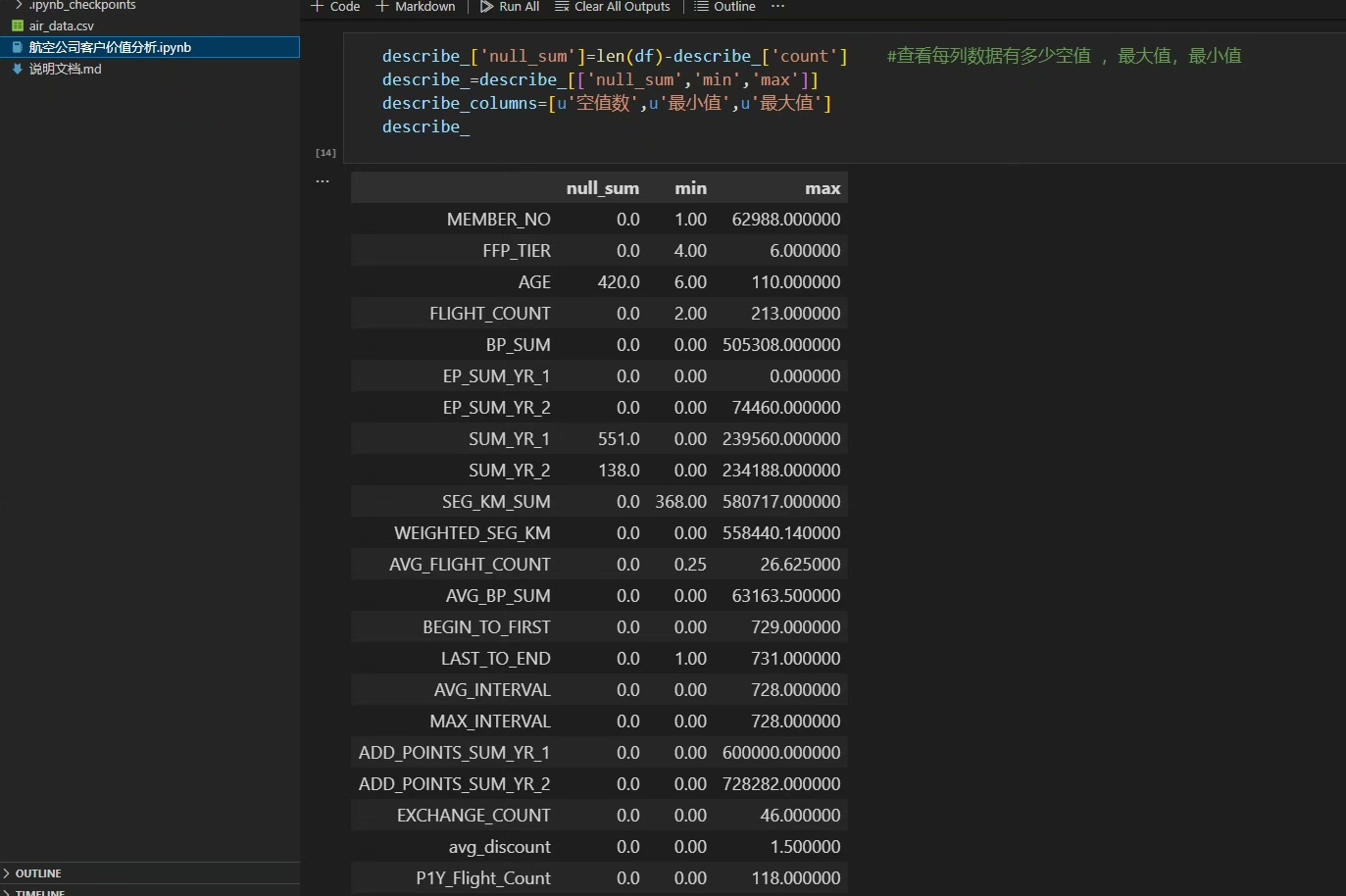
先看数据长啥样。原始数据里藏着入会日期、最近乘机时间、飞行次数这些宝贝字段:
import pandas as pd
raw_data = pd.read_csv('airline.csv')
print(raw_data[['FFP_DATE','LAST_FLIGHT_DATE','FLIGHT_COUNT']].head(2))
# FFP_DATE LAST_FLIGHT_DATE FLIGHT_COUNT
# 0 2006/11/2 2014/1/31 210
# 1 2008/5/3 2014/1/19 140特征工程这块得下猛料。L代表客户资历(入会时长),R是最近消费间隔,F是飞行次数,M是总里程,C是平均折扣:
# 计算L特征
raw_data['LOAD_TIME'] = pd.to_datetime('2014-2-1') # 假设分析时点
raw_data['L'] = (raw_data['LOAD_TIME'] - pd.to_datetime(raw_data['FFP_DATE'])).dt.days//30
# 计算R特征
raw_data['R'] = (pd.to_datetime('2014-2-1') - pd.to_datetime(raw_data['LAST_FLIGHT_DATE'])).dt.days
# 聚合计算FMC
fmc = raw_data.groupby('MEMBER_NO').agg(
F=('FLIGHT_COUNT','sum'),
M=('SEG_KM_SUM','sum'),
C=('avg_discount','mean')
)
lrfmc_data = pd.concat([raw_data[['L','R']], fmc], axis=1)标准化处理别偷懒,KMeans对量纲敏感得像新买的球鞋:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaled_data = scaler.fit_transform(lrfmc_data)
# 看眼处理后的数据分布
pd.DataFrame(scaled_data).hist(figsize=(10,6))确定聚类数这事好比试吃汤圆,得一个个尝。手肘法搭配轮廓系数双保险:
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
sse = []
sil_score = []
for k in range(2,9):
kmeans = KMeans(n_clusters=k, random_state=666)
kmeans.fit(scaled_data)
sse.append(kmeans.inertia_)
plt.plot(range(2,9), sse, 'bo-')
plt.xlabel('K值')
plt.ylabel('SSE')当曲线在K=5出现明显拐点,这数就成了。上主菜开始聚类:
final_kmeans = KMeans(n_clusters=5, random_state=666)
clusters = final_kmeans.fit_predict(scaled_data)
# 把分群结果绑回原数据
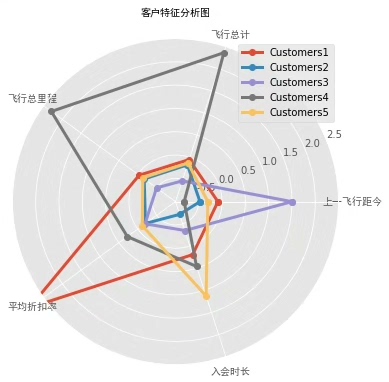
lrfmc_data['CLUSTER'] = clusters画个雷达图看得更明白,各群特征门儿清:
import numpy as np
cluster_means = lrfmc_data.groupby('CLUSTER').mean()
labels = ['L','R','F','M','C']
fig = plt.figure(figsize=(10,6))
for i in range(5):
ax = fig.add_subplot(2,3,i+1, polar=True)
stats = cluster_means.loc[i,labels].values
angles = np.linspace(0, 2*np.pi, len(labels), endpoint=False)
stats = np.concatenate((stats,[stats[0]]))
angles = np.concatenate((angles,[angles[0]]))
ax.plot(angles, stats, 'o-')
ax.fill(angles, stats, alpha=0.25)这么一折腾,五类客户现原形:
- 高价值老司机(L长,R短,FMC全高)
- 潜力萌新(L短但消费活跃)
- 濒临流失客户(R值爆表)
- 价格敏感型(C值低但F高)
- 佛系乘客(各项指标平平)
实战中发现,那些飞行次数多但折扣系数高的客户,虽然总消费金额不一定最高,但他们的舱位选择习惯给航空公司带来的利润更持久。反倒是有些长途经济舱客户,看似贡献流水多,实际边际利润可能还赶不上短途商务客。
调参有个坑得提醒:当数据存在明显偏态时,别直接用StandardScaler,试试RobustScaler或者做对数变换。上次我忘记处理R特征的右偏分布,结果聚类效果就跟没对焦的照片似的——全是糊的。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)