14 回归分析-一元线性回归的统计检验与模型评价
Python 数据分析入门:一元线性回归的统计检验与模型评价(附可视化 Python 实战案例)
适合人群:Python 初学者 / 数据分析入门 / 机器学习入门 / 教学案例分享
很多初学者在学习一元线性回归时,容易产生一个误解:只要画出一条回归直线,模型就算完成了。
实际上,这只是回归分析的起点。在线性回归建模之后,还需要进一步回答几个关键问题:
- 回归直线与样本数据的贴合程度如何?
- 自变量和因变量之间是否存在较明显的关系?
- 模型误差是否处于可接受范围?
- 模型能否用于实际预测?
这些问题对应的,正是一元线性回归中的模型检验与效果评价。
本文围绕“一元线性回归的统计检验与模型评价”展开,结合 Python 示例,介绍以下内容:
- 为什么一元线性回归建模后还需要评价
- 什么是训练误差、测试误差和泛化能力
- 为什么测试误差比训练误差更值得关注
- MAE、MSE、RMSE、R² 等常见指标的含义
- 如何通过可视化方式分析回归模型效果
文章摘要
本文介绍一元线性回归中的模型检验与效果评价方法。回归分析是一种预测性的建模技术,研究因变量与自变量之间的关系,常用于预测分析、时间序列模型以及变量关系研究。文章结合“作业成绩预测期末成绩”的示例,说明为什么回归模型不能停留在“画出回归线”这一步,而应进一步考察模型在测试数据上的表现,并借助 MAE、MSE、RMSE、R² 等指标及可视化图形,分析模型的预测误差与解释能力。
一、为什么回归模型不能只看“能不能画线”?
回归分析是一种预测性的建模技术,研究的是因变量(目标)和自变量(预测器)之间的关系,通常用于预测分析、时间序列模型以及发现变量之间的因果关系。
从任务类型看,回归问题和分类问题形式相似,但二者的预测目标不同:在分类问题中,预测值 y 是离散变量,代表类别;而在回归问题中,y 是连续变量。这意味着,回归模型的目标不仅是得到一条拟合直线,更重要的是利用这种关系解释变量变化,并对连续结果进行预测。
因此,仅仅“画出一条线”并不能说明模型一定有效。真正需要关注的是:
- 模型对已有数据的拟合情况
- 模型对变量关系的解释能力
- 模型在新数据上的预测表现
二、回归模型为什么还需要评价?
回归分析不仅可以表明自变量和因变量之间是否存在显著关系,还可以反映多个自变量对一个因变量的影响强度。这说明,建立回归方程并不是终点,还需要进一步判断:
- 变量关系是否稳定
- 模型是否具有解释意义
- 模型是否具有实际预测价值
回归分析的一般过程包括:收集数据、初步设定回归模型、求解回归系数、进行相关性检验,并利用模型作出预测或解释。其中,模型评价正是连接“建模结果”和“实际应用”的关键步骤。
三、训练误差、测试误差与泛化能力
在线性回归的效果分析中,训练误差、测试误差和泛化能力是几个非常重要的概念。
通常来说:
- 训练误差:模型在训练样本上的误差
- 测试误差:模型在测试样本上的误差
- 泛化能力:模型对未知新样本的预测能力
在模型评价中,更值得关注的是测试误差,因为它更能反映模型在新数据上的表现。一个模型如果只在训练集上效果很好,而在测试集上表现较差,通常说明它对训练样本的适应过强,而对新样本的预测能力不足。
换句话说,模型评价的重点,不在于“训练得有多像”,而在于“面对没见过的数据时表现如何”。
四、为什么测试误差比训练误差更重要?
模型的最终用途通常不是解释已经见过的数据,而是对未来或未知数据进行预测。因此,测试误差比训练误差更具有参考价值。
如果一个模型在训练集上误差很小,但在测试集上误差明显增大,说明模型未必真正掌握了变量之间的规律,而可能只是过度适应了训练数据。这种情况下,模型虽然“看上去很好”,但实际预测能力并不理想。
因此,在回归模型评价中,测试集表现通常比训练集表现更值得重视。
五、模型复杂度、欠拟合与过拟合
在实际建模中,能够解释数据的模型往往不止一个。
模型过于简单时,可能无法充分反映数据中的规律;模型过于复杂时,又可能把训练数据中的随机波动甚至噪声也学进去。
这两种情况通常表现为:
- 欠拟合:模型过于简单,不能较好刻画数据关系
- 过拟合:模型过于复杂,在训练集上效果很好,但测试集表现较差
因此,模型评价的意义之一,就是帮助判断当前模型复杂度是否合适。
对回归模型而言,真正理想的状态不是“训练误差最小”,而是“在测试集上表现稳定、具有较好泛化能力”。
六、回归模型常见评价指标
一元线性回归中,常见的评价指标包括:
- MAE
- MSE
- RMSE
- R²
这些指标主要从两个方面衡量模型:
- 预测误差大小
- 对数据变化的解释能力
七、MAE:平均绝对误差
MAE(Mean Absolute Error)表示平均绝对误差。
它的计算思路是:
- 先求每个样本的预测误差
- 对误差取绝对值
- 再求平均值
MAE 反映的是模型平均每次预测偏差多少。
例如,在成绩预测问题中,如果 MAE = 3,可以理解为模型平均每次预测大约相差 3 分。
MAE 的特点是:
- 含义直观
- 单位与原始数据一致
- 数值越小越好
八、MSE:均方误差
MSE(Mean Squared Error)表示均方误差。
它与 MAE 的区别在于,MSE 会先对误差进行平方,再求平均值。
这样一来,较大的误差会被进一步放大,因此 MSE 对“大偏差”更加敏感。
一般来说:
MSE 越小,说明模型整体误差越小。
九、RMSE:均方根误差
RMSE(Root Mean Squared Error)表示均方根误差。
它是在 MSE 的基础上再开平方。这样做的好处是:
- 数值单位恢复为原始数据单位
- 更便于结合具体业务场景解释结果
例如,在成绩预测中,如果 RMSE = 4,可以理解为模型预测值与真实值之间的典型偏差约为 4 分。
RMSE 同样遵循:
数值越小越好。
十、R²:决定系数
R²(R Squared)是回归分析中非常常见的指标,用来衡量模型对因变量变化的解释能力。
在入门阶段,可以将它理解为:
模型能够解释多少比例的数据变化。
通常情况下:
- R² 越接近 1,模型解释能力越强
- R² 越接近 0,模型解释能力越弱
因此,在模型评价时通常遵循下面的基本判断逻辑:
- MAE、MSE、RMSE:越小越好
- R²:越大越好
十一、案例:用作业成绩预测期末成绩
下面通过一个简单案例,演示如何对一元线性回归模型进行评价。
案例背景
已知一组学生数据,包括:
- 作业成绩
- 期末成绩
目标是建立一元线性回归模型,根据作业成绩预测期末成绩,并结合评价指标和图形分析模型效果。
十二、Python 实战代码:建模、预测与可视化
下面的代码包含以下内容:
- 划分训练集和测试集
- 训练一元线性回归模型
- 计算 MAE、MSE、RMSE、R²
- 绘制回归直线图
- 绘制真实值与预测值对比图
- 绘制评价指标柱状图
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import font_manager
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
# =========================
# 1. 设置中文字体,避免图表乱码
# =========================
font_path = "simfang.ttf" # 请确认当前目录下存在该字体文件
font_prop = font_manager.FontProperties(fname=font_path)
plt.rcParams["font.family"] = font_prop.get_name()
plt.rcParams["axes.unicode_minus"] = False
# =========================
# 2. 构造数据:作业成绩 -> 期末成绩
# =========================
X = np.array([60, 65, 70, 75, 80, 85, 90, 95]).reshape(-1, 1)
y = np.array([62, 66, 72, 78, 81, 86, 91, 96])
# =========================
# 3. 划分训练集和测试集
# =========================
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42
)
# =========================
# 4. 创建并训练模型
# =========================
model = LinearRegression()
model.fit(X_train, y_train)
# =========================
# 5. 测试集预测
# =========================
y_pred = model.predict(X_test)
# 用于绘制整体回归直线
y_all_pred = model.predict(X)
# =========================
# 6. 计算评价指标
# =========================
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
print("回归系数(斜率):", model.coef_[0])
print("截距:", model.intercept_)
print("测试集真实值:", y_test)
print("测试集预测值:", y_pred)
print("MAE:", mae)
print("MSE:", mse)
print("RMSE:", rmse)
print("R²:", r2)
# =========================
# 7. 散点图 + 回归直线
# =========================
plt.figure(figsize=(8, 5))
plt.scatter(X, y, color='blue', label='原始数据')
plt.plot(X, y_all_pred, color='red', linewidth=2, label='回归直线')
plt.xlabel("作业成绩")
plt.ylabel("期末成绩")
plt.title("一元线性回归:作业成绩预测期末成绩")
plt.legend()
plt.grid(alpha=0.3)
plt.show()
# =========================
# 8. 测试集真实值与预测值对比图
# =========================
plt.figure(figsize=(8, 5))
x_index = np.arange(len(y_test))
plt.plot(x_index, y_test, marker='o', label='真实值')
plt.plot(x_index, y_pred, marker='s', label='预测值')
plt.xticks(x_index, [f"样本{i+1}" for i in range(len(y_test))])
plt.xlabel("测试样本")
plt.ylabel("期末成绩")
plt.title("测试集真实值与预测值对比")
plt.legend()
plt.grid(alpha=0.3)
plt.show()
# =========================
# 9. 评价指标柱状图
# =========================
metric_names = ['MAE', 'MSE', 'RMSE', 'R²']
metric_values = [mae, mse, rmse, r2]
plt.figure(figsize=(8, 5))
bars = plt.bar(metric_names, metric_values,
color=['#4C72B0', '#55A868', '#C44E52', '#8172B2'])
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width() / 2, height,
f'{height:.3f}', ha='center', va='bottom')
plt.title("回归模型评价指标可视化")
plt.ylabel("指标值")
plt.grid(axis='y', alpha=0.3)
plt.show()
十三、结果分析
从输出结果和图形中,可以重点关注以下几个方面。
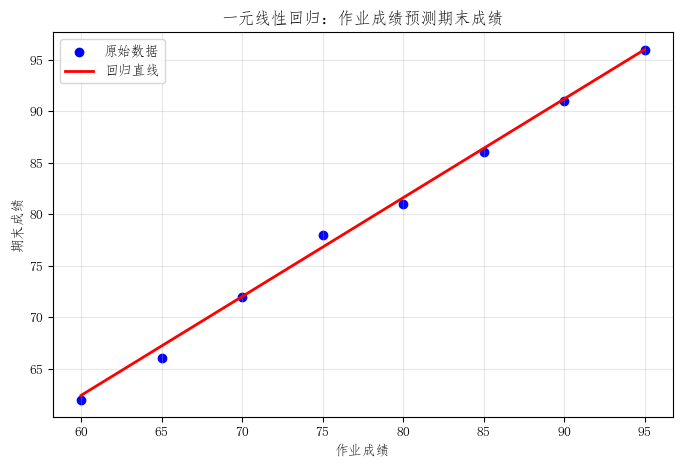
1)回归直线与原始数据的贴合程度
散点图与回归直线图能够直观展示模型的拟合情况。
如果样本点大多分布在回归直线附近,通常说明模型对数据关系的刻画较为合理。
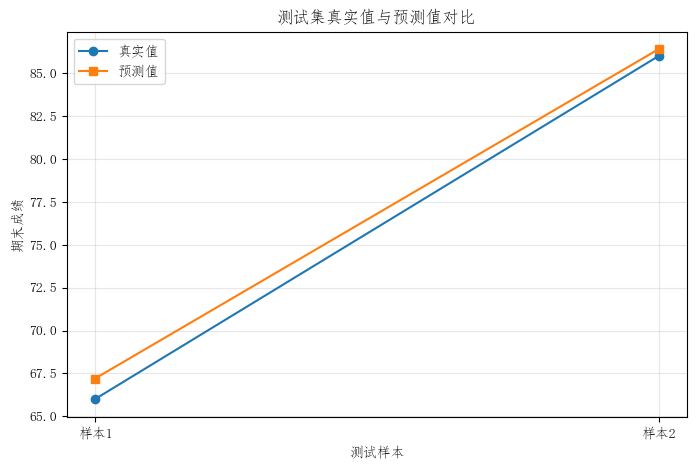
2)测试集真实值与预测值之间的差距
通过对比图可以清楚看到模型在测试样本上的预测表现。
如果预测值与真实值整体接近,说明模型在测试集上的误差相对较小。
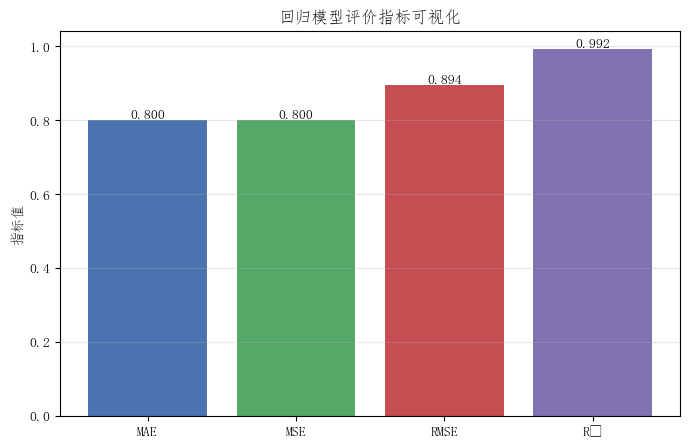
3)误差指标与解释能力指标
模型评价时需要同时关注两类指标:
- 误差指标:MAE、MSE、RMSE
- 解释能力指标:R²
其中:
- MAE、MSE、RMSE 越小越好
- R² 越大越好
十四、模型评价中常见的几个误区
1)只看训练集效果
训练集表现好,并不代表模型在新数据上也表现好。
模型最终是否可靠,更应参考测试集结果。
2)只看一个指标
只看 MAE 或只看 R²,都难以全面判断模型效果。
更合理的做法是结合多个指标综合分析。
3)忽视模型复杂度
模型并非越复杂越好。
模型过于简单可能欠拟合,过于复杂则可能过拟合。
4)把“拟合好”误认为“预测好”
模型对训练数据拟合得很好,不一定意味着它对测试数据也预测得好。
这正是区分训练误差和测试误差的意义所在。
十五、总结
回归分析是一种研究因变量与自变量关系的预测性建模技术,常用于预测分析以及变量关系研究。在一元线性回归中,建立模型只是第一步,更重要的是进一步评价模型是否可靠。
本文主要介绍了以下内容:
- 为什么回归模型不能只停留在“画出一条线”
- 什么是训练误差、测试误差和泛化能力
- 为什么测试误差比训练误差更值得关注
- MAE、MSE、RMSE、R² 的基本含义
- 如何结合 Python 代码与图形对回归模型进行分析
从实际应用角度看,回归模型评价的核心可以归纳为一句话:
不仅要看模型是否能够拟合已有数据,更要看它是否能够对未知数据做出合理预测。
写在最后
如果这篇文章对你有帮助,欢迎点赞、收藏、评论支持一下。
你在学习一元线性回归模型评价时,最容易卡住的是哪一部分?
- 训练集和测试集的区别
- MAE、MSE、RMSE、R² 的理解
- 欠拟合与过拟合
- 还是代码实现和结果解读
欢迎在评论区交流。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 44
44 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)