15 回归分析-多元线性回归
Python 数据分析入门:多元线性回归——多个因素如何一起预测结果(附完整可视化案例)
很多初学者在学完一元线性回归之后,都会遇到一个很自然的问题:
现实中的预测问题,往往不是一个因素决定结果,而是多个因素共同作用。
这种情况下,应该怎么建模?
例如:
- 学生总评成绩,不只是由作业成绩决定
- 房价,不只是由面积决定
- 销售额,也不只是由广告投入决定
这时候,只用一个自变量建立模型,往往不能完整反映实际情况。更合理的做法是:
把多个因素同时纳入模型,分析它们对结果的共同影响。
这就是多元线性回归要解决的问题。
回归分析是一种预测性的建模技术,研究的是因变量(目标)和自变量(预测器)之间的关系,通常用于预测分析、时间序列模型以及发现变量之间的因果关系 [1]。根据因变量和自变量的个数,回归分析可以分为一元回归分析、多元回归分析、逻辑回归分析和其他回归分析;线性回归是其中最基本的方法 [1]。
本文围绕“多个因素如何一起预测结果”这一主题,介绍:
- 什么是多元线性回归
- 它和一元线性回归有什么区别
- 什么情况下适合使用多元线性回归
- 如何用 Python 建立一个多元线性回归模型
- 如何通过图表对模型结果进行可视化分析
摘要
多元线性回归是回归分析中的重要形式,适用于多个自变量共同影响一个因变量的场景。回归分析本质上是一种预测性的建模技术,用于研究因变量与自变量之间的关系,并服务于预测分析、时间序列建模以及变量关系研究 [1]。本文以“学生总评成绩预测”为案例,介绍多元线性回归的基本思想、适用场景与建模流程,并结合 Python 给出包含相关性热力图、真实值与预测值对比图、误差图和回归系数图的完整可视化示例。
一、为什么要学习多元线性回归?
一元线性回归适合“一个自变量预测一个因变量”的场景。
例如:
- 用学习时长预测考试成绩
- 用房屋面积预测房价
但在很多真实问题中,结果并不是由单一因素决定的。
例如在学生成绩分析中,总评成绩往往同时受到:
- 作业成绩
- 考勤情况
- 课堂表现
- 实验成绩
等多个因素影响。
如果只选取其中一个变量进行预测,虽然模型可以建立,但信息往往不够完整,预测能力和解释能力都会受到限制。
因此,当一个结果明显受到多个因素共同作用时,就更适合使用多元线性回归。
二、什么是多元线性回归?
回归分析是一种通过对数据进行分析实现预测的方法 [1]。根据自变量和因变量个数的不同,可以分为一元回归分析和多元回归分析 [1]。
所谓多元线性回归,可以理解为:
当一个因变量同时受到多个自变量影响时,利用线性关系建立预测模型的方法。
它的特点是:
- 因变量只有一个
- 自变量有多个
- 这些自变量共同作用于结果
例如:
| 场景 | 自变量 | 因变量 |
|---|---|---|
| 学生成绩预测 | 作业成绩、考勤、课堂表现、实验成绩 | 总评成绩 |
| 房价预测 | 面积、楼层、房龄、地段评分 | 房价 |
| 销售预测 | 广告投入、促销次数、门店数量 | 销售额 |
所以,多元线性回归本质上就是:
多个因素一起预测一个连续值结果。
三、多元线性回归和一元线性回归有什么区别?
一元线性回归和多元线性回归都属于线性回归,它们的核心思想是一致的,都是通过建立线性关系来进行预测。不同之处主要在于自变量的数量。
一元线性回归
- 只有 1 个自变量
- 更适合单因素问题
多元线性回归
- 有多个自变量
- 更适合多因素共同影响结果的问题
简单来说:
- 一元线性回归是“一个因素看结果”
- 多元线性回归是“多个因素一起看结果”
由于现实中的很多问题都具有多因素特征,因此多元线性回归往往比一元线性回归更接近实际应用场景。
四、多元线性回归适用于什么场景?
多元线性回归适合以下类型的问题:
1. 一个结果受到多个因素影响
例如:
- 学生总评受平时成绩、考勤、课堂表现共同影响
- 房价受面积、楼层、地段等因素共同影响
- 销售额受广告投入、节假日活动、价格调整等因素共同影响
2. 既想预测结果,又想分析影响因素
除了预测结果,很多场景还希望进一步分析:
- 哪个因素影响更大
- 哪个因素影响更稳定
- 多个因素合在一起时,模型整体效果如何
这些都属于多元线性回归的典型应用。
五、回归分析的一般过程
回归分析的一般过程包括以下几个步骤 [1]:
- 收集一组包含因变量和自变量的数据
- 根据因变量和自变量之间的关系,初步设定回归模型
- 求解合理的回归系数
- 进行相关性检验,确定相关系数
- 利用模型对因变量作出预测或解释,并计算预测值的置信区间
多元线性回归同样遵循这一过程:
- 先准备多变量数据
- 再建立线性模型
- 然后进行预测和效果分析
六、案例:用多个学习指标预测学生总评成绩
下面通过一个完整案例,演示多元线性回归的建模与可视化分析过程。
案例背景
已知某班学生的以下数据:
- 作业成绩
- 考勤成绩
- 课堂表现
- 实验成绩
现在希望根据这些指标,共同预测学生的总评成绩。
这是一个典型的多元线性回归问题:
- 自变量:多个学习表现指标
- 因变量:总评成绩
下面的代码将输出多种图表,包括:
- 相关性热力图
- 真实值与预测值散点图
- 测试集真实值与预测值对比图
- 预测误差柱状图
- 回归系数柱状图
- 模型评价指标柱状图
七、Python 实战代码:完整可视化版本
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import font_manager
import seaborn as sns
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
# =========================
# 1. 设置中文字体
# =========================
font_path = "simfang.ttf" # 请确认路径下有该字体文件
font_prop = font_manager.FontProperties(fname=font_path)
plt.rcParams["font.family"] = font_prop.get_name()
plt.rcParams["axes.unicode_minus"] = False
# =========================
# 2. 构造示例数据
# =========================
data = pd.DataFrame({
'作业成绩': [80, 85, 78, 90, 88, 76, 95, 89, 84, 91, 87, 79],
'考勤成绩': [90, 92, 85, 96, 94, 80, 98, 93, 89, 97, 91, 84],
'课堂表现': [85, 88, 80, 92, 90, 78, 96, 91, 86, 94, 89, 82],
'实验成绩': [82, 86, 79, 91, 89, 75, 97, 90, 85, 93, 88, 80],
'总评成绩': [84, 88, 80, 93, 90, 77, 97, 91, 86, 95, 89, 81]
})
# =========================
# 3. 划分自变量和因变量
# =========================
X = data[['作业成绩', '考勤成绩', '课堂表现', '实验成绩']]
y = data['总评成绩']
# =========================
# 4. 划分训练集和测试集
# =========================
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42
)
# =========================
# 5. 创建并训练模型
# =========================
model = LinearRegression()
model.fit(X_train, y_train)
# =========================
# 6. 预测
# =========================
y_pred = model.predict(X_test)
# =========================
# 7. 模型评价指标
# =========================
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
print("回归系数:")
for feature, coef in zip(X.columns, model.coef_):
print(f"{feature}: {coef:.4f}")
print("截距:", round(model.intercept_, 4))
print("测试集真实值:", list(y_test))
print("测试集预测值:", [round(v, 2) for v in y_pred])
print("MAE:", round(mae, 4))
print("MSE:", round(mse, 4))
print("RMSE:", round(rmse, 4))
print("R²:", round(r2, 4))
# =========================
# 8. 图1:相关性热力图
# =========================
plt.figure(figsize=(8, 6))
sns.heatmap(data.corr(), annot=True, cmap='Blues', fmt=".2f")
plt.title("各变量相关性热力图")
plt.show()
# =========================
# 9. 图2:真实值 vs 预测值散点图
# =========================
plt.figure(figsize=(7, 5))
plt.scatter(y_test, y_pred, color='blue', s=80)
plt.plot([y.min(), y.max()], [y.min(), y.max()], 'r--', linewidth=2)
plt.xlabel("真实值")
plt.ylabel("预测值")
plt.title("测试集真实值与预测值散点图")
plt.grid(alpha=0.3)
plt.show()
# =========================
# 10. 图3:测试集真实值与预测值对比图
# =========================
plt.figure(figsize=(8, 5))
x_index = np.arange(len(y_test))
plt.plot(x_index, y_test.values, marker='o', linewidth=2, label='真实值')
plt.plot(x_index, y_pred, marker='s', linewidth=2, label='预测值')
plt.xticks(x_index, [f"样本{i+1}" for i in range(len(y_test))])
plt.xlabel("测试样本")
plt.ylabel("总评成绩")
plt.title("测试集真实值与预测值对比")
plt.legend()
plt.grid(alpha=0.3)
plt.show()
# =========================
# 11. 图4:预测误差柱状图
# =========================
errors = y_test.values - y_pred
plt.figure(figsize=(8, 5))
bars = plt.bar([f"样本{i+1}" for i in range(len(errors))], errors, color='#55A868')
plt.axhline(0, color='red', linestyle='--')
plt.xlabel("测试样本")
plt.ylabel("误差(真实值-预测值)")
plt.title("测试集预测误差柱状图")
plt.grid(axis='y', alpha=0.3)
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2, height,
f"{height:.2f}", ha='center',
va='bottom' if height >= 0 else 'top')
plt.show()
# =========================
# 12. 图5:回归系数柱状图
# =========================
plt.figure(figsize=(8, 5))
coef_series = pd.Series(model.coef_, index=X.columns)
bars = plt.bar(coef_series.index, coef_series.values, color='#4C72B0')
plt.xlabel("自变量")
plt.ylabel("回归系数")
plt.title("各自变量回归系数对比")
plt.grid(axis='y', alpha=0.3)
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2, height,
f"{height:.2f}", ha='center',
va='bottom' if height >= 0 else 'top')
plt.show()
# =========================
# 13. 图6:模型评价指标柱状图
# =========================
metric_names = ['MAE', 'MSE', 'RMSE', 'R²']
metric_values = [mae, mse, rmse, r2]
plt.figure(figsize=(8, 5))
bars = plt.bar(metric_names, metric_values,
color=['#4C72B0', '#55A868', '#C44E52', '#8172B2'])
plt.title("模型评价指标可视化")
plt.ylabel("指标值")
plt.grid(axis='y', alpha=0.3)
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2, height,
f"{height:.3f}", ha='center', va='bottom')
plt.show()
八、代码结果怎么看?
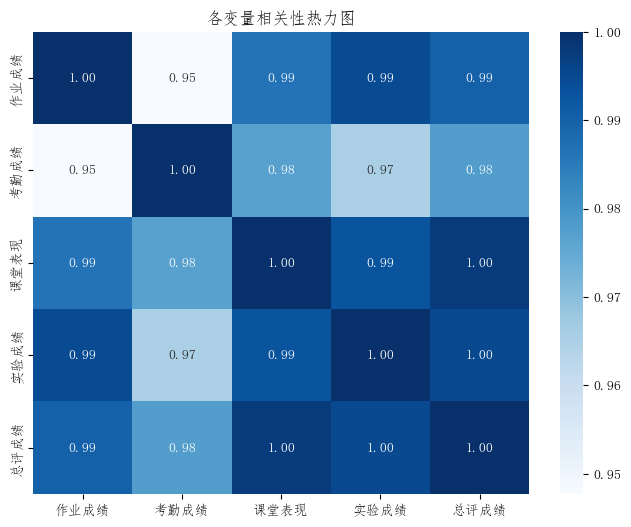
1. 相关性热力图
热力图可以直接展示各变量之间的相关程度。
这一步有助于观察:
- 哪些变量与总评成绩关系更明显
- 哪些自变量之间可能存在较强相关性
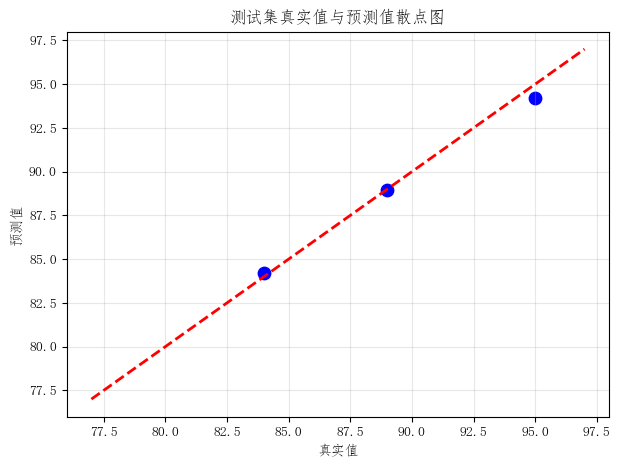
2. 真实值与预测值散点图
这张图中:
- 横轴是真实值
- 纵轴是预测值
如果散点大多靠近对角线,说明模型预测效果较好;如果偏离较远,说明模型误差较大。
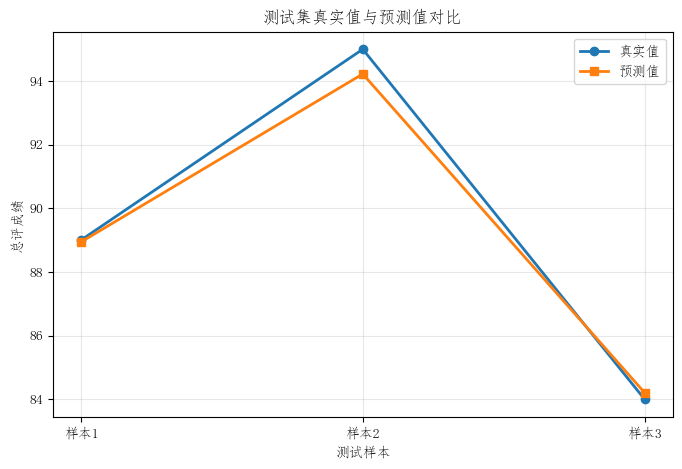
3. 测试集真实值与预测值对比图
这张图可以逐个样本比较真实值与预测值,更容易观察:
- 哪些样本预测得更准确
- 哪些样本存在明显偏差
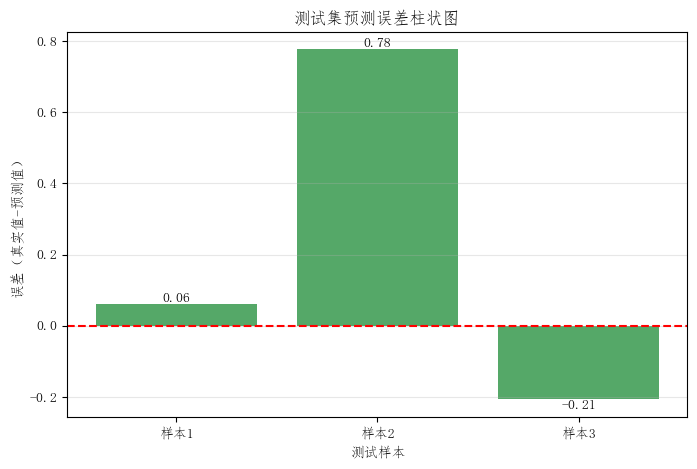
4. 预测误差柱状图
误差柱状图展示的是真实值减去预测值:
- 柱子高于 0,说明模型低估了真实值
- 柱子低于 0,说明模型高估了真实值
5. 回归系数柱状图
回归系数图可以直观展示不同自变量对结果的影响方向和相对大小。
系数越大,通常说明该变量对总评成绩的影响越明显。
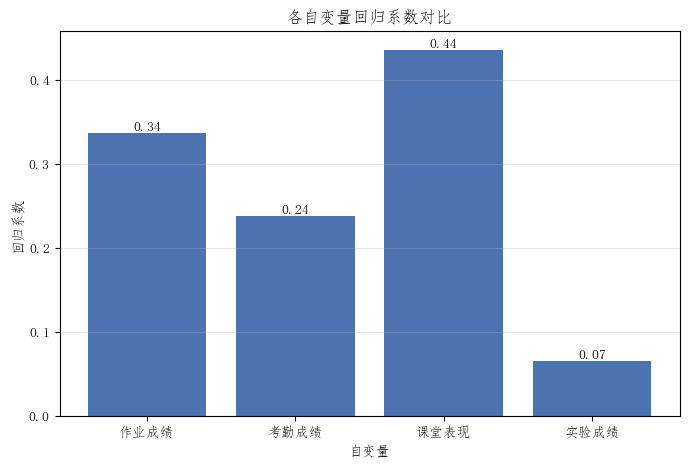
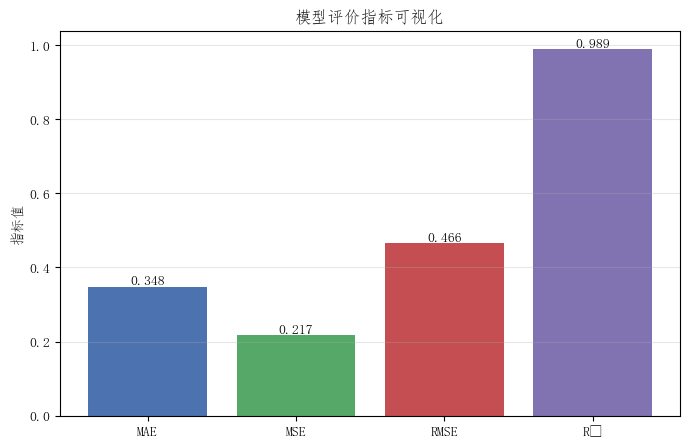
6. 模型评价指标柱状图
代码中给出了 4 个常见指标:
- MAE
- MSE
- RMSE
- R²
一般来说:
- MAE、MSE、RMSE 越小越好
- R² 越大越好
九、学习多元线性回归时常见的误区
1. 认为自变量越多越好
不是。
变量过多可能带来冗余信息,反而影响模型分析效果。
2. 只关注预测结果,不分析变量作用
多元线性回归的价值不仅在于预测,还在于分析多个因素对结果的共同影响。
3. 只输出指标,不做图形分析
仅看数字往往不够直观,图表更有助于理解模型表现和变量关系。
4. 把“模型跑通”当成“模型解释清楚”
模型运行成功只是第一步,更重要的是解释:
- 为什么这样建模
- 哪些变量更重要
- 模型效果如何
- 误差表现怎样
十、总结
多元线性回归是回归分析中的重要内容,适用于多个自变量共同影响一个因变量的场景。回归分析的一般过程包括数据收集、模型设定、回归系数求解、相关性检验以及利用模型进行预测或解释 [1]。因此,多元线性回归不仅是“多放几个变量”,而是一个完整的数据分析与预测过程。
通过本文的案例,可以建立以下几个基本认识:
- 多元线性回归适合多因素共同影响结果的问题
- 它比一元线性回归更接近真实应用场景
- 建模之后不仅要看预测值,还要结合图表分析模型效果
- 回归系数、预测误差和评价指标都是结果分析的重要部分
从入门角度看,可以把多元线性回归概括为一句话:
当一个结果受到多个因素共同影响时,用线性模型把这些因素整合起来进行预测和分析。
写在最后
如果这篇文章对你有帮助,欢迎点赞、收藏、评论支持一下。
你在学习多元线性回归时,最容易卡住的是哪一部分?
- 不知道怎么选自变量
- 看不懂回归系数
- 不清楚图表该怎么画
- 还是模型能跑但不会解释结果
欢迎在评论区交流。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)