大语言模型智能体架构深度解析:为什么必须通过 Tool Result 注入外部数据而非篡改 System Prompt
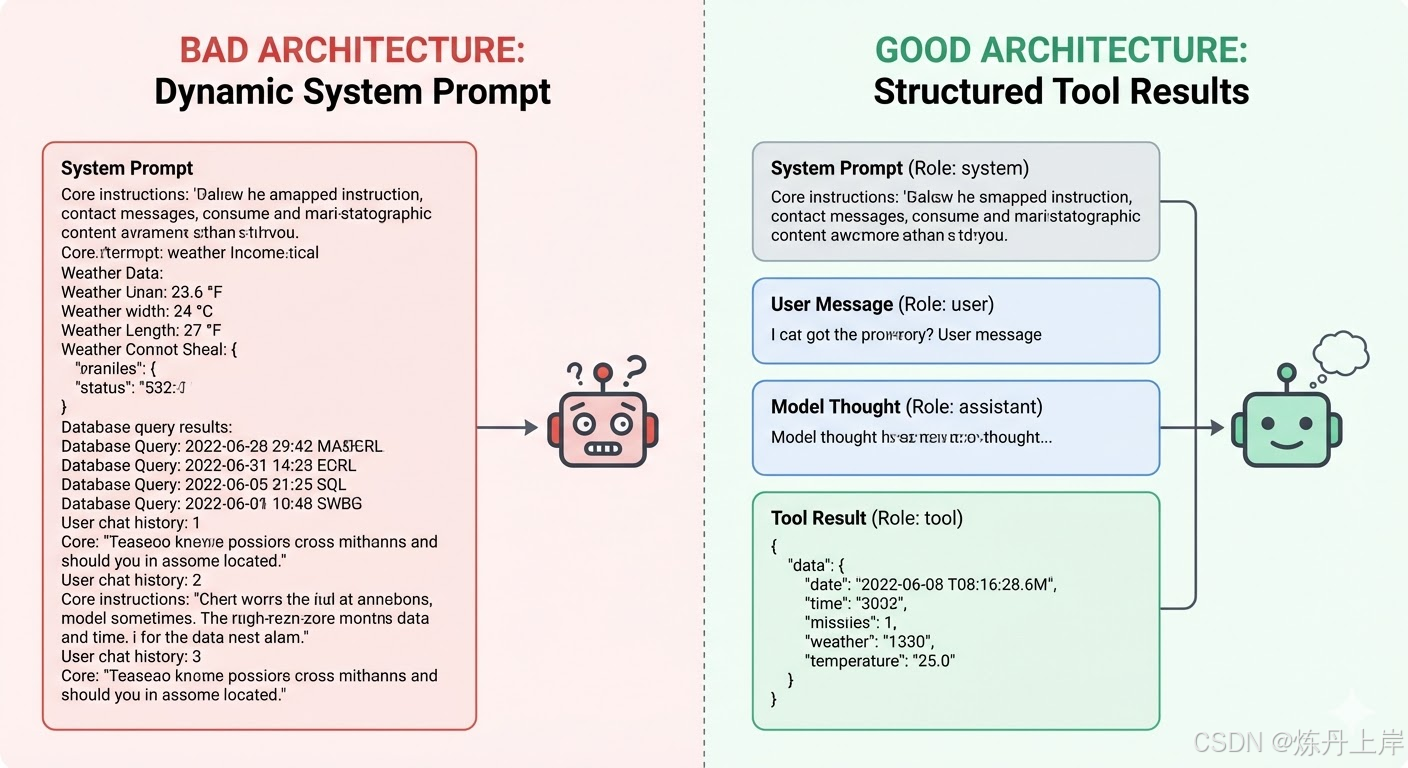
在设计与编排大语言模型(LLM)智能体的过程中,开发者常常会面临一个直觉上的架构悖论:既然所有的工具执行结果(Tool Result)最终都会被合并成一整段文本字符串(Prompt)送入模型,为什么不能简单地将外部结果直接动态拼接在系统提示词(System Prompt)里?
本文将深入剖析底层推理逻辑,论证为什么通过标准的 tool_result 注入外部上下文是现代 AI 系统设计中不可逾越的架构红线。
一、 揭开“大一统”提示词的假象:底层分词器与聊天模板机制
要理解系统提示词与工具调用结果的本质区别,必须考察 API 请求是如何转化为数学张量的。
1. 聊天模板与控制词元的语义边界
在分词器(Tokenizer)层面,结构化数据通过聊天模板(Chat Templates)被压平。在这个过程中,分词器会隐式注入控制词元(Control Tokens),如 <|im_start|>system 或 <|tool_execute|>。
- 系统提示词: 紧随
<|im_start|>system,被训练为绝对的规则和长期角色设定。 - 工具结果: 紧随
<|im_start|>tool,被视为瞬时事实数据。
2. 分布偏移对指令遵循的破坏
如下表对比了不同注入方式在底层字符串形态上的差异:
| 架构选择 | 分词器处理后的底层字符串形态示例 (以 ChatML 为例) | 模型的内在语义解析 |
|---|---|---|
| 错误:系统提示词拼接 | `< | im_start |
| 正确:工具结果消息 | `< | im_start |
二、 注意力机制的诅咒:指令漂移与系统提示词的纯洁性
大模型处理文本的核心是自注意力机制(Self-Attention)。
1. 系统提示词的定位:持久化的“岗位职责”
系统提示词应当被严格视为 AI 的“岗位职责(Job Description)”。它包含高阶指令、角色设定(Persona)和工具签名规范。
2. 认知过载与指令层次结构的崩溃
- 指令漂移(Instruction Drift): 当系统提示词塞满动态数据时,相关的指令被迫与大量不相关内容竞争注意力。
- 渐进式信息披露: 通过
tool_result将数据追加到末尾,确保了模型能清晰区分“必须遵守的规则”与“正在处理的数据”。
三、 经济学与物理学的双重约束:KV 缓存(Prompt Caching)
决定该做法不可行的最致命因素,来源于基础设施层的物理约束。
1. Prefill 阶段与 KV 张量的持久化
推理分为预填充阶段(Prefill)和解码阶段(Decode)。预填充阶段计算的键/值张量(KV Tensors)可以被缓存。
2. 精确前缀匹配的要求
提示词缓存生效的前提是**“精确前缀匹配”**。
- 反模式: 修改系统提示词会破坏前缀哈希,导致缓存未命中(Cache Miss)。
- 后果: 首字延迟(TTFT)大幅拉长,且无法享受高达 90% 的成本折扣。
| 架构维度 | 系统提示词动态拼接方案 (反模式) | Tool Result 消息流方案 (最佳实践) |
|---|---|---|
| 序列前缀稳定性 | 极差,每次注入都会改变。 | 完美,系统指令固定在前端。 |
| KV Cache 命中率 | 几乎为零。 | 极高。 |
| 首字延迟 (TTFT) | 极高,需执行完整预填充。 | 极低,利用缓存缩减 80% 延迟。 |
| API 输入成本 | 全额计费。 | 大幅降低,静态前缀享 90% 折扣。 |
四、 零信任架构下的智能体安全:防御提示词注入攻击
在大模型中,执行指令与数据之间不存在严格的句法隔离。
- 危险: 若将网页拉取结果塞入系统提示词,等于赋予了外部数据 “Root 权限”。
- 隔离: 通过
role: "tool"注入数据,建立了一道检疫区(Quarantine Zone)。
纵深防御设计模式
- 上下文最小化模式: 敏感数据与原始注入载荷不在同一窗口出现。
- 代码后执行模式: 通过沙箱运行脚本处理数据,切断恶意回流。
- 动作选择器模式: 限制模型为状态机,仅输出动作而非直接处理原始结果。
五、 动态上下文管理与大模型可观测性(Observability)
1. 上下文窗口耗尽与清理
- 结构化优势: 标准工具流允许 SDK 进行精准的上下文压缩(Context Compaction),通过摘要(Summary)替代冗长的原始数据。
- 清理策略: 自动识别并清除老旧工具返回内容,为深度推理腾出空间。
2. 评估与追踪
引入标准工具流后,开发者可以利用 Langfuse 或 Weave 等平台追踪:
- 思维链(CoT): 了解模型调用工具的动机。
- 工具参数: 校验模型生成的结构化参数。
- 载荷与回复: 评估外部数据对最终回复的影响。
六、 主流大模型 API 层的 Tool Result 规范
| 平台 | 工具返回 Role | 核心校验要求 |
|---|---|---|
| OpenAI | tool |
必须包含与模型请求对应的 tool_call_id。 |
| Anthropic | user |
必须包含 tool_result 块且携带匹配的 tool_use_id。 |
functionResponse |
必须包含 name 字段以显式匹配函数名称。 |
结论:遵循大语言模型的物理与逻辑法则
系统提示词是**“宪法”(静态、高优先级),而工具结果是“呈堂证供”**(动态、临时流)。将两者混淆会引发认知失效、经济损失与安全风险。将工具结果作为结构化的离散消息放置在序列末端,是现代 LLM 智能体开发的绝对金科玉律。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)